一種用戶畫像系統的設計與實現
2018-04-18 11:33:36丁志剛鄭樹泉齊文秀
計算機應用與軟件 2018年3期
關鍵詞:用戶
王 洋 丁志剛 鄭樹泉 齊文秀
1(上海市計算技術研究所 上海 200040) 2(上海產業技術研究院 上海 201206) 3(上海計算機軟件技術開發中心 上海 201112) 4(上海嵌入式系統應用工程技術研究中心 上海 201112)
0 引 言
截至2016年6月,中國網民規模達7.10億[1]。隨著互聯網的蓬勃發展,越來越多的人加入到互聯網用戶的隊伍中來,這為互聯網企業帶來了諸多的機遇,同時,也帶來了諸多的挑戰。這將意味著誰更了解自己用戶的上網習慣、瀏覽偏好等,誰就能夠在激烈的競爭中脫穎而出。
現如今用戶行為日志隨著互聯網的快速發展呈現激增的趨勢,數據規模已經開始由GB向TB乃至PB級別邁進。為了解決數據量過大帶來的種種問題,本文提出了一種基于Hadoop大數據平臺的離線數據處理分析系統。
用戶畫像就是根據用戶的人口屬性、偏好習慣和行為信息而抽象出來的標簽化畫像[2]。目前,國內淘寶和京東都推出了自己的用戶畫像功能,通過對用戶的個體消費能力、消費內容等長時間多頻次的建模,為每個客戶構建一個精準的消費畫像[2]。國外對于用戶畫像研究,基于復雜網絡理論對用戶行為探索始于2005年,Barabási在Nature發表的一篇論文[3],該文通過對用戶普通郵件和電子郵件的發送和回復時間間隔統計特性研究,發現相鄰兩個時間間隔的分布服從反比成幕率的長尾效應。此外,Barabási在他最近一本名為《Bursts》的書中就大膽地提出,93%的人類活動是可預測的[4]。
本文是用戶畫像在大數據環境下的一種實踐。傳統的分析方式基于少量精確的結構化數據,但是,面對數據量大的情況,會出現速度慢甚至程序崩潰的風險。由此,引入基于Hadoop分布式集群的大數據處理平臺,在數據量較大的情況下提供更可靠的分析與處理服務。
1 需求分析與相關技術
1.1 需求分析
用戶畫像系統的建立需要依賴于具體的應用場景以及所擁有的數據。本系統采用了某公司推出的一款互聯網WiFi產品中采集的用戶行為日志以及其他相關的用戶信息作為源數據。
該日志中包含了用戶瀏覽部分核心頁面的歷史記錄,包括:用戶MAC地址、訪問時間、接入設備MAC地址、訪問頁面類型、頁面URL、客戶端類型等。由于用戶行為日志中提取出的電影和電視數據不足以支撐后續的分析與處理任務,需要通過添加輔助數據采集模塊,采集相關的電影和電視節目表單數據作為用戶行為日志的補充。
依據用戶行為日志中現有的數據信息,補充日志中殘缺的部分,所構成的完整數據集合提交給大數據處理分析平臺進行處理分析。然后通過可視化模塊進行展示達到用戶畫像助力企業為用戶進行推薦的目的。
1.2 相關技術
網絡爬蟲是一種自動提取網頁的程序,它為搜索引擎從萬維網上下載網頁,是搜索引擎的重要組成[5]。數據爬取模塊通過網絡爬蟲獲取網絡電視和電影數據,為源數據作補充。
大數據處理平臺主要使用了Hadoop以及Hive等框架。Hadoop是Apache軟件基金會下的一個開源分布式計算平臺。HDFS作為Hadoop生態系統中主要存儲系統,在實時性要求不高的情況下,已經成為很多公司首選的存儲方案[6]。
Hive是構建在Hadoop上的數據倉庫框架。將結構化的文件映射為一張數據庫表,并提供查詢功能,可以SQL語句轉化為MapReduce任務運行。
Sqoop是一個用來將Hadoop和關系型數據庫中的數據相互轉移的工具,可以將一個關系型的數據庫中的數據轉移到Hadoop的HDFS中,也可以將HDFS中的數據轉移到數據庫中。
可視化模塊主要用了Spring、SpringMVC、Mybatis作為Web端開發框架。
Spring是一款開源框架,為了解決企業應用開發的復雜而創建[7]。Spring框架的IOC容器設計降低了業務對象替換的復雜性,對組件之間解耦起到了重要作用。SpringMVC框架提供了構建Web應用程序的全功能MVC模塊,分離了控制器、模型對象、分派器以及處理程序對象的角色。MyBatis是支持定制化SQL、存儲過程和高級映射的優秀的持久層框架。
2 用戶畫像系統總體設計
用戶畫像系統的整體架構分為四層:數據源層、數據采集層、基于Hadoop的大數據分析平臺層、數據可視化層。基本流程為:數據采集層采集系統所需數據并將數據存入數據源層;大數據平臺層由數據源層導入數據并且對數據進行分析與處理,將處理完成的結果導出到數據源層;數據可視化層從數據源層讀取數據并將數據呈現在Web端頁面供管理者參考。用戶畫像系統架構如圖1所示。

圖1 用戶畫像系統架構圖
2.1 功能模塊劃分
用戶畫像系統分為三大模塊:數據采集模塊、基于Hadoop集群的大數據分析平臺、數據可視化模塊。宏觀上講,數據采集模塊主要用于補充用戶行為日志中缺乏的電影數據、電視節目的相關數據以及源數據對接,使得數據集更加完備,為之后的分析與處理獲得全面且合理的數據集作準備。基于Hadoop集群的大數據分析平臺對用戶行為日志經過清洗、規范化、分析與處理等步驟為用戶標識相應權重的標簽,實現為用戶“畫像”的目的。數據可視化模塊將大數據平臺中分析完成的結果進行展示,直觀地看到用戶的人畫像,為決策起到輔助作用。
2.2 數據采集模塊
數據采集模塊包括三個部分:電影數據爬取模塊、電視數據爬取模塊和源數據對接模塊。其中,電視數據爬取模塊和源數據對接模塊主要采用調用第三方API接口獲取數據的方式,定時抓取數據。
電影數據爬蟲子模塊通過爬取豆瓣電影網站中的相關數據來獲取電影信息,主要包括電影名稱、電影評分、電影導演、電影演員等。電影數據爬蟲子模塊爬取流程如圖2所示。

圖2 電影數據爬蟲子模塊爬取流程圖
電影數據爬蟲子模塊流程如下:
1) 將初始待爬取URL存入數據庫。并初始化其狀態為未爬取狀態。
2) 從數據庫中獲取未爬取狀態的且id最小的URL,使用基于HttpClient實現的Http訪問工具包對該URL進行訪問,獲取到該URL的HTML頁面數據。
3) 對獲取到的HTML頁面利用HTML解析器Jsoup進行處理,分析并獲取頁面中的電影名稱、演員表、導演表以及電影評分等,將解析成功的數據存入數據庫中。
4) 獲取該頁面中固定模塊中存在的URL并判斷其是否電影相關的URL,將符合要求的存入數據庫中等待爬取。
2.3 數據可視化模塊
數據可視化模塊中,采用基于MVC模式的三層架構。使用Spring、MyBatis和SpringMVC框架作為支撐,Echarts商業級圖標框架進行展示。
整個模塊在展示用戶個人畫像的基礎上,以接入的設備作為區域,展示區域內用戶整體的統計分析量。數據可視化部分效果如圖3所示。
(a) 用戶標簽圖

(b) 區域用戶分布圖
(c) 區域用戶訪問頻率

(d) 區域用戶訪問時段圖圖3 數據可視化模塊效果圖
3 Hadoop大數據分析平臺
大數據指的是無法在規定的時間內用現有的常規軟件工具對其內容進行抓取、管理和處理的數據集合。
3.1 集群拓撲結構
集群拓撲結構如圖4所示。
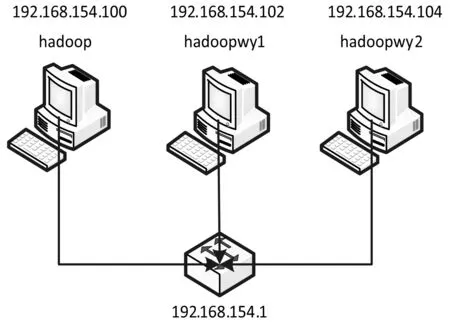
圖4 Hadoop集群拓撲結構
Hadoop節點結合ZooKeeper服務組成高可用Hadoop集群。取名為Hadoop的節點擔任集群中NameNode角色。Hadoopwy1作為NameNode節點的候選節點處于StandBy狀態且擔任集群中負責任務分配和資源管理的ResourceManager角色。Hadoopwy2主要作用在于存儲HDFS數據、處理MapReduce任務等。
3.2 大數據分析平臺架構
大數據分析平臺首先由Hive提取部分用戶日志進行清洗與數據的整合交換,生成用于用戶行為分析的建模數據,利用算法庫算法對建模數據進行分析,生成用于用戶行為分析的模型。然后,對所有用戶行為日志進行數據清洗與數據的整合變換,得到預處理后的業務數據集,將得到的模型應用于該數據集得到最終的應用結果。最后,通過應用結果進行評測的方式評價模型優劣并對模型進行優化。
基于Hadoop集群的大數據分析平臺架構如圖5所示。
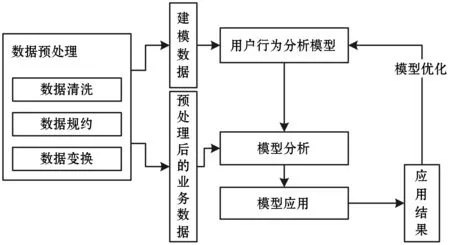
圖5 基于Hadoop集群的大數據分析平臺架構圖
3.3 用戶畫像標簽體系
根據用戶的相關數據將標簽體系進行了劃分,總體劃分為兩大類,基礎信息標簽、動態信息標簽。基礎信息標簽是根據用戶的注冊信息中填寫的個人信息得到;而動態信息標簽結合聚類等數據挖掘算法對用戶行為進行分析挖掘,達到利用用戶行為數據進行用戶分類的目的。
平臺部分標簽體系如圖6所示。其中,基礎信息標簽主要是從用戶地址、用戶的手機使用情況兩方面進行分析。動態信息標簽以用戶價值標簽和用戶電影傾向標簽為例進行分析與說明。

圖6 用戶畫像標簽體系圖
3.4 用戶行為分析模型
基礎信息標簽主要采用統計的方式,按照一定的規則為用戶標記對應的標簽。
動態信息標簽中,部分標簽采用統計方法,另一部分標簽采用數據挖掘算法對數據進行分析的方法,經過抽取數據分析所需要的數據,通過聚類等算法分析后區分各用戶。
3.4.1基礎信息標簽模型
地址標簽是按照用戶注冊時填寫的用戶地址直接為用戶標記該標簽。手機標簽模型是根據用戶使用手機類型與數量進行標記。如表1所示。

表1 用戶手機標簽模型
3.4.2動態標簽模型及K-means改進算法
1) 用戶價值模型該模型將用戶使用次數(UT)、初次使用到最近一次使用天數(DC)、最近一次使用距今天數(DF)、用戶在線總時長(OT)四個值作為用戶價值模型的參考指標,使用K-means聚類算法對數據進行聚類,通過對用戶的行為數據聚類實現用戶分類的目的。
K-means算法是基于距離的聚類算法,在最小化誤差函數的基礎上將數據劃分為預定的類數K,采用距離作為相似性的評價指標,即認為兩個對象的距離越近,其相似度就越大。K-means算法[8]對于給定樣本集D={x1,x2,…,xm}聚類所得簇劃分C={C1,C2,…,Ck}最小化其平方誤差:
(1)

但是K-means存在著依賴初始化中心的缺陷,針對該問題對K-means進行改進。本文采用各個節點之間投票的方式選出第一個中心點,得到票數最多者勝出。這里假設每個節點為其余每個節點都準備一票,但是實際的投票值為除以兩點之間的距離而得到的值。越是聚集的簇中心其所得票數相對較多,由此選出一個節點,然后求與已經得到的節點相距最遠的節點,依次求出需要的節點。投票的值可以表示為:
(2)
式中:d是歐式空間中連個點之間的距離且x≠y。
初次聚類得到類簇以后,對每個類簇再分別隨機選取其中的一個節點作為新的中心點。然后再一次進行聚類,循環多次選取方差較小者為最終聚類中心,從而降低K-means聚類時因為初始節點的選取而造成的影響。
實驗表明,改進以后的K-means算法更加穩定,準確率更高。
通過hive進行統計與合并構成上述用戶價值模型的數據集,運用PCA將數據降為2維數據如圖7所示。

圖7 用戶價值模型數據分布圖
本文采用了SSE(誤差平方和)的方式對聚類效果進行度量。隨著聚類簇數K值的增大,總SSE值將逐漸減小。當K的值小于其實際簇數的時候,隨著K值的增大,總SSE迅速下降。當K值大于實際的簇數時,隨著K的增大,總SSE的值將呈現緩慢下降的趨勢[9]。本文從多次聚類結果中選擇總SSE遞減趨勢明顯變緩的K值作為聚類簇數。多次聚類后SSE值遞減趨勢如圖8所示。
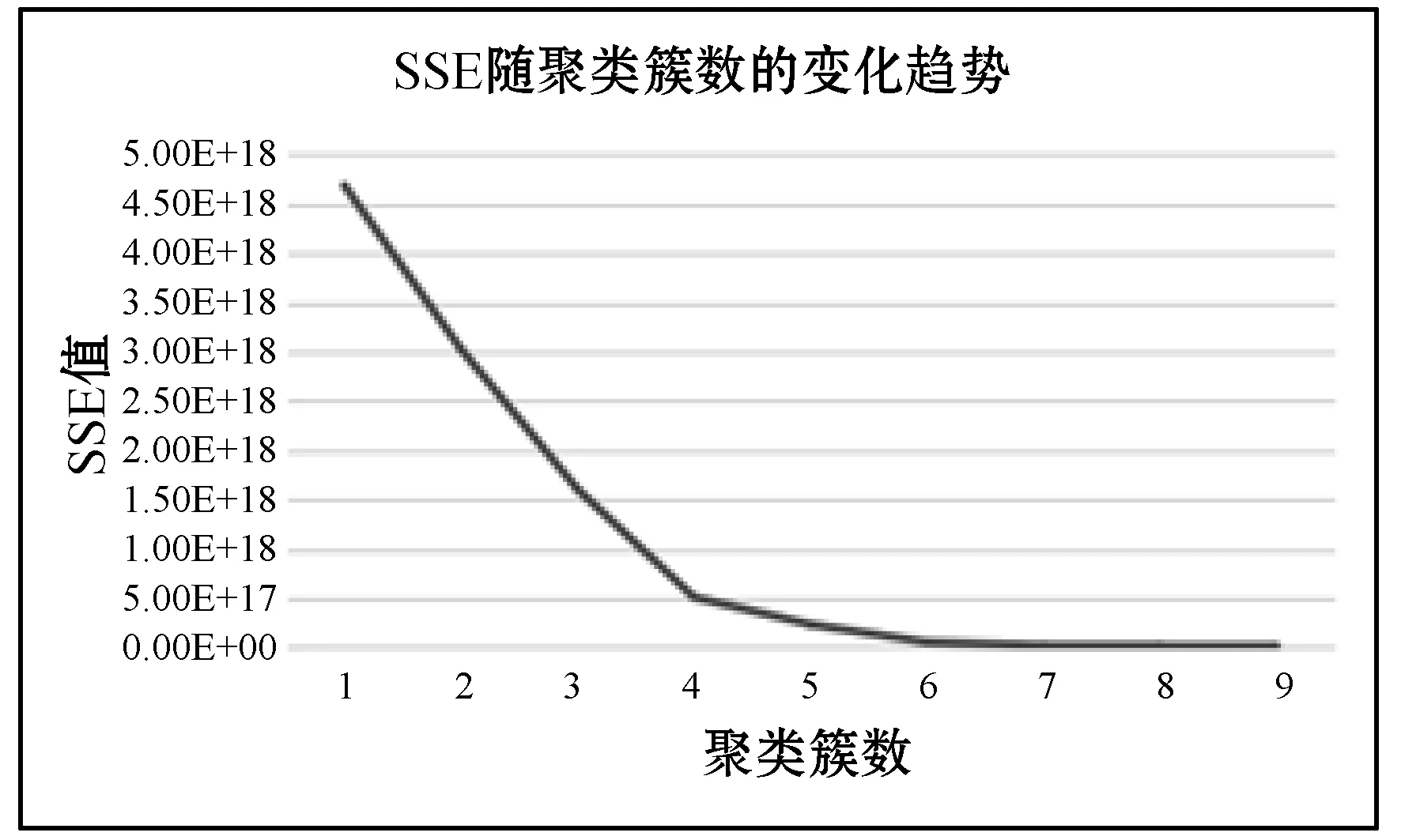
圖8 誤差平方和SSE遞減趨勢圖
從圖8中可以看出,當K=4的時候誤差平方和的值已經遞減十分緩慢,使用手肘法并結合業務需求以及圖7中展示的PCA降維圖確定K值為4,即本文中將用戶行為數據劃分為4個簇。
聚類分群后的結果如表2所示。根據表中分類結果可以看出,類1用戶使用次數最少,初次使用到最近一次使用天數最少,最近一次使用至今天數最大,在線時長最少,基于這些特征將類1標記為一般與低價值用戶。類2用戶使用次數較多,初次使用至最近一次使用天數較長,最近一次使用至今天數較多,在線時長較多,基于這些特征將類2標記為重要發展客戶。類3用戶使用次數最多,初次使用至最近一次使用天數最大,最近一次使用至今天數最小,在線時長最長,基于這些特征可以將類3標記為重要保持客戶。類4用戶使用次數稍多,初次使用至最近一次使用天數稍多,最近一次使用至今天數稍長,在線時長稍長,基于這些特征可以將類4標記為重要挽留客戶。
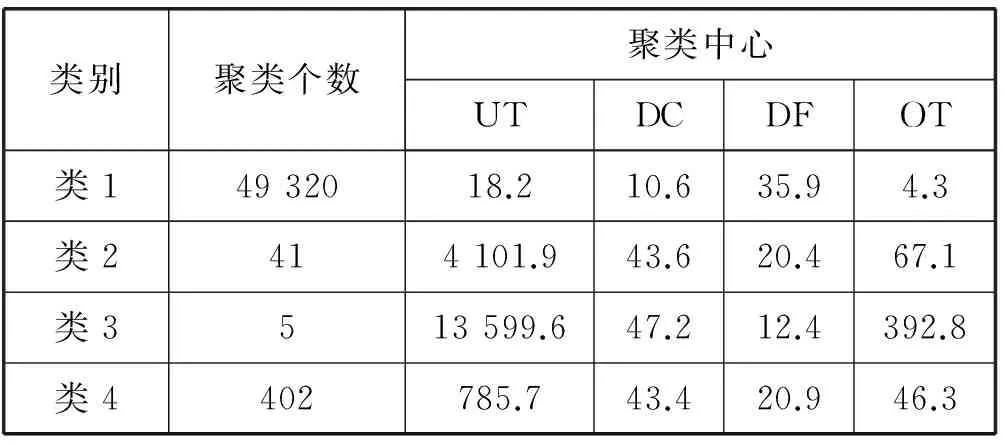
表2 用戶行為聚類結果
2) 用戶驅動力標簽用戶驅動力標簽是面向影視數據而言的,主要用于說明用戶喜歡看電影對評分和星級的傾向。運用K-means算法對以電影評分、電影星級為數據集的電影數據進行聚類,方法與用戶價值模型中類似。誤差平方和的遞減趨勢如圖9所示。
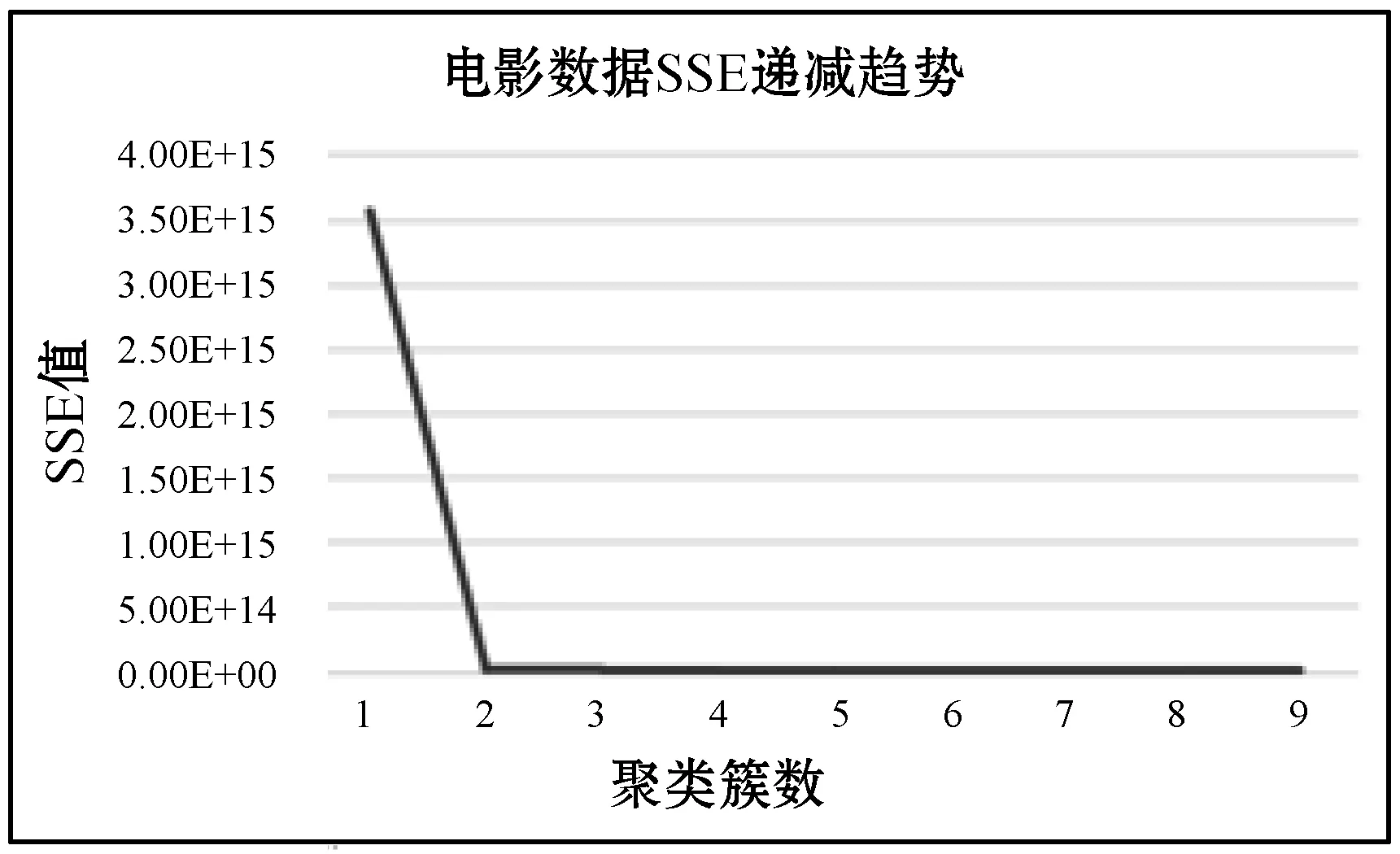
圖9 電影數據SSE遞減趨勢圖
通過該圖選取聚類簇數為2,對電影數據進行聚類分析,聚類結果如表3所示。
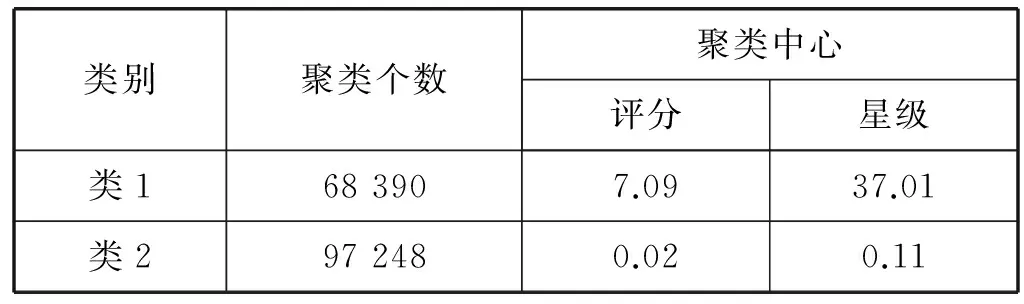
表3 電影數據聚類結果表
根據表3中的聚類結果進行分析,類1中電影評分較高,星級數目較多,基于這些特征將類1的電影定位為高分熱評電影。類2中電影評分較低,星級數目較少,根據該特征將其定位為低分少評電影。
生成模型時通過計算用戶所觀看過的電影的評分與星級數目的平均值,與聚類質心計算距離,選取距離較近的質心所代表的類作為該用戶的實際分類,將電影分類各自代表的標簽賦予用戶,表征用戶的電影傾向標簽。
4 系統測試
采用UCI機器學習庫上面提供的開放數據集Wine、Iris以及本系統經過人工標記后的部分數據作為測試數據,驗證文中提出的對K-means算法的改進。
Wine數據使用K-means算法采用隨機初始化中心時測試數據如表4所示。
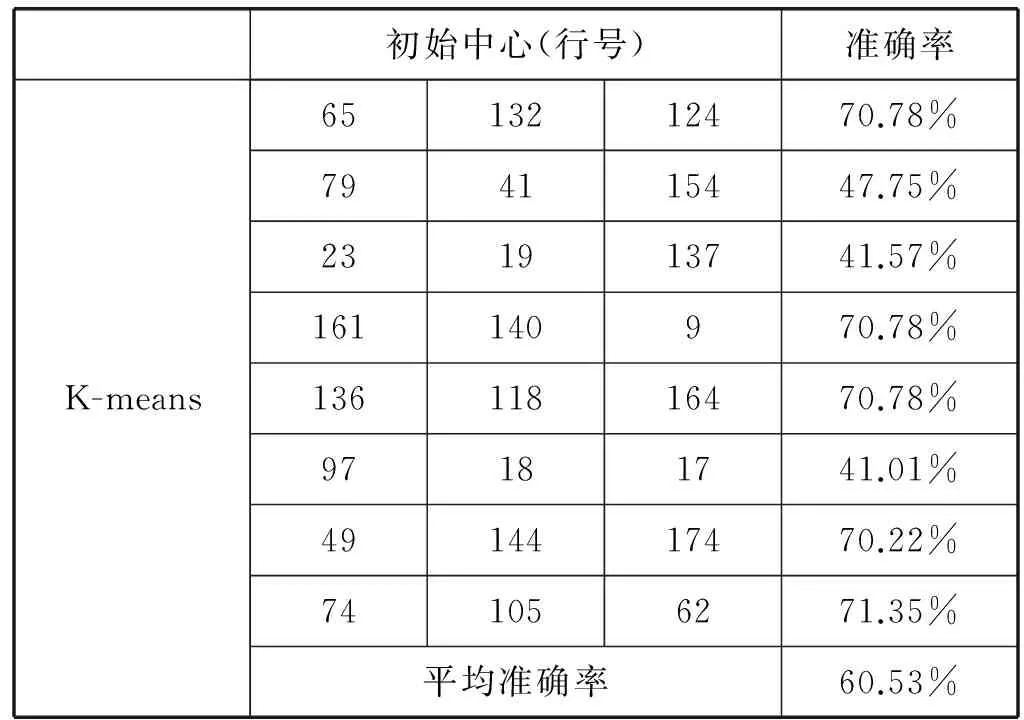
表4 K-means算法對Wine測試數據表
采用本文中提出的改進方案,多次測試結果趨于穩定,這不再一一列出。其初始化中心為:(3, 13.73, 4.36, 2.26, 22.5, 88, 1.28, 0.47, 0.52, 1.15, 6.62, 0.78, 1.75, 520)、(1, 14.19, 1.59, 2.48, 16.5, 108, 3.3, 3.93, 0.32, 1.86, 8.7, 1.23, 2.82, 1 680)、(2, 12, 0.92, 2, 19, 86, 2.42, 2.26, 0.3, 1.43, 2.5, 1.38, 3.12, 278)。其中,第一列分類號不包含在計算之內。通過該聚類中心可以看出,本文提出改進起到了較好的初始中心的選擇效果。針對該方案同樣進行多次測試結果基本穩定,準確率的平均值為70.78%。
Iris數據集使用K-means算法采用隨機初始化中心點的測試數據如表5所示。

表5 K-means算法對Iris測試數據表
運用本文提出的改進算法,多次測試結果趨于穩定,在此不再一一列出。初始中心點為:(1, 5.1, 3.5, 1.4, 0.2)、(3.0, 7.7, 2.6, 6.9, 2.3)、(1.0, 4.3, 3, 1.1, 0.1)。其中,第一列分類號不包含在計算之內。最終生成的聚類中心為:(5.01, 3.42, 1.46, 0.24)、(6.87, 3.09, 5.75, 2.09)、(5.9, 2.75, 4.41, 1.43)。對比本文改進算法確定的第一個初始中心點和最終生成的聚類中心點可以看出二者相差很小。多次測試后的準確率平均值為:88.67%。
針對系統用戶日志的標記數據進行聚類并統計其準確率同樣得到了較高的提升,其中運用K-means隨機確定初始中心的方式平均準確率為:64.50%,運用本文提出的改的K-means算法平均正確率為83.43%。可以看出準確率在采用改進后的算法后有了較大的提升。
此外,為了驗證本文中提出的基于Hadoop集群的大數據處理平臺集群環境相對于單機環境效率的提升。在同等大小的數據集用戶行為日志的基礎上針對不同MAC地址各自操作次數的統計功能編寫了在單機環境下和Hadoop集群環境下不同的實現方式,并測試了五組不同數據集的情況下的運行時間。
由實驗數據得知,單機處理情況下,分別處理250 MB、500 MB、1 GB、2 GB、4 GB數據的時間隨著數據量的突增呈指數級增長的趨勢,用時分別為:5.45 s、7.5 s、13.94 s、42.18 s、158.75 s。而使用Hadoop分布式集群環境處理任務的情況下,分別用時為17.01 s、20.99 s、21.30 s、22.42 s、30.04 s。單機與集群環境下運行時間對比如圖10所示。從圖10中可以看出單機情況下隨著數據量的劇增處理時間也隨之劇增,在1 GB范圍內的數據量表現較好,但是當數據量繼續增長,執行時間隨之集合呈現指數增長的趨勢。而集群環境下,從250 MB數據劇增到4 GB的數據量的過程中,運行時間變化不大,變化趨勢較為平穩。可見,基于Hadoop的分布式集群環境在大數據處理方面的優勢很顯著,而且隨著數據量的不斷增大其優勢將越明顯。
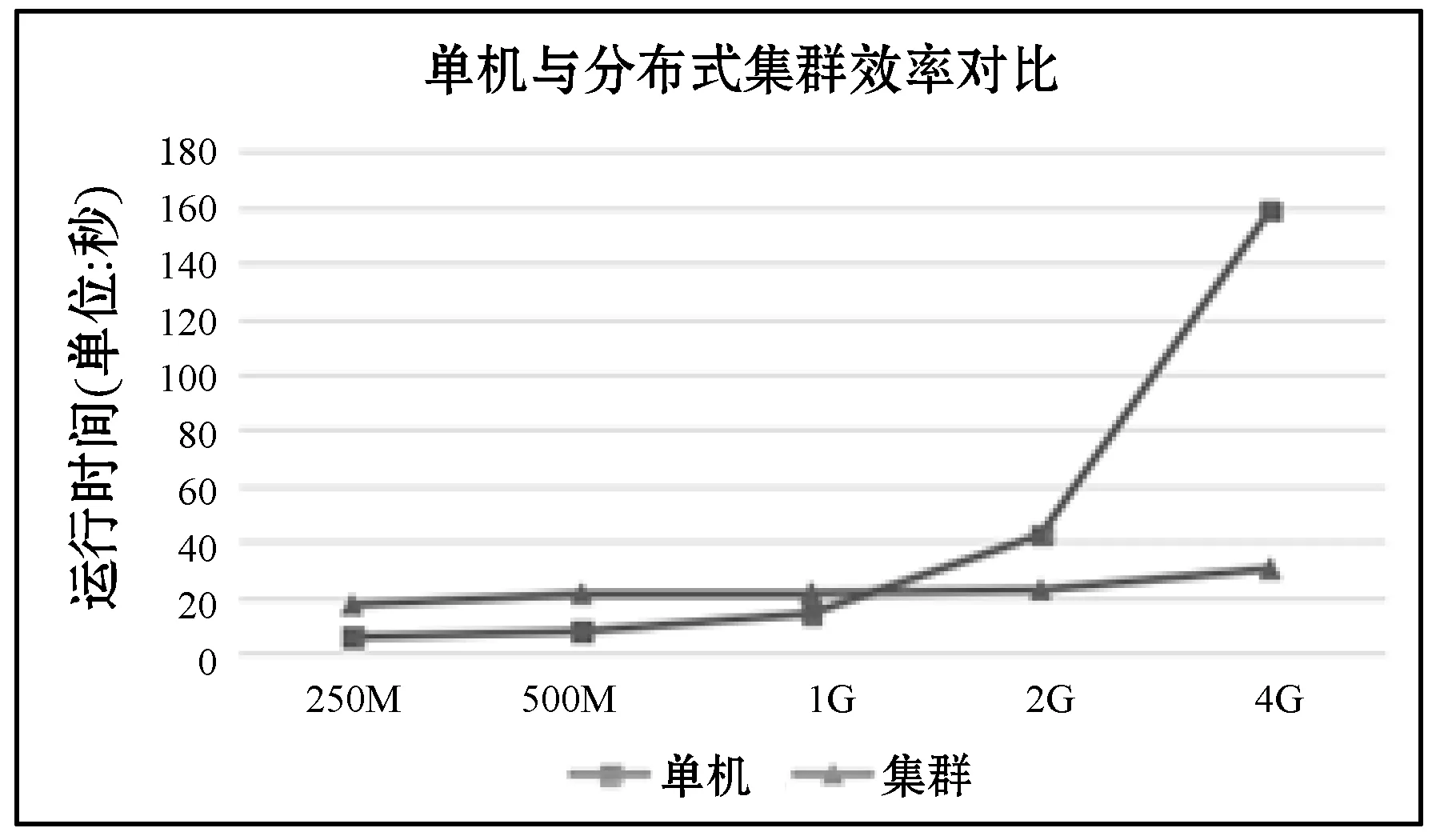
圖10 單機與集群執行時間對比圖
5 結 語
本文針對用戶喜好與互聯網企業產品之間的矛盾,設計并實現了基于Hadoop集群的用戶畫像系統。首先,通過接口調用、網絡爬蟲等數據采集方式,獲取到完善的數據集。然后,用戶的行為日志經過統計分析和數據挖掘等方式的分析與處理,把用戶抽象成標簽的集合,從而達到為用戶“畫像”的目的。最后,可視化系統將用戶畫像系統的分析結果展示出來,為企業決策人員提供決策依據以及為后續向用戶進行精準推送鋪平道路。此外,本文對K-means算法依賴初始中心的缺陷進行了改進,改進后的算法更趨近于最終聚類中心,且準確率得到了極大的提升。
[1] 中國互聯網絡信息中心(CNNIC).第38次中國互聯網絡發展狀況統計報告[R].2016:1-2.
[2] 曾鴻,吳蘇倪.基于微博的大數據用戶畫像與精準營銷[J].現代經濟信息,2016(16):306-308.
[3] Barabási A. The origin of bursts and heavy tails in human dynamics[J]. Nature, 2005, 435(7039):207.
[4] Barabási Albert-Lászlò. Bursts:The Hidden Patterns Behind Everything We Do[M].Dutton Adult,2010.
[5] 周德懋,李舟軍.高性能網絡爬蟲:研究綜述[J].計算機科學,2009,36(8):26-29.
[6] 馬建紅,霍振奇.基于HDFS的創新知識云平臺存儲架構的研究與設計[J].計算機應用與軟件,2016,33(3):63-65.
[7] 李洋.SSM框架在Web應用開發中的設計與實現[J].計算機技術與發展,2016,26(12):190-194.
[8] 潘巍,周曉英,吳立鋒,等.基于半監督K-Means的屬性加權聚類算法[J].計算機應用與軟件,2017,34(3):190-191.
[9] 成衛青,盧艷紅.一種基于最大最小距離和SSE的自適應聚類算法[J].南京郵電大學學報(自然科學版),2015,35(2):103-107.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
