基于Python的決策樹算法在學生招生錄取數據中的應用研究
2018-01-04 12:02:04黃雪華
電腦知識與技術 2018年29期
摘要:分類算法是數據挖掘技術中非常重要的一個研究領域,預測離散數據的分類標號。主要應用于客戶分類、垃圾郵件處理、信用卡分級等。該文主要研究分類中的決策樹算法,并應用于我校學生招生錄取數據,采用Python語言建立分類模型,并驗證了該模型的準確率。
關鍵詞:決策樹;Python;招生數據
中圖分類號:TP311 文獻標識碼:A 文章編號:1009-3044(2018)29-0016-02
1 決策樹理論介紹
決策樹算法是一種典型的分類算法,它的分類過程是基于樣本數據建立一棵倒立的樹的過程。從樹的根節點到葉節點的路徑實際就是決策的過程,確定數據樣本所屬類標號的過程,它是一個遞歸地從上到下確定分支節點和葉節點的過程﹒葉節點存放的是數據樣本所屬的類標號;分支節點根據數據樣本的某個合適的屬性值進行數據集劃分[1]。
2數據介紹
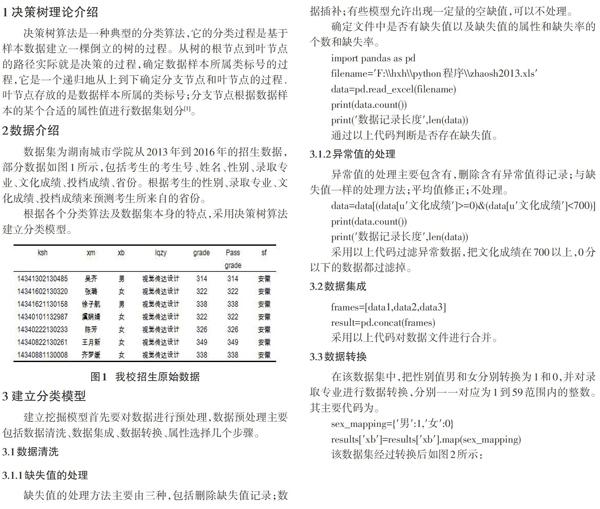
數據集為湖南城市學院從2013年到2016年的招生數據,部分數據如圖1所示,包括考生的考生號、姓名、性別、錄取專業、文化成績、投檔成績、省份。根據考生的性別、錄取專業、文化成績、投檔成績來預測考生所來自的省份。
根據各個分類算法及數據集本身的特點,采用決策樹算法建立分類模型。
3 建立分類模型
建立挖掘模型首先要對數據進行預處理,數據預處理主要包括數據清洗、數據集成、數據轉換、屬性選擇幾個步驟。
3.1數據清洗
3.1.1缺失值的處理
缺失值的處理方法主要由三種,包括刪除缺失值記錄;數據插補;有些模型允許出現一定量的空缺值,可以不處理。
確定文件中是否有缺失值以及缺失值的屬性和缺失率的個數和缺失率。
通過以上代碼判斷是否存在缺失值。
3.1.2異常值的處理
異常值的處理主要包含有,刪除含有異常值得記錄;與缺失值一樣的處理方法;平均值修正;不處理。
采用以上代碼過濾異常數據,把文化成績在700以上,0分以下的數據都過濾掉。
3.2數據集成
采用以上代碼對數據文件進行合并。
3.3數據轉換
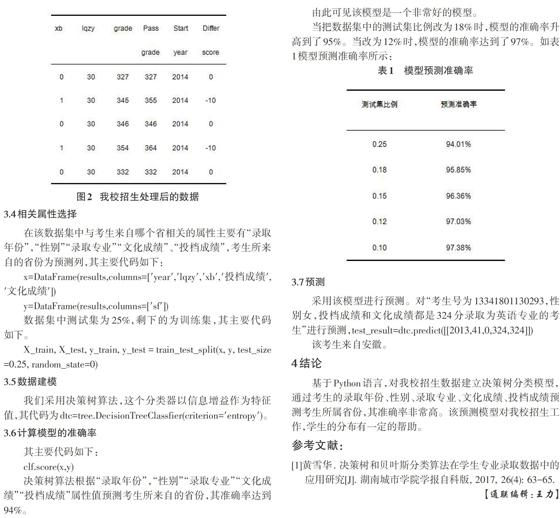
在該數據集中,把性別值男和女分別轉換為1和0,并對錄取專業進行數據轉換,分別一一對應為1到59范圍內的整數。其主要代碼為。
4結論
基于Python語言,對我校招生數據建立決策樹分類模型,通過考生的錄取年份、性別、錄取專業、文化成績、投檔成績預測考生所屬省份,其準確率非常高。該預測模型對我校招生工作,學生的分布有一定的幫助。
參考文獻:
[1]黃雪華. 決策樹和貝葉斯分類算法在學生專業錄取數據中的應用研究[J]. 湖南城市學院學報自科版, 2017, 26(4): 63-65.
【通聯編輯:王力】
