一種基于HBase的語義數據存儲模型
2018-04-18 11:40:35翟社平李兆兆
計算機應用與軟件 2018年3期
翟社平 高 山 郭 琳 李兆兆
(西安郵電大學計算機學院 陜西 西安 710121)
0 引 言
語義Web核心思想[1]是通過語義信息的分享,實現網絡信息服務的智能化、自動化,從而促使互聯網成為信息交換的通用媒介。
隨著人工智能的發展和計算機應用需求的不斷增強,語義Web技術已經深入到社會生活的各個領域,如輿情監控、知識圖譜、穿戴計算、智能家居、智慧校園等。語義Web是萬維網的一個擴展,其影響范圍和應用范圍在不斷地擴大,越來越多的研究者開始高度關注和重視到語義Web技術的應用。
為了對Web資源及其屬性進行規范化描述,W3C組織提出了一個Web資源之間語義關系的開放元數據框架RDF[2]。RDF是語義Web建立的重要基礎,通常以三元組(RDF Triple)數據模型(主語、謂語、賓語)描述Web資源之間存在的特定關系。簡單而言,一個RDF語句是由資源、屬性類型、屬性值構成的三元組。基于語義Web的RDF三元組標簽可以構造信息間邏輯推理關系的本體模型,進而使人與機器間、機器與機器間的交流變得像人與人之間交流一樣輕松。
隨著語義Web的迅猛發展,越來越多的互聯網數據以RDF的形式發布出來。自2007年第一代關聯數據發布至今,RDF數據增長速度不斷加快。據關聯開放數據LOD(Link Open Data)統計,2012年關聯數據云中已經包括295個數據集、316億個RDF三元組以及5.04億個RDF鏈接。截止2017年1月,關聯數據云中的數據集已經達到1 146個[3],約是2012年的4倍。如此大規模的RDF數據就為語義Web技術的發展提出了新的挑戰。
現在的互聯網正處在語義化蛻變過程中,智能化語義Web在理解人類語言的基礎上逐漸實現了人機交互的網絡訪問。如何高效地管理大規模RDF數據已經成為推動語義Web技術發展亟待解決的重要問題。目前,RDF數據存儲需要解決以下兩個關鍵問題:
1) 如何建表才能在RDF數據存儲空間開銷和查詢性能之間找到平衡點;
2) 如何建立簡單、有效索引才能將RDF數據的查詢化繁為簡。
針對傳統的RDF數據存儲在大數據集下表現不盡人意的現狀,本文從用戶行為習慣的角度出發,統計發現90%以上的查詢都包含被約束的謂語值。通過分析現有的存儲模式,充分結合語義數據查詢特征,本文提出了一種基于分布式數據庫HBase的RDF數據存儲模型。將RDF數據存儲到HBase表中以實現海量語義數據的分布式存儲,并通過自定義的Bulk Loading數據加載方式完成數據上傳,進而解決數據初始導入效率低的問題,同時實現RDF數據的高效查詢。
1 相關研究工作
傳統集中式的RDF數據管理大都采用關系型數據庫管理系統RDBMS(Relational Database Management System)來存儲RDF數據。RDBMS是一個二維映射的集中式存儲數據庫系統,表中每一列需預定義數據類型和長度,且表中的列數存在限制。目前基于關系型數據庫的語義數據存儲方案有三元組表存儲、垂直存儲、水平存儲和模式生成存儲等。
三元組表存儲是最為簡潔的一種RDF數據存儲方式,其核心思想是每條三元組對應一條數據記錄。垂直存儲的核心思想是將同一謂語的三元組存到同一張表中,由于數據表本身已經將RDF的謂語屬性值隱藏,因此數據表只保存主語和賓語兩列數據值。水平存儲的核心思想是將所有謂語作為列名存儲在一張表中,通過一張表即可存儲所有RDF數據。模式生成存儲的核心思想是根據空值分布對表做垂直和水平切分,混合切分后的數據表會在很大程度上減少表中存儲的空值數量。
表1從優勢、劣勢兩個方面對以上四種存儲方案進行簡單總結。
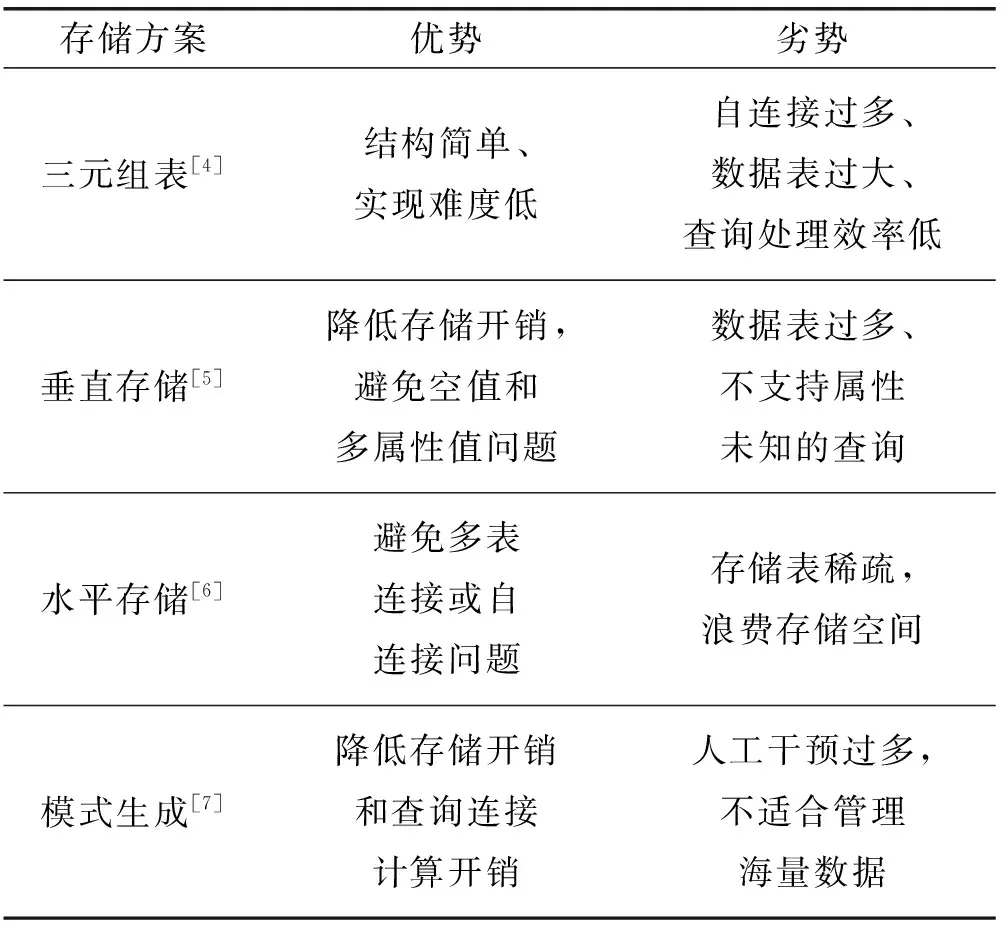
表1 基于關系型數據庫的存儲方案總結
面對RDF數據的急劇增長,傳統關系型數據庫已無法高效地對其進行管理,越來越多的研究者使用分布式系統和并行計算技術來管理大規模RDF數據。這類系統采用傳統的分布式計算架構,并對RDF數據存儲和查詢進行優化。
其中,研究者曾提出一個分布式RDF數據查詢框架SPARQL ENGINE[8],該系統架構實現了大數據環境下RDF數據的分布式查詢機制。但是,該框架并沒有對RDF數據在分布式數據庫中的存儲策略進行研究。Bigdata是另一種分布式存儲系統,在存儲上,其采用分區存儲,利用key-range劃分的B+樹索引來分布式訪問集群資源,而且這種劃分是動態進行的[9]。但是該系統也存在著通信開銷大、數據存取結構和安全性難以控制的缺點。
除此之外,在RDF數據存儲領域已經有研究人員將RDF與Hadoop相結合,目前這方面的研究工作主要集中在Hadoop的存儲設計以及基于存儲模式的數據查詢處理上。Hadoop是Apache公司效仿Google云設計的開源平臺,其具有可擴展、經濟、高效、可靠等諸多優點,適合于對海量數據進行存儲、搜索、挖掘和分析。研究學者提出了一種基于Hadoop的RDF數據編碼模型,詳細介紹了詞典構建的方法,通過構建好的數據詞典實現RDF三元組的編解碼操作,該方法在減少存儲容量占用的同時保證了數據的安全性[10]。但是,該存儲模型仍然采用S_PO、P_OS、O_SP、PS_O、SO_P和PO_S六張索引表進行存儲,在數據存儲設計方面并沒有給出存儲模式的優化方案。
2 基于HBase的RDF數據存儲
2.1 存儲分析
HBase是一個高可靠性、高性能、列存儲、可伸縮、支持實時讀寫的數據庫系統,底層的Hadoop分布式文件系統HDFS(Hadoop Distributed File System)具有高容錯性且可以被部署在低價的硬件設備之上[11]。HBase是一個多維映射的數據存儲表,其數據存儲模型為Key-Value類型:
(Row-Key,Column Family,Timestamp)->Value
Row-Key為表中唯一的行標識,動態擴展的多個列合并為一個列族(Column Family),時間戳用來區分所存數據的不同版本,進而唯一確定數據單元值Value。
表2描述了百度網站分頻道(百科、文庫、貼吧等)關系數據在HBase表中的S_PO存儲結構。該表以主語www.baidu.com為Row-key,謂語Anchor:channel對應三個賓語值,Timestamp表示時間戳。
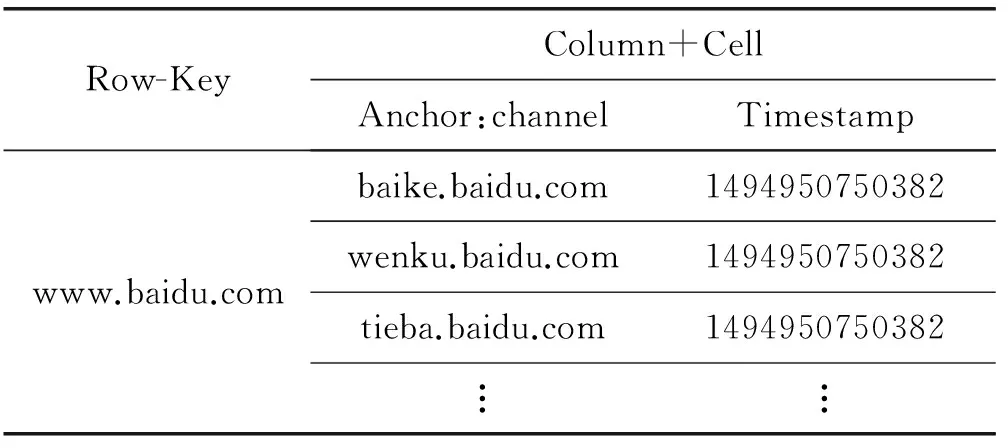
表2 表S_PO在HBase中的存儲結構
基于HBase的數據存儲方案不對空值做存放操作,邏輯上為空的單元值并不占用實際的存儲空間,所以HBase的稀疏特性非常適合存儲RDF數據。
將RDF三元組<主語(Subject)、謂語(Predicate)、賓語(Object)>中不同的元素和元素組合作為Row-Key索引,需要設計S_PO、P_OS、O_SP、PS_O、SO_P和PO_S六張HBase索引表來對數據進行存儲。實際上,S_PO、P_OS、O_SP三種數據屬性排列方式足以能夠為所有的三元組查詢模式提供索引服務。S_PO、P_OS、O_SP分別表示以S、P、O為Row-Key,其查詢組合對應的索引如表3所示。

表3 查詢組合索引表
注:“?”表示在三元組的位置存在一個未知值,“--”表示該值被約束(即,固定)
2.2 存儲改進策略
RDF數據存儲模型的目標是高效地執行各種查詢操作,現有的RDF存儲系統為了實現這一目標大都從數據源本身出發,對如何合理地拆分三元組數據集進行研究。但是,從數據查詢的角度來講,已有的存儲方式忽略了用戶查詢習慣本身所帶來的應用價值。
本文通過對里海大學基準LUBM(Lehigh University Benchmark)測試基準中的查詢記錄進行統計分析,發現SP?、?PO、?P?三種約束謂語的查詢模式最符合日常查詢習慣,其查詢請求數量約占查詢總數的90%。由此可見,謂語在大多數情況下是作為約束對象出現在查詢語句中。但是在實際的RDF數據集中,謂語的數量通常在數十至數百范圍內,遠遠少于主語和賓語數量,因此當謂語作為行鍵索引(Row-Key)時會使系統負載增大,查詢效率降低。
為了適應謂語在查詢中出現的高頻特性,本文在S_PO、O_SP索引表不做處理的基礎上,對P_OS索引表給出改進策略。將基于謂語索引的存儲表細分為P_OS、P_SO兩大類,實現謂語約束下主語或賓語查詢的兩種不同組合。具體實現形式表示如下:
P_OS:
Row Key:Predicate URI{
Column Family:Object{
Column:(Subject)
}
}
P_SO:
Row Key:Predicate URI{
Column Family: Subject {
Column:(Object)
}
}
2.3 模型設計
本文設計如圖1所示的RDF三元組數據存儲模型,該模型在S_PO和O_SP索引表不做修改的基礎上對P_OS索引表進行改進。每條謂語分別對應P_OS、P_SO兩類索引表,將每一謂語值作為熱數據進行索引存儲。完成以謂語為索引的RDF數據存儲模型后,謂語確定的RDF數據查詢會變得十分高效。由于謂語在整個RDF數據集中數量級極小,所以以謂語為索引的RDF數據存儲表可以快速鎖定數據,再加上原有S_PO和O_SP的RDF數據存儲模型,整個存儲系統就會變得很完善。從用戶查詢的角度講,也能滿足絕大多數數據的高效查詢。
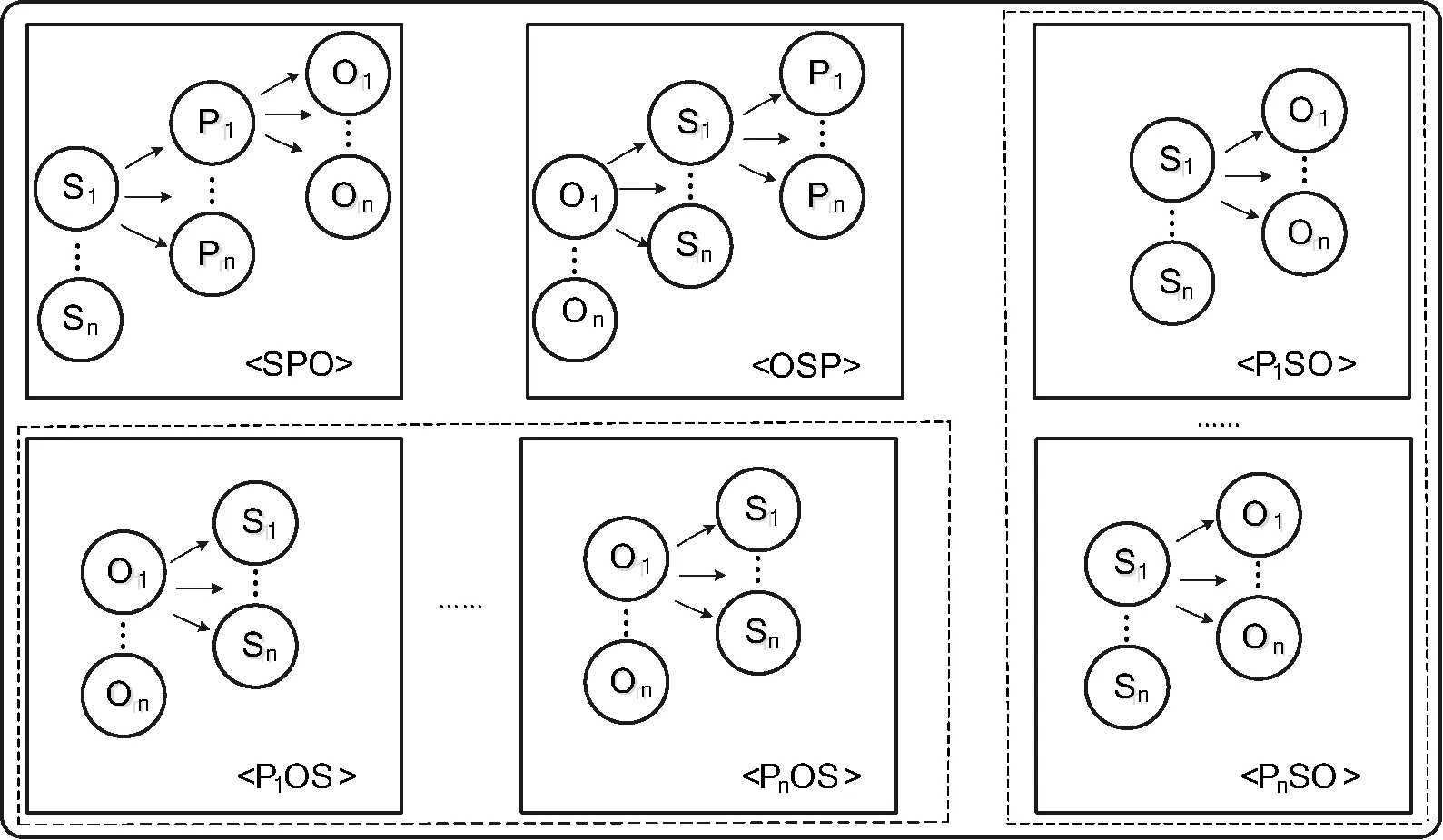
圖1 RDF三元組存儲模型
以謂語為索引的RDF數據存儲模型旨在優化以謂語為約束條件的RDF數據查詢。對照表3所示的查詢組合索引,該存儲模型針對不同查詢索引做出改進,具體方案如下:
1) 為每種查詢組合指定唯一確定的索引表;
2) 針對SP?高頻查詢組合,將優化前的S_PO索引表替換為P_SO索引表。
該存儲模型充分考慮RDF三元組合的謂語特征,在實現系統負載均衡的同時能夠提升數據的查詢效率。表4介紹了改進后的RDF數據查詢索引情況。
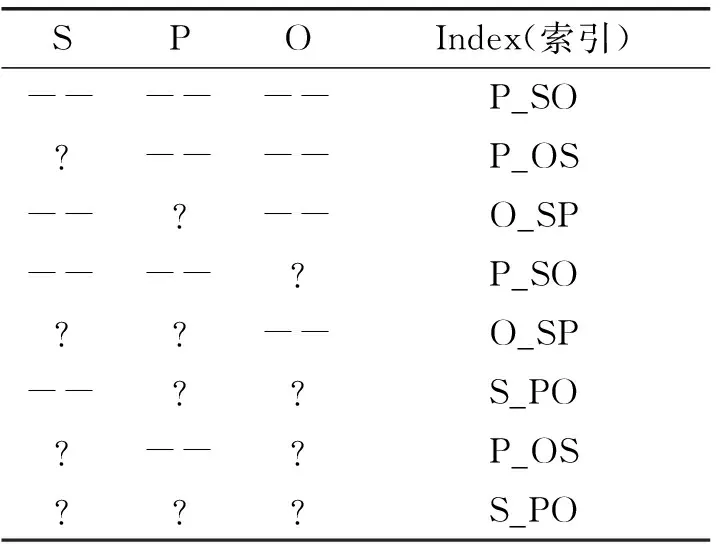
表4 查詢索引表(改進后)
2.4 查找索引算法
查找索引算法的目標是找出與查詢請求相對應的索引類型。結合表4的查詢組合索引,給出該存儲模型的查詢索引算法,如算法1所示。
算法1查詢索引
輸入:查詢語句
輸出:索引類型
開始
//若謂語被約束
if(predicate is constrained)
{
//且主語被約束
if (subject is constrained)
return P_SO
else
return P_OS
}
else
{
//賓語被約束
if (object is constrained)
return O_SP
else
return S_PO
}
結束
該算法給出了查詢索引的詳細過程。根據查詢語句做出判斷,若謂語被約束,可以通過判斷主語是否被約束來確定相對應的索引類型;反之,可以通過判斷賓語是否被約束來確定相對應的索引類型。該算法的核心思想是根據用戶查詢請求模型,優先匹配被約束的元素,進而快速決定使用何種對應索引。
2.5 Bulk Loading數據加載
完成數據存儲模型的設計后,接下來就要實現將RDF數據按照S_PO,P_SO,P_OS,O_SP模型加載到HBase中。HBase數據加載有兩種通用方法:一是通過MapReduce調用TableOutpu-tFormat;二是在client上調用API寫入數據。但是這兩種方式都需要頻繁地通過遠程過程調用協議RPC(Remote Procedure Call Protocol)方式與HRegion服務器進行通信,當一次性寫入大量數據時會造成額外的資源開銷。針對海量語義數據的存儲,這兩種方式顯然不是最有效的。
HBase可通過自帶的用戶自定義程序向HBase中加載數據。針對改進后的數據存儲模型,本文在HBase自帶數據加載方法的基礎上,自定義了Bulk Loading數據加載程序。數據加載具體步驟如下:
1) HDFS不適合存放大量小文件,所以要先把RDF數據處理成為與S_PO,P_SO,P_OS,O_SP模型對應的結構。
2) 在Hadoop的分布式文件系統HDFS上為RDF數據創建一個專門的存儲目錄,然后調用Hadoop的Put接口進一步將數據導入到HDFS分布式文件系統的RDF數據存儲目錄下。
3) 在HBase中建立空的S_PO,P_SO,P_OS,O_SP表結構,并指定它們的列族。
4) 執行一個MapReduce任務,并行加載RDF數據到HBase,任務的輸入是存放RDF數據的文件,輸出是HBase文件。
5) 查看HBase中對應的表結構下是否存入了RDF數據。
對Bulk Loading數據加載核心部分的代碼進行描述(向新增的P_SO表加載數據):
Method Map(Text value, Context context)
String[]textStrSplit=text.toString().split(″ ″);
//將謂語作為Row key
String hkey=textStrSplit[1];
String column=textStrSplit[0];
String hvalue=textStrSplit[2];
rowKey=Bytes.toBytes(hkey);
//謂語值存在
while(hkey==ture)
//創建Put對象用于存放Put實例
Put HPut=new Put(rowKey);
byte[ ] cell=Bytes.toBytes(hvalue);
//向Put對象中添加單元數據
HPut.add(Bytes.toBytes(column), cell);
context.write(HKey, HPut);
該數據加載算法主要包括數據分割、加載三元組和寫入數據三部分。基于謂語的數據索引,需要將數據按照P_SO和P_OS模式分別完成加載。同時,對每一謂語值是否為空預先做出判斷,若謂語值不存在,則不將該記錄存入以謂語為索引的存儲表中;反之,直接將數據寫入對應的數據索引表中。S_PO和O_SP存儲表本文不做詳細說明。
3 系統測試與分析
3.1 實驗環境
實驗搭建了具有5個節點的Hadoop集群,每個節點硬件配置如表5所示。存儲結構設計是將RDF數據存儲在HBase集群中,HBase構建在HDFS之上,HRegionServer(域服務器)作為HBase的集群節點維護存儲RDF數據的域(region),RDF數據均衡分布在集群各節點中。實驗采用LUBM測試集進行測試,LUBM[12]是當前使用最廣泛的測試樣例,該測試集可以根據指定的參數生成相應規模的數據集。例如LUMB(10),參數10表示生成具有10個大學的語義數據集,其中指定參數越大數據集規模越大。
表5 硬件配置
3.2 實驗結果分析
實驗采用UBA[13](數據發生器)生成三組不同大小的RDF數據集進行測試,數據集大小如表6所示。

表6 測試數據集
數據加載性能是評價該存儲模型的一個重要指標,本文基于MapReduce編程模型實現了大規模RDF數據的并行加載功能。表7給出了串行加載算法和MapReduce并行加載算法加載三組不同規模RDF數據所需的時間。

表7 數據加載消耗時間
實驗加速比可由式(1)得出:
(1)
式中:T(1)表示串行加載運行時間,T(N)表示并行加載運行時間。
由表7可以看出,對比串行方法,Bulk loading并行數據加載算法在數據規模較小時優勢并不明顯,原因是當數據規模小時Map任務個數也較少,不能有效利用MapReduce的并行機制。隨著數據規模的增大,實驗表明該加載算法能夠高效地完成海量RDF三元組數據的加載操作。
本文數據查詢測試主要目的是驗證謂語索引表P_SO的高效性,設計謂語綁定,主語已知,賓語未知的查詢用例:
SELECT ?Y
WHERE
{
}
將該查詢用例分別在S_PO和P_SO存儲模式上進行測試,三組不同規模RDF數據所需的查詢的響應時間如表8和圖2所示。
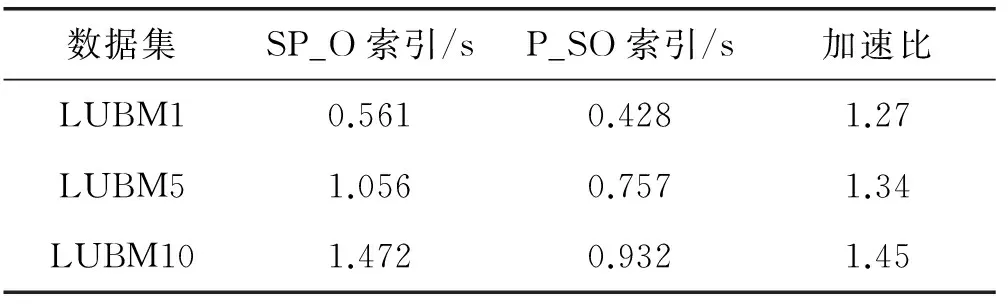
表8 SP?查詢響應時間
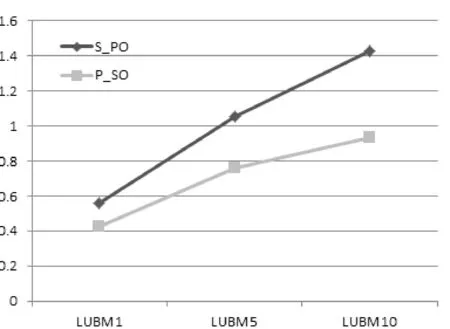
圖2 SP?查詢響應時間
由統計分析得出,基于謂語約束的查詢請求數量約占整個系統查詢總數的90%。改進后整個系統的查詢加速比(表8)可由Amdahl定律得出:
(2)
本實驗Fe=0.9,Fe是執行某個任務的總時間中可被改進部分的時間所占的百分比,Se是改進部分采用改進措施后比沒有采用改進措施前性能提高倍數。
對比優化前的S_PO查詢索引,P_SO在查詢時能夠快速確定Row-Key范圍,原因是數據源本身具有謂語數量級小的特點,根據Row-Key檢索所有包含謂語P的三元組,然后根據主語S進行過濾操作,最終得出查詢結果。隨著數據規模的增長,謂語P確定的Row-Key范圍也逐漸變大,因此查詢時間遞增。同時,MapReduce并行機制進一步提升查詢效率,查詢加速比逐漸增大。
4 結 語
針對海量語義數據的管理問題,本文提出了一種基于分布式數據庫HBase的RDF數據存儲模型。相較于傳統的三元組存儲方法,該模型可以直接根據謂語的索引更加快速地查詢到相應的關聯數據值。在保證查詢性能的同時有效地減少了存儲開銷,為實現大規模語義數據的高效查詢和推理奠定了理論和應用基礎。
本文在RDF數據的查詢處理問題上沒有做針對性的研究,接下來的工作是要對該模型上的查詢算法進行優化,進一步提升數據的查詢效率。
[1] 常亮,劉進,古天龍,等.基于動態描述邏輯的語義Web服務組合[J].計算機學報,2013,36(12):2468-2478.
[2] 杜方,陳躍國,杜小勇.RDF數據查詢處理技術綜述[J].軟件學報,2013(06):1222-1242.
[3] Bizer C,Jentzsch A,Cyganiak R.State of the LOD Cloud[EB/OL].http://lod-cloud.net/.
[4] Kaoudi Z,Manolescu I.RDF in the clouds:a survey[J].Vldb Journal,2015,24(1):67-91.
[5] Harris S,Lamb N,Shadbolt N,et al.4store:The design and implementation of a clustered rdf store[J].Scalable Semantic Web Knowledge Base Systems,2009,4:94-109.
[6] 杜小勇,王琰,呂彬.語義Web數據管理研究進展[J].軟件學報,2009,20(11):2950-2964.
[7] Zhou Q,Hall W,Roure D D.Building a Distributed Infrastructure for Scalable Triple Stores[J].Journal of Computer Science & Technology,2009,24(3):447-462.
[8] Rajapoornima M,Tamilselvan L,Priyadarshini R.Personalized semantic retrieval of information from large scale blog data[C]//IEEE International Conference on Recent Trends in Electronics,Information & Communication Technology.IEEE,2017:1055-1059.
[9] Owens A,Seaborne A,Gibbins N,et al.Clustered TDB:A Clustered Triple store for Jena[C]//Proceedings of 18th Internation Conference on World Wide Web,2009.
[10] Abiri F,Kahani M,Zarinkalam F.An entity based RDF indexing schema using Hadoop and HBase[C]//International Econference on Computer and Knowledge Engineering.IEEE,2014:68-73.
[11] 徐德智,劉揚,Sarfraz Ahmed.基于Hadoop的RDF數據存儲及查詢優化[J].計算機應用研究,2017,34(2):477-480,486.
[12] Guo Y,Pan Z,Heflin J.LUBM:A benchmark for OWL knowledge base systems[J].Web Semantics Science Services & Agents on the World Wide Web,2005,3(2-3):158-182.
[13] Helflin J,Stuckenschmidt H.Editorial:Web-scale semantic information preprocess[J].Web Semantic:Science,Services and Agents on the World Wide Web,2012(10):121-132.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
