基于語義分割的增強現(xiàn)實圖像配準技術(shù)
2018-02-28 09:38:04卞賢掌費海平李世強
電子技術(shù)與軟件工程 2018年23期
關(guān)鍵詞:深度學習
卞賢掌 費海平 李世強


摘要
增強現(xiàn)實(AR)通過分析場景特征,將計算機生成的幾何信息通過視覺融合方法添加到真實環(huán)境中,以增強對環(huán)境的感知。其中圖像配準技術(shù)是AR技術(shù)的核心問題之一,即在三維環(huán)境中估計視覺傳感器的姿態(tài)并理解場景中的對象。近年來,計算機視覺領(lǐng)域取得了巨大的進步,但是AR系統(tǒng)在三維場景中基于自然特征點的配準技術(shù)仍然是一個嚴重的挑戰(zhàn)。由于不穩(wěn)定因素的影響,在三維場景中精確計算移動相機的姿態(tài)還存在較大的困難,如圖像噪聲,光照變化和復(fù)雜的背景圖案。因此,設(shè)計一種穩(wěn)定、可靠、高效的場景識別算法仍然是一項非常具有挑戰(zhàn)性的工作。本文提出了一種結(jié)合視覺同步定位與地圖構(gòu)建(SLAM)和基于深度卷積神經(jīng)網(wǎng)絡(luò)(語義分割)的語義分割算法來提高AR圖像配準性能。基于語義分割的語義分割是一種計算量較大的預(yù)測任務(wù),其目的是在應(yīng)用AR圖像配準時預(yù)測圖像中每個像素的類別,并能夠縮小兩幀之間特征點的搜索范圍,從而提高系統(tǒng)的穩(wěn)定性。實驗結(jié)果表明,語義分割的場景信息將大幅提高AR圖像配準技術(shù)的性能。
【關(guān)鍵詞】語義分割 SLAM 深度學習 增強現(xiàn)實
1 介紹
增強現(xiàn)實技術(shù)(AR)是一種新型的人機交互技術(shù),它利用計算機系統(tǒng)提供信息來增強人們對真實環(huán)境的感知。真實場景將疊加計算機生成的虛擬場景、對象或系統(tǒng)信息,實現(xiàn)對現(xiàn)實的增強。AR技術(shù)強調(diào)現(xiàn)有虛擬世界與虛擬世界的融合,強調(diào)真實對象與虛擬對象的共存與互補。其中圖像配準是AR技術(shù)的關(guān)鍵內(nèi)容之一。
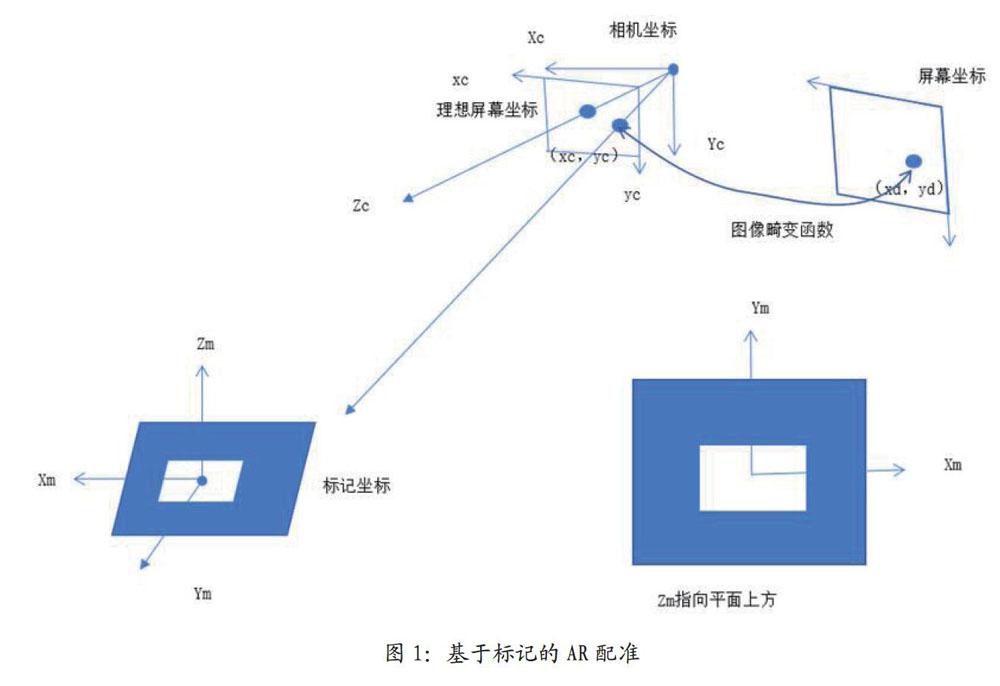
如圖1所示,目前大多數(shù)川之應(yīng)用都是通過相機識別已知的標記來計算三維配準的空間位置,將虛擬模型疊加在真實場景中。然而,一般在行業(yè)應(yīng)用中不允許使用標記,因此使用自然特征點進行三維配準是AR應(yīng)用的必然趨勢。
目前,基于自然特征點的三維配準技術(shù)主要采用視覺同步定位與地圖構(gòu)建(SLAM)算法[1][2]。圖2是視覺SLAM的示意圖。利用機器視覺提取圖像特征點,計算描述符和匹配特征點。相機捕捉相鄰幀的連續(xù)視頻序列并匹配關(guān)鍵點,并根據(jù)相機姿態(tài)的匹配結(jié)果,最終實現(xiàn)AR的3D配準。
然而,基于自然特征點的三維配準算法目前還不成熟。很容易匹配錯誤的特征點,從而限制了AR應(yīng)用的推廣。造成不匹配的主要原因是場景中有很多特征點,并且有很多相似的特征,這時當相機采集圖像并匹配像素點時,就很容易混淆。本文研究了一種基于語義分割的強魯棒場景感知技術(shù),在對自然特征點進行匹配的同時對匹配區(qū)域進行限制。首先將相機拍攝的場景進行語義分割,即根據(jù)對象本身的含義將各階段的對象進行分割。當對三維配準的自然特征進行匹配時,相鄰幀的匹配結(jié)果僅限于同一對象的像素區(qū)域。
如圖3所示,當相鄰幀特征點匹配,桌子和椅子分別對應(yīng),如果匹配特征點是放在桌子上,其余的是在椅子上,我們可以判斷哪些是錯誤匹配點并刪除它們,這將提高自然特征點匹配精度。
2 相關(guān)研究
基于自然特征點的AR尚處于初始階段,大多數(shù)基于自然特征點的AR應(yīng)用配準都使用了視覺SLAM算法。Castle等人[3]的作品是最早將物體識別和單眼關(guān)鍵幀與SLAM相結(jié)合的作品之一。在檢測到兩幀圖像中的物體后,他們在地圖上計算出物體的位置。但與我們的方法不同,它們只關(guān)注點的幾何意義,對AR三維配準的語義信息和優(yōu)化不感興趣。
Bao等人[4]是第一個從運動(SSFM)中應(yīng)用語義結(jié)構(gòu)的研究員。SLAM執(zhí)行視頻流使得點云和關(guān)鍵幀的映射逐漸遞增,而SSFM可以同時處理所有幀,SSFM的重構(gòu)與識別是分離與獨立的,SSFM使用邊框搜索對象并專注于重建。
Fioraio等人[5]展示了一個新的SLAM系統(tǒng),該系統(tǒng)將3D對象添加到地圖中,并通過調(diào)整來優(yōu)化它們的姿態(tài)。他們建立了含有7個對象的數(shù)據(jù)庫來描述這些對象,這些對象采用RGB-D攝像機在幾個尺度上獲得三維特征,并為每個尺度創(chuàng)建了獨立的索引。通過尋找3D到3D的對應(yīng)關(guān)系,實現(xiàn)了目標識別,并采用RANSAC算法進行濾波。雖然它們可以生成房間大小的地圖,但是它們的應(yīng)用程序不會實時運行。
Salas-Moreno等人[6]提出了一種結(jié)合了RGB-D地圖重建和目標識別的新型視覺SLAM系統(tǒng)。他們用KinectFusion預(yù)建對象數(shù)據(jù)庫,用點來描述對象的幾何形狀。這些點都由哈希表索引,并通過計算hough投票來標識。但它對數(shù)百個對象的可擴展性尚不清楚。
Abhishek Anand等人[7]提出了一種通過檢測點云來獲取語義對象的方法。他們訓練相應(yīng)對象的特征點,并匹配新幀的幾何信息。Liefeng Bo等人[8]提出了一種利用特征點與RGB-D信息匹配來檢測目標的方法。DanielMaier等人[9]利用NAO機器人攜帶AsusXtion Pro實時傳感器,實現(xiàn)了機器人在3D環(huán)境下的定位和障礙物識別,重建了3D點云環(huán)境,但缺乏場景的語義信息。
為了理解場景,語義分割起著至關(guān)重要的作用,引起了越來越多研究者的興趣[10-13]。在現(xiàn)有的方法中,卷積神經(jīng)網(wǎng)絡(luò)(neural network,CNN)在利用RGB圖像進行語義分割方面具有很大的優(yōu)勢。典型的CNN,稱為全卷積神經(jīng)網(wǎng)絡(luò)(FCN),在過去幾年中已經(jīng)取得了重要的進展。文獻[14]采用以不同層間融合為代表的編碼器式FCNs,大大提高了預(yù)測精度的密度。為了在不丟失分辨率的情況下擴展接收域,并在多個分割任務(wù)中獲得更好的性能,擴展卷積算子取代了碼譯碼器體系結(jié)構(gòu)。盡管做了很多努力去改進,但效果仍然不令人滿意,尤其是在物體的邊界上。為了解決這個問題,研究者們開始將基于全連通條件隨機場(allconnectedconditions random field,CRFs)的RGB模型與CNN相結(jié)合,并進行了改進[15][16]。然而,這些方法很難應(yīng)用于室內(nèi)環(huán)境中顏色相近的物體。
3 系統(tǒng)設(shè)計
在本節(jié)中,我們將從兩個部分介紹我們的方法,視覺SLAM和語義分割。圖4是這個系統(tǒng)的簡圖。本文關(guān)注SLAM和語義分割,而不是g2o庫的優(yōu)化。AR的圖像配準主要分為語義分割和視覺slam兩部分。
3.1 視覺SLAM
可以使用類似于depth camera Kinect的微軟Hololens進行圖像采集,得到每個像素的RGB和depth值。我們假設(shè)坐標系如圖5所示。
如圖5所示,o-xyz是圖像的坐標,o-xyz是攝像機的坐標。假設(shè)圖中的點為(u,v),對應(yīng)的3D點為(x,y,z),則它們的坐標變換如式(1)。
首先,我們得到地圖的深度數(shù)據(jù)來代替Z,計算出x和y,其中f代表焦距,c代表中心點。然后,當我們得到圖像中每個點的位置時,由于相鄰幀之間的差異,我們可以計算出相機的位移和旋轉(zhuǎn)。
在圖6中,很容易看出這兩個數(shù)字已經(jīng)轉(zhuǎn)向了一個特定的角度。但它會轉(zhuǎn)多少度呢?這個問題被稱為相機相對姿態(tài)估計。經(jīng)典的算法是迭代最近點(ICP)。該算法需要兩個圖像的特征點。我們使用OpenCV進行特征點匹配。這樣就可以用PnP算法預(yù)測攝像機的姿態(tài)。如式(2)所示。
R是攝像機的姿態(tài),C是攝像機的標定矩陣。R是連續(xù)變化值,C是穩(wěn)定常數(shù)。一般情況下,只要有四組匹配點,就可以計算出模型。圖7為本次實驗的圖片,結(jié)果顯示相鄰兩幀檢測到的特征點有317個,出現(xiàn)大量誤匹配特征點。
理論上,只要不斷地比較新幀和舊幀,就可以解決定位問題。然后,把這些關(guān)鍵點放在一起,就可以生成地圖。當然,如果slam如此簡單,那就不值得學習超過30年。這主要是由于相鄰幀之間有大量相似的特征點,噪聲處理非常復(fù)雜,導(dǎo)致了不匹配。因此,我們提出了一種優(yōu)化匹配誤差的方法。
3.2 語義分割
本方法需要圖像的語義信息的目的是當相鄰的幀特征點匹配時,合格的匹配點在同一個像素區(qū)域,根據(jù)語義分割信息進行篩選。語義分割主要采用全卷積神經(jīng)網(wǎng)絡(luò)。全卷積神經(jīng)網(wǎng)絡(luò)輸入一個圖像得到與原始相同大小的輸出圖像,輸出圖像具有像素到像素的映射,這是一個像素級的識別,輸出圖像中每個像素的輸入圖像在原始圖像上都有相應(yīng)的標記,表示什么對象最有可能是對象或類別。
Jiang[17]提出了一個RGB-D FCN體系結(jié)構(gòu)(DFCN)來生成每個像素上每個類的一元可能性的響應(yīng)。如圖8所示,DFCN部分主要有兩個模塊:
(1)三個向下樣本池的卷積層,用于特征提取和深度融合;
(2)用于上下文推理和稠密預(yù)測的膨脹卷積層。
它使用了16層的VGG net第一層 Conv1到Conv4作為基本框架。該基本結(jié)構(gòu)適用于RGB通道和深度通道的特征提取。在網(wǎng)絡(luò)的兩個分支的每次池化之前都將它們與元素求和。然后,在主分支的每個池化層之前添加融合層。為了防止函數(shù)映射的進一步減少,VGG-16中的第4池化層被替換為一次最大池化,而第五池化層被替換為一次最大池化和一次平均池化。為了使兩個分支中的值兼容并更易于訓練,它對深度通道進行了規(guī)范化,深度通道的初始范圍從0到65535到相同的彩色圖像范圍從0到255。
4 實驗評價
在我們的設(shè)計中,利用語義分割的輸出來限定兩個視頻幀之間的匹配點。具體來說,我們將這兩種技術(shù)的結(jié)合定義為式(3)。p和Q是連續(xù)幀圖像m和n中的特征點,R和t是旋轉(zhuǎn)矩陣和位移向量,PRGB-m和QRGB-n是三個通道在語義分割圖對應(yīng)特征點上的RGB值。
我們使用開放數(shù)據(jù)集SUN RGBD進行測試。它包含NYUv2圖像及其像素級語義注釋的數(shù)據(jù)。在TensorFlow框架中實現(xiàn)了DFCN-DCRF架構(gòu),并使用隨機梯度下降(SGD)進行端到端訓練。如圖9所示,左邊的RGB,深度在中間和右邊的語義分割和不同顏色代表了不同場景的對象。可見,目前顯著的目標分割效果是理想的。然而,小對象的分割并不理想
假設(shè)有兩個相鄰的幀圖像F1、F2和兩組對應(yīng)的特征點,如式(4)所示。
我們的目標是算出位移矢量的旋轉(zhuǎn)矩陣R和t,如式(5)所示。
然而,在現(xiàn)實中,由于誤差的存在,不可能得到等號,所以我們通過最小化誤差來求解,如式(6)所示。
這個問題可以用經(jīng)典的ICP算法來解決。其核心是奇異值分解(SVD)。我們將調(diào)用OpenCV中的函數(shù)來解決這個問題。接下來,我們將簡要介紹實現(xiàn)過程。由于我們需要匹配兩個圖像并計算它們的旋轉(zhuǎn)和位移關(guān)系,所以我們分三部分來做。首先,使用SIFT算法提取圖像特征點,用這些關(guān)鍵點周圍的像素計算描述子。其次,在前面的描述的基礎(chǔ)上,使用快速最近似近鄰搜索庫(FLANN)進行圖像特征匹配,返回DMatch結(jié)構(gòu),包括queryldx(上一個關(guān)鍵幀)、trainldx(下一個關(guān)鍵幀)、距離。然后根據(jù)經(jīng)驗值將距離大于最小范圍4倍的點移除。最后,根據(jù)語義分割的結(jié)果,對匹配的特征點進行RGB值的過濾,保持顏色相同的特征點即相同的對象,反之亦然。最后,用PnP算法估計攝像機的姿態(tài),得到旋轉(zhuǎn)矩陣和位移向量。
5 結(jié)果評價
將視覺slam和語義分割相結(jié)合是利用視覺SLAM圖像處理方法得到的特征匹配結(jié)果,判斷下一幀匹配的特征點是否在同一目標像素區(qū)域內(nèi)。如果不在同一區(qū)域內(nèi),則判斷為不匹配并刪除。圖7所示,這是只使用自然特征點為特征點匹配,很明顯,有很多錯配的結(jié)果,一些房子的匹配點誤以為傘,一些墻壁誤以為路面等等。在使用過本文新的方法后如圖10中,我們刪除一些相鄰幀處在不相同的像素區(qū)域內(nèi)的匹配點,結(jié)果明顯好了很多。我們的方法在一定程度上提高了匹配的準確性,提高了增強現(xiàn)實圖像配準的準確性。
如表1所示,兩幀的特征點總數(shù)為317,兩個匹配特征點之間的最小距離為6.7像素。沒有語義信息的匹配特征點有114個,有語義信息的匹配特征點有87個。也就是說,當我們使用語義信息時,我們可以減少21個不匹配特征點。盡管進行了篩選,但仍然存在不匹配的可能性。
本文提出了一種結(jié)合語義分割的圖像配準方法來提高視覺SLAM的準確性,進而提高增強現(xiàn)實圖像配準的準確性。圖像特征匹配限制在同一物體在不同幀中的像素區(qū)域,以減少噪聲對特征匹配的影響。當然,當前的語義分割在場景中不能被充分識別。本文僅在一定程度上提高了SLAM匹配精度。隨著語義分割準確率的逐步提高,對階段的感知將逐步增強,用于AR的圖像配準技術(shù)將變得更加智能化。
參考文獻
[1]趙洋,劉國良,田國會,羅勇,王梓任,張威,李軍偉.基于深度學習的視覺SLAM綜述[J].機器人,2017,39(06).
[2]江宛諭.基于深度學習的物體檢測分$1[J].電子世界,2018,15(05).
[3]R.O.Castle,G.Klein and D.W,Murray,Combining monoSLAM withobject recognition for sceneaugmentation using a wearablecamera,Image Vis.Comput.28(11)(2010)1548-1556.
[4]S.Y.Bao and S.Savarese,Semanticstructure from motion,Comput.Vis.Pattern Recognit.,20-25 June 2011,Providence,R1 pp.2025-2032.
[5]N.Fioraio,G.Cerri and L.Di Stefano,Towards semanticKinectFusion,Lecture Notes inComputer Science(includingsubseries Lecture Notes in Arti cialIntelligence and Lecture Notes inBioinformatics)8157 LNCS(PART 2)(2013)299-308.
[6]R.F.Salas-Moreno,R.A.Newcombe,A.J.Davison and P.H.J.Kelly,SLAM++:Simultaneous localisation andmAPPing at the level of objects,inIEEE Int.Conf.Comput. Vis.PatternRecogni.23-28 June,Portland,OR
[7]A.Anand,H.S.Koppula,T.Joachimsand A. Saxena,Contextually guidedsemantic labeling and search for 3Dpoint clouds,Int.i.Robot.Res,32(1)(2013)19-34.
[8]L.Bo,X.Ren and D.Fox,Learninghierarchical sparse features forRGB-(D)object recognition,Int.J.Robot.Res.33(4)(2014)581-599.
[9]D.Maier,A.Hornung and M.Bennewitz,Real-time navigationin 3d environments based on depthcamera data,in 2012 12th IEEE-RASInt.Conf.Humanoid Robots(Humanoids2012),2012,pp.692-697.
[10]梁明杰,閔華清,羅榮華.基于圖優(yōu)化的同時定位與地圖創(chuàng)建綜述[J].機器人,2013,35(04):500-512.
[11]王浩.基于視覺的行人檢測技術(shù)研究[D].遼寧工業(yè)大學,2018.
[12]嚴超華.深度語義同事定位與建圖[D].浙江大學,2018.
[13]付夢印,呂憲偉,劉形,楊毅,李星河,李玉.基于RGB-D數(shù)據(jù)的實時SLAM算法[J].機器人,2015.
[14]V.Badrinarayanan,A.Kendall and R.Cipolla,Segnet:A deep convolutionalencoderdecoder architecture forscene segmentation,IEEE Trans.Pattern Anal.Mach.Intell.39(12)(2017)2481-2495.
[15]L.-C.Chen,G.Papandreou,I.Kokkinos,K.Murphy and A.L.Yuille,Deeplab:Semantic image segmentationwith deep convolutional nets,atrousconvolution,and fully connectedcrfs,arXiv:1606.00915.
[16]J.Dai,K.He and J.Sun,Boxsup:Exploiting bounding boxes tosupervise convolutional networks forsemantic segmentation,in Proc.IEEEInt.Conf.Comput.Via.2015,pp.1635-1643.
[17]J. Jiang,Z. Zhang,Y. Huang andL.Zheng,Incorporating depth intoboth CNN and CRF for indoor semanticsegmentation,arXiv:1705.07383.
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
