基于重大活動突發事件的預警與推演技術
2018-02-08 03:10:47王曉泓
中國人民警察大學學報 2018年1期
關鍵詞:模型
王曉泓
(上海市警衛局,上海 200030)
一、引言
隨著我國國際地位的不斷提升,各類重大活動、重要會議頻繁舉辦。與此同時,國際恐怖活動猖獗,國內社會矛盾凸顯,突發事件頻發,警衛安保任務面臨嚴峻考驗。利用前沿科技,對突發事件處置工作的指揮體系、流程、方法和效果進行科學推演,進而高效處置,確保重大活動順利安全舉辦,既是構建和諧社會的需要,也是警衛安保部門亟須解決的重大課題和國際社會長期關注的焦點問題。
本文遵循重大活動“全方位、大數據、高時效、高可靠”的安全保衛工作總則,針對國內外警衛安保領域所面臨的“立體、動態、智能”預警推演重大技術挑戰,運用物聯網、人工智能、復雜系統仿真及大數據處理等技術,克服在大范圍、復雜時空環境中,對各種警衛安全工作所涉信息全方位動態采集、主動預警和高效處置所面臨的特殊困難,展開“人群—事件—場景—推演”的智能化綜合分析技術攻關,形成自主的技術體系和成套設備,實現重大活動安全保衛工作從“平面、靜態”到“立體、動態”的躍升,為各類重大活動中突發事件的快速反應、科學決策、正確指揮、高效處置提供強有力的技術保障,確保國家安全、社會穩定和經濟發展[1]。
二、面臨的主要技術難題
近年來,我國成功舉辦的2008年北京奧運會、2010年上海世博會、2014年北京APEC峰會、2015年“9·3”抗戰勝利紀念日閱兵等一系列重大活動,具有規格高、規模大、人群多、地域廣、時間長、警衛對象高度集中等特點[2],對其中可能發生的突發事件預警、推演、處置,面臨如下技術難題。
(一)異常目標感知分析
大范圍密集人群場景下,嚴重遮擋和透射畸變嚴重影響目標群的精確提取。同時,原有的目標人群檢測模型只能定位目標群,無法對異常目標人群數目、密集度、集群性、凝聚力等態勢給出有效分析,致使對重大活動與警衛對象的危險評估精準度不高。亟須設計通用性強、高精準的目標人群理解算法框架,顯著提升智能監測系統對特定目標群的態勢感知能力,為異常、可疑、特定目標準確分析判斷提供基礎。
(二)高時效事件預警
重大活動現場覆蓋區域廣闊,警衛目標數量多,相關安保布勤工作時間和空間跨度大。例如,上海世博中心占地面積為6.654公頃,總建筑面積約14萬平方米,僅世博中心建筑體內外就安裝了約800路攝像頭,24小時無間斷工作產生海量視頻數據。重大活動時將會對世博中心周邊幾公里的區域進行布控,則視頻數據量會更大。傳統的視頻智能分析技術缺乏有效手段識別包含多個特定目標的、跨相機的群體協同行為,缺乏表征群體協同行為中事件序列之間相關性的聚類模型,以及事件序列中基元事件之間順序關系和因果關系的激勵模型。亟須研制基于點過程因果推斷的突發事件預測模型,突破大范圍跨域復雜情形下突發事件的提前預警問題。
(三)全信息融合顯示
源自于多路實時視頻的海量圖像信息,以及手機、RFID、GPS、北斗、傳感器、警務通等獲得的大量零散數據,給警衛安保重點區域全場景的整體關聯、綜合調度和全程調度指揮帶來了巨大挑戰。亟須設計以警衛對象、警衛目標和突發事件為尋蹤中心的多維度線索全信息融合顯示平臺,突破分布式監控視頻中目標人群動態信息和孤立動態場景圖像序列在三維圖形場景中的無縫融合,解決警衛安保力量部署全信息直觀展示和事件多粒度觀察的問題,從過去的看得見,到現在的看得懂、將來的看得透[3]。
(四)科學高效動態處置
由于警衛重大活動處突實戰演練組織難度高、經費需求多、社會影響大,尤其是眾多警衛安保目標地處市中心、鬧市區,周邊情況復雜、敏感性高、易擾民,演練不可能成為常態。同時,面向全面實戰模擬的數字推演技術面臨時間瓶頸問題。亟須研究實時環境驅動的動態推演技術,通過設計元胞自動機的驅動源以及計算資源調度智能優化策略,解決警衛重大活動處突工作的最大難點——動態地為突發事件提供科學的、及時的應急預案處置。
三、主要技術體系
針對上述技術難題,重大活動突發事件多維預警與動態推演技術體系設計如圖1所示:
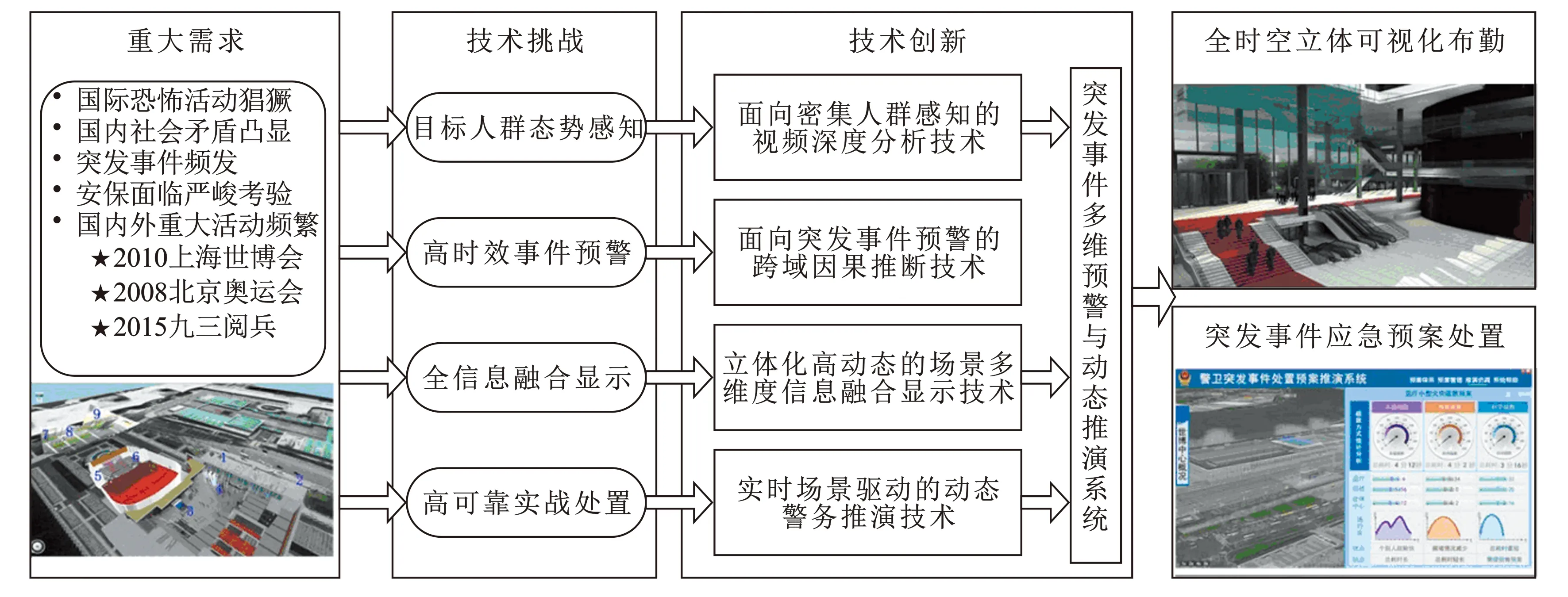
圖1 突發事件多維預警與動態推演技術體系
1.提出面向密集人群感知的視頻深度分析技術,解決復雜、動態場景下對樣本稀疏的特定目標人群自動進行高精準定位以及態勢預測的難題[4]。2.提出面向突發事件檢測的跨域因果推斷技術,保障大范圍、跨域復雜情形下突發事件的提前預警[5]。3.提出立體化高動態的場景多維度信息融合技術,解決警衛安保工作勤務部署全局直觀展示和事件多粒度觀察的問題。4.提出實時場景驅動的動態勤務推演技術,解決重大活動警衛安保工作的最大難點——動態地為突發事件提供科學的、及時的應急預案處置。
四、主要技術創新點
(一)面向密集人群感知的視頻深度分析技術
當應用環境發生變化時,原有的計算機視覺和機器學習方法通常因樣本稀少,導致對目標特征的描述能力不穩定,存在著目標檢測模型對動態場景適應性差的問題。本創新點提出目標視頻樣本多樣性增強方法和具有多層異構神經元結構的大規模視頻深度分析模型,利用目標視頻樣本多樣性增強方法和具有多層異構神經元結構的大規模視頻深度分析模型,解決復雜、動態場景下對樣本稀疏的特定目標群自動進行高精準定位以及態勢預測的難題[6],分述如下:
1.目標視頻樣本多樣性增強方法:對目標圖像關鍵點進行對齊并對關鍵點位置進行擾動,通過采用線性變換、仿射變換、分塊仿射變換等生成新的目標樣本。通過增加樣本的多樣性和訓練量,解決因樣本稀疏導致的目標檢測模型通用性差的問題。
2.多層異構神經元結構的視頻圖像分類模型:采用無監督學習的方式提取包含類間區分性和空間區域性的圖像特征,具備表達圖像和視頻中復雜語義模式的能力,能夠實現對場景類別、目標類別、目標關鍵部位類別的實時同步分析。
3.大范圍目標人群的態勢感知模型:針對特定的目標群體,采用基于大規模密集場景數據驅動的深度學習模型,自動提取對動態變化場景具有普適性的目標群體特征;在該特征空間中,基于特征匹配獲得訓練數據集中相似目標群體的態勢數據,并通過無監督聚類方法獲得目標群體的精確分割,從而實現對當前目標群體的精確定位與態勢預測[7]。
(二)面向突發事件預警的跨域因果推斷技術
重大活動及突發事件的現場覆蓋區域廣闊,涉及的特定目標人群以及協同行為時間空間跨度大,這對目標的檢測、跟蹤和行為識別帶來了極大挑戰。同時,傳統的視頻智能分析技術缺失有效手段實現對異常事件的預測,導致突發事件預警時效性受到極大局限。
通過設計目標的長期跟蹤機制與跨相機的目標重識別機制,提取目標群體協同行為的時空軌跡;在時空軌跡約束下,基于點過程建立表征協同行為中事件序列之間相關性的聚類模型,以及表征事件序列中基元事件之間順序關系和因果關系的激勵模型;基于重大活動安保案例事件庫實現突發事件的聚類分析和激勵模式匹配,解決大范圍跨域復雜情形下突發事件的提前預警問題。
圖2為本創新點提出的面向突發事件預警的跨域因果推斷技術框架,該框架包括基于四元光流和分層卷積特征相關匹配的長期目標跟蹤技術、跨攝像機的重識別技術和基于點過程因果推斷的事件預測等三項創新關鍵技術,分述如下:
1.特定目標的長期穩定跟蹤技術:提取四元數顏色角點,與灰度角點共同構成良好的目標特征點集,采用四元數光流估計算法在目標特征點位置獲得更準確的短期跟蹤結果[8]。同時,提出基于分層卷積特征相關匹配的目標檢測技術,通過跟蹤—學習—檢測的算法框架,解決復雜背景下目標長期跟蹤任務中“跟得上、跟得準”的難題[9]。
2.跨相機的目標重識別技術:針對跨域聯網監控視頻中運動目標的姿態變化、遠近景之間目標尺度的變化,視野盲區和遮擋情形下目標的重新捕獲,采用基于加權陸地距離與步態特征的目標重識別技術,突破了特定目標的跨相機重識別難題[10]。
3.基于因果推斷的事件預測技術:基于點過程建立表征協同行為中事件序列之間相關性的聚類模型,以及表征事件序列中基元事件之間順序關系和因果關系的激勵模型;基于警衛重大活動安保案例事件庫對突發事件進行聚類分析和激勵模式匹配,解決大范圍跨域復雜情形下突發事件的提前預警問題。
(三)立體化高動態的場景融合技術
警衛重大活動安保工作面臨著大量孤立的視頻源時空不連續,無法展現整體場景的問題。同時,缺乏有效手段直觀展示安保力量部署的全部線索信息,難以針對警衛對象、警衛目標和突發事件進行預演分析,實現指揮防控體系的高效運作。亟須突破以警衛對象和警衛目標為中心的多維度線索融合技術。
通過將分布式監控視頻中目標人群的動態信息和孤立動態場景圖像序列與三維圖形場景進行無縫融合,實現了從孤立的分鏡頭畫面到以警衛對象、警衛目標和突發事件為尋蹤中心的全景全信息融合顯示的飛躍,解決了警衛安保力量部署全信息直觀展示和事件多粒度觀察的問題[11]。
圖3為利用本創新點實現的全時空多維線索可視化展示平臺,該平臺需要兩個關鍵技術的支撐,分述如下:
1.穩健的全景圖像拼接技術:全景視頻圖像拼接融合到三維虛擬場景數據中,即可實現全時空高動態場景展示。多個監控相機捕捉到的多視點視頻圖像,通常存在重疊區域小、特征點稀疏、雜亂背景干擾等現象,采用全局外觀一致性約束優化局部特征點匹配結果,攻克了關鍵點特征匱乏以及局外點干擾顯著情形下的圖像匹配難題,顯著提高了全景圖像拼接的精確度[12]。

圖2 面向突發事件預警的跨域因果推斷技術框架

圖3 全時空多維線索可視化展示平臺
2.多維信息融合顯示技術:基于相機標定技術,建立視頻圖像數據和三維場景空間的坐標變換關系,將實時采集的動態視頻數據拼接融合到三維場景的空間數據中,實現全景立體視頻顯示,并將多種傳感器信息、目標人群動態信息、事件預警信息等整合到全景立體視頻中,以實現全方位的多維信息融合展示。
(四)實時場景驅動的動態勤務推演技術
重大活動安保工作的難點之一在于對全局資源的合理調派,以及全面的實戰模擬可行性低。亟須開發實時場景驅動的動態推演軟件系統,實現對突發事件的快速決策、高效組織和科學處置。
根據突發事件實際特性及周邊環境設計元胞自動機的前端輸入和驅動源[13],并采用資源調度智能優化策略對動態目標人群以及重點安保目標快速建立高分辨率的、精準的仿真推演模型,突破了全面實戰模擬的時間瓶頸,解決了重大活動警衛安保工作的最大難點——動態地為突發事件提供科學的、及時的應急處置預案。
圖4為利用本創新點實現的實時環境驅動的動態推演系統,該系統包括大規模三維場景的高效渲染技術、疏散自動模型技術和多源異構數據交互技術等三項創新關鍵技術,分述如下:
1.大規模三維場景的高效渲染技術:通過將三維模型無縫集成到矢量地形場景中,以及對地形分層分塊集合的效率優化繪制,實現對大規模三維場景的高效渲染,獲得最佳的虛擬實現效果。
2.多源異構數據交互技術:通過空間因子耦合建立起各模型參數在各空間觀測尺度間的映射關系及時間因子耦合的重采樣或插值實現各模型之間不同時間分辨率下數據的轉換,來突破異構環境下多源實體數據的同步交融問題,確保各實時環境變化量的相互通信和協作,作為動態推演的前端驅動。
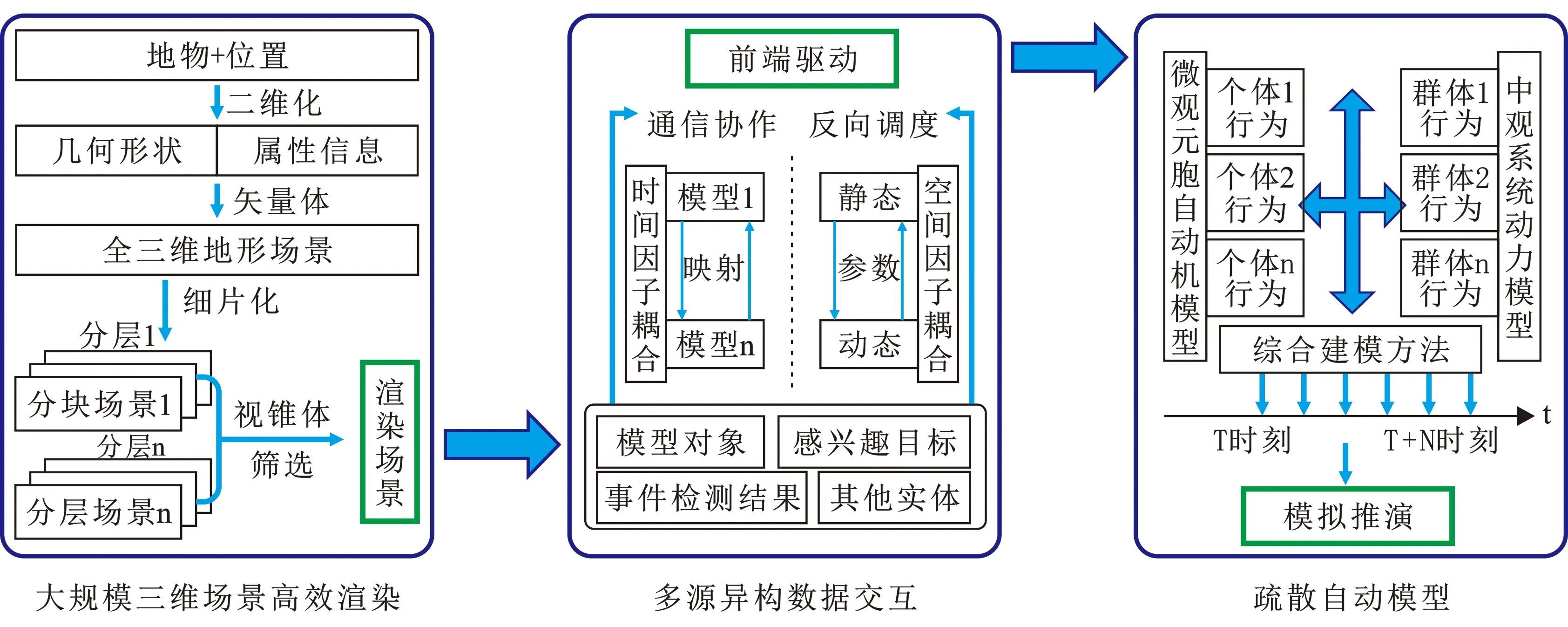
圖4 實時環境驅動的動態推演系統
3.疏散自動模型技術:利用自主核心的疏散模型,結合三維場景,在微觀和中觀層面研究不同對象在各種復雜環境下的人群群體性運動規律。所有微觀個體根據局部環境自行決策如何運動,但受中觀人群數學模型的控制,并通過適時調節微觀及中觀建模占比,來達到實效性計算的平衡[14]。在此結果基礎上,結合三維場景建立各類模擬疏散、排兵布陣推演模型。
五、結束語
基于上述技術和設備,成功研制“突發事件預警系統”“全時空立體可視化布勤系統”“警衛重大活動突發事件處置預案推演系統”三個應用系統,應用范圍涵蓋公共安全管理、國內反恐工作、突發事件應急指揮、重大活動警衛安保勤務部署等多個領域,研發成果被上海市政府授予科技進步二等獎。今后重點研究方向是:如何拓展監控視頻深度分析技術,能夠實現密集人群的意向性可能狀態屬性的預測,在應用領域更具挑戰性的大群體、弱環境情況下進行動態推演。大群體將使計算量突變,需要從宏觀層面適配大群體演化算法,再調整中觀和微觀的算法占比,使模擬和推演的時效性更高。
[1] 國務院.國家突發公共事件總體應急預案[Z].2006-01-08.
[2] 王曉泓.上海世博會警衛勤務信息系統建設與應用[J].武警學院學報,2012,28(7):15-17.
[3] YAN Qing, XU Yi, YANG Xiaokang.Separation of weak reflection from a single superimposed image[J]. IEEE Signal Processing Letters,2014,21(10):1173-1176.
[4] ZHANG Cong, KANG Kai, LI Hongsheng, et al. Data-driven crowd understanding: a baseline for a large scale crowd dataset[J]. IEEE Trans on Multimedia,2016:1-15.
[5] ZHU Jun, WANG Baoyuan, YANG Xiaokang, et al. Action recognition with actions[C]. Proc of IEEE International Conference on Computer Vision.2013:3559-3566.
[6] MA Lianyang, YANG Xiaokang, XU Yi, et al. Generalized EMD with body prior for pedestrian identification[J]. Journal of Visual Communication and Image Representation,2013,24(6):708-716.
[7] CHEN Erkang, XU Yi, YANG Xiaokang, et al. Robust event detection scheme for complex scenes in video surveillance[J]. Optical Engineering,2011,50(7):1-9.
[8] CHEN Erkang, XU Yi, YANG Xiaokang, et al. Quaternion based optical flow estimation for robust object tracking[J]. Digital Image Processing,2013,23(1):118-125.
[9] MA Chao, YANG Xiaokang, ZHANG Chongyang, et al. Long-term correlation tracking [C]. IEEE Conference on Computer Vision and Pattern Recognition.2015:5388-5396.
[10] ZHANG C, WANG X G, YANG X K. Cross-scene crowd counting via deep convolutional neural networks[C]. IEEE Conf on Computer Vision and Pattern Recognition.2015:833-841.
[11] ZHU Jun, WU Tianfu, ZHU S C, et al. A reconfigurable tangram model for scene representation and categorization[J]. IEEE Transactions on Image Processing, 2015,25(1):150-166.
[12] XU Yi, YU Licheng, XU Hongteng, et al. Vector sparse representation of color image using quaternion matrix analysis[J]. IEEE Trans on Image Processing,2015,24(4):1315-1329.
[13] 郭玉榮,郭磊,肖巖.基于元胞自動機理論的緊急人員疏散模擬[J].湖南大學學報(自然科學版),2011,38(11):25-29.
[14] ZHAO J, XU Y, YANG X, et al. Crowd instability analysis using velocity-field based social force model[C]. Visual Communications and Image Processing(VCIP).2011:1-4.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
