效能評估可信度的客觀度量方法
2018-02-27 10:57:56王軍李建勛王興戚宗鋒
西安交通大學學報 2018年2期
王軍,李建勛,王興,戚宗鋒,3
(1.中國洛陽電子裝備試驗中心,471000,河南洛陽;2.上海交通大學自動化系,200240,上海;3.電子信息系統(tǒng)復雜電磁環(huán)境效應(yīng)國家重點實驗室,471000,河南洛陽)
目前效能評估在裝備鑒定、網(wǎng)絡(luò)安全評估、電力系統(tǒng)性能評估[1]等領(lǐng)域有著廣泛的應(yīng)用。評估可信度是研究評估工作中各環(huán)節(jié)的可信程度,而目前關(guān)于評估可信度研究的公開文獻還很少。針對可信度的研究目前大多見于仿真系統(tǒng),如文獻[2-5]分別對重力壩仿真系統(tǒng)、戰(zhàn)爭模擬系統(tǒng)概率仿真模型、電信網(wǎng)絡(luò)仿真模型以及移動自組織網(wǎng)絡(luò)仿真系統(tǒng)的可信度進行了研究。然而,評估系統(tǒng)可信度不同于仿真系統(tǒng)可信度,其主要區(qū)別為:①效能評估系統(tǒng)是一個比仿真系統(tǒng)更為抽象的系統(tǒng),構(gòu)建仿真系統(tǒng)模型可參考真實系統(tǒng),而構(gòu)建效能評估模型無真實模型可以參考;②仿真系統(tǒng)的仿真結(jié)果可以與真實系統(tǒng)進行比較,而評估系統(tǒng)無法獲取真實值。
效能評估可信度分析可以概括為3個方面:①效能評估過程的可信度分析;②效能評估穩(wěn)健性實現(xiàn)方法;③效能評估結(jié)果可信度分析[6]。在效能評估穩(wěn)健性實現(xiàn)方法方面,隨著機器學習方法的不斷發(fā)展,大量的研究人員將機器學習算法應(yīng)用到效能評估中,這在一定程度上解決了效能評估不穩(wěn)健的問題。在效能評估過程及結(jié)果可信度分析方面,文獻[7]給出了一種基于元評估的可信度分析方法,該方法通過描述評估過程是否科學嚴謹,分析評估過程可信度并給出評估結(jié)果的可信度結(jié)果,本質(zhì)是一種主觀評價方法。評估可信度直接關(guān)系到評估結(jié)論的使用,只有建立一種效能評估可信度客觀度量方法,才能確保效能評估的真正價值。因此,本文研究評估可信度的客觀度量方法,解決目前實際工程應(yīng)用中的問題,以彌補效能評估中的不足。
1 效能評估與模式分類的關(guān)系
效能評估流程主要包括評估指標體系構(gòu)建、指標數(shù)據(jù)采集、評估模型構(gòu)建及評估結(jié)果分析等[8],如圖1所示。在指標體系構(gòu)建時,要求所選取的每個指標值能描述同類系統(tǒng)不同對象間的區(qū)別;在指標數(shù)據(jù)采集時,通過試驗采集相應(yīng)的指標數(shù)據(jù);在評估模型構(gòu)建時,根據(jù)評估工作的需要,建立科學合理的評估模型;在評估結(jié)果分析時,通過分析評估結(jié)果指導評估工作前面環(huán)節(jié)的完善。

圖1 效能評估主要流程
模式分類是指對表征事物或現(xiàn)象的各種形式信息進行處理,以對事物或現(xiàn)象進行描述、辨認、分類和解釋的過程[9]。模式是模式分類系統(tǒng)中的基本元素,根據(jù)研究對象的不同,將具有不同特征的對象看作不同的模式,很多問題可以采用模式分類的方法解決,例如故障診斷[10-12]、圖像檢測[13]等。典型模式分類流程包括數(shù)據(jù)采集、特征選擇或抽取、分類器設(shè)計以及分類結(jié)果分析[9],如圖2所示。

圖2 典型模式分類流程
效能評估中的指標選擇其實是選擇不同的特征,這與模式分類中的特征選擇或提取的本質(zhì)是一樣的。如果將不同的效能等級看作不同的模式,那么對被評估對象的效能評估過程也是一種模式分類的過程。因此,為了研究效能評估可信度,本文從模式分類的角度研究評估可信度問題。
2 評估模型可信度
2.1 模型性能評價方法
通過上面的分析可以看出,評估模型實際上可以看作是一個分類模型。對分類模型的性能評價常用的指標是分類準確率、運算速度、成本等,在對效能評估模型性能分析時由于運算速度、成本等本身并不影響分類結(jié)果的正確性,因此這里僅考慮模型的分類準確率。
一般在二分類問題中,評價模型分類性能的直觀方法是根據(jù)正負樣本分類結(jié)果繪制ROC曲線和AUC曲線[14-15]。在多分類模型中,無正負樣本之分,但是仍然可以通過計算分類準確率描述分類模型的性能。多分類模型中,模型對不同類別樣本的分類能力是不同的,因此需要分別計算模型對每類樣本的分類準確率。第i類樣本的分類準確率PTi的計算公式為
(1)
式中:NTi表示i類樣本被正確劃分的個數(shù);Ni表示i類樣本的總個數(shù)。
2.2 評估模型可信度
上面從分類的角度給出了評估模型性能評價方法。在評估系統(tǒng)中,模型的可信度代表著評估者對評估模型的認可程度,度量的是一種人主觀想法的表現(xiàn),不同的人對同一模型的認可程度不同,但是人的主觀判斷是基于客觀數(shù)據(jù)的推斷,因此只有基于客觀數(shù)據(jù)通過科學的數(shù)學方法得出的可信度才更準確,同時也能夠避免不同人對同一模型認可程度不同的問題。
在不確定性理論中,可信度是建立在可能性及必要性測度上的。假設(shè)某一事件A發(fā)生的可能性測度為Ppos(A),事件A發(fā)生的必要性測度為Pnec(A),那么事件A發(fā)生的可信度為
C(A)=λPpos(A)+(1-λ)Pnec(A)
0≤λ≤1
(2)
式中:λ為可能性和必要性平衡系數(shù),通常可以認為可能性與必要性同等重要,此時λ=1/2。
本文借鑒不確定性理論中可信度的概念,討論評估模型的可能性及必要性測度進而確定評估模型的可信度。事件A定義為通過評估模型將應(yīng)屬于A類的樣本劃分為A類,則事件A發(fā)生的可能性測度Ppos(A)定義為事件A發(fā)生的概率,即
(3)
式中:PTA表示事件A發(fā)生的概率;NTA表示A類樣本被正確分類個數(shù);NA表示A類樣本總數(shù)。
事件A發(fā)生的必要性定義為不屬于A類的樣本被劃分到A類的不可能性,于是事件A發(fā)生的必要性測度Pnec(A)定義為
(4)
式中:NFA表示不屬于A類的樣本被錯誤分為A類的個數(shù);N表示樣本總數(shù)。
由式(2)~式(4)可以得到事件A發(fā)生的可信度為
C(A)=λPpos(A)+(1-λ)Pnec(A)=
(5)
3 單樣本分類置信度
對一待測樣本,通過分類模型進行分類后,在不考慮分類結(jié)果是否正確的情況下,該樣本被劃分為某類的可信性程度稱為單樣本分類置信度。單樣本分類置信度僅代表模型將樣本分類的結(jié)果和其相似樣本分類結(jié)果一致性的度量,與分類結(jié)果是否正確無關(guān)。例如,樣本x1通過某評估模型得到的評估分類結(jié)果為y1,模型在對樣本x1評估時,經(jīng)過計算認為x1屬于y1的置信度為95%,此時不管分類結(jié)果是否正確,樣本的評估分類結(jié)果置信度就是95%。
關(guān)于分類置信度的計算,文獻[16-17]給出了一種最近鄰分類器的分類置信度計算方法。文獻[16]同時給出了SVM分類器分類置信度計算方法。綜合各種分類算法的主要思想可知,分類器是通過樣本間的距離將進行分類的,這種距離包括同類樣本距離與異類樣本距離,因此可以通過距離度量樣本分類置信度。另外,從高維空間的角度分析,樣本在高維空間的分布影響著分類的結(jié)果,對單個待測樣本來講,單樣本與鄰域樣本中的同類樣本分布關(guān)系和異類樣本分布關(guān)系都影響其分類結(jié)果,這些關(guān)系包括樣本數(shù)量和樣本空間距離。影響樣本分類置信度的因素如圖3所示。

圖3 影響樣本分類置信度的因素
基于此,本文提出一種新的滿足多數(shù)分類算法的單樣本分類置信度計算方法。
定義1 設(shè)ms(x)為測試樣本中與待測樣本x同類的鄰域樣本個數(shù),m(x)為測試樣本中待測樣本x的鄰域樣本總數(shù),Ds(x)為待測樣本x與鄰域樣本中所有同類樣本的歐氏距離和,Dd(x)為待測樣本x與鄰域樣本中異類樣本的歐氏距離和。定義待測樣本x的分類置信度為
(6)
特別規(guī)定:當待測樣本鄰域內(nèi)無異類樣本時Dd(x)=0。顯然,該置信度取值范圍是0~1。
4 效能評估綜合可信度度量方法
以上分析了評估模型可信度及待測樣本置信度,對于待評估的對象,其評估可信度應(yīng)包括被評估對象樣本數(shù)據(jù)的可信度、模型可信度及樣本分類置信度等3個方面。試驗數(shù)據(jù)的可信度主要受試驗活動中的不確定性影響,下面討論試驗數(shù)據(jù)的不確定性對樣本數(shù)據(jù)可信度的影響及處理方法,以及如何將試驗數(shù)據(jù)可信度、評估模型可信度及單樣本分類置信度3個方面進行綜合,得到最終評估可信度。
4.1 不確定性數(shù)據(jù)的處理
通常采用隨機變量、模糊變量以及區(qū)間變量描述試驗過程中的不確定性。對于隨機變量和模糊變量可以直接計算不確定性測度,進而確定試驗數(shù)據(jù)的可信度,或者將隨機變量及模糊變量轉(zhuǎn)化為區(qū)間數(shù)據(jù)再進行處理。文獻[18]給出了模糊變量及隨機變量的不確定性測度計算方法,本文不再討論。本文重點研究包含區(qū)間變量的評估可信度度量問題。設(shè)xi=(xi1,xi2,…,xin)為某裝備的試驗樣本,假設(shè)樣本分量xi1的值是區(qū)間值,即xi1取值范圍是a~b。在對樣本xi進行效能評估時可以分別采用區(qū)間上限及區(qū)間下限進行計算,此時計算結(jié)果會出現(xiàn)2種情況。一是采用區(qū)間上限和區(qū)間下限得到的評估分類結(jié)果一致,此時區(qū)間數(shù)據(jù)不影響被評估對象的效能等級劃分,但是影響效能評估的可信度;二是采用區(qū)間上限及區(qū)間下限時得到的評估結(jié)果不同。進一步假設(shè)當取區(qū)間上限b時,評估結(jié)果為y1,當取區(qū)間的下限a時,評估結(jié)果為y2,此時需要分別計算該樣本屬于效能等級y1與y2的可信度。在已知xi1在a~b內(nèi)的概率密度函數(shù)的情況下,假設(shè)通過判斷xi1取區(qū)間中某點c時,樣本xi=(xi1,xi2,…,xin)處在分界面上,此時將區(qū)間a~b分為a~c和c~b,分別計算a~c及c~b的概率分布值,此時概率分布描述的是僅考慮試驗數(shù)據(jù)時的評估可信度。
4.2 可信度傳播模型
設(shè)評估系統(tǒng)數(shù)學模型為
D=f(X)
(7)
式中:D為評估結(jié)果,即效能值;X={x1,x2,…,xn}為評估系統(tǒng)的輸入。
可信度傳播分為模塊間的串聯(lián)和并聯(lián)2種情況,可信度傳播模型如圖4所示。圖4a代表的是一種串聯(lián)情況,其可信度傳播模型為
C(D)=C(Y)C[f(X)]
(8)

(a)串聯(lián)
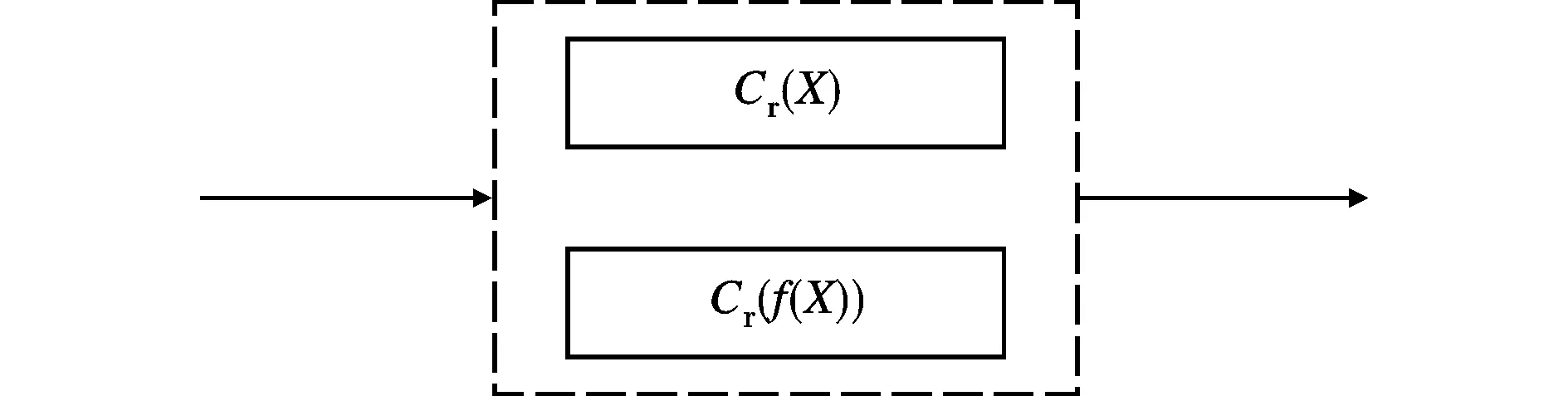
(b)并聯(lián)圖4 可信度傳播模型
圖4b代表的是一種并聯(lián)情況,其可信度傳播模型為
C(D)=min{C(X),C[f(X)]}
(9)
效能評估可信度是評估數(shù)據(jù)、評估模型及樣本置信度3個因素的累積影響,是一種串聯(lián)情形。假設(shè)試驗數(shù)據(jù)的置信度用Cd(x)表示,模型的可信度用Cm(f)表示,單樣本的評估分類的置信度用f(x)表示,那么待評估樣本x的綜合評估可信度為
C(x)=Cd(x)Cm(f)f(x)
(10)
上面分別討論了試驗數(shù)據(jù)的不確定性處理方法、評估模型可信度分析方法以及單樣本分類置信度計算方法,并給出了一種簡單的可信度傳播模型。
4.3 綜合可信度分析方法原理
從上面的分析可以給出綜合效能評估可信度分析方法原理,如圖5所示。

圖5 評估可信度分析方法原理
從圖5可以看出,本文將評估可信度分為評估數(shù)據(jù)可信度、評估模型可信度以及單樣本置信度3個方面。在計算評估數(shù)據(jù)可信度時,根據(jù)所包含的不確定性數(shù)據(jù)類型,直接計算可信度大小或者轉(zhuǎn)化為區(qū)間數(shù)據(jù)進行處理;在計算評估模型可信度時,將評估模型與模式分類模型建立聯(lián)系,結(jié)合不確定性理論中的可信度概念,將分類性能評價指標轉(zhuǎn)化為可信度指標;在計算單樣本分類置信度時,結(jié)合現(xiàn)有分類置信度計算的主要思想,綜合考慮鄰近樣本的類別與距離信息,確定待測樣本分類置信度。最后,將影響評估可信度的3個方面通過簡單的可信度傳播模型進行綜合,得到最終的評估可信度。
5 實例分析
以雷達抗干擾效能評估為例,選取抗干擾拖引
成功率(P1)、抗假目標欺騙成功率(P2)、發(fā)現(xiàn)概率(P3),跟蹤誤差(E)、抗干擾扇面有效度(θ)以及平局虛假航跡改善因子(I)等6個評估指標。通過仿真試驗獲取140組數(shù)據(jù),將效能等級劃分為4個等級(1、2、3、4)得到140個樣本的仿真數(shù)據(jù),其中部分組數(shù)據(jù)如表1所示。
選取140組樣本中的75組為訓練樣本、65組為測試樣本。將測試樣本中效能等級為1的樣本集記為S1,共計15個;將效能等級為2的樣本集記為S2,共計12個;將效能等級為3的樣本集記為S3,共計18個;將效能等級為4的樣本集記為S4,共計20個。采用SVM評估模型進行計算,評估程序運行結(jié)果界面如圖6所示,圖中左側(cè)為樣本實際分類結(jié)果(類標簽),右側(cè)是運算錯誤結(jié)果。
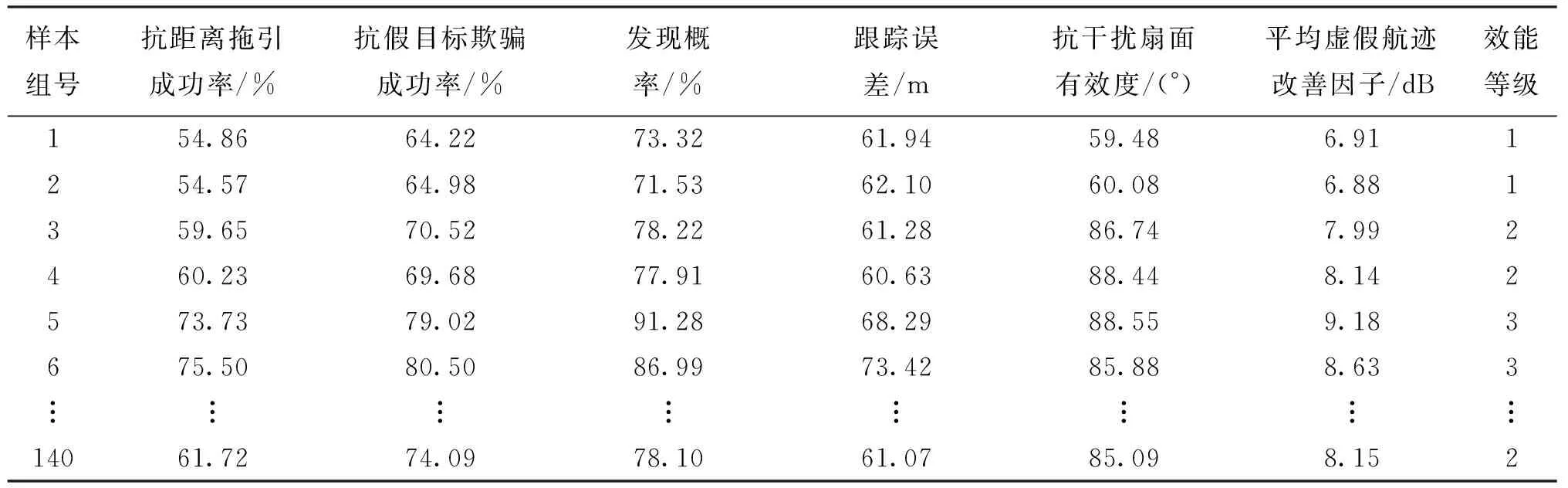
表1 雷達抗干擾效能評估仿真數(shù)據(jù)
Original Label is:1 Wrongly Predicted Label is 2
Original Label is:1 Wrongly Predicted Label is 2
Original Label is:2 Wrongly Predicted Label is 1
Original Label is:2 Wrongly Predicted Label is 4
Original Label is:3 Wrongly Predicted Label is 2
Original Label is:3 Wrongly Predicted Label is 4
Original Label is:3 Wrongly Predicted Label is 1
Original Label is:4 Wrongly Predicted Label is 2
Original Label is:4 Wrongly Predicted Label is 3
Original Label is:4 Wrongly Predicted Label is 3
圖6 評估程序運行結(jié)果界面
根據(jù)圖6的計算結(jié)果及式(3)、(4),可得每一類樣本分類結(jié)果的可能性及必要性分別為
(11)
(12)
根據(jù)式(5),取λ=0.5,得到模型對每類樣本分類的可信度為
(13)
表2為試驗采集的3組待評估裝備樣本的指標數(shù)據(jù),其中部分指標無具體的數(shù)據(jù),只能得到其取值的范圍。ST2中的θ以及ST3中的I的試驗數(shù)據(jù)是區(qū)間值,需要分別考慮區(qū)間上限及下限情況,判斷其效能等級是否一致。經(jīng)過分析,ST2中θ取區(qū)間上限及下限的效能等級相同。ST3中的指標I取區(qū)間下限時,效能等級為3,取區(qū)間上限時,效能等級為4,進一步通過區(qū)間搜索發(fā)現(xiàn):當ST3中的指標I取值為8.81時,效能等級為3,取值為8.82時,效能等級為4,于是近似認為8.815為ST3樣本的效能分界點。假設(shè)該參數(shù)在區(qū)間內(nèi)取每一點值的概率相同,于是對于樣本ST3有:當指標I取值為8.79~8.815時,效能等級為3,其概率大小為0.42;當指標I取值為8.815~8.85時,效能等級為4,其概率大小為0.58。如果想要獲取準確的效能等級,需要通過試驗進一步確定指標I的精確值。

表2 3組待評估裝備試驗數(shù)據(jù)
式(13)給出的模型對每類樣本分類可信度在一定程度上描述了評估的可信度。下面進一步分析單樣本的置信度。表3給出了測試樣本中ST1樣本的鄰域樣本及ST1樣本與鄰域樣本的距離dT1。
由式(6)得到ST1樣本的分類置信度為
(14)
記ST2中指標I取區(qū)間下限時的樣本為ST21,記取區(qū)間上限時的樣本為ST22,分別計算ST21和ST22的在測試樣本中的鄰域樣本及其與鄰域樣本的距離dT21、dT22樣本,經(jīng)計算測試樣本中ST21和ST22的鄰域樣本相同,距離信息如表4所示。
由表4及式(6)可以得到T21及T22樣本的分類
置信度分別為
(15)
(16)
由式(15)及式(16)的結(jié)果可以看出,ST2樣本的區(qū)間上限和下限結(jié)果基本相同,而且效能評估分類結(jié)果相同,因此可以忽略指標I的區(qū)間數(shù)據(jù)對ST2樣本評估及評估可信度的影響。
對于ST3樣本可采用同樣的方法進行分析,求得其分類置信度,這里不再贅述。
上面分析了區(qū)間數(shù)據(jù)對評估結(jié)果及評估可信度的影響,并得到了模型對每一類樣本分類的可信度,同時得到了單樣本的置信度。于是,根據(jù)串聯(lián)模塊可信度傳播模型可以得到樣本ST1和ST2的評估可信度為
C(ST1)=C(S2)f(ST1)=0.88×0.68=0.60
(17)
C(ST2)=C(S2)f(ST2)=0.90×0.84=0.76
(18)
式(17)和式(18)表示樣本ST1和ST2所代表的裝備效能評估結(jié)果為等級2和等級3的可信度分別為60%和76%,而3個裝備通過蒙特卡洛仿真試驗驗證的效能等級分別為2、3、4,其可信度分別為0.6~0.68、0.7~0.79以及0.5~0.56。同時,邀請雷達領(lǐng)域4名專家給出的3個裝備效能等級分別為2、3、4,其綜合可信性分別為0.73、0.86、0.68。

表3 ST1樣本的鄰域樣本及相關(guān)數(shù)據(jù)信息

表4 ST2樣本的鄰域樣本及相關(guān)數(shù)據(jù)信息
從上面具體實例可以看出,本文提出的效能評估可信度度量方法并沒有利用專家經(jīng)驗知識,避免了不同專家對同一被評估對象評估結(jié)果分析的不同,便于編程實現(xiàn)評估結(jié)果的自動分析,能夠提高計算效率,且計算結(jié)果與蒙特卡洛仿真試驗結(jié)果相符,取蒙特卡洛仿真結(jié)果中間值作為可信度基準值,經(jīng)計算本文方法與專家主觀判斷結(jié)果相比,準確率提高了約10%,證明了本文可信度客觀度量方的有效性。
6 結(jié) 論
本文為解決評估可信度缺少客觀度量方法的難題,在分析現(xiàn)有效能評估與模式分類相關(guān)性的基礎(chǔ)上,創(chuàng)新性地將模式分類相關(guān)理論應(yīng)用到效能評估中,提出了從試驗數(shù)據(jù)可信度到評估模型可信度,再到單樣本分類置信度3個方面客觀度量評估可信度的方法。在評估模型可信度分析方面,結(jié)合不確定性理論給出了計算評估模型可信度的方法;在單樣本分類置信度計算方面,給出了一種適用多數(shù)分類算法的相對置信度計算方法;同時本文還討論了不確定性試驗數(shù)據(jù)對評估可信度的影響及處理方法,并重點研究了區(qū)間值數(shù)據(jù)的處理方法,并給出了一種簡單的可信度傳播模型,基于可信度傳播模型,可得到效能評估綜合可信度。最后,以雷達抗干擾效能評估可信性度量為例,驗證了本文提出的方法能夠在不使用專家經(jīng)驗知識的情況下,客觀地度量效能評估可信度,計算結(jié)果更加客觀、準確,有效地解決了評估可信度難以客觀度量的問題,提高了裝備試驗鑒定效率。
[1] 王秀麗, 張擇策, 侯雨伸. 主動配電網(wǎng)多維度靜態(tài)安全評估 [J]. 西安交通大學學報, 2016, 50(8): 110-116. WANG Xiuli, ZHANG Zece, HOU Yushen. Multidimensional static security assessment for active distribution network [J]. Journal of Xi’an Jiaotong University, 2016, 50(8): 110-116.
[2] CAO X, GU C. Risk analysis of gravity dam instability using credibility theory Monte Carlo simulation model [J]. Springer Plus, 2016, 5(1): 1-14.
[3] 李震, 董鴻鵬, 姜本清. 作戰(zhàn)仿真概率模型可信性測試 [J]. 計算機與現(xiàn)代化, 2016(1): 82-86. LI Zhen, DONG H P, JIANG B Q. Credibility test of probability model in warfare simulation system [J]. Computer & Modernization, 2016(1): 82-86.
[4] PAWLIKOWSKI K, JEONG H D J, LEE J S R. On credibility of simulation studies of telecommunication networks [J]. IEEE Communications Magazine, 2002, 40(1): 132-139.
[5] ANDEL T R, YASINSAC A. On the credibility of manet simulations [J]. Computer, 2006, 39(7): 48-54.
[6] 汪連棟, 曾勇虎, 申緒澗. 電子信息系統(tǒng)復雜電磁環(huán)境效應(yīng)研究路線圖 [M]. 北京: 國防工業(yè)出版社, 2013: 8.
[7] 宋彥學, 張志峰, 齊立輝. 基于元評估的武器裝備作戰(zhàn)效能評估可信性研究 [J]. 火力與指揮控制, 2009(S1): 128-131. SONG Yanxue, ZHANG Zhifeng, QI Lihui. Research on the creditability of operational effectiveness evaluation with weapon equipment based on meta-evaluation [J]. Fire Control and Command Control, 2009(S1): 128-131.
[8] 黃炎焱. 武器裝備作戰(zhàn)效能穩(wěn)健評估方法及其支撐技術(shù)研究 [D]. 長沙: 國防科學技術(shù)大學, 2006: 22-25.
[9] 姜斌, 黎湘, 王宏強, 等. 模式分類方法研究 [J]. 系統(tǒng)工程與電子技術(shù), 2007, 29(1): 99-102. JIANG Bin, LI Xiang, WANG Hongqiang, et al. Methods for pattern classification [J]. Systems Engineering and Electronics, 2007, 29(1): 99-102.
[10]張西寧, 雷威, 李兵. 主分量分析和隱馬爾科夫模型結(jié)合的軸承監(jiān)測診斷方法 [J]. 西安交通大學學報, 2017, 51(6): 1-7. ZHANG Xining, LEI Wei, LI Bing. Bearing fault detection and diagnosis method based on principal component analysis and hidden Markov model [J]. Journal of Xi’an Jiaotong University, 2017, 51(6): 1-7.
[11]WANG T, QI J, XU H, et al. Fault diagnosis method based on FFT-RPCA-SVM for cascaded-multilevel inverter [J]. ISA Transactions, 2016, 60: 156-163.
[12]YIN Z, LIU J, KRUEGER M, et al. Introduction of SVM algorithms and recent applications about fault diagnosis and other aspects [C]∥Proceedings of 2015 IEEE International Conference on Industrial Informatics. Piscataway, NJ, SUA: IEEE, 2015: 550-555.
[13]張鵬, 陳湘軍, 阮雅端, 等. 采用稀疏SIFT特征的車型識別方法 [J]. 西安交通大學學報, 2015, 49(12): 137-143.
ZHANG Peng, CHEN Xiangjun, RUAN Yaduan, et al. A vehicle classification technique based on sparse coding [J]. Journal of Xi’an Jiaotong University, 2015, 49(12): 137-143.
[14]張小利. 圖像融合及其性能評估若干問題研究 [D]. 長春: 吉林大學, 2016: 115-119.
[15]王穎, 李金, 王磊, 等. 基于機器學習的microRNA預測方法研究進展 [J]. 計算機科學, 2015, 42(2): 7-13. WANG Ying, LI Jin, WANG Lei, et al. Research and progress of microRNA prediction methods on mach in learning [J]. Computer Science, 2015, 42(2): 7-13.
[16]趙行. SVM分類器置信度的研究 [D]. 北京: 北京郵電大學, 2010: 8-20.
[17]薛磊, 楊曉敏, 吳煒, 等. 一種基于KNN與改進SVM的車牌字符識別算法 [J]. 四川大學學報(自然科學版), 2006, 43(5): 1031-1036. XUUE Lei, YANG Xiaomin, WU Wei, et al. An algorithm based on KNN and improved SVM for license plate recognition [J]. Journal of Sichuan University (Natural Science Edition), 2006, 43(5): 1031-1036.
[18]柯宏發(fā), 陳永光, 劉思峰. 電子裝備試驗數(shù)據(jù)的不確定性分析方法 [J]. 應(yīng)用基礎(chǔ)與工程科學學報, 2011, 19(4): 653-663. KE Hongfa, CHEN Yongguang, LIU Sifeng. New method of uncertainties analysis for electronic equipment test data [J]. Journal of Basic Science and Engineering, 2011, 19(4): 653-663.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
