Map/Reduce下快速剪枝算法在復雜任務調度中的應用*
2018-01-16 01:42:59裴樹軍宋冬梅孔德凱
計算機與生活 2018年1期
關鍵詞:效率
裴樹軍,宋冬梅,孔德凱
哈爾濱理工大學 計算機科學與技術學院,哈爾濱 150080
1 引言
隨著計算、存儲以及通信等技術的快速發展,云計算[1-2]已經成為一種新興的商業計算模式。云計算通過對分布處理(distributed computing)、并行處理(parallel computing)、網格計算(grid computing)、虛擬化技術和分布式數據庫等計算機和網絡技術的整合和改進,實現了對基礎資源的共享,并提供更為靈活的彈性服務。目前IBM、Google、Amazon、Microsoft等知名公司都加大對云計算的研究,比如Google公司的Google搜索[3],Amazon的EC2。近些年國內學者對云計算也進行了卓有成效的研究,比如阿里巴巴的云計算平臺,中國移動的OneNet平臺。現今國內外云計算大部分采用Google提出的Map/Reduce編程模型,Map/Reduce是Google公司開發的用于解決大規模數據集(大于1 TB)分布式存儲和并行計算的一種軟件架構,是處理海量數據的并行編程模型。這種編程模型是一種線性的、可伸縮的編程模型,主要擅長于對半結構化或非結構化數據進行分析,具有容錯能力強而且基礎設施可以靈活擴展的特點,因此現在任務調度模型大都基于Map/Reduce開發。
任務調度問題[4]一直是云計算系統關注的核心問題,影響任務調度效率的因素很多,其中復雜任務的處理是影響任務調度效率的一個關鍵因素。復雜任務是指任務之間存在一定偏序或依賴關系,即后一個任務必須在前一個任務完成之后才能開始執行,這種依賴關系可能具有迭代性,也可能不具有迭代性,如Fibonacci函數Fk+2=Fk+Fk+1,前后數據項之間存在很強的依賴關系。傳統任務調度算法對復雜任務沒有明確的限定,因此缺少合理的復雜任務調度策略。
因為傳統的Map/Reduce任務調度模型的并行化處理模式沒有對復雜任務的明確處理策略,所以在任務執行時可能會由于某一個子任務無法正常執行導致整個任務執行效率較低,甚至會由于任務阻塞導致程序無法正常運行。因此如何提高復雜任務的處理效率成為提高任務調度整體效率的核心問題。本文主要針對復雜多任務調度[5]提出了一種在Map/Reduce框架下基于剪枝算法的任務調度算法,以抽樣法[6]獲得節點處理任務的時間,再將其與節點處理任務的能力(計算能力、網絡帶寬能力等)的比值作為時間預測,即處理時間與節點處理能力成反比,而抽樣的任務處理時間與真實任務處理時間成正比。其中節點處理能力Γij=ti.l/rj.c為任務長度與資源計算能力的比值。將得到的任務處理時間進行量化,建立任務和節點處理時間的n×n矩陣,通過使用剪枝算法先獲得任務分配局部最優解,之后逐步剪枝獲得任務分配全局最優解,并按照復雜任務預處理產生的最佳拓撲排序對最佳分配矩陣中的任務進行分配,從而使復雜任務高效準確地執行。其與Spark中的DAG(directed acyclic graph)相比:首先每個節點都充分考慮內存資源的使用情況,減少了因不確定因素導致的內存溢出,產生任務執行失敗的情況;其次本文任務排序是根據任務之間的依賴關系大小而產生的最佳拓撲排序,很大程度上使任務之間的關聯更明確,并且如果某個任務執行失敗,可以根據依賴關系的大小依次從父節點的內存中取出需要的信息與現有內存數據一起重新執行該任務,如果依賴關系強的父節點數據足夠執行該任務,則不再獲取其他依賴節點數據,因此提升了任務的調度效率和容錯性能。本文使用Hadoop平臺進行任務調度實驗,證明了算法能夠提高任務調度的整體效率,具有一定的理論和實際應用價值。
2 Map/Reduce模型
2.1 Map/Reduce作業執行過程
Map/Reduce[7]是面向大數據處理的并行計算模型和方法,最初的提出是為了解決搜索引擎中大規模網頁數據的并行化處理問題。其設計思想是對大數據并行處理分而治之,通過借鑒函數式程序設計語言Lisp的設計思想,將處理過程抽象為Map和Reduce兩個基本操作,即映射(Map)和規約(Reduce)。Map/Reduce執行過程如圖1所示。
Map階段:首先分割函數把輸入的文件分割為一系列數據塊即子任務(Split),每個數據塊一般為64 MB,其存儲位置按照一定的策略進行布局,每個數據塊都有備份且保存在不同的節點上。然后Master將N個任務分配給N個空閑的Map節點,使已分配任務的Map節點讀取Split的內容并分析出Key/Value對,由Map函數產生中間Key/Value結果緩存在內存中,并周期性地寫到本地磁盤,再由分割函數把它們寫入不同區域,并將結果傳輸給Reduce。
Reduce階段:Reduce worker根據Master節點傳輸的中間結果存儲位置讀取中間結果,通過排序使具有相同Key的內容聚合在一起。由Reduce節點迭代排過序的中間結果產生唯一的中間Key,然后對遇到的每個唯一的中間Key,把Key和相關中間Value集傳遞給用戶自定義的Reduce函數。最后將Reduce函數的輸出結果添加到最終輸出的文件中。
2.2 傳統任務調度算法的不足及改進
傳統的任務調度[8-10]過程可分為Map-Shuffle-Reduce階段(圖2),這3個階段產生的關鍵數據通常是以文件的形式存放在本地磁盤,雖然這樣存放增加了任務的本地性和安全性,但卻導致了大量的I/O操作,嚴重影響了任務處理的整體效率。例如Map節點在形成中間結果時,因為Spill溢寫產生中間文件數量過多,進而會導致后期處理文件的時間過長;又如Reduce端的Shuffle,當Merge過程產生的數據量達到閾值時,會啟動內存到磁盤的Merge過程,將文件存入磁盤,之后執行Reduce就需要將文件存入內存,在此過程中涉及大量的I/O操作,嚴重影響任務處理的整體效率。
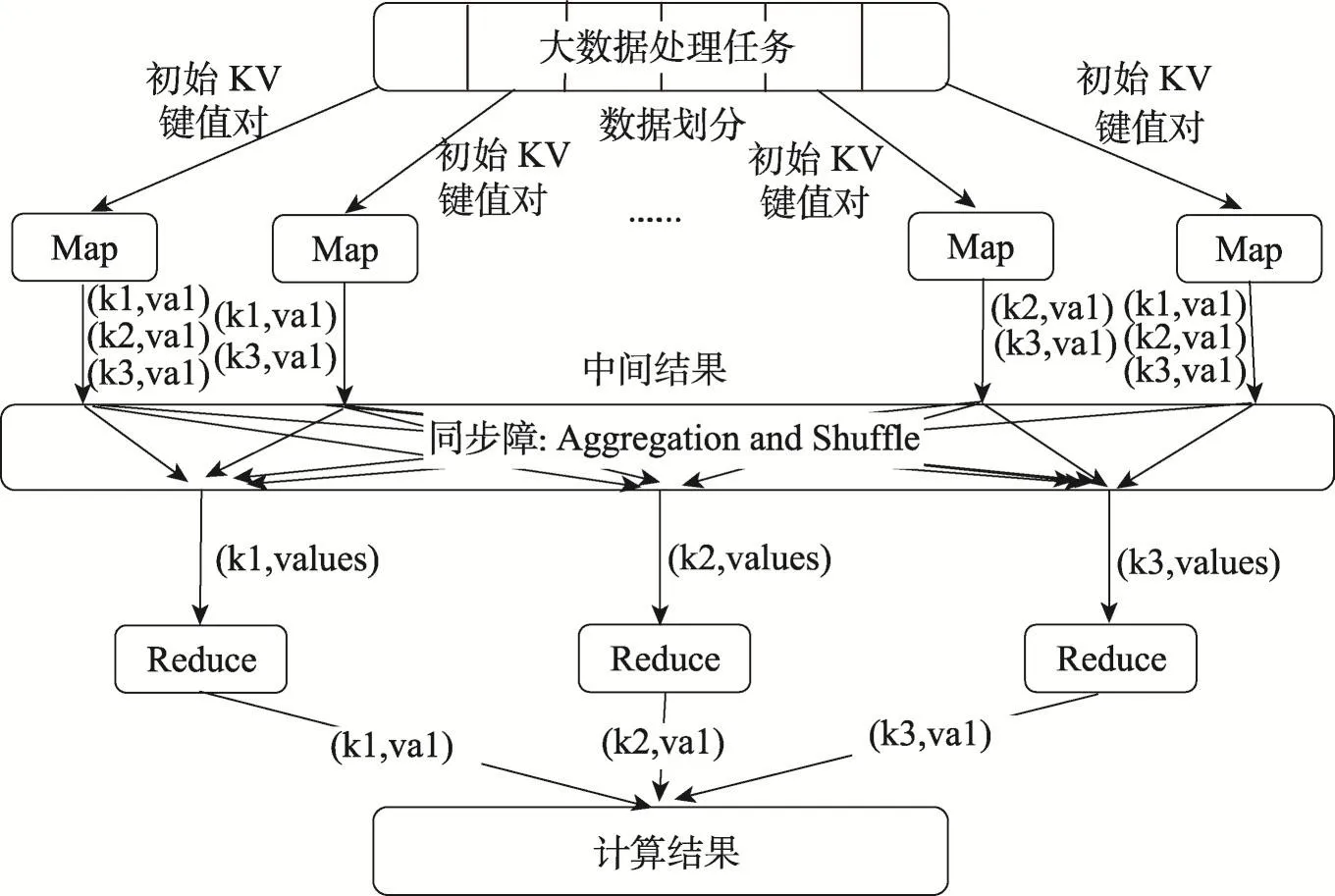
Fig.1 Map/Reduce execution process圖1 Map/Reduce執行過程圖
傳統的任務調度模型[11]在處理具體作業時效率較低,因此在后期國內外很多學者紛紛改進了任務調度模型,如Yang等人提出了Map Reduce Merge模型[12],通過在Map/Reduce執行后添加一個Merge處理,使數據能夠快速均衡地合并輸出(圖3)。這樣做對于一些小的無約束任務處理具有極高的效率,但是對于大量且具有復雜關系的任務在處理效率上就會變得較低,并且沒有充分考慮I/O問題。
針對上述問題,本文提出了一種在輸入任務到達Map節點前將復雜任務進行預處理的方法,先由Master節點將復雜任務的子任務表示為AOV(activity on vertex network)網并產生最佳拓撲排序,按排序結果由Master對每個子任務的執行順序進行標記,并結合剪枝算法產生的最佳分配矩陣實現對復雜任務的合理調度。通過在任務調度Map端創建內存資源池,收集Map處理過程中因為Spill溢寫而產生的數據,在Map任務執行結束后將所有結果匯總寫入中間結果集。此外在Reduce端增加Shuffle內存緩存區大小并提高閾值,使Copy來的數據逐步在內存中進行Merge,直到數據Merge結束,將結果傳入Reduce輸出最終結果。通過這種方式改進傳統數據處理模式,減少了內存與磁盤以及磁盤與磁盤之間的數據交換,從而減少任務數據交換的處理時間。并且在整個Map/Reduce任務調度過程不用考慮復雜任務的相互制約以及內存磁盤數據交換時間過長等問題,而在任務執行失敗時,Master節點可直接根據最佳拓撲排序依次回溯到該節點的父節點,獲取所需數據,直到滿足任務調度需求為止,這樣減少了遍歷所有依賴關系節點所需的時間,從而提高任務調度的整體效率。
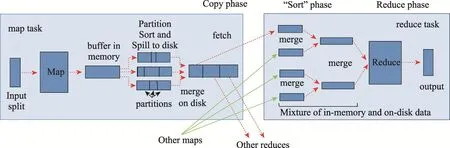
Fig.2 Map-Shuffle-Reduce process圖2 Map-Shuffle-Reduce過程
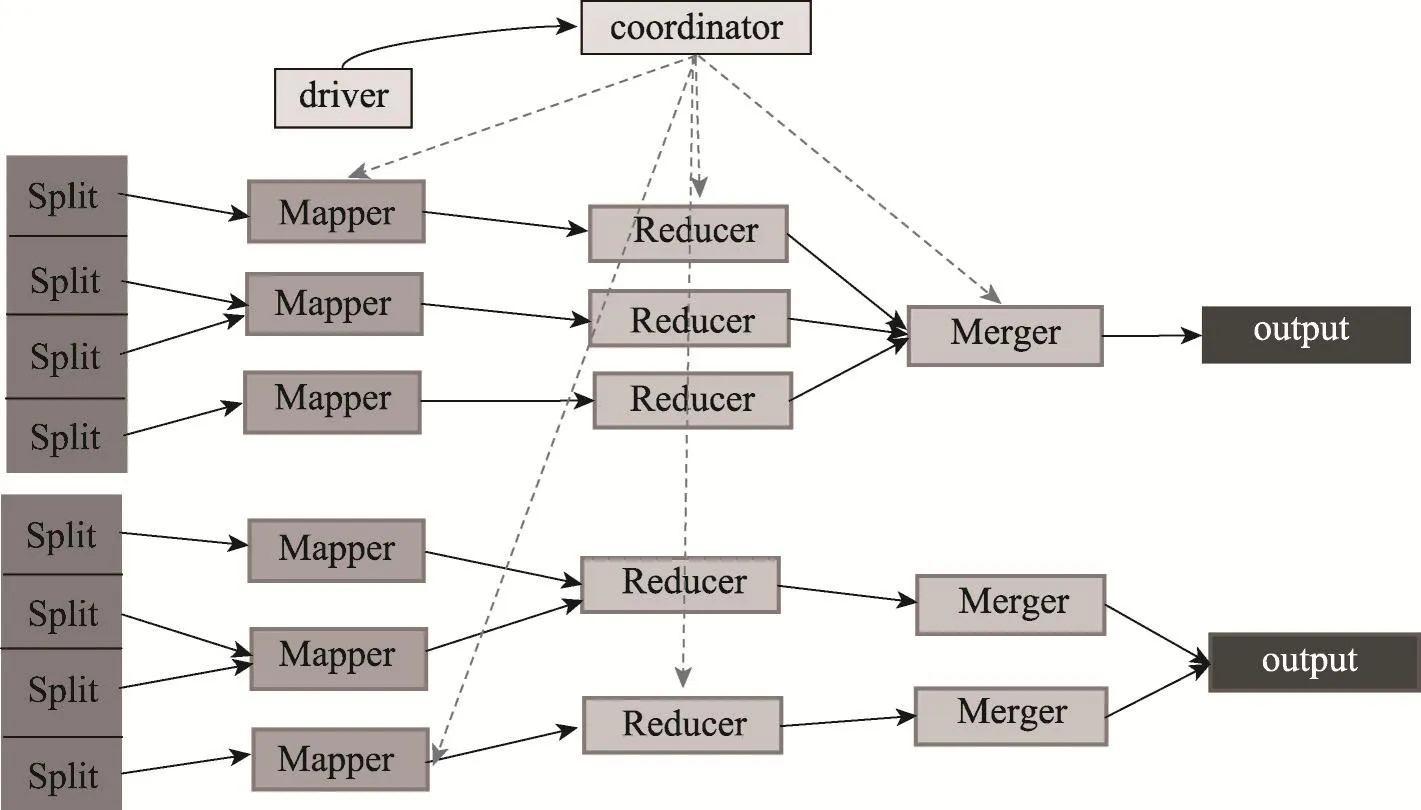
Fig.3 Map Reduce Merge chart圖3 Map Reduce Merge架構圖
3 剪枝算法任務調度理論和步驟
3.1 剪枝算法理論
云環境下基于剪枝算法[13]的復雜任務調度算法,是一種采用剪枝策略逐步縮小調度規模,最終實現復雜任務合理調度的全局最優算法。系統由Master節點將輸入的復雜任務依次分解為N個子任務,每個Map節點處理子任務的時間已知,即形成子任務和Map節點之間的n×n時間矩陣,依據該矩陣進行任務分配。任務調度要求確定子任務和Map節點之間的分配調度方案以達到效率最優時間最短的目的,且同時必須滿足兩個約束條件:每個任務都必須要執行,并且一個Map節點只處理一個子任務。
記矩陣

為任務分配矩陣(初始值為0),元素mij的值為1或0,1為true,0為false。記矩陣
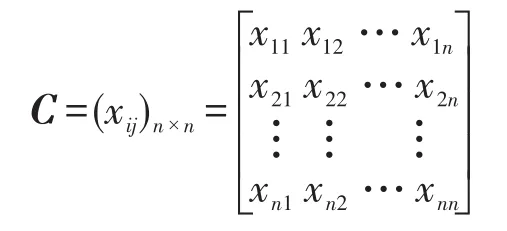
為任務分配的時間代價矩陣,xij表示第i個任務由第j個Map節點執行所用的時間代價。因此以最高效率完成任務分配可以表示為:

函數約束條件為:

即一個Map節點完成一個任務;
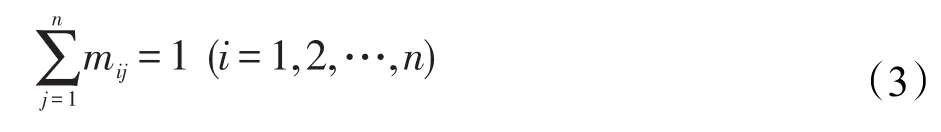
即一個任務只能被一個Map節點完成。對于任務分配可能存在N種分配方案。設T為所有可能的任務分配集合,M∈T,其中
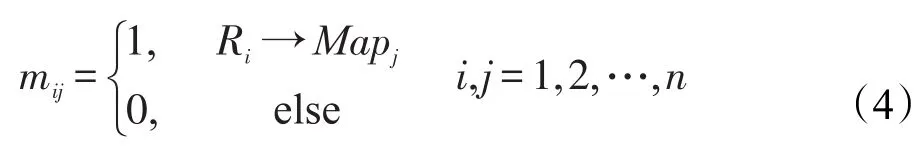
Ri→Mapj表示第i個任務被第j個節點處理;Fmin表示最優目標函數值;M′表示最優的目標分配方案。
3.2 相關定義
(1)F=FminM∈T(M,C)為全局最優任務分配的目標函數。
(2)T1={M|mrt=1}表示部分分配mrt=1已確定的可剪枝的局部最優方案,T1∈T,Ri表示第i個任務。
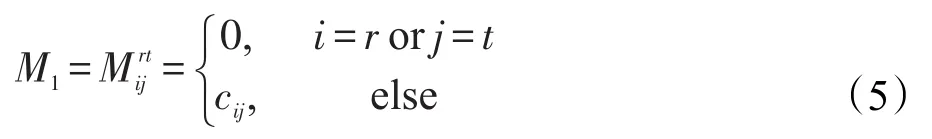
其中,r為時間代價矩陣C中列相減的最小值對應的行號;t為第一列的列號:
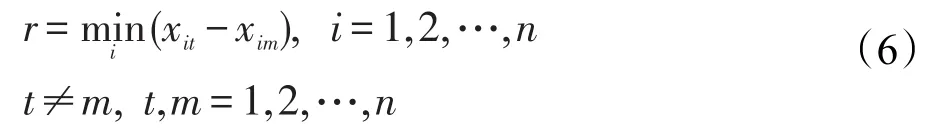
并且確保形成的局部任務分配矩陣函數值小于等于全局分配矩陣函數值:
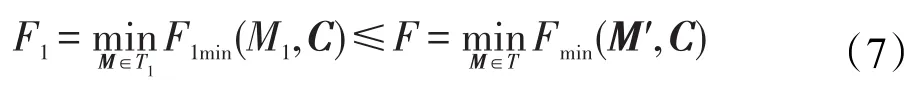
以后M1中的0元素將不再進行任務分配。以
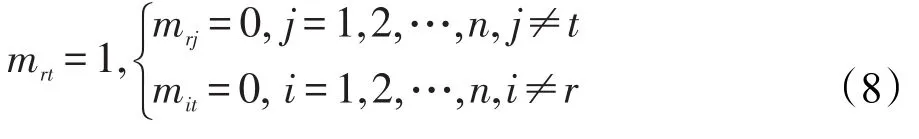
對M進行任務剔除。這樣就很明顯可以看出C變為一個n-1階的任務分配問題,則任務的分配空間將縮小,依次進行任務的剔除直到矩陣C只剩下一個元素為止。最后一個任務將直接進行分配,可以得到任務分配的最佳方案,每次對任務進行剔除的過程就是剪枝[14]。
(4)減法器(subtractor):由Master節點對產生的任務分配矩陣按照式(6)進行處理,是剪枝算法任務選取的依據。
(5)定義(T,→,A)為復雜任務,指輸入的任務具有一定依賴關系的任務組合,即在對用戶輸入的作業進行分割后產生的子任務之間具有一定偏序關系。其中T=(t1,t2,…,tn)是一組具有依賴關系的子任務,→是T中子任務的一種依賴關系,用來表示子任務之間的優先約束關系,如ti→tj,則表示ti必須在tj之前開始執行。A表示任務的計算量,Ai>0(1≤i≤n)為第i個任務的計算量。
3.3 復雜任務的預處理
云計算中,組成復雜任務的子任務之間存在一定的優先約束關系,因此可以將復雜任務表示為一個AOV網V=(T,E),其中T表示網中節點的集合,E表示邊的集合,邊的權值表示節點之間的依賴關系,權值越大依賴關系越大,如權值為0,則兩個任務可并行處理。AOV網的約束關系表示為一個節點在沒有獲得其前序節點信息之前是不能執行的。由Master節點將復雜任務轉換為AOV網并記錄任務的關聯關系及權值(圖4),再將AOV網用拓撲排序法轉換為最佳拓撲排序(optimum topological-sort,OTS)(圖5)。其中AOV網中V與T的節點數相同,V中有足夠的邊能連接所有節點且沒有回路。最后由Master節點按照OTS順序,對每個子任務的優先順序進行標記,實現剪枝前任務順序的初始化。
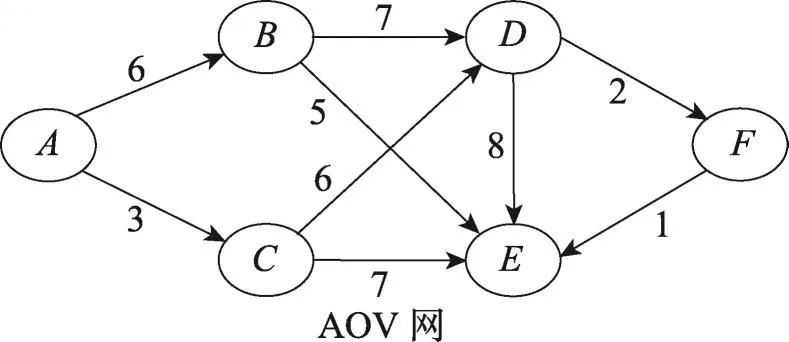
Fig.4 AOV net圖4 AOV網
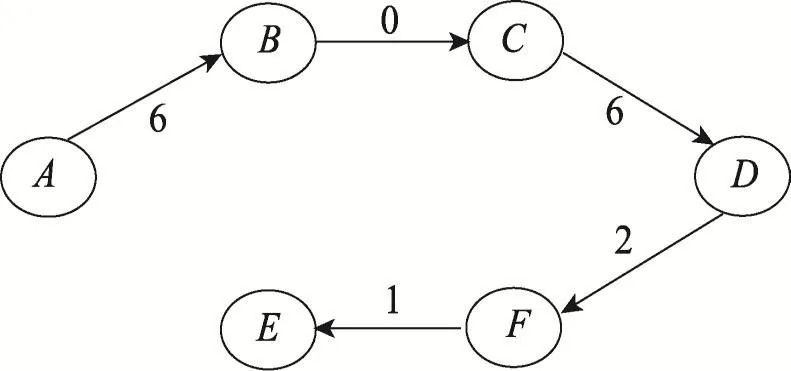
Fig.5 Optimum topological-sort圖5 最佳拓撲排序
3.4 剪枝算法復雜任務調度具體步驟
首先由Map/Reduce庫函數對用戶提交的任務請求進行劃分,對生成的子任務進行識別、分類,將具有依賴關系的子任務分為一類。簡單任務分為一類。其次將具有依賴關系的子任務進行復雜任務預處理,使任務具有順序標記,將具有依賴關系的子任務按照剪枝算法[15]進行分配。實現復雜任務分配最優、代價最小的調度過程如下:
(1)將所有任務看成簡單任務,由Master將任務分配矩陣M初始化,令所有元素為0代表為false,即不可執行狀態mij=0,i,j=1,2,…,n。
(3)進行剪枝,將選取的坐標(r,t)對應初始化矩陣M,將對應元素值改為1,即為true,該元素對應的行和列值不變:
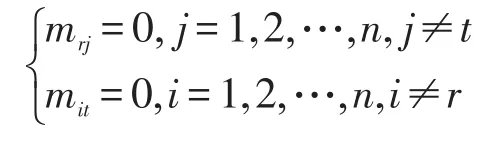
則該坐標對應的行和列除本元素外全部剪掉,使矩陣規模減小1階,這就是一次剪枝過程。
(4)對于剪枝后的矩陣重復執行(2)、(3)兩步,進行n-1次迭代,使矩陣最后只有一個元素,該元素的狀態改為可執行狀態,即為true,矩陣值為1。
(5)到此所有的復雜任務都進行了最優分配,每個節點對應每個任務的剪枝過程結束,最后按照復雜任務預處理產生的OTS順序,結合最優分配方案矩陣M′,由Master交給對應的Map節點進行處理。而簡單任務因為沒有相互約束關系,直接由Master節點按照節點預測時間與節點計算能力的比值矩陣依次提交給Map節點執行。
(6)至此復雜任務經剪枝算法處理后產生了最優的任務分配方案,并按此方案進行最終任務調度。在Map端首先為每個處理機根據Map節點的數量與內存緩沖區大小建立適當的內存資源池(大于單個Map節點內存緩沖區大小,且可適當調整)。然后將任務傳入Map節點進行任務處理,當產生的數據量達到Map節點內存緩存區閾值時,將Map節點產生的鍵值對進行Merge并傳入內存資源池,直到所有Map任務處理結束,開啟進程將數據寫入本地磁盤。
(7)在任務調度過程中由TaskTracker實時監測每個任務的執行狀態,如果任務執行成功,則將每個Map節點數據緩存區數據存入資源池,并記錄在資源池的存儲位置,再將其恢復到初始狀態并請求下次執行任務;如果任務處理失敗,保留當前節點數據,并根據Master節點存儲的每個任務的OTS以及任務依賴關系的大小,依次回溯到當前節點的父節點,獲取父節點在資源池中數據,直到在父節點中獲取的數據能夠滿足當前任務的數據需求為止,結合當前任務,按照節點處理能力重新分配任務節點進行任務處理。
(8)在Map節點任務執行完成后,向JobTracker發送任務完成指令,然后執行Reduce前的Shuffle過程。此時Shuffle的緩存區容量遠遠大于Reduce節點的緩存區,將所有已完成的Map節點緩存區的數據直接拉取Copy到Shuffle緩存區,并將獲取的數據進行Merge,直到獲取所有已完成的Map節點數據為止。此時調用進程將產生數據存入磁盤進行備份,同時將數據傳入Reduce端進行最后的Reduce過程,并將最終產生的文件存入HDFS(Hadoop distributed file system),整個任務調度過程完成。
由剪枝步驟可知,該算法對于求解一個n×n矩陣的分配問題時,只需要進行n-1次循環就可以求得最優解。該過程解決了復雜任務的資源和順序最優的處理問題,并且該過程減少了大量的數據I/O操作,使數據能夠在內存中進行交換,能夠在很大程度上提升程序的運行效率。根據對Map/Reduce模型的分析并結合任務的處理過程,實現了對原有的任務調度的合理簡化,提高了任務調度的分配效率。
3.5 剪枝算法實例具體實現過程
對于復雜任務分解后每個Map節點處理子任務的具體時間與任務形成的矩陣為(以3×3矩陣為例)首先初始化矩陣為,然后采用減法器對矩陣C進行取差得到矩陣C′=取C′最小值-5,得到r=1,t=1,根據(r,t)對M進行剪枝,進行第一次剪枝得到的結果為M=同時對C′同樣剪枝后取最小值為-4,得到r=2,t=2,進行第二次剪枝得到的結果為M′=這樣取得的最優任務分配方案為(1,4,1)。復雜任務的剪枝過程結束,一個三階任務分配兩次就可以得到最優解。結合OTS排序結果使任務按順序執行。這樣任務調度完成。
4 算法的驗證與比較
為了驗證本文算法的性能,將算法與公平份額調度算法[16]、遺傳算法[17]及GRAPHENE算法進行對比驗證。
實驗環境:使用Hadoop1.2.1,由6個節點組成集群環境,其中1個為Master節點,其余5個為Slaver節點,集群之間是同構的,具體的集群配置情況見表1。在實驗中為集群配置了默認的負載均衡策略,并且采用Ganglia來監測集群狀態,主要是監測內存利用率。

Table 1 Cluster related configuration表1 集群相關配置情況
實驗1驗證使用抽樣法對Map節點處理任務的時間進行估計是可行的。實驗使用Hadoop自帶的基準測試用例wordcount和terasort作為測試程序,并且為了確保任務處理時間的準確性,將程序運行4次并取平均值作為最終值。獨立運行wordcount和terasort采用不同數目的Map任務進行對比,結果如圖6所示。由圖可知,隨著Map節點的增加,任務的處理時間沒有明顯的變化,這說明在一個大作業中使用少量Map任務處理時間作為Map節點的處理時間進行預測是合理的。復雜任務只是任務之間具有依賴關系,在獲得必要數據后對節點處理時間影響不大,因此同樣可以進行預測。
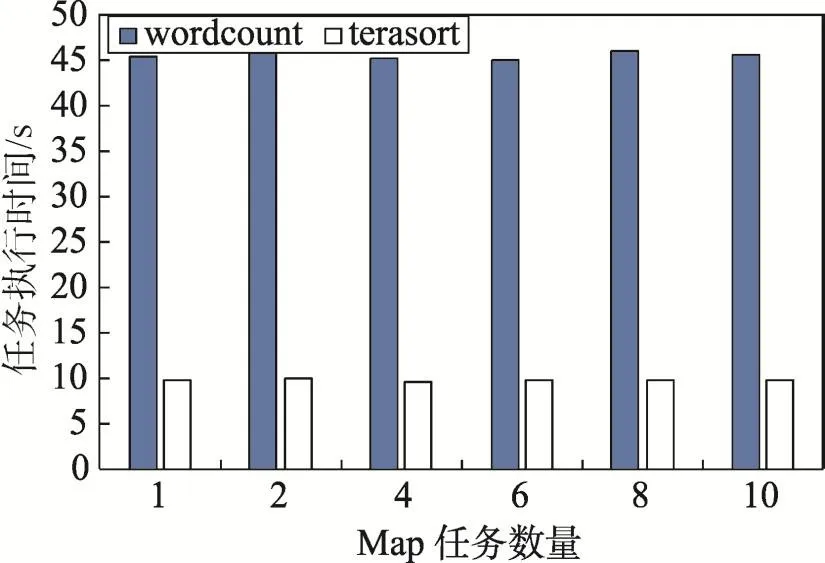
Fig.6 Task independent execution time圖6 任務獨立執行時間
實驗2驗證剪枝算法能夠提高任務調度整體效率和資源使用率。任務調度整體效率主要通過任務調度平均響應時間、任務調度執行時間以及不同算法的吞吐量進行衡量;資源使用率主要通過內存使用率進行衡量。采用Hadoop自帶的terasort基準測試程序進行測試,選取100,150,…,350個任務進行任務調度,4種不同算法的平均任務響應時間以及任務調度執行時間進行對比驗證,結果如圖7、圖8所示。
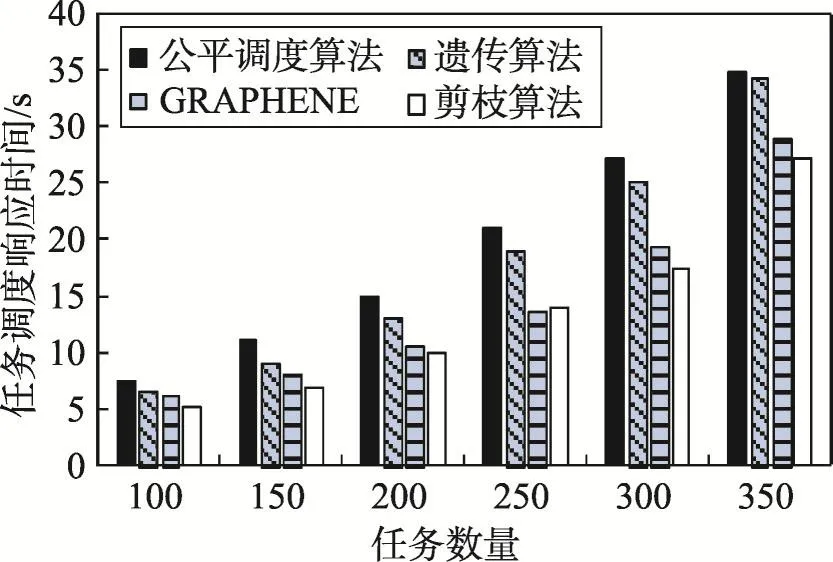
Fig.7 Task scheduling average response time圖7 任務調度平均響應時間
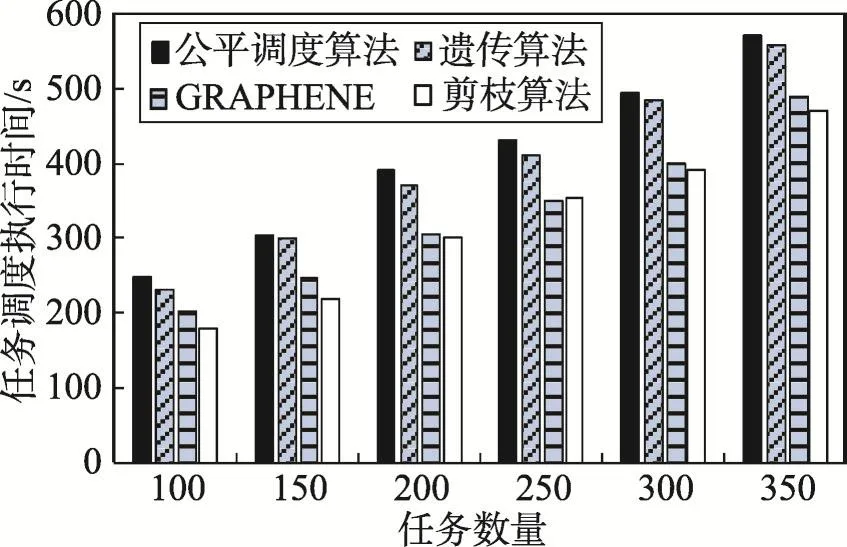
Fig.8 Task scheduling execution time圖8 任務調度執行時間
由圖7可知,隨著任務數量的增加,任務調度平均響應時間都在增加,遺傳算法的任務響應時間在任務較少時明顯低于公平調度算法,任務較大時任務執行效率略有下降,但明顯高于本文算法。在GRAPHENE算法仿真實驗中,因為無論任務數量的多少,都要先找出TroublesomeTasks,然后剩余部分被分為TroublesomeTasks的祖先、同輩和后代,最后再依據數據依賴關系進行分配,所以在任務較少時任務調度的響應時間相比本文算法相對較高,隨著任務數量的增加效率有很大提升。由圖8可知,隨著任務數量的增加,任務調度的執行時間變化趨勢與任務調度響應時間基本一致。
由圖9可知,剪枝算法的吞吐量在不同的數據流負載量下,均要高于其他的3種算法。其中公平調度算法以及遺傳算法的實驗結果隨著數據流負載量的改變,沒有太大波動,GRAPHENE算法隨著數據流負載量的增加逐步增大。當流量負載參數SL(stream load)從2.0增加到2.4時,剪枝算法的平均吞吐量有很大的提升,說明剪枝算法在任務請求與吞吐量之間是一種正相關關系,這也證明了剪枝算法具有較強的任務處理能力。
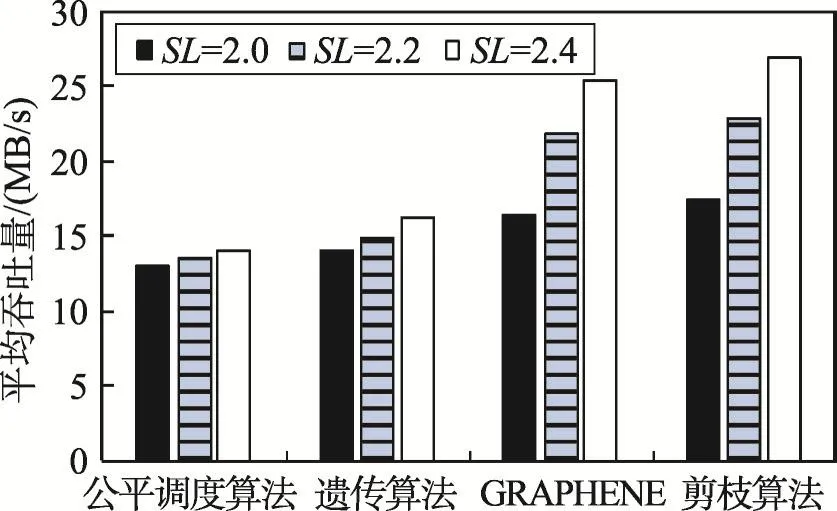
Fig.9 Average throughput of different algorithms圖9 不同算法的平均吞吐量
在資源利用率方面,選取算法在任務調度過程中100~500 s內的內存使用率情況進行對比(圖10),其中開始以及結束的內存使用率數據沒有截取。從圖10中可以看出,隨著時間的增加因為任務的大小以及內存使用情況等因素的影響,使得內存的使用率一直處在波動狀態。因為GRAPHENE算法是在內存中處理任務,而剪枝算法在任務調度過程中減少了內存與磁盤之間的數據交換,增加了數據在內存中處理的過程,所以在任務調度過程中剪枝算法的內存使用率與GRAPHENE算法的內存使用率基本一致,都要高于公平調度算法以及遺傳算法。根據任務調度處理時間、平均吞吐量以及內存使用率的對比可以得出,剪枝算法能夠提高任務調度的整體效率,提高資源的使用率。
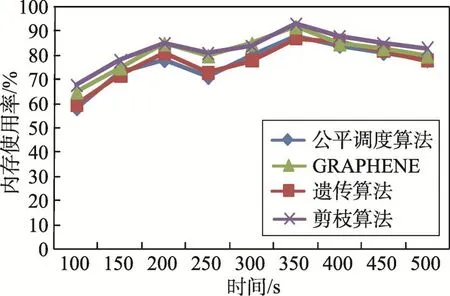
Fig.10 Memory utilization圖10 內存利用率
5 結論
本文主要論述了在Map/Reduce框架下的復雜任務的處理過程,通過Master節點將具有依賴關系的復雜任務的子任務轉化為AOV網,并按照依賴關系的大小產生最佳拓撲排序,實現對子任務處理順序的預處理。根據節點處理任務的時間建立任務與節點的時間度量矩陣,使用剪枝算法進行任務分配,得到全局最優分配方案,并結合OTS對任務進行調度。任務調度過程中,采用增加內存資源池與增大Shuffle緩存區大小等方法,使數據在內存中進行處理,減少了內存與磁盤以及磁盤與磁盤之間的數據交換,從而解決了處理時間過長、任務調度效率低的問題,提高了任務調度的效率。使用Hadoop平臺分別從任務調度效率與資源使用率角度,將剪枝算法與公平調度算法、遺傳算法以及GRAPHENE算法進行對比,實驗結果表明剪枝算法能明顯提高復雜任務調度整體效率,具有一定的理論指導意義。
[1]Vaquero L M,Rodero-Merino L,Caceres J,et al.A break in the cloud:towards a cloud definition[J].ACM SIGCOMM Computer Communication Review,2009,39(1):50-55.
[2]Armbrust M,Fox A.Above the clouds:a Berkeley view of cloud computing,UCB/EECS-2009-28[R].Berkeley:University of California,2009.
[3]Barroso LA,Dean J,H?lzle U.Web search for a planet:the Google cluster architecture[J].IEEE Micro,2003,32(2):22-28.
[4]Selvarani S,Sadhasivam G S.Improved cost-based algorithm for task scheduling in cloud computing[C]//Proceedings of the 2010 International Conference on Computational Intelligence and Computing Research,Coimbatore,Dec 28-29,2010.Piscataway:IEEE,2010:620-624.
[5]Karthick A V,Ramaraj E,Subramanian R G.An efficient multi queue job scheduling for cloud computing[C]//Proceedings of the 2014 World Congress on Computing and Communication Technologie,Tiruchirappalli,Feb 27-Mar 1,2014.Washington:IEEE Computer Society,2014:164-166.
[6]Dong Xicheng,Wang Ying,Liao Huaming.Scheduling mixed real-time and non-real-time applications in MapReduce environment[C]//Proceedings of the 17th International Conference on Parallel and Distributed Systems,Tainan,China,Dec 7-9,2011.Washington:IEEE Computer Society,2011:9-16.
[7]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communication of the ACM,2008,51(1):107-113.
[8]Shi Hengliang.Research of job scheduling on cloud computing[D].Nanjing:Nanjing University of Science and Technology,2012.
[9]Mathew T,Sekaran K C,Jose J.Study and analysis of various task scheduling algorithms in the cloud computing envi-ronment[C]//Proceedings of the 3rd International Conference on Advances in Computing,Communications and Informatics,Delhi,Sep 24-27,2014.Piscataway:IEEE,2014:658-664.
[10]Lu Lu,Shi Xuanhua,Jin Hai,et al.Morpho:a decoupled MapReduce framework for elastic cloud computing[J].Future Generation Computer Systems,2014,36:80-90.
[11]Zarei M H,Shirsavar MA,Yazdani N.AQoS-aware task allocation model for mobile cloud computing[C]//Proceedings of the 2nd International Conference on Web Research,Tehran,Apr 27-28,2016.Piscataway:IEEE,2016:43-47.
[12]Yang H C,Dasdan A,Hsiao R L,et al.Map-reduce-merge:simplified relational data processing on large clusters[C]//Proceedings of the 2007 International Conference on Management of Data,Beijing,Jun 12-14,2007.New York:ACM,2007:1029-1040.
[13]Rong H J,Ong Y S,Tan A H,et al.A fast pruned-extreme learning machine for classification problem[J].Neurocomputing,2008,72(1/3):359-366.
[14]Ma Yunhong,Jing Zhe,Zhou Deyun.A faster pruning optimization algorithm for task assignment[J].Journal of Nothwestern Polytechnical University,2013,31(1):40-43.
[15]Zheng Wei,Ma Nan.An improved post-pruning algorithm for decision tree[J].Computer&Digital Engineering,2015,43(6):960-966.
[16]Ma Xiaoyan,Hong Jue.A multi-resource fair scheduler of Hadoop[J].Journal of Integration Technology,2012,1(3):66-71.
[17]Hu Yanhua,Tang Xinlai.A task scheduling algorithm based on improved genetic algorithm in cloud computing environment[J].Computer Technology and Development,2016,26(10):137-141.
附中文參考文獻:
[8]史恒亮.云計算任務調度研究[D].南京:南京理工大學,2012.
[14]馬云紅,井哲,周德云.一種任務分配問題的快速剪枝優化算法[J].西北工業大學學報,2013,31(1):40-43.
[15]鄭偉,馬楠.一種改進的決策樹后剪枝算法[J].計算機與數字工程,2015,43(6):960-966.
[16]馬肖燕,洪爵.多資源公平調度器在Hadoop中的實現[J].集成技術,2012,1(3):66-71.
[17]胡艷華,唐新來.基于改進遺傳算法的云計算任務調度算法[J].計算機技術與發展,2016,26(10):137-141.
猜你喜歡
瘋狂英語·初中天地(2021年5期)2021-07-21 02:24:28
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
遼寧經濟(2017年6期)2017-07-12 09:27:16
中國衛生(2016年9期)2016-11-12 13:27:54
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國洗滌用品工業(2015年7期)2015-02-28 19:02:38
電子設計工程(2015年12期)2015-02-27 12:06:10
中國衛生(2014年11期)2014-11-12 13:11:32
