基于Hive的大數據在線分析處理
2018-01-26 16:04:13陳耀旺朱寧施揚朋
計算機時代 2018年1期
陳耀旺+朱寧+施揚朋
摘 要: 隨著傳統行業與互聯網的快速匹配,企業面對大量堆積的業務數據和用戶數據而無從下手,用戶的查詢需求也越來越復雜且涉及跨庫、跨表的大數據量綜合分析查詢,傳統關系型數據庫的方式已無法滿足企業大數據在線分析處理的要求。文章提出基于Hive的大數據在線分析的系統架構,研究數據倉庫的主題構建、多維分析以及數據可視化的綜合分析處理方案,滿足在線查詢分析結果的用戶需求,相比于傳統數據庫的OLAP方案,查詢的時間效率得到顯著提升。
關鍵詞: Hadoop; Hive; 數據倉庫; 在線分析
中圖分類號:TP399 文獻標志碼:A 文章編號:1006-8228(2018)01-01-03
Online analytic processing of big data based on Hive
Chen Yaowang1, Zhu Ning2, Shi Yangpeng2
(1. Hangzhou Dianzi University·School of Computer, Hangzhou, Zhejiang 310018, China; 2. Zhejiang Topcheer Information Technology Co., Ltd)
Abstract: Along with the traditional industry and the Internet fast matching, enterprises face large volumes of business data and user data but cannot handle, the user's query requirements are more and more complex and involve comprehensive analytical query of large cross-database data, the traditional way of using relational database has been unable to meet the requirements of enterprises online analysis and processing. In this paper, the system architecture of online data analysis based on Hive is proposed. The theme building and multidimensional analysis of data warehouse, and the comprehensive analysis of data visualization are studied to meet the needs of online query and analysis of the results. Compared with the OLAP of traditional database, the query time efficiency has been significantly improved.
Key words: Hadoop; Hive; data warehouse; online analysis
0 引言
隨著傳統行業與互聯網的快速匹配,運營模式迭代更新與用戶量的飛速增長,企業面對大量堆積的業務數據和用戶數據無從下手,在處理TB級別以上的數據,傳統的關系型數據庫在擴展性方面有一定的局限性,對于企業海量數據的存儲和在線分析的需求已經無法滿足,這是各行各業急需解決的問題。
1 現狀分析
隨著數據庫的廣泛應用,企業的數據海量增長,用戶的查詢需求也越來越復雜且涉及跨庫跨表的大數據量的綜合分析查詢。同時數據倉庫和商業智能(DW/BI)行業[1]逐漸成熟,商業智能主要是數據倉庫、多維分析技術[2]、可視化技術的綜合應用。
聯機分析處理(OLAP)是數據倉庫[3]系統重中之重的應用技術,用于服務繁瑣的分析操作,按照決策者的業務需求,從初始的數據轉換到能夠展現企業真實面貌的多維特性數據,使用戶能準確、迅速、一致的從多角度對信息和數據進行分析處理,并且能夠依據主題構建多維查詢,靈活準確的進行大數據處理,直觀清晰的展現給決策人員所需的查詢處理結果,以便可以直觀準確的把握企業各方面的現狀。目前的離線數據的解決方案是在Hive數據倉庫的基礎上的多維分析系統,將多維分析操作利用HQL語句轉化成Map/Reduce任務運行以后得到分析結果。
大數據技術不局限于結構化數據,它能處理各種非結構化和半結構化數據,并且整個過程都是基于分布式存儲的數據進行分析,Hadoop以及全部hadoop生態系統也給商業智能供應了一套完備的、高效率的解決方案。雖然基于 hive 的數據倉庫可用于離線數據的處理,但對于在線數據處理存在查詢速度較慢的問題,以及如何解決查詢分析結果的實時顯示,使企業能快速的從海量數據中得到數據各個維度的分析結果,這是本文需要解決的問題。
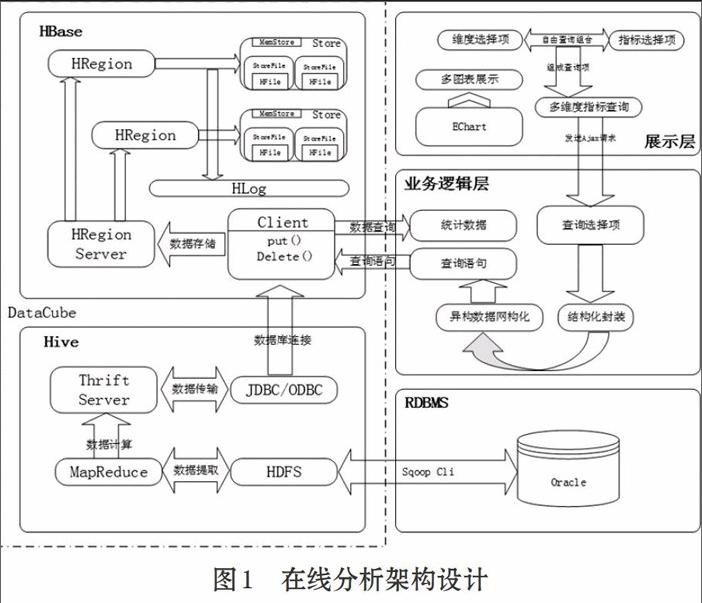
2 在線分析架構設計
基于對大批量數據統計和分析的考慮,選用建立在hadoop生態圈[4]上的Hive作為數據倉庫,它提供了一些用于對hadoop文件中的數據集進行數據過濾、特殊查詢和分析存儲的工具。Hive提供的是一種結構化數據的機制[5-6],可以將結構化的數據文件映射為一張數據庫表,并提供完整的sql查詢功能,可以通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析,但Hive的執行速度慢,不能支持用戶實時的查詢,所以在Hive的基礎上結合使用HBase。endprint
基于用戶對統計分析結果[7]快速展示在頁面上的考慮,選用了HBase數據庫,它是一個分布式、面向列的開源數據庫,能提供低延遲的數據庫訪問。它能提供實時計算服務主要原因是由其架構和底層的數據結構決定的,即由LSM-Tree(Log-Structured Merge-Tree)+HTable(region分區)+Cache決定的,客戶端可以直接定位到要查數據所在的HRegion server服務器,然后直接在服務器的一個region上查找要匹配的數據,并且這些數據部分是經過cache緩存的。讀取速度快是因為它使用LSM樹型結構,而不是B或B+樹。磁盤的順序讀取速度很快,但是相比而言,尋找磁道的速度就要慢很多。HBase的存儲結構將磁盤尋道時間控制在可預測范圍內,并且讀取與所要查詢的rowkey連續的任意數量的記錄都不會引發額外的尋道開銷。故選用HBase作為實時查詢統計分析后的結果。
數據處理采用Ajax+Servlet進行前后端交互,Hive技術用于對海量的原始數據進行ETL處理,并將分析結果存入HBase數據庫中,HBase數據庫用于實時查詢統計結果返回前臺。具體架構設計如圖1所示。
本文數據可視化采用EChart前端框架,能夠生成包括曲線圖、區域圖、柱狀圖、餅狀圖、散狀點圖在內的多種動態圖表[8],清晰鮮明地展現數據內容指標。數據處理采用Hive預處理+HBase實時查詢的方式,首先利用后臺離線操作將hive中的數據進行ETL處理,對原始數據進行主題的維度項與指標項的CUBE構建分析,并得出結果存入HBase數據庫中,然后提供在線實時查詢,即從HBase數據庫中提取所需的統計信息返回前臺展示,并且響應時間能夠達到毫秒級,因此可以帶來良好的用戶體驗。
3 ETL處理與DataCube構建
ETL是數據抽取(Extract)、清洗(Cleaning)、轉換(Transform)、裝載(Load)的過程。用戶從數據源抽取出所需的數據,需要對導入的數據進行數據清洗工作,對數據進行去重,清除錯誤的、無關的數據,清除相關表中與主題無關的多余列,將多表連接成最大維度的事實表,最終按照預先定義好的數據倉庫模型,將數據加載到hive數據倉庫。Hive沒有專門的數據存儲格式,只需要在創建表的時候告訴Hive數據中的列分隔符和行分隔符,Hive 就可以解析數據。Hive中所有的數據都存儲在 HDFS 中,Hive中包含以下數據模型:表(Table),外部表(External Table),分區(Partition),桶(Bucket) [9]。
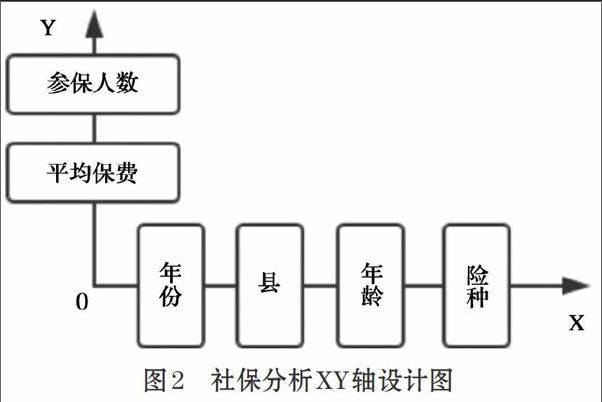
本文選定某省人力社保系統的數據集,異地系統中單表數據量級為百萬級,需統計的表數為十多張,因此,異地系統總的數據量為千萬級別[10]。通過業務問題分析得到多維分析的維度:年份、縣、年齡、險種、參保人數、平均保費。XY軸設計,如圖2所示,X軸:年份、縣、年齡、險種,Y軸:參保人數、平均保費。
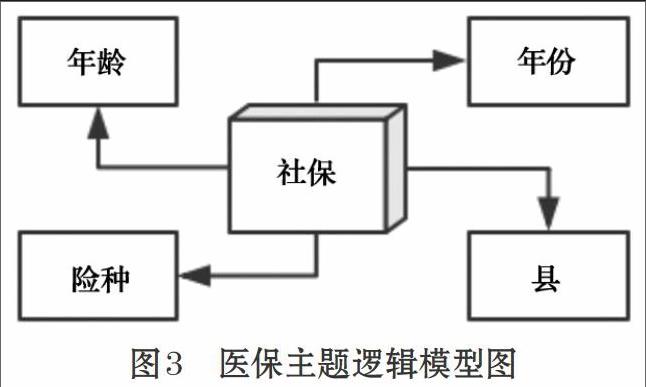
事實表與維度表以最典型的星型模型進行關聯構建,是為事實表為中心,維度表向外擴散的幾個角度,通過關鍵字來聯系。如圖3所示。
經過ETL數據處理和主題構建,實驗采用四條SQL查詢語句進行對比操作,具體語句如表1。
實驗采用3臺物理機測試,配置如下:Intel(R) Core (TM) i7-4500u 1.8GHz,內存4.0GB,操作系統是,Master和Slave節點均使用ubuntu12.04,hadoop2.2.0、HBase0.96.0、hive0.13.0,JDK1.7.0,2G數據量。進行Hive與oracle數據庫查詢測試對比,隨著查詢的字段及分組(Group)操作的字段增加,查詢時間效率的差別顯著。如表2及圖4的對比結果。
因為通過DataCube的構建,查詢分析結果保存在HBase中,經過測試,首次業務操作界面響應速度在6秒以內,之后業務普通查詢、跨多表綜合查詢的業務操作界面響應速度均在 0.05秒以內。
4 結束語
本文基于Hive的技術特點,進行數據處理和構建多維數據的主題,采用HBase數據庫存儲分析結果,滿足實時展現的需求。實驗表明,在Hive上構建多維數據主題后的數據倉庫對比Oracle數據庫,查詢效率得到顯著提升,并且HBase的響應時間能夠達到毫秒級,因此可以帶來良好的用戶體驗。
參考文獻(References):
[1] 范東來.Hadoop海量數據處理[M].人民郵電出版社,2015.
[2] 沙倩.基于云平臺的多維數據分析的研究與應用[D].北京郵
電大學,2013.
[3] (美)金博爾(Kimball, R.),(美)羅斯(Ross).數據倉庫工具箱[M].
清華大學出版社,2015.
[4] 陸嘉恒.Hadoop實戰[M].機械工業出版社,2011.
[5] 唐榕蔚.基于HIVE電子商務多維分析技術應用研究[D].北方
工業大學碩士學位論文,2015.
[6] Hu P. The Cooperative Study Between the Hadoop Big
Data Platform and the Traditional Data Warehouse[J]. Open Automation & Control Systems Journal,2015.7(1):1144-1152
[7] 吳明禮,唐榕蔚,李也白.基于HIVE面向多企業的經營分析
技術應用研究[J].工業技術創新,2014.5:609-613
[8] 左譜軍,朱曉民.基于Hive的數據管理圖形化界面的設計與
實現[J].電信工程技術與標準化,2014.1:89-92
[9] Thusoo A, Sarma J S, Jain N, et al. Hive: a warehousing
solution over a map-reduce framework[J].Proceedings of the Vldb Endowment,2010.2:1626-1629
[10] 秦玉蘭.基于HIVE的海量數據報表服務系統的設計與實現[D].北京郵電大學碩士學位論文,2014.endprint
