基于情感分析的美食評論挖掘
2018-01-04 12:02:04吉書佩李晟宇
電腦知識與技術 2018年29期
吉書佩 李晟宇
摘要:美食評論表達了人們的各種情感色彩和情感傾向性,對于消費者的選擇具有重要的影響。通過結合情感分析和評論挖掘技術,設計并實現了一個美食評論挖掘系統,幫助用戶從大量信息中快速選擇最為合適的餐廳。
關鍵詞:情感分析;評論挖掘;推薦系統
中圖分類號:TP391 文獻標識碼:A 文章編號:1009-3044(2018)29-0208-03
Abstract:Food reviews express people's various emotionsand emotional tendencies, which have an important impact on consumers' choices. This paper combines emotional analysis and review miningto complete a food review mining system, which helps users to quickly select the most suitable restaurants from a large amount of information.
Key words:sentimental analysis;review mining;recommender system
1引言
隨著以用戶為中心的web2.0的發展,特別是大眾點評、美團網等美食點評網站的飛速發展,為人們打造了一個良好的發表自己的觀點和想法的環境,由此產生了大量的用戶對于某一對象的評論信息。而由于這些美食評論信息越來越多,消費者更加容易迷失。
這些美食評論表達了人們的各種情感色彩和情感傾向性,同時也會對其他用戶的決定造成影響。如今用戶越來越習慣于參考其他用戶的評論信息,傾向于選擇口碑好、評價高的餐廳。但是,無論是餐館還是評論數量都十分巨大,人工查找和利用這些評論信息成本很高。此外,傳統的推薦系統所提供的得分往往是用戶自己打出來的分數,而由于用戶的評分標準不同,這個分數與用戶評論內容往往并不相符。因此,如何從這些評論信息中搜集、提煉出有用的內容并分析出用戶真正的情感信息就成為一個重要的課題。
在這一背景下,本文從餐飲這一行業出發,結合情感分析和評論挖掘技術,完成了一個美食評論挖掘系統,幫助用戶從大量信息中快速選擇最為合適的餐廳。
2系統框架
本文結合情感分析和評論挖掘技術,完成了一個美食評論挖掘系統,其主要由數據采集、特征提取、情感分析和美食應用四部分構成,如圖1所示。
2.1 數據采集
美團、大眾點評和百度糯米都是現階段知名度和使用度最高的美食網站,有眾多商鋪入駐且評論數量多,因此更具有代表性。而又由于大眾點評和美團合并導致商鋪評論重合,因此最終我們選定美團和百度糯米兩個網站作為此次評論采集的對象。
其次,我們將范圍劃定在南昌地區,又由于南昌地區的餐廳多樣,評論繁多,為了使研究結果更加簡潔明了,最終我們選取了火鍋和西餐這兩個最有代表性的種類作為此次研究的對象。
集搜客(http://www.gooseeker.com/)是一款操作方便、專業的數據采集器,可以使用爬蟲群并發抓取海量網頁,并且可以把數據直接導入Excel,非常適合我們做評論抓取。于是我們使用“集搜客”這款軟件在2018年2月至2018年3月采集了這兩家美食網站上的593家店鋪,共312337條評論(已處理空白評論)。
2.2 特征提取
首先,我們對搜集到的評論進行分詞處理并進行詞頻統計,在此基礎上構建特征詞表。
2.2.1 詞頻統計
詞頻統計是一種詞匯分析研究方法,通過對一定長度文本的詞頻進行統計、分析,進而描繪出詞匯規律。到目前為止,已有很多學者對詞頻統計規律進行研究,包括詞頻統計規律的提出[1-2]、驗證[3]、應用[4-5]等各個方面[6]。這種方法適用于評價著作、確定某種語言或某學科的基本詞匯。
我們使用“集搜客”的一個分詞打標軟件——天據英眼進行分詞處理與詞頻統計。該軟件操作簡單,支持Excel直接導入,自動分詞,并且可以把詞語列表按照詞頻大小排序,點擊詞語可以查看樣本數據,篩選出有用的詞。系統會自動把詞語與原文本進行匹配,得到選詞結果表和打標結果表。因此我們使用該軟件得到評論中的所有詞語及出現頻率。
2.2.2 提取特征詞
我們從評論語料中抽取出現頻率在200以上(最高頻率在28000以上)的名詞,人工判別其中與美食有關的名詞,如“環境”、“口味”、“服務”等,并對這些名詞進行分類,最終得到了有關餐廳的特征詞和其對應的指示詞,如表1所示。
2.3 情感分析
情感分析是指分析說話者在傳達信息時所隱含的情緒狀態,對說話者的態度、意見進行判斷或者評估。按照處理文本的粒度不同,情感分析可分為詞語級、短語級、句子級、篇章級以及多篇章級等幾個研究層次[7]。而基于我們的研究內容,主要使用的句子級的情感分析。
在情感分析方面,主要使用的技術分兩大類:一類是采用情感詞典與規則相結合的方法,根據文本中所包含的正向情感詞和負向情感詞的個數來進行情感分類;另一類是用機器學習的方法,選擇文本中的一些特征,標注訓練集和測試集,使用樸素貝葉斯、最大熵、支持向量機等分類器來進行情感分類[8]。而本文將使用后者進行分析。
2.3.1 預處理
首先,由于每一條評論的內容中都包含多個特征詞和指示詞,且摻雜著許多與觀點無關的詞語或句子,這些語句會對之后的情感分析產生不可預見的影響。因此在進行評分之前,對文本進行篩選、分類并刪除無關信息是必不可少的,簡而言之,就是進行預處理。
Python語言是一種功能強大的具有解釋性、交互性和面向對象的第四代計算機編程語言。Python也是一種腳本語言,它開發代碼的效率非常高,它具有強大和豐富實用的第三方標準庫,使得編程變得簡潔快速。Python語言可通過其提供的標準庫有效的解決用Python進行大數據處理的問題,這些數據轉換成適合Python分析的數據結構,之后用Python相應的工具進行數據分析、處理,提出數據特征并用一定的結構形式表現出來[9]。
我們用Python語言編寫程序對原評論進行處理,得到包含某個指示詞的所有語句,并根據表1將這些指示詞下的語句匯總在一起,即得到經過處理的、包含特征詞的語句。比如,我們采集的評論中關于餐廳“小龍坎老火鍋(勝利路店)”有一條評論為“味道很不錯,就是量太少,都沒吃飽,還可以,服務很好!!”則按指示詞可分為“味道很不錯”、“就是量太少”和“服務很好”,并把它們分別添加到該餐廳的特征詞“味道”、“服務”和“份量”下面。
2.3.2 情感評分
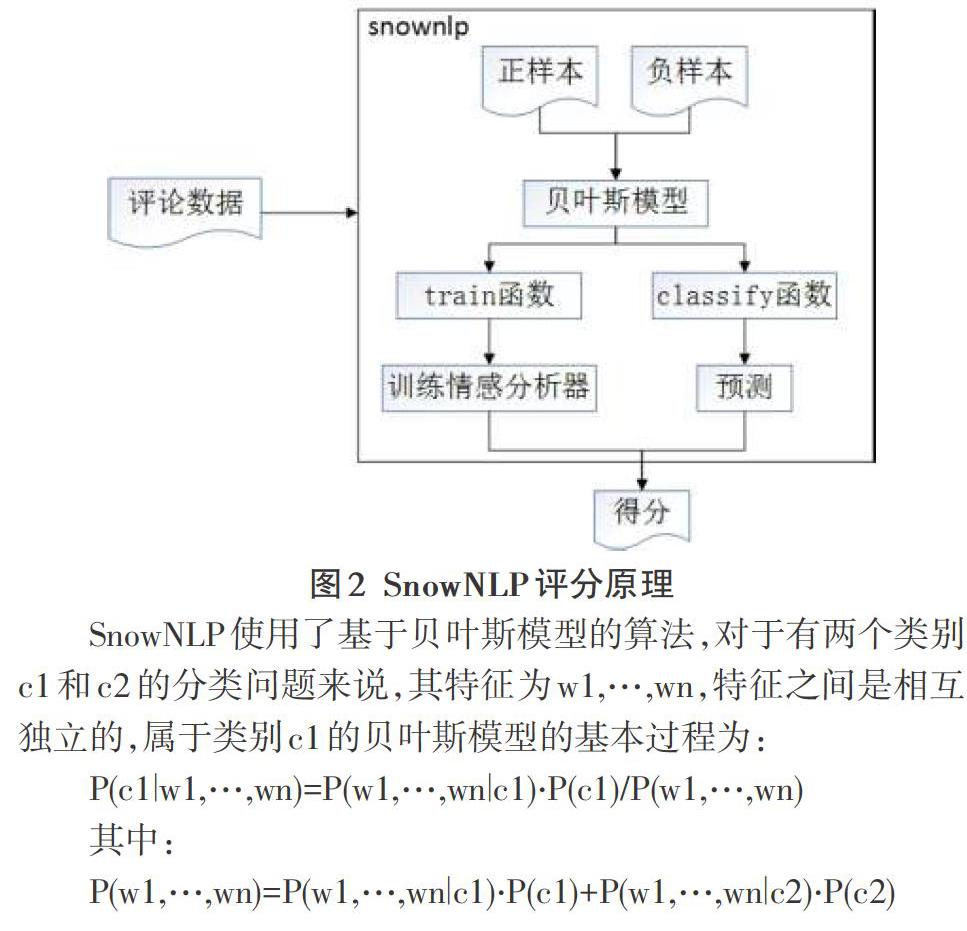
得到經過處理并已按特征詞分好組的語句后,我們選擇使用Python的庫——SnowNLP進行情感分析。SnowNLP中文文本分析工具是專門針對中文文本進行處理的類,可以進行中文分詞、詞性標注、情感分析、文本分類、提取文本關鍵詞等。我們知道,任何一個情感分析工具都是被訓練出來的。訓練時使用的是什么文本材料,會直接影響到模型的適應性。而SnowNLP的訓練文本就是評論數據。因此,用它來分析中文評論信息是比較合適的。但為了使分數更加合理,我們重新訓練了情感分析模型,如圖2所示。
我們使用該庫對所有句子進行評分,得出每個句子里所包含的情感色彩。最后再按照餐廳得出每個特征詞的平均分。例如上面的例子中,“味道很不錯”得分為0.89,“就是量太少”得分為0.27,“服務很好”得分為0.77。由此我們便可得出每個餐廳在不同方面的得分。
注意,在這個過程中,我們并不對“人群”這一特征詞進行處理,對于這一分類,我們只需對每個指示詞在每個餐廳中出現的次數作記錄即可。同樣,“人均”這一指示詞多為“人均XX元”這樣的句式,因此,我們也不對其進行評分,而是算出每個餐廳的人均值為多少元。
2.4 系統應用
前面我們已經詳細介紹了如何進行情感分析,并對我們采集到的評論按特征詞分類并進行評分。在前文已得到相關數據的基礎上,我們設計并開發了一款移動美食推薦系統。在該系統中,我們主要按照我們所得到的特征詞——味道、服務、環境、價格、份量、位置、菜品、人氣、人群——為用戶進行推薦。用戶可以選擇自己感興趣的某一個(或某幾個)特征詞,系統則將該特征詞下的餐廳按照得分高低排序并返回給用戶(若選擇多個特征詞,則將多個特征詞的得分的平均數反饋給用戶)。
3 系統演示
該系統使用eclipse軟件開發,并使用SQL Server數據庫。用JavaWeb開發網頁,采用B/S三層架構,按不同用戶的不同偏好為其推薦合適的餐廳,只要用戶有瀏覽器就可以使用該系統。
接下來我們來演示一下這個系統。首先登錄系統,會出現如圖3所示的二級聯動下拉框。
第一個下拉框可以選擇火鍋和西餐兩個選項,第二個下拉框可以選擇味道、服務、環境等特征詞,可以多選。選擇后出現如圖4所示的查詢結果。
該查詢結果包括排名、店名、情感得分以及查看評論鏈接,用戶可以點擊店名跳轉到相應的美團鏈接以查看餐廳的詳細信息、地址以及電話等,也可以點擊“查看評論詳情”查看評論,如圖5所示。
4結束語
隨著O2O電子商務的快速發展,越來越多的人選擇通過使用互聯網和移動互聯網來查找和訂購美食。美食評論表達了人們的各種情感色彩和情感傾向性,對于消費者的選擇具有重要的影響。本文結合情感分析和評論挖掘技術,完成了一個美食評論挖掘系統,幫助用戶從大量信息中快速選擇最為合適的餐廳。
參考文獻:
[1] ZIPF G K.Human behavior and the principle of least effort: an in-troduction to human ecology[M].Boston: Addison-Wesley Press,1949: 23.
[2] BOOTH A D.A law of occurrences for words of low frequency[J].Information and Control,1967,10(4): 386-393.
[3] EGGHE L.A new short proof of Naranans theorem,explaining Lotkas law and Zipfs law[J]. Journal of the American Society for Information Science and Technology,2010,61(12): 2581-2583.
[4] CHAN P,HIJIKATA Y,NISHIDA S. Computing semantic relat-edness using word frequency and layout information of wikipedia[C]//Proceedings of the 28th Annual ACM Symposium on Ap-plied Computing.New York: ACM,2013: 282-287.
[5] SURYASEN R,RANA M S.Content analysis and application of Zipfs law in computer science literature[C]//Proceedings of the 2015 4th International Symposium on Emerging Trends and Technologiesin Libraries and Information Services.Piscataway,NJ: IEEE,2015: 223-227.
[6]羅燕,基于詞頻統計的文本關鍵詞提取方法[J]. 計算機應用,2016,36(3): 718-725.
[7] Huang XJ, Zhao J. Sentiment analysis for Chinese text. Communications of CCF, 2008,4(2) (in Chinese with English abstract).
[8] 陳顧遠. 一種基于微博數據的公眾環境污染情感指數估算方法[G]//中國環境科學學會環境信息化分會.全國環境信息技術與應用交流大會暨中國環境科學學會環境信息化分會年會論文集. 北京:出版社不詳,2016: 469-476
[9] 肖旻,陳行.基于Python語言編程特點及應用之探討[J]. 電腦知識與技術,2014(6).
【通聯編輯:王力】
