基于分類數據的可視化改善方法
2018-04-24 07:58:46李存燕
現代計算機 2018年8期
李存燕
(四川大學計算機學院,成都 610065)
0 引言
分類數據是取值不連貫、沒有次序關系的數據,屬于統計數據的一種,可以反映事物的類別,例如人屬于一種分類數據,可以按照性別分為男、女兩類。對分類數據進行預處理,例如排序,聚類等可以改善可視化效果,用來確定相同屬性的相似之處和不同屬性之間的關系。
可視化技術對大型多維數據集的分析和探索變得越來越重要[1-2]。雖然大量的工作已經解決了數字數據的可視化問題,但是許多領域都需要對大量的分類數據進行可視化。目前,研究者已經針對多個領域的數據進行了可視化技術的研究。例如人口普查數據中的城市名稱和本文研究對象網絡管理數據中的告警名稱、產生告警設備編號等,只是與數值數據不同的是,分類值沒有順序。常用的可視化技術例如散點圖和平行坐標圖等,分類值需要映射到坐標軸上(例如產生告警設備編號),處理后按照一定規則排序的數據可以極大地提高可視化的質量。
1 排序分類數據的算法
排序分類數據的算法分為三個步驟:
第一步,使分類數據形成自然聚類,這個階段需要使用領域知識進行分組,例如將接近同樣的時間發出相似事件的設備作為一組。這樣構造的一個重要含義是使得一個分類值可能屬于多個分組。
第二步,給第一步發現的聚類排序。這應該由最小化沖突,或者最大化的解決潛在沖突來完成。這個優化問題能夠更進一步的轉化為一個圖形問題。例如聚類 C1 包含 D1,D3,D4,D5,D6 六個主機,C2 包含D1,D2,D3,D7 四個主機,C3 包含 D1,D4,D5,D8 四個主機,則C1和C2沖突的數量為2(D1,D3),C1和C3沖突的數量為3(D1,D4,D5),C2和C3沖突的數量為 1(D1)。如圖1所示,在這張圖中,節點代表聚類,權重說明聚類間潛在沖突的數量。聚類排序為了最大化的解決潛在沖突,找到一個路徑恰好遍歷每個節點并最大化遍歷弧的總和,是一樣的。這是一個Hamilton[3]路徑問題,一個完全NP問題,有很多啟發式的算法被用于解決這個問題,我們用一個簡單的貪心算法。
第三步,給每個聚類的主機排序。這是直接希望排序相鄰聚類的分類值來消除所有兩個聚類間的潛在的沖突。
算法的假設條件為:排序分類數據能夠改善可視化的效果,以至于能夠更好的研究分析大型、復雜的數據。
●算法輸入:一個告警數據(Excel)
●算法的主要步驟:

圖2 算法流程
●算法輸出:用來構造Y軸的設備號的排序
●平行坐標軸排序分類數據的算法主要思想
平行坐標軸排序分類數據的算法的主要思想繼承了散點圖排序分類數據算法的主要思想。除了第一步不同外,兩個算法的思想跟步驟都基本相同。平行坐標軸排序分類數據的第一步是把基于兩個值的關聯規則聚類成一個屬性。例如,A,B主機都發射了相同的事件類型,則A,B主機被聚為一類。這種方法一個主機也可能同時屬于多個聚類。
2 可視化
數據的可視化是展示實驗結果的最后一步,它負責呈現工作效果、是與客戶交流的關鍵[4]。為了銜接項目組成員在前面所做的工作,我們的任務是尋找合適的可視化工具,借此分別用散點圖和平行坐標圖來展示原始數據與通過算法分組排序后的數據。
通過調研,發現大部分工具功能缺乏,例如魔方,無法進行平行坐標圖的繪制;一部分工具例如raw只能支持在線進行可視化,無法滿足可視化要求;一部分工具比如iCharts,是需要腳本語言進行調用,將其嵌入到網站開發代碼中。通過比較,選擇Tableau和Xdat對實驗數據結果進行可視化。Tableau是用于畫散點圖的工具,十分靈活,可視化圖案美觀清晰,能夠自主調節X軸和Y軸順序。Xdat是用于畫平行坐標圖的工具,它是個開源工具,使用簡單。缺點是不能自主調節X軸和Y軸順序。
散點圖和平行坐標圖的可視化流程如圖3所示。
圖3 散點圖和平行坐標圖的可視化流程
3 實驗
(1)實驗目標
驗證排序分類數據改善可視化效果。
(2)實驗對象(網絡和數據仿真)
實驗對象為根據數據描述制造的仿真數據,部分數據如表1所示:

表1 部分仿真數據
(3)實驗預期結果
對仿真數據進行排序處理后的可視化效果明顯優于未進行排序處理前的可視化效果,①找到某個屬性中相同值的分組;②找到不同屬性值之間的關系。
(4)實驗步驟設計
第一步,構造分類值的自然聚類,實現步驟如下:
每臺設備需要配備3人及1臺運輸切縫用水三輪車,每天切縫80m,折合成本5.75元/m。通過對比分析節省總成本38.88萬元,速度快2.5倍。
①讀取Excel實驗數據
②按照時間段給數據分組,例如6秒內的數據分為一個組
>一共有幾個分組(幾個節點)
>每個分組里面的主機號(重復的忽略)
>根據節點兩兩之間重復的主機號,確定權重
關鍵代碼如下:
//獲取指定的兩個參數之間的權重
③列出每個節點與其他每個節點的權重,輸出矩陣
利用Hamilton算法寫出程序,將矩陣輸入后得到聚類的排序
第三步,給每個聚類內部的主機排序[5],希望可以消除兩個聚類間的潛在沖突,實現步驟如下:
h1,h2為自然聚類得到的分組 a1,2為h1,h2中相同主機號的集合
a)對h1-a1,2中的值進行排序,使其序列處于h2中這些對應值之前
b)對h2-a1,2中的絕對值值進行排序,使其序列處于h2中對應值之后
c)在h2-a1,2和h1-a1,2之間選定a1,2的位置
d)用h2-a1,2和h1-a1,2,絕對值循環排列
關鍵代碼如下:


(5)實驗中間結果展示
經過編碼測試,排序分類數據的結果如下圖所示:
第一步,分類值自然聚類的實驗結果如圖4所示:

圖4 分類值得自然聚類結果
第二步,給第一步得到的自然聚類排序的結果如圖5所示:
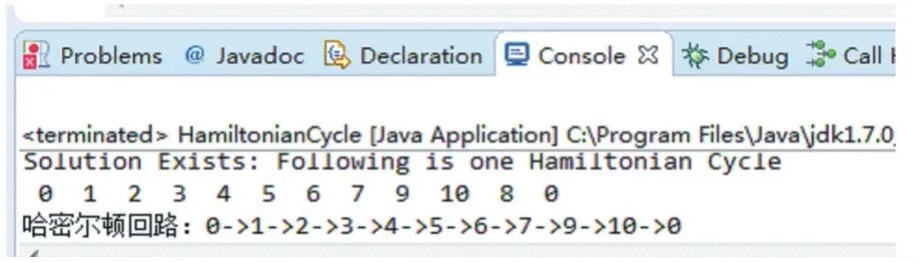
圖5 對自然聚類排序的結果
第三步:給每個聚類內部的主機排序的結果如圖6所示:

圖6 聚類內部的主機排序的結果
(6)可視化效果
對分類數據排好序后,使用畫散點圖的工具Tab?leau,按照分類結果調節Y軸,然后倒入仿真數據得到可視化結果,如下圖所示:
●散點圖繪制實例如圖7和8所示。

圖7 排序前的可視化圖
4 可視化結果分析
觀察實驗得到的排序前后的可視化效果圖,發現經過處理后平行坐標軸的可視化效果更佳,達到了預期找到不同屬性值之間的關系的效果。從圖9處理后的平行坐標軸可視化圖可以明顯觀察到大多數other類的告警都是由設備D1產生的,error7_alarm3到er?ror7_alarm48的告警基本都是由設備D9產生的等,該結果可用于告警預測,或者當網絡發生告警時進行根因分析、定位等。
圖8 排序后的可視化圖
●平行坐標軸繪制實例如圖9所示:
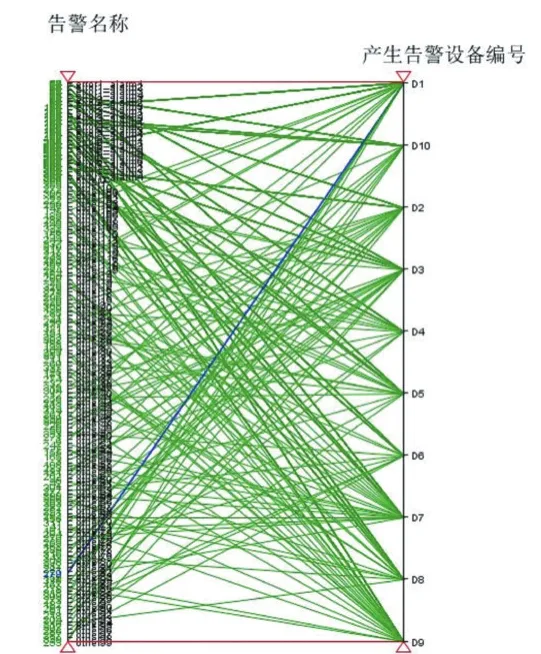
圖9 處理前的可視化圖
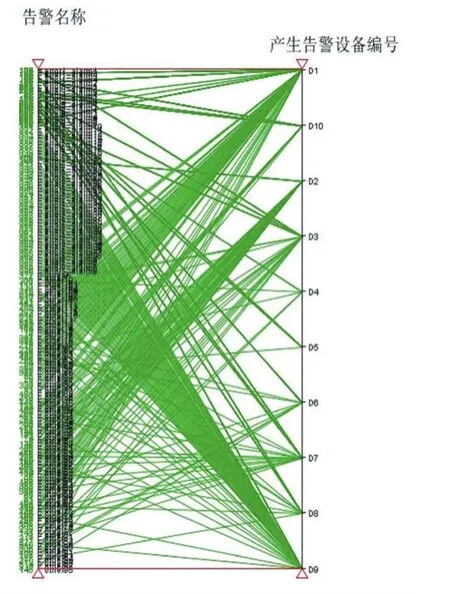
圖10 處理后的可視化圖
散點圖的可視化效果改善不夠明顯,分析有如下原因:①實驗使用的是根據數據描述制造的仿真數據,數據本身相當于經過了預處理后的數據,所示實驗結果不理想;②實驗數據量太少,改善效果不夠明顯。下一步考慮采取增大數據量或者采用真實數據等方法,以期獲得更優的實驗效果。
參考文獻:
[1]Ahlberg C,Wistrand E.IVEE:an Information Visualization and Exploration Environment[M].CiteSeer,1995.
[2]Ankerst M,Berchtold S,Keim D A.Similarity Clustering of Dimensions for an Enhanced Visualization of Multidimensional Data[C].Information Visualization,1998.Proceedings.IEEE Symposium on.IEEE,1998:52-60,153.
[3]蔡延光,張新政,錢積新,孫優賢.邊賦權森林ω-路劃分的 O(n)算法[J].軟件學報,2003(05):897-903.
[4]沈漢威,張小龍,陳為,袁曉如,王文成.可視化及可視分析專題前言[J].軟件學報,2016,27(05):1059-1060.
[5]Ma S,Hellerstein J L.Ordering Categorical Data to Improve Visualization[J].Proceedings of the IEEE Information Visualization Symposium Late Breaking Hot Topics,1999.
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
云南化工(2021年8期)2021-12-21 06:37:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
傳媒評論(2019年4期)2019-07-13 05:49:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
