基于最大熵譜估計和時頻特性的語音端點檢測
2017-12-08 03:23:59陳瑩瑩
計算機應用與軟件 2017年11期
陳瑩瑩 簡 磊
(四川大學錦江學院電氣與電子信息工程學院 四川 彭山 620860)
基于最大熵譜估計和時頻特性的語音端點檢測
陳瑩瑩 簡 磊
(四川大學錦江學院電氣與電子信息工程學院 四川 彭山 620860)
語音端點檢測對于構建實際語音識別系統具有重要的意義。為了提升在低信噪比條件下語音端點檢測算法的性能,提出一種基于最大熵譜和時頻特性的端點檢測算法。對分幀后的語音信號通過最大熵估算出功率譜,并根據帶噪語音信號時頻域上的特性進行特征捕捉,從而進行端點檢測。實驗結果表明,此方法在較低的信噪比下(-9~0 dB)能夠比較準確地捕捉語音信號的特征,明顯地提高了端點檢測的準確性。
端點檢測 最大熵譜估計 時頻特性 信噪比
0 引 言
語音信號端點檢測技術是語音處理中一個重要的前端處理環節。相對有效的端點檢測技術不僅能減少語音識別系統中的數據采集量,大大降低處理時間,還能去除靜音段或噪聲段的干擾,使語音識別系統的性能得以提升。
實際的端點檢測的目的是從帶噪語音中對語音信號進行檢測,因此大大提高了檢測的難度,目前的端點檢測最常用的方法比如[1]:短時過零率、短時能量、雙門限法、基于自相關函數的檢測,此類方法原理簡單、運算量小,當信噪較高的時候性能良好,但是信噪比較低時檢測性能大大降低。隨著技術發展,近年來又出現了頻帶方差[2]、倒譜系數[3]、小波[4]等方法,這些方法性能上有了很大改善,但是容易受到噪聲的影響,強噪聲環境下檢測效果仍然不理想。
熵代表一種不確定的信息。不確定的信息越多,熵值就越大,而且語音的熵和噪聲的熵存在很大區別。Shen[5]等將譜熵引入到語音信號端點檢測中,由于語音信號存在共振峰結構的特點,且歸一化譜概率密度函數分布不均勻,所以語音信號的譜熵值與噪聲的譜熵相比一般較低,與噪音信號相比在統計學概率上有區別。由于譜熵值與能量大小無關,所以譜熵法在帶噪環境下檢測效果優于其他算法。目前出現了許多基于譜熵的端點檢測算法[6-7],信噪比在0 dB以上檢測效果良好,為了進一步提高在信噪比較低(0 dB以下)的檢測準確性,提出了一種改進的基于最大熵譜估計的端點檢測算法。通過最大熵法求出每幀信號的功率譜分布,并結合改進的語譜圖分析得到基于短時功率譜的新特征參數。最大熵譜估計是一種以數據模型為基礎的現代譜估計技術。該算法具有短時性,對采樣點數要求較低,可以用來分析語音的短時特性,與短時FFT譜相比,短時最大熵譜的譜線明顯平滑,分辨率也大大提高了,可以從低信噪比下提取出有用信號。
1 理論基礎
1.1 譜熵法的介紹
基于譜熵的語音端點檢測方法的思路是利用檢測譜的分布程度來實現語音端點檢測的目的。為了提高檢測效果,語音信息譜熵采用短時功率譜來計算,實現了對語音段和噪聲段的區分。下面是對譜熵的定義的介紹。
設語音信號時域波形為x(i),加窗分幀后的第i幀語音信號為xn(m),FFT變換為Xn(k),k表示為第k條譜線。該語音幀的短時能量為:
(1)
某一譜線k的能量譜為:
(2)
則每個頻率分量的歸一化譜概率密度函數為:

(3)
該語音幀的短時譜熵為:
(4)
檢測方法為:
(1) 對語音信號進行分幀加窗處理,進行FFT變換。
(2) 得到每幀的譜能量值。
(3) 計算得到每幀語音信號的概率密度函數的大小。
(4) 經過計算得到每幀語音信號的譜熵值。
(5) 通過設置判決門限,利用各幀的譜熵值最終實現語音端點的檢測。
從譜熵法的算法推導過程和檢測思路可以看出,譜熵法檢測算法重點在于對語音信號的功率譜估計。功率譜估計的傳統方法是通過對信號進行傅里葉變換的方法來實現的,傅里葉變換有比較成熟物理基礎,實現起來較容易,所以在功率譜估計方面有很大的用途。但是由于傳統方法只有當要研究的數據較長也就是采樣點多的時候,功率譜估計精度才比較高。但是這樣處理數據的工作量增加了,而且在研究短信號或者瞬時信號時性能降低。傳統的功率譜估計方法進行運算時還必須要引入窗函數,假設將數據窗以外的數據全部設為零,就降低了功率譜分辨率,強信號的主瓣部分淹沒了弱信號的主瓣部分等現象,當處理的數據很短的時候這種影響就變得更加嚴重[6]。
正是在這一背景下Burg于1967年提出了以數據模型為基礎的最大熵譜估計方法,該算法根據少量的采樣數據便可獲得高頻譜分辨率的功率譜估計。所以比較適合分析短時信號,比如包含128個采樣點的一幀語音信號。最大熵方法,把關于過程的自相關函數無限外推,大大提高了估計得到的功率譜分辨率,所以與經典的方法相比,最大熵方法在對功率譜的質量要求較高時,彌補了傳統方法的不足。
1.2 最大熵譜估計算法描述
通過最大熵譜方法進行功率譜估計的基本思路[8]:對于已知有限延遲點上的自相關函數值保持不變;對于未知延遲點自相關函數,不進行其他任何假設,基于最大熵準則,利用已知的有限數據用無限外推法的方法求得,從而估計出被測信號的功率譜密度。
首先熵的定義為[9]:
(5)
可見熵是消息源發出每個消息的平均信息量,當隨機變量為對于高斯分布的時候,布卡喬夫證明了在信息熵和自協方差矩陣間存在著以下關系:
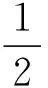
(6)
當時間序列為零均值時(當均值不為零,可以用時間序列減去均值的方法進行處理),熵和自相關函數之間存在關系:
(7)
當過程為無限長時,用熵率作為信息的度量如下所示:
(8)
時間序列功率譜密度和熵率存在著如下關系:
(9)
其中:離散的時間序列頻率為[-fc,fc]。
離散的時間序列的相關函數為:
(10)
離散的時間序列的功率譜可表示為:
(11)

(12)
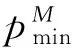
對于Burg遞推算法,它的主要思想是只從研究的離散時間序列本身出發,與最大熵保持一致的是對延拓的數據部分不進行任何先驗假設,所以得到了廣泛應用。Burg算法首先利用前向預測誤差功率和后向預測誤差功率兩者總均方差之和為最小的方法來求解得到反射系數,從而計算出預測誤差濾波器系數。
通過Burg法計算最大熵功率譜主要包括以下幾個步驟[10]:
(1) 對離散時間序列進行中心化處理,保證離散時間序列x(n)的均值不為零,如為零,則先將x(n)去均值。
(3) 通過相關計算得到反射系數km。
(6) 計算濾波器輸出:
fm(n)=fm-1(n)+kmgm-1(n-1)
gm(n)=gm-1(n-1)+kmfm-1(n)
(7) 令M=M+1,并重復步驟(3)至步驟(6),直到預測誤差功率不再明顯減小。

1.3 最大熵譜估計階數的選擇
預測誤差濾波器階數的選擇在最大熵譜估計過程中很重要,所以必須要正確選擇模型的階數。假設模型階數為M,采樣序列長度為N,如果選擇的M值太小,通過最大熵方法估計得到的離散時間序列的功率譜會過度的平滑,分辨率較低,從而出現被研究信號中最容易預測,變化最緩慢的頻點的峰值。反之,如果M太大,會使擬合產生急劇的變化,得到的譜估計中包含虛假的細節部分,降低譜估計的準確性。

2 語音信號的時頻特性介紹
語音的發音過程中經過的器官之一聲道通常都是處不穩定狀態的,所以得到了時變的共振峰特性。但是與振動過程相比,這個時變過程比較緩慢,在研究過程中可以假設它具有短時平穩性,每一時刻的頻譜可以用這時刻附近的一段短時語音信號得到,比如12 ms的時間段。連續地對語音信號進行頻譜分析可以得到關于語音的一種二維圖譜,在圖中時間為橫坐標,頻率為縱坐標,對應時刻和對應頻率的信號能量密度用每像素的灰度值大小表示,能量越大顏色越深,能量越小顏色越淺。通過這種方法得到時頻圖為語譜圖(Spectrogam)[11]。很多與語音特性有關的信息包含在語譜圖中,并且這種時頻圖結合了頻譜圖和時域圖的特點,明顯地顯示出語音動態的頻譜,即隨時間變化的頻譜特性,被視為可視語言的時頻圖在語音分析中有重要實用價值。對于發音器官,任一時刻共振峰特征、基音頻率、是否清音和爆破音等參數都可以從語譜圖上得到。總之,在語音識別、合成及編碼中語譜分析具有很重要的意義。
圖1為語音信號“我到黑龍江”的語譜圖,通過圖中可以看到花紋有橫條紋和豎條紋。其中橫條紋反映的是共振峰特性,參數值為與時間軸平行的幾條深黑色帶紋,所以共振峰頻率和帶寬可以從對應橫杠的頻率和寬度確定。同時橫杠是也判斷濁音的重要標志。其中一個個的豎直條相當于一個個的基音,聲門脈沖的起點用條紋的起點表示,基音周期通過條紋之間的距離表示。基音頻率越高的語音信號得到的條紋越密。在得到的語譜圖里,根據橫軸可以判斷每個字的開始和結束,因此可以將語譜圖作為端點檢測的依據。

圖1 “我到黑龍江”語譜圖灰度顯示
3 算法介紹
3.1 算法原理
當在整個頻帶上語音信號的能量都有分布時,全頻帶上能量分布的變化會受到語音信號的變化;通過分析可知,在頻域范圍內語音信號能量最大點在諧波附近[11]。當背景噪聲很大的時候,雖然語音信號時域特性已被噪聲完全淹沒,但是語譜圖上的能量分布仍然比較明顯。圖2所示的是語音“我在黑龍江”在高斯白噪聲污染下的頻譜圖,其中信噪比為2 dB,圖中顯示語音信號大部分區域被噪聲所掩蓋,但是在語音存在的地方顏色較其他區域較突出,圖中白亮、有黑白條紋的地方為語音信號存在的范圍。這個特點可以作為語音信號和非語音信號部分的依據,而且在復雜的惡劣的噪聲背景下也具有很強的魯棒性,所以語譜圖可以用于低信噪比環境中的端點檢測[12]。

圖2 帶噪聲的“我到黑龍江”語譜圖灰度顯示
3.2 算法實現
(1) 將語音信號進行預處理:首先對語音信號進行采樣,采樣頻率為8 kHz,然后分幀加窗,幀長取16 ms(128個采樣點),幀移為8 ms,對每幀信號加128點的漢明窗得到的信號為sw(n),n為幀數,w代表加窗。
(2) 求出每幀的功率譜參數:利用最大熵法求出每幀信號sw(n)的功率譜pxx(n),其中預測濾波器階數采用14階,最后求出所有幀的功率譜對數值p(n,k),其中n為幀數,用橫坐標表示,k為每幀的采樣點數,用縱坐標表示,通過將p(n,k)的值表示為灰度級得到的二維圖像就是語譜圖[13]。經過以下變換:10log10(p(n,k))能得到語譜圖的分貝表示。
(3) 提取時頻特性參數[13]:對10log10(p(n,k))進行歸一化,選取基準值Base取經驗值,得到了矩陣L(n,k),把小于Base的值設為0,大于Base的值線性映射為0~1內的歸一化值。
(4) 計算每幀的功率譜均值矩陣l(1:n)。
(5) 利用移動平均法對l(1:n)進行平滑處理。
4 實驗結果及分析
通過實驗,對算法進行了評價。選取其中一組語音“我到黑龍江”來說明檢測情況,其中語音的采樣頻率為8 kHz,幀長為16 ms,幀移位8 ms。加入的噪聲為高斯白噪聲,實驗分別在不同信噪比下對基于短時能量、基于頻譜方差、本論文改進的方法進行了比較和分析。
圖3-圖8為不同信噪比下的檢測分析圖,其中SNR為信噪比,可以得出以下結論:
(1) 當信噪比大于0 dB時三種檢測方法都可以很容易檢測出這段語音包含的五個字的端點,提取出來的特征參數和原始語音信號的時域圖匹配。
(2) 當信噪比在-2.7 dB本論文方法檢測結果與原始語音信號時域圖基本匹配,而基于短時能量和基于頻譜方差的檢測方法檢測誤差比較大,尤其是頻譜方差的檢測方法誤差最大。
(3) 當信噪比在-5 dB、-7.5 dB和-9 dB時,基于短時能量和基于頻譜方差的檢測方法檢測識別不出語音信號的特征。本文改進方法仍然能夠準確地提取到純凈語音信號的特征參數,當信噪比在-9 dB檢測匹配度仍在80%左右。
(4) 總之,從圖3-圖8可見,隨信噪比的減小,頻譜方差和短時能量的檢測效果變差,最大熵譜和時頻特性方法在幾種情況下均可以提取出被測語音的特征,通過觀察改進的功率譜特性圖(每圖的第四個波形),從中可以明顯地看到語音信號的起止點,從而進行準確的語音端點檢測。當信噪比為-9 dB以上時,通過改進的檢測方法,噪聲部分相當于被削弱,而語音特征變得明顯,在低信噪比情況下提高了語音端點檢測的效果。

圖3 SNR=8 dB時的檢測分析圖

圖4 SNR=0 dB時的檢測分析圖

圖5 SNR=-2.7 dB的檢測分析圖

圖6 SNR=-5 dB的檢測分析圖

圖7 SNR=-7.5 dB的檢測分析圖

圖8 SNR=-9 dB的檢測分析圖
表1是語音“我到黑龍江”在基于最大熵譜估計和時頻特性得到的測試統計情況,數字范圍是單個漢字對應的范圍,表中列出了不同信噪比情況下的檢測結果。可以看出整體檢測效果較好,在信噪比大于-5 dB的情況下,每個字的起止檢測都較準確。信噪比降到-9 dB的時候每個字的起止點都會出現了部分錯誤,不過檢測率仍然大體保持在80%左右。在這段語音中由于“黑龍”兩字之間出現連音情況,端點檢測結果出現了一定的偏差。
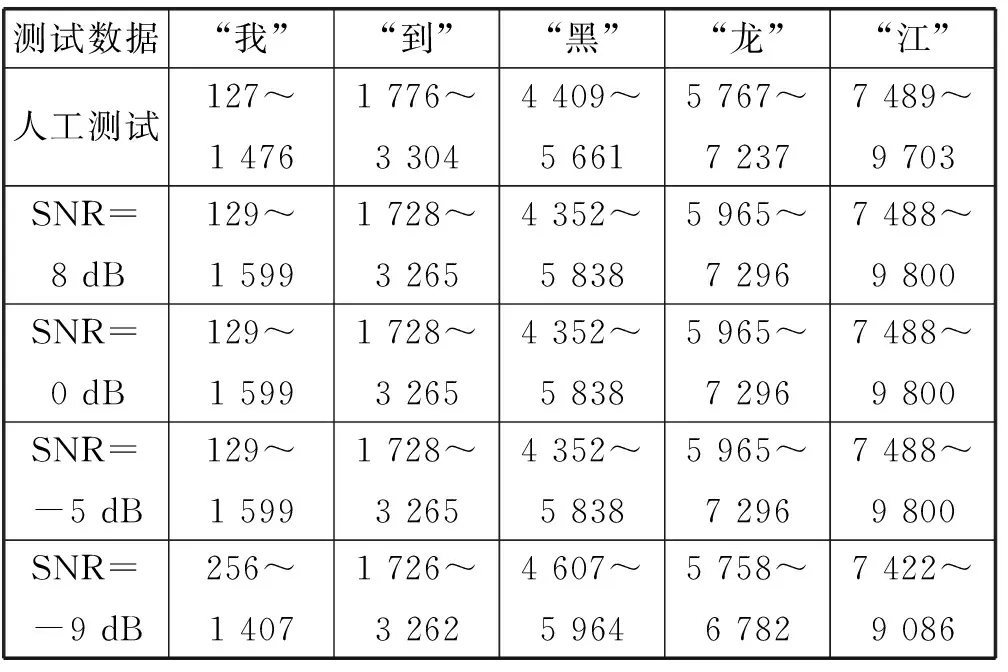
表1 測試統計情況
5 結 語
提出一種基于最大熵譜和時頻特性的語音端點檢測方法,最大優點是提高了在低信噪比(-9~0 dB)情況下可以有效地提取出語音信號的特征參數,從而大大提高了端點檢測的準確率。通過利用語音信號和噪聲在最大熵譜估計及語譜圖上特性的區別,首先利用最大熵方法計算帶噪語音的短時功率譜,然后利用時頻特性提取特征參數從而進行端點檢測。實驗證明這種不同于以往的短點檢測算法效果比較理想,該檢測算法尤其適合于在白噪聲環境下。但是實驗中出現連字情況時檢測效果受到了影響,對于爆破音、除白噪聲以外的噪聲情況沒有考慮,在這些方面可以對算法進行進一步的改進。
[1] 宋知用.MATLAB在語音信號分析與合成中的應用[M].北京:北京航空航天大學出版社,2013:16-27.
[2] Zhao H,Zhao L X,Zhao K,et al.Voice activity detetion based on distance entropy in noisy environment[C]//5th International Joint Conference on INC,IMS and IDC Seoul.Korea:IEEE Computer Society,2009:1364-1367.
[3] 沈紅麗,曾毓敏,王鵬.一種改進的基于倒譜特征的帶噪語音端點檢測方法[J].通信技術,2009,42(2):156-158.
[4] 魯遠耀,周妮,肖珂,等.強噪聲環境下改進的語音端點檢測算法[J].計算機應用,2014,34(5):1386-1390.
[5] Shen J L,Hung J W,Lee L S.Robust entropy-based endpoint detection for speech recognition in noisy environments[EB/OL].[2014-08-12].http://wenku.baidu.com/view/e676ac0979563clec5da71d5.html.
[6] 劉艷,倪萬順.基于子帶譜熵的仿生小波語音增強[J].計算機應用,2015,35(3):868-871.
[7] 張婷,何凌,黃華,等.基于臨界頻帶及能量熵的語音端點檢測[J].計算機應用,2013,33(1):175-178.
[8] 任月清,張澤.基于最大熵譜估計的超聲檢測回波頻譜分析[J].內蒙古大學學報,2007,38(4):454-457.
[9] 曹建農.圖像分割的熵方法綜述[J].模式識別與人工智能,2012,25(6):958-970.
[10] 趙成林,王桂軍,孫學斌.基于最大熵譜估計的頻譜感知方法的研究[J].計算機仿真,2010(5):508-512.
[11] 劉紅星,戴蓓蒨,陸偉.非平穩噪聲環境下基于諧波能量的語音檢測[J].計算機仿真,2008(11):305-308.
[12] 吳迪,趙河明,黃呈偉,等.低信噪比下采用感知頻譜結構邊界參數的語音端點檢測[J].聲學學報,2014,39(3):392-399.
[13] 李富強,萬紅,黃俊杰.基于MATLAB的語譜圖顯示于分析[J].微計算機信息,2005,10(3):172-174.
SPEECHSIGNALENDPOINTDETECTIONBASEDONMAXIMUMENTROPYSPECTRUMESTIMATIONANDTIME-FREQUENCYSIGNATURE
Chen Yingying Jian Lei
(SchoolofElectricalandElectronicInformationEngineering,JinjiangCollege,SichuanUniversity,Pengshan620860,Sichuan,China)
Speech endpoint detection is crucial to the construction of a practical automatic speech recognition system. A new algorithm based on the maximum entropy spectrum estimation and time-frequency signature is proposed to improve the performance of speech endpoint detection in low SNR (Signal Noise Ratio) environment. The framed speech signal power spectrum was estimated through the maximum entropy, and then the characteristics of noisy speech were extracted in time-frequency field in order to detect the endpoint. Experimental results show that, this method can accurately capture the characteristics of speech signals under lower SNR (-9~0 dB), and significantly improves the accuracy of endpoint detection.
Endpoint detection Maximum entropy spectrum estimation Time-frequency characteristics SNR
2016-12-22。陳瑩瑩,講師,主研領域:信號檢測與識別。簡磊,講師。
TP391.42
A
10.3969/j.issn.1000-386x.2017.11.017
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
電子制作(2018年11期)2018-08-04 03:25:42
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
