基于GPU的RDF類型同構并行算法
2018-03-28 05:02:02馮佳穎張小旺馮志勇
計算機研究與發展 2018年3期
馮佳穎 張小旺 馮志勇
1(天津大學計算機科學與技術學院 天津 300350) 2(天津大學軟件學院 天津 300350) 3 (天津市認知計算與應用重點實驗室 天津 300350) (fengjiaying@tju.edu.cn)
語義網(semantic Web)是一種新型的智能網絡,它旨在解決當前Web上信息爆炸導致人們獲取目標信息十分困難的問題.資源描述框架(resource description framework, RDF)和SPARQL查詢語言是W3C(World Wide Web Consortium)組織推薦的用來描述語義網中的數據資源及其之間關系的語言規范和數據查詢語言.隨著RDF數據量的不斷增大,如何在大規模RDF數據集上進行高效的查詢檢索是當今面對的一個重大挑戰.
傳統RDF數據集的查詢方法使用CPU作為處理器,諸如Jena[1],RDF-3X[2],gStore[3]等集中式查詢引擎系統,它們已將CPU的計算能力發揮到了極致.近年來,圖形處理單元(graph processing unit, GPU)計算性能不斷增強.由于GPU具有浮點計算能力強、帶寬高、性價比高、能耗低等優勢,可以極大地補充CPU的計算能力.利用GPU的并行處理能力實現算法和操作,可以大大降低CPU的負載.
在RDF數據集上的SPARQL(Simple Protocol and RDF Query Language)查詢過程就是一個子圖同構的過程.子圖同構問題是圖處理問題中一個最基本的研究內容,屬于NP完全問題.類型同構是一種不精確的子圖同構.通過頂點和邊的標簽約束,將部分查詢轉化為類型同構問題.并結合GPU數據處理方面高效的的計算性能,本文提出了使用并行硬件GPU實現對RDF類型同構查詢的算法,從而提高RDF數據集的查詢性能.
本文主要貢獻如下:結合RDF數據的特征和GPU極高的計算能力,提出一種基于GPU的匹配算法,使GPU多處理器調度更簡便;在GPU的硬件加速下,對本算法進行大量的性能實驗.實驗結果表明:基于GPU的類型匹配算法性能對于現有方法有了顯著的提高.
1 背景知識
1.1 RDF和SPARQL
資源描述框架RDF是W3C組織提出的語義Web標準數據模型.它是用于形式化描述Web資源的元數據.RDF通過語法符號和序列化數據格式的方法來描述概念并對信息進行建模.RDF三元組(S,P,O)是RDF數據集的基本單元,一個RDF數據集中包含了許多RDF三元組,這些三元組表示了資源和資源之間的聯系,其中S代表主語(subject),是被描述的資源,P代表謂語(predicate),表示資源的一個屬性或關系,O代表賓語(object),表示屬性值.
由許多RDF三元組組成的數據集將語義Web的信息表示成為一個帶標注的有向圖,稱為RDF圖.
定義1. RDF圖.一個RDF圖可以表示成為給定一個帶標簽的有向圖G=(V,E,μ,σ).V表示頂點的有限集,E表示邊的有限集.μ:V→LV表示頂點到頂點標簽類型的映射函數.σ:E→LE表示邊到邊標簽類型的映射函數.LV和LE是按標簽排列的離散符號集合,表示了聯系2個帶標簽的頂點或邊的標簽值向量.
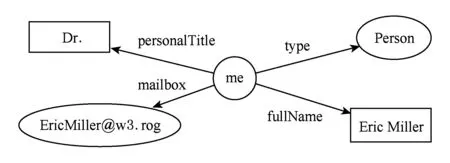
Fig. 1 RDF graph圖1 RDF圖
如圖1展示了一個RDF圖,其中,橢圓節點表示資源,有向邊表示屬性,矩形節點表示字符值.例如,對于資源“me”,其“fullName”屬性的值是一個字符值“Enic Miller”.
SPARQL查詢語言是W3C組織推薦的RDF標準查詢語言,由一組三元組模式(triple pattern)組成.大多數SPARQL查詢都是由若干個基本圖模式(basic graph pattern, BGP)組成.SPARQL查詢即為圖模式匹配,其查詢的過程為找到與每個三元組模式匹配的三元組,再連接(join)具有共享變量的三元組模式的局部結果.結合圖1,如果我們想獲得某個具有屬性“type”,同時具有屬性“fullName”其值為“Eric Miller”的資源時,我們可以通過如下的SPARQL查詢獲得,其對應的查詢圖如圖2所示.
SELECT ?xWHERE{
?xtype ?y.
?xfullName “Eric Miller”.}

Fig. 2 SPARQL query graph圖2 SPARQL查詢圖
本工作通過研究SPARQL語法細節和語義的形式化定義[4]并使用GPU上的類型同構算法來提高特定基本圖模式中查詢處理的性能.
1.2 RDF中的子圖同構與類型同構
依據RDF圖是帶標簽的有向圖的特征,本文的研究重點僅關注帶標簽的有向圖.在已知的RDF數據中進行SPARQL查詢的過程也就是一個模式圖(即圖2所示查詢圖)與RDF圖的子圖同構匹配過程.
定義2. 子圖同構.給定一個RDF圖G和一個模式圖P,P包含n個頂點(v0,v1,v2,…,vn-1).如果G中包含n個頂點(u0,u1,u2,…,un-1),與P之間存在一個單射函數f:P→G,使G的頂點和邊與P的頂點和邊一一匹配,則認為模式圖P子圖同構于有向圖G.
尋找子圖同構就是將模式圖Gp嵌入RDF圖G的過程.當子圖的所有頂點、邊都與模式圖的排列順序相同,并且對應的頂點和邊符合各自的標簽時,匹配過程結束.
定義3.k邊游走.假設一個圖中的非空有限序列W=(v0,e0,v1,e1,v2,…,ek-1,vk),其中邊ei連接頂點vi和vi+1.這個序列的長度為2k+1,被稱為k邊游走(k-edge walk).
定義4. 類型同構.給定一個RDF圖G=(VG,EG,μ,σ),和相關聯的模式圖P=(VP,EP,μ,σ),它們之間存在標簽函數的映射關系,μ:V→LV和σ:E→LE分別定義了頂點和邊與標簽之間的映射關系,其中LV和LE為標簽集合,即LVP?LVG和LEP?LEG.定義P的k邊游走為
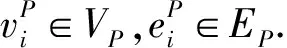

類型同構通過k邊游走算法,計算出RDF有向圖中與模式圖的類型相匹配的部分.如圖3(b)和圖4(b)中虛線框內G的子圖均為滿足P的類型同構.不同之處在于圖3(b)是對P的頂點不加約束的類型同構,圖4(b)是對P的頂點增加約束的類型同構,說明類型同構只是匹配滿足映射的頂點與邊,并不要求同構.
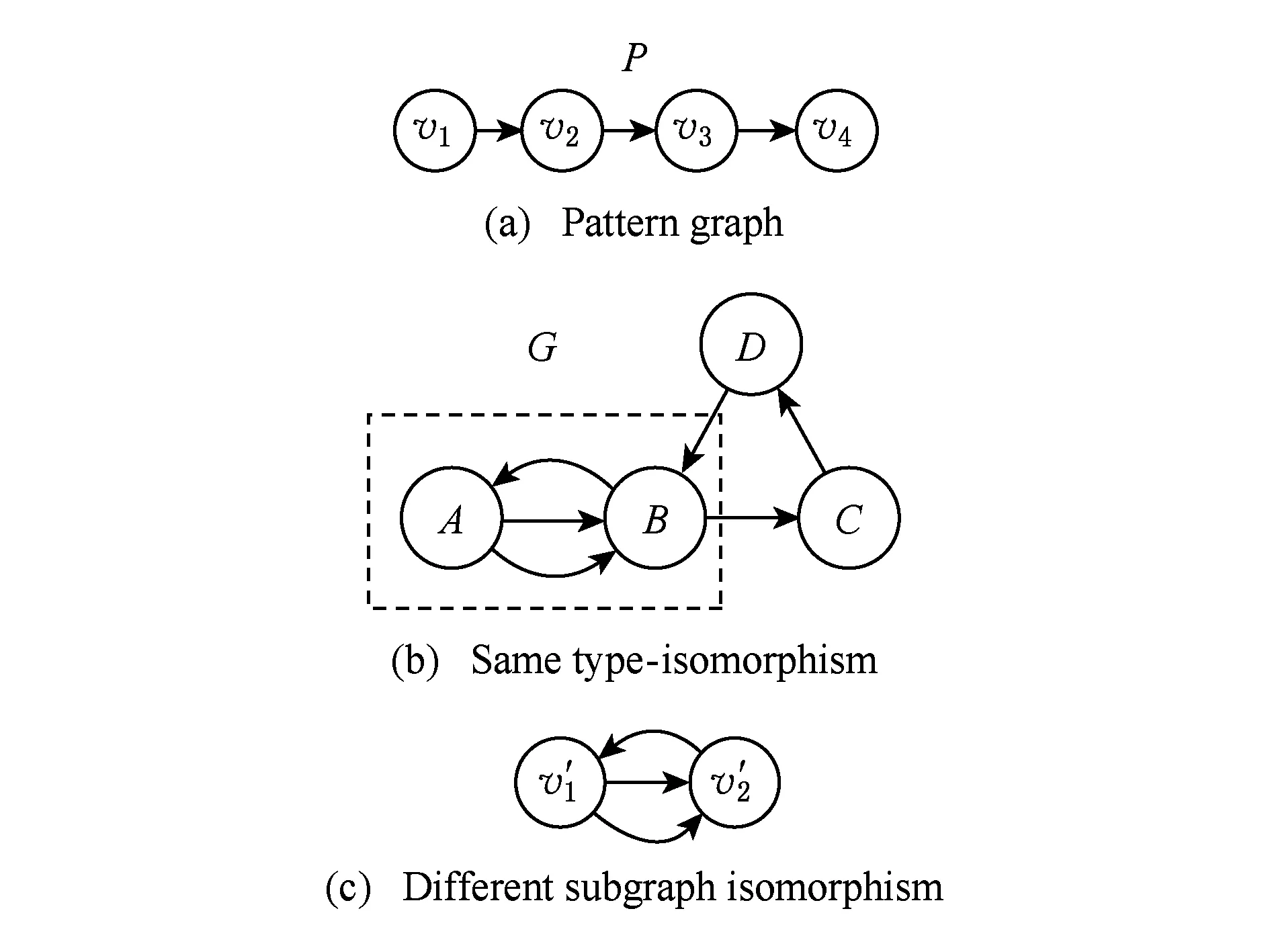
Fig. 3 Without constrained type-isomorphism of P vertexes 圖3 P的頂點不加約束的類型同構
類型同構是一種不精確的子圖匹配,不同于子圖同構問題的是類型同構不需要找到同構結構.如圖3(a)和圖4(a)所示的G對應了相同的類型同構,但對應了不同的子圖同構,如圖3(c)和圖4(c)所示.通過對類型同構的k邊游走序列增加標簽的限制,從而得到更精確的結果,如圖3所示.IRSMG[5]中提出子圖同構問題的解可以簡化為約束的類型同構的解.因此,本文將在RDF圖與基本圖模式之間的匹配問題,轉化為RDF圖與相應的關聯模式圖的附加約束的類型同構匹配問題.
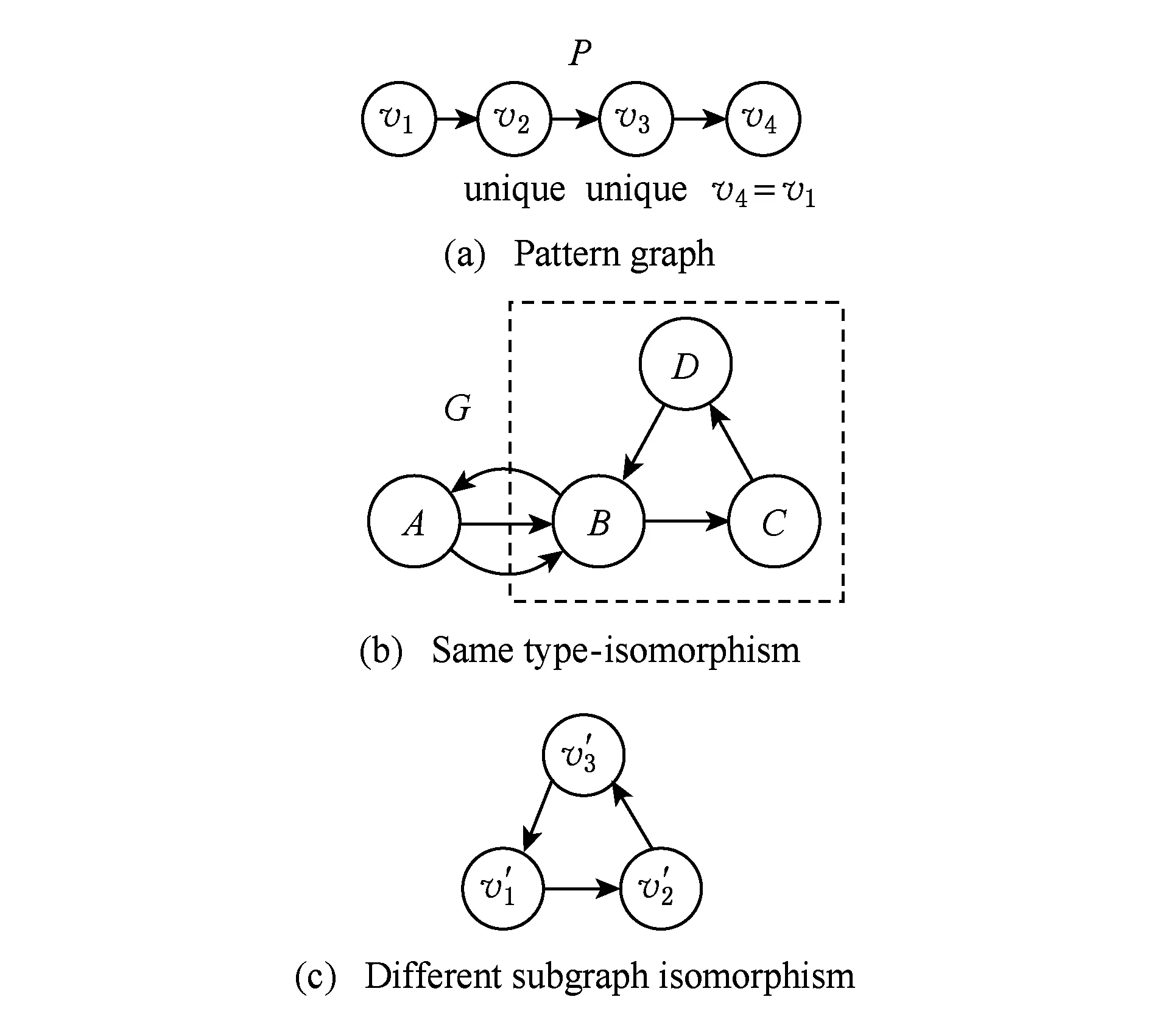
Fig. 4 Constrained type-isomorphism of P vertexes圖4 P的頂點增加約束的類型同構
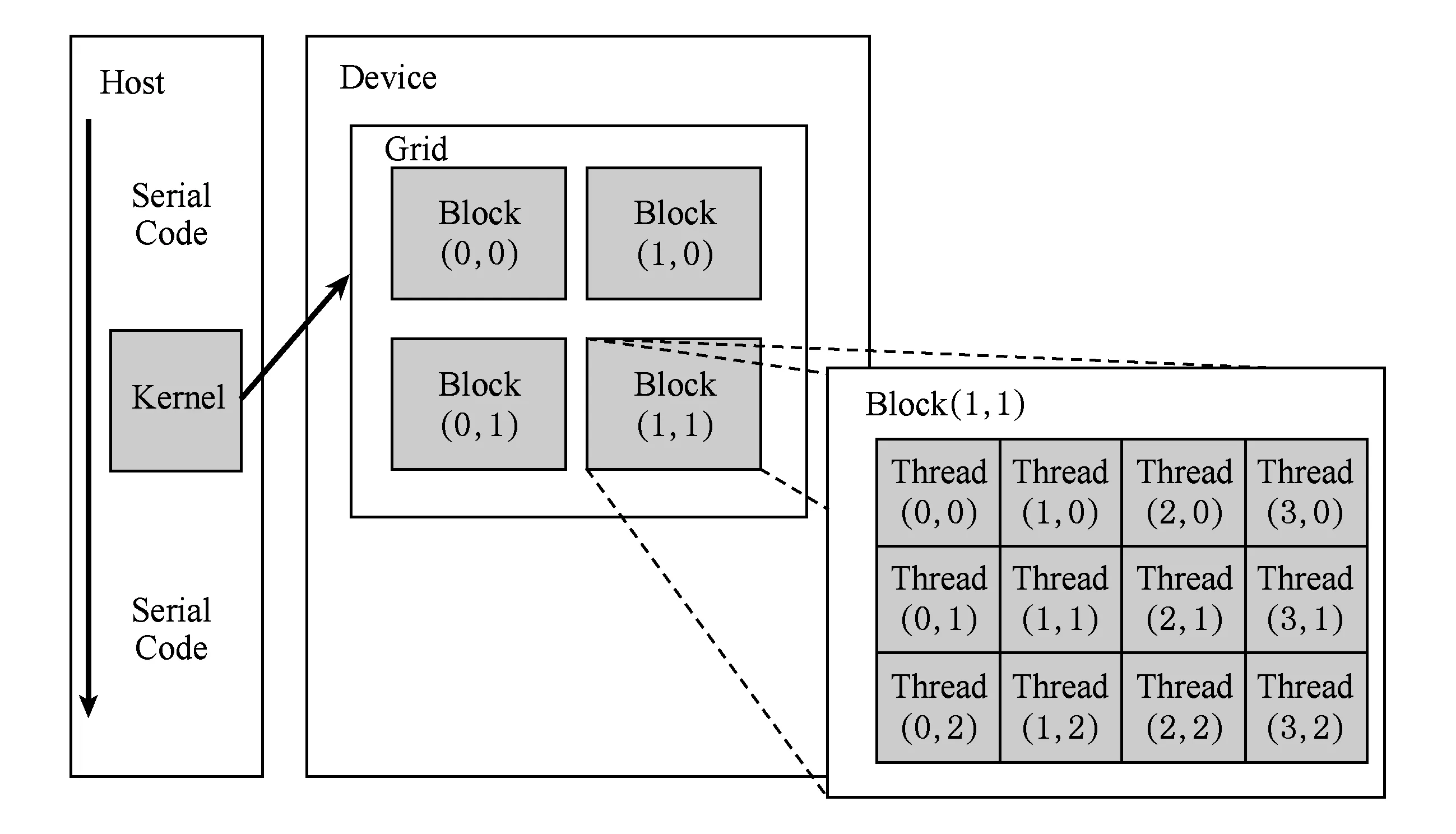
Fig. 6 Concurrent threads of GPU圖6 GPU的并發線程
1.3 GPU架構和CUDA編程模型
圖5所示為CPU與GPU架構示意圖.與CPU相比,GPU增多了算術邏輯單元(arithmetic and logic unit, ALU),使其更適用于規則結構、算法單一的數據處理.基于GPU的特征,本文設計了GPU多處理器的調度模型,以提高其計算性能.
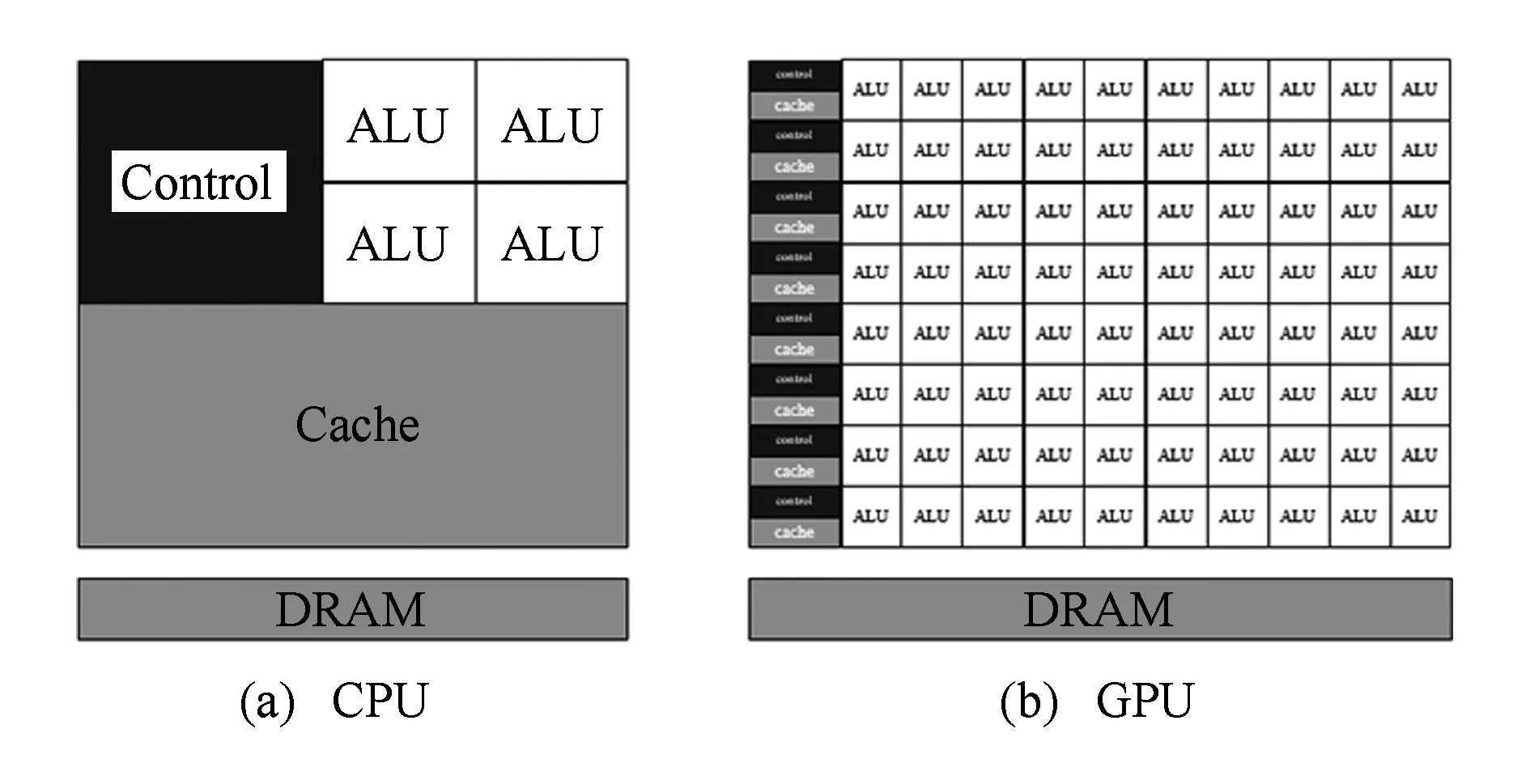
Fig. 5 Architecture of CPU and GPU圖5 CPU與GPU架構示意圖
GPU由許多單指令多數據流(single instruction multiple data, SIMD)處理器組成,支持數千個并發線程,如圖6所示為擁有GPU設備,Host為CPU控制端,Device為GPU設備端.Host端程序的執行按照串行代碼(serial code)運行,圖6左端箭頭指示了程序串行執行的時間順序.當內核(kernel)程序運行時,調用GPU進行計算,數以千計的GPU將同時進行計算,其組織形式如圖6所示.GPU線程具有低上下文切換和低創建線程時間的特點.GPU的線程被組織為線程組(thread group).同一個線程組中的所有線程共享計算資源,例如寄存器、緩存等.線程組被分為多個調度單元方便在多處理器上動態調度.GPU內存具有高帶寬和高訪問延遲等特點,這些優勢使GPU更適合于大規模RDF數據的并行計算.
CUDA(compute unified device architecture)是顯卡廠商NVIDIA推出的一款用于GPU并行編程的編程模型API(application programming interface).在CUDA中,并行工作負載以計算內核(kernel)的形式表示并提交到設備上執行.內核的構造方式提供了細粒度并行性.通常在主機的CPU上控制內核的提交和執行.每個線程被分配唯一標識符,并為它們安排調度順序.線程標識符常用于加載和存儲的內存偏移量的計算.主進程和計算單元之間的數據傳輸通過全局存儲器來完成,并且所有線程都有全局存儲器訪問權限.但是CUDA編程模型不提供計算單元的內存分配方法.這意味著在執行內核之前,主進程需要分配好所需的輸出緩沖區.
結合RDF數據和GPU計算能力的特征,本文主要涉及的是為內核計算的編碼和執行設計一個完善的GPU調度策略,并提出一種基于GPU的類型算法來提高部分基本圖模式的查詢效率.
2 相關工作
子圖同構是精確的圖匹配,是圖數據研究中的一個NP-完全(NP-complete)問題.近年來,子圖同構問題得到了廣泛的關注,很多研究人員嘗試了許多方法來解決通用圖中的子圖同構問題.1976年,Ullmann[6]第1次提出了實用的子圖同構的搜索算法.該算法基于回溯的思想,當部分解決方案可行時對其進行迭代直到找出完整的解決方案;如果發現部分解決方案不可行,則及時終止.目前,已有一些方法對Ullmann算法進行改進,例如VF2[7],QuickSI[8],GraphQL[9],GADDI[10],SPath[11]等.這些算法利用不同的連接順序、剪枝規則或輔助信息對候選集進行及時有效的剪枝篩選,從而減少連接操作的運算量,提高算法性能.但是,由于時間復雜度較高,這些算法不適用于大規模圖數據的應用場景.
為了加速在大規模圖或者多數量圖上的子圖同構操作,STwig算法[12]將查詢圖分解成一系列結構簡單的基本單元,這些基本單元能夠非常容易地在數據圖中完成匹配,但是將產生的局部結果組合在一起則需要高效的連接策略.呂雪棟等人[13]設計的FFD-Inde是建立一種新穎的索引算法來加速星形圖的查詢處理.在星形查詢中,這種方法在數據量巨大的情況下顯著地提高了查詢效率,但是星形查詢只是查詢圖的一部分,無法推廣到查詢圖的一般情況.基于類型同構的非精確子圖同構是由精確子圖同構問題的泛化引入的.這種方法比較新穎并且可以擴展到子圖同構問題.Berry等人[14]提出了基于類型同構的不精確的子圖同構問題.類型同構不需要像子圖同構一樣結構完全相同.根據RDF數據的特征,考慮利用頂點和邊的標簽的類型信息,將子圖同構問題轉化成為帶約束的不精確的類型同構問題.
近些年,圖形處理器GPU在并行處理方面取得了十分顯著的成績.由于計算能力強和便于編程,GPU已經逐漸發展成為用于通用計算中常用的協處理器[15].基于GPU的大規模并行處理框架已經成功應用于處理大規模圖上的基本圖操作,包括廣度優先搜索[16]、最短路徑[17]和最小生成樹[18].在RDF數據管理領域,Pan等人[19]率先在RDFS中明確提出計算量的工作負載的概念從而允許利用GPU的細粒度并行,并以此獲得性能的提高.該工作僅關注了RDFS推理的并行,沒有關注在底層數據查詢查詢處理的優化.Choksuchat等人[20-22]提出一種基于Jena的RDF處理系統,存儲結構使用基于Cassandra的Key-value結構和基于HDT的二進制三元組模式(binary triple pattern),并實現了基于JCuda語義查詢.Chantrapornchai等人[23]提出基于Bitstructure的修剪算法處理查詢并使用概要信息以減少數據讀取量的方法,以保證可擴展性和優化內存使用狀況.TripleID[24]是用于RDF查詢和推導處理的并行框架,它提供了一種新穎的壓縮RDF數據的文件格式,以通過GPU并行加速數據處理.Fu等人在2014年提出的MapGraph[25]是基于對PowerGraph’s Gather-Apply-Scatter(GAS)模型的修改而實現的.他們使用MapGraph實現了4種常見的圖形分析操作:寬度優先搜索(BFS),單源最短路徑(SSSP),連接組件(CC)和PageRank(PR).2015年,Yang等人[26]提出了在普通圖上進行并行處理子圖同構的GPU算法,但普通圖的規模有很大的局限性[27],例如語義信息含量少、節點數量少等[28],所以此方法并不適用于大規模的RDF數據[29].同樣,對于處理大規模的RDF數據的類型同構問題也沒有高效的基于GPU的求解方式.
這些方法的共同之處在于將RDF三元組進行編碼壓縮,并對其建立索引,以加速存儲查詢的過程.本文依據RDF圖數據的特性,提出一種基于類型同構的子圖匹配算法,以使GPU并行計算應用于在RDF圖處理,并提高子圖匹配的性能.
3 RDF類型同構算法
3.1 字典構建
本文選擇以串行的方式解析文件和預處理數據.依據RDF數據的特性,每個三元組元素都由主語、謂語和賓語3部分組成,并且每個元素都是字符串(string)值,例如URI(uniform resource identifier)或字符值.程序在內存中構造字典將所有字符串值轉化為整數值.這樣保證了每個值都是固定長度,方便后續程序對數據進行處理.同時,由于緩沖區需要在數據傳輸前進行分配,固定長度可以降低GPU調用的的復雜度,提高算法的性能.
字典是在CPU中動態構建的.本算法使用散列映射(Hash map)建造字典.散列映射是一個關聯容器,用于關聯Key類型的對象與Data類型的對象.散列映射中可以高速查找Key值元素,本算法利用這一優勢來查找字典中的無序三元組.字典可以簡便地加載到內存或存儲在磁盤文件中.在解析三元組時,主語和賓語均描述的是資源,算法對其進行相同的處理.謂詞作為資源的連接關系需要單獨處理,并將三元組擴展成了五元組G=(S,P,O,μ,σ).μ映射表示標簽值與每個頂點(即主語和賓語)的關系,σ映射表示標簽值與每個邊(即謂語)的關系.
3.2 基于GPU的類型同構算法
基本圖模式查詢是SPARQL查詢的基本形式和主要子集[19].SPARQL中的其他圖模式,如聯合模式(union graph pattern)、可選模式(optional graph pattern)等,都可以通過額外的代數運算轉換為基本圖模式.
由2.2節中描述的概念,類型同構根據已形成的游走路徑WP來訪問RDF中頂點和邊.理想情況下,查詢包含用作最小游走長度的歐拉路徑.如果查詢是可以由歐拉路徑構造的基本圖模式查詢,并且在頂點和邊添加標簽約束,那么類型同構的解就是基本圖模式查詢的解.但是在實際情況中,基本圖模式查詢都是有向無環圖.因此,查詢可能無法追蹤任何的滿足歐拉路徑的游走路徑而導致失敗.
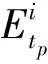
1) 基于GPU的并行映射算法.第2節中討論過GPU和CUDA編程模型的特性.由于GPU在代碼的執行期間不支持在設備上動態分配內存.所以需要利用設計好的數組結構在執行GPU程序之前為輸入數據和輸出結果分配空間.當GPU執行映射操作時,如果三元組滿足映射條件,則將候選三元組Etp放置在輸出緩沖器中;如果不滿足映射條件,則需要為輸出緩沖器設置額外的空間以存儲中間結果.因此,將所有數組結構中的元素初始設置為0,在緩沖區根據主語ID排序,以減少三元組主語ID的重復.
2) 基于GPU的連接算法.連接是將多個已匹配的局部匹配圖合并為完整匹配圖的操作.如果基本圖模式包含共享變量,那么就將映射的輸出直接傳遞到連接中.如果基本圖模式沒有共享變量,則無法進行接下來的連接操作.那么對于類型同構來說,如果2個匹配的三元組有1個共享變量,那么它們可以被合并成1個通路.
為了充分利用GPU并行的優點,連接過程包含3個階段:①并行映射;②按ID排序;③去重.在并行映射階段中,本算法根據共享變量在三元組中的位置設置標志以減少去重階段的冗余操作,而GPU的單指令多數據的體系架構特點也有助于加速笛卡兒乘積的平行化.
本文提出的算法請見算法1,是以初始化游走列表InitWalks開始,以選擇RDF數據圖中第1個可以與WP模式匹配的分段.從行②開始的循環,每次迭代都會通過匹配分段,進一步擴大候選集的游走長度的范圍.映射操作輸出分段并以頂點ID作為關鍵字(Key).行③說明了匹配的實現,并且本算法使用雙調排序法(bitonic sort)對映射操作的結果進行并行排序.其作用是通過共享變量頂點的關鍵字對游走的候選集進行排序.算法1的其余部分是通過對計算笛卡兒積而實現去重操作.算法1通過1次迭代WP的一個分段以構建與該分段匹配的所有游走的候選集.顯然,生成結果中完整長度的有向路徑的集合即是所有類型同構游走的結果集合,也就是在RDF數據圖中完成了類型同構的匹配過程.
算法1. 基于GPU的類型同構算法.
輸入:RDF數據圖中所有三元組模式的集合S、將圖分段成k個有序列表TP;
輸出:在RDF中完成匹配的集合R.
① InitWalks:接收S和TP從S中讀取分段s;
② ifs能夠匹配WP中的第1個分段(S1,P1,O1)
③ 將S添加入candidate walk為1的候選集中;
④ ExtendWalks:
⑤ for每一個Key值小于k的記錄do
⑥ 從S中讀取另一個分段s.如果它能夠匹配WP中的第1個分段(St,Pt,Ot),將s添加入游走長度為t的候選集中,并從最近訪問的候選集中讀取candidate walk;
⑦ end for
⑧ 使用雙調排序發對candidate walk進行并行排序;
⑨ for每個定點do
⑩ whileCandWalkList的每個成員
4 實驗設計和性能分析
本節在GPU架構上實現了RDF圖上的類型同構算法,并對其進行了性能測試.經過與CPU架構下的類型同構算法的效率對比,并將gStore中基于子圖同構的方法與本文中的算法進行比較,證明了GPU架構解決類型同構問題的效率優于CPU架構,進一步說明GPU在解決RDF數據查詢問題上具有突出的性能.
4.1 CPU與GPU的比較實驗
1) 實驗環境和數據集
本實驗平臺的配置為NVIDIA GTX590 1.35 GHz GPU的顯卡和運行英特爾?Core(i)i7-26 001.35 GHz的4核處理器.操作系統版本為Linux Ubuntu 14.04,內存大小為2 GB,GPU的設備內存為1 536 MB.GPU使用PCI-E3.0總線在主存儲器和設備存儲器之間進行數據傳輸數據,其傳輸帶寬為4 GB/s.
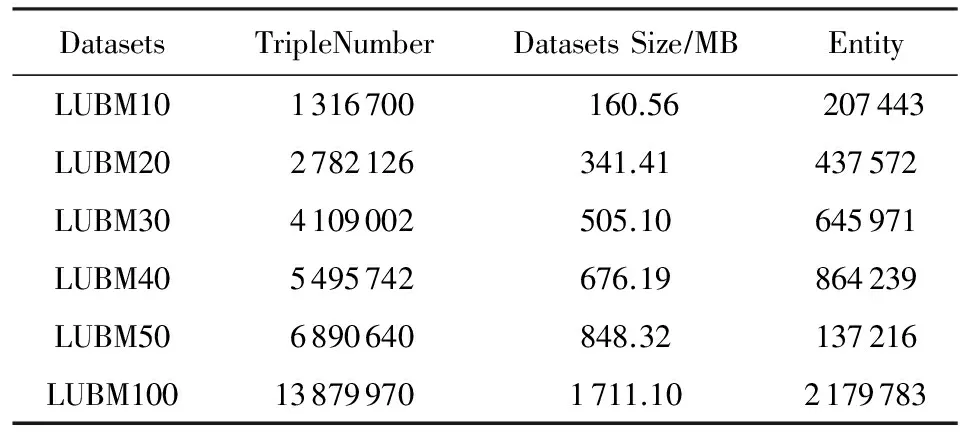
實驗采用LUBM(Lehigh University Bench-mark)數據集.LUBM是一個采用大學領域內本體的基準,可以生成任意大小的OWL數據類型.這些數據中包含了教師、學生、課程等信息之間的關聯信息.由于本算法關注的是RDF數據的圖匹配問題,需要對產生的OWL數據進行預處理,將其轉化為系統處理所需的RDF三元組格式.本實驗選取了7個不同規模的LUBM數據集來測試算法的性能.表1詳細描述了這7個數據集的數據特征和規模.為了對本文提出的算法進行測試與分析,本實驗選取了2種查詢方案,如表2所示.
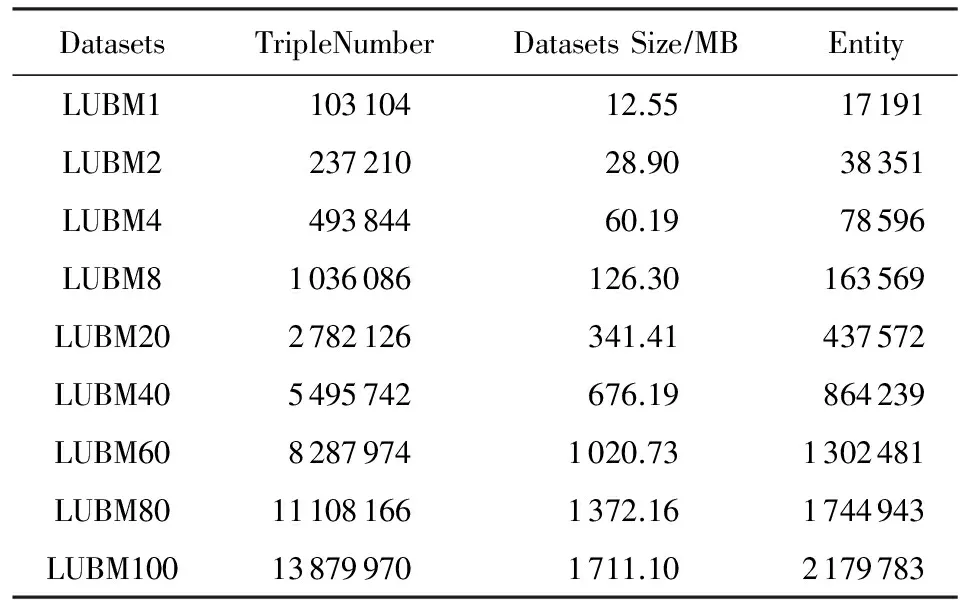
Table 1 LUBM Datasets of Experiment表1 實驗使用LUBM數據集

Table 2 Benchmark Test Queries表2 基準測試查詢語句
2) CPU與GPU實驗結果和分析
本文選取了LUBM查詢中具有代表性的查詢語句作為實驗的基準測試查詢,分別對7個不同規模的數據集上進行測試,以比較相同環境下CPU和GPU的性能.表3和表4中分別記錄了每個查詢僅使用CPU計算單元計算類型同構匹配算法的響應時間、使用基于GPU計算單元加速類型同構匹配算法的查詢響應時間、以及它們之間的加速比.表3和表4中的查詢響應時間均為多次測試后的平均響應時間.本實驗所測試的算法查詢響應時間僅包括從用戶提交查詢到查詢結束之間的時間,不包括數據的載入時間和數據IO的傳輸時間.

Table 3 Query Response Time of Q1 over LUBM Datasets表3 Q1在LUBM數據集上的查詢響應時間 ms
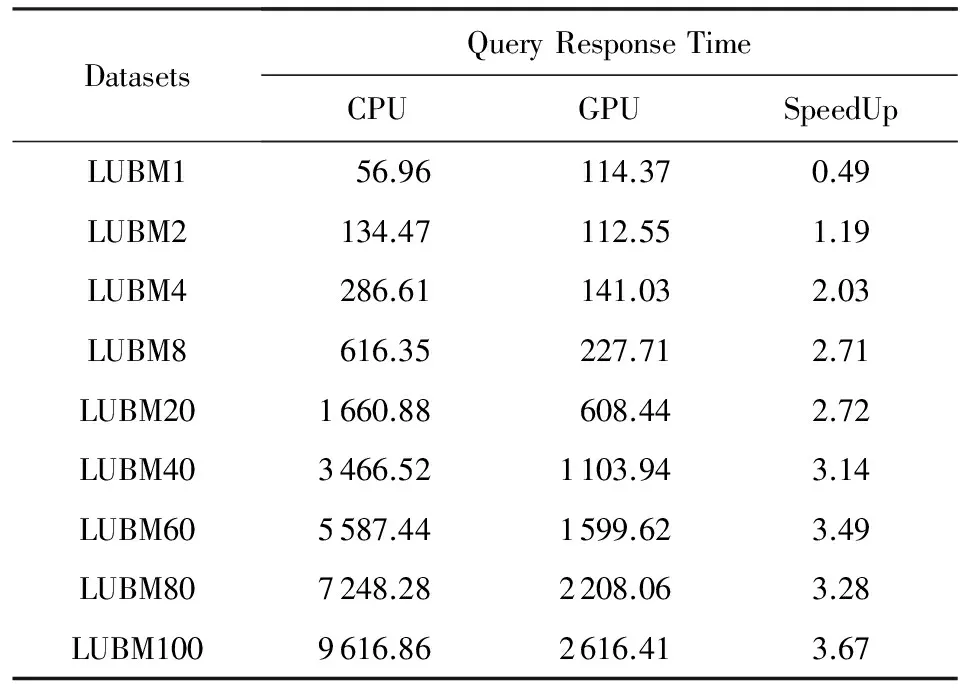
Table 4 Query Response Time of Q2 over LUBM Datasets表4 Q2在LUBM數據集上的查詢響應時間 ms
圖7(a)為查詢Q1在不同規模LUBM數據集上的查詢響應時間,圖7(b)為基于CPU的查詢響應時間與基于GPU查詢的加速比.圖8則分別為查詢Q2在不同規模LUBM數據集上的查詢響應時間和基于CPU的查詢響應時間與基于GPU的加速比.
由實驗結果分析,在數據量較少的情況下,例如LUBM1,本算法的查詢響應時間與基于CPU的算法的時間近似.原因是在初始化時CPU調用GPU進行數據分配調用的過程需要額外耗費一定通信代價.但是隨著數據集的不斷增大,由于GPU并行計算能力強,GPU的查詢響應時間遠遠低于CPU的運行時間.圖7和圖8所示,隨著數據量的不斷增大,GPU的查詢響應時間明顯低于CPU.且CPU和GPU的加速比隨著數據量的增大而逐漸上升,最后穩定在3倍左右.說明在類型同構并行算法中,GPU的查詢效率遠高于CPU.
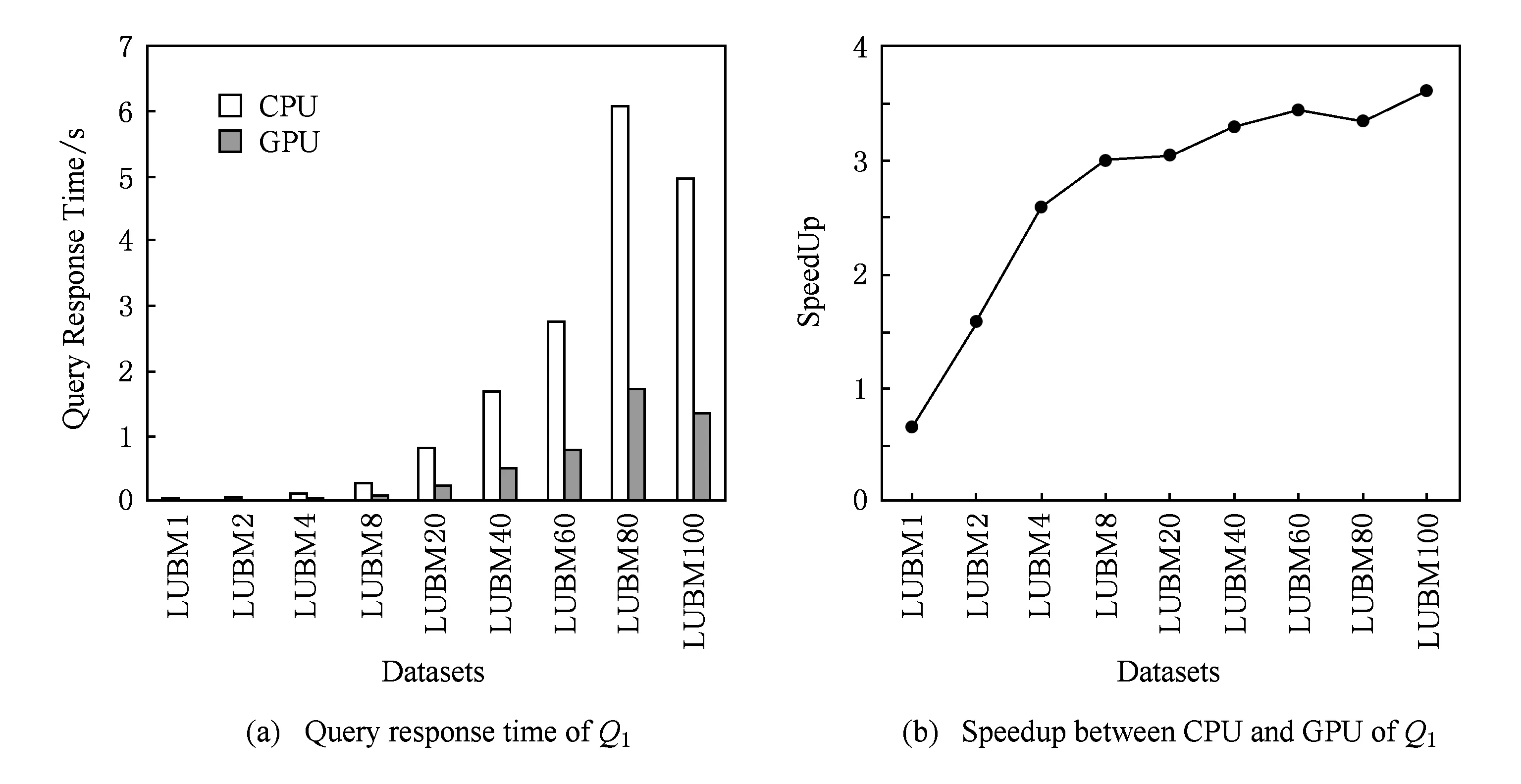
Fig. 7 Query response time and speedup between CPU and GPU of Q1圖7 Q1的查詢響應時間及CPU與GPU運算的加速比
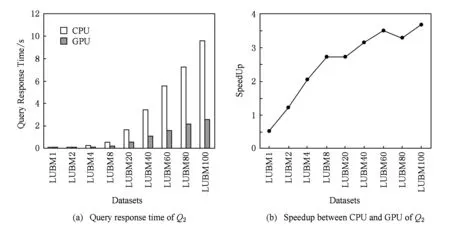
Fig. 8 Query response time and speedup between CPU and GPU of Q2圖8 Q2的查詢響應時間及CPU與GPU運算的加速比
對比實驗結果數據,本文提出的基于GPU的RDF類型同構的并行算法性能顯著高于CPU處理的性能.
4.2 類型同構與子圖同構算法比較結果和分析
1) 實驗環境和數據集
本實驗平臺的配置有NVIDIA Tesla M40 GPU的顯卡和運行英?Xeon?E5-2603 v4 1.7 GHz的6核處理器.操作系統版本為Linux Ubuntu 14.04 Server,內存大小為8 GB,GPU的設備內存為24 GB.本實驗使用數據集及查詢語句如表5和表6所示.
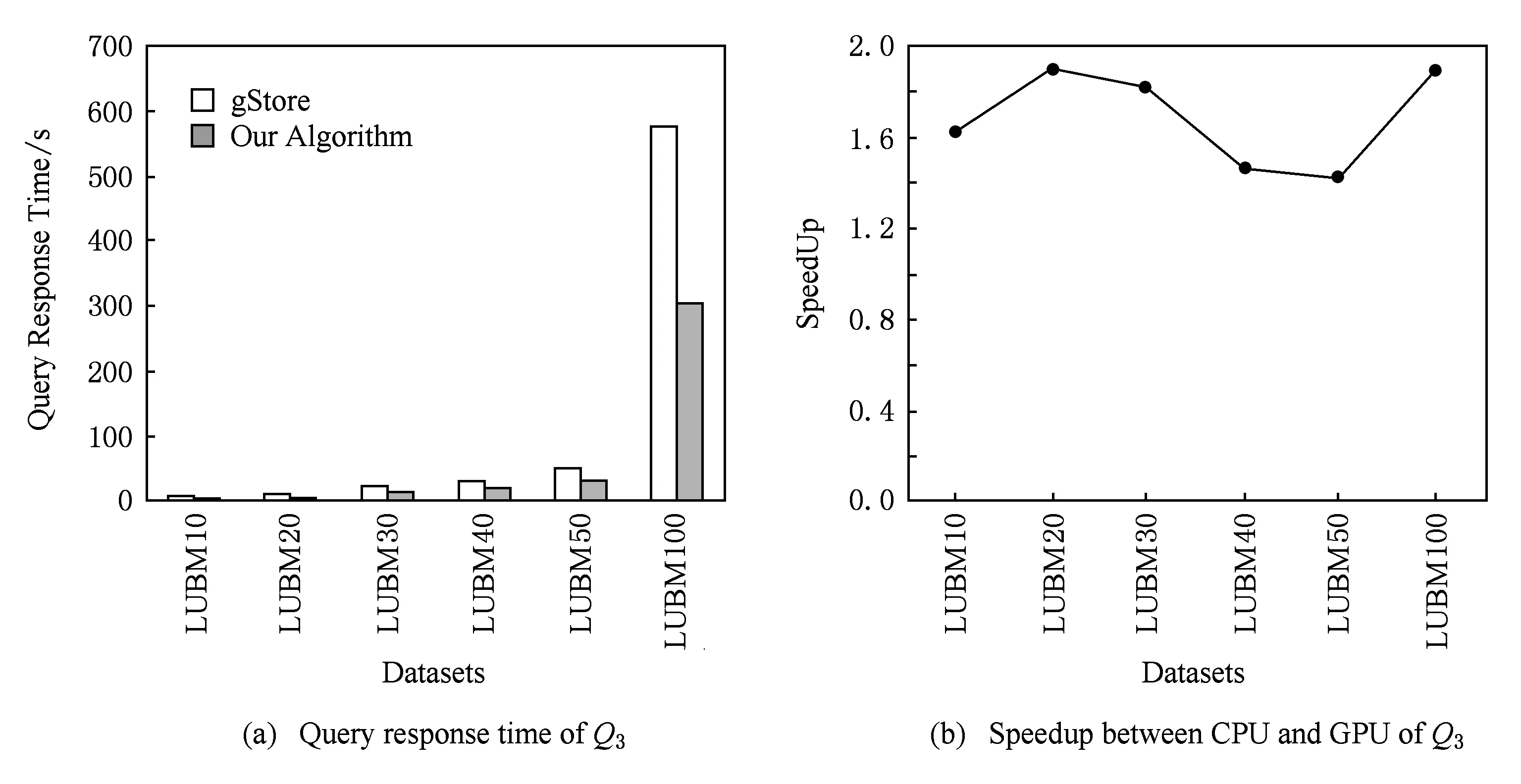
Fig. 9 Query response time and speedup between CPU and GPU of Q3圖9 Q3的查詢響應時間及CPU與GPU運算的加速比
DatasetsTripleNumberDatasetsSize∕MBEntityLUBM101316700160.56207443LUBM202782126341.41437572LUBM304109002505.10645971LUBM405495742676.19864239LUBM506890640848.32137216LUBM100138799701711.102179783

Table 6 Benchmark Test Queries表6 基準測試查詢語句
為了與4.1節中實驗區分,本文選取了LUBM查詢中的較為復雜的查詢語句(作為實驗的基準測試查詢,分別對8個不同規模的數據集上進行測試.比較相同環境下基于子圖同構的RDF數據查詢引擎與本文所提算法性能.
2) CPU與GPU實驗結果和分析
本文選取了LUBM查詢中具有代表性的查詢語句作為實驗的基準測試查詢,分別對7個不同規模的數據集上進行測試.
表7和表8中的記錄了Q3和Q4的查詢響應時間與加速比.并在圖9和圖10中以圖表形式分別進行展示.
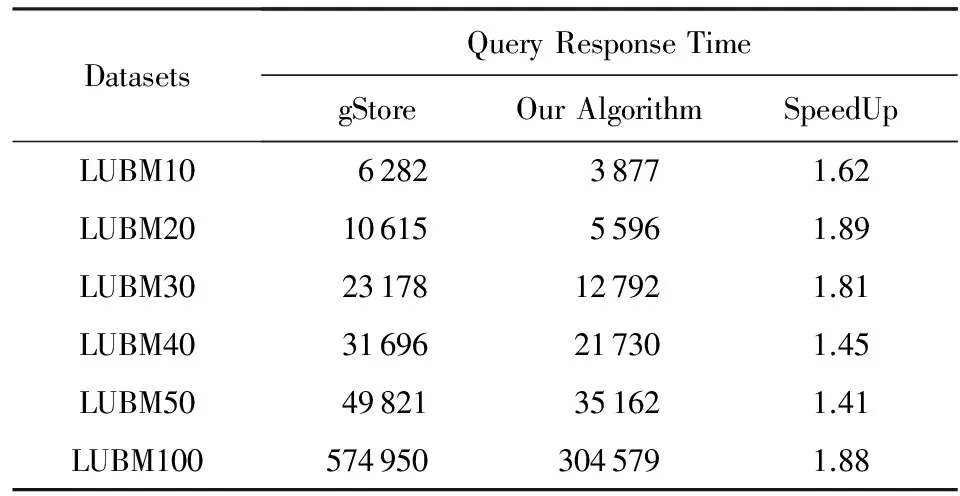
Table 7 Query Response Time of Q3 over LUBM Datasets表7 Q3在LUBM數據集上的查詢響應時 ms
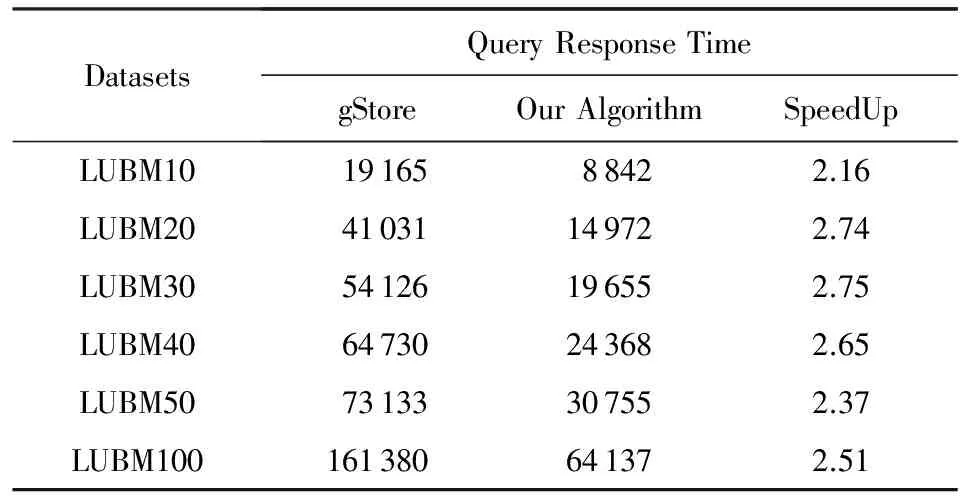
Table 8 Query Response Time of Q4 over LUBM Datasets表8 Q4在LUBM數據集上的查詢響應時間 ms
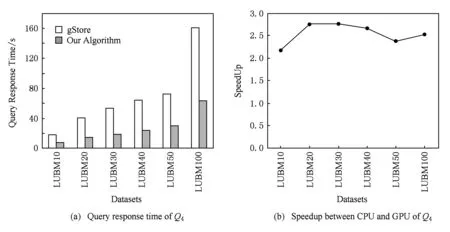
Fig. 10 Query response time and speedup between CPU and GPU of Q4圖10 Q4的查詢響應時間及CPU與GPU運算的加速比
由圖表分析所得,本實驗所提方案與目前性能較好的集中式查詢引擎gStore進行比較.與gStore相比,Q3的加速比約在1.4~1.9倍,本算法查詢響應時間僅為其響應時間的1/2左右.Q4的加速比約在2.1~2.7倍,本算法查詢響應時間僅為其響應時間的1/3左右.本算法總體性能提高了1.4~2.7倍.隨著數據量的增大,本實驗所提方案提升的性能顯著.
經過查詢對比發現,本算法在包含鏈狀的查詢(如Q1和Q4),展現了良好的性能.但是在只含有星狀查詢(如Q3)中,其查詢性能則略低于包含鏈狀的查詢.結合本文的理論基礎分析,算法在星狀查詢中展開成k邊游走的過程中可能導致邊的重復遍歷,因而導致了算法的性能有所下降.
通過對比實驗,本文提出的基于GPU的RDF類型同構的并行算法性能顯著高于基于CPU的RDF子圖同構的處理方法.
5 總 結
依據RDF圖本身的數據特征,傳統的子圖同構的問題可以用來解決SPAQRL中基本圖模式查詢問題.本文基于IRSMG的方法和理論,提出了一種基于GPU的RDF類型同構并行算法,以高效地完成基本圖模式查詢,減少查詢響應時間.本文通過研究約束的類型同構問題,將問題引申至RDF圖的模式匹配和查詢.通過設置游走等級的方法,對滿足查詢圖標簽的頂點進行遍歷檢查,確定后續查找范圍.最后得到每個三元組模式的局部解,使用GPU并行的進行連接操作.因此最大程度利用了GPU的計算能力,使基本圖模式查詢性能有了顯著的提高.
盡管本工作研究的問題僅限于基本圖模式查詢,但是其性能優于CPU的處理方式.這為以后RDF數據處理的發展提供了新的思路.由于現在本文所提出的算法僅能支持部分基本圖模式,例如涉及星狀和鏈狀的查詢,對于包含環狀的查詢則體現了較為一般的性能.因此如何將本算法的思想推廣到基本圖模式一般情況將是本文后續工作.
[1] Mcbride B. Jena: Implementing the RDF model and syntax specification[C] //Proc of the 5th ISWC’01. New York: ACM, 2001: 23-28
[2] Neumann T, Weikum G. RDF-3X: A RISC-style engine for RDF[J]. VLDB Journal, 2008, 1(1): 647-659
[3] Zou Lei, ?zsu M, Chen Lei, et al. gStore: Answering SPARQL queries via subgraph matching[J]. VLDB Journal, 2014, 23(4): 565-590
[4] Pérez J, Arenas M, Gutierrez C. Semantics and Complexity of SPARQL[M]. Berlin: Springer, 2006: 1-45
[5] Zhang Junzhao, Zhang Bingyi, Zhang Xiaowang, et al. IRSMG: Accelerating inexact RDF subgraph matching on the GPU[C] //Proc of ISWC’16. Berlin: Springer, 2016
[6] Ullmann J. An algorithm for subgraph isomorphism[J]. Journal of the ACM, 1976, 23(1): 31-42
[7] Cordella L, Foggia P, Sansone C, et al. A (sub) graph isomorphism algorithm for matching large graphs[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2004, 26(10): 1367-1372
[8] Shang Haichuan, Zhang Ying, Lin Xuemin, et al. Taming verification hardness: An efficient algorithm for testing subgraph isomorphism[J]. VLDB Journal, 2008, 1(1): 364-375
[9] He Huahai, Singh A. Graphs-at-a-time: Query language and access methods for graph databases[C] //Proc of ICDM’08. New York: ACM, 2008: 405-418
[10] Zhang Shijie, Li Shirong, Yang Jiong. GADDI: Distance index based subgraph matching in biological networks[C] //Proc of EDBT’09. New York: ACM, 2008: 405-418
[11] Zhao Peixiang, Han Jiawei. On graph query optimization in large networks[J]. VLDB Journal, 2010, 3(1-2): 340-351
[12] Sun Zhao, Wang Hongzhi, Wang Haixun, et al. Efficient subgraph matching on billion node graphs[J]. VLDB Journal, 2012, 5(9): 788-799
[13] Lyu Xuedong, Wang Xin, Li Yuanfang, et al. FFD-Index: An efficient indexing scheme for star subgraph matching on large RDF graphs[G] //LNCS 9052: Proc of Database Systems for Advanced Applications. Berlin: Springer, 2015: 240-245
[14] Berry J, Hendrickson B, Kahan S, et al. Software and algorithms for graph queries on multithreaded architectures[C] //Proc of IPDPS’07. Los Alamitos, CA: IEEE Computer Society, 2007: 1-14
[15] Xu Xinhai, Lin Yufei, Yi Wei. A survey of techniques of CPU-GPGPU heterogeneous architecture[J]. Computer Engineering & Science, 2009, 31(S1): 24-26 (in Chiness)
(徐新海, 林宇斐, 易偉. CPU-GPGPU異構體系結構相關技術綜述[J]. 計算機工程與科學, 2009, 31(S1): 24-26)
[16] Merrill D, Garland M, Grimshaw A. Scalable GPU graph traversal[J]. ACM Sigplan Notices, 2012, 47(8): 117-128
[17] Katz G, Kider J. All-pairs shortest-paths for large graphs on the GPU[C] //Proc of GH’08. New York: ACM, 2008: 47-55
[18] Vineet V, Harish P, Patidar S, et al. Fast minimum spanning tree for large graphs on the GPU[C] //Proc of HPG’09. New York: ACM, 2009: 167-171
[19] Heino N, Pan J. RDFS Reasoning on massively parallel hardware[G] //LNCS 7649: Proc of ISWC’12. Berlin: Springer, 2012: 133-148
[20] Choksuchat C, Chantrapornchai C. Large RDF representa-tion framework for GPUs case study key-value storage and binary triple pattern[C] //Proc of ICSEC’2013. Piscataway, NJ: IEEE, 2013: 13-18
[21] Choksuchat C, Chantrapornchai C. Experimental framework for searching large RDF on GPUs based on key-value storage[C] //Proc of JCSSE’13. Piscataway, NJ: IEEE, 2013: 171-176
[22] Choksuchat C, Chantrapornchai C. On the HDT with the tree representation for large RDFs on GPU[C] //Proc of the 19th ICPADS’13. Los Alamitos, CA: IEEE Computer Society, 2013: 651-656
[23] Chantrapornchai C, Choksuchat C, Haidl M, et al. Entailment processing for large RDF data sets using GPU[C] //Proc of SoMeT’16. Clifton, NJ: IOS, 2016: 333-345
[24] Haidl M, Gorlatch S. TripleID: A low-overhead represen-tation and querying using GPU for large RDFs[C] //Proc of BDAS’16. Berlin: Springer, 2016: 400-415
[25] Fu Zhisong, Personick M, Thompson B. MapGraph: A high level API for fast development of high performance graph analytics on GPUs[C] //Proc of GRADES’14. New York: ACM, 2014: 1-6
[26] Yang Bo, Lu Kai, Gao Yinghui, et al. GPU acceleration of subgraph isomorphism search in large scale graph[J]. Journal of Central South University, 2015, 22(6): 2238-2249
[27] Fu Lizhen, Meng Xiaofeng. Reachability indexing for large-scale graphs: Studies and forcasts[J]. Journal of Computer Research and Development,2015, 52(1): 116-129 (in Chiness)
(富麗貞, 孟小峰. 大規模圖數據可達性索引技術:現狀與展望[J]. 計算機研究與發展, 2015, 52(1): 116-129)
[28] Zou Lei, Peng Peng. A survey of distributed RDF data management[J]. Journal of Computer Research and Development, 2017, 54(6): 1213-1224 (in Chiness)
(鄒磊, 彭鵬. 分布式RDF數據管理綜述[J]. 計算機研究與發展, 2017, 54(6): 1213-1224)
[29] Li Jianhui, Shen Zhihong, Meng Xiaofeng. Scientific big data management: Concepts, technologies and system[J]. Journal of Computer Research and Development, 2017, 54(2): 235-247 (in Chiness)
(黎建輝, 沈志宏, 孟小峰. 科學大數據管理: 概念、技術與系統[J]. 計算機研究與發展, 2017, 54(2): 235-247)
