面向暴恐音視頻的內(nèi)容檢測(cè)系統(tǒng)研究與實(shí)現(xiàn)*
2018-01-19 05:30:58黃超,易平,2
通信技術(shù) 2018年1期
黃 超,易 平,2
(1.上海交通大學(xué) 網(wǎng)絡(luò)空間安全學(xué)院,上海 200240;2.上海市信息安全綜合管理技術(shù)研究重點(diǎn)實(shí)驗(yàn)室,上海 200240)
0 引 言
隨著網(wǎng)絡(luò)的普及和音視頻技術(shù)的高速發(fā)展,網(wǎng)絡(luò)上的音視頻數(shù)量呈現(xiàn)爆炸性增長(zhǎng)。在海量的音視頻中,混雜著一定數(shù)量的不健康音視頻,如含暴力﹑恐怖內(nèi)容的音視頻,對(duì)社會(huì)和諧﹑網(wǎng)絡(luò)環(huán)境的健康有著不容忽視的損害。
由于網(wǎng)絡(luò)音視頻的數(shù)目極為龐大且每天都會(huì)產(chǎn)生大量新數(shù)據(jù),若僅依靠人工審核的方式進(jìn)行檢測(cè),效率和時(shí)效上是無(wú)法應(yīng)對(duì)的。因此,需要建立面向暴恐音視頻的內(nèi)容檢測(cè)系統(tǒng),不僅能對(duì)待檢測(cè)音視頻給出暴恐/非暴恐的分類(lèi)標(biāo)簽,還能給出暴恐程度的評(píng)估;既要保持高準(zhǔn)確率,也要
具有高時(shí)效性[1]。
當(dāng)前,對(duì)于暴恐音視頻的檢測(cè)方法,主要可以分為聲音﹑圖像和時(shí)空三方面特征的方法。
聲音特征。對(duì)于一段音視頻來(lái)說(shuō),其音頻處理所花的時(shí)間通常要比其視頻處理所花時(shí)間的1/10還要少。因此,聲音特征是音視頻檢測(cè)中時(shí)效性最高也最廣泛應(yīng)用的。Cheng[2]等人提出了一種基于分層模型的音頻片段檢測(cè)方法,最典型的是槍聲和飆車(chē)聲,以判定相應(yīng)的場(chǎng)景。Smeaton[3]等人也通過(guò)選擇音頻特征來(lái)分類(lèi)動(dòng)作電影中的暴力鏡頭。典型的聲音特征包括爆炸聲﹑槍擊聲﹑尖叫聲等。
圖像特征對(duì)于暴恐音視頻來(lái)說(shuō),有典型的火焰﹑血液﹑爆炸等,這些圖像特征取自每一個(gè)幀。Lam[4]采用以拍攝為基礎(chǔ)的方法,同時(shí)考慮一些全局特征(如顏色矩﹑邊緣方向直方圖和局部二進(jìn)制模式等)。Nam等人[5]則提出了利用火焰﹑血液等圖像特征來(lái)識(shí)別暴恐視頻。然而,研究如何降低誤檢的概率,不能僅僅因?yàn)楹谢鹧娴溺R頭多就認(rèn)為是暴恐視頻。
時(shí)空特征對(duì)于暴恐音視頻來(lái)說(shuō),往往有人的動(dòng)作。通過(guò)動(dòng)作識(shí)別典型的暴力動(dòng)作如揮拳﹑踢腿等,可以作為檢測(cè)的依據(jù)。Datta等人[6]提出了一種基于加速運(yùn)動(dòng)矢量的暴力視頻檢測(cè),主要用于檢測(cè)打斗﹑拳擊等場(chǎng)景。Ali等人[7]利用光流法提取人的運(yùn)動(dòng)信息,但計(jì)算量大,魯棒性不足。Nievas等人[8]評(píng)價(jià)了利用現(xiàn)有的動(dòng)作識(shí)別的辦法去檢測(cè)視頻中的打斗畫(huà)面的效率和性能,其中應(yīng)用了STIP和Motion SIFT去檢測(cè)。
本文的面向暴恐音視頻的內(nèi)容檢測(cè)系統(tǒng),選擇音頻特征MFCC,采用詞袋模型建模,利用支持向量機(jī)分類(lèi)。雖然只采用了聽(tīng)覺(jué)的MFCC特征做檢測(cè),但本文致力于在單個(gè)特征的利用上得到最佳的檢測(cè)效果,以供后續(xù)研究中融合其他的聽(tīng)覺(jué)或視覺(jué)特征進(jìn)行多模態(tài)檢測(cè)。
1 理論基礎(chǔ)
1.1 MFCC特征
MFCC(全稱“Mel Frequency Cepstrum Coefficient”)即為Mel頻率倒譜系數(shù)(梅爾頻率倒譜系數(shù))。Mel標(biāo)度是一種非線性的頻率單位,表征了人體耳朵對(duì)頻率的感知。因?yàn)槿硕拖駷V波器,只對(duì)某些特定的頻率分量進(jìn)行感知。人的耳朵對(duì)于真實(shí)頻率的感知是非線性的,在低頻率段可以近似為線性,而在高頻率的1000 Hz以上時(shí)則近似為對(duì)數(shù)增長(zhǎng)關(guān)系。因此,Mel頻域的濾波器可以用來(lái)模擬人體耳朵的臨界頻率和非線性特征。MFCC現(xiàn)在已經(jīng)成為語(yǔ)音識(shí)別領(lǐng)域效果應(yīng)用最好的特征[9],主要應(yīng)用于語(yǔ)音識(shí)別和對(duì)說(shuō)話者的識(shí)別上。
1.2 詞袋模型
詞袋模型,“Bag of Words”[10],即用詞匯(可以類(lèi)比于“基底”的概念)來(lái)表征不同詞匯的集合模型。這里的詞匯可以是文字﹑圖像或者音頻等。在分析文字時(shí),僅僅考慮每個(gè)單詞詞匯出現(xiàn)的頻次,而不考慮他們的出現(xiàn)順序和相互之間的聯(lián)系(即組合方式),這樣雖然帶來(lái)一定程度上的信息損失,但提高了分析文字的效率,可以高效地構(gòu)建模型并進(jìn)行模型應(yīng)用,且關(guān)鍵詞出現(xiàn)的頻次在某些應(yīng)用場(chǎng)景下更具實(shí)用性。詞袋模型在文字建模和分析上取得成功后,繼而被用于圖像識(shí)別領(lǐng)域。文字中有一個(gè)個(gè)單詞可以作為詞匯,圖像中也有類(lèi)似的“基底”,但圖像的“基底”不是小區(qū)域的圖像特征,而是局部區(qū)域匹配特征,如SIFT(Scale-invariant Feature Transform,尺度不變特征轉(zhuǎn)換)[11]在圖像識(shí)別領(lǐng)域的應(yīng)用愈加廣泛。
音頻詞袋模型和圖像詞袋模型類(lèi)似,它們的詞匯不像文字詞匯可以很容易地完全匹配,而是采用局部特征,需要應(yīng)用聚類(lèi)算法對(duì)特征相似距離進(jìn)行計(jì)算和分類(lèi)。音頻中常用的有MPEG-7(多媒體內(nèi)容描述接口)中的一些特征如音頻簽名﹑MFCC特征等。
1.3 支持向量機(jī)
支持向量機(jī)(Support Vector Machine)是Vapnik等人[12]于1995年首次提出的基于統(tǒng)計(jì)學(xué)理論的新型機(jī)器學(xué)習(xí)算法,是一種有監(jiān)督學(xué)習(xí)模型。它的學(xué)習(xí)機(jī)制是全新的,有著堅(jiān)實(shí)的理論基礎(chǔ)和統(tǒng)計(jì)學(xué)算法,能夠從訓(xùn)練數(shù)據(jù)中尋找并發(fā)現(xiàn)內(nèi)在的規(guī)律,通過(guò)“學(xué)習(xí)”后能夠?qū)Υ龣z測(cè)樣本進(jìn)行預(yù)測(cè)。支持向量機(jī)致力于得到的最優(yōu)分離超平面,不僅要能夠?qū)⒋龣z測(cè)樣本無(wú)差錯(cuò)地分為兩類(lèi),還要使得這兩類(lèi)樣本之間的距離最大化。
2 算法研究
2.1 算法整體框架
本文設(shè)計(jì)的面向暴恐音視頻檢測(cè)的內(nèi)容過(guò)濾系統(tǒng),整體框架如圖1所示。
檢測(cè)模型基于音頻詞袋模型,采用語(yǔ)音識(shí)別中最常用到的MFCC特征。對(duì)MFCC特征聚類(lèi)可以得到詞袋模型的詞匯,再通過(guò)對(duì)詞頻的計(jì)算分別表征訓(xùn)練集和測(cè)試集的詞袋模型表示。對(duì)于訓(xùn)練集的詞袋模型表示,用支持向量機(jī)SVM去訓(xùn)練。得到訓(xùn)練模型后,用此訓(xùn)練模型對(duì)測(cè)試集進(jìn)行分類(lèi)測(cè)試。
2.2 MFCC特征維數(shù)選取
MFCC是當(dāng)前語(yǔ)音識(shí)別領(lǐng)域最常用的檢測(cè)特征。在本文實(shí)驗(yàn)數(shù)據(jù)集中,由于電影鏡頭中暴恐和非暴恐鏡頭的音頻能量特征差異較大,因此本文考慮MFCC中能量很大的C0,即取13維的MFCC作為識(shí)別特征。考慮到暴恐鏡頭的音頻識(shí)別檢測(cè)效率,提取的MFCC特征為較低維數(shù),舍棄了其一階導(dǎo)數(shù)(總共26維)和二階導(dǎo)數(shù)(總共39維)。因此,對(duì)每一幀的MFCC向量聚類(lèi)得到的音頻詞袋的詞匯也是13維,聚類(lèi)﹑匹配效率高。
2.3 詞袋模型的詞匯生成
采用k-means算法對(duì)數(shù)據(jù)集的全部幀的MFCC特征進(jìn)行聚類(lèi),聚類(lèi)得到的k個(gè)聚類(lèi)的中心——聚類(lèi)質(zhì)心作為詞袋模型的“詞匯”。
在聚類(lèi)過(guò)程中,相似度高的向量容易被聚類(lèi)到一個(gè)聚類(lèi)中。聚類(lèi)完成后,同一個(gè)聚類(lèi)中的各幀的MFCC特征是相對(duì)接近的,很可能同屬于一類(lèi)聲音。將聚類(lèi)的質(zhì)心作為詞匯,通過(guò)計(jì)算詞頻去表征不同的鏡頭特征,即為詞袋模型的核心。
對(duì)于每一幀的MFCC向量來(lái)說(shuō),它們之間的相似程度用歐幾里德距離來(lái)衡量最合適。歐幾里德距離越小,代表相似程度越大。例如,對(duì)于13維的
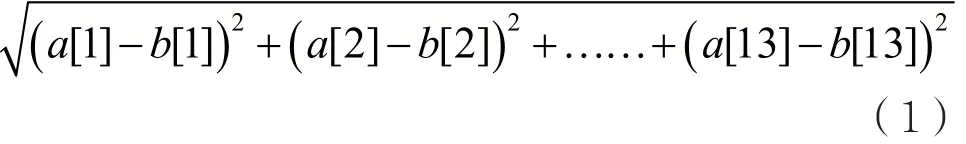
待檢測(cè)短鏡頭的幀數(shù)長(zhǎng)度變化很大,從最短的3幀到最多的4 846幀。因此,本文實(shí)驗(yàn)中聚類(lèi)了不同個(gè)數(shù)(參數(shù)設(shè)為k)的質(zhì)心,分別為8個(gè)﹑16個(gè)﹑32個(gè)﹑64個(gè)﹑128個(gè)﹑256個(gè)﹑512個(gè)﹑1 024個(gè),然后再通過(guò)實(shí)驗(yàn)來(lái)選取最佳的聚類(lèi)個(gè)數(shù)。聚類(lèi)得到k個(gè)13維的MFCC向量,則為音頻詞袋的k個(gè)詞匯。
2.4 特征的詞袋模型表征
訓(xùn)練時(shí),要用音頻詞袋模型的詞匯去表征一段單位鏡頭的音頻特征,這里的特征定義為每個(gè)音頻詞匯出現(xiàn)的詞頻。這里定義的單位鏡頭不是數(shù)據(jù)集定義的短鏡頭或長(zhǎng)鏡頭,而是擬定的100幀長(zhǎng)度(時(shí)間長(zhǎng)度4 s)的單位鏡頭。三部用于分類(lèi)測(cè)試的電影的短鏡頭共有6 564個(gè),總的幀數(shù)為606 302幀,平均每一個(gè)短鏡頭有92幀,因此取100幀作為一個(gè)單位鏡頭是合理的。
每一個(gè)單位鏡頭中,每一幀的MFCC向量去和聚類(lèi)得到的k個(gè)音頻詞匯的MFCC向量求歐幾里德距離,認(rèn)為每一幀的MFCC向量可以用離它最近(歐幾里德距離)的那個(gè)MFCC詞匯去表征,即該詞匯的出現(xiàn)頻次加1。這樣每100幀的單位鏡頭都能表示為一個(gè)k維的詞匯頻次向量,其k維的頻次總和為100。
同理,需要先對(duì)分類(lèi)測(cè)試集做同樣的詞袋模型詞匯表示后,才能對(duì)其進(jìn)行支持向量機(jī)的分類(lèi)。不過(guò),分類(lèi)測(cè)試的對(duì)象不是100幀的單位鏡頭,而是給定好的幀數(shù)長(zhǎng)短不一的短鏡頭。這里需要用到“歸一化”的方法。假設(shè)一個(gè)待檢測(cè)短鏡頭的幀數(shù)為x幀,對(duì)每一幀的MFCC特征求得最近的音頻詞匯后,得到k維詞匯頻次向量,其k維的頻次總和為x,歸一化將k維向量每一維的元素值除以x再乘以100,則歸一化后k維的頻次總和為100,才可以使用先前通過(guò)支持向量機(jī)訓(xùn)練得到的模型進(jìn)行分類(lèi)。
2.5 支持向量機(jī)參數(shù)選取
本文實(shí)驗(yàn)采用的是臺(tái)灣大學(xué)林智仁等人開(kāi)發(fā)的LIBSVM系統(tǒng)的MATLAB版本[13]。支持向量機(jī)有2個(gè)重要參數(shù)——損失函數(shù)和gamma參數(shù),對(duì)分類(lèi)結(jié)果影響較大。為了便于求出最佳的損失函數(shù)和gamma參數(shù),這里使用一種網(wǎng)格搜索(grid search)方法。與LIBSVM自帶的grid.py思想相同,即遍歷每一組損失函數(shù)和gamma參數(shù),用交叉驗(yàn)證的辦法求出交叉驗(yàn)證準(zhǔn)確度最高的組合。由于過(guò)高的損失函數(shù)有可能造成過(guò)擬合而影響分類(lèi)的準(zhǔn)確性,所以相同準(zhǔn)確度下將損失函數(shù)最小的那一組認(rèn)為是最佳的參數(shù)設(shè)定。
本文實(shí)驗(yàn)中,將支持向量機(jī)svmtrain中參數(shù)b設(shè)置為1,這樣能夠輸出支持向量機(jī)分類(lèi)的概率值結(jié)果,是一個(gè)二元值。顯然,屬于暴恐的概率加上屬于非暴恐的概率相加為1;且哪一個(gè)概率值越大,則該條向量便歸屬為哪一類(lèi)。
3 實(shí)驗(yàn)分析
3.1 數(shù)據(jù)集介紹和優(yōu)化處理
本文實(shí)驗(yàn)基于多媒體benchmark評(píng)估組織MediaEval中的一個(gè)競(jìng)賽項(xiàng)目——“暴力場(chǎng)景檢測(cè)任務(wù)VSD(Violent Scenes Detection)”[14],致力于研究對(duì)暴力音視頻片段的自動(dòng)檢測(cè)。它的官方數(shù)據(jù)集由Technicolor提供,有14部電影作為訓(xùn)練集,3部作為測(cè)試集。每一部電影的時(shí)長(zhǎng)都在2 h左右。數(shù)據(jù)集提供了40 ms/幀(即25幀/s)的音視頻特征,則14部電影共有2 411 714幀。
數(shù)據(jù)集的每部電影都提供了官方的短鏡頭分割結(jié)果,由Technicolor的鏡頭分割軟件產(chǎn)生,下文中的“短鏡頭”都指這個(gè)定義。
數(shù)據(jù)集由官方劃分為諸多長(zhǎng)鏡頭,有著唯一的暴恐或非暴恐標(biāo)注;下文中的“長(zhǎng)鏡頭”都指這個(gè)定義。每一個(gè)暴恐/非暴恐的長(zhǎng)鏡頭中都包含了若干個(gè)短鏡頭。
當(dāng)短鏡頭落在帶有暴恐標(biāo)注的長(zhǎng)鏡頭中時(shí),則認(rèn)為該短鏡頭為暴恐短鏡頭;反之,亦然。3部測(cè)試集的暴恐短鏡頭比例分別為1.771%﹑12.773%和10.481%。
3.1.1 無(wú)用鏡頭的過(guò)濾
對(duì)于電影來(lái)說(shuō),需要過(guò)濾掉一些非常規(guī)的鏡頭,以提升后續(xù)詞袋模型構(gòu)建的準(zhǔn)確度。因?yàn)殡娪暗钠^和片尾有一些非常規(guī)鏡頭(非自然生活)如片頭的廠家logo和片尾的字幕。考慮到非常規(guī)鏡頭不可能為暴恐鏡頭,因此每部電影從第一段暴恐長(zhǎng)鏡頭起始幀開(kāi)始到最后一段暴恐長(zhǎng)鏡頭結(jié)尾幀結(jié)束。過(guò)濾之前14部電影總幀數(shù)2 411 714幀,過(guò)濾后為2 029 984幀。待聚類(lèi)的樣本無(wú)用干擾項(xiàng)被清除,降低訓(xùn)練復(fù)雜度,且暴恐鏡頭沒(méi)有被過(guò)濾,最終的1 920 507幀的非暴恐鏡頭仍然大于109 477幀的暴恐鏡頭。可見(jiàn),這樣的過(guò)濾對(duì)最后分類(lèi)精確度提升很有意義。
3.1.2 欠采樣的樣本平衡
14部訓(xùn)練集電影中的暴恐長(zhǎng)鏡頭數(shù)目為962個(gè),共109 477幀。在分類(lèi)測(cè)試集中的短鏡頭共有6 564個(gè),總幀數(shù)為606 302幀,每一個(gè)短鏡頭平均幀數(shù)為92幀。因此,在訓(xùn)練集中取100幀為單位長(zhǎng)度鏡頭最合適。下文實(shí)驗(yàn)也驗(yàn)證了50幀和150幀的結(jié)果明顯不如100幀好。
從每個(gè)暴恐長(zhǎng)鏡頭中取100幀為單位長(zhǎng)度的鏡頭,共取出662個(gè)單位長(zhǎng)度鏡頭(部分長(zhǎng)鏡頭的尾部不滿100幀的被舍棄)。訓(xùn)練電影中的非暴恐鏡頭總幀數(shù)約為暴恐鏡頭總幀數(shù)的17倍,因此提取的100幀的單位鏡頭的數(shù)目也相差了17倍左右。正負(fù)樣本的不平衡問(wèn)題,導(dǎo)致支持向量機(jī)分類(lèi)得到的超平面靠近數(shù)量多的負(fù)樣本。由這樣的模型進(jìn)行分類(lèi),結(jié)果是傾向于把全部結(jié)果都分類(lèi)到負(fù)樣本。
為了解決正負(fù)樣本不平衡問(wèn)題,本文實(shí)驗(yàn)采用文獻(xiàn)[15]提出的欠采樣(Undersampling)方法。欠采樣和增采樣可以用來(lái)解決正負(fù)樣本不平衡的問(wèn)題,相比之下欠采樣在訓(xùn)練過(guò)程中的復(fù)雜度更低,訓(xùn)練效率也更高,更適用于樣本數(shù)目較多的情況。本文采用的欠采樣方法是均勻間隔取樣的方式,使得取得的負(fù)樣本(非暴恐)數(shù)目和正樣本(暴恐)數(shù)目一樣。這是考慮到電影劇情較為連貫,相同鏡頭里相鄰的幾個(gè)100幀之間的MFCC特征差距較小。因此,均勻間隔取樣方法不僅可以平衡正負(fù)樣本數(shù)目,而且減少了相似累贅的訓(xùn)練樣本,縮小了訓(xùn)練復(fù)雜度。
3.2 算法驗(yàn)證實(shí)驗(yàn)
3.2.1 客觀評(píng)估方法
VSD規(guī)定要使用同一訓(xùn)練集,以提取任意多個(gè)模態(tài)特征,經(jīng)過(guò)算法模型給出待檢測(cè)樣本的暴恐/非暴恐標(biāo)簽,并給出相應(yīng)的概率,然后使用VSD官方認(rèn)定的平均準(zhǔn)確率Average Precision@100評(píng)估分類(lèi)測(cè)試的結(jié)果。Average Precision@n是按檢測(cè)概率從大到小,統(tǒng)計(jì)前n個(gè)被檢測(cè)到的樣本,計(jì)算其統(tǒng)計(jì)準(zhǔn)確率,計(jì)算公式如下:
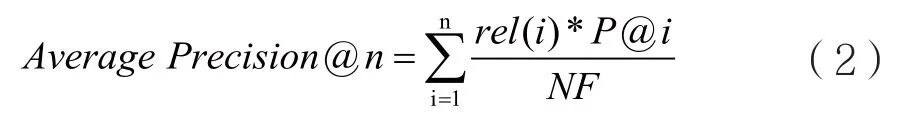
當(dāng)@n不指定時(shí),則默認(rèn)為對(duì)全部被檢測(cè)到的樣本進(jìn)行統(tǒng)計(jì),計(jì)算統(tǒng)計(jì)準(zhǔn)確率。
在本文實(shí)驗(yàn)得到的支持向量機(jī)分類(lèi)結(jié)果中,首先對(duì)每一個(gè)結(jié)果屬于暴恐類(lèi)別的概率做排序,再取排序前n=100個(gè)結(jié)果做統(tǒng)計(jì)。
3.2.2 初步驗(yàn)證實(shí)驗(yàn)結(jié)果
本文構(gòu)建的詞袋模型維數(shù)為8維﹑16維﹑32維﹑64維﹑128維﹑256維﹑512維﹑1 024維共8種維數(shù)。本文選定的單位長(zhǎng)度鏡頭為100幀。為了對(duì)比,同時(shí)選取50幀和150幀做實(shí)驗(yàn)。圖2是分別取3種單位長(zhǎng)度鏡頭下的檢查結(jié)果。
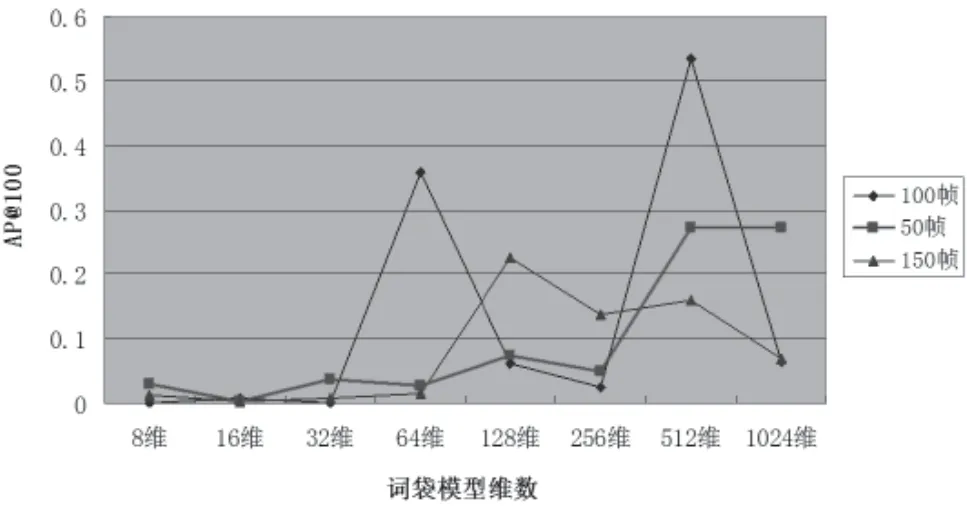
圖2 初步實(shí)驗(yàn)結(jié)果AP@100
由圖2的折線圖可以看到如下規(guī)律:
(1)在8維﹑16維﹑32維時(shí),因?yàn)榫S數(shù)還過(guò)小,AP@100都很低;
(2)100幀和50幀的單位長(zhǎng)度鏡頭下,在512維時(shí)的AP@100最高,150幀的512維結(jié)果也不錯(cuò),在后續(xù)改進(jìn)實(shí)驗(yàn)中也是512維的結(jié)果最好;
(3)3種詞袋模型最高的AP@100都有超過(guò)0.2;(4)100幀的結(jié)果明顯優(yōu)于50幀和150幀。當(dāng)前,最佳的結(jié)果在維數(shù)為100幀單位長(zhǎng)度鏡頭﹑512維詞袋模型的參數(shù)情況下,為AP@100=0.532 792。
3.2.3 實(shí)驗(yàn)結(jié)果對(duì)比
本文應(yīng)用的數(shù)據(jù)集和采用的運(yùn)行水平﹑評(píng)估指標(biāo)等都按照VSD官方指定。將初步實(shí)驗(yàn)的結(jié)果按官方評(píng)估指標(biāo)即最佳AP@100放入其他隊(duì)伍中進(jìn)行對(duì)比[16],畫(huà)出柱狀圖將更為直觀,如圖3所示。
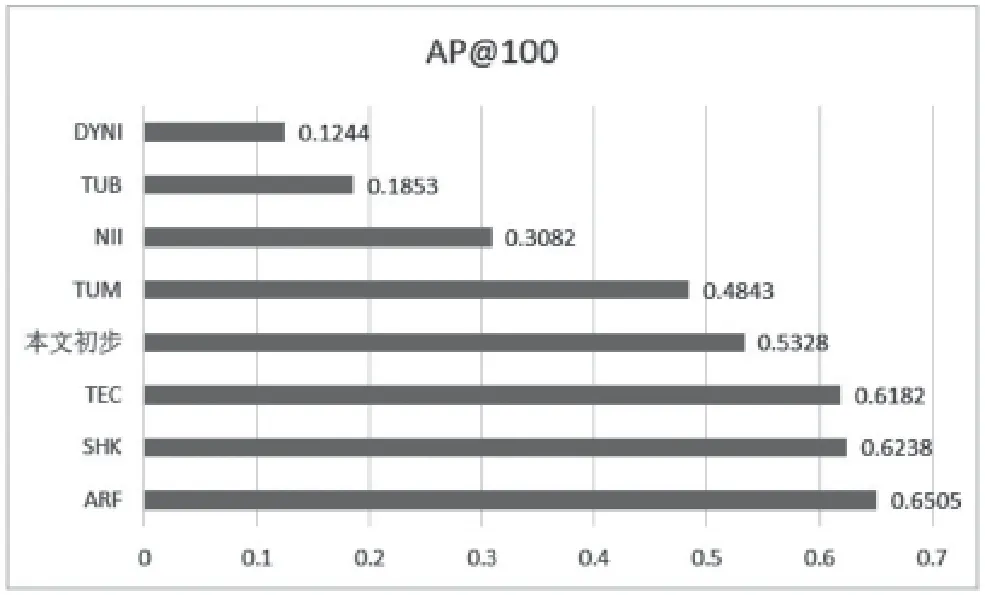
圖3 AP@100結(jié)果對(duì)比
由對(duì)比實(shí)驗(yàn)結(jié)果可以看到,本文實(shí)驗(yàn)中最佳參數(shù)下的AP@100屬于較高水平,排名第四。AP@100的和通常意義的準(zhǔn)確率不同,是統(tǒng)計(jì)意義上的準(zhǔn)確率,很難達(dá)到80%的水平,另一個(gè)原因是測(cè)試電影中的暴恐鏡頭比例很低,在1.7%~12.7%。
其他隊(duì)伍都選取了多模態(tài)或者視頻特征,訓(xùn)練復(fù)雜度高,而本實(shí)驗(yàn)僅僅選取了音頻的一種特征就達(dá)到了理想結(jié)果,因此本方法具有較好的應(yīng)用前景和可拓展性。
3.3 算法改進(jìn)實(shí)驗(yàn)
3.3.1 詞頻加權(quán)參數(shù)的改進(jìn)算法
通常情況下,對(duì)于詞袋模型的表示方法,是對(duì)每一幀的MFCC向量計(jì)算和它距離最近的詞匯向量,將這個(gè)詞匯的詞頻加1。當(dāng)詞袋模型的維數(shù)即詞匯個(gè)數(shù)較多時(shí),如k維有512個(gè)詞匯,每一個(gè)MFCC向量可能和周?chē)膸讉€(gè)詞匯向量距離都相近,如果僅僅將距離最近的詞匯詞頻加1,那么對(duì)于僅比其最短距離多了微小距離的詞匯來(lái)說(shuō)是“不公平”的,也會(huì)損失部分有效信息。因此,在改進(jìn)的詞頻加權(quán)中,對(duì)于距離最近的詞匯的詞頻加1,對(duì)于距離第二近的詞匯的詞頻加1/2,對(duì)于距離第三近的詞匯的詞頻加1/4。以此類(lèi)推,直到距離第c近的詞匯的詞頻加上1/2c-1。
對(duì)于詞袋模型維數(shù)k分別為8維﹑16維﹑32維﹑64維﹑128維﹑256維﹑512維﹑1 024維共8種維數(shù),每一種模型的實(shí)驗(yàn)中都設(shè)置了6種詞頻加權(quán)方式進(jìn)行檢測(cè),都是為距離最近的c個(gè)詞匯進(jìn)行詞頻加權(quán)。下文中的“詞頻加權(quán)參數(shù)c”都指的是這個(gè)定義。6種方式的區(qū)別在于c的取值,分別為1﹑2﹑3﹑5﹑k/2﹑k/4。在取k/2和k/4時(shí),由于過(guò)大的c對(duì)應(yīng)的加權(quán)數(shù)值1/2c-1過(guò)于小,為減少?zèng)]有意義的計(jì)算加權(quán)帶來(lái)的系統(tǒng)檢測(cè)復(fù)雜度的大幅提升,本文規(guī)定當(dāng)k/2和k/4的數(shù)值超過(guò)8時(shí),也將該值取為8。
本文實(shí)驗(yàn)選取8種詞袋模型的維數(shù),每種維數(shù)有6種詞頻加權(quán)方式。進(jìn)行組合實(shí)驗(yàn),對(duì)最高結(jié)果中對(duì)應(yīng)的詞頻加權(quán)參數(shù)c的出現(xiàn)比例總計(jì)做出餅狀圖,如圖4所示。
從統(tǒng)計(jì)結(jié)果來(lái)看,最高結(jié)果對(duì)應(yīng)的詞頻加權(quán)參數(shù)c中,c=1只占據(jù)了13.33%,c>1的情況占據(jù)了86.67%。因此,可以證明詞頻加權(quán)考慮最近的幾個(gè)詞匯的加權(quán)方法在普遍情況下是可以使詞袋模型的表示更為準(zhǔn)確,從而使得后續(xù)的支持向量機(jī)的訓(xùn)練和分類(lèi)更加準(zhǔn)確。
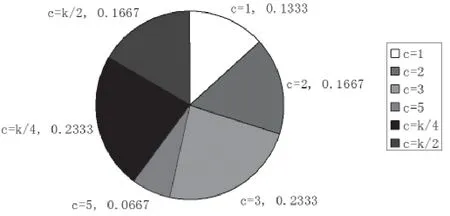
圖4 最高結(jié)果中對(duì)應(yīng)的詞頻加權(quán)參數(shù)c比例
3.3.2 基于距離倍數(shù)的詞頻加權(quán)改進(jìn)算法
在上文的詞頻加權(quán)中,統(tǒng)計(jì)了最近c(diǎn)個(gè)詞匯進(jìn)行加權(quán),是考慮到可能有幾個(gè)詞匯都和某MFCC向量的距離接近。進(jìn)一步來(lái)看,在計(jì)算復(fù)雜度允許的情況下,距離也可以直接作為標(biāo)尺。因此,在改進(jìn)的詞頻加權(quán)方式中,考慮了距離的數(shù)值。首先選取最近的距離對(duì)該詞匯的詞頻加1,然后對(duì)后續(xù)的距離進(jìn)行區(qū)間分段。對(duì)于落于最近距離的1~2倍中的詞匯,詞匯詞頻加1/2;落于2~3倍中的詞匯,詞匯詞頻加1/4;以此類(lèi)推,直到9~10倍距離中的詞匯,詞匯詞頻加1/29。這里需要進(jìn)行歸一化,使得詞匯頻次總和仍為之前設(shè)定的100。
改進(jìn)后的詞頻加權(quán)方式為對(duì)最短距離的1~10倍的詞匯進(jìn)行詞頻加權(quán),與詞頻加權(quán)最近c(diǎn)個(gè)詞匯中的c=1﹑c=2﹑c=3﹑c=5做實(shí)驗(yàn)對(duì)比,結(jié)果如圖5所示。
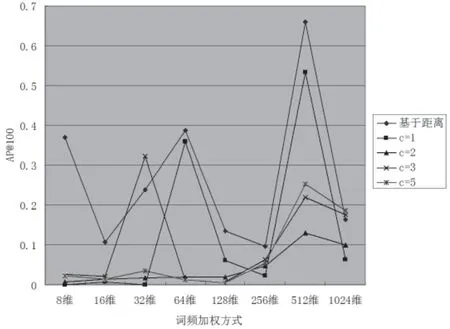
圖5 優(yōu)化算法AP@100對(duì)比
從圖5的折線圖可以看出,優(yōu)化后算法的AP@100基本上包絡(luò)著原有不同參數(shù)c的AP@100結(jié)果(即在它們的上面),即結(jié)果更優(yōu),具有普遍適用性。最重要的是,改進(jìn)算法使得最優(yōu)結(jié)果AP@100從原先的0.532 792提升到了0.658 726,略高于VSD中最高的0.650 5。
4 結(jié) 語(yǔ)
網(wǎng)絡(luò)上海量的音視頻中存在著數(shù)量不容忽視的暴恐音視頻,在人工檢測(cè)無(wú)法滿足現(xiàn)實(shí)要求的情況下,本文研究了面向暴恐音視頻的內(nèi)容檢測(cè)系統(tǒng),既保持高準(zhǔn)確率,也致力于提升檢測(cè)的時(shí)效性。本文選擇的檢測(cè)特征是音頻特征MFCC,采用詞袋模型建模,利用支持向量機(jī)分類(lèi)。雖然只采用了音頻的MFCC特征做檢測(cè),但本文致力于在MFCC單個(gè)特征的利用上做到精益求精,得到最佳的檢測(cè)效果,以供后續(xù)研究融合其他聽(tīng)覺(jué)或視覺(jué)特征進(jìn)行多模態(tài)檢測(cè)。因此,本文優(yōu)化了多個(gè)全局參數(shù),選取了13維作為MFCC特征的維數(shù),過(guò)濾了無(wú)用鏡頭,選取100幀長(zhǎng)度作為單位鏡頭并驗(yàn)證了合理性。此外,采用欠采樣的方法來(lái)平衡正負(fù)樣本的數(shù)目差距,減少了樣本冗余和訓(xùn)練復(fù)雜度。最后,實(shí)現(xiàn)的檢測(cè)系統(tǒng)取得了理想結(jié)果,不僅能給出鏡頭為暴恐/非暴恐的檢測(cè)結(jié)果,還能給出暴恐的程度評(píng)估,具有高實(shí)用性。
本文的創(chuàng)新之處在于提出了詞頻加權(quán)參數(shù)c的改進(jìn)算法,又提出了基于距離倍數(shù)的詞頻加權(quán)改進(jìn)算法,改進(jìn)的詞頻加權(quán)能使詞袋模型的表示更精確,提高了檢測(cè)準(zhǔn)確率。
[1] 吳震.聯(lián)網(wǎng)報(bào)警與視頻監(jiān)控系統(tǒng)平臺(tái)實(shí)現(xiàn)技術(shù)[J].通信技術(shù),2010,43(05):195-197.
WU Zhen.Implementation of Social Networking Alarm and Video Surveillance Platform[J].Communication Technology,2010,43(05):195-197.
[2] Cheng W H,Chu W T,Wu J L.Semantic Context Detection based on Hierarchical Audio Models[C].ACM Sigmm International Workshop on Multimedia Information Retrieval ACM,2003:109-115.
[3] Smeaton A F,Lehane B,O'Connor N E,et al.Automatically Selecting Shots for Action Movie Trailers[C].ACM Sigmm International Workshop on Multimedia Information Retrieval,2006:231-238.
[4] Lam V,Le D D,Phan S,et al.NII-UIT at MediaEval 2014 Violent Scenes Detection Affect Task[C].Media Eval,2014.
[5] Nam J,Alghoniemy M,Tewfik A H.Audio-Visual Content-Based Violent Scene Characterization[J].IEEE International Conference on Image Processing,1998(01):353-357.
[6] Datta A,Shah M,da Vitoria Lobo N.Person-onperson Violence Detection in Video Data[C].Pattern Recognition,2002:433-438.
[7] Ali S,Shah M.Human Action Recognition in Videos Using Kinematic Features and Multiple Instance Learning[J].IEEE Transactions on Software Engineering,2010,32(02):288-303.
[8] Nievas E B,Suarez O D,Garc′ ?a G B,et al.Violence Detection in Video Using Computer Vision Techniques[C].Computer Analysis of Images and Patterns,2011:332-339.
[9] Ahmad J,Fiaz M,Kwon S,et al.Gender Identification Using MFCC for Telephone Applications-A Comparative Study[J].arXiv preprint arXiv:1601.01577,2016:351-355.
[10] Peng X,Wang L,Wang X,et al.Bag of Visual Words and Fusion Methods for Action Recognition:Comprehensive Study and Good Practice[J].Computer Vision & Image Understanding,2016,150(C):109-125.
[11] Yang Q,Peng J Y.Chinese Sign Language Recognition Research Using SIFT-BoW and Depth Image Information[J].Computer Science,2014(02):302-307.
[12] Vapnik V N.The Nature of Statistical Learning Theory[J].Neural Networks IEEE Transactions on,1995,10(05):988-999.
[13] Hsu C W,Chang C C,Lin C J.A Practical Guide to Support Vector Classication[D].Taibei:National Taiwan University,2010.
[14] Sj?berg M,Ionescu B,Jiang Y G,et al.The Media Eval 2014 Affect Task:Violent Scenes Detection[C].Media Eval.2014.
[15] Pozzolo A D,Caelen O,Bontempi G.When is Under sampling Effective in Unbalanced Classification Tasks?[C].Joint European Conference on Machine Learning and Knowledge Discovery in Databases,2015:200-215.
[16] Demarty C H,Penet C,Soleymani M,et al.VSD,A Public Dataset for the Detection of Violent Scenes in Movies:D esign,Annotation,Analysis and Evaluation[J].Multimedia Tools & Applications,2015,74(17):7379-7404.
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
