面向數據中心網絡的鏈路故障實時檢測即服務
2018-04-16 11:59:25王軍曉李克秋周曉波
計算機研究與發展 2018年4期
王軍曉 齊 恒 李克秋 周曉波
1(大連理工大學計算機科學與技術學院 遼寧大連 116024) 2 (天津大學計算機科學與技術學院 天津 300072) (wangjunxiao@mail.dlut.edu.cn)
鏈路故障檢測作為一種十分重要的網絡性能保障手段,目前已被廣泛應用于大規模網絡環境中,例如數據中心網絡等[1].鏈路故障檢測可以為許多大規模在線業務例如搜索引擎、社交網絡、文件系統等提供網絡連通性方面的保障.隨著網絡規模的增長、鏈路數量的上升,如何快速地、實時地完成探測成為鏈路故障檢測中的一個重要挑戰[2].
傳統被動式的檢測辦法依賴于簡單網絡管理協議(simple network management protocol, SNMP)查詢網絡設備例如路由器或交換機中的計數器,或通過命令行界面(command line interface, CLI)登錄到網絡設備上查看運行信息.這些方法在網絡設備不發生故障的情況下可以檢測出一些問題,例如設備端口故障.但是一旦與網絡設備間的連接發生中斷,這些檢測方法將無法正常工作.此外,這些方法需要對網絡設備進行配置,因此很難適應網絡設備的升級、服務的遷移、網絡規模的擴展.
網絡功能虛擬化(network function virtualiza-tion, NFV)[3]概念的出現為鏈路故障檢測的實現方法帶來了更多的可能性.網絡功能虛擬化的思想由眾多運營商例如AT&T、中國移動等提出,目前已經被逐漸應用于簡化網絡服務的部署難度方面以及加快網絡服務的升級速度方面.從2012年起,歐洲電信標準化協會ETSI發布了一系列關于網絡功能虛擬化的白皮書,介紹了其面臨的機遇與挑戰、標準架構以及演進方向.網絡功能虛擬化的思想是利用標準IT虛擬化技術,將傳統網絡服務轉化為可運行于通用x86平臺服務器之上的軟件服務.這些基于軟件驅動的網絡服務可以實現按需彈性供給,而不需要對原有設備進行變動.網絡管理者可以靈活地創建、刪除或升級特定的網絡服務,大大降低了網絡服務的部署和維護成本.除此之外,網絡服務的部署方式從傳統的基于設備的集中式部署模式轉化為支持分布式的部署模式,部署于多個服務器上的虛擬網絡服務可以聯合提供一種復雜的網絡功能.這種分布式的部署模式有利于服務實例間的負載均衡和故障切換.
基于網絡功能虛擬化,一些主動式的檢測辦法出現.Pingmesh[4]通過發送基于端到端的探針實現了虛擬的鏈路故障檢測功能.由于這些探針是由運行于服務器中的軟件服務進行管理,使得該方法不涉及網絡設備,因此不需要對網絡設備進行配置,也不需要保持與網絡設備之間的連接,可以更好地體現出對場景的適應性,從而檢測出更多情況下的鏈路故障.然而,Pingmesh在網絡中每對服務器之間維護一個探針.當網絡規模擴展時,需要維護的探針數量將以指數級增長,導致每次探測的用時過長,同時產生過多的帶寬負載,難以實現實時的、快速的探測.
我們發現導致以上問題的根本原因是缺乏對探測路徑的選擇.在如圖1所示場景,我們可以借助一些其他技術獲取到網絡中服務器間的路徑信息,例如借助軟件定義網絡(SDN)技術[5],從管理底層網絡的SDN控制器集群處獲取可用路徑.但我們不依賴控制器集群對這些可用路徑進行鏈路故障檢測(SDN控制器有時檢測到的故障是控制器與轉發設備之間的控制信道連接故障而不是真正的數據平面故障).如果我們可以僅用網絡中的一部分路徑而不是全部路徑作為鏈路故障檢測時的探測路徑并發送端到端探針,那么就有可能降低維護探針的代價,減少每次探測的用時,降低探測流對正常工作負載流的影響,從而實現一種新型的虛擬化網絡功能,以支持面向大規模數據中心網絡的鏈路故障實時檢測即服務.
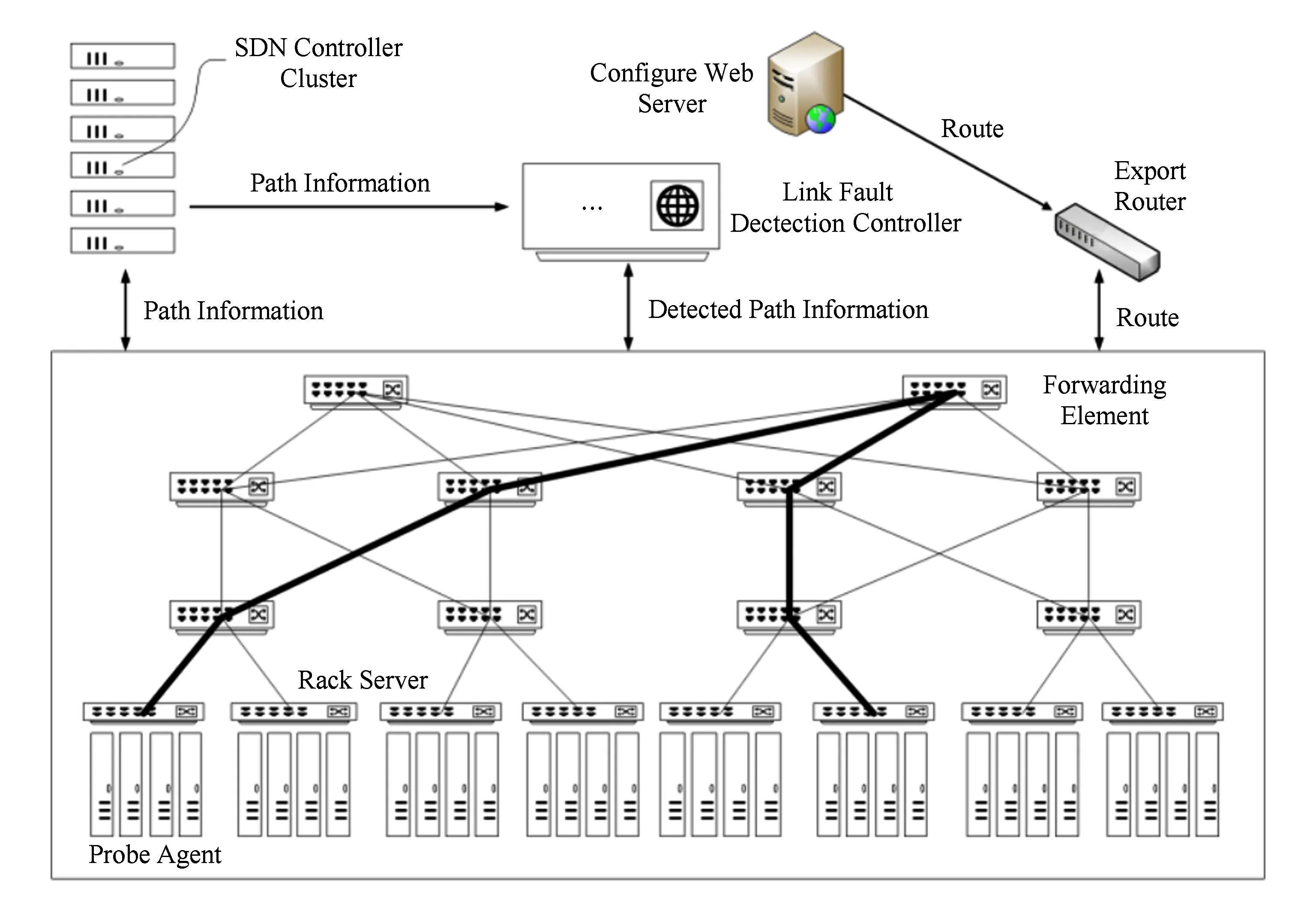
Fig. 1 The architecture of virtualized link fault detection function圖1 虛擬化鏈路故障檢測功能架構
因此,我們提出一種新型的主動式的、基于網絡功能虛擬化的鏈路故障檢測架構,如圖1所示.該架構主要由3部分構成:SDN控制器集群[6]、鏈路故障檢測控制器和探針代理.其中SDN控制器集群與底層網絡中的轉發設備建立連接,從底層網絡獲取轉發路徑信息與鏈路拓撲信息.當SDN控制器集群改變拓撲結構時,例如SDN控制器集群下發命令將轉發設備的某些端口禁用等,SDN控制器集群可以及時將這些拓撲的變化推送給鏈路故障檢測控制器.故障檢測控制器作為虛擬化鏈路故障檢測功能的大腦,從SDN控制器集群獲取最新的轉發路徑信息,執行探測路徑選擇算法,從所有底層轉發路徑中選擇一部分路徑作為探測路徑,并建立探測路徑與探針代理之間的映射.探針代理被部署在底層網絡的服務器中,并與故障檢測控制器保持連接.其中,被探測路徑映射到的探針代理與故障檢測控制器間的連接被激活.這些連接被激活的探針代理可以從故障檢測控制器處接收探針地址,并以自身的網絡地址為源地址,以探針地址為目的地址構建并發送網絡探針.當某個探針代理收到其他探針代理返回的對于自己探針的回復時,該探針代理將構建鏈路正常的消息發送給故障檢測控制器,否則構建發現故障的消息發送給故障檢測控制器.
本文的主要貢獻有4個方面:
1) 提出了一種在已知底層轉發路徑的前提下,僅基于端到端測量即可實現鏈路故障檢測的鏈路故障實時檢測即服務架構;
2) 采用了基于貪婪策略的探測矩陣近似優化算法,可以有效減少探測路徑數量,從而使實時探測成為可能;
3) 在減少探測路徑數量的基礎上,我們還針對探測路徑的質量進行分析,并結合了2種可反映探測路徑質量的指標,實現高質量探測路徑的選擇.
4) 基于仿真的實驗結果表明,我們提出的實時探測方法與之前工作中的方法相比,在單次探測用時、網絡帶寬占用以及端點負載方面具有明顯優勢,且優化探測矩陣所帶來的開銷是可容忍的.
1 相關工作
鏈路故障的快速檢測是大規模網絡系統中的一個被廣泛關注的問題.針對這個問題,近年來許多網絡監控系統被提出,例如Pingmesh[4],它將整個底層網絡看作是一個黑盒系統,然后考慮如何在網絡邊緣的服務器之間構建端到端的探測路徑.這種方式雖然在理論上可以測量出任何故障場景下,網絡邊緣端到端的鏈路故障,無論這些鏈路故障是基于軟件層面的、操作系統內核層面的、網卡層面的、轉發設備芯片層面的、安全層面的或是線纜層面的.但是這種檢測方法在網絡規模大幅度擴展的情況下,相應的探測路徑會成指數級增長.這樣會導致單次探測的用時無法被控制在一定范圍內,大量的探測路徑報文傳輸和端到端探針維護工作會給底層網絡的帶寬以及邊緣服務器處理能力帶來顯著的壓力,并且這種常駐性負載在服務高峰時可能導致業務應用相關的工作負載和傳輸受到嚴重影響.
Duffield最先提出了一種名為布爾網絡診斷的技術[7].隨后在這項技術的基礎上出現了許多其他工作,例如Cunha等人的工作[8]、Netdiagnoser[9],Nguyen等人的工作[10-11]、PlanetSeer[12]還有Zhao等人的工作[13].這些工作基于的假設都是探測路徑是不變且不可控的.基于該假設,導致這些工作很難實現覆蓋整個底層網絡的鏈路故障檢測.NetSonar[14]則考慮探測路徑是變化的,即改變探針代理的部署從而改變探測路徑,這樣就可以實現對整個底層網絡的鏈路故障檢測,但由于該方法考慮特殊的骨干網應用場景,導致該方法的擴展性較差.
與基于端到端探針實現的探測方法不同,Sharma等人利用網絡編碼的方式實現探測[15],類似的工作還有Yao等人[16]、Kandula等人[17]以及Herodotou等人[18]的網絡診斷工作.其中,有些工作借助轉發設備的日志信息實現探測,還有一些工作借助多播技術實現探測.在網絡監控方面,Pivot Tracing[19]考慮以分布式的方式從底層網絡中收集數據并進行分析從而找到造成鏈路故障的根本原因.LossRadar[20]提出一種基于轉發設備實現的監控手段,該方法需要可編程設備支持.文獻[21]提出一種基于OpenFlow協議的鏈路故障檢測方案,與本文方法相比,其檢測到的故障有可能來自控制器與轉發設備之間的控制信道連接故障而不是真正的數據平面故障.
綜合來看,現有相關工作中缺乏對大規模網絡場景下實時探測的關注.這一研究現狀驅動我們去設計一種能夠實時快速檢測故障鏈路的方法.
2 最少探測路徑數量問題
本節主要介紹如何用矩陣的方式去定義一個最少探測路徑數量問題,并說明該問題的解決思想.
2.1 基于轉發設備故障的探測矩陣
我們將任意底層網絡G定義為
G=(P,N),
(1)
其中,P是網絡G中所有轉發路徑的集合,N是G中所有轉發設備的集合.我們將轉發路徑與轉發設備之間的關系矩陣R定義為
(2)
其中,當轉發設備位于轉發路徑之上時,關系矩陣R中對應位置的值為1,否則值為0.關系矩陣R可以看成由多個行向量構成的集合,其中每個行向量對應一條轉發路徑.探測矩陣是由行向量所構成的矩陣,其中探測路徑由轉發路徑構成.根據探測矩陣可以確定探針依次經過哪些轉發設備.
我們假設某一底層網絡G的拓撲如圖2所示.根據探測矩陣的定義,可以寫出G的含有2條探測路徑的探測矩陣D為

(3)
這2條探測路徑分別依次經過N1,N2,N5三個轉發設備以及N1,N3,N6三個轉發設備.假設我們分別在這2條探測路徑的源頭發送探針,一段時間后如果我們能收到探測路徑另一側回復的探針,就說明這條探測路徑上的轉發設備及其鏈路是正常的,否則就說明這條探測路徑上發生了鏈路故障.如果N2對應的轉發設備發生了單點故障,那么第1條路徑上的探測結果應為故障,第2條路徑結果應為正常.同理,如果N5對應的轉發設備發生了單點故障,2條路徑上的探測結果也是相同的.通過觀察可以發現,造成這2種情況下探測結果相同的根本原因是N2和N5對應的轉發設備在探測矩陣中的列向量是完全相同的.
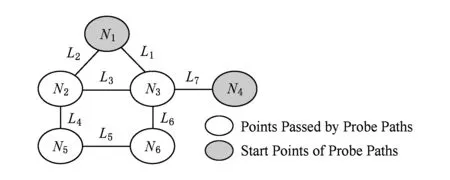
Fig. 2 The example network圖2 示意網絡圖
引理1. 如果某個轉發設備在探測矩陣中的列向量與其他轉發設備的列向量都不相同,那么當該轉發設備發生單點故障時,相應的鏈路故障可被探針檢測到.
根據引理1可以發現,N1對應的轉發設備在探測矩陣中的列向量與其他轉發設備的列向量都不相同,因此當N1對應的轉發設備發生單點故障時,相應的鏈路故障可被探針檢測到.雖然N4對應的轉發設備在探測矩陣中的列向量也與其他轉發設備的列向量都不相同,但由于沒有探測路徑經過該轉發設備,因此也無法根據探測結果推斷其是否發生故障.
如果我們將列向量相同的轉發設備歸為一組,那么可以認為上面的探測矩陣將轉發設備分成了4組,分別是(N1),(N2,N5),(N3,N6)以及(N4,N7),其中N7對應的轉發設備是我們虛構的轉發設備,用來代指探測路徑不可達的轉發設備.
引理2. 如果探測矩陣中的每個列向量都不相同,那么在每個轉發設備發生單點故障時,相應的鏈路故障都可被探針檢測到.且這種功能的探測矩陣可以從初始探測矩陣(一般為關系矩陣)中構建.
下面以一個例子對引理2展開進一步說明.如圖2所示,分別以N1和N4對應的轉發設備為探測路徑的源頭,構建一個初始的探測矩陣:
(4)
根據引理2可知,該初始探測矩陣可以探測出所有轉發設備的單點故障.那么接下來,我們從中選擇探測矩陣式(3)的2條探測路徑構成一個新的探測矩陣:
(5)
該探測矩陣中的轉發設備被分成了4組,分別是(N1),(N2,N5),(N3,N6)以及(N4,N7).從初始探測矩陣中其余的探測路徑中選擇一條加入該探測矩陣,新加入的探測路徑應使得分組被分解得更為分散.根據這個原則,進一步構建探測矩陣:
(6)
該探測矩陣中的轉發設備被分成了7組,分別是(N1),(N2),(N3),(N4),(N5),(N6),(N7).根據引理2可知,該探測矩陣具備和初始探測矩陣一致的功能,且與初始探測矩陣相比,探測路徑的數量由初始的9條減少到現在的3條.
2.2 基于端口連接故障的探測矩陣
2.1節介紹的探測矩陣是基于轉發設備單點故障的.現在,我們考慮基于端口連接單點故障的探測矩陣.即假設在任意時間內只有一條端口連接發生故障,我們可以通過探測結果推斷出故障點是哪條端口連接.
首先,我們將前面提到的任意底層網絡G中的每個轉發設備看成一條端口連接,將每條端口連接看成一個轉發設備,并進行如圖3所示的轉換.將轉換后的底層網絡定義為
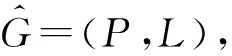
(7)
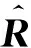
(8)
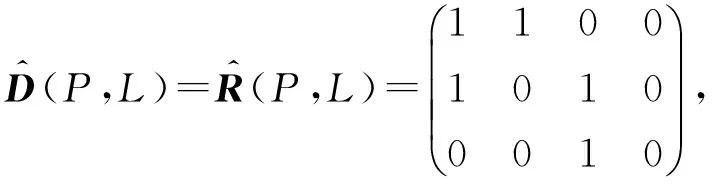
(9)
我們將該關系矩陣作為初始探測矩陣,圖3(b)中L4對應的端口連接是我們虛構的端口連接,用來代指探測路徑不可達的端口連接.
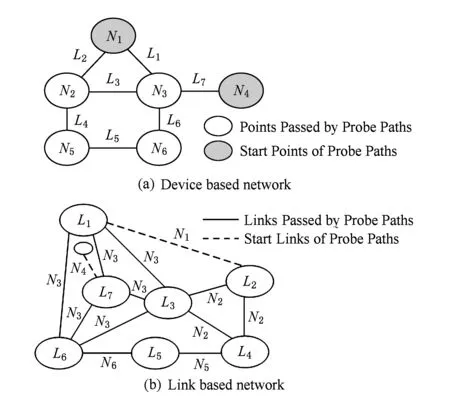
Fig. 3 The example of transformation圖3 轉換示意圖
引理3. 如果探測矩陣中的每個列向量都不相同,那么在每個端口連接發生單點故障時,相應的鏈路故障都可被探針檢測到.且這種功能的探測矩陣可以從初始探測矩陣(一般為關系矩陣)中構建.
如圖3所示,任何一個基于端口連接的探測矩陣都可以找到與其對應的基于轉發設備的探測矩陣,其中,轉換方式是將底層網絡中的每個轉發設備看成一條端口連接,將每條端口連接看成一個轉發設備.根據引理2可知,轉換后的探測矩陣滿足引理3的性質,從而可以證明引理3的正確性.
根據引理3可以發現,上面的初始探測矩陣將端口連接分成了4組,分別是(L1),(L2),(L3),(L4),因此在任意時間內只有一條端口連接發生故障的前提下,該探測矩陣可根據探測結果推斷出故障點是哪條端口連接.
事實上,我們還可以構建包含更少探測路徑的探測矩陣,例如構建只包含第1條探測路徑和第2條探測路徑的探測矩陣:
(10)
可見,在只有一條端口連接發生故障的情況下,我們可通過優化探測矩陣的方式,將探測路徑的數量由初始的3條減少到現在的2條.
值得注意的是:對于大部分數據中心底層網絡,特別是冗余端口連接較多的底層網絡,例如fat-tree拓撲,端口連接的數量通常大于轉發設備的數量.因此,通過對比2.1節和2.2節可以發現,同基于轉發設備的探測相比,基于端口連接進行探測往往需要構建包含更多探測路徑的探測矩陣,但同時也帶來了更細粒度的基于端口級別的探測.
2.3 探測矩陣優化
從2.1節和2.2節中分析可知,無論是基于轉發設備的探測矩陣還是基于端口連接的探測矩陣,都可以通過對探測矩陣的優化實現探測路徑數量的減少.因此,我們考慮如何優化探測矩陣才能實現最少的探測路徑數量,從而降低探測的代價.以2.1節中的基于轉發設備故障的探測矩陣為例(基于端口連接故障同理),可以定義轉發設備的初始集合:
S0={{N1,N2,N3,N4,N5,N6,N7}},
(11)
我們從其初始探測矩陣中選擇一條探測路徑:
(12)
構建一個只含有該探測路徑的探測矩陣,轉發設備因此被該探測矩陣分解為(N1,N2,N5)和(N3,N4,N6,N7)兩部分.通過觀察,該探測路徑經過(N1,N2,N5),但不經過(N3,N4,N6,N7).可知,被該探測路徑經過的部分形成了一個子集,沒有被該探測路徑經過的部分形成了另外一個子集:
S1={{N1,N2,N5},{N3,N4,N6,N7}},
(13)
接下來,向該探測矩陣中加入一條探測路徑:
(14)
轉發設備被該探測矩陣分解為(N1),(N2,N5),(N3,N6)以及(N4,N7)四部分.通過觀察,可以發現這4組分別表示2條探測路徑都經過、第1條路徑經過而第2條路徑不經過、第1條路徑不經過而第2條路徑經過以及2條路徑都不經過.可知,(N1,N2,N5)中被新的探測路徑經過的部分形成了一個子集,沒有被新的探測路徑經過的部分形成了另外一個子集.同理,(N3,N4,N6,N7)中也根據有沒有被新的探測路徑經過形成了2個子集:
S2={{N1},{N2,N5},{N3,N6},{N4,N7}},
(15)
最后,再向該探測矩陣中加入一條探測路徑:
(16)
同理,(N1),(N2,N5),(N3,N6)以及(N4,N7)中分別根據有沒有被新的探測路徑經過各形成了2個子集:
S3={{N1},{N2},{N5},{N3},{N6},
{N4},{N7}},
(17)
分解過程進行到這一步,如果仍存在子集不由單個元素構成,那么還需繼續向探測矩陣中添加新的探測路徑,直至所有形成的子集都是由單個元素構成.
通過這種故障點集合分解的方法,我們可以獲得一個由初始探測矩陣(一般為關系矩陣)中探測路徑的子集構成的探測矩陣,但這并不能保證該探測矩陣中包含的探測路徑數量是最優的.并且,我們還發現當探測路徑的數量達到最優時,對應的最優探測矩陣可能并不是唯一的.
無論是基于轉發設備的探測矩陣還是基于端口連接的探測矩陣.假設探測路徑的數量是m,那么探測結果最多為2m種,并且其中有一種探測結果為無故障發生.假設需要檢測的故障點有n個,且在任意時間點只可能發生單點故障的情況下,理想上檢測所需的探測路徑數量為

(18)
當然,具體數量還與底層網絡拓撲有關.搜索最優探測矩陣的過程中可以使用指數時間復雜度的窮舉搜索算法.但由于時間復雜度過高,在大規模場景下并不實用.因此,我們采用一種基于貪婪策略的近似算法對最優探測矩陣進行搜索.該近似算法的思想是:每次向探測矩陣中添加新的探測路徑時,選擇產生最大信息熵的探測路徑進行添加.我們以一個例子來說明該近似算法的原理.假如,在第2次添加探測路徑時,選擇的探測路徑產生了情況的分解:
(19)
即使該分解可使3個子集只由單個元素組成,但由于其后還必須再添加至少2條探測路徑才能使所有子集都由單個元素構成.相較之下,
S2={{N1},{N2,N5},{N3,N6},{N4,N7}},
(20)
該分解雖然只能使一個子集由單個元素組成,但由于其后可能只需要再添加一條探測路徑就能使所有子集都由單個元素構成,因此我們認為它具有更大的混亂度,即信息熵,使得分解更接近于最終狀態.進而我們認為后者探測路徑的優先級比前者更高.
假設選擇并添加某條探測路徑后所對應的分解M由i個子集構成,那么將這i個子集分解到最終狀態還必須再添加的探測路徑可表示為
(21)
同時,這也是該探測路徑所對應的信息熵的倒數.
假設初始探測矩陣(一般為關系矩陣)中行向量的數量為x,那么當每次選擇并添加探測路徑時,需要與其余候選的探測路徑所對應的信息熵進行比較,因此該算法的時間復雜度可表示為
(22)
3 探測路徑質量問題
在本節中,我們主要介紹如何定義一條探測路徑的質量,并說明如何找到滿足質量的探測路徑.
3.1 探測路徑質量標準
在減少探測路徑數量的基礎上,我們還需要針對探測路徑的質量進行分析,為此我們首先給出2個用于反映探測路徑質量的指標.
定義1.Θ并發的探測矩陣.如果存在這樣的探測矩陣,在任意時間點至多有Θ個故障點同時發生故障的情況下,仍能夠根據探測結果推斷出故障點.我們將這樣的探測矩陣定義為Θ并發的探測矩陣.
前面提到的探測矩陣都是基于任意時間點只有一個故障點發生故障的,即在Θ=1的情況下,現在我們需要將這個前提進行推廣.為此,我們以2.2節中底層網絡的關系矩陣為例進行考慮,假設我們想要檢測出L1和L3對應的端口連接可能同時發生故障,則需要構建一個擴展的關系矩陣:
(23)
其中,最后一個列向量是對L1和L3對應故障點列向量中的元素依次執行或運算所生成的.通過這種構建額外列向量的方式,我們可以在探測矩陣中表示可能同時發生的多個故障.假設需要檢測的故障點為n個,為了保證探測矩陣是Θ并發的,初始化階段應額外構建的列向量數目為
(24)
其中,全部故障點都發生故障與都正常同屬于Θ=1情況下.接下來,我們只需對構建了額外列向量的關系矩陣實施2.3節中介紹的Θ=1情況下的分解步驟,最終就可以得到滿足Θ并發的探測矩陣.
定義2.Γ冗余的探測矩陣.如果每個故障點都被至少Γ條探測路徑經過,滿足這樣條件的探測矩陣,我們將它定義為Γ冗余的探測矩陣.Γ冗余決定了故障點的探測可靠性,當Γ>1時,有多條探測路徑經過故障點,即使其中部分探測路徑失效(如轉發設備的緩存溢出導致探針丟失等),也能使故障被正常檢測出來.
此外,通過Γ冗余還可以使探測路徑更為均勻地分布在需要檢測的故障點上,從而使鏈路故障檢測所帶來的額外負載能夠均衡分布在底層網絡中.為此,我們為每一條候選探測路徑設置了一個參數Φ:
(25)
其中,參數Φ表示分解過程中添加該探測路徑的優先級;參數Δ是每個故障點的一個屬性,用于保障探測路徑的冗余性;參數Υ表示分解過程中與該探測路徑產生交集的子集數量.如果探測路徑的參數Φ較小,一方面說明它所經過的故障點被已添加的探測路徑所覆蓋的程度較小,另一方面說明添加它對于分解過程所帶來的信息熵較大.可見,這樣設置既可保證探測的可靠性,又可保證探測負載的均衡性,還可保證探測路徑數量的最少化.
3.2 探測路徑選擇
基于以上2方面的探測路徑質量指標,我們采用了一種基于貪心策略的探測矩陣的近似優化算法,如算法1所示.首先,算法1會根據Θ值構建底層網絡的擴展關系矩陣,從而將Θ>1情況下的問題轉換為Θ=1情況下可以解決的問題.在每輪向探測矩陣中添加探測路徑之前,需要更新所有待選路徑的Φ值并以正序排列,然后選擇排序中第1條待選路徑作為探測路徑,并把它添加到探測矩陣中.最后,更新已選路徑上所有故障點的Δ值.算法1輸出探測矩陣的條件為,經過若干輪路徑選擇后,所有故障點的Δ值都大于Γ且所有子集都由單個元素構成.如果添加完所有路徑后仍然不能滿足條件,算法1將輸出找不到合適的探測矩陣.
算法1. 探測矩陣構建算法.
輸入:關系矩陣R、并行度Θ、冗余度Γ、故障點集N;
輸出:探測矩陣D.
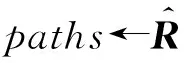
④ while (num≠|N|‖points≠?) &&
paths≠? do
⑤ fori∈pathsdo
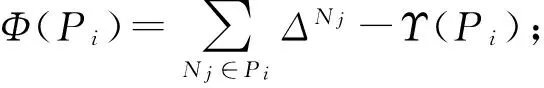
⑦ end for
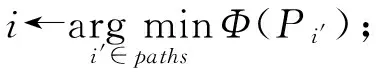
⑨P←P∪{i};
⑩paths←paths{i};
引理4. 在探測路徑的數量最少化方面,該基于貪心策略的探測矩陣優化算法的近似比為
(26)
其中,e為自然對數.證明時,首先定義一個函數f:
(27)
由于探測路徑經過的故障點數量應大于分解過程中與該探測路徑產生交集的子集數量.可知:
(28)
(29)
根據式(28)(29),Φ(Pi)的非負性得證.又因為:
f(s)≥0,
(30)
0≤f(S)≤f(S∪s),
(31)
根據式(30)(31),f的非負性得證,且f為單調非遞減.由于我們的目標是最小化S的模,此時原目標可以被轉換為最小化f.
由于越多的路徑被選擇,分解所產生的子集數量就會變得越多,同時與新加入路徑產生交集的子集數量也會變得越多.因此可以得到:
f(s|S)≤f(s|T),
(32)
f(s|S)=f(S∪s)-f(S),
(33)
其中,T?S.根據式(32)(33),f的子模性得證.由于目標的非負性、單調性以及子模性都可以得到證明,因此該近似算法的近似比可以得到證明.
由于該算法的時間復雜度為關系矩陣中轉發路徑數量的平方級,因此如何有效降低算法的執行時間是一個需要考慮的問題.我們選擇從2個方面進行優化:
1) 基于底層網絡的關系矩陣構建一張二分圖,圖中的一個點集代表故障點,另一個點集代表轉發路徑,兩點之間若存在邊則代表故障點位于轉發路徑之上.如果某2條轉發路徑所經過的故障點完全不同,則形成更小規模的子圖以及子關系矩陣.經過這樣的處理,原問題可被拆分為多個獨立的子問題,在每個子問題中算法可以并行執行.通過線性時間的算法可實現對二分圖的一次遍歷以及對子問題的拆分.
2) 基于數據中心底層網絡的拓撲對稱性,當某條轉發路徑被添加到探測矩陣時,其對稱路徑也會被加入.經過這樣的處理,原問題的規模可以被進一步降低.為此,我們需要在探測開始之前一次性計算出關系矩陣中的對稱路徑.
4 實驗與結果
在本節中,我們針對探測矩陣的探測性能與計算開銷展開仿真實驗,并根據實驗結果進行分析.
4.1 實驗環境設置
在仿真實驗中,我們基于Java開發環境實現了基于探測矩陣的鏈路故障檢測方法BPM-N以及BPM-L.其中,BPM-N是基于故障點為轉發設備的,BPM-L是基于故障點是端口連接的.我們考慮的鏈路故障為所有經過故障點的報文全部無法被對端收到(中途被轉發設備丟棄、報文丟失或轉發表配置錯誤路由到錯誤的目的地后被丟棄).在探測矩陣構建時,我們考慮Θ=1,Γ=2的情況.
我們采用了2種底層網絡設置分別是一個FatTree(12)拓撲和一個VL2(20,12,20)拓撲,以驗證我們的方法在不同拓撲結構和規模下的效果.其中,FatTree和VL2拓撲都是廣泛應用的,且具有冗余傳輸鏈路的數據中心內部網絡拓撲結構.這2種拓撲中的流量轉發路徑具有一定規律,所有從源服務器中發送的流量會先經過一個ToR交換機,之后再經過匯聚層交換機或核心層交換機到達目的服務器所在的ToR交換機.相同Pod內的流量只經過匯聚層交換機,不經過核心層交換機;而不同Pod之間的流量則需要先經過匯聚層交換機上傳至核心層,再由核心層下傳至匯聚層.我們考慮每條轉發路徑都是雙向的,即探針回復時的路徑與探針發送時的路徑相同.因此部分鏈路故障可能不是在探針發送時被檢測出來,而是在探針回復時被檢測到.
關系矩陣中的轉發路徑由所有接入層ToR交換機之間的鏈路構成.在一個FatTree(12)拓撲中,轉發路徑中包含180個轉發設備(共612個節點)以及864條端口連接(共1 296條鏈路),而在一個VL2(20,12,20)拓撲中,轉發路徑中包含82個轉發設備(共1 282個節點)以及240條端口連接(共1 440條鏈路).我們選擇進行對比的方法是Pingmesh中提出的探測方法.它是一種對底層網絡不進行感知的鏈路故障檢測方法,即將整個底層網絡視為一個黑盒系統,并基于服務器之間進行端到端的網絡探測.該方法產生的探針數量由Pod內部以及Pod之間2種情況組成,在Pod內部,由所有的服務器以完全圖的方式彼此發送探針;而在Pod之間,則是由所有的ToR交換機以完全圖的方式彼此發送探針,其中,ToR交換機之間探針的發送也是由服務器實現的.在一個FatTree(12)拓撲中,該方法產生的探針數量為20 232,而在一個VL2(20,12,20)拓撲中,該方法產生的探針數量為26 340.我們選取了BPM-N,BPM-L以及Pingmesh這3種方法下10個探測周期的數據進行比較.
4.2 探測性能對比
為了檢驗我們提出的實時探測方法與之前工作中提出的方法在探測性能上的差別,我們分別針對單次探測用時、網絡帶寬占用以及端點負載3個指標在2種拓撲下進行了對比仿真實驗.
評價指標中的單次探測用時包括3部分的用時:1)中央控制器(鏈路故障檢測控制器)激活探測過程中涉及的所有服務器的探針代理所需的時間;2)探針代理發送網絡探針并等待回復的時間;3)探針代理將探測結果上傳到中央控制器所需的時間.其中,探針代理每隔固定一段時間就發送一個探針(而不是一直等待直到收到上輪探針的回復后再發送下一輪探針),每個探針上用時間戳和自增序號進行標記,探針代理確認回復的時間存在閾值,一旦計時器檢測到超過,就會向中央控制器發送鏈路故障消息.在任意時隙內,如果中央控制器已收到大部分探測結果(例如95%),就認為當前一個探測周期已經完成,并進入下一個探測周期.
在單次探測用時方面,FatTree(12)拓撲下的實驗結果如圖4所示,可以看出我們采用的BPM-L和BPM-N的探測周期遠遠低于Pingmesh的探測周期,差距最大處接近47倍.造成這樣結果的主要原因是BPM-L和BPM-N使用的探測路徑的數量要遠遠小于Pingmesh使用的.另一方面,BPM-N的探測周期整體低于BPM-L的探測周期,差距最大處接近2.5倍.造成這樣結果的主要原因是,BPM-N探測矩陣中故障點數小于BPM-L中的.但同時BPM-L帶來了更細粒度的基于端口級別的探測.

Fig. 4 The results of FatTree on detection period圖4 FatTree探測周期結果圖

Fig. 5 The results of VL2 on detection period圖5 VL2探測周期結果圖
VL2(20,12,20)拓撲下的單次探測用時的實驗結果如圖5所示,可以看出在VL2拓撲下,BPM-L和BPM-N的探測周期與Pingmesh的差距更加明顯,差距最大處已經接近89倍.造成這樣結果的主要原因是由于BPM-N和BPM-L的探針數量分別是受轉發設備以及端口連接數目影響的,而Pingmesh的探針數量則是受服務器數量影響的.與FatTree(12)拓撲相比,VL2(20,12,20)拓撲中的轉發設備與端口連接數目更少,而服務器數量更多.在VL2拓撲中BPM-N的探測周期同樣整體低于BPM-L的探測周期,差距最大處接近1.5倍.
在網絡帶寬占用方面,FatTree(12)拓撲下的實驗結果如圖6所示.我們考慮每條鏈路上的帶寬數量是一定的,其中一定比例(如90%)的帶寬需要傳輸工作負載,那么剩余比例(如10%)的帶寬中,每條探測路徑會消耗其中的一部分(如1%),而且消耗的部分越多,越有可能對工作負載的傳輸造成不良影響.從實驗結果可以看出我們采用的BPM-L和BPM-N的平均帶寬占用遠遠低于Pingmesh的平均帶寬占用,差距最大處接近9倍.同理,造成這樣結果的主要原因是BPM-L和BPM-N使用的探測路徑的數量要遠遠小于Pingmesh使用的探測路徑數量.此外,BPM-N的平均帶寬占用也同樣低于BPM-L,差距最大處接近2倍.這也是由于BPM-N探測矩陣中的故障點數小于BPM-L中的故障點數所造成的結果.
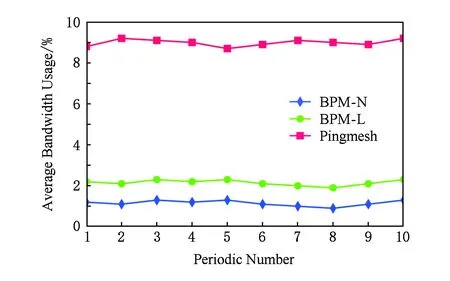
Fig. 6 The results of FatTree on average bandwidth usage圖6 FatTree平均帶寬占用結果圖
VL2(20,12,20)拓撲下的平均帶寬占用的實驗結果如圖7所示,可以看出在VL2拓撲下,BPM-L和BPM-N的平均帶寬占用與Pingmesh的差距更加明顯,差距最大處已經接近17倍.由于我們考慮的是Γ=2情況下的BPM-L,因此在Fat-Tree和VL2兩種拓撲下BPM-L的平均帶寬占用的結果非常接近.在VL2拓撲中BPM-N的平均帶寬占用同樣整體低于BPM-L的平均帶寬占用,差距最大處接近3倍.
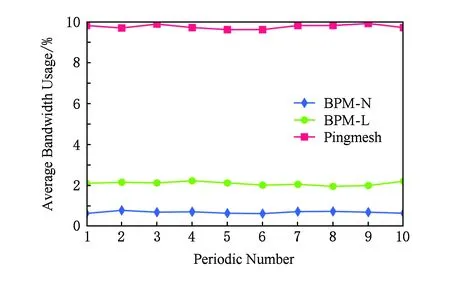
Fig. 7 The results of VL2 on average bandwidth usage圖7 VL2平均帶寬占用結果圖
評價指標中的端點負載,與網絡帶寬占用相似,指的是網絡邊緣的服務器運行探針代理所產生的代價.我們考慮服務器中可用于運行探針代理的CPU利用率是一定比例(如5%)以內的,單位時隙內,每維護一個探針會占用一定比例(如0.5%)的CPU利用率,而且占用的部分越多,越有可能對其他應用進程的運行造成不良影響.在我們的方法中,所有探針代理產生的端點負載可以在ToR交換機下屬的所有服務器間進行負載均衡.而在Pingmesh的方法中,僅有Pod之間情況下的端點負載可以在ToR交換機下屬的所有服務器間進行負載均衡.

Fig. 8 The results of FatTree on average serverCPU usage圖8 FatTree服務器平均CPU占用結果圖
在端點負載方面,FatTree(12)拓撲下的實驗結果如圖8所示.可以看出我們采用的BPM-L和BPM-N的服務器平均CPU占用遠遠低于Pingmesh的平均CPU占用,差距最大處接近4.5倍.造成這樣結果的主要原因是BPM-L和BPM-N在服務器間需要維護的探針數量要遠遠小于Pingmesh的.另一方面的原因是,在BPM-L和BPM-N中,由于所有的ToR交換機下屬的服務器之間都可以進行負載均衡,從而可以進一步降低服務器平均CPU占用.BPM-N在服務器平均CPU占用方面仍然低于BPM-L,差距最大處接近1.5倍.說明由于基于端口連接的故障點數更多,導致對BPM-L的探針維護和端點負載的影響更大.
VL2(20,12,20)拓撲下的端點負載的實驗結果如圖9所示,可以看出在VL2拓撲下,BPM-L和BPM-N的端點平均CPU占用與Pingmesh之間仍存在差距,且差距最大處接近4倍,這與FatTree(12)拓撲中的結果相比有所下降.VL2拓撲下的BPM-N的服務器平均CPU占用同樣整體低于BPM-L的,差距最大處接近1.5倍.
Fig. 9 The results of VL2 on average server CPU usage圖9 VL2服務器平均CPU占用結果圖
綜合來看,我們采用的BPM-L和BPM-N鏈路故障檢測方法在單次探測用時(探測周期)、網絡帶寬占用(平均帶寬占用)和端點負載(服務器平均CPU占用)3方面與之前的工作Pingmesh相比較,具有顯著的優勢,主要原因是我們采用的方法可以根據已獲取的底層網絡轉發路徑構建近似最優的探測矩陣,從而減少探測路徑和端到端探針的數量,進而降低單次探測用時、網絡帶寬占用以及端點負載,實現實時快速的虛擬故障鏈路檢測功能.
4.3 探測矩陣計算開銷
雖然探測矩陣在每次網絡更新之后只需要進行一次優化,但每次對探測矩陣進行優化的過程中都存在一定的計算開銷,該開銷包括計算時間上的開銷以及計算內存上的開銷.在時間開銷方面,我們考慮了算法1基于BPM-L的探測矩陣構建方法DMO,以及另外2種基于DMO并進一步優化了算法時間復雜度的構建方法.其中,DMO-S是考慮了子問題拆分后的改進方法,DMO-T則是考慮了拓撲對稱性后的改進方法.我們分別在FatTree(12)和VL2(12,20,12)兩種拓撲下對3種不同的探測矩陣構建方法的時間開銷進行了仿真實驗.
仿真實驗的結果如圖10所示.其中,未經過任何優化的DMO在FatTree(12)中的運行時間與它在VL2(12,20,12)中的運行時間分別為224.7 s和23.2 s.而經過DMO-S優化后的運行時間是6.8 s和24.3 s,可見DMO-S在Fat-Tree拓撲下的效果明顯.經過DMO-T優化后的運行時間是1.1 s和1.9 s,說明在對稱的數據中心網絡拓撲中,DMO-T的效果最好.基于BPM-N的探測矩陣構建方法由于具有更少的故障點數量,因此與BPM-L相比,其運行時間會更短.
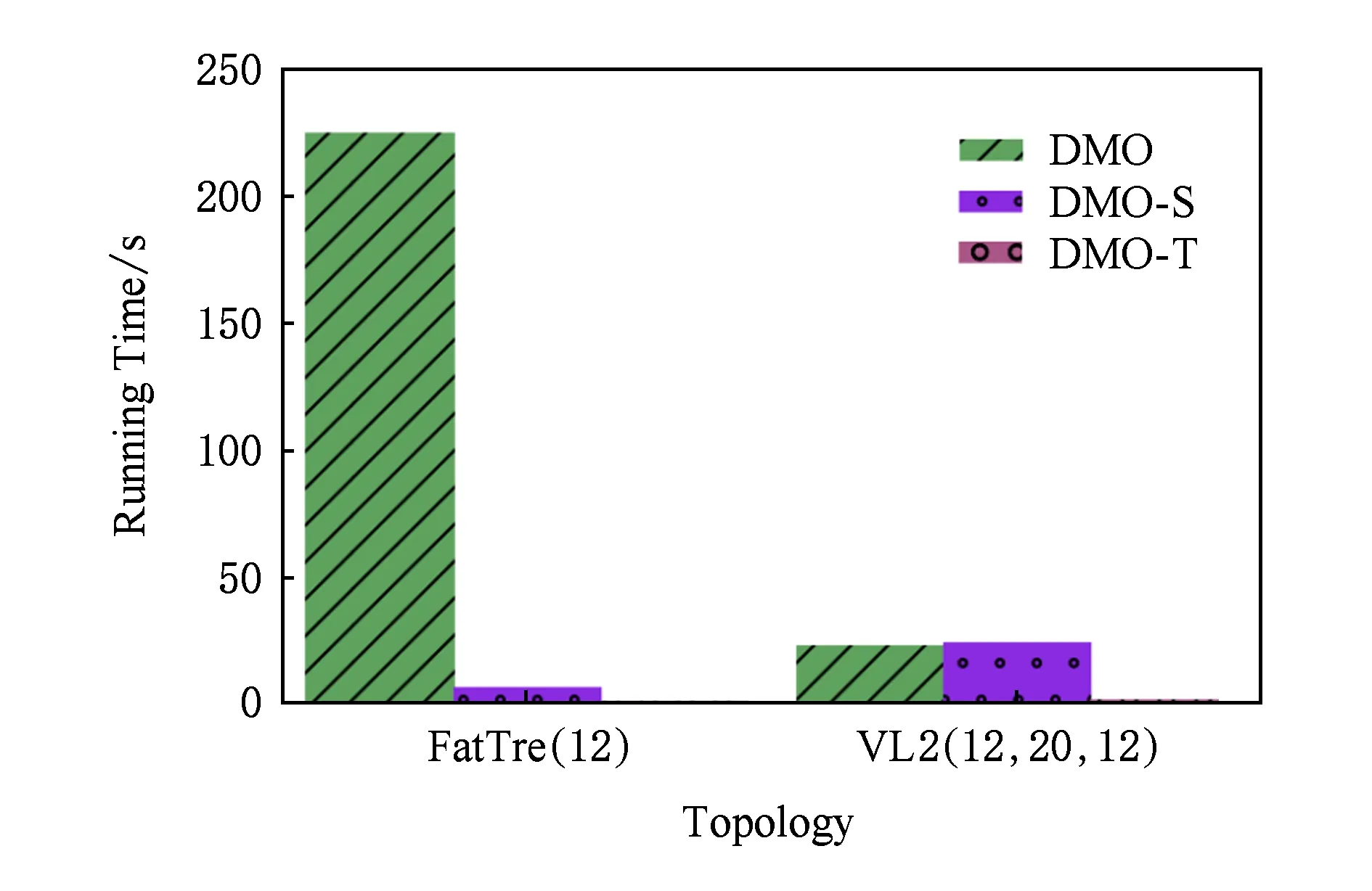
Fig. 10 The results on algorithm running time圖10 算法運行時間結果圖
在內存開銷方面,我們考慮了BPM-L與BPM-N在FatTree(12)和VL2(12,20,12)兩種拓撲下關系矩陣的內存消耗,仿真實驗的結果如圖11所示.其中,我們在Java中使用int類型保存關系矩陣中的位值.由于該類型包含4個字節即32 b,因此理論上測得的結果是最低內存開銷的32倍.對比結果顯示,關系矩陣在FatTree(12)下的內存占用更大,差不多是VL2(12,20,12)下的2.5倍;而在同一拓撲中,BPM-L的內存占用更小,差不多是BPM-N的45.
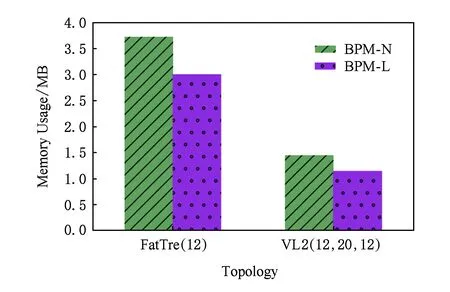
Fig.11 The results on algorithm memory usage圖11 算法內存占用結果圖
事實上,一般數據中心網絡的層數都在3層以內,以最廣泛應用的FatTree和VL2拓撲為例,每條路徑最多包含5個故障點(基于端口連接的情況下為4個),一個商用大規模12階FatTree拓撲中的路徑總數為184 032,而一個商用大規模(20,12,20)的VL2拓撲中的路徑總數為70 800.這2種拓撲下單點故障的初始探測矩陣(基于關系矩陣)的大小可以計算出來分別為920 160 b和354 000 b,即115.02 KB和44.25 KB,一般被認為是可以忍受的內存開銷.
綜合來看,我們采用的BPM-L和BPM-N鏈路故障檢測方法在構建探測矩陣的過程中所產生的計算開銷是完全可以容忍的.在常見的商用大規模數據中心網絡拓撲中,計算時間開銷經過優化后可以達到秒級,計算內存開銷可以維持在MB級別.
5 總 結
本文通過對已有的鏈路故障檢測工作中存在的問題進行分析,發現了最少化探測路徑數量對于提升檢測速度具有重要的意義.因此,我們采用優化探測矩陣的方法,以此來構建數量最少化、質量最大化的探測路徑集合.在解決該問題的過程中,我們給出了探測矩陣的定義和探測矩陣的優化方法,在提升探測路徑的質量方面,我們定義了2種質量指標,并給出了結合質量指標的探測矩陣優化方法.最后,我們通過仿真實驗的方式驗證了該實時檢測方法在單次探測用時、網絡帶寬占用以及端點負載3方面比之前工作中的方法具有顯著優勢,且優化探測矩陣所帶來的開銷是可容忍的.
[1]Al-Fares M, Loukissas A, Vahdat A. A scalable, commodity data center network architecture[C]Proc of ACM SIGCOMM’08. New York: ACM, 2008: 63-74
[2]Govindan R, Minei I, Kallahalla M, et al. Evolve or die: High-availability design principles drawn from Googles network infrastructure[C]Proc of ACM SIGCOMM’16. New York: ACM, 2016: 58-72
[3]Han B, Gopalakrishnan V, Ji L, et al. Network function virtualization: Challenges and opportunities for innovations[J]. IEEE Communications Magazine, 2015, 53(2): 90-97
[4]Guo Chuanxiong, Yuan Lihua, Xiang Dong, et al. Pingmesh: A large-scale system for data center network latency measurement and analysis[C]Proc of ACM SIGCOMM’15. New York: ACM, 2015: 139-152
[5]Kreutz D, Ramos F M V, Verissimo P J E, et al. Software-defined networking: A comprehensive survey[J]. Proceedings of the IEEE, 2014, 103(1): 10-13
[6]Berde P, Gerola M, Hart J, et al. ONOS: Towards an open, distributed SDN OS[C]Proc of ACM HotSDN’14. New York: ACM, 2014: 1-6
[7]Duffield N. Network tomography of binary network performance characteristics[J]. IEEE Trans on Information Theory, 2006, 52(12): 5373-5388
[8]Cunha í, Teixeira R, Feamster N, et al. Measurement methods for fast and accurate blackhole identification with binary tomography[C]Proc of ACM IMC’09. New York: ACM, 2009: 254-266
[9]Dhamdhere A, Teixeira R, Dovrolis C, et al. Netdiagnoser: Troubleshooting network unreachabilities using end-to-end probes and routing data[C]Proc of ACM CoNEXT’07. New York: ACM, 2007: 18-30
[10]Nguyen H X, Teixeira R, Thiran P, et al. Minimizing probing cost for detecting interface failures: Algorithms and scalability analysis[C]Proc of IEEE INFOCOM’09. Piscataway, NJ: IEEE, 2009: 1386-1394
[11]Nguyen H X, Thiran P. The Boolean solution to the congested IP link location problem: Theory and practice[C]Proc of IEEE INFOCOM’07. Piscataway, NJ: IEEE, 2007: 2117-2125
[12]Zhang M, Zhang C, Pai V S, et al. PlanetSeer: Internet path failure monitoring and characterization in wide-area services[C]Proc of USENIX OSDI’04. Berkeley, CA: USENIX Association, 2004: 167-182
[13]Zhao Yao, Chen Yan, Bindel D. Towards unbiased end-to-end network diagnosis[C]Proc of ACM SIGCOMM’06. New York: ACM, 2006: 219-230
[14]Zeng Hongyi, Mahajan R, Mckeown N, et al. Measuring and troubleshooting large operational multipath networks with gray box testing, MSR-TR-2015-55[R]. Redmond: Microsoft Research Lab, 2015
[15]Sharma G, Jaggi S, Dey B K. Network tomography via network coding[C]Proc of IEEE ITA’08. Piscataway, NJ: IEEE, 2008: 151-157
[16]Yao Hongyi, Jaggi S, Chen Minghua. Network coding tomography for network failures[C]Proc of IEEE INFOCOM’10. Piscataway, NJ: IEEE, 2010: 91-95
[17]Kandula S, Mahajan R, Verkaik P, et al. Detailed diagnosis in enterprise networks[C]Proc of ACM SIGCOMM’09. New York: ACM, 2009: 243-254
[18]Herodotou H, Ding B, Balakrishnan S, et al. Scalable near real-time failure localization of data center networks[C]Proc of ACM KDD’14. New York: ACM, 2014: 1689-1698
[19]Mace J, Roelke R, Fonseca R. Pivot tracing: Dynamic causal monitoring for distributed systems[C]Proc of ACM SOSP’15. New York: ACM, 2015: 378-393
[20]Li Yuliang, Miao Rui, Kim C, et al. LossRadar: Fast detection of lost packets in data center networks[C]Proc of ACM CoNEXT’16. New York: ACM, 2016: 481-495

[21]Hou Le, Wang Shuo, Lin Yikai, et al. Link failure recovery based on SDN[J]. Telecommunications Science, 2015, 31(6): 18-23 (in Chinese)(侯樂, 汪碩, 林毅凱, 等. 基于SDN的鏈路故障恢復[J]. 電信科學, 2015, 31(6): 18-23)WangJunxiao, born in 1991. PhD candidate at Dalian University of Technology. His main research interests include software defined networking, network function virtualization, and cloud computing.

QiHeng, born in 1981. PhD. Associate professor at Dalian University of Technology. Member of CCF. His main research interests include computer network, future Internet technology and multimedia computing.

LiKeqiu, born in 1971. PhD. Professor and PhD supervisor at Dalian University of Technology. Distinguished member of CCF. His main research interests include data center networks, cloud computing and wireless networks.

ZhouXiaobo, born in 1984. PhD. Associate professor at Tianjin University. Member of CCF. His man research interests include network information theory, cloud computing, and software defined networking.
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:26:08
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
工業設計(2016年12期)2016-04-16 02:52:00
汽車維修與保養(2015年6期)2015-04-17 03:31:50
