服務器中高性能網絡數據包處理方法的對比研究
2017-12-08 03:26:14朱顥東
計算機應用與軟件 2017年11期
關鍵詞:優化
李 霞 李 虎 甘 琤 朱顥東
(鄭州輕工業學院計算機與通信工程學院 河南 鄭州 450002)
服務器中高性能網絡數據包處理方法的對比研究
李 霞 李 虎 甘 琤 朱顥東
(鄭州輕工業學院計算機與通信工程學院 河南 鄭州 450002)
隨著計算機軟硬件性能的不斷提升,以往只有在通信鏈路上才能見到的10 Gbit/s、40 Gbit/s數據傳輸速率,近幾年也逐漸出現在服務器集群中。然而,相對于服務器,通信鏈路上的網絡設備使用了不同的指令集和微架構,硬件和系統內核都經過了裁剪。這使得服務器無法像網絡設備那樣能夠快速處理網絡數據包。針對這一問題,首先從服務器的硬件結構和操作系統這兩個角度分析網絡數據包的處理過程,找出在該處理過程中存在的性能瓶頸,并總結相關解決方法。然后將目前較為流行的幾個網絡數據包處理框架進行對比研究,并分析各自的優缺點。緊接著,通過仿真實驗對這些處理框架在不同應用場景下表現出的性能進行驗證。最后根據不同處理框架的技術特點給出各自的適用場景和深入研究建議。
服務器 網絡數據包 通信鏈路 Netmap DPDK VPP OVS
0 引 言
諸如軟件定義網絡、云計算、大數據分析、物聯網、社交網絡等這些第三方平臺的業務,在為企業提供業務流程改造和商業模式轉變的同時,也在不斷驅動著它們所依托的數據中心網絡不斷升級和服務器網卡速率的提升。有權威分析指出:到2018年,在數據中心交換機的花費中,超過90%的花費將用于10~40 Gbit以太網[1]。
工作在通信鏈路上的網絡設備大多采用專用集成電路(ASIC)或網絡處理器(NP)的方式來實現對網絡數據包的快速處理。但是,采用這兩種方式需要很長的開發周期才能形成產品,另外還存在開發難度大、靈活性差和擴展性不足等缺點。面對靈活可控的網絡管理需求和日新月異的用戶需求,越來越多的國內外學者將目光投向了通用服務器解決方案。
近幾年,10 Gbit、40 Gbit以太網已經開始出現在服務器上,然而由于CPU性能、PCI-E帶寬、內存和操作系統的影響,基于商用多核處理器的服務器很難滿足線速處理網絡數據的需求。類似的問題早在服務器網卡從100 Mbit/s向1 Gbit/s過渡的時期就曾出現過。當時很多國內外學者發現,在1 Gbit/s的以太網中,利用商用多核處理器和發行版的操作系統難以實現線速捕獲網絡數據的需求。針對這一問題,專家學者們也相應地給出了一些解決方案[2-5]。此后,針對通用服務器處理網絡數據時存在的性能不足,國內外很多學者在硬件優化和軟件優化兩個方面做了很多深入的研究,并隨之出現了許多解決方案(例如:PFQ[5]、OpenOnload[6]、DPDK[7]、Netmap[8]、PacketShader[9]、Snap[10]、NBA[11]等)。這些解決方案可以提升報文捕獲、軟件路由器、深度報文檢測和軟件定義網絡等這些業務需求在10~40 Gbit以太網中的網絡性能。
針對服務器處理網絡數據存在性能不足這一問題,本文首先從硬件和軟件這兩個方面分析了網絡數據包的處理過程,選取了目前幾個主流的網絡數據包處理框架進行對比研究,分析了每個方案的優缺點,并找出了在該處理過程中存在的性能瓶頸和解決方法。然后將目前較為流行的幾個網絡數據包處理框架進行了對比研究,并分析了各自的優缺點。通過仿真實驗對這些處理框架在不同應用場景下的表現出的性能進行了驗證。最后根據不同處理框架的技術特點給出了各自的適用場景和深入研究建議。
1 服務器軟硬件方面存在的問題及解決方案
目前,大部分的服務器采用了多核的X86架構。在此架構中,從網卡到內存緩沖區的數據傳輸依靠中斷和DMA/DCA來實現,這導致了不可逾越的性能瓶頸。另外,DMA/DCA將網絡數據包拷貝到緩沖區后,操作系統需要經過多次內存中的復制和軟中斷才能將數據傳遞給用戶空間的應用程序,這是另一個重要的性能瓶頸。接下來,本文將從服務器普遍采用的商用多核的硬件結構與操作系統兩個方面對可能存在的性能瓶頸進行描述,并對優化方法進行了總結。
1.1 硬件方面存在的問題以及解決方案
處理器在網絡數據進行處理所涉及的硬件中,處理器是最重要的一個環節。目前,通用服務器CPU的指令架構大多采用X86架構,不同廠家的CPU以及同一廠家不同系列的CPU又會在微架構和硬件實現上有差別。這些差別會導致當使用不同的CPU處理相同的程序的時候,CPU的運行效率存在很大的差異[12]。衡量CPU運行效率有兩個主要的衡量指標:時鐘周期和緩存的命中率。文獻[13]從CPU的時鐘周期和緩存兩個角度對網絡數據包的處理進行了詳細的描述和實驗驗證。從其推導出的公式fcpu=n(CIO+Ctask+Cbusy)我們可以看出:在處理網絡數據包時,CPU的開銷主要由IO總線傳遞數據占用的開銷CIO、CPU處理數據的開銷Ctask和CPU處于忙時的開銷Cbusy三部分組成。在緩存的命中率方面,由于CPU采用了超標量、亂序執行、分支預測等技術,這使得緩存的命中率可以接近1。另外,根據處理器的優化方式,我們可以將現有的優化方案分為兩大類:基于CPU微架構的優化方案[14-15]和基于CPU+協處理器優化方案。基于CPU微架構的優化方案不具有通用性,而基于CPU+協處理器優化方案主要分為采用GPU作為協處理器的方案(PacketShader、Snap、NBA)和采用FPGA作為協處理器的方案(DAG[16]、NetFPGA SUME[17]、NPDK[18])。
總線總線是影響網絡數據處理性能的另一個重要因素。主要涉及CPU的內部總線和PCI-E總線。內部總線主要用于CPU內各部件之間的信號和數據的傳遞。自2010年,Intel Xeon?系列的內部總線開始使用4條獨立的環形總線結構[19],每條環可以提供25.6 GB/s的峰值帶寬,同時內存控制器和PCI-E控制器也被集成到了CPU上。理論上,采用PCI Express 2.0 x8的設備雙向傳輸的有效帶寬為32 Gbit/s,而采用PCI Express 3.0 x8的設備雙向傳輸的有效帶寬約為63 Gbit/s。以一個使用PCI-E 2.0 x8接口的萬兆網卡舉例,如果一張網卡上的網絡接口數量為兩個的時候,這張網卡的吞吐率將會達到40 Gbit/s,顯然有效帶寬只有32 Gbit/s的PCI Express 2.0 x8接口將會成為瓶頸。
內存從硬件方面考慮內存的瓶頸,主要從內存的親和性和內存的帶寬兩方面考慮。內存帶寬通常不會是造成處理網絡數據的瓶頸,因為在常見的DDR3和DDR4中,即使DDR3中最慢的速度也能達到51.2 Gbit/s。內存親和性則有可能成為性能瓶頸。內存親和性是指內存控制器被移到CPU內部之后,在多個NUMA(Non-Uniform Memory Access)節點并存的情況下,本節點內的設備應盡可能地訪問本節點的內存,跨節點訪問內存會造成數據所經過的多個NUMA節點的IO性能下降。文獻[9]對跨NUMA節點的內存訪問進行了測試,結果表明跨節點的內存訪問會導致帶寬利用率下降20%~30%,進一步導致訪問時間會增加40%~50%。
網卡目前大多數的10 Gbit/s、40 Gbit/s網卡采用PCI Express 2.0或PCI Express 3.0的標準。另外,很多網卡提供硬件多隊列的支持,RSS(Receiver Side Scaling)技術就是一種通過哈希函數對IP五元組的值進行處理,然后根據處理結果將不同的數據包交給不同的硬件隊列。 Linux內核自2.6.21版本之后就開始支持這一功能。
1.2 軟件方面存在的問題以及解決方案
Han[9],Gallenmuller[13],Liao[15],Emmerich[20]等均對Linux處理網絡數據包時所占用CPU的時鐘周期進行過測試,這些測試結果均反映出:網卡驅動程序、數據包緩沖區的管理方式、操作系統協議棧這些環節都會占用大量的CPU時鐘周期。
驅動程序現有的網卡驅動程序大多采用環形隊列的方式管理數據包緩沖區。當網卡驅動程序加載的時候,多個環形隊列就會被提前準備好,當隊列中的數據包被傳輸出去之后,空閑的存儲空間又可以被重復使用。這種環形隊列管理方式相對于為每個數據包單獨分配存儲空間的方式避免了不必要的開銷。為了提高處理網絡數據的性能,在Linux內核版本中,自2.6版本之后,NAPI[23]技術成為了提升處理網絡數據的性能的一個主要方法。這種技術使用中斷與輪詢的方式,解決了每當有網絡數據包到達時都要觸發中斷從而影響操作系統性能的問題,取而代之的是每次中斷都會以批處理的方式處理數據包,從而分攤了這一部分的CPU開銷。UIO[24]技術同樣是一種用于提升處理網絡數據性能的技術,這是一種將環形隊列數據映射給用戶空間應用程序的技術。因為它仍然在內核空間駐留了少量代碼,所以這一做法并不會對系統的穩定性產生太大的影響。
多次數據拷貝網絡數據包被寫入環形隊列后,需要經過內存之間的拷貝才能從環形隊列進入內核空間的數據緩沖區,同樣需要經過內存之間的拷貝才能從內核緩沖區進入用戶空間的內存區域。根據數據包長度的不同,每次內存之間的拷貝都要消耗500~1 200不等的CPU時鐘周期[15]。在這一部分CPU時鐘周期中,二級緩存未命中導致的損耗占50%,共享緩存未命中導致的損耗占27%,指令的執行周期占20%。在文獻[9]中也得出了類似的結論。數據拷貝產生的瓶頸可以通過內存映射的方法解決:將環形隊列的內存區域映射給用戶空間的內存區域,或將存儲網絡數據包的內核緩沖區映射給用戶空間的內存區域。顯然前一種方法比后一種方法少了一次內存拷貝,缺點是將環形隊列和網卡寄存器暴露給了用戶空間的應用。文獻[8]認為這將會影響系統的穩定性,但是,文獻[18-21]認為所有的解決方案向用戶空間應用提供的軟件接口會起到保護的作用。
操作系統協議棧操作系統中的用戶態進程需要調用協議棧提供的Socket接口才能進行正常的網絡通信。由于調用內核協議棧需要頻繁的CPU上下文切換,因此這種方法在占用大量的開銷的同時,還會導致CPU中cache的命中率下降。操作系統協議棧中包含了大量的網絡協議層的協議,完善的協議棧保證了數據可以可靠地交付給用戶態進程的同時,還占用了大量的CPU開銷。最后,操作系統的協議棧需要通過拷貝的方式才能將數據包從內核空間的內存區域傳遞到用戶態的內存區域,這一過程同樣占用了大量的CPU開銷。文獻[2,11]中的解決方案大多繞開了操作系統協議棧,這就造成了基于操作系統協議棧的應用程序必須經過移植才能使用這些解決方案。替代的方法是將協議棧移置用戶空間,這樣可以大量減少內存拷貝和CPU開銷。文獻[25]的研究表明,在TCP連接數量到達8 000個的時候,內核協議棧拷貝數據的耗時量是用戶態的協議棧耗時量的55~145倍。
中斷平衡在使用了多核CPU的操作系統中,會存在中斷平衡的問題。當網卡的中斷被頻繁切換的時候,會導致CPU的緩存命中率下降,從而影響處理網絡數據的性能。正如上文分析內存時指出的,在多個NUMA(Non-Uniform Memory Access)節點并存的情況下,同一個節點內的設備應盡可能地訪問本節點的內存。同理,應該盡可能使用相同NUMA節點中的CPU和內存處理網卡的數據,甚至應該盡可能使用相同節點中的同一個CPU內核處理網卡的同一個隊列的數據。
大頁內存這種技術可以減少TLB(Translation Look aside Buffer)的未命中以及減少虛擬內存地址和物理內存地址之間的轉換多帶來的開銷。大頁內存技術尤其適合內存消耗巨大、內存訪問隨機和存在內存訪問瓶頸這些情況。文獻[7,11]使用了這種技術優化了訪問內存時候的開銷。
2 相關軟件優化方案與硬件優化方案
基于研究結果是否可以復現這一考慮,本文挑選了5種完全開源的方案:DPDK、Netmap、Snap、NBA和PFQ。那些需要付費、不便于復現的研究[9],以及不具有通用性的研究[6,14-18]不在本文的考慮范圍之內。表1對比了這些方案的技術特征。
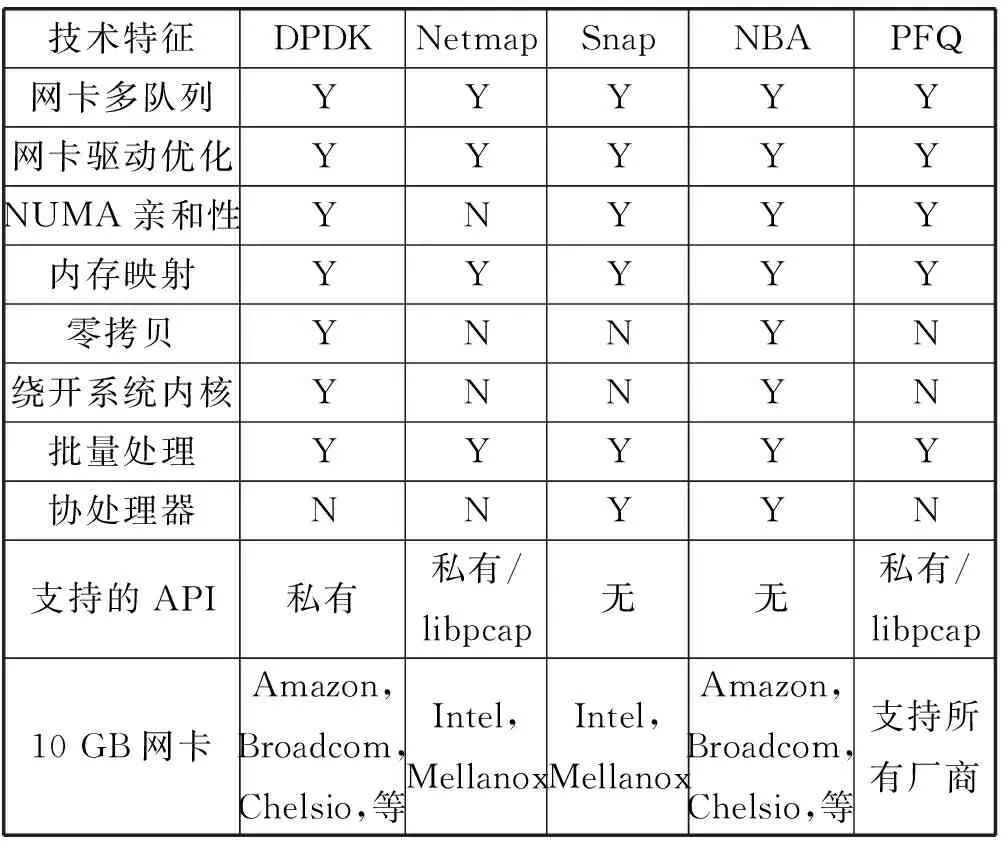
表1 優化方案的技術特征
DPDK:它是Intel官方推出的一款數據平臺開發工具箱,由多種功能的函數庫組成。函數庫涵蓋驅動、內存、計時器、鎖、協議棧等多方面的開發需求。DPDK使用了UIO技術,用于將網卡緩沖區映射給用戶空間應用程序。因為它繞開了操作系統的內核,所以工作在操作系統協議棧上的應用程序無法直接使用它。另外需要指出的是它提供了虛擬化的功能,這使得它可以提升Open vSwith和OpenFlow switch中數據包的處理性能。
Netmap:它是一種采用了優化環形隊列的結構、內存映射、批量處理、繞開系統內核等多種技術的數據包處理框架。首先,Netmap將網卡環形隊列中的數據拷貝到了內核空間中的共享內存;接著,當沒有程序調用Netmap的API的時候,Netmap管理的共享內存將和操作系統協議棧交換數據,當有程序調用Netmap的API的時候,Netmap管理的共享內存直接和應用程序交互數據,同時會拷貝一份數據給操作系統協議棧。通過這種方法,操作系統不會意識到任何的改變,仍然可以正常管理網卡[8]。Netmap提供有API的同時還提供了libpcap接口,使得基于libpcap的程序可以利用Netmap提高自身的性能。另外,Netmap還可以運行在Windows和FreeBSD環境中,尤其是FreeBSD已經將Netmap集成到了內核中。在虛擬化環境中,它可用于提升Qemu/kvm、Click和VALE等軟件處理數據包的性能。
Snap:這是一種使用了Netmap和Click的數據包處理方法。它解決了Click并發性能不足的問題,為Click增加了使用GPU處理數據包的模塊。Snap處理數據包的過程:首先,在將Netmap控制的內存中的數據拷貝給Click控制的內存區域之前,Snap通過給每個進程增加一個數據包緩沖區的方法解決了Click并發性能不足的問題,另外,還通過將Click的數據包處理進程綁定給不同的CPU內核的方法解決了Click的CPU緩存命中率低的問題。其次,Snap通過增加Click模塊的方法解決了主機內存與設備內存之間數據拷貝的問題。最后,Snap通過數據包切片(即處理每個數據包的部分內容)的方法節約了該處理方案對內存和PCI-E帶寬的占用量。由于沒有解決好數據包分歧(packet divergence)的問題,Snap方案中存在多次內存之間的數據拷貝,這使得Snap處理小包的性能不足。從其SDN轉發結果可以看出:包大小為64 Byte時,每個10 Gbit/s速率的接口使用CPU處理的轉發速率約為8.79 Mpps;使用GPU處理的轉發速率約為12.21 Mpps;只有進一步對數據包切片后,使用GPU處理的轉發速率約為14.65 Mpps。
NBA:這是一種使用了DPDK和Click的數據包處理方法,解決方法與Snap類似。不同的是該方案還提供了負載模塊,它允許在CPU和GPU之間進行負載調度。另外,它還采用了批量拷貝和批量處理的方法來緩解內存拷貝帶來的開銷。盡管這些改進可以幫助NBA提升處理數據的性能,但是,在NBA處理數據的過程中同樣存在多次內存拷貝的問題。這使得它也不能滿足線速處理數據包的需求。
PFQ:這是一種不需要改動網卡驅動程序就能實現對Linux環境下網絡數據包處理進行優化的解決方案。PFQ在內核中增加了內核模塊,該模塊通過內存映射的方法將網卡中的數據分發給不同的PFQ隊列,不同隊列的數據又會傳遞給各自的Socket和用戶空間程序。然而,正是因為PFQ沒有繞開內核協議棧,這使得網卡的環形隊列中的數據不可以直接傳遞給用戶空間的應用程序,從而影響了該方案在處理數據包時的性能。
在這5種解決方案中,DPDK、Netmap和PFQ屬于純軟件的解決方案,用于解決數據包在網卡緩沖區與用戶態進程之間傳輸性能低的問題。由于DPDK和Netmap對處理數據包時存在的問題解決得更徹底,這使得它們可以滿足線速處理數據包的需求。而Snap和NBA屬于軟件和GPU結合的協處理器解決方案,而且都是在已有的軟件方案基礎上利用GPU處理數據包的解決方案。但是,由于Snap和NBA在處理數據的過程中都存在多次內存拷貝的問題,使得它們不能滿足線速處理數據包的需求。
3 測試與驗證
針對不同解決方案適用的場景不同,接下來,本文將從Linux網絡性能優化、報文捕獲和云計算這三個應用場景,對Linux環境中多種數據包處理方案進行對比研究。通過仿真實驗對這些方案進行了驗證,所有的仿真實驗都遵循RFC2544[26]標準。實驗環境中每臺服務器包含兩個NUMA節點,每個節點中的CPU型號為Intel Xeon E5-2620,內存類型為DDR4-2133 MHz,PCI-E插槽類型為PCI-E 3.0,網卡型號為Intel X510-SR2,操作系統為Ubuntu-16.04.1-server。在該仿真環境中,發包軟件為Pktgen-dpdk-3.1.0,它使用雙隊列就可實現報文長度在64~1 518 Byte范圍內的線速發包。
3.1 應用場景1:Linux的網絡性能優化
由于現有網絡數據包處理方案大多繞過了操作系統的網絡協議棧,因此,這些方案無法直接為運行在操作系統協議棧之上的網絡應用提高性能。然而,除了操作系統的協議棧,服務器中影響網絡性能的因素還有很多,主要有硬件的特性、驅動程序的參數、內核參數和開啟的網絡功能等。因此,該場景的實驗無法逐一對這些影響因素進行對比研究。在使用相同型號硬件和相同操作系統版本的情況下,該場景使用清單1的優化方法對操作系統的網絡性能進行了優化,在圖1中對比了優化前后的結果。
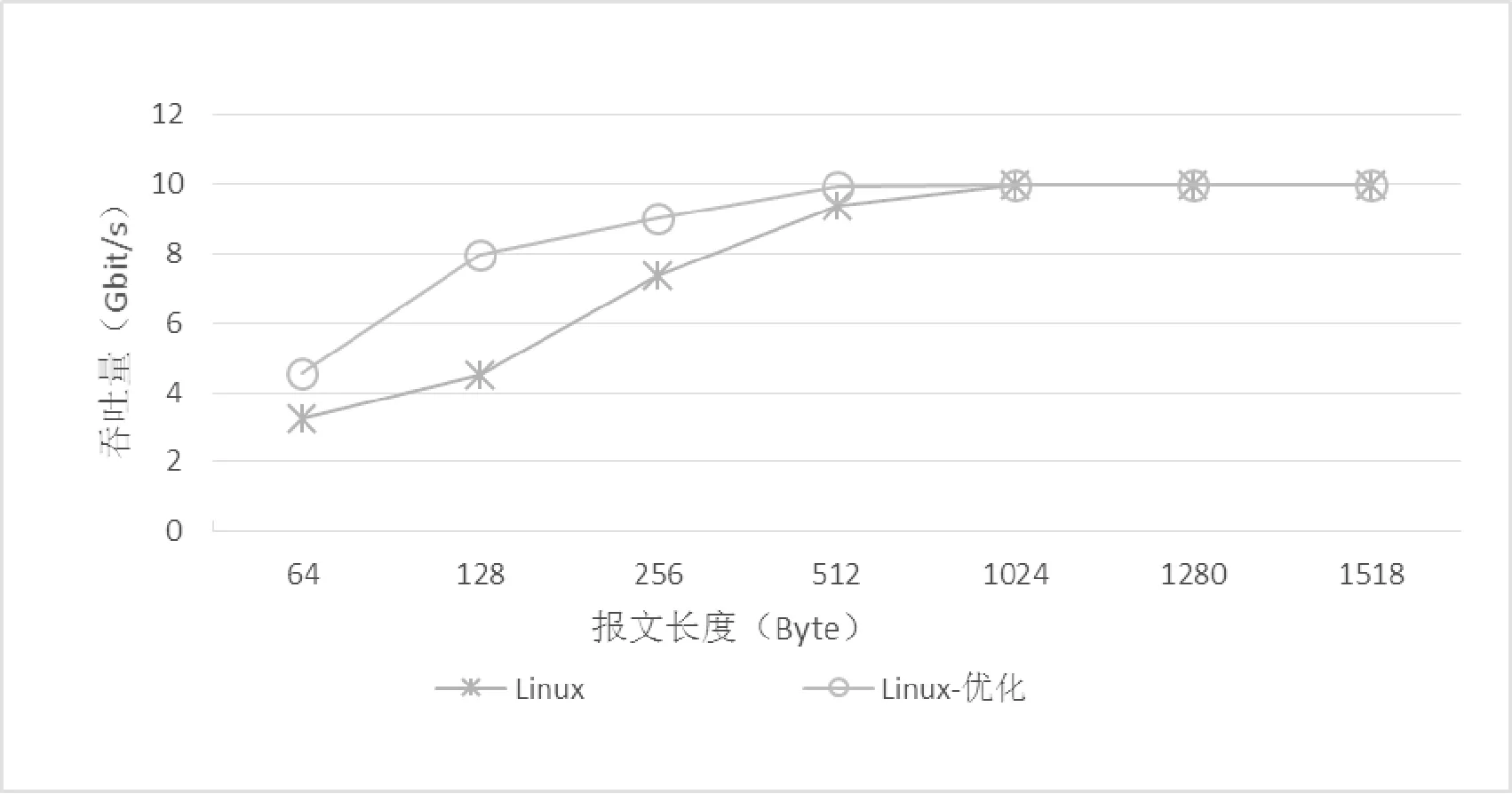
圖1 Linux系統的網絡優化前后的吞吐量
測試環境的優化內容:
檢查CPU內核所屬的NUMA節點
lscpu
檢查每個網卡的PCI總線地址
lspci | grep Ethernet
檢查網卡所屬的NUMA節點
cat /sys/bus/pci/devices/0000…XX…XX.X/
numa_node
在網卡所屬的NUMA節點中隔離CPU內核
iommu=pt intel_iommu=on isolcpus=0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30
關閉操作系統的irqbalance服務
/etc/init.d/irqbalance stop
依次調整所有隔離出來的CPU內核工作頻率
echo performance>/sys/devices/system/cpu/cpuX/
cpufreq/scaling_governor
使用ixgbe驅動時,調整網卡隊列數量
echo 0 > /sys/devices/system/cpu/cpuX/online
rmmod ixgbe
modprobe ixgbe
關閉影響網卡接收性能的功能
ethtool-K eth0 gro off lro off rx off
調整網卡的環形隊列的長度
ethtool-G eth0 rx 4096
設置網卡的MTU以減少每個幀的開銷
ifconfig eth0 mtu 1500
清單1給出了在相同的硬件與操作系統的測試環境下,如何通過調整網卡與CPU的親和性優化NUMA節點內的數據傳輸的效率。同時還給出了通過隔離CPU和關閉中斷平衡的方法,保證了不相關的進程無法使用被隔離出的CPU,從而避免了網卡隊列的中斷頻繁在不同的CPU內核之間切換的問題。另外,通過關閉接收隊列的數據包聚合、關閉流量控制的功能、增加接收隊列的長度和調整MTU大小等一系列的方法,提高了網卡的接收效率。
從圖1的對比結果可以看出:在對操作系統的網絡優化之前,操作系統處理小包的吞吐量較低。經過優化,盡管操作系統處理小包的吞吐量明顯上升,但是在處理報文長度小于512 Byte的時候,吞吐量仍然無法達到10 Gbit/s。
對于那些在Linux環境中對小包處理較為敏感的網絡應用,在優化網絡性能的時候,建議從網卡所屬的NUMA節點中挑選出若干CPU內核,專門用于處理網卡中的數據。這樣有助于提升這些應用處理小包的性能。
3.2 應用場景2:報文捕獲
在該應用場景中,發包方保持每個報文長度為64 Byte不變并以14.88 Mpps的速度發包;接收方則采用圖1的方法對測試環境進行了優化,以保證在相同的環境中,每種方案都能發揮出最佳的性能。測試對象為包括DPDK、Netmap、PFQ和libpcap在內的4種方案。通過改變每種方案的接收隊列數量,測得了以上4種方案的丟包率,結果如圖2所示。
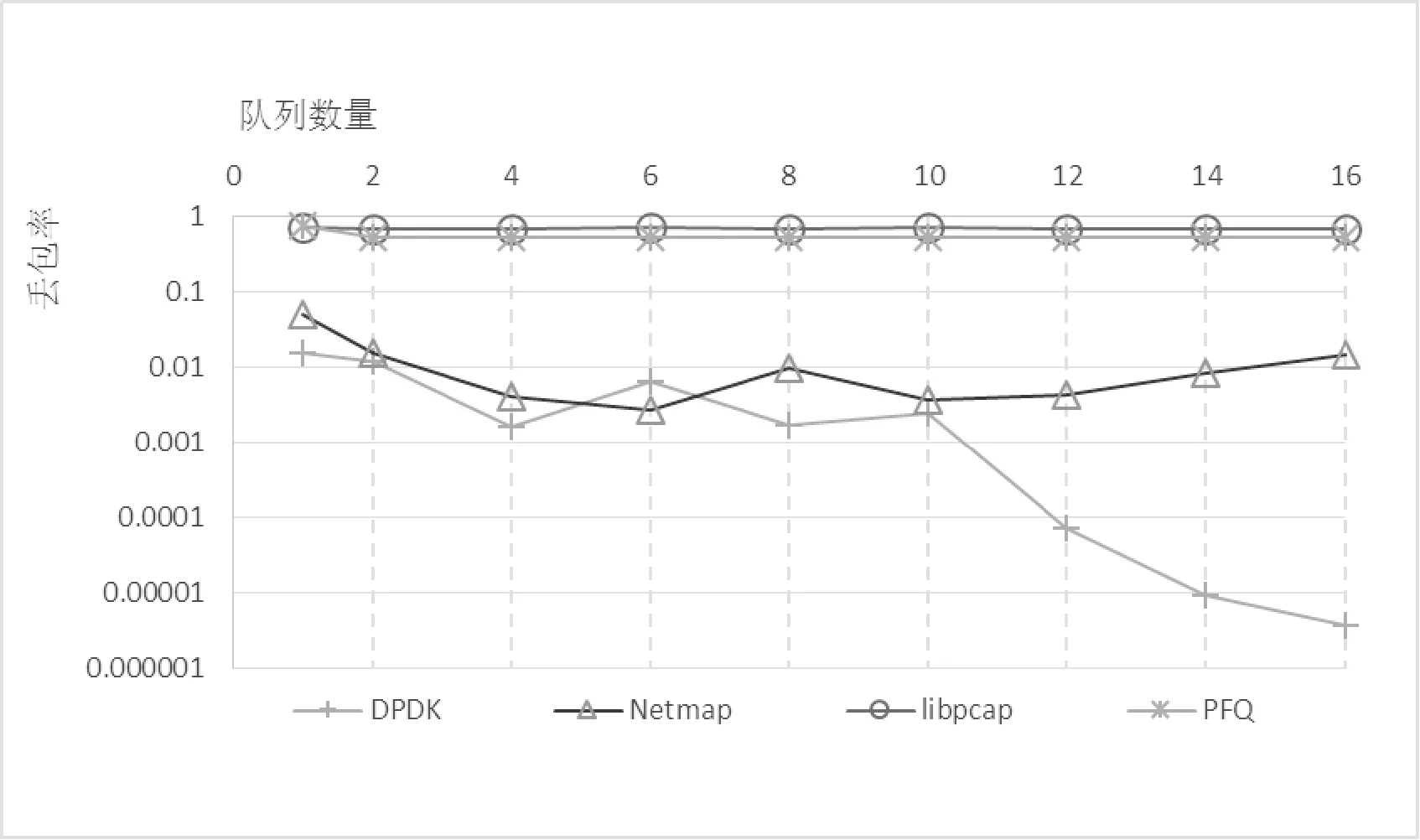
圖2 報文捕獲場景中的丟包率
該場景中的DPDK和PFQ支持通過參數的方式調整隊列,而Netmap和libpcap則不可以。該實驗通過CPU下線并保留與隊列數量相同的CPU數量的方式,達到了在實驗中調整隊列數量的目的。
從圖2的實驗數據上可以看出:當發包方持續以14.88 Mpps的速度發包的時候, libpcap和PFQ的丟包率較高,DPDK和Netmap則一直保持著較低的丟包率。隨著隊列數量的增加,所有方案的丟包率均有小幅的波動。而DPDK在隊列數量達到10的時候,丟包率的波動幅度減少,并且丟包率持續下降,直至隊列數量達到16的時候,丟包率接近于0。
在那些對網絡報文捕獲率有較高要求的應用場景中,建議利用DPDK或Netmap作為底層框架進行二次開發。DPDK擁有較為完整的開發文檔和活躍的技術社區,而Netmap可以平滑地升級那些基于libpcap開發的應用。
3.3 應用場景3: 云計算與軟件定義網絡
在云計算和軟件定義網絡中,通常使用OVS(Open vSwitch)處理網絡數據包的轉發。但是原生的OVS存在吞吐量較低,處理延遲較大等問題。自版本2.2開始,OVS分別從物理網卡和虛擬網絡兩方面支持使用DPDK優化OVS的數據包傳遞性能。類似OVS的軟件還有VPP(Vector Packet Processing),該軟件也可以使用DPDK進行性能優化。該實驗中,發包方使用不同的數據包長度依次進行發包。收包方同樣先采用圖1的方法對OVS(v2.6.1)和VPP(v17.04-rc0)的測試環境進行了優化,然后在統一了接收隊列數量和隊列長度的基礎上,測得了兩種軟件的轉發速率,結果如圖3所示。
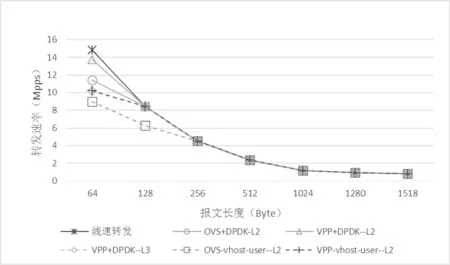
圖3 OVS與VPP的轉發速率
從圖3的實驗數據上可以看出:VPP和OVS的轉發性能,在整體上表現出了較為相似的結果,尤其是在報文長度大于256 Byte之后,均接近了線速轉發。主要原因是兩種軟件都使用DPDK方案處理網卡和用戶空間程序之間的數據流。但是在報文長度小于256 Byte的時候,兩種軟件的處理小包的性能展現出了明顯的不同。無論是處理物理網卡之間的二層轉發和處理物理網卡與vhost-user虛擬網卡之間的二層轉發,VPP表現出來的性能都優于OVS。另外,兩種軟件處理物理網卡之間的二層轉發的性能優于使用虛擬網卡vhost-user做二層轉發的性能。由于OVS自身不支持三層轉發,該實驗僅測得了VPP的三層轉發速率。
在那些對數據轉發有嚴格要求的VPP和OVS的應用場景中,建議盡量使用物理網卡實現二層轉發。在VPP和OVS環境中,盡管經過DPDK優化后的虛擬網卡vhost-user表現出了很高的轉發性能,但是在虛擬機中仍然存在處理數據的瓶頸。這使得在虛擬機中使用vhost-user虛擬網卡提升網絡性能的效果不明顯。
4 結 語
對服務器處理網絡數據性能不足這一問題的研究目前是計算機網絡領域的一個研究熱點,本文中對比研究的這些網絡數據包處理方案,大多長期保持持續更新的狀態。尤其是DPDK和Netmap兩種方案,已經開始應用于與之相關的研究課題。特別是在云計算與軟件定義網絡中的應用,由于DPDK的性能優異,使得VPP和OVS的轉發速度可以接近線速。但是,由于傳統網絡應用程序無法直接使用這些解決方案提升自身的網絡性能,這一原因造成了這些解決方案目前無法廣泛應用于提升服務器處理網絡數據包的性能。另外,相對于內核協議棧,雖然用戶態的協議棧已經在一定程度上解決了協議棧處理數據包時存在的問題,但是它仍然存在小包處理速度慢和其他用戶態進程無法直接使用等問題。解決好這些問題對于提升操作系統的整體網絡性能將具有重要的意義。
[1] Brad Casemore,Petr Jirovsky,Rohit Mehra.The New Need for Speed in the Datacenter Network[R].IDC Technology Spotlight,2015.
[2] Deri L,Via N S P A,Km B,et al.Improving passive packet capture:beyond device polling[J].Proceedings of Sane,2004.
[3] Gibb G,Lockwood J W,Naous J,et al.NetFPGA—An Open Platform for Teaching How to Build Gigabit-Rate Network Switches and Routers[J].IEEE Transactions on Education,2008,51(3):364-369.
[4] 劉峰.Linux環境下基于Intel千兆網卡的高速數據包捕獲平臺的研究[D].廈門大學,2008.
[5] Bonelli N,Pietro A D,Giordano S,et al.On Multi-gigabit Packet Capturing with Multi-core Commodity Hardware[C]//International Conference on Passive and Active Measurement,2012:64-73.
[6] Solarflare.Openonload[EB/OL].2008.http://www.openonload.org/.
[7] Intel.Intel DPDK:Data Plane Development Kit[EB/OL].2013.http://dpdk.org/.
[8] Rizzo L.Netmap:a novel framework for fast packet I/O[C]//Usenix Conference on Technical Conference.USENIX Association,2012:9-9.
[9] Han S,Jang K,Park K S,et al.PacketShader[J].Acm Sigcomm Computer Communication Review,2010,40(4):195.
[10] Sun W,Ricci R.Fast and flexible:Parallel packet processing with GPUs and click[C]//Architectures for Networking and Communications Systems (ANCS),2013 ACM/IEEE Symposium on,2013:25-35.
[11] Kim J,Jang K,Lee K,et al.NBA (network balancing act):a high-performance packet processing framework for heterogeneous processors[C]//Tenth European Conference on Computer Systems.ACM,2015:1-14.
[12] Braun L,Didebulidze A,Kammenhuber N,et al.Comparing and improving current packet capturing solutions based on commodity hardware[C]//ACM SIGCOMM Conference on Internet Measurement 2010,Melbourne,Australia-November.DBLP,2010:206-217.
[13] Gallenmuller S,Emmerich P,Wohlfart F,et al.Comparison of frameworks for high-performance packet IO[C]//Eleventh Acm/ieee Symposium on Architectures for Networking & Communications Systems.IEEE,2015:29-38.
[14] Binkert N L,Saidi A G,Reinhardt S K.Integrated network interfaces for high-bandwidth TCP/IP[J].Acm Sigplan Notices,2006,34(5):315-324.
[15] Liao G,Xia Z,Bnuyan L.A new server I/O architecture for high speed networks[C]//High Performance Computer Architecture (HPCA),2011 IEEE 17th International Symposium on.IEEE,2011:255-265.
[16] Endace,Capture network packet device[EB/OL].2016.http://www.endace.com/endace-dag-high-speed-packet-capture-cards.html.
[17] Zilberman N,Audzevich Y,Covington G A,et al.NetFPGA SUME:Toward 100 Gbps as Research Commodity[J].IEEE Micro,2014,34(5):32-41.
[18] Lu T,Yan J L,Sun Z G,et al.Towards high-performance packet processing on commodity multi-cores:current issues and future directions[J].Science China Information Sciences,2015,58(12):1-16.
[19] Park C,Badeau R,Biro L,et al.A 1.2 TB/s on-chip ring interconnect for 45nm 8-core enterprise Xeon?processor[C]//Solid-State Circuits Conference Digest of Technical Papers.IEEE,2010:180-181.
[20] Emmerich P.Assessing Soft- and Hardware Bottlenecks in PC-based Packet Forwarding Systems[J].Computation World,2015:78-83.
[21] García-Dorado J L,Mata F,Ramos J,et al.High-Performance Network Traffic Processing Systems Using Commodity Hardware[M].Data Traffic Monitoring and Analysis,2013:3-27.
[22] Intel.Design considerations for efficient network applications with Intel?multi-core processor-based systems on Linux[EB/OL].2010.http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/multi-core-processor-based-linux-paper.pdf.
[23] The Linux Foundation,NAPI[EB/OL].2016.https://wiki.linuxfoundation.org/networking/napi.
[24] Corbet.UIO:user-space drivers[EB/OL].2007.https://lwn.net/Articles/232575/.
[25] Jeong E Y,Woo S,Jamshed M,et al.mTCP:a highly scalable user-level TCP stack for multicore systems[C]//Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation.USENIX Association,2014:489-502.
[26] Bradner S.Benchmarking Methodology for Network Interconnect Devices[S].RFC 2544,1999.
COMPARATIVERESEARCHONHIGH-PERFORMANCENETWORKPACKETPROCESSINGMETHODSINSERVERS
Li Xia Li Hu Gan Cheng Zhu Haodong
(SchoolofComputerandCommunicationEngineering,ZhengzhouUniversityofLightIndustry,Zhengzhou450002,Henan,China)
With the improvement of computer software and hardware performance, the data transmission rate of 10 Gbit/s and 40 Gbit/s can only be seen on the communication link in the past. In recent years, it has gradually appeared in the server cluster. However, with respect to the server, the network device on communication link uses a different set of instructions and microarchitecture, the hardware and the system kernel have been clipped, which makes it impossible for the server to process network packets as quickly as a network device. To solve this problem, this paper firstly analyzed the process of network packet processing from the two aspects of the hardware structure and operating system of the server, and found out the bottleneck and summarized relevant solutions. Secondly, a comparative study was made on several popular network packet processing frameworks, and their advantages and disadvantages were analyzed. Subsequently, the performance of the framework was verified by simulation experiments under different application scenarios. Finally, according to the technical characteristics of the different processing framework, the respective application scenarios and suggestions were put forward.
Servers Network packet Communication link Netmap DPDK VPP OVS
2017-01-17。李霞,教授,主研領域:計算機網絡,數據挖掘。李虎,碩士生。甘琤,講師。朱顥東,副教授。
TP301
A
10.3969/j.issn.1000-386x.2017.11.033
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
