基于虛擬化環境的多GPU并行通用計算平臺研究
2017-12-08 03:15:48吳俊敏楊志剛
計算機應用與軟件 2017年11期
徐 恒 吳俊敏 楊志剛 尹 燕
1(中國科學技術大學軟件學院 安徽 合肥 230027) 2(中國科學技術大學計算機科學與技術學院 安徽 合肥 230027) 3(中國科學技術大學蘇州研究院 江蘇 蘇州 215123)
基于虛擬化環境的多GPU并行通用計算平臺研究
徐 恒1,3吳俊敏2,3楊志剛2尹 燕2
1(中國科學技術大學軟件學院 安徽 合肥 230027)2(中國科學技術大學計算機科學與技術學院 安徽 合肥 230027)3(中國科學技術大學蘇州研究院 江蘇 蘇州 215123)
針對分布式多節點多GPU的系統環境,實現一種基于CUDA框架的多GPU通用計算虛擬化平臺。應用程序可以如同使用本地GPU一樣方便地使用多個遠程GPU,原來的CUDA應用程序可以不經過修改或者只進行少量的修改就可以運行在該虛擬化GPU平臺上,從而實現單機多GPU和多機多GPU在編程模式上的統一,并通過一個基于高斯混合模型的數據聚類程序來進行實驗驗證。實驗結果表明,在不影響程序正確性的前提下,相對于原來使用CPU的程序,使用兩個遠程GPU可以獲得十倍左右的加速比。
虛擬化 GPU 多機多GPU 分布式
0 引 言
近年來, GPU的通用計算功能得到了迅速發展。隨著GPU的性能提高以及GPU自身的結構特性,使得GPU在大規模并行計算中起著越來越重要的作用,對于GPU的通用計算功能的研究也成為了熱點。在通用計算領域,以CUDA為代表的并行計算架構將GPU引入到科學計算。但是CUDA規范只能直接訪問本地的GPU,并沒有直接提供對遠程GPU的訪問接口,為了能夠使用網絡中的遠程GPU,開發人員需要用到MPI與CUDA結合等方法,這增加了程序的復雜性并且給開發人員帶來額外的工作量。
為了能夠更加方便地使用多GPU系統的計算資源,本文以開源項目gVirtuS為基礎,實現了一種基于CUDA框架的、支持多GPU通用計算的虛擬化方案,可以將分布式環境中多個節點的GPU資源的統一抽象到一個GPU池中。程序可以用本地GPU的方式使用任意位置、任意數量的GPU的資源,原有的CUDA程序可以不修改源代碼只要在編譯過程中進行簡單的配置就可以在該虛擬化平臺上運行,即使沒有GPU設備或者只有不支持CUDA的GPU設備也能夠十分方便地使用分布式環境中的非本地GPU資源進行通用計算。
1 GPU虛擬化背景
虛擬化技術在現代計算機系統中有非常廣泛的應用,是對傳統計算資源的使用方式的一種突破。在虛擬化技術中,由于I/O設備的復雜性、多樣性與封閉性,針對I/O設備的虛擬化一直是瓶頸。GPU屬于I/O設備中的特殊部分,其功能主要有圖形計算與通用計算兩部分,近年來隨著神經網絡的興起,GPU的通用計算功能越來越受重視,針對GPU通用計算的虛擬化一直是學術界研究的熱點。目前GPU虛擬化技術主要有三類:1) 設備獨占;2) 設備模擬;3) 應用層接口虛擬化(即API重定向)。此外還有硬件虛擬化,但是運用較少。
由于CUDA的廣泛應用,對GPU通用計算的虛擬化主要是基于CUDA的解決方案,例如rCUDA[1]、vCUDA[2-3]、 gVirtuS[4]、Gvim[5]等。其中vCUDA是針對在虛擬機環境中運行CUDA程序提出的解決方案,“采用在用戶層攔截和重定向CUDA API的方法,在虛擬機中建立物理GPU的邏輯映像”[3]。vCUDA出現時間較早,對于CUDA 4.0之后的版本不再支持。Gvim是基于Xen系統的,實現了基于前后端的CUDA虛擬化系統,但是并沒有實現CUDA全部功能的虛擬化。rCUDA是目前比較成熟的GPU虛擬化解決方案,支持最新的CUDA 7.5,支持cuDNN,其不再側重于針對虛擬機的GPU虛擬化,而是所有不包括NVIDIA GPU的節點都可以使用rCUDA來使用GPU進行通用計算。rCUDA可以免費獲得,但是不開源,其具體實現細節與原理都未公開。gVirtuS是基于前后端模式實現的GPU通用計算虛擬化方案,其前端提供了一個封裝了CUDA接口的偽庫。在前端的所有的對CUDA API的調用都會被這個偽庫攔截并轉發到后端進行處理,而后端則運行在具有處理能力的宿主機上,負責處理前端發來的請求。這種虛擬化方案被稱為API重定向( API remoting),其訪問遠程GPU時采用的前后端通信方式是TCP/IP,只能使用一臺遠程主機中的GPU資源。
以上方案無論是針對虛擬機的vCUDA還是針對遠程物理機的rCUDA,其設計都包含有高效性、普適性、透明性三個原則。高效性是要求虛擬化方案不能帶來額外的開銷;普適性是指虛擬化方案不能只針對特定虛擬化平臺有效,在本文中的虛擬化方案除了虛擬化平臺外還包括了沒有GPU的物理平臺;透明性是指虛擬化的方案對于CUDA應用保證兼容性,不要求修改CUDA程序源碼或者重新編譯,或者只需要做很少的修改就可以在虛擬化平臺上運行,在透明性良好的虛擬化方案中,原有的單機多GPU程序可以直接在多機多GPU的分布式環境中運行,從而實現了不同環境中的編程模式的統一,這也是本文研究的重點。
2 單GPU虛擬化
本節討論如何通過API重定向虛擬化方案來訪問單個的遠程GPU進行通用計算的問題,以此為基礎,下一節再來討論如何使用分布式環境中的多個GPU的問題。在本文中的“虛擬節點”這個術語有兩層含義:一是指傳統意義上的虛擬機節點;二是指沒有配備可以運行CUDA的GPU的物理機節點。為了不引起歧義,本文使用“前端節點”這個術語來指代以上兩層含義。相應的,使用“后端節點”這個術語來指代宿主機。
2.1 API重定向虛擬化方案
API重定向技術虛擬化方案[6],是一種應用層接口虛擬化,是對GPU相關的應用程序編程接口在應用層進行攔截,然后使用重定向方式實現相應的功能,將完成的結果返回給對應的應用程序。
這種方案是針對CUDA運行時API(Runtime API)進行虛擬化,為前端提供了一個運行時偽庫,該偽庫重寫了CUDA的運行時API,將其實現為對后端的遠程調用。前端編寫的CUDA程序對CUDA API的調用被偽庫動態攔截,偽庫將CUDA API的參數與名稱發送到前端通信部分,再由前端通信部分通過網絡發送給后端,后端接受相應參數后調用真正的CUDA程序進行計算,然后將運行結果返回給前端。結構如圖1所示。
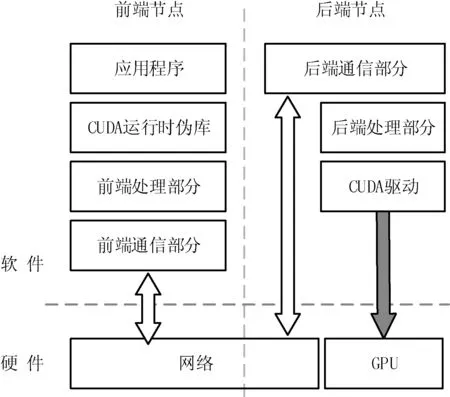
圖1 API重定向虛擬化方案結構
這種方案解耦了上層軟件與底層硬件之間的強耦合關系,不僅可以應用在虛擬機中,也可以為沒有配備GPU資源或者配備了缺少支持CUDA的GPU資源的計算機提供一種使用遠程節點上的GPU的方法。這兩種方案的區別在于前端與后端的通信方式的不同:在虛擬機中可以利用虛擬機與宿主機之間的高速通信方式,而在訪問遠程節點上的GPU時只能使用網絡通信。
這種方案不依賴于特定的虛擬化平臺,前端節點可以是一個Xen、KVM、Vmware或者其他任何一臺虛擬機,甚至可以是一臺真正的物理機,只要與后端節點有網絡連通,都可以使用這種方案來搭建虛擬化平臺。搭建的方式也十分簡單,只需要在前端節點中安裝好運行時偽庫(一般與原裝庫同名),然后在配置文件中將后端節點的IP地址正確的寫入即可。原本的代碼不需要做任何的修改,只要在編譯時將偽庫鏈接到可執行文件中,源程序不需要做任何的修改就可以運行在虛擬化平臺上。應用程序可以如同使用本地GPU一樣方便地使用遠程GPU,虛擬化平臺的復雜的執行流程對程序員完全透明。
一個典型的CDUA API的執行過程如圖2所示,不同的API執行步驟會有差異,但基本流程都是如圖2所示。圖中虛框部分是虛擬化平臺所做的處理,一般包括前端部分與后端部分,分別位于不同的節點上。前端節點與后端節點之間的交互包括數據傳輸與函數調用,前端的所有參數都會被偽庫攔截轉發給后端,后端節點接收了參數之后會啟動核函數進行運算,最后將結果返回給前端節點。每一個CUDA API在執行時都會涉及上述步驟,執行期間會有大量數據傳輸,涉及不同組件、不同節點,數據傳輸對應用程序的性能會產生重大影響,是虛擬化方案設計時要解決的重要問題。
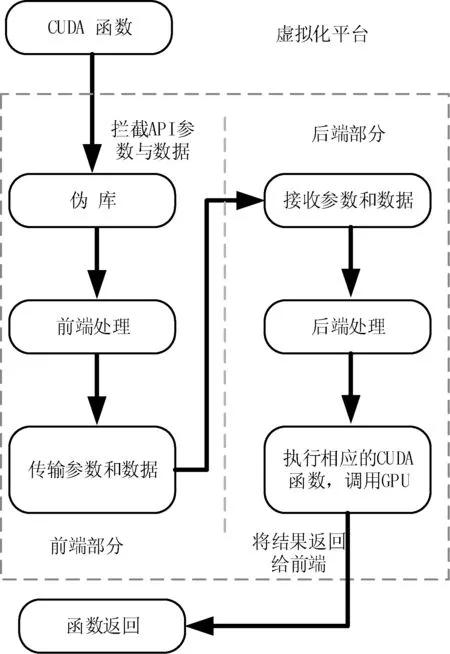
圖2 CUDA函數在虛擬化平臺上的執行流程
2.2 程序在虛擬化平臺上的執行過程
圖2顯示了CUDA函數在虛擬化平臺上的執行流程,與直接在本地上運行時不同,在虛擬化平臺上程序執行時被分解為了前端與后端兩個部分,這使得其執行步驟更加復雜。在沒有虛擬化的環境下,一次GPU運算的過程可以簡單地分成三個步驟:
1) 將數據從主機內存拷貝到GPU顯存。
2) 在GPU上啟動核函數,開始計算。
3) 將結果由GPU顯存拷貝回主機內存。
在虛擬化方案中,由于前端節點與后端節點往往不是在一臺機器上,除了必要的數據外,前后端之間還需要傳輸大量的參數信息與控制信息,這些都是由虛擬化平臺來處理。
圖3是一個求后端節點的GPU數目的簡單程序,原程序不需要做任何的修改就可以移植到虛擬化平臺上,并得到正確的結果,只是其執行的流程更加復雜:
1) 根據配置文件中提供的IP地址,前端傳輸相關的參數到后端,完成GPU資源的初始化,并傳回句柄的相關信息。如果無法完成初始化,則報錯。
2) 在后端GPU上注冊代碼段(FatBinary),程序在本地上運行時,這一步驟會隱式的調用一個CUDA未公開的API _cudaRegisterFatBinary()來完成如內存偏移、空間大小、GPU設備編號等相關初始化工作。該API是在程序的所有代碼之前被調用。在虛擬化環境下,這一過程由平臺來完成,同樣對前端編程人員透明。
3) 將計算數據與參數從前端內存傳輸到后端節點的內存,這往往是通往網絡傳輸的。
4) 根據前端傳輸過來的參數以及控制信息,后端節點調用GPU進行計算。
5) 后端節點將計算結果拷貝回主存,釋放資源,并且完成相關的清理工作,在GPU程序的所有代碼執行結束之后,還需要調用另外一個未公開的CUDA API: _cudaUnregisterFatBinary()來注銷相關的信息。
6) 虛擬化平臺的后端將計算結果傳回給前端節點。

圖3 一個簡單程序在虛擬化平臺上的執行
上述一個簡單的求后端節點的GPU數目的例子中就涉及到了兩個未公開的CUDA API。由于CUDA的封閉性,還有其余未曾公開的API,這些不曾出現在官方文檔中的API是實現虛擬化方案的過程中需要處理的棘手問題。為了保證虛擬化平臺的透明性,這些API的功能都是由虛擬化平臺來實現。
以上是對虛擬化平臺的程序執行步驟的簡單介紹。一個簡單的程序在虛擬化平臺上的運行過程往往就涉及到了復雜的參數傳遞與控制信息傳遞,這些數據都要通過網絡來傳輸,新增加的軟件棧也會導致性能降低。另外,在一些程序中,需要處理大量的數據,這些數據在前端/后端之間傳輸所帶來的延時往往會比GPU處理這些數據的時間高的多,這也常常成為程序的性能瓶頸。
2.3 改變通信方式提高效率
在2.1小節論述了論述了虛擬化平臺的普適性、透明性原則,本小節討論虛擬化過程的效率性。本文采用的API重定向技術是在應用層完成了對GPU的虛擬化,這是一種在CUDA的封閉、不了解其內部細節情況下提出的虛擬化方案[7],也是目前研究GPU通用計算虛擬化的主流方案。API重定向方案可以解決CUDA封閉性問題,然而由于需要攔截/轉發、前端處理、后端處理等步驟來實現平臺的功能并對上層程序員透明,因此帶來了額外傳輸開銷與控制開銷。新增加的軟件棧也會降低系統的性能[8],尤其是在采用網絡傳輸來實現前端/后端的參數傳遞與數據傳輸時。相對于主機內存到GPU顯存的高速傳輸,網絡傳輸的延時往往會高好幾個數量級,這部分開銷也成了整體性能的瓶頸,如何通過提高通信的性能也是本文要討論的重點。
前端節點與后端節點的通信方式有不同的選擇,當需要訪問遠程的GPU時,采用的是基于socket的傳輸方式進行通信,這帶來兩個問題,一是前端/后端之間的數據傳輸延時比較大;二是一個前端節點只能與一個后端節點進行通信,無法同時對多個GPU進行抽象和映射。本小節將其通信方式改為ZeroMQ來解決第一個問題,第二個問題在第4節討論。由第2.1小節可以知道,通信部分為CUDA編程提供了有效的底層通信接口,前端通信部分與后端通信部分的關聯十分緊密,而通信部分與系統的其余部分的耦合性并不高,在深入研究之后為系統增加了一種新的高效通信方式:ZeroMQ通信方式。
ZeroMQ是一種基于消息隊列的多線程網絡庫,其對套接字類型的底層細節進行抽象,提供跨越多種傳輸協議的套接字。相對于Socket來說ZeroMQ是一個更為高效的傳輸層協議。ZeroMQ設計之初就是為了高性能的消息發送而服務的,所以其設計追求簡潔高效。ZeroMQ是面向“消息”的而非字節流,發送消息采用異步模式。
實驗表明,采用ZeroMQ通信方式的程序能夠比原來的Socket方式整體性能更高。實驗中的后端節點配置Inter(R) Core(TM) i5-4590CPU(3.3 GHz)處理器,4 GB內存和100 GB硬盤,GeForce GTX750 Ti GPU,Ubuntu 14.04 64位操作系統,CUDA版本為7.5。前端節點是一臺物理機,配置Celeron(R) Dual-Core CPU T3000(1.8 GHz)處理器,3 GB內存和30 GB硬盤,沒有NVIDIA顯卡,也沒有安裝CUDA程序,Ubuntu 14.04 64位操作系統。前后端之間通過百兆以太網交換機互聯。由于網絡環境會影響到實驗結果,所以每組數據都是測試多次取平均值,實驗運行的程序都是CUDA SDK自帶的程序。計算性能實驗在三類平臺上進行對比,即本地GPU計算平臺、基于Socket通信方式的虛擬化計算平臺以及基于ZeroMQ通信方式的虛擬化計算平臺。
圖4顯示的是向量加法的性能實驗結果,其中橫坐標表示的是向量長度,縱坐標是運行時間。除了運行時間不同之外,運行結果與本地機上的運行結果沒有差別,說明虛擬化平臺不會對程序的正確性有影響。實驗結果表明使用ZeroMQ通信方式可以提高系統的整體性能,在這個程序中,可以獲得20%~35%的性能加速。然而與本地運行的程序相比,隨著數據量的加大,不論是哪一種通信方式的虛擬化方案所帶來的性能損失也越來越大。這是因為隨著向量規模的增加需要傳輸的數據量越多,就有更多的數據和參數需要在前端/后端之間傳遞,自然會有更大的傳輸開銷與控制開銷。而數據在GPU上計算所增加的時間并不多,這是因為GPU特別適合處理向量加法這種可以并行的程序,因此數據規模的加大并不會使GPU的運算時間大幅提高。
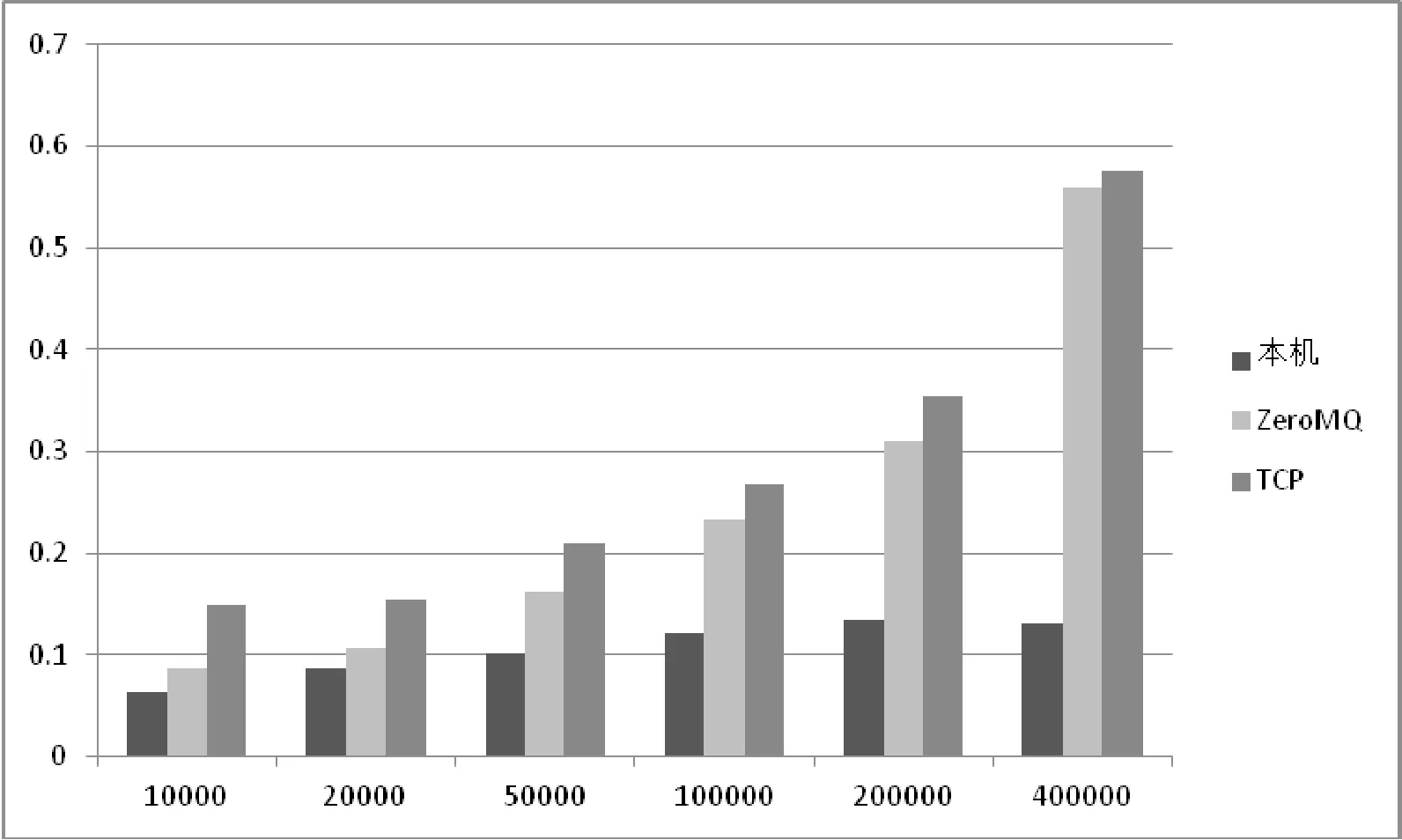
圖4 不同平臺上向量加法程序的執行結果
在GPU上運行的往往不會是向量加法這么方便地進行并行處理的程序,比如復雜一些的CUDA程序:矩陣乘法,這是一個計算密集型程序,其需要傳輸的數據并不太多,而GPU的運算卻相對復雜,結果如圖5所示。
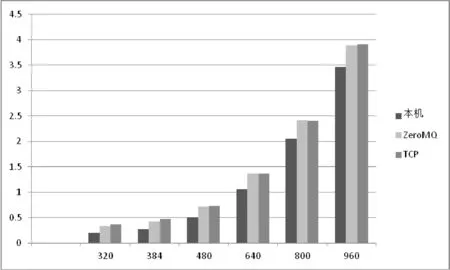
圖5 不同平臺上矩陣乘法程序的執行結果
圖5中橫坐標是參加運算的矩陣的階數,縱坐標是程序的運行時間。實驗結果表明,當矩陣規模越大時,虛擬化方案的性能反而越接近物理機,當矩陣的規模為960×960時,程序在基于ZeroMQ的虛擬化平臺上的運行時間是在物理機器上運行時間的1.12倍,此時達到臨界點,規模更大的矩陣運算不會使程序的性能更接近本地機,因為傳輸開銷與控制開銷以及額外的軟件棧等是虛擬化無法避免的性能損失。以上實驗結果表明虛擬化平臺在處理計算密集型的程序時損失的性能會相對較少。圖5中還顯示了另外一個問題:基于ZeroMQ方式與基于Socket方式的虛擬化平臺之間的性能差距不再十分明顯。這同樣是由于程序的計算比較復雜,需要GPU運算的時間大大超過了數據在網絡中傳輸的時間,通過改變通信方式獲得的性能提升不再明顯,那么為什么依舊選擇ZeroMQ呢?下一節的多GPU虛擬化來討論這個問題。
3 多GPU虛擬化
多GPU平臺主要有兩種構架,如圖6所示。一種是單機多GPU,另一種是多機多GPU,即GPU集群[9]。在編程方式上,在單機多GPU的環境下CUDA提供了直接的編程接口,而對于多機多GPU的結構CUDA沒有相關的編程接口,需要借助其他工具,如基于MPI與CUDA相結合的方式,要求編程人員顯式地采用分布式MPI編程。目前的多GPU的處理方案中,一般都是將兩種情況區別對待,運行在單機多GPU上的CUDA代碼需要進行很大的修改才能移植到多機多GPU的環境上,如何實現二者在編程模式上的統一是本文討論的重點。

圖6 單機多GPU與多機多GPU
在第2節中提到的基于Socket方式來實現的單GPU虛擬化方案中,由于Socket只支持一對一的通信,一個前端節點只能訪問一個遠程GPU,無法同時調用集群環境中的多個GPU來加速應用程序。因此,在基于ZeroMQ通信方式的虛擬化方案除了能夠提高效率外,還實現了另外的功能:ZeroMQ支持一對多的通信,從而能夠同時使用多個遠程GPU,實現多GPU的虛擬化方案,如圖7所示。一個前端節點可以綁定多個后端節點的IP地址,從而能夠通過ZeroMQ同時調用多個后端節點上的GPU資源。GPU集群中存在多個節點,每個節點配備了不同的GPU資源,節點之間通過網絡互連。在虛擬化的過程中,通過IP地址來標識不同節點的GPU,將其映射到一個統一的GPU池中,并且順序編號為GPU0,GPU1,…,GPUn等。所有分布式環境下需要解決的容錯性,冗余性等問題都在虛擬化過程中解決。對于前端節點來說,其能夠使用的GPU的最大數目就是這個GPU池中的數目。在邏輯上,前端應用調用這個GPU池中的GPU的方式和使用本地GPU的方式完全相同,從而將多機多GPU卡的物理環境抽象成了單機多GPU卡的邏輯環境,使得單機多卡的程序可以不用修改或者只做很少的修改就可以運行在多機多卡的環境下,實現了兩個環境編程模式的統一。
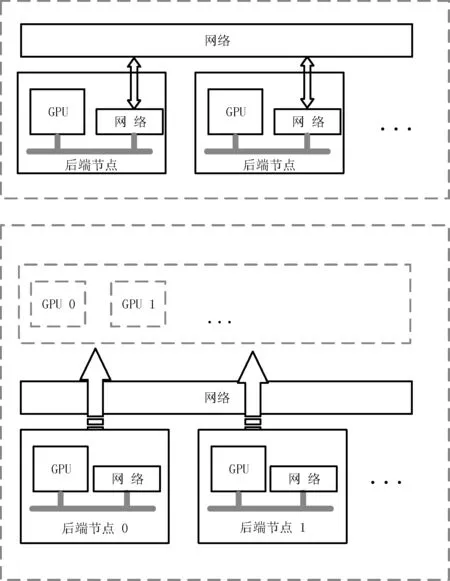
圖7 多GPU虛擬化平臺的物理結構與邏輯結構
如圖7所示,集群中的所有GPU資源都由虛擬化平臺來管理,前端需要使用GPU資源時,只需要在配置文件中準確描述后端節點的IP地址和需要的GPU數目,就可以將相應節點上的GPU映射到本地。應用程序可以像訪問本地GPU一樣調用這些映射來的GPU進行加速。此外當有些程序需要的GPU資源超過了單個節點的能力時,這也是一種很好的解決方案。程序開發過程中,開發人員只需要專注于CUDA編程, GPU資源的分布、數據的傳輸、冗余與錯誤處理等都交給虛擬化平臺來處理。這種方式的靈活性極好,對GPU資源的分配只需要修改配置文件即可。
多GPU虛擬化平臺的優勢是可以使用分布式環境中的其他節點的GPU資源,并且理論上沒有數目的限制,具體需要使用多少的GPU資源取決于程序開發人員和分布式環境中的GPU資源數目。此外由于虛擬化平臺的透明性很好,使用遠程GPU的方式就如同使用本地GPU一樣,可以直接通過CUDA提供的接口方便的調用,可移植性非常好。例如CUDA SDK自帶的多GPU samples程序絕大部分都可以直接運行在虛擬化平臺上,不需要修改源碼,只需要修改編譯時的選項并重新編譯即可,只不過這些程序往往都是以演示功能為主,計算規模不大,并不能體現出多GPU虛擬化的優勢。
在第2節中詳細分析了程序在單GPU的虛擬化平臺上的執行流程,在多GPU的虛擬化環境下程序的執行流程也是基本如此。此外在進行多GPU的并行計算時,還有數據的分解、運算和合并等步驟,因此會帶來更多的軟件棧和控制開銷。所以當程序的計算規模不大時,使用多GPU虛擬化平臺往往不能得到很好的結果。第4節的實驗結果可以證明,當計算規模比較大的時,使用多個GPU是可以抵消這些開銷所帶來的性能損失從而提升程序的執行效率。
4 實驗結果與性能分析
4.1 實驗環境
實驗中的后端節點是兩臺配置Inter(R) Core(TM) i5-4590CPU(3.3 GHz)處理器,4 GB內存和100 GB硬盤,GeForce GTX750 Ti GPU,Ubuntu 16.04和Ubuntu 14.04 64位操作系統,CUDA版本分別為6.5和7.5;前端節點是一臺物理機,配置Celeron(R) Dual-Core CPU T3000(1.8 GHz)處理器,沒有NVIDIA顯卡,也沒有安裝CUDA程序,Ubuntu 14.04 64位操作系統;前端與后端節點通過百兆以太網互連。
4.2 實驗內容
實驗運行的程序基于CUDA框架使用EM(Expectation Maximization)算法在高斯混合模型(Gaussian Mixture Model)下進行數據聚類,原程序可以使用單個節點上的多個GPU進行加速,是CLUSTER[10]的GPU實現,程序有單節點單GPU和單節點多GPU兩個不同的執行模式,當探測到節點中的GPU數目多于一個時,會啟用多個線程控制多個GPU來加速程序的執行,實驗使用的數據集是用Matlab生成的,所有不同類型的程序都是在同一個數據集上執行。實驗中分別在前端節點上使用本地CPU和通過虛擬化平臺使用1個、2個遠程GPU計算同樣的輸入數據集,后端節點配置了相同類型的GPU,只是CUDA 版本和操作系統版本有區別。虛擬化平臺為基于ZeroMQ通信方式的多GPU虛擬化方案。
圖8中橫軸代表的是初始時cluster的數目,不同的數目會影響程序的執行時間,所以使用這個參數來做對比,縱軸表示整個程序運行的時間。隨著初始cluster的值增加,使用CPU處理花費的時間增長更快,使用GPU獲得的加速比也越大,當初始有200個cluster時使用1個GPU比CPU獲得6.1的加速比,而使用2個GPU時與使用1個GPU獲得1.85的加速比,實驗中繼續增加cluster時,獲得的加速比并沒有繼續增加。

圖8 使用不同設備時程序運行的時間
實驗中計算得到了許多參數,如均值、協方差等,表1中的系數π實際上是每個component被選中的概率,并不指代圓周率,實驗中運行的GMM程序會得到三個系數;CPU列是使用CPU計算出來的系數π的值,GPU列是使用GPU計算出來的系數π的值。可以看出,對于同樣的輸入數據集,對于不同的初始cluster,使用GPU計算得到的系數與使用CPU計算的到的系數有些許的誤差,這是由于實驗中使用的GPU與CPU處理浮點數據的精度不同以及小數的舍入導致的,并不是虛擬化平臺影響了程序的正確性。
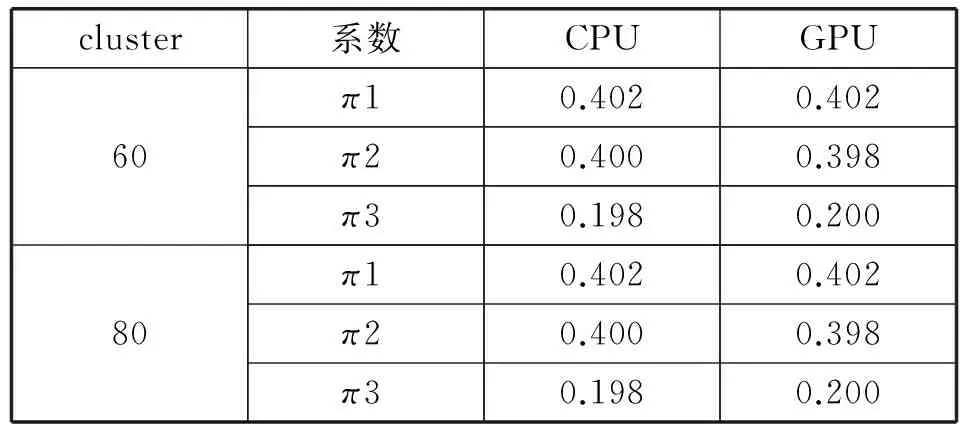
表1 不同平臺上執行得到的compunent的系數

續表1
以上可知,虛擬化平臺可以保證程序正確性的情況下,獲得比使用CPU時更好的性能,只使用兩個GPU時,就可以獲得十倍的加速比;GPU的數目增加時可以獲得更大的加速比,但是還未達到線性的加速比。這是因為在有多個GPU時會涉及更多的數據交換和參數控制,網絡傳輸的延時也會增加,新增加的軟件棧也會影響效率,這些是虛擬化所無法避免的開銷。
4.3 實驗結論
基于虛擬化的多GPU通用計算平臺上,原來基于單機多GPU實現的GMM程序不需要修改源代碼就可以運行在沒有NVIDIA顯卡的前端節點上。通過調用兩個遠程GPU就能夠獲得比使用CPU時十倍以上的加速比,并且只需要修改一些配置文件就可以方便地增減所使用的GPU數目,十分靈活。雖然虛擬化帶來了一定的性能損失,但是可以有效地實現單機多GPU和多機多GPU的編程模式統一。
5 結 語
實現了基于虛擬化的多GPU通用計算平臺,可以十分方便地使用遠程GPU進行通用計算。能夠使用分布式環境中不同節點上的多個GPU加速程序,且不需要對源碼做太多的修改。最后在實驗中驗證了該平臺的有效性。
實驗中發現網絡性能對于平臺的性能有很大的影響,如果使用高速網絡如InfiniBand將會提高虛擬化平臺的性能,此外,還有GPU RMDA技術,多GPU使用時的P2P問題等能夠提升性能的技術可以應用到虛擬化平臺上。
[1] Duato J,Pena A J,Silla F,et al.rCUDA:Reducing the number of GPU-based accelerators in high performance clusters[C]//High Performance Computing and Simulation (HPCS),2010 International Conference on.IEEE,2010:224-231.
[2] Shi L,Chen H,Sun J,et al.vCUDA:GPU-accelerated high-performance computing in virtual machines[J].IEEE Transactions on Computers,2012,61(6):804-816.
[3] 石林.GPU通用計算虛擬化方法研究[D].湖南大學,2012.
[4] Giunta G,Montella R,Agrillo G,et al.A GPGPU transparent virtualization component for high performance computing clouds[C]//European Conference on Parallel Processing.Springer Berlin Heidelberg,2010:379-391.
[5] Gupta V,Gavrilovska A,Schwan K,et al.GViM:GPU-accelerated virtual machines[C]//Proceedings of the 3rd ACM Workshop on System-level Virtualization for High Performance Computing.ACM,2009:17-24.
[6] 仝伯兵,楊昕吉,謝振平,等.GPU虛擬化技術及應用研究[J].軟件導刊,2015,14(6):153-156.
[7] Suzuki Y,Kato S,Yamada H,et al.GPUvm: why not virtualizing GPUs at the hypervisor?[C]//Usenix Conference on Usenix Technical Conference.USENIX Association,2014:109-120.
[8] Liu M,Li T,Jia N,et al.Understanding the virtualization “Tax” of scale-out pass-through GPUs in GaaS clouds:An empirical study[C]//IEEE,International Symposium on High PERFORMANCE Computer Architecture.IEEE,2015:259-270.
[9] 楊經緯,馬凱,龍翔.面向集群環境的虛擬化GPU計算平臺簡[J].北京航空航天大學學報,2016,42(11):2340-2348.
[10] Bouman C A,Shapiro M,Ncsa,et al.Cluster:An unsupervised algorithm for modeling Gaussian mixtures[J].Soft Manual,2005.
[11] Castelló A,Duato J,Mayo R,et al.On the use of remote GPUs and low-power processors for the acceleration of scientific applications[C]//The Fourth International Conference on Smart Grids,Green Communications and IT Energy-aware Technologies (ENERGY),2014:57-62.
[12] Sourouri M,Gillberg T,Baden S B,et al.Effective multi-GPU communication using multiple CUDA streams and threads[C]//2014 USENIX Annual Technical Conference Parallel and Distributed Systems (ICPADS).IEEE,2014:981-986.
[13] Gottschlag M,Hillenbrand M,Kehne J,et al.LoGV:Low-Overhead GPGPU Virtualization[C]//IEEE,International Conference on High PERFORMANCE Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing.IEEE,2014:1721-1726.
[14] Yang C T,Liu J C,Wang H Y,et al.Implementation of GPU virtualization using PCI pass-through mechanism[J].The Journal of Supercomputing,2014,68(1):183-213.
[15] 張玉潔.基于多GPGPU并行計算的虛擬化技術研究[D].南京航空航天大學,2015.
[16] 閔芳,張志先,張玉潔.虛擬化環境下多GPU并行計算研究[J].微電子學與計算機,2016,33(3):69-75.
[17] 張玉潔,呂相文,張云洲.GPU虛擬化環境下的數據通信策略研究[J].計算機技術與發展,2015,25(8):24-28.
[18] 張云洲.虛擬化環境下的GPU通用計算關鍵技術研究[D].南京航空航天大學,2014.
[19] 王剛,唐杰,武港山.基于多GPU集群的編程框架[J].計算機技術與發展,2014,24(1):9-13.
[20] 陳志佳,朱元昌,邸彥強,等.一種改進的GPU虛擬化實施方法[J].計算機工程與科學,2015,37(5):901-906.
RESEARCHOFPARALLELCOMPUTINGPLATFORMOFMULTI-GPUBASEDONVIRTUALENVIRONMENT
Xu Heng1,3Wu Junmin2,3Yang Zhigang2Yin Yan2
1(SchoolofSoftware,UniversityofScienceandTechnologyofChina,Hefei230027,Anhui,China)2(SchoolofComputerScienceandTechnology,UniversityofScienceandTechnologyofChina,Hefei230027,Anhui,China)3(SuzhouInstituteforAdvancedStudy,UniversityofScienceandTechnologyofChina,Suzhou215123,Jiangsu,China)
Aiming at the distributed multi-node and multi-GPUs system environment, a general computing virtualization platform of multi-GPUs based on CUDA framework is implemented. The application program can use the remote GPUs in the same way as the local GPUs. The original CUDA application program can be run on the virtual platform of GPUs without modification or with only a few changes, in order to achieve unity in the programming model of single multi-GPUs and multi-machine multi-GPUs. In the end, we verify the correctness of the experiment through a Gaussian mixture model for data classification by CUDA. The experiment shows that the result of a program using two remote GPUs can get about ten times faster than using the original CPU without affecting the correctness.
Virtualization GPU Multi-machine and multi-GPU Distributed
2017-01-04。國家重點研發計劃項目(2016YFB1000403)。徐恒,碩士生,主研領域:GPU通用計算,虛擬化。吳俊敏,副教授。楊志剛,碩士生。尹燕,博士生。
TP3
A
10.3969/j.issn.1000-386x.2017.11.014
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中國衛生(2015年3期)2015-11-19 02:53:32
