基于HBase的心電信號存儲系統的研究與實現
2018-03-14 10:21:20王利琴高衛香蘭軍翟艷東
現代計算機 2018年4期
王利琴,高衛香,蘭軍,翟艷東
(河北工業大學計算機科學與軟件學院,天津 300401)
0 引言
根據《中國心血管報告2016》[1]的統計結果,心血管疾病的死亡高居我國城鄉居民死亡原因首位。隨著心臟病、高血壓、糖尿病等慢性疾病的死亡率不斷飆升,越來越多的人面臨健康的威脅。同時隨著通信網絡技術和傳感器技術的發展,來自醫院的傳統心電檢查數據以及來自移動終端等設備的心電數據(ECG,Electro?cardiogram)呈指數級增長、復雜程度增大,逐步構成了心電大數據。如果能對這些數據進行分析挖掘,發現潛在的心臟疾病,并在發作前提供預警,則將大大降低病人的致死率及醫療成本,同時為醫護人員的臨床實踐提供參考。因此構建心電數據的存儲平臺,實現心電數據的共享,為心臟疾病的診斷提供支撐具有重要的現實意義。
Hadoop作為分布式的存儲平臺,已有不少文獻將其應用到了心電信號的存儲領域。文獻[2]提出了一種基于HBase的心電信號存儲架構,并利用MapReduce編程框架實現對信號處理的方案,該方案在存儲系統滿足數據輸入和輸出響應需求的同時很容易地將計算并行化,從而解決了當前各類由于傳感器和其他監測終端產生的結果數據越來越多,存儲計算需求越來越高的需求。文獻[3]基于Hadoop和HBase技術構建心電數據庫,并對數據庫的存儲時間、訪問時間做了測試,實驗表明基于Hadoop和HBase構建的心電信號存儲系統具有較高的可靠性,可以滿足心電數據的存儲要求。但文獻中只分析了數據的存儲時間、查詢時間,并沒有給出具體的存儲系統架構。本文將從分布式存儲系統設計的角度,詳細給出存儲系統設計的系統結構,數據存儲流程以及HBase表結構設計及主鍵設計。
1 相關技術
1.1 Hadoop
Hadoop[4]由Hadoop分布式文件系統(Hadoop Dis?tributed File System,HDFS)和MapReduce編程框架組成,是一個提供分布式存儲和計算能力的主從架構平臺。HDFS與傳統的分布式系統不同,傳統的分布式系統需要在客戶端和服務器之間重復傳輸數據,這對計算密集型的工作很適用,但對大數據處理,由于數據變得太大,對其進行移動已變得不可實現。Hadoop實現了移動計算而非移動數據,主節點(NameNode)只發送要執行的MapReduce程序到從節點(DataNode)上,而且這些程序通常很小(通常是千字節),集群的帶寬完全可以滿足。同時,集群中的數據被分解并分布在集群中的所有數據節點上,并且計算盡可能多地在同一臺機器上的數據塊進行。
1.2 MapReduce
MapReduce[5]是一種編程模型,廣泛應用于大數據的并行處理。MapReduce由Map函數和Reduce函數具體執行,Map函數對輸入的數據進行切分,并輸出鍵值對形式的中間結果,Reduce函數合并具有相同鍵的多個不同的值,形成一個鍵值對的集合。它只專注于計算,而不必關心數據,使得基于MapReduce的編程更易實現。此外,由于大多數計算都是在存儲數據副本的從節點上完成的,這使得在網絡上傳輸的數據量較小,從而提高了整體計算效率。
1.3 HBase
HBase[6]是運行在HDFS之上的分布式列存儲數據庫,它基于Google BigTable并支持MapReduce編程模型,提供了方便的、隨機訪問數據的方法。作為一種NoSQL數據庫,HBase對表、行和列的定義與傳統的關系數據庫不同,它的數據模型主要包含如下幾個部分:
表:Hbase用表存儲數據。
行:行由一個可排序的行鍵(rowkey)唯一標識。
列族:列族需事先定義,每行的數據按照列族分組存儲。
列修飾符:列修飾符也就是列,列族里的數據通過列定位。每行有相同的列簇,但是在行之間,相同的列簇不需要有相同的列。
單元:行鍵、列族和列修飾符一起確定一個單元。
HBase在數據存儲和操作方面比傳統的關系數據庫管理系統具有巨大的優勢。因此,采用HBase設計數據存儲模型,使其能夠滿足高并發性、海量存儲和高擴展性等需求[7]。
2 基于大數據分布式平臺的心電信號存儲系統設計
2.1 基于Hadoop的存儲平臺設計
基于Hadoop平臺的分布式特性,本文構建的心電大數據處理存儲平臺如圖1所示,由Hadoop、Zookeep?er和HBase構建。在這個平臺中,Hadoop提供基本的分布式存儲和處理功能,Zookeeper協調應用程序并管理相關配置,HBase存儲ECG信號數據。
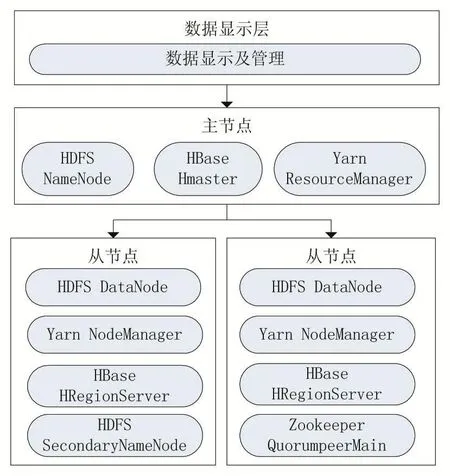
圖1 心電大數據存儲平臺設計
2.2 數據存儲流程
心電大數據存儲系統不僅存儲由各類傳感器和醫療設備采集的實時心電數據,而且也要存儲已有的數據,用于數據和疾病預測的相關分析等場合。因此,對大數據存儲系統來說,要分離線存儲和在線存儲兩個過程,如圖2所示。
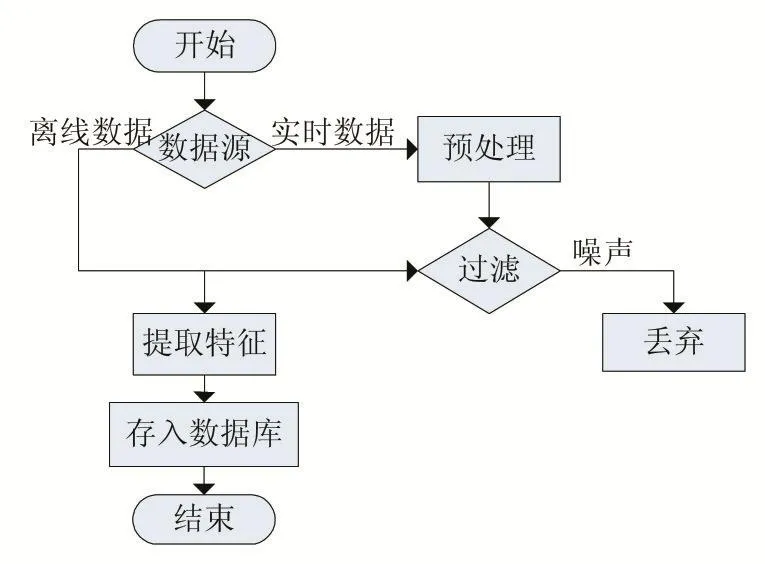
圖2 心電大數據存儲流程
2.3 表結構設計
考慮到HBase在存儲數據時,不同的列族存儲在不同的文件中。同時當某個列族在flush的時候,與它鄰近的列族也會因關聯效應被觸發flush,最終導致系統產生更多的I/O。因此,本文在設計存儲數據表時,只設計一個列族,以心電數據存儲表為例,只包含一個列族ECG,包含如下列:
文件名:心電數據作為時間序列數據,為更好的對其實施管理,需將其按照固定時間進行截取,存為一個文件。
文件存儲路徑:數據實際在HDFS上的存儲位置。
信號特征:在分析心電圖時,需要用到ECG數據的特征參數,如QRS持續時間、R波振幅、ST段振幅、ST段斜率、ST段位移、PR間期、QT間期以及由特征提取算法提取到的其他特征值。通過分析這些特征參數,應用程序可以找到各種參數與疾病之間的相關關系。
疾病類別:在心電數據存入數據庫之前,基于提取到的信號特征采用某種分類方法將其大致進行分類。
用戶屬性:心電數據對應的患者相關的一些數據,如患者的病史、生活方式、性別、年齡、服藥歷史等屬性,這些屬性往往也與疾病存在著相關關系。
2.4 行主鍵設計
HBase只提供了行級索引,因此為實現多條件查詢,需要設計合適的行主鍵。本文選擇用戶id和疾病id聯合作為行主鍵。同時為避免region的熱點問題,充分利用集群分布式的特性,將用戶id倒序。
3 實驗及結果
3.1 實驗環境及數據集
測試硬件環境為在1臺服務器構建分布式Hadoop集群,集群包含1個主節點,4個從節點,用到的各軟件版本分別為 Hadoop2.6.2、Zookeeper3.4.6、HBase1.2.6,操作系統均為64位CentOS 6.5。服務器的硬件配置如下:
處理器:英特爾·至強·E5-2600V4處理器;
磁盤:600GB;
內存:32GB;
本文采用的心電數據庫如表1所示,共包含來自三個數據集的263個心電信號文件,共約10.2G的數據。其中European ST-T數據集包含90個30分鐘的心電記錄文件,Long-Term AF包含84個21小時的心電記錄文件,Long-Term ST包含89個24小時的心電記錄文件。
3.2 數據寫入性能
因ECG數據是從5KB到100MB的不等的文件,為考察心電存儲平臺數據的導入性能,需事先對ECG文件進行預處理,根據采樣頻率按照每分鐘的時長將原始文件切分成同樣的長度,各數據集含有的記錄條數如表1所示,共236700條記錄。將數據分別寫入到本文構建的存儲平臺和MySQL數據庫中,每秒記錄一次寫入的記錄條數,實驗進行10次,取平均值,實驗結果如圖3所示。實驗結果表明:HBase數據的寫入性能總體優于MySQL寫入性能。HBase隨著寫入記錄數的增加,數據寫入性能總體平穩,最快寫入速度19813條/秒。
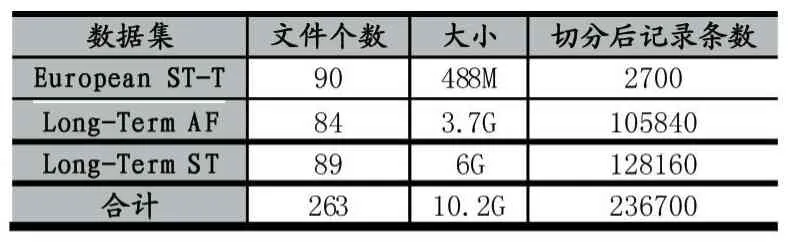
表1 實驗數據集
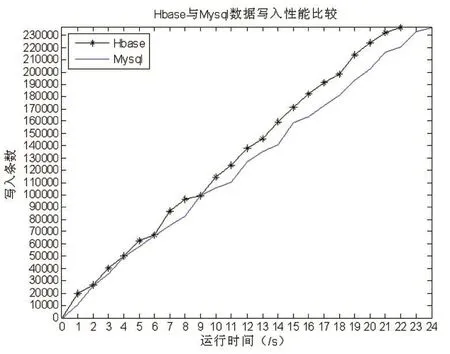
圖3 HBase與MySQL數據寫入性能比較
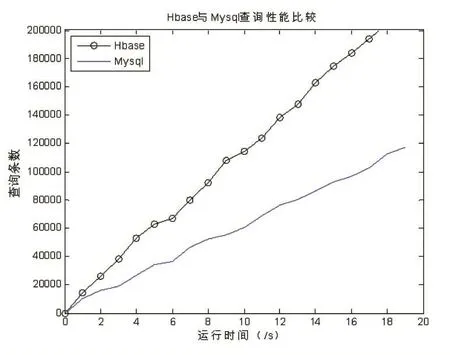
圖4 HBase與MySQL數據查詢性能比較
3.3 數據查詢性能
按照行鍵的設計,設計三種查詢測試用例,包含只按照用戶id查詢、只按照疾病id查詢和用戶id和疾病id組合查詢,每個用例一共執行10次后取均值,結果如圖4所示。實驗結果表明,HBase的查詢性能總體優于MySQL,最快查詢速度15805條/秒,數據檢索結果返回時效達到毫秒級,能夠滿足業務應用中對心電信號存儲和檢索時效的要求。
4 結語
針對關系型數據庫對心電數據的存儲及檢索效率低的問題,通過對HBase中相關表的結構及行鍵設計,建立了基于HBase的分布式存儲與處理系統,使實時采集和監控心電數據成為可能。系統中關鍵技術是基于MapReduce的并行數據導入。實驗驗證了該方案相對于MySQL具有較高的存儲效率和查詢速度,能夠滿足業務中的時效性要求。
[1]http://news.medlive.cn/heart/info-progress/show-129366_129.html
[2]Nguyen AV,Wynden R,Sun Y:HBase,MapReduce,and Integrated Data Visualization for Processing Clinical Signal Data.In AAAI Spring Symposium:Computational Physiology:2011.
[3]熊艷,陳宇,蔣文濤等.基于Hadoop的心電數據庫存儲研究[J].生物醫學工程研究,2016,35(3):175-177.
[4]Shvachko K,Kuang H,Radia S,Chansler R:The Hadoop Distributed File System.In Mass Storage Systems and Technologies(MSST),2010 IEEE 26th Symposium on:2010,IEEE;2010:1-10.
[5]K.C.Wee and M.S.M.Zahid.Auto-tuned Hadoop MapReduce for ECG Analysis.2015 IEEE Student Conference on Research and Development(SCOReD),Kuala Lumpur,2015:329-334.
[6]張智,龔宇.分布式存儲系統HBase關鍵技術研究[J].現代計算機,2014(11):33-37.
[7]R.C.Taylor.An overview of the Hadoop/MapReduce/HBase Framework and Its Current Applications in Bioinformatics.J.BMC Bioinformatics,2010.
猜你喜歡
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
財經(2017年15期)2017-07-03 22:40:49
Coco薇(2017年5期)2017-06-05 08:53:16
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
