2.25階/2.5階網絡零模型模擬退火優化算法
2018-01-23 07:14:02宋玉蓉
計算機技術與發展 2018年1期
關鍵詞:模型
吳 睿,宋玉蓉
(南京郵電大學 自動化學院,江蘇 南京 210023)
1 概 述
通常,將具有與實際網絡給定階次度相關特性的隨機網絡稱為該實際網絡的隨機化網絡,這類隨機化網絡模型在統計學上稱為零模型。Mahadeven等[1]為了從粗糙到精確逐步逼近真實網絡的性質,按照約束條件從少到多,將零模型的階次依次從低階到高階(0階至3階)進行了定義。不同階數網絡零模型之間并不是獨立的,按照約束條件從少到多,存在一種包含關系,即任何一個d階零模型都會包含d-1階零模型的性質。通過原始網絡(即實際網絡)與不同階次的零模型的比較,就可以檢測到實際網絡中一些性質的來源。
零模型生成方法有兩種:網絡模型方法和隨機置亂方法。基于網絡模型[2-4]生成零模型是一個從無到有生成新網絡的過程,熟知的ER隨機圖[5]、WS小世界網絡[6]、BA模型[7]、配置模型[8-9]等都可以視為網絡模型方法。ER隨機圖可以視為階數最低的0階零模型(與原始網絡具有相同的平均度),而配置模型可生成1階(與原始網絡具有相同的度分布)、2階(與原始網絡具有相同的聯合度分布)或更高階零模型。基于隨機置亂生成零模型是將實際網絡進行隨機斷邊重連[10-11],在保持原有連接的前提下隨機化某些因素。這種方法可以產生0至2.5階網絡零模型。Gjoka等[12]認為3階網絡零模型要求與原始網絡具有相同的聯合邊度分布,其約束條件已經很多,不具備實用性;2.25階零模型與原始網絡具有相同的聯合度分布和平均聚類系數;2.5階零模型與原始網絡具有相同的聯合度分布和聚類譜,是現在能夠實現的最高階的實用零模型。
2.25階和2.5階零模型對研究網絡的聚類特性有著重要作用。聚類特性作為一個重要的拓撲特性,對復雜網絡上的動力學行為[13-15]影響顯著。例如,有研究表明[2,16-17],高聚類網絡可抑制病毒傳播;Kim[18]等對神經網絡的研究發現,網絡的計算功能更多取決于聚類系數而不是度分布,且低聚類網絡的性能優于高聚類網絡。
網絡中三角形的數量對聚類系數的變化有重要影響,通常三角形數量越多,聚類系數越大。文獻[19]基于配置模型思想,根據固定的度序列與聚類譜,對一個只有節點的網絡進行添邊,生成指定度分布和聚類譜的網絡模型。進行添邊時主要依靠對三角形數量的控制。該算法無法控制同配系數,因此聯合度分布會不同。
Bansal等[20]結合隨機重連算法和馬爾可夫鏈生成指定度分布和聚類系數的隨機網絡模型,簡稱ClustRNet算法。該算法從隨機選擇的節點入手,從該節點的鄰居節點中隨機選擇兩條邊進行斷邊重連,確保有三角形生成,但也可能破壞現有三角形。該算法復雜度為O(M2),其中M為網絡邊數,該算法不能保證生成指定的聯合度分布。
Gjoka等[12,22]評價文獻[21]中的算法生成2.5階零模型是不切實際的,雖然一開始會生成許多新三角形,但同時很可能破壞了更多已有三角形,此外因約束條件限制,導致該算法重復率很高,得到與原始網絡相等的聚類譜的概率是很小的。為此,Gjoka等[12,22]對Mahadevan等[21]構造2.5階零模型的隨機重連算法進行了改進(MCMC改進算法):交換連邊時更傾向于選擇包含較少三角形的連邊,在此理論基礎上能夠更少地破壞已有三角形,生成更多新三角形。為生成更多三角形,達到目標聚類譜,該文獻對節點采樣生成了聯合度分布和度相關的聚類系數的有效估計量并成功構建了2階零模型網絡和2.5階零模型網絡。
在國內學者的研究中,文獻[23-24]很好地總結了現有一些零模型構造算法及其應用。文獻[25]針對生成的0階、1階、2階網絡零模型,提出了基于GPU的大尺度網絡零模型分組生成并行算法。
為此,提出了一種生成2.25階、2.5階零模型的優化算法:dK-目標保持重連算法(d代表階數,K代表度相關性)。該算法改進了Hamiltonian函數[26],并結合了模擬退火算法[27]和Metropolis準則。運用現有算法如dK-隨機重連算法[21](d=0,1,2)生成所需2階零模型,在2階零模型基礎上應用所提出的算法,生成與真實網絡具有相同的聯合度分布和聚類系數/聚類譜的2.25階/2.5階零模型。最后通過實驗對該算法進行驗證。
2 零模型生成算法及模擬退火算法
2.1 dK隨機重連算法
靜態無權網絡中最常用的就是使用隨機重連來產生復雜網絡零模型。隨機重連的方法主要是在原始網絡的基礎上將網絡中原有的連邊隨機地斷開重連,使原始網絡模型盡可能隨機化。由于隨機重連算法簡單、易操作,不需要理解和運用復雜的數學公式、也不會產生自環和重邊現象,卻能精確保持真實網絡的一些物理屬性,因此廣泛應用于實際各種類型的網絡分析中。
d=0:隨機去除原始網絡的一條邊(i,j),再隨機選擇網絡中兩個不相連的節點a和b,并在它們之間添加一條連邊(a,b)。
d=1:隨機選擇原始網絡中的兩條邊(i,j)和(a,b),如果這四個節點之間只有這兩條邊,那么就去除這兩條邊,并將節點a和j相連、節點b和i相連,從而得到兩條新邊(b,i)和(a,j)。
d=2:隨機選擇原始網絡中的兩條邊(i,j)和(a,b)并且ka=ki(節點a和i度值相同),如果這四個節點之間只有這兩條邊,那么就去除這兩條邊,并將節點a和j相連、節點b和i相連,從而得到兩條新邊(b,i)和(a,j)。
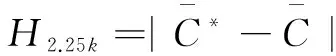
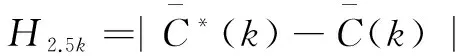
2.2 模擬退火算法
模擬退火算法來源于固體退火原理,將固體加溫至充分高,再讓其徐徐冷卻。加溫時,固體內部粒子隨溫升變為無序狀,內能增大,而徐徐冷卻時粒子漸趨有序,在每個溫度都達到平衡態,在常溫時達到基態,內能減為最小。
根據Metropolis準則:假設在狀態xold時,系統受到某種干擾而使其狀態變為xnew。與此相對應,系統的能量也從E(xold)變為E(xnew),系統由狀態xold變成xnew的接受概率p表示為:
p=
(1)
粒子在溫度T時趨于平衡的概率p為exp(-ΔE/kT),其中E為溫度T時的能量,ΔE為其改變量,k為Boltzmann常數。用固體退火模擬組合優化問題,將改變量ΔE模擬為目標函數值ΔH,溫度T演化成控制參數t,即得到解組合優化問題的模擬退火算法:由初始解i和控制參數初值t開始,對當前解重復“產生新解→計算目標函數差→接受或舍棄”的迭代,并逐步衰減t值,算法終止時的當前解即為所得近似最優解。這是基于蒙特卡羅迭代求解法的一種啟發式隨機搜索過程。
退火過程由冷卻進度表(Cooling Schedule)控制,包括控制參數的初值T0及其衰減因子Δt、每個t值時的迭代次數N和停止條件S。模擬退火算法是一種通用的優化算法,理論上算法具有概率的全局優化性能,目前已在工程中得到了廣泛應用,諸如VLSI、生產調度、控制工程、機器學習、神經網絡、信號處理等領域。
3 2.25階、2.5階零模型優化算法
為了用更少的迭代次數得到隨機化更徹底的聚類網絡(d=2.25,2.5),在使用dK-隨機重連算法(d=0,1,2)的基礎上結合模擬退火算法,提出了dK-目標保持重連算法(d=2.25,2.5)。
該算法具體步驟為:
Step1:設置初始參數。首先,從隨機重連算法所述過程中得到的2階零模型作為初始網絡G0,并令其為目標優化網絡。
設置優化目標誤差值為He,系統初始溫度T0,用于控制降溫的快慢參數γ,同一溫度內的網絡未更新次數上限α,溫度的下限Tmin。
Step2:計算G0與真實網絡Gv關于聚類系數和聚類譜的Hamiltonian改進函數。
(1)關于聚類系數,即2.25階:
(2)
(2)關于聚類譜,即2.5階:
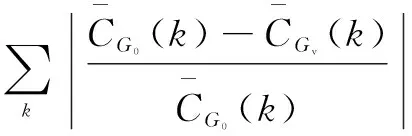
(3)
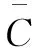
Step3:對G0網絡執行隨機斷邊重連算法,即從G0中隨機選擇兩條邊(u,v)和(x,y)且有ku=kx;變換連邊,得到包含新邊(u,y)和(x,v)的新網絡Gn;
依據式(2)和式(3)計算Hn/Hkn。
Step4:令
ΔH=|Hn-H0|
(4)
或
ΔHk=|Hkn-Hk0|
(5)
計算網絡更新概率:
(6)
或
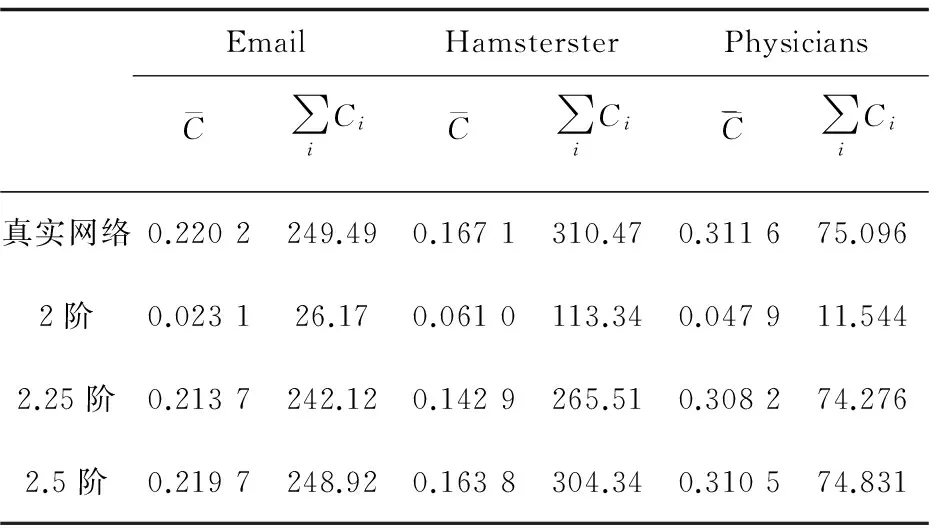
(7)
以概率p/pk更新G0網絡及相關參數,即令G0=Gn,H0=Hn或Hk0=Hkn。
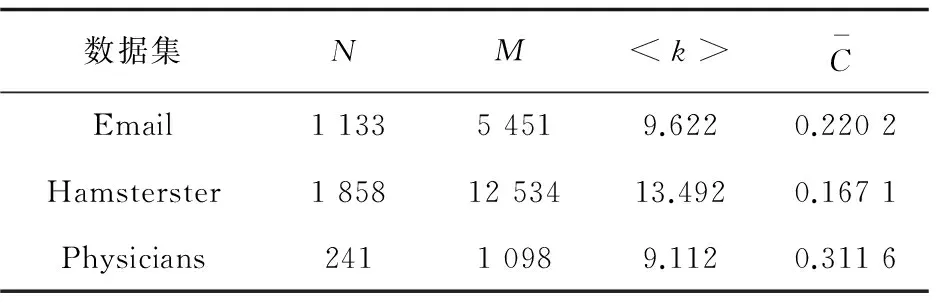
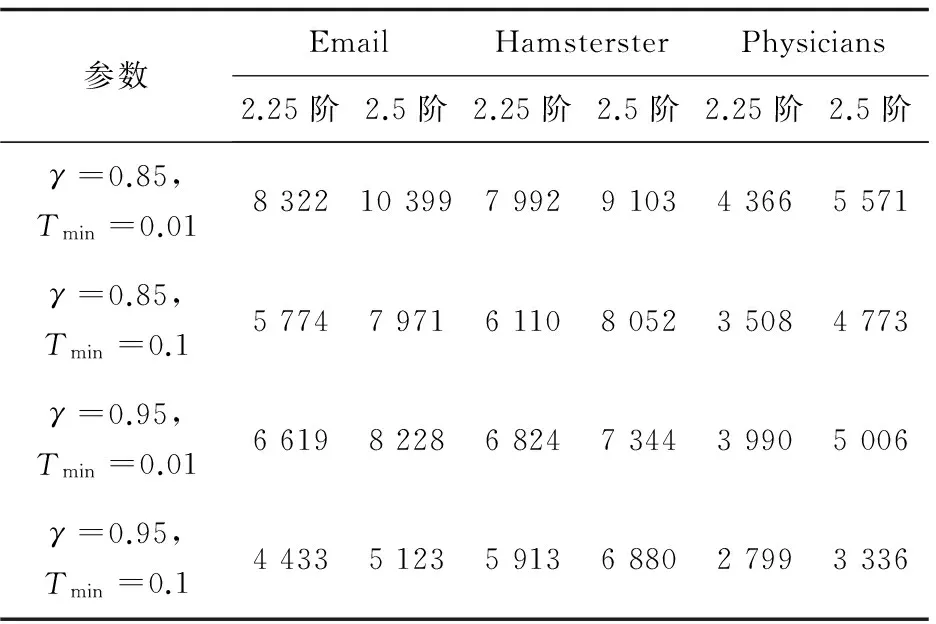
若H0 Step5:如果連續α次網絡未獲得更新,重復Step3和Step4,否則轉到Step6。 Step6:降溫過程: Tk=T0×γ (8) 若達到終止溫度Tk Step7:輸出G0,即為得到的2.25階或2.5階零模型網絡。 實驗選取三個無權無向的真實網絡。其網絡名稱、數據規模、具體統計參數如表1所示。 表1 真實網絡的具體統計參數 本算法需設置系統初始溫度T0,用于控制降溫的快慢參數γ,溫度的下限Tmin,優化目標誤差值He,同一溫度內的網絡未更新次數上限α。 系統初始要處于一個高溫的狀態,因此T0設為100。將He設為0.02,α設為8。 參數γ的設置很重要,若γ過大,則搜索到全局最優解的可能會較高,但搜索的過程也就較長;若γ過小,則搜索的過程會很快,但最終可能會達到一個局部最優值。對比分析了γ分別取0.85和0.95,終止溫度Tmin分別取0.01和0.1時,生成2.25階和2.5階零模型時所需要的迭代次數。結果如表2所示,可以看到算法在取γ=0.95,Tmin=0.1時迭代次數最少,效果最好。 表2 算法參數設置對迭代次數的影響 運用dK-目標重連算法生成了2.25階和2.5階零模型后,統計出表3中每個真實網絡生成的四個網絡模型的平均聚類系數和聚類系數總和,以便于對算法誤差率進行分析。 表3 三個真實網絡及各階零模型(d=2,2.25,2.5)聚類系數分析 接著,通過仿真分別對三個真實網絡的聚類譜與2.25階和2.5階零模型網絡的聚類譜進行了對比分析,以驗證本算法生成的2.5階零模型的有效性和準確性。仿真結果如圖1所示。 圖1 生成的2.25階和2.5階零模型與真實網絡聚類譜的比較分析 從圖1可以看出,三個真實網絡的聚類譜分布均和本算法生成的對應網絡的2.5階零模型聚類譜分布幾乎重疊,與2.25階零模型聚類譜相差明顯。仿真結果表明,本算法生成的2.5階零模型具有較高的準確率和有效性。 將MCMC算法[21]、MCMC改進算法[12]和ClustRNet改進算法[20]以及文中提出的算法就算法復雜度進行對比。這些算法在生成2.25階/2.5階模型時都是建立在MCMC算法生成的同一2階零模型的基礎上進行迭代后獲得。 特別說明,由于ClustRNet算法[20]不能保證生成指定的聯合度分布,故對該算法進行一些必要的修改,將馬爾可夫鏈中的度分布信息設置為聯合度分布,以保證生成的2.25階、2.5階模型的聯合度分布與真實網絡相同。該算法重新命名為ClustRNet改進算法。 經過多次實驗,使MCMC改進算法[12]和ClustRNet改進算法[20]與文中提出的算法得到的2.25階、2.5階零模型聚類系數與真實網絡的目標誤差He控制在0.02范圍內。而MCMC算法在生成2.25階時He為0.02,2.5階時He為0.1。四種算法的迭代次數如圖2所示。 圖2 2.25/2.5階零模型算法復雜度對比 從圖中可以看出,提出的算法生成2.25階和2.5階零模型時在迭代次數上占有明顯優勢,有效降低了算法的復雜度。 為快速、有效地獲得與真實網絡具有相同的聯合度分布和聚類系數、聚類譜的零模型,將模擬退火算法運用于構造2.25階、2.5階零模型,提出了一種目標保持優化策略。仿真結果表明,該算法生成的2.25階、2.5階零模型在具有準確性和有效性的同時,有效降低了計算復雜度,且其算法復雜度優于其他已有算法。 [1] MAHADEVAN P,HUBBLE C,KRIOUKOV D,et al.Orbis:rescaling degree correlations to generate annotated internet topologies[J].ACM SIGCOMM Computer Communication Review,2007,37(4):325-336. [2] NEWMAN M E.Properties of highly clustered networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2003,68(2):026121. [3] GUILLAUME J L,LATAPY M.Bipartite graphs as models of complex networks[J].Physica A Statistical Mechanics & Its Applications,2006,371(2):795-813. [4] SALA A,CAO L,WILSON C,et al.Measurement-calibrated graph models for social network experiments[C]//Proceedings of the 19th international conference on world wide web.[s.l.]:ACM,2010:861-870. [6] WATTS D J,STROGATZ S H.Collective dynamics of “small-world” networks[J].Nature,1998,393(6684):440-442. [8] MOLLOY M,REED B.A critical point for random graphs with a given degree sequence[J].Random Structures & Algorithms,1995,6(2-3):161-180. [9] NEWMAN M E,STROGATZ S H,WATTS D J. Random gr-aphs with arbitrary degree distributions and their applications[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2001,64:026118. [10] SERGEI M,KIM S.Specificity and stability in topology of protein networks[J].Science,2002,296(5569):910-913. [11] MASLOV S,SNEPPEN K,ZALIZNYAK A.Detection of topological patterns in complex networks:correlation profile of the internet[J].Physica A:Statistical Mechanics and Its Applications,2004,333:529-540. [12] GJOKA M,KURANT M,MARKOPOULOU A.2.5K-Graphs:from sampling to generation[C]//Proceedings of IEEE INFOCOM.[s.l.]:IEEE,2012:1968-1976. [13] PETERMANN T,RIOS P D L.The role of clustering and gridlike ordering in epidemic spreading[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2004,69(6):066166. [14] SOFFER S N,VZQUEZ A.Network clustering coefficient without degree-correlation biases[J].Physical Review E,2005,71(2):057101. [15] SERRANO M,BOGUM.Clustering in complex networks. I. General formalism[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2006,74(5):056114. [16] NEWMAN M E J.Random graphs with clustering[J].Physical Review Letters,2009,103:058701. [17] GLEESON J P,MELNIK S,HACKETT A.How clustering affects the bond percolation threshold in complex networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2010,81:066114. [19] ANGELES S M,BOGUM.Tuning clustering in random networks with arbitrary degree distributions[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2005,72:036133. [20] BANSAL S,KHANDELWAL S,MEYERS L A.Exploring biological network structure with clustered random networks[J].Bmc Bioinformatics,2009,10:405. [21] MAHADEVAN P,KRIOUKOV D,FALL K,et al.Systematic topology analysis and generation using degree correlations[J].ACM SIGCOMM Computer Communication Review,2006,36(4):135-146. [22] GJOKA M,TILLMAN B,MARKOPOULOU A.Construction of simple graphs with a target joint degree matrix and beyond[C]//IEEE conference on computer communications.[s.l.]:IEEE,2015. [23] 尚可可,許小可.基于置亂算法的復雜網絡零模型構造及其應用[J].電子科技大學學報,2014,43(1):7-20. [24] 陳 泉,楊建梅,曾進群.零模型及其在復雜網絡研究中的應用[J].復雜系統與復雜性科學,2013,10(1):8-17. [25] 李 歡,盧 罡,郭俊霞.基于GPU的大尺度網絡零模型分組生成并行算法[J].計算機工程與設計,2016,37(1):93-99. [26] PARK J,NEWMAN M E J.Statistical mechanics of networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2004,70(2):066117. [27] GOFFE W L,FERRIER G D,ROGERS J.Global optimization of statistical functions with simulated annealing[J].Journal of Econometrics,1994,60(1-2):65-99.4 實驗仿真
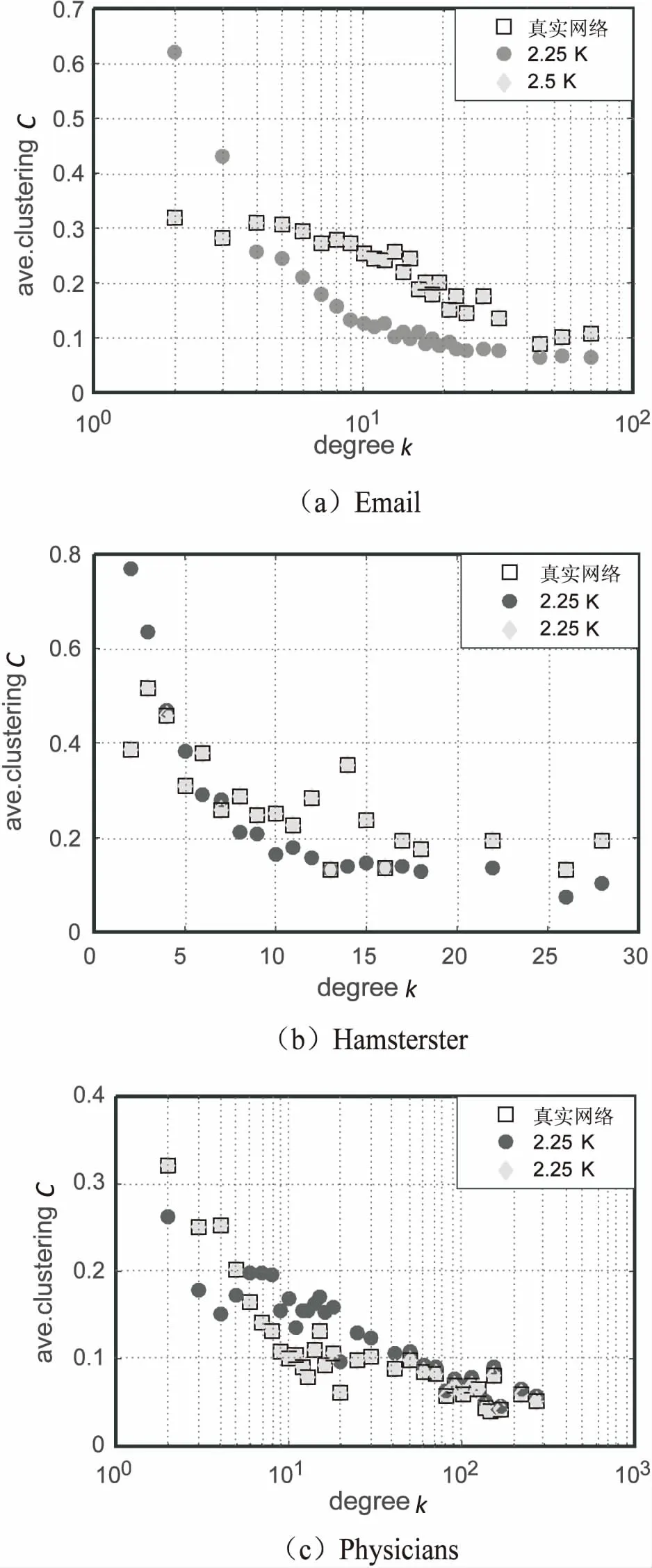
4.1 模擬退火算法參數分析
4.2 2.25/2.5階零模型的有效性分析
4.3 算法復雜度對比
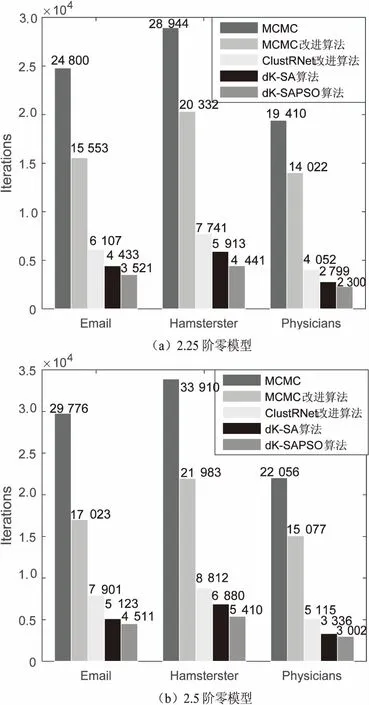
5 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網絡安全與數據管理(2022年1期)2022-08-29 03:15:20導航定位學報(2022年4期)2022-08-15 08:27:00中學生數理化·中考版(2022年8期)2022-06-14 06:55:24新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36成都醫學院學報(2021年2期)2021-07-19 08:35:14新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24光學精密工程(2016年6期)2016-11-07 09:07:19
