圖像語義相似性網絡的文本描述方法
2018-02-27 03:06:39周向東施伯樂
計算機應用與軟件 2018年1期
劉 暢 周向東 施伯樂
(復旦大學計算機科學技術學院 上海 200433)
0 引 言
圖像的文本化描述是指根據一幅圖像自動的生成一句描述性的文字。由于互聯網上的大部分的數據是圖像等非結構數據,圖像的文本化描述有助于人們從海量圖像中進行數據挖掘、分析和檢索,是橫跨計算機視覺領域和自然語言處理領域的新興的研究方向。該任務是從圖像中學習自然語言,面臨著克服語義鴻溝、圖像文本對齊、訓練模型收斂等挑戰。圖像具有多通道、高維度的特點,并且受到光照、分辨率、環境和噪聲的影響。自然語言具有結構,語法多樣規范,詞匯靈活多變,建立圖像和文本之間的對應關系是一項極具挑戰的任務。近年來圖像的文本化描述研究引起了愈來愈多的關注。
解決圖像的文本化描述問題,常用的方法分為基于檢索和基于語言模型兩種。基于檢索的方法是對圖像和文本分別進行語義分割,利用馬爾科夫隨機場MRF(Markov Random Field)[1]或者典型關聯分析CCA(Canonical Correlation Analysis)[2]等方法,把圖像和文本投影到同一空間,建立對應關系,從數據庫中找到與圖像最匹配的文本。基于語言模型的方法可以生成全新的語句,例如使用條件隨機場提取圖像中的物體、場景和關系,然后采用模板生成語句。文獻[3-4]提取圖像的卷積神經網絡CNN(Convolutional Neural Network)特征[5]作為特殊的視覺單詞,采用遞歸神經網絡RNN(Recurrent Neural Network)[6]建立語言模型。基于檢索的方法生成的語句更加自然,依賴大規模有標注的數據庫。基于語言模型的方法可以靈活的生成全新的語句。目前神經網絡方法在該任務的實驗效果較好,利用在ImageNet數據集上訓練好的CNN網絡,提取圖像的全連接層特征[7]。RNN網絡按照時間展開,可以直接處理時序數據和構建語言模型[4],隱層節點一般選用LSTM[8]或GRU[9]。采用CNN網絡和RNN網絡結合的方法,可以直接得到圖像和文本的對應關系,不需要進行目標檢測、句法分析和模板填充等步驟,是一個端到端的模型。
傳統方法僅考慮圖像和文本之間的轉換過程,由于存在語義鴻溝和缺乏大規模數據集,模型訓練困難,預測的文本與圖像內容可能存在較大差異。受到圖像檢索的視覺相似性的啟發[4],本文考慮數據間的相似程度,用相似圖像的語義信息作為補充構造語義相似性神經網絡進行預訓練,深入挖掘圖像間和對應文本描述間的相似性信息,并與遞歸神經網絡語言模型相互配合。用圖像CNN特征的余弦距離和BLEU[14]等機器翻譯指標分別衡量圖像間的視覺相似度和語義相似度。把視覺相似度與RNN網絡生成的文本串聯,作為全連接網絡的輸入,擬合得到語義相似度。通過引入數據間的相似性信息,在預測階段保持相似圖像的有效語義,從而獲得更好的文本描述。另外,為提高語言模型學習能力,增加棧式隱層和普通隱層的深度,最終得到接近人類語言的通順語句。在這種背景下,本文提出圖像語義相似性神經網絡。Flickr30k數據集[19]和MSCOCO數據集[20]的實驗結果表明,本文方法在BLEU、ROUGE[15]、METEOR[16]和CIDEr[17]等多數機器翻譯評價指標上超過了Google NIC[3]和log Bilinear[21]等目前主流的方法。
1 相關工作
Farhadi等提出圖像的文本化描述任務[1],把圖像和文本投影到<對象,動作,場景>的三元組空間,利用馬爾科夫隨機場對圖像進行投影,用句法解析對文本進行投影,然后計算相似性。Kulkarni等利用條件隨機場對圖像的對象、屬性和空間關系進行標注[10],采用模板生成方法產生全新的語句。Gong等采用典型關聯分析方法[2],建立圖像和文本之間的對應關系。圖像采用卷積神經網絡特征,文本采用詞袋特征,同時用大量弱標注的圖像文本數據集進行輔助學習。Karpathy和Vinyals等提出使用神經網絡構造端到端的語言模型[3-4],提取圖像的CNN特征作為視覺單詞,采用三層遞歸神經網絡訓練語言模型,可以直接得到圖像到文本的映射關系。Johnson等提出全卷積定位網絡[11],不僅能生成整幅圖像的描述,也能生成圖像內部區域的描述。Xu等提出的網絡模型可以學習圖像內部區域和單詞的對應關系[12]。Tang等提出一種基于深度遞歸神經網絡的方法[13],把圖像特征輸入到遞歸神經網絡的每一個時刻。
2 模型架構
本文提出圖像語義相似性神經網絡模型,由兩個共享參數的多層遞歸神經網絡和一個全連接網絡構成。首先對圖像語義相似性網絡預訓練,學習相似圖像的語義信息,然后在遞歸神經網絡上繼續訓練語言模型。多層遞歸神經網絡能夠增強模型的學習能力,有助于理解圖像的高級語義信息。
2.1 圖像語義相似性網絡
圖像語義相似性神經網絡模型如圖1所示,能夠學習圖像之間的視覺相似性和對應文本描述的語義相似性,進而提升網絡的泛化能力。其主要思想是,當模型學習圖像的文本描述時,應當受到相似圖像語義的約束,在預測階段,通過聯想相似圖像的語義信息進而提升文本描述的質量。該方法可以應用到現有的遞歸神經網絡語言模型。
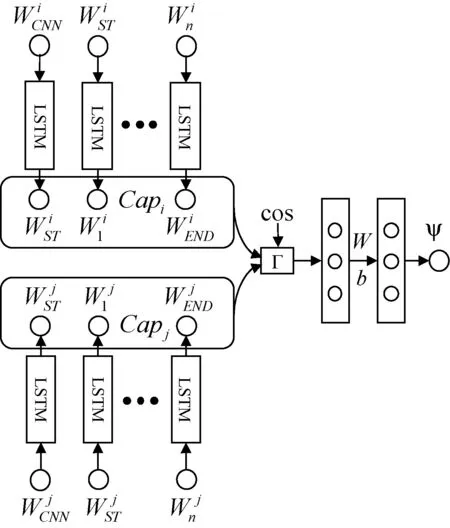
圖1 圖像語義相似性神經網絡
為了衡量圖像的視覺相似性,首先提取圖像的卷積神經網絡特征[24],然后計算兩個特征的余弦距離:
(1)

為了衡量文本描述的語義相似性,本文采用BLEU,ROUGE,METEOR和CIDEr等機器翻譯的評價指標。由于數據集中每幅圖像都有多句文本描述,因此可以直接計算文本的機器翻譯得分作為語義相似性。
(2)

(3)
集合Z={BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, CIDEr, ROUGE},表示7種評價指標。t表示圖像的獨立描述語句的個數,n表示具體一種評價指標的類型。構造圖像文本相似性四元組數據集,按CNN特征的余弦距離對圖像聚類,在每個類里選擇兩幅圖像計算余弦距離cos和文本的語義相似性ψ組成四元組,再從不同的類中選擇圖像組成相同數量的四元組,共同構成四元組數據集:
(imgi,imgj,cos,ψ)
(4)
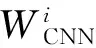
(5)
o1=σ(Γ·W1+b1)
(6)
o2=σ(o1·W2+b2)
(7)
式中:Wi、bi和oi是第i個全連接層的權重、偏置和輸出。其中,σ是sigmoid函數,是全連接層的激活函數:
(8)
全連接網絡用來擬合輸入向量Γ和文本相似性得分Ψ的映射關系。損失函數采用均方誤差損失:
(9)
2.2 遞歸神經網絡語言模型
圖像語義相似性神經網絡中的RNN網絡采用圖2中的結構。把圖像的卷積神經網絡特征WCNN和單詞的詞向量特征Wi投影到p維空間。遞歸神經網絡的各個時刻的輸入是Xi=[WCNN,WST,W1,…,Wn]∈R(n+2)×p,輸出是Xo=[WST,W1,W2,…,WEND]∈R(n+2)×p。WST和WEND表示語句的特殊起始詞和終止詞,語句的最大長度是n。由于傳統的淺層RNN網絡學習能力較弱,為了學習圖像的復雜語義信息,本文從以下三個方面增加網絡深度:
1) 棧式隱層(ST層):可以接受上一時刻隱層狀態輸入的層,增強多尺度時間序列記憶。
2) 普通隱層(CH層):除去棧式隱層之外的隱層,增強當前時刻網絡深度。
3) 輸出層(MO層):在隱層節點和最后的輸出層節點之間添加層,把隱層的輸出投影到輸出空間。

圖2 遞歸神經網絡語言模型
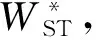
Xi=[WCNN,WST,W1,…,Wn]
(10)
(11)
Xo=[WST,W1,W2,…,WEND]
(12)
采用交叉熵損失函數訓練RNN網絡。在預測階段,采用束搜索算法預測語句。語句的搜索空間是一個有向無環圖,WST是起始節點,WEND是終止節點,每層的大小是束(beam),表示該層單詞的搜索空間,束越大,搜索結果越接近全局最優,計算復雜度是O(beamn)。
sentence=argmaxsP(s|image)
(13)
s表示遞歸神經網絡預測的語句。首先對圖像語義相似性神經網絡進行預訓練,然后在數據集上繼續訓練RNN網絡語言模型。引入相似圖像的語義信息和增強語言模型的學習能力,有利于生成符合圖像內容的通順的語句。
3 實驗結果和分析
3.1 數據集和預處理
本文采用Flickr30K數據集[19]和MSCOCO數據集[20],每幅圖像均有5個獨立的標注語句。Flickr30K數據集包含31 783幅圖像,訓練集、驗證集和測試集大小分別是29 783、1 000和1 000。MSCOCO數據集包含123 287幅圖像,訓練集、驗證集和測試集大小分別是113 287、5 000和5 000。
經典的卷積神經網絡模型包括AlexNet[23]、VGGNet[24]、GoogleNet[25]和ResNet[26]等,本文采用16層的VGGNet提取圖像特征。圖像尺寸縮放為224×224,采用均值歸一化,使得RGB通道的像素均值為0。人工標注的語句長度不固定,大于16的語句分布超過90%,長度閾值取16。大于閾值的語句,多余單詞截斷,小于閾值的語句,末尾用終止字符WEND補全。數據集中出現頻率小于閾值5的單詞為停止詞,去除停止詞后的Flickr30K數據集和MSCOCO數據集的單詞表大小分別為8 625和9 566。
3.2 評價方法和對比方法
本文采用BLEU[14],ROUGE[15],METEOR[16]和CIDEr[17]指標評價圖像的文本化描述效果。原理是比較機器翻譯結果(candidate)和人工翻譯結果(reference)的相似度。BLEU準則比較candidate和reference的n-gram匹配的數量,可以評價生成文本的充分性、保真性和流暢程度。ROUGE準則定義最長公共子序列來計算相似度,序列要求有順序不一定連續。METEROR準則采用精確匹配、詞根詞干匹配和同義詞匹配三種方式計算相似度。CIDEr準則首先計算n-gram的項頻反向文檔頻率TFIDF(Term Frequency-Inverse Document Frequency)[18],然后計算candidate和reference的余弦距離。
本文方法和GoogleNIC[3]、BRNN[4]、Log Bilinear[21]、LRCN[22]、Semantic Attention[27]、Memory Cells[13]、Hard-Attention[12]等方法的實驗結果進行對比。GoogleNIC和BRNN方法均采用三層遞歸神經網絡語言模型,分別用GoogleNet和VGGNet提取圖像特征。Log Bilinear方法采用多模態LBL語言模型學習圖像到文字的映射關系。Semantic Attention方法首先識別圖像屬性,然后輸入到遞歸神經網絡。LRCN方法是一種融合遞歸神經網絡和卷積神經網絡的深度網絡,能夠學習圖像和視頻的文本描述。Memory Cell方法把圖像特征輸入到遞歸神經網絡的每一個時刻。Hard Attention方法采用圖像的卷積層特征,建立圖像子區域和文本單詞的對應關系。
3.3 結果分析
本文分別在Flickr30k數據集和MSCOCO數據集進行實驗。首先訓練圖像語義相似性神經網絡,如圖1,然后訓練遞歸神經網絡語言模型,如圖2。分析不同的棧式隱層、普通隱層和輸出層的組合對生成文本質量的影響,結果如表1和表2,然后和最新的方法進行對比,結果如表3和表4,最后舉例說明本文模型生成文本的效果。
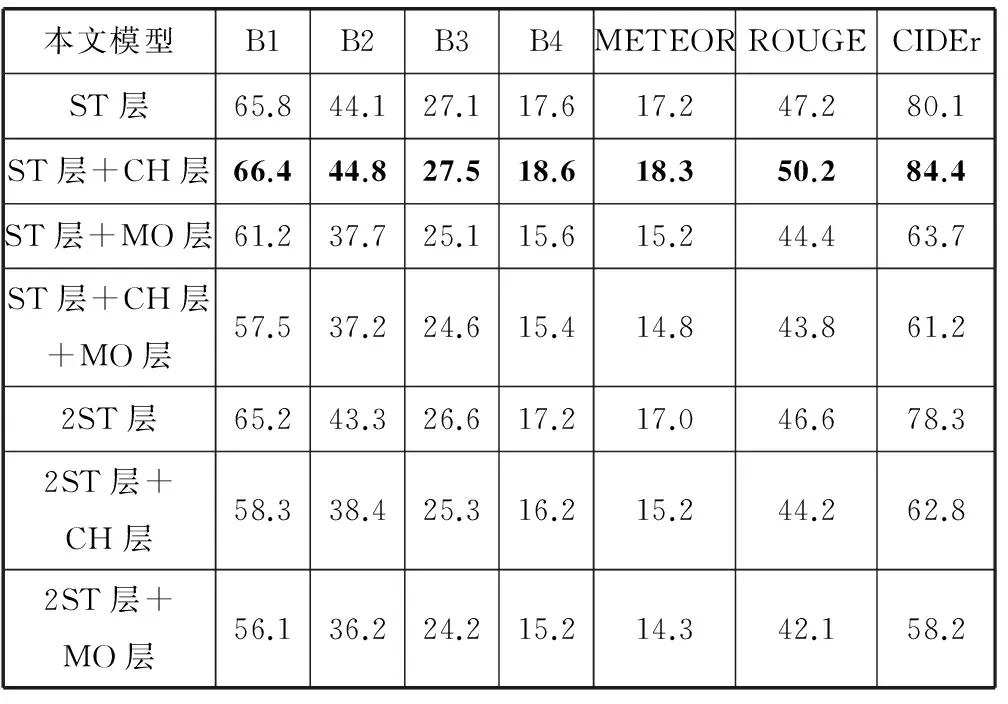
表1 Flickr30k數據集的實驗結果(BLEU-i簡寫為Bi)
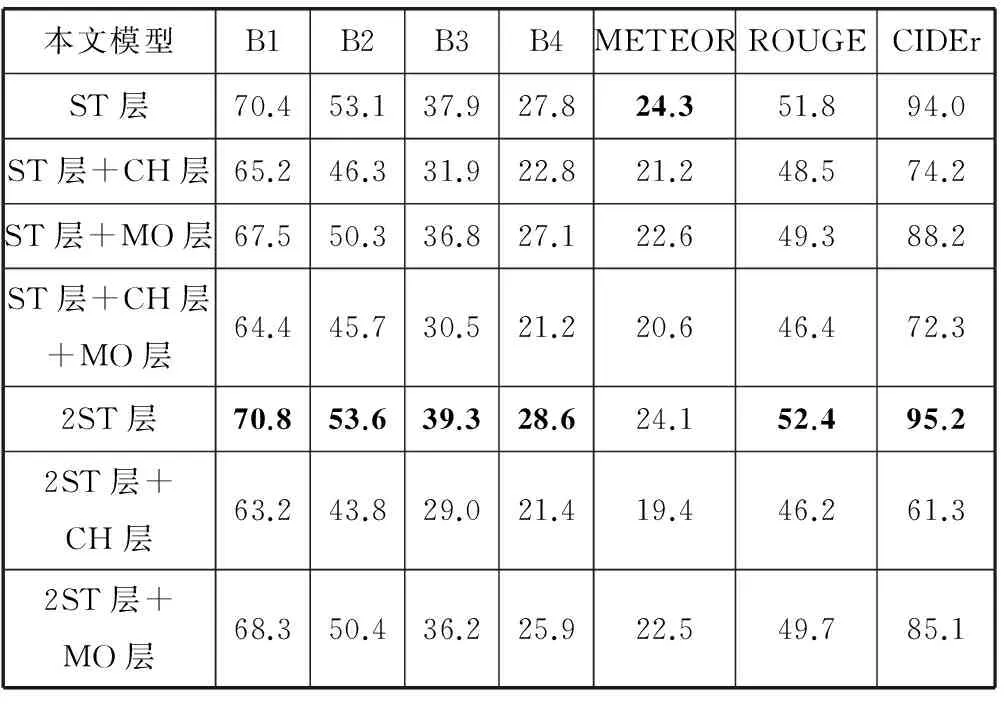
表2 MSCOCO數據集的實驗結果(BLEU-i簡寫為Bi)

表3 本文方法和其他方法在Flickr30k數據集實驗結果對比(BLEU-i簡寫為Bi)
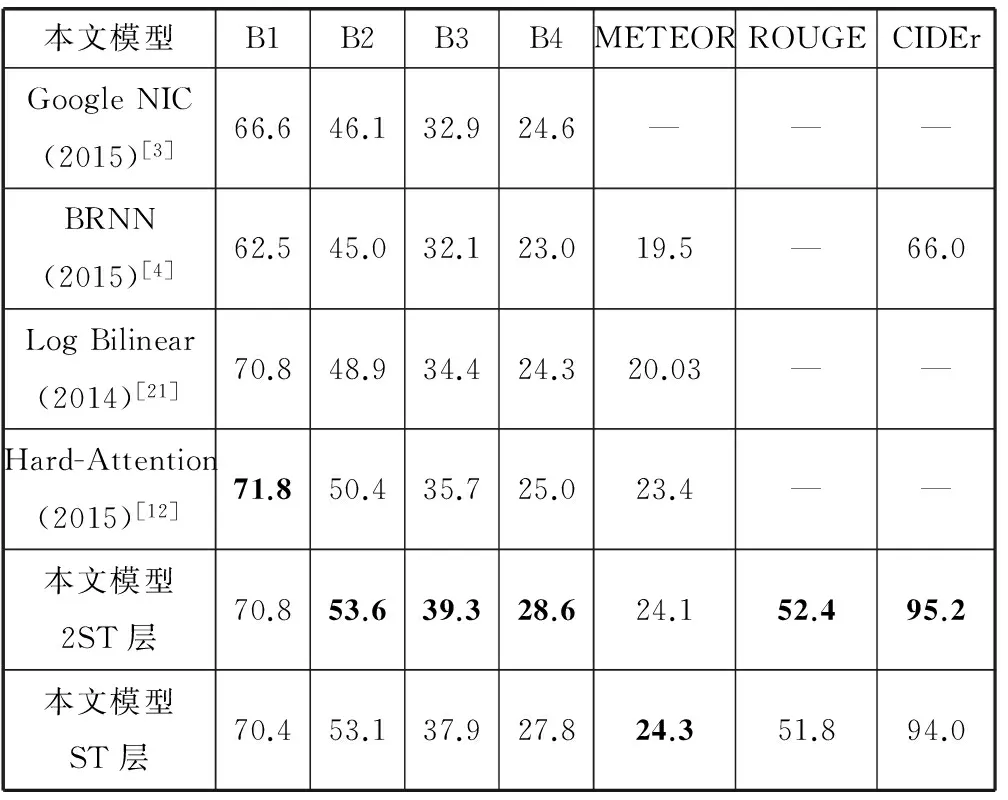
表4 本文方法和其他方法在MSCOCO數據集實驗結果對比(BLEU-i簡寫為Bi)
表1和表2的結果表明,Flickr30k數據集訓練的“模型ST層+CH層”和MSCOCO數據集訓練的“模型2ST層”效果最好,說明增加遞歸神經網絡棧式隱層和普通隱層的深度能夠提高生成文本的質量。棧式隱層負責把信息傳遞到下一時刻,對語言模型生成文本起到關鍵作用。普通隱層只能在當前時刻傳遞信息,適當增加普通隱層能夠提升模型復雜度和學習能力。增加輸出層深度會降低實驗效果。同時隱層總深度不宜太大,否則導致模型復雜度過高和模型訓練困難,降低生成文本的質量。
表3和表4的結果表明,Flickr30k數據集上,本文方法的BLEU-1、ROUGE和CIDEr的得分最高,其他指標略低于Semantic Attention方法。Semantic Attention方法在BLEU-2、BLEU-3、BLEU-4指標較高是因為提取圖像的屬性標簽加入RNN結構中,有利于生成多詞匹配較高的語句。MSCOCO數據集上,“模型ST層”的各項指標超過GoogleNIC和BRNN等方法,“模型ST層”和“模型2ST層”的多項指標均達到最高,其中BLEU-2、BLEU-3、BLEU-4的得分達到53.6、39.3和28.6,顯著超過其他方法,說明了圖像語義相似性網絡可以提供相似圖像的有效語義信息,進而改善文本描述的質量。“模型2ST層”的多項指標均超過“模型ST層”,表明增加隱層深度可以提升語言模型的學習能力,有利于生成更加通順的語句。Hard Attention方法的BLEU-1得分最高,因為考慮單詞和圖像子區域的對應關系,而文本描述的通順程度更加依賴于多詞匹配數量。
圖3是本文方法生成的圖像文本化描述的示例。第一行是錯誤的描述。圖3(a)描述的是兩個人站在飛機旁邊,但是生成的文本是“a man standing next to a plane on a field”,僅僅識別出了一個人。圖3(b)描述的是一個人坐在街道旁,但是生成的文本是“a man sitting on a bench talking on a cell phone”,錯誤的認為一個男人拿著手機。第二行是正確的描述,生成的文本分別是“a cow is standing in a field of grass”和“a man riding a motorcycle down a street”。圖3(a)和圖3(b)生成了錯誤的描述,可能是由于訓練集中缺乏相關類型的數據,并且圖像分辨率較低,陰影部分的內容較難識別。由于圖像語義相似性網絡能夠通過相似圖像的文本描述作為補充信息,因此正確的識別了圖中的主體,例如“man”“plane”,以及動作,例如“standing”“sitting”。

圖3 本文方法的圖像文本化標注示例
4 結 語
本文提出圖像語義相似性神經網絡的圖像文本化描述模型,采用多層復合遞歸神經網絡語言模型。能夠學習到相似圖像的有效語義信息,并通過增加遞歸神經網絡的深度,提高網絡的學習能力,進而提升圖像的文本描述的質量。實驗結果表明,該方法在多個評價指標上均取得很好效果,超過目前的主流方法。
[1] Farhadi A,Hejrati M,Sadeghi M A,et al.Every picture tells a story:Generating sentences from images[C]//European Conference on Computer Vision.Springer Berlin Heidelberg,2010:15-29.
[2] Gong Y,Wang L,Hodosh M,et al.Improving image-sentence embeddings using large weakly annotated photo collections[C]//European Conference on Computer Vision.Springer International Publishing,2014:529-545.
[3] Vinyals O,Toshev A,Bengio S,et al.Show and tell:A neural image caption generator[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3156-3164.
[4] Karpathy A,Fei-Fei L.Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3128-3137.
[5] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems,2012:1097-1105.
[6] Lee Giles C,Kuhn G M,Williams R J.Dynamic recurrent neural networks:Theory and applications[J].IEEE Transactions on Neural Networks,1994,5(2):153-156.
[7] Donahue J,Jia Y,Vinyals O,et al.DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition[C]//ICML.2014:647-655.
[8] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural computation,1997,9(8):1735-1780.
[9] Cho K,Van Merri?nboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[DB].arXiv preprint arXiv:1406.1078,2014.
[10] Kulkarni G,Premraj V,Ordonez V,et al.Babytalk:Understanding and generating simple image descriptions[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(12):2891-2903.
[11] Johnson J,Karpathy A,Fei-Fei L.Densecap:Fully convolutional localization networks for dense captioning[DB].arXiv preprint arXiv:1511.07571,2015.
[12] Xu K,Ba J,Kiros R,et al.Show,attend and tell:Neural image caption generation with visual attention[DB].arXiv preprint arXiv:1502.03044,2015.
[13] Tang S,Han S.Generate Image Descriptions based on Deep RNN and Memory Cells for Images Features[DB].arXiv preprint arXiv:1602.01895,2016.
[14] Papineni K,Roukos S,Ward T,et al.BLEU:a method for automatic evaluation of machine translation[C]//Association for Computational Linguistics,2002:311-318.
[15] Lin C Y.ROUGE:A package for automatic evaluation of summaries[C]//Text summarization branches out:Proceedings of the ACL-04 workshop.2004.
[16] Denkowski M,Lavie A.Meteor Universal:Language Specific Translation Evaluation for Any Target Language[C]//The Workshop on Statistical Machine Translation.2014:376-380.
[17] Vedantam R,Lawrence Zitnick C,Parikh D.Cider:Consensus-based image description evaluation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2015:4566-4575.
[18] Robertson S.Understanding inverse document frequency:on theoretical arguments for IDF[J].Journal of documentation,2004,60(5):503-520.
[19] Young P,Lai A,Hodosh M,et al.From image descriptions to visual denotations:New similarity metrics for semantic inference over event descriptions[J].Transactions of the Association for Computational Linguistics (TACL),2014,2(4):67-78.
[20] Lin T Y,Maire M,Belongie S,et al.Microsoft coco:Common objects in context[C]//European Conference on Computer Vision.Springer International Publishing,2014:740-755.
[21] Kiros R,Salakhutdinov R,Zemel R S.Multimodal neural language models[C]//ICML’14 Proceedings of the 31st International Conference on International Conference on Machine Learning,2014:595-603.
[22] Donahue J,Hendricks L A,Guadarrama S,et al.Long-term recurrent convolutional networks for visual recognition and description[C]//Computer Vision and Pattern Recognition.IEEE,2015:677-691.
[23] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017,60(2):2012.
[24] Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[DB].arXiv preprint arXiv:1409.1556,2014.
[25] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2015:1-9.
[26] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2016:770-778.
[27] You Q,Jin H,Wang Z,et al.Image captioning with semantic attention[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2016:4651-4659.
[28] Tang S,Han S.Generate Image Descriptions based on Deep RNN and Memory Cells for Images Features[DB].arXiv preprint arXiv:1602.01895,2016.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
