基于粗糙集的決策樹在醫療診斷中的應用
2017-12-20 10:06:16黃錦靜李夢天
計算機技術與發展 2017年12期
關鍵詞:肺癌
黃錦靜,陳 岱,李夢天
(中國礦業大學 計算機科學與計算學院,江蘇 徐州 221116)
基于粗糙集的決策樹在醫療診斷中的應用
黃錦靜,陳 岱,李夢天
(中國礦業大學 計算機科學與計算學院,江蘇 徐州 221116)
網上醫療診斷越來越受歡迎,電子病例的數據也越來越多。如何從眾多的醫療數據中降低醫療數據的冗余度,快速提取有用的醫療價值,提高醫療診斷的速度和精度,成了一個大家研究的熱點問題。針對這一系列問題,研究了醫療系統關于肺癌診斷的一些數據,建立了基于屬性依賴改進的可分辨矩陣屬性約簡的C4.5算法,并用隨機森林進行算法改進。屬性約簡算法降低了醫療數據的冗余度,決策樹算法提取了肺癌診斷的一些規則,隨機森林提高了醫療診斷的準確性。文中對肺癌診斷場景進行了仿真實驗與應用,并將單純的C4.5算法,屬性約簡與單棵C4.5決策樹,屬性約簡和C4.5決策樹隨機森林進行性能比較。實驗結果表明,該方法加快了計算速度,提高了醫療診斷的精度。
粗糙集;屬性約簡;可分辨矩陣;C4.5算法;決策樹
1 概 述
隨著計算機行業的快速發展,醫院也開始走向電子化時代,網上掛號、網上診斷、電子病例等,積累了海量的醫療數據。如何利用這些數據挖掘出醫療價值,即基于醫療的數據挖掘,成為一個非常熱門的研究領域。醫療數據的挖掘在醫療領域應用的主要內容包括醫療圖像數據挖掘、醫療管理檢索系統和電子病例的分析等。例如,在醫療圖像方面,文獻[1]提出了一種基于成像的神經退行性疾病的分類方法,以提取突出的腦模式。在電子病例這種文本數據方面,文獻[2]提出了一種可變精度粗糙集模型的屬性約簡算法。
特別是電子病例這類的文本數據,數據量龐大,儲存了大量信息,是數據挖掘的一個熱點對象。病例隱含了眾多信息,記錄了很多病情癥狀,即很多屬性特征,針對不同的病情不同屬性的重要度也不同,但是電子病例里面往往包含很多屬性,而且有很多是冗余的。大家去醫院檢查都要做各種繁復的檢查,其實很多檢查項是冗余的,記錄了很多冗余的屬性,同時還增加了病人的費用。針對這些問題,如何在海量的電子病例中刪除冗余癥狀,高效和準確地建立決策樹,挖掘有重要應用價值的特征數據,是一個十分重要的課題。
粗糙集理論是一種研究模糊性和不確定性問題的數學分析和數據挖掘工具。粗糙集的主要內容是屬性約簡、規則提取,在很多領域應用廣泛。例如,文獻[3]在郵件過濾領域提出了基于變精度粗糙集的決策樹分類算法,提高了郵件的正確分類率。文獻[4]提出了一種在多準則排序方面的算法,即基于粗糙集的多準則排序方法,非常高效。文獻[5]將粗糙集應用到食品安全檢測領域,并且得到了很好的食品檢查效果,提高了食品檢查的速度,文獻[6]將粗糙集和BP神經網絡相結合,提高了糧食產量預測的精確度。文獻[7]為了提高圖像插值方法的插值效率,改善放大圖像邊緣的模糊現象,提出了一種基于粗糙集約簡的支持向量機圖像插值方法。文獻[8]為解決危險品風險分析的一些問題,應用粗糙集理論,加快了計算速度。文獻[9]為了能夠有效、快速地評價電網運行的優質性水平,提出一種粗糙集與證據理論相結合的方法等。
文中將粗糙集的屬性約簡算法應用到肺癌診斷上。屬性約簡算法有很多,如通過去除某屬性后,判斷不可區分關系是否改變來決定是否應刪除該屬性,但是這種算法得到的約簡集不完備。自從SKOWRON提出可分辨矩陣這一理論后[10],就出現了可分辨矩陣和粗糙集理論相結合的屬性約簡算法[11]。這種算法可以得到比較完備的約簡集,但是引入矩陣自然增加了運算量,所以算法的復雜度高、耗時長。為了得到完備的最小約簡集,文中提出了一種基于屬性依賴改進的可分辨矩陣的屬性約簡算法,減少了計算量,提高了運算速度。
經過屬性約簡后的病例集屬性間的冗余度有所降低,將該病例集作為訓練集來構建決策樹,進行規則提取。這樣相比直接構建決策樹進行規則提取,不僅減少了計算量,也減少了樹的深度,使規則更加準確。決策樹是從一組無次序且無規則的元組中推理出一組以決策樹為表現形式的分類規則。它是一種自頂向下的遞歸方式,在樹的內部節點進行屬性值之間的比較,根據屬性值的不同從當前節點向下進行分支,而葉節點是最終要劃分的類,即決策屬性。從根節點到葉節點的一條路徑對應著一條合取規則,而整個決策樹對應著一組析取表達式規則。決策樹算法有很多,如基于粗糙集的變精度算法[12]和ID3算法[13],但是它們不能很好地處理連續值;C4.5算法是ID3算法的改進,能很好地處理連續值。因此文中采用C4.5算法通過信息熵增益率來構建決策樹,同時為了提高準確率引入了決策樹的隨機森林。
2 問題定義
就肺癌的醫療診斷數據進行分析,定義病例樣本集S={U,C,D,V,f}。其中U為病例樣本的實例集合?,即論域;C為條件屬性;D為決策屬性;Vi為屬性i的值域;f為信息映射函數,f:C(C∪D)→V。
根據給定的訓練集建立決策樹,找到肺癌診斷的推理規則,進行智能診斷并預測病人的情況。因此如何建立快速且準確的診斷規則,即如何快速準確地建立決策樹是關鍵。
2.1 粗糙集約簡算法模型
定義1:已知論域U,對于每一個屬性子集P?(C∪D),P≠?,定義不可分辨關系IND(P);則有:?x∈U,[x]IND(P)=[x]p=∩?R∈P[x]R。即論域U上的一個劃分為U/IND(P),IND(P)為論域U的等價關系,即有U/IND(P)={[x]IND(p)|?x∈U}。
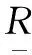
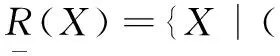
(1)
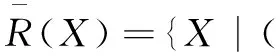
(2)
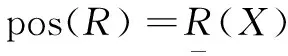
定義3:對于R∈C,對于決策條件D,如果
posIND(C)(IND(D))=posIND(C-{R})(IND(D))
(3)
則R是條件屬性C上D的可約分關系,否則是不可約分關系。
定義4:在論域U上,所有的條件屬性C上D的不可約分關系構成的集合,稱為C的核心集,記為Core(C)。核心集為條件屬性的所有約簡集的交集,所以約簡集一定包含核心集,且對于每個病例樣本集核心集是唯一的。
定義5:對于病例集S={U,C,D,V,f},對于所有的屬性P,Q屬于C,有Q對P的依賴度為
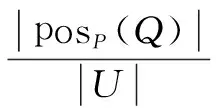
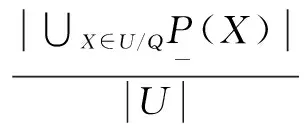
(4)
若有屬性k=1,則P和Q等價。所以為了節省計算量,P和Q不應該出現在同一個最小約簡集。
文中采用基于屬性依賴度的可分辨矩陣約簡算法,對于經典的屬性頻率的約簡算法而言,減小了很多不必要的計算,并且考慮了屬性間的依賴性,使屬性約簡集更加完備[14]。
對于病例集S,構建其二進制可分辨矩陣:
m((i,j),k)=
(5)
當m((i,j),k)=1時,表示屬性ck在(xi,xj),xi,xj∈U下可區分,否則不可區分。
文中基于核心集Core(C),首先求最小約簡集R=Core(C),然后求核心集對應的等價屬性,并在可分辨矩陣中去掉其等價屬性對應的值,然后選擇|M(ck)|最大值的屬性ck加入最小約簡集。
2.2 決策樹算法模型—C4.5算法
由問題定義可知,在病例集S={U,C,D,V,f}中,假設它的一個劃分為{X1,X2,…,Xn},其中pi=P(xi),則有:
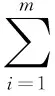
(6)
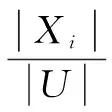
信息熵最早由香農提出,表示物理學上信息的不確定度,而在數學上則表示為信息冗余度和概率之間的關系。信息熵增益表示病例集S按照某條件屬性C劃分時造成熵減少的期望,如下:
Gain(S,C)=Entropy(S)-
(7)
其中,Vc表示某一條件屬性c的值域;Sv表示病例集S中屬性C劃分時,屬性C取值為v的子集合的信息熵。
ID3算法以信息熵增益作為條件屬性選擇的依據,更傾向于選擇屬性取值多的屬性作為決策樹的節點,而某些情況下這些節點并不是特別有價值。而C4.5算法用信息熵增益率代替了信息熵增益作為選擇的標準,克服了ID3算法的不足。信息熵增益率計算方法如下:
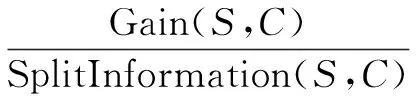
(8)
其中,SplitInformation(S,C)表示按照條件屬性C劃分病例集的廣度和均勻性,稱為分裂因子,其公式為:
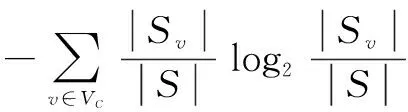
(9)
決策樹算法是基于屬性頻率的,所以ID3算法和基于粗糙集決策樹無法處理好連續的實數型參數,因此要對連續實數型屬性進行離散化。假設條件屬性C1是連續實數型的,且樣本總數為n,則設它的取值序列為VC1={v1,v2,…,vn}。C4.5算法將對它做如下處理:
步驟1:將VC1={v1,v2,…,vn}進行排序。
步驟2:對已經排序好的取值序列,以相鄰兩個元素的和作為斷點,如下:
v=(vi+vi+1)/2(1≤i≤n)
(10)
步驟3:總共取了n-1個斷點,對決策系統而言,單個斷點將病例集分成條件屬性C1≤v和C1>v兩部分,對每個斷點計算GainRatio(S,v)的值,選GainRatio(S,v)最大的那個作為區分屬性C1的分割閾值,從而將屬性C1離散化。
為了避免由于訓練集S過多,加大樹的深度,樹過飽和,而導致樹的準確率下降,采用悲觀剪枝的方法對其進行剪枝。
3 算法設計
3.1 算法描述
基于可分辨矩陣的粗糙集屬性約簡的C4.5智能診斷算法包括兩部分:基于屬性依賴改進的可分辨矩陣屬性約簡算法,給定病例集S,對S進行屬性約簡,得到最小屬性約簡集;然后將S進行簡化,即只留下最小約簡集的屬性和決策屬性,得到簡化后的病例集S,然后用C4.5算法構建決策樹,提取關于S的規則。
算法1:基于屬性依賴改進的可分辨矩陣的屬性約簡算法。
輸入:U,原始病例樣本集,待屬性約簡;
輸出:U,屬性約簡后的樣本實例集。
步驟1:求基于論域U,條件屬性C的正域。通過式[3]找出所有不可約分關系,并求不可約分關系的交集即為核心集Core(C)。設最小約簡集R=Core(C);
步驟2:求Core(C)的等價關系,并從條件屬性和樣本集U中去掉相關的值;
步驟3:構建二進制可分辨矩陣,選擇|M(ck)|最大值的條件ck加入最小約簡集;
步驟4:如果R滿足知識完備性,則得到最小約簡集,去掉不是約簡集中數據的樣本實例集U,不然返回步驟3。
算法2:基于C4.5的決策樹構造算法。
輸入:U,屬性約簡后待訓練的病例樣本實例集;
輸出:Tree,構建好的基于C4.5算法的決策樹C4.5_DTree(U)。
步驟1:計算病例集的每個條件屬性的取值范圍VC;
步驟2:如果當前的樣本集U對于決策屬性的取值全部相同,則將葉子節點賦值為該決策屬性的取值,或者樣本集的條件屬性集為空,則葉子取值為決策屬性取值比較多的值,并返回,不然轉入步驟3;
步驟3:計算每個條件屬性Ci的信息熵增益,首先判斷是否是連續性取值,如果是,按照2.2節中的算法求其基于決策屬性Dj的信息增益率,如果條件屬性為離散值,直接求該屬性對于決策屬性Dj的信息熵增益率;
步驟4:取信息熵增益率最大的條件屬性Cmax作為決策樹的節點,并從條件屬性集中刪除屬性Cmax;
步驟5:根據條件屬性Cmax的取值對樣本集U進行劃分,并返回步驟2;
步驟6:根據樣本集對決策樹進行悲觀剪枝。
3.2 算法改進
決策樹建立在已知病例集上,一課決策樹的預測和分析可能會不太準確,為了提高準確率,文中構建了決策樹森林,即將屬性約簡之后的病例集隨機劃分成多個病例集,然后每個病例集生成多棵決策樹,多棵決策樹構成森林。由于構建每棵決策樹的病例集是獨立的,所以決策樹之間沒有關聯,當有一條新的病例數據產生時,讓森林里的每一棵決策樹分別進行判斷,以概率最大的結果作為決策結果,可以提高準確率。
4 性能評價與系統仿真
為驗證文中算法對醫療診斷推理的正確性和有效性,取某醫療系統關于肺癌診斷的一些電子病例集,對基于屬性依賴的可分辨矩陣屬性約簡算法與可分辨矩陣屬性約簡算法進行性能比較,將單純的C4.5算法、屬性約簡與單棵C4.5決策樹、屬性約簡和C4.5決策樹隨機森林進行性能比較。
4.1 仿真數據與仿真指標
采用某醫療系統關于肺癌手術后是否康復或者壽命只為1年的醫療數據進行分析,該數據總共有870條記錄,有16個條件屬性,1個決策屬性,如表1所示。
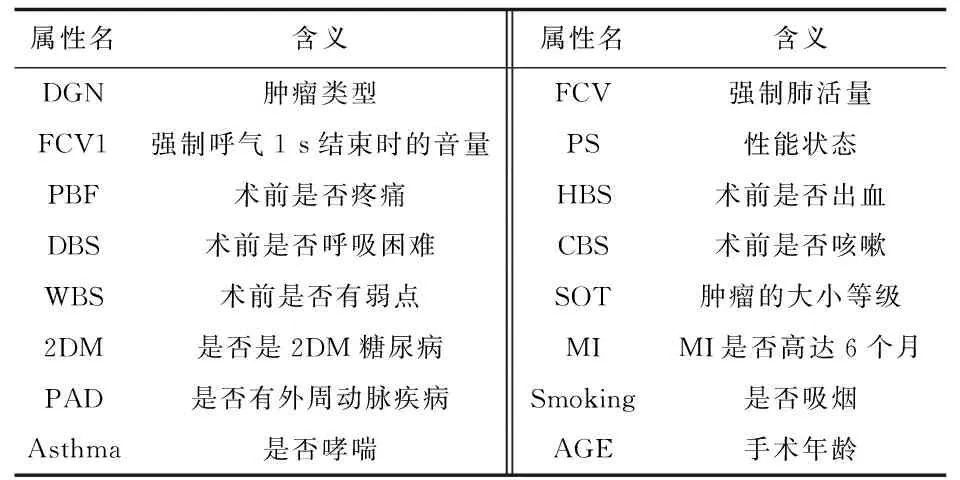
表1 屬性表
以編寫的C++程序作為測試工具,主要從分類的正確性和時間消耗這兩個方面對肺癌數據的分析進行評價。
4.2 仿真結果
在仿真中,為驗證文中提出算法的時間性能,將其與可分辨矩陣屬性約簡算法進行性能比較,如表2所示。

表2 屬性約簡算法的實驗結果比較
這個數據集的核屬性有5個。從表2可知,兩種算法在肺癌的診斷數據上得到的最佳簡約集相同,但是基于屬性依賴的可分辨矩陣屬性約簡算法比可分辨矩陣屬性約簡算法的時間消耗小,前者大約是后者的0.6倍左右。
表3列舉了約簡后的部分數據集。
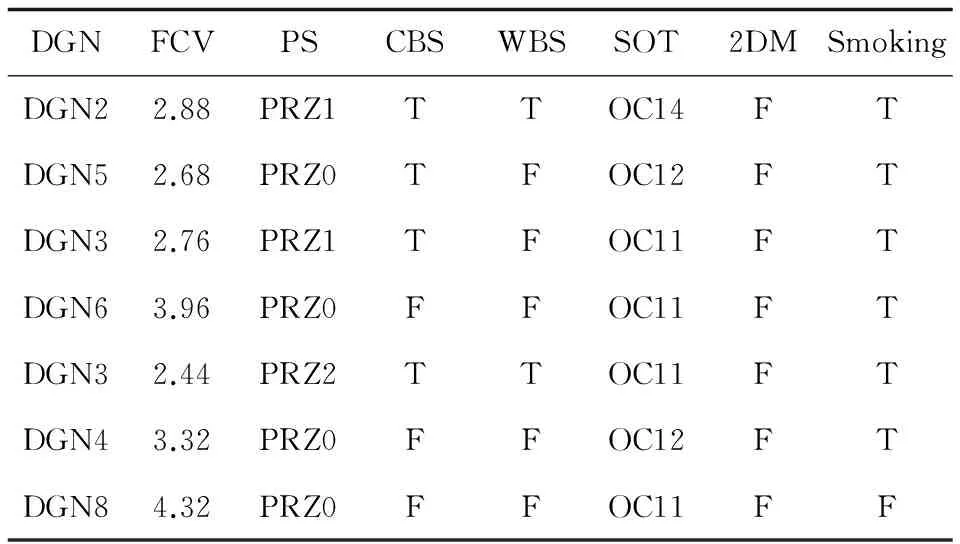
表3 屬性約簡之后的部分數據集
為驗證屬性約簡之后用C4.5算法以及C4.5加隨機森林的準確性,進行了規則提取的仿真。從870條記錄中隨機抽取120條作為檢驗正確性的測試集,然后用剩下的750條做訓練集。對于單純的C4.5算法,未經過屬性約簡,直接將原始的病例集作為訓練集,構建決策樹,構建好的決策樹的節點有236個,規則有91條,準確率為80.8%,比較低,耗時為2.326 s。
屬性約簡后的訓練集,用C4.5算法構建單棵決策樹,得到146個節點,78條規則,正確率為91.7%,有比較大的提升,耗時減少為1.843 s。
屬性約簡和單棵C4.5決策樹直接將這750條測試數據當作訓練集即可,而對于屬性約簡和C4.5決策樹隨機森林,該算法要先進行屬性約簡,然后將約簡后的750條數據隨機抽樣出300條記錄,抽樣成5份訓練集,然后測試集進行測試時走每棵決策樹的結果,將以占比大的推理結果作為結果,時間消耗比單棵決策樹有所提高,為2.048 s,但正確率提升為94.2%。
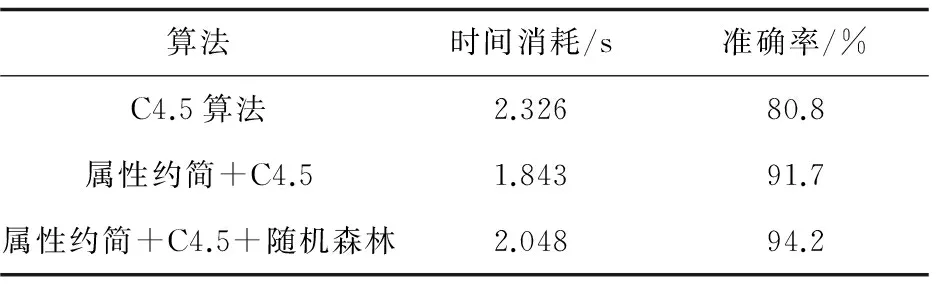
表4 決策樹算法的實驗結果比較
實驗結果表明,屬性約簡之后再用C4.5算法,減少了時間消耗,提高了肺癌診斷的正確性,而且耗時短。說明去掉那些不必要的因素可以很好地提高推理的正確性,而且也防止了決策樹因訓練集太多,導致過飽和,而使正確性下降。從表4可以看出,加入隨機森林之后,醫療診斷的準確度有所提升,這很好地避免了由于訓練集過多而使決策樹節點過多,從而導致不準確的情況。該算法使肺癌診斷的準確性上升了一個臺階。
5 結束語
對肺癌診斷數據進行研究與分析,著重于醫療數據屬性冗余度大的問題,提出了一種基于屬性依賴的可分辨矩陣的屬性約簡算法,找出最佳約簡集,減少了很多不必要的屬性。仿真結果表明,與基于可分辨矩陣的屬性約簡算法比較,在保證信息量的前提下,減少了算法時間開銷。對快速提出準確規則問題,文中將屬性約簡后的訓練集用C4.5算法進行規則提出,相比直接進行C4.5算法,準確率提高很多,時間消耗也降低了。為了提高分類的準確性,提出了基礎C4.5算法的隨機森林,實驗結果表明,該算法提高了肺癌診斷結果的準確性。該方法不只可以用在肺癌數據的分類推理中,也可以用在其他病醫療數據中;但是文中本質上是根據醫療記錄對肺癌數據進行的分類訓練,對其他未知的情況無法給出明確的解答,這個問題還要在后期研究工作繼續探索。
[1] RUEDA A,GONZLEZ F A,ROMERO E.Extracting salient brain patterns for imaging-based classification of neurodegenerative diseases[J].IEEE Transactions on Medical Imaging,2014,33(6):1262-1274.
[2] INUIGUCHI M.Attribute reduction in variable precision rough set model[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2011,14(4):461-479.
[3] 王 靖,王興偉,趙 悅.基于變精度粗糙集決策樹垃圾郵件過濾[J].系統仿真學報,2016,28(3):705-710.
[4] SZELAG M,GRECO S,SOWISKI R.Variable consistency dominance-based rough set approach to preference learning in multicriteria ranking[J].Information Sciences,2014,277(2):525-552.
[5] 鄂 旭,任駿原,畢嘉娜,等.基于粗糙變精度的食品安全決策樹研究[J].計算機技術與發展,2014,24(1):242-245.
[6] 徐興梅,曹麗英.基于粗糙集和BP神經網絡的糧食產量預測研究[J].東北農業大學學報,2014,45(10):95-100.
[7] 賈曉芬,趙佰亭,周孟然,等.基于粗糙集約簡的圖像插值方法[J].計算機應用研究,2015,32(2):623-626.
[8] 高舉紅,趙天一.基于粗糙集理論的危險品運輸風險分析[J].安全與環境學報,2015,15(1):40-43.
[9] 蔣亞坤,李文云,趙 瑩,等.粗糙集與證據理論結合的電網運行優質性綜合評價[J].電力系統保護與控制,2015,43(13):1-7.
[10] SKOWRON A,RAUSZER C.The discernibility matrices and functions in information system[J].Theory and Decision Library,2012,11:331-362.
[11] 常梨云,王國胤,吳 渝.一種基于Rough Set理論的屬性約簡及規則提取方法[J].軟件學報,1999,10(11):1206-1211.
[12] 常志玲,周慶敏.基于變精度粗糙集的決策樹優化算法研究[J].計算機工程與設計,2006,27(17):3175-3177.
[13] ZHAO Guoying,HUANG Xiaohua,MATTI T,et al.Facial expression recognition from near-infrared videos[J].Image and Vision Computing,2011,29(9):607-619.
[14] 王 玨,王 任,苗奪謙,等.基于Rough Set理論的“數據濃縮”[J].計算機學報,1998,21(5):393-400.
ApplicationofDecisionTreeBasedonRoughSetinMedicalDiagnosis
HUANG Jin-jing,CHEN Dai,LI Meng-tian
(School of Computer Science and Technology,China University of Mining and Technology,Xuzhou 221116,China)
Online medical diagnosis is becoming more and more popular,so more and more data are in electronic records.How to reduce the redundancy of medical data,extract useful medical value rapidly from a large number of medical data,and improve the speed and accuracy of medical diagnosis has become a hot issue.In view of it,some data of diagnosis of lung cancer in medical system are researched,and the C4.5 algorithm of attribute reduction based on attribute-dependent improved discernibility matrix is established and improved by stochastic forest.Attribute reduction algorithm reduces the redundancy of medical data,the decision tree algorithm extracts some rules of lung cancer diagnosis,and the stochastic forest raises the accuracy of diagnosis.In this paper,simulation and application are carried out under the scenario of lung cancer diagnosis.The simple C4.5 algorithm is made a comparison with the attribute reduction and the single C4.5 decision tree,and attribute reduction and random forests of C4.5 decision tree.The experiment shows that the proposed method accelerates the computing and improves the accuracy of medical diagnosis.
rough set;attribute reduction;discernibility matrix;C4.5 algorithm;decision tree
TP39
A
1673-629X(2017)12-0148-05
10.3969/j.issn.1673-629X.2017.12.032
2017-01-21
2017-05-25 < class="emphasis_bold">網絡出版時間
時間:2017-09-27
國家級大學生創新項目(201510290002)
黃錦靜(1994-),女,研究方向為計算機科學與技術;陳 岱,副教授,研究方向為計算機應用。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170927.1000.074.html
猜你喜歡
保健醫苑(2023年2期)2023-03-15 09:03:04
中國臨床醫學影像雜志(2022年2期)2022-05-25 13:24:34
中國藥學藥品知識倉庫(2022年1期)2022-03-23 04:16:57
昆明醫科大學學報(2021年4期)2021-07-23 01:21:44
天津醫科大學學報(2021年2期)2021-03-29 05:30:38
天津醫科大學學報(2019年6期)2019-08-13 07:04:26
癌變·畸變·突變(2016年3期)2016-02-27 06:15:34
醫學研究雜志(2015年12期)2015-06-10 06:57:46
中國當代醫藥(2015年7期)2015-03-01 02:01:19
鄭州大學學報(醫學版)(2015年1期)2015-02-27 14:50:26
