基于co-location模式的空間分類算法
2018-04-18 11:33:53趙秦怡王麗珍羅桂蘭
計(jì)算機(jī)應(yīng)用與軟件 2018年3期
趙秦怡 王麗珍 羅桂蘭
1(大理大學(xué)數(shù)學(xué)與計(jì)算機(jī)學(xué)院 云南 大理 671003) 2(云南大學(xué)信息學(xué)院 云南 昆明 650091)
0 引 言
空間分類是指對空間對象分類時(shí),除了要考慮待分類對象的非空間屬性對分類結(jié)果的影響[1],還要考慮其空間鄰接對象對分類結(jié)果的影響[2]。Fayyad等[2]提出了一種空間決策樹分類方法,使用決策樹對衛(wèi)星圖像中的星系對象進(jìn)行分類。Ester等[3]提出一種基于ID3算法的空間分類方法,分類標(biāo)準(zhǔn)基于待分類對象的非空間屬性及空間屬性、謂詞和函數(shù)。Koperski等[4]對Ester等的算法進(jìn)行了改進(jìn),降低了算法的時(shí)間復(fù)雜度。Shekhar等[5]提出了一種基于粗糙集的空間分類方法,采用空間謂詞對空間關(guān)系進(jìn)行泛化,再使用粗糙集對數(shù)據(jù)進(jìn)行分類。
空間co-location模式挖掘是指發(fā)現(xiàn)一組空間特征集合c,c中空間特征的實(shí)例在地理空間中頻繁出現(xiàn)[6]。基于全連接的Join-based算法[7]將Apriori算法思想引入了空間co-location模式挖掘中,利用特征實(shí)例間的鄰近關(guān)系挖掘co-location模式。部分連接的partial-join算法[7]把連續(xù)空間中的實(shí)例分割為不相交的團(tuán),并且通過鄰近關(guān)系的斷點(diǎn)保持這些團(tuán)之間的關(guān)系。文獻(xiàn)[8]提出了一種基于星型鄰居擴(kuò)展的無連接joinless算法,算法不需要通過連接實(shí)例來產(chǎn)生co-location模式表實(shí)例。針對產(chǎn)生的表實(shí)例開銷大的問題,王麗珍等[9-11]提出了基于前綴樹的co-location模式挖掘方法。
在滿足某種co-location模式的空間中,一些具有特定特征空間對象的出現(xiàn)意味著另一種特定特征空間對象的出現(xiàn)[12]。如半濕潤常綠闊葉林生長的地方80%有蘭類植物的生長,有尼羅河鱷魚的地方85%會(huì)有埃及鸻。特定環(huán)境下的co-location模式中含有空間分類所需的分類規(guī)則,本文提出了基于co-location模式的空間分類算法。
1 基本概念
1) 空間co-location模式[12]:一個(gè)空間co-location模式是一組空間特征的集合c,這些空間特征的實(shí)例在地理空間中頻繁地出現(xiàn),其中c?F。
例:{半濕潤常綠闊葉林,蘭類植物}是一個(gè)co-location模式。
2) 參與度(PR(c))[12]:參與度是指衡量co-location模式c的頻繁性所使用的支持度標(biāo)準(zhǔn),它的取值是co-location 模式c的所有空間特征參與率(PR值)中的最小值,記為PI(c)。
參與率[12]記為PR(c,fi),是特征fi的實(shí)例在co-location模式c的所有實(shí)例中不重復(fù)出現(xiàn)的個(gè)數(shù)與fi總實(shí)例個(gè)數(shù)的比率,其計(jì)算式如下:
(1)
3) 類別特征
定義1在空間分類問題中,待分類對象的類標(biāo)號屬性值域記為C,由C中的每一個(gè)元素值定義的空間特征稱為類別特征。
例1:在植物生長區(qū)域的分類任務(wù)中,類屬性“是否有蘭類植物生長”值域?yàn)閧Yes,No},可將該分類任務(wù)的類別特征集定義為{CS1,CS2},CS1代表特征“有蘭類植物生長”,CS2代表特征“沒有蘭類植物生長”。
4) 與分類任務(wù)相關(guān)的空間co-location模式
定義2與分類任務(wù)相關(guān)的空間co-location模式是指一個(gè)含有類別特征的空間co-location模式(記為CB co-location)。一個(gè)CB co-location模式的表實(shí)例滿足最小參與度閾值。
例2:在某分類任務(wù)中,類別特征集CS={CS1,CS2,CS3},與該分類問題相關(guān)的空間屬性集F={A,B,C,D},模式{CS1,A}、{CS2,B}、{CS1,A,B}、{CS2,C,D}、{CS3,B,C}含某一類別特征,參與度大于給定的最小參與度閾值,它們是CB co-location模式。而模式{A,B}、{B,C,D}不含類別特征,不論參與度為多少,它們不是CB co-location模式。
5) 規(guī)則A→B的置信度:指出現(xiàn)特征A的情況下,特征A、B共同出現(xiàn)的概率,是衡量規(guī)則可信度的有效性度量,記為Confidence(A→B),計(jì)算式表示為:
(2)
2 基于co-location模式的空間分類算法
2.1 算法思想
在特定的空間分類任務(wù)中,空間對象的類別和自身非空間屬性相關(guān)較小,和空間近鄰對象的特征相關(guān)較大[12-13],用傳統(tǒng)的空間分類方法來進(jìn)行分類并不適用。如加油站選址分類任務(wù)主要考察近鄰對象是否具備如高速路、交通關(guān)口、交通流量等特征;移動(dòng)服務(wù)運(yùn)營商針對不同地區(qū)設(shè)置相應(yīng)的移動(dòng)服務(wù)需求模式;廣告商在某類人群聚集區(qū)域放置不同種類的廣告。在前述的分類問題中,目標(biāo)對象的類別由近鄰對象的特征決定,和自身非空間屬性的相關(guān)關(guān)系可以忽略。若將分類任務(wù)進(jìn)行泛化,即將近鄰對象及目標(biāo)對象的類別進(jìn)行泛化,得近鄰特征及類別特征,前述的分類任務(wù)可描述為:在特定空間模式下,近鄰特征集的不同決定了空間目標(biāo)對象類別的不同,即特定空間中的co-location模式含空間分類所需的分類規(guī)則。
基于co-location模式的空間分類是指利用含類別特征的空間co-location模式對空間對象進(jìn)行分類。算法需在特征實(shí)例集中挖掘所有含任一類別特征的CB co-location模式。第一步,在訓(xùn)練階段根據(jù)類標(biāo)號屬性的值域得到若干相應(yīng)的空間類別特征CS1~CSn,n為分類問題中類屬性的取值個(gè)數(shù)。確定與分類問題相關(guān)的空間特征集A,該項(xiàng)工作可由領(lǐng)域?qū)<逸o助完成。由類別特征CS1和A構(gòu)成空間特征集AR,在AR的實(shí)例集中挖掘含有類別特征CS1的CB co-location模式;由類別特征CS2和A構(gòu)成空間特征集AR,挖掘含類別特征CS2的CB co-location模式;重復(fù)該過程,直至挖掘出含類別特征CSn的CB co-location模式。將上述所有的CB co-location模式歸并,構(gòu)成目標(biāo)模式集CB。第二步,生成CB對應(yīng)的分類規(guī)則集R,規(guī)則的后件為類別特征,計(jì)算規(guī)則的置信度。由于CB co-location模式均為頻繁模式,故規(guī)則的支持度(興趣度標(biāo)準(zhǔn))在算法中不再度量。第三步,分類階段在空間近鄰集中查詢出待分類對象的近鄰對象集,將其概化為近鄰空間特征集[14],運(yùn)算出該特征集的各子集,找出分類規(guī)則集R中所有包含任一子集的分類規(guī)則,由其中支持度最大的分類規(guī)則中規(guī)則后件(類別特征)決定待分類對象的類別。
例3:某空間分類問題中,訓(xùn)練集類別特征集CS={CS1,CS2},與分類任務(wù)相關(guān)空間特征集A={A,B,C,D,E},參與度閾值70%。各特征實(shí)例為:CS1.1~CS1.3,CS2.1~CS2.3,A.1~A.4,B.1~B.4,C.1~C.4,D.1~D.4,E.1~E.4。特征實(shí)例間的近鄰關(guān)系如圖1所示。待分類空間對象O1、O2、O3,含分類對象的空間近鄰關(guān)系集略。

圖1 例3中特征實(shí)例間的近鄰關(guān)系圖
基于co-location模式的分類過程如下:
1) 生成空間特征集AR={CS1,A,B,C,D,E},挖掘含類別特征CS1的CB co-location模式。所得含CS1的頻繁模式如表1所示。

表1 含CS1的CB co-location模式
得到目標(biāo)模式集合CB={{CS1,A},{CS1,B}, {CS1,A,B}}。
2) 生成空間特征集AR={CS2,A,B,C,D,E},挖掘含類別特征CS2的CB co-location模式。所得含特征CS2的頻繁模式如表2所示。

表2 含CS2的CB co-location模式
得到目標(biāo)模式集合CB={{CS1,A},{CS1,B}, {CS1,A,B},{CS2,C},{CS2,D},{CS2,E},{CS2,D,E}}。
3) 由集合CB導(dǎo)出分類規(guī)則并計(jì)算規(guī)則的置信度。得規(guī)則集R={A→CS1(100%),B→CS1(75%),(A,B)→CS1(75%),C→CS2(75%),D→CS2(75%),E→CS2(75%),(D,E) →CS2(75%)}。
4) 在空間數(shù)據(jù)庫中查詢待分類空間對象O1、O2、O3的近鄰對象,將近鄰對象概化為空間特征,得到O1的近鄰空間特征集{A,B,E},O2的近鄰特征集{D,E},O3的近鄰特征集{A,B,C,D,E}。對象O1的近鄰特征集的所有子集為{A},{B},{E},{A,B},{A,E},{B,E},{A,B,E},集合R中的規(guī)則A→CS1(100%),B→CS1(75%),(A,B)→CS1(75%) 包含了子集{A},{B},{A,B},其他規(guī)則不包含O1的任意子集。故對象O1的類別由規(guī)則A→CS1(100%),B→CS1(75%),(A,B)→CS1(75%)決定。根據(jù)算法,由參與度最大的規(guī)則A→CS1(100%)得到O1的類別為CS1。O2和O3的分類過程同上,得O2的類別為CS2,O3的類別為CS1。
空間co-location模式在挖掘時(shí),將k階特征集(前n項(xiàng)相同)相連接而得到k+1階特征集。由此可知在挖掘與類別相關(guān)的空間co-location模式時(shí),若k階co-location模式中含類別特征,則k+1階co-location模式也含類別特征。在挖掘2階co-location模式時(shí),只需考慮含類別特征的二階模式集,將類別特征在空間特征集中排在第一位,由模式組合方法,即前n-1個(gè)特征相同進(jìn)行組合,可知挖掘出的更高階co-location模式也一定含類別特征。這樣,在剪枝階段避免了大量剪枝,算法的計(jì)算復(fù)雜度得到了有效降低。
2.2 算法描述
算法1基于co-location模式的空間分類算法
輸入:實(shí)例近鄰關(guān)系集T,類別特征集S,分類任務(wù)相關(guān)空間特征集A,空間類別特征集CS。
輸出:R,C_label。
算法中所用符號說明見表3。

表3 符號說明

續(xù)表3
算法描述:
Step1數(shù)據(jù)預(yù)處理:在實(shí)例近鄰集T中刪除不含任一類別特征實(shí)例的完全獨(dú)立連接。
Step2由集合CS和A生成含類別特征CSi的分類任務(wù)相關(guān)空間特征集(CSi,A1,A2,…,An)→AR。
Step3挖掘滿足最小參與度閾值minf并且含特征CSi的CBco-location→CB。
Step4i++,若i≤n,轉(zhuǎn)Step2。(這樣所有含CS1~CSn中某一特征的CB co-location均挖掘出)。
Step5生成形如X→CSi的分類規(guī)則集R:對CB中的每一個(gè)co-location模式,模式中的第一個(gè)特征(CSi)作為規(guī)則的后件,模式中第2個(gè)特征起始的所有特征作為規(guī)則的前件,掃描近鄰實(shí)例集,計(jì)算規(guī)則的置信度。
Step6查詢對象O的近鄰對象集N,將N概化為近鄰特征集NA,計(jì)算NA的所有子集。
Step7對每一子集NAi,若NAi等于R中某一規(guī)則的前件,則將該規(guī)則→OB。
Step8挑選出OB中置信度最大的規(guī)則CY,CY的后件→C_label。
算法在挖掘二階模式時(shí),只需挖掘含類別特征的二階模式,故不需要將特征集中所有特征兩兩組合。算法中候選模式生成階段的SQL偽代碼如下:
if k==1
//在初始屬性集中將類別特征CSi放在元素f1的位置上
{ for q=f2to fn
select CSi,,q -> insert into C2
}
else
{ forall co-location p∈Ck
forall co-location q∈Ck
insert into Ck+1
select p.f1,p.f2,…,p.fk,q.fk+1
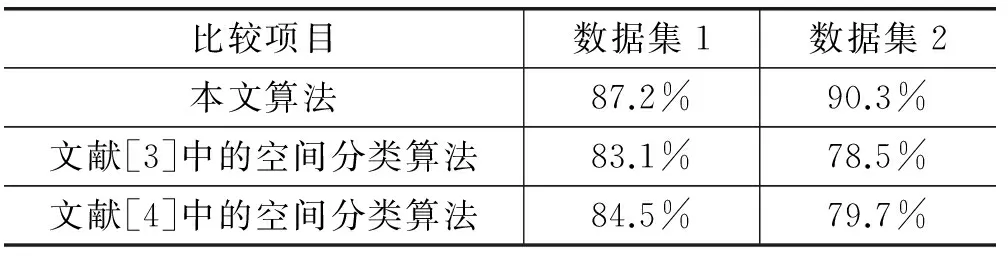
where p.f1=q.f1,…,p.fk=q.fk,p.fk+1 } 算法的時(shí)間復(fù)雜度集中在二階表實(shí)例的搜索及分類規(guī)則支持度計(jì)算階段,若特征實(shí)例數(shù)越多,需要的運(yùn)行時(shí)間越長。其次,若分類問題的類標(biāo)號屬性值越多,需要挖掘的含類別特征的分類規(guī)則增加,算法的運(yùn)行時(shí)間隨之增加。設(shè)有n個(gè)類別,m個(gè)特征,每個(gè)特征k個(gè)實(shí)例,算法時(shí)間耗費(fèi)主要在星型模型生成、二階頻繁模式生成、模式連接及表實(shí)例搜索、規(guī)則參與度計(jì)算等階段,算法總的時(shí)間復(fù)雜度為O(n(k2+2m+1k))。 通過實(shí)驗(yàn)對算法的分類準(zhǔn)確率和運(yùn)行時(shí)間進(jìn)行了評價(jià)。實(shí)驗(yàn)環(huán)境:intel core(TM)i7-7500U的CPU,2.7 GHz主頻,8 GB內(nèi)存,Windows 10操作系統(tǒng),編程環(huán)境VC++6.0,模式挖掘采用joinlesss方法。實(shí)驗(yàn)中數(shù)據(jù)集1采用合成數(shù)據(jù),含類別特征3個(gè),與分類任務(wù)相關(guān)空間特征5個(gè),特征實(shí)例數(shù)共2 000個(gè);數(shù)據(jù)集2為某地區(qū)電信服務(wù)運(yùn)營商的服務(wù)類別空間數(shù)據(jù),含類別特征4個(gè)(即4種服務(wù)類別),與分類任務(wù)相關(guān)空間特征7個(gè),特征實(shí)例數(shù)共3 000個(gè)。其中,60%的數(shù)據(jù)用于訓(xùn)練集,40%的數(shù)據(jù)用于測試集。 1) 分類準(zhǔn)確率,結(jié)果見表4。 表4 幾種算法分類準(zhǔn)確率 實(shí)驗(yàn)結(jié)果表明,在特定的空間分類任務(wù)中,分類結(jié)果與待分類對象空間近鄰的特征相關(guān)較大,與自身非空間屬性相關(guān)較小,用文獻(xiàn)[3]和文獻(xiàn)[4]中傳統(tǒng)的分類方法并不適用,分類準(zhǔn)確率較低。本文提出的基于co-location模式的空間分類方法由于在訓(xùn)練階段所得的分類規(guī)則均為興趣度高的規(guī)則,分類準(zhǔn)確率較高,是有效的空間分類方法。本實(shí)驗(yàn)在對數(shù)據(jù)集1和數(shù)據(jù)集2中的空間對象實(shí)現(xiàn)文獻(xiàn)[3]和文獻(xiàn)[4]的算法時(shí),還合成了數(shù)據(jù)集1,收集了數(shù)據(jù)集2中空間對象在分類時(shí)所需的數(shù)據(jù),如空間對象的非空間屬性、鄰接關(guān)系、鄰接對象的非空間屬性等。 2) 數(shù)據(jù)集1不同實(shí)例規(guī)模下的算法運(yùn)行時(shí)間,結(jié)果見表5。 表5 不同數(shù)據(jù)規(guī)模下算法運(yùn)行時(shí)間 實(shí)驗(yàn)結(jié)果表明,隨著特征數(shù)及實(shí)例數(shù)增加,算法所需的運(yùn)行時(shí)間增長比較快,但也表明了本算法是高效的空間分類算法,可適用于空間數(shù)據(jù)庫中的大數(shù)據(jù)集。 由于實(shí)例的近鄰集中不含類別特征實(shí)例的完全獨(dú)立連接與分類任務(wù)不相關(guān),算法在數(shù)據(jù)預(yù)處理階段,在實(shí)例的近鄰集中去除不含類別特征實(shí)例的獨(dú)立完全連接,在查找頻繁模式的表實(shí)例時(shí),搜索范圍可得到有效的縮減。在分類規(guī)則集中,一部分規(guī)則在分類階段的利用率不高,在搜索階段卻需要頻繁搜索,增加了算法的開銷,可以考慮提高模式參與率、統(tǒng)計(jì)規(guī)則使用率等方法減少分類規(guī)則。在分類之前還可以利用測試集對分類規(guī)則集進(jìn)行劃分,在測試集上測試分類準(zhǔn)確率時(shí)挑選出頻繁使用的規(guī)則,不頻繁的規(guī)則可構(gòu)成候選規(guī)則集,將測試集分成若干子集,重復(fù)挑選若干次,增加頻繁規(guī)則集的興趣度。在分類階段,首先搜索頻繁規(guī)則集,無規(guī)則適應(yīng)的情況下再來搜索候選規(guī)則集即可。 在特定的空間分類任務(wù)中,類別與自身屬性相關(guān)較小,與空間近鄰對象的特征相關(guān)較大,用一些典型的空間分類方法進(jìn)行分類并不適用,得到的分類準(zhǔn)確率較低。基于co-location模式的空間分類算法由含類別特征的空間co-location模式導(dǎo)出與分類任務(wù)相關(guān)度比較高的分類規(guī)則,利用待分類對象空間近鄰對象的特征對其分類。實(shí)驗(yàn)結(jié)果表明,本文提出的空間分類算法在特定的分類任務(wù)下是分類準(zhǔn)確率較高的有效分類算法。但數(shù)據(jù)集增大時(shí),算法的時(shí)間耗費(fèi)增長較快,對算法進(jìn)行有效剪枝,減少算法時(shí)間復(fù)雜度,提高分類準(zhǔn)確率,是今后的努力方向。 [1] 張晶,畢佳佳,劉爐.基于 mRMR的多關(guān)系樸素貝葉斯分類[J].計(jì)算機(jī)應(yīng)用與軟件,2016,33(8):57-61. [2] Fayyad R T,Muntz R.Mining Knowledge in Geographical Data[J].IEEE Transaction on Knowledge and Data Engineering,2005,10:903-913. [3] Ester M,Kriegel H P,Sander J.Spatial data mining:A database approach[C]//International Symposium on Advances in Spatial Databases.Springer-Verlag,1997:47-66. [4] KoperSki K,Han J W,Stefanovic N.An efficient two-step method for classification of spatial data[J].IEEE Transaction on Knowledge and Data Engineering,2008,14(5):1003-1016. [5] Shekhar S,Schrater P R,Vatsavai R R,et al.Spatial contextual classification and prediction models for mining geospatial data[J].IEEE Transactions on Multimedia,2002,4(2):174-188. [6] Huang Y,Shekhar S,Xiong H.Discovering co-location patterns from spatial data sets:A general approach[J].IEEE Transactions on Knowledge and Data Engineering,2004,16(12):1472-1485. [7] Yoo J S,Shekhar S.A partial join approach for mining Co-location patterns[C]//Proceedings of the ACM International Symposium on Advances in Geographic Information System s(ACMGIS).Washington,USA,2004:241-249. [8] Yoo J S,Shekhar S,Celik M.A join less approach for Co-location pattern mining:A summary of results[C]//Proceedings of the IEEE International Conference on Data Mining (ICDM ).Houston,USA,2005:813-816. [9] Wang Lizhen,Bao Yuzhen,Lu J,et al.A new join-less approach for co-location pattern mining[C]//Wu Qiang,He Xiangjian,Nguyen Q V.Proceedings of the IEEE 8th International Conference on Computer and Information Technology (CIT’08),Sydney,Australia,2008.Piscataway,NJ,USA:IEEE,2008:197-202. [10] Wang Lizhen,Bao Yuzhen,Lu Zhongyu.Efficient discovery of spatial co-location patterns using the iCPI-tree[J].The Open Information Systems Journal,2009,3(1):69-80. [11] Wang Lizhen,Zhou Lihua,Lu J.An order-clique-based approach for mining maximal co-locations[J].Information Sciences,2009,179(19):3370-3382. [12] 王麗珍,陳紅梅.空間模式挖掘理論與方法[M].北京:科學(xué)出版社,2014. [13] 王麗珍,周麗華,陳紅梅.數(shù)據(jù)倉庫與數(shù)據(jù)挖掘原理及應(yīng)用[M].2 版.北京:科學(xué)出版社,2009. [14] 郭慶勝,魏智威,王勇,等.特征分類與鄰近圖相結(jié)合的建筑物群空間分布特征提取方法[J].測繪學(xué)報(bào),2017,46(5):631-638.3 算法分析及實(shí)驗(yàn)

4 結(jié) 語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
