基于密度最大值的K—means初始聚類中心點(diǎn)算法改進(jìn)
2018-01-11 14:01:52劉闖陳桂芬
數(shù)字技術(shù)與應(yīng)用 2017年11期
劉闖+陳桂芬
摘要:聚類分析是機(jī)器學(xué)習(xí)中重要的方法,傳統(tǒng)的K-means算法對于聚類的初始中心點(diǎn)的選擇具有隨機(jī)性,這就造成不同的選擇產(chǎn)生不同的聚類結(jié)果。針對這一問題,提出一種基于密度最大值的優(yōu)化初始聚類中心選取算法。試驗結(jié)果顯示,改進(jìn)后的算法與傳統(tǒng)算法相比具有較高的穩(wěn)定性和可靠性。
關(guān)鍵詞:聚類;穩(wěn)定性;局部密度;可靠性
中圖分類號:TP393 文獻(xiàn)標(biāo)識碼:A 文章編號:1007-9416(2017)11-0118-02
1 引言
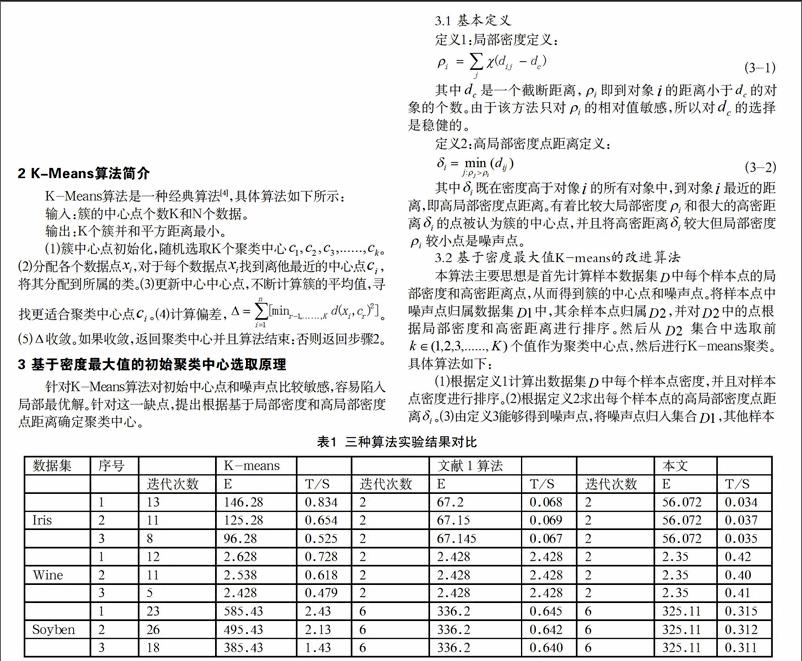
聚類算法是數(shù)據(jù)挖掘中一種重要的算法,K-means聚類算法思路簡單,聚類快速。但是,其缺點(diǎn)也是十分明顯,易受噪聲影響,容易陷入局部最優(yōu)解。為解決傳統(tǒng)K-means聚類算法問題,很多學(xué)者從不同角度提出改進(jìn)算法。文獻(xiàn)[1]根據(jù)密度和平均距離完成聚類中心的優(yōu)化,文獻(xiàn)[2]選擇相互距離最遠(yuǎn)的K個處于高密度區(qū)域的點(diǎn)作為中心。文獻(xiàn)[3]選擇平均密度優(yōu)化初始聚類中心。綜合各個改進(jìn)思想,提出基于密度最大值初始聚類中心的K-means算法。
4 仿真實(shí)驗分析
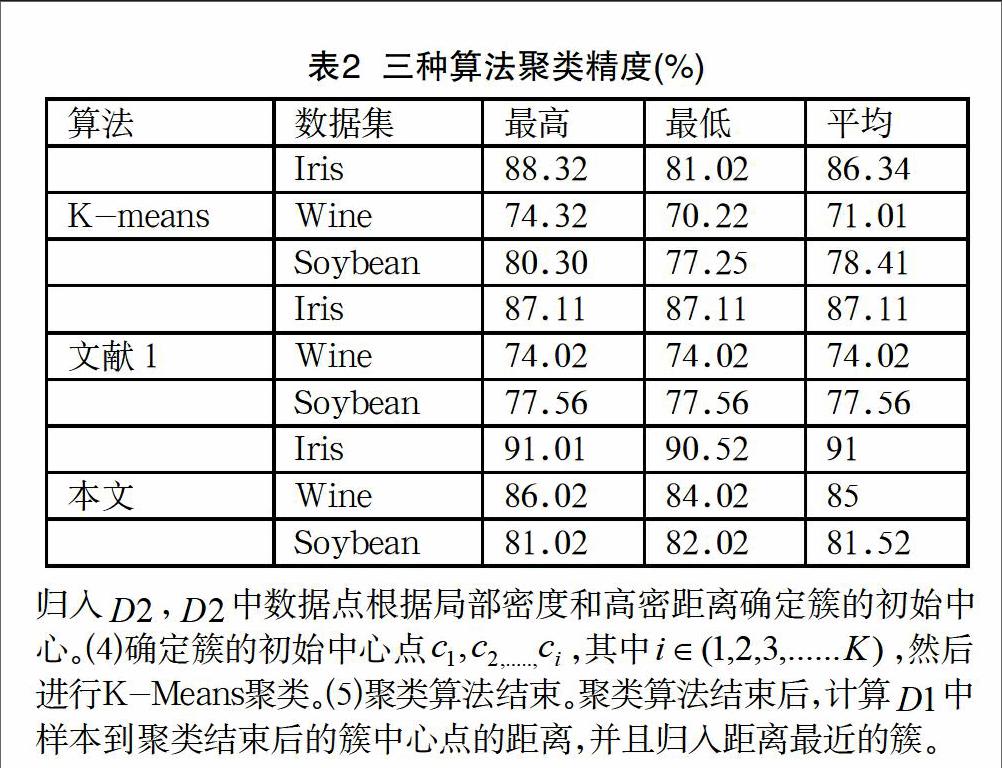
為驗證改進(jìn)算法的有效性,采用國際上的專門用來測試機(jī)器學(xué)習(xí)算法的UCI數(shù)據(jù)集中Iris、Wine、Soybean這三組數(shù)據(jù)進(jìn)行測試。Iris數(shù)據(jù)有950條數(shù)據(jù),每個數(shù)據(jù)對象有4個屬性,分三類;Wine數(shù)據(jù)750條數(shù)據(jù),每個數(shù)據(jù)13屬性,分三類;Soybean數(shù)據(jù)500條,每個數(shù)據(jù)對象35個屬性,分7類。測試實(shí)驗結(jié)果如表1,表2所示。
由表1,表2實(shí)驗對比結(jié)果可知改進(jìn)后算法在迭代次數(shù),平方誤差,測試時間,準(zhǔn)確率等方面對比傳統(tǒng)K-means算法,由表可知,改進(jìn)后算法準(zhǔn)確率明顯高于其他兩種算法。
5 結(jié)語
對于提出基于密度最大值初始化聚類中心的K-means算法,通過實(shí)驗對比表明,算法迭代次數(shù)和聚類所需時間減小,準(zhǔn)確率提高。
參考文獻(xiàn)
[1]王浩,黃越.基于距離測度學(xué)習(xí)的AP聚類圖像標(biāo)注[J].計算機(jī)工程與應(yīng)用,2016:43-46.
[2]孫士保,秦克云.改進(jìn)的k-平均聚類算法研究[J].計算機(jī)工程,2014:57-62.
[3]邢長征.基于平均密度優(yōu)化初始聚類中心的K-means算法[J].計算機(jī)應(yīng)用工程,2014:56-59.
[4]Han Jiawei.Data mining:concepts and techniques[M].San Francisco:Morgan Kaufmann Publishers,2014:32-35.
Abstract:Clustering analysis is an important method in machine learning. The traditional K-means clustering algorithm has randomness to the initial central point of clustering, which leads to different choices to produce different clustering results. In response to this problem, an optimal initial clustering center selection algorithm based on maximum density is proposed. Compared with the standard data UCI, the experiment shows that the improved algorithm has higher stability and reliability than the traditional algorithm.
Key Words:Clustering;stability;local density;reliabilityendprint
