基于網絡分割聚類的標簽語義規范化推薦算法
2017-12-08 03:23:56葉婷曹杰
計算機應用與軟件 2017年11期
葉 婷 曹 杰
(南京財經大學信息工程學院 江蘇 南京 210046)
基于網絡分割聚類的標簽語義規范化推薦算法
葉 婷 曹 杰
(南京財經大學信息工程學院 江蘇 南京 210046)
傳統的推薦算法多以用戶評分數據計算用戶的興趣偏好以及資源相似度,對稀疏數據以及新用戶的推薦質量較低。考慮到用戶標簽數據的隨意性和語義模糊性,提出基于標簽網絡分割聚類的語義規范化方法并建立基于規范化標簽的用戶興趣模型。該模型能在不改變用戶興趣的前提下有效降低用戶標簽興趣模型的向量維數,并能避免分析標簽語義的復雜過程,且能根據用戶自身的理解來獲取用戶興趣。最后將標簽興趣模型應用到推薦算法中。通過與經典的推薦算法進行比較,驗證了該算法能有效緩解數據稀疏性、推薦冷啟動問題,提升了推薦結果的準確性,能獲得更好的推薦效果。
標簽 語義規范化 推薦算法
0 引 言
隨著計算機科技的迅猛發展,社會的進步已經離不開信息網絡,人們獲取信息的方式以及溝通交流的方式也在不斷增多,互聯網已經極大地改變了人們的生活。然而,網絡中充斥著復雜多樣的信息,人們享受著足不出戶便可以搜索豐富網絡資源的同時,也不得不忍受“信息過載”帶來的生活上的不便。傳統的搜索引擎技術已經不能滿足用戶的搜索需要,因此個性化推薦技術孕育而生。個性化推薦系統可以挖掘分析用戶的歷史行為數據,并構建用戶的興趣模型從而智能地從海量信息資源中篩選出用戶需要的資源推薦給用戶,從而很好地緩解了信息過載問題[1]。然而,推薦系統自身也存在一些弊端,主要表現為系統的數據稀疏性問題、冷啟動問題等,這些缺陷會一定程度上影響推薦的效率以及準確率。
在個性化推薦系統中靈活地利用用戶自定義標簽的特性,使推薦系統的研究迎來了一個嶄新的時代。因為標簽系統的標簽是由用戶自主標注的,所以標簽不僅包含資源的特征屬性,還可以反映出用戶的興趣和認知偏好等信息。同時,利用標簽信息進行用戶的興趣模型的構建,可以提高用戶興趣模型的貼切度與準確度。其次,通過分析標簽的語義信息可以挖掘出用戶對于資源的喜好,以方便找到與目標用戶有相似喜好的用戶集群,從而可以更加精確地推薦其感興趣的項目集合給該用戶。然而隨著標簽應用越來越廣泛,標簽中出現的弊端也越來越明顯,由于標簽的自主性,存在標簽的語義表達概念模糊,并且不同用戶認知也存在差異,這導致其表達的語義不準確,同時用戶可能在輸入標簽時不夠嚴謹,也導致大量噪聲標簽的存在。目前,不少學者都進行了相關的學術研究。Wei等[2]通過用戶標注在資源上的標簽信息構建用戶的偏好主題模型,并結合用戶的評分信息以增強推薦效果。Martins等[3]利用正面和負面用戶反饋迭代選擇輸入標簽并結合遺傳算法策略來學習推薦函數,從而有效地解決冷啟動問題。Gan等[4]提出構建對象-用戶-標簽異構網絡,并采用隨機游走算法與重啟模型以將關聯的強度分配給候選對象,從而提供用戶優先查詢對象以加強推薦。Cao等[5]融合混合型協同過濾算法提出Web服務的雙向推薦機制,該機制既可以為用戶推薦感興趣的Web服務,也可以為服務者提供潛在用戶。Kim等[6]結合用戶的評分信息將資源分為積極項目和消極項目,分別計算用戶的興趣模型。Xu等[7]提出SemRec系統,利用層次式聚類方法將經常共同出現的標簽放在同一類簇并結合其語義信息以進一步增強推薦性能。Xie等[8]通過標簽向量來表示用戶和資源,然后求用戶和資源的相似性匹配度再進行相關性推薦。
由于用戶標簽數據的稀疏性、異構性等特點,推薦算法的正確率往往不盡如人意。以上研究大多只是考慮標簽的頻數信息而沒有很好地利用標簽豐富的語義信息來豐富個性化模型。為此,本文提出基于網絡分割聚類的標簽語義規范化方法,用語義明確且能較好地表達一類資源主題的規范化標簽替代用戶的隨意標簽,構建個性化推薦的用戶規范化標簽興趣數據模型并應用到推薦算法中。
1 基于外部詞庫的標簽語義關聯構建
用戶自定義標簽具有很強的自主性和無約束性,且網絡中標簽數據的稀疏性使其不能很好地被利用到推薦系統中。由于網絡中的標簽繁雜多維化,想要充分利用標簽所表達的豐富的語義信息,就需要借助外部詞庫建立標簽之間的語義關聯。因此提出了基于英文維基百科的外部詞庫構建標簽的語義關聯,利用標簽的語義特征為后面的研究做好準備工作。
1.1 Word2vec的語義模型訓練
Word2vec是Google于2013年新開發的一款基于深度學習的工具[9]。它基于特定的語料庫,利用優化后的訓練模型得到詞語的包含了自然語言中的語義和語法關系的向量表達形式,為自然語言的研究開辟了一個新的領域。在向量空間模型中,做兩個向量的相似度(向量距離/夾角)運算,其中模型中向量的相似度即代表兩個詞之間語義的相似度,換句話說,就是兩個詞在同一個語義場景出現的概率,詞向量的算術運算則是計算機的“命辭遣意”。詞向量是詞性特征常用的表達方式,因為它具有豐富的語義信息。詞向量共400維,單位維上的值表示包含特定的語法和語義上表述的特性。本部分采取分布式的表現形式,它是一個低維的、稠密的實值向量。其中每一維表現了單詞的一個潛在詞性特征,該特性蘊含了豐富的語義和句法特征信息。
通過離線深度學習訓練,形成知識庫,支持數據分析功能的詞之間的相似度計算。本部分采用英文的維基百科數據作為訓練模型的源數據,維基百科是目前知識庫增長速度最快且規模最大的百科全書,有250萬多篇的文章和不計其數的投稿人,其數目龐大的網絡入口、互相參考的網絡以及以樹為主體的圖結構層次的分類能提供豐富的精確定義的語義知識[10]。
1.2 基于維基百科的標簽語義關聯的構建
在眾分眾類的標注系統中, 用戶標注行為較為自由,通常表示相同意思但標注的標簽往往是同一詞根的不同演變形式,包括英文標簽的單復數、大小寫、時態等各種問題。為了減小標簽構建Word2vec的計算復雜度,本文對英文標簽首先進行兩步預處理縮減一定的標簽:對非英文字符以及大寫字母等進行剔除或替換,并利用詞根提取算法處理單復數并提取詞根,最后進行比較以及合并重復標簽。
本文基于外部詞庫訓練語義模型,形成結構化的語義詞典,對于任意輸入的英文標簽可以給出其語義訓練模型中的詞向量表示。其中,詞與詞之間的相似度可以表示為兩個詞對應的Word2vec的語義空間上的距離,極大地簡化了詞與詞之間相似度的計算,以構成標簽的語義關聯。
2 基于網絡分割的標簽語義規范化推薦算法
社會標簽系統中用戶自定義標簽可以根據自己的認知和理解隨意進行標簽標注,具有很強的無約束性和自由性,標簽自身真正的含義不一定能精確表達用戶真正的意圖,因此標簽存在語義模糊、歧義性以及標簽濫用等較嚴重的語義問題。針對標簽存在的語義問題,本文提出一種基于加權網絡分割的標簽聚類規范化方法,即用戶產生的繁雜隨意標簽用與其相似且核心度高的規范化標簽代替,在不改變用戶本身興趣愛好的前提下以期得到更加精確的用戶興趣模型。本文首先構建基于融合相似度的標簽共現網絡,并提出了衡量標簽節點核心程度的計算方法。該聚類算法基于標簽節點的核心度,并結合標簽融合相似度來進行網絡分割,將與核心節點相似的節點劃分成一個子網,同時該類簇的聚類中心即可理解為該類簇的核心節點。首先定義如下三個概念以便于后面的研究:
定義1基于融合相似度的標簽共現網絡定義為一個加權網絡G=
定義2標注矩陣定義為m×n矩陣A=(Aij),其中Aij表示標簽i和在資源j上標注的次數,即標簽頻度。
定義3關聯度矩陣定義為m×n矩陣B=(Bij)其中Bij表示標簽i與資源j的關聯程度,其關聯程度的計算借鑒TF-IDF思想并進行改進,可以記為TagBasedTFIDF:
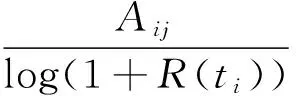
(1)
其中:R(ti)表示標簽ti標注的資源總數。
2.1 標簽相似度計算
定義4規范化標簽定義為用戶公眾認可的由用戶產生的表達概念明確的標簽,各規范化標簽之間的相似度為0或可以忽略不計。將用戶定義的標簽用語義規范化的標簽數據表示,其能夠有效地緩解標簽表達概念不精確、語義模糊等問題。標簽相似度計算由下列屬性確定。
(1) 標簽資源共現相似度:標簽a和標簽a′的資源共現相似度定義如下:
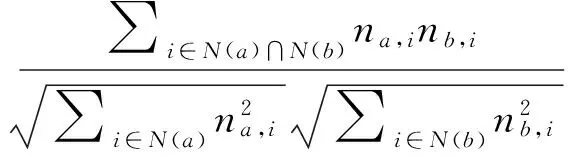
(2)
其中:對于標簽a,令N(a)為有標簽a的物品集合,na,i為物品i打上標簽a的用戶數,本文通過如上余弦現相似度公式計算標簽a和標簽b的資源共現相似度:
(2) 標簽詞向量語義相似度:標簽a和標簽b′的語義相似度即它們對應Word2vec的余弦相似度。定義如下:
(3)
(3) 標簽融合相似度:
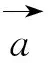
(4)
其中:λ為調節權重。線性融合標簽關于用戶數據的資源共現相似度和關于標簽的詞向量語義相似度,得出用戶數據中標簽與標簽之間的融合相似度,作為聚類的相似度計算公式。
2.2 標簽核心度計算
標簽的核心度用來衡量該標簽在標簽網絡中的核心程度,主要由標簽融合相似度、標簽主題度綜合計算。
定義5標簽主題度用于衡量一個標簽能否很好地表現一類資源主題。如果該標簽所表示的資源都較為相似則可以認為這個標簽能夠較好地表示一個資源主題。我們用Ct表示被標簽t標注的資源均值中心,由式(5)計算。其中R(t)表示標簽t所表示的資源總數,資源ri由關聯度矩陣B中的列向量表示。
(5)
標簽的主題度由標簽標注的資源中心Ct與該標簽標注的所有資源之間的平均余弦相似度計算:
(6)
標簽的核心度計算公式如下:
(7)
其中:t′表示標簽共現網絡圖中與標簽t相連接的標簽。
2.3 算法流程
基于網絡分割聚類的標簽規范化推薦算法:
輸入:用戶—規范化標簽—資源數據{U,T,I},聚類數目K,推薦資源個數N。
輸出:目標用戶u的Top-N推薦集。
第1步計算標簽之間的融合相似度,構建基于融合相似度的資源共現標簽網絡。并計算標簽網絡中每個標簽節點v的核心度。
第2步將節點按核心度降序的順序插入鏈表L。
第3步取出鏈表首節點即核心度最高的標簽節點,并在標簽網絡中逐個判斷其鄰接節點的相似度是否大于該鄰接節點與其任何節點的相似度,如果是則將該點與首節點劃為一個類簇,并把該節點從鏈表中刪去。
第4步得到類簇以首節點為核心的規范化標簽,并從L中刪除。
第5步重復第3步、第4步,直到鏈表L為空或聚類數目達到K,停止聚類。
第6步得到各個類簇的聚類中心即規范化標簽,以及用戶的自定義標簽集合,將用戶自定義標簽替換成其所在類簇的聚類中心(規范化標簽),形成新的用戶—規范化標簽—資源數據{U,Ts,I}。
第7步計算標簽基于TF-IDF的權重構建用戶的興趣模型并應用到協同過濾的推薦算法。取前N個資源組成Top-N推薦集合recommend-list={i1,i2,…,iN}并輸出。算法的偽代碼見算法1。
算法1基于網絡分割的標簽聚類規范化的推薦算法
輸入:用戶-規范化標簽-資源數據Q={U,T,I},聚類數目K,推薦資源個數N
輸出:目標用戶u的Top-N推薦集recommend-list
1:creat the resource co-occurrence label network based on fusion similarity
2:for each vertexv∈Vdo
3: computeCore(v)
4: end for
5: insert allCore(v) by ascending order into ListL
6: while (Lis not empty or number of clusters!=K)
7: select the first vertexviinL
8: for each adjacent edgevjofvido
9: ifeij> each adjacent edge ofvjofvido
10: assignvjto the cluster withvi
11: deletevjfromL
12: end if
13: end for
14: deletevifromL
15: obtain a cluster with label=vi16: end while
17:Transfor the User tags to the normalized tagsvi
18: for all useruinQdo
19: use TF-IDF compute the weight
20: produce the user intrest model
21: find the KNN neighbors
22: take the top-N item
23: end for
23:outputrecommend-list={i1,i2,…,iN}
2.4 標簽規范化結果展示
在MovieLens數據集中,通過網絡分割聚類的標簽規范化方法,將數據集中用戶自定義標簽與規范化標簽形成關聯。 經過網絡分割聚類的規范化標簽及與其聚類為一個類簇即相映射的自定義標簽數據部分展示如下,并根據這些自定義標簽與其對應的規范化標簽之間的融合相似度按大到小的順序排列,實驗結果見表1。
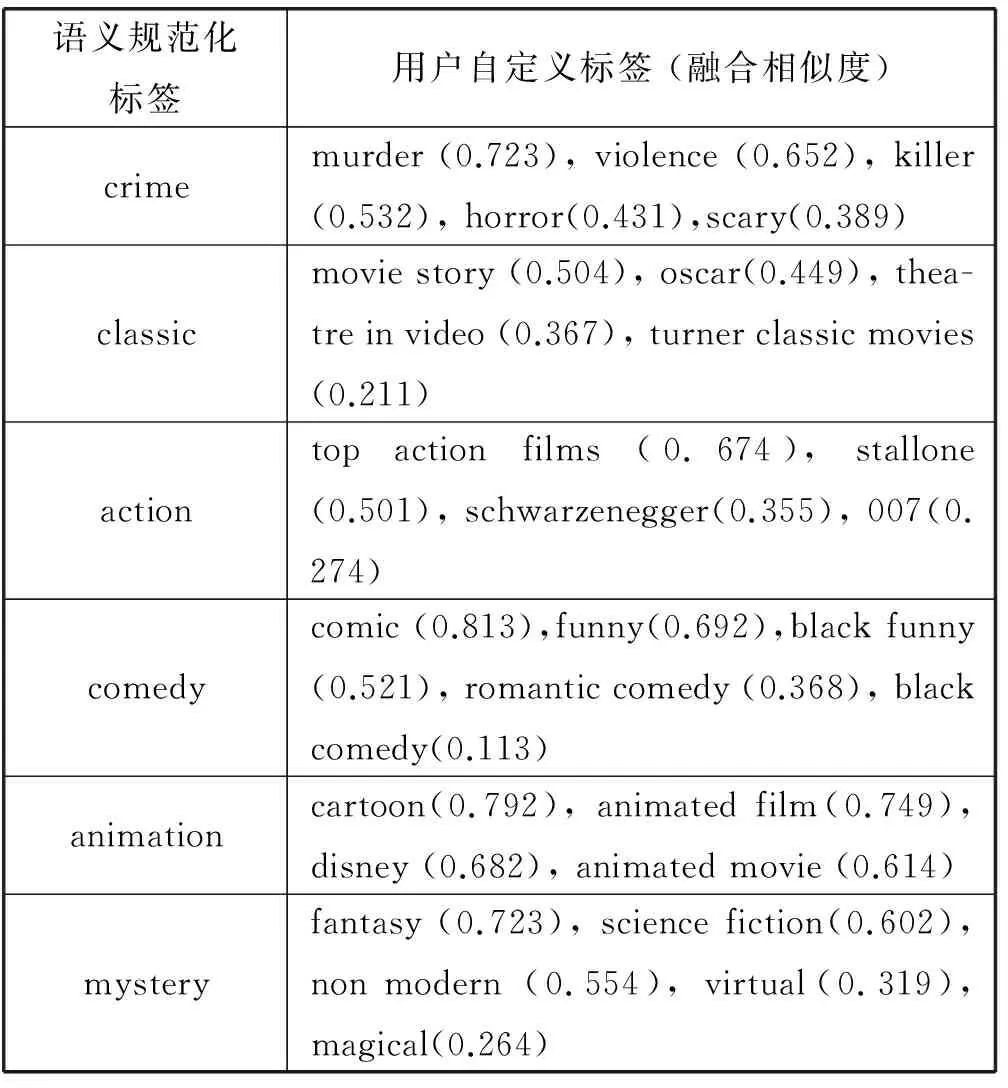
表1 語義規范化標簽與用戶自定義標簽
3 規范化標簽的應用與實驗結果分析
3.1 數據集
為了驗證本文算法的有效性,本文采用MovieLens和Delicious兩組數據集[11],具體數據集集合見表2。本實驗將語義規范化的標簽并結合TF-IDF算法實驗采用5折交叉驗證,每次將數據集隨機選取80%數據為訓練集,剩余20%數據為測試集,對五次結果取平均作為最終結果。
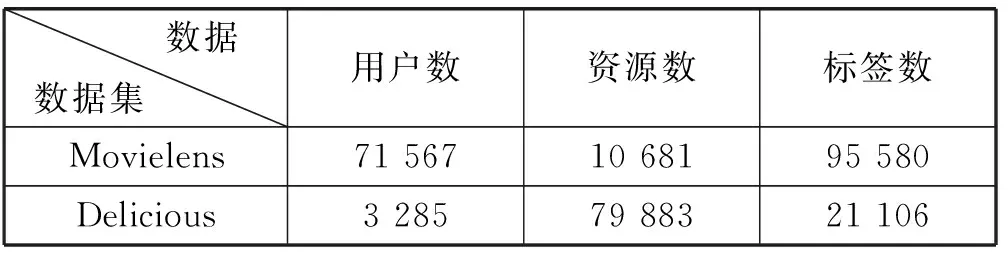
表2 數據集結構
3.2 度量標準
本文實驗中采用準確率(Precision)、召回率(Recall)、F-measure作為度量算法優劣的評價標準;準確率表示為用戶產生的推薦列表中,有多大比例的資源是用戶真正喜歡的,如式(8)表示;召回率表示用戶真正喜歡的商品中,有多大比例的商品進入了推薦列表,如式(9)表示,準確率和召回率越高,表示推薦效果越好[12];同時還使用了一個平衡以上兩種指標的綜合評價指標F-measure,如式(10)表示。設R(u)指用戶在訓練集上通過分析用戶行為得到的推薦列表,T(u)表示用戶在測試集中的行為列表。則推薦結果的準確率定義如下:
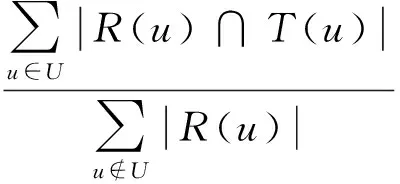
(8)
推薦結果的召回率定義如下:
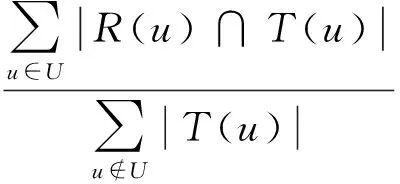
(9)
F-measure定義為:
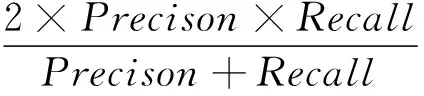
(10)
3.3 實驗結果
本文將基于網絡分割聚類的標簽規范化后的標簽應用推薦算法中,實驗試圖從兩個方面展開:一是分析在標簽規范化中融合相似計算的參數λ對推薦結果的影響,二是比較所提方法與其他推薦算法進行推薦效率與準確率的比較。
(1) 確定融合相似度參數λ對推薦質量的影響
本部分測試λ的值對推薦結果的影響,實驗設置λ的值為0到1,值變化的間隔為0.1,并設置鄰居數目分別為20、40、60、80,每組數據集上分別進行實驗,實驗中分別測試推薦結果的Precision。其結果如表3所示。
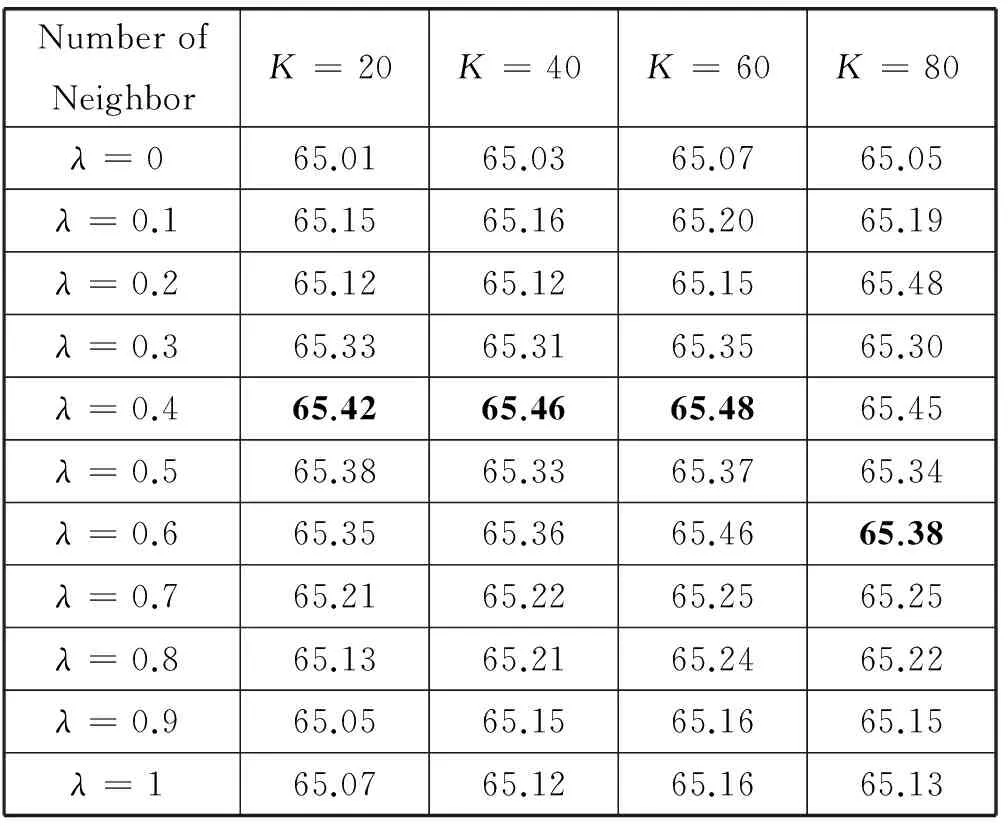
表3 不同參數λ值對Precision變化情況
從表3可以看出,參數λ值的變化確實可以影響推薦結果,但總體變化不大。其中當λ=0表示在標簽規范化過程中標簽相似度計算僅考慮計算標簽的資源共現相似度,而當λ=1表示僅考慮計算標簽的語義相似度,最終規范后的標簽應用到推薦算法的效率都不高,而融合相似度計算方法后推薦效果明顯好于單一的計算方法。表3中可獲知,當λ值不斷變化時,Precision值會有所變化,但當λ=0.4時,Precison值普遍最大。
(2) 算法推薦效果比較
為了進一步驗證本文標簽規范化推薦算法的有效性,將本文算法NT-CF與兩個較新的算法tensor-u[13]與colla-tv[14]和一個經典推薦算法T-CF[15]用Precision、Recall、F-measure三個度量標準驗證實驗,根據前面的實驗所知,設K=60,λ=0.4,隨著推薦列表的數量N值的變化,三個度量標準的值也會不同,并將N設置從5到25變化,值變化間隔為5。對比結果如圖1、圖2所示。通過在Movielens和Delicious兩個數據集上三個度量標準進行對比,可知本文的算法在準確率、召回率、F-measure三個度量標準都明顯好于其他推薦算法。
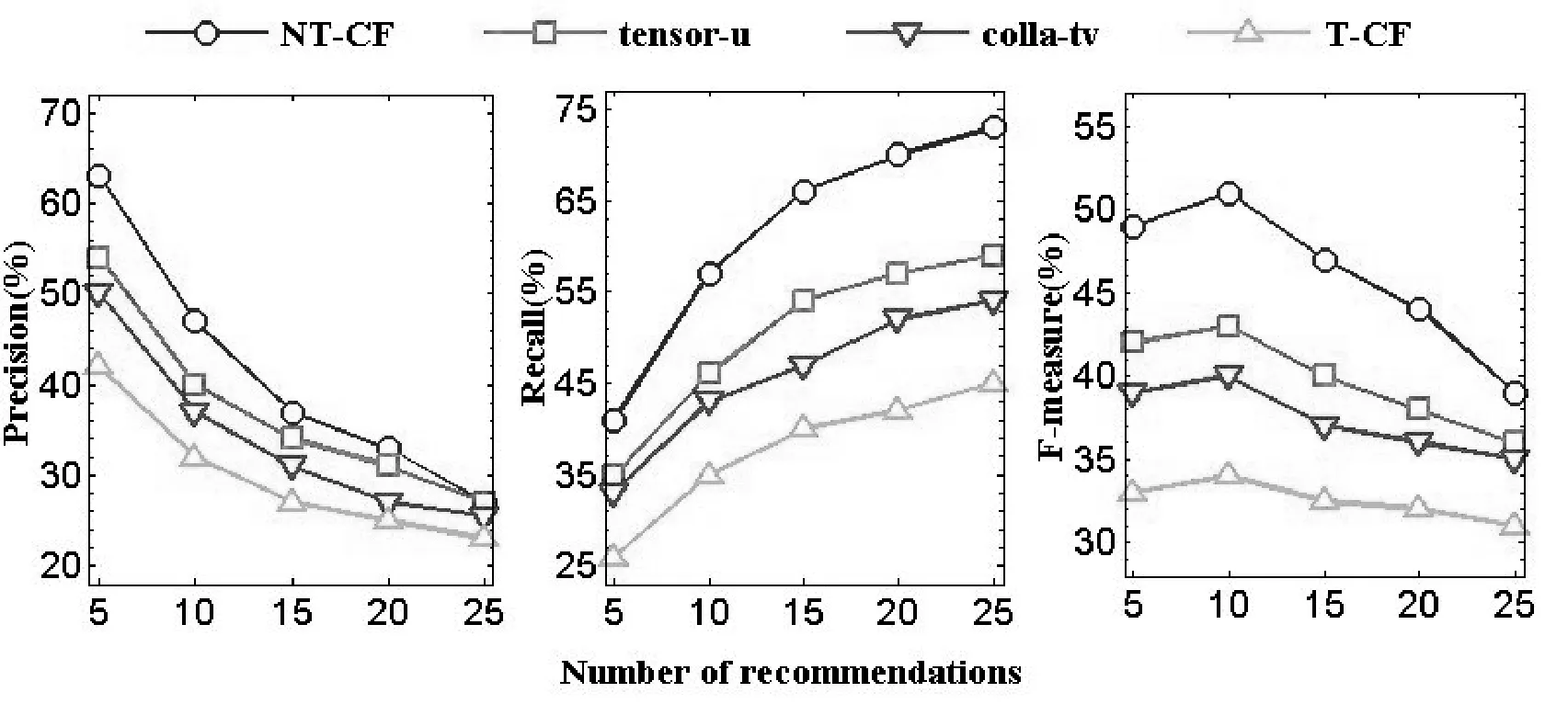
圖1 Movielens數據集結果對比
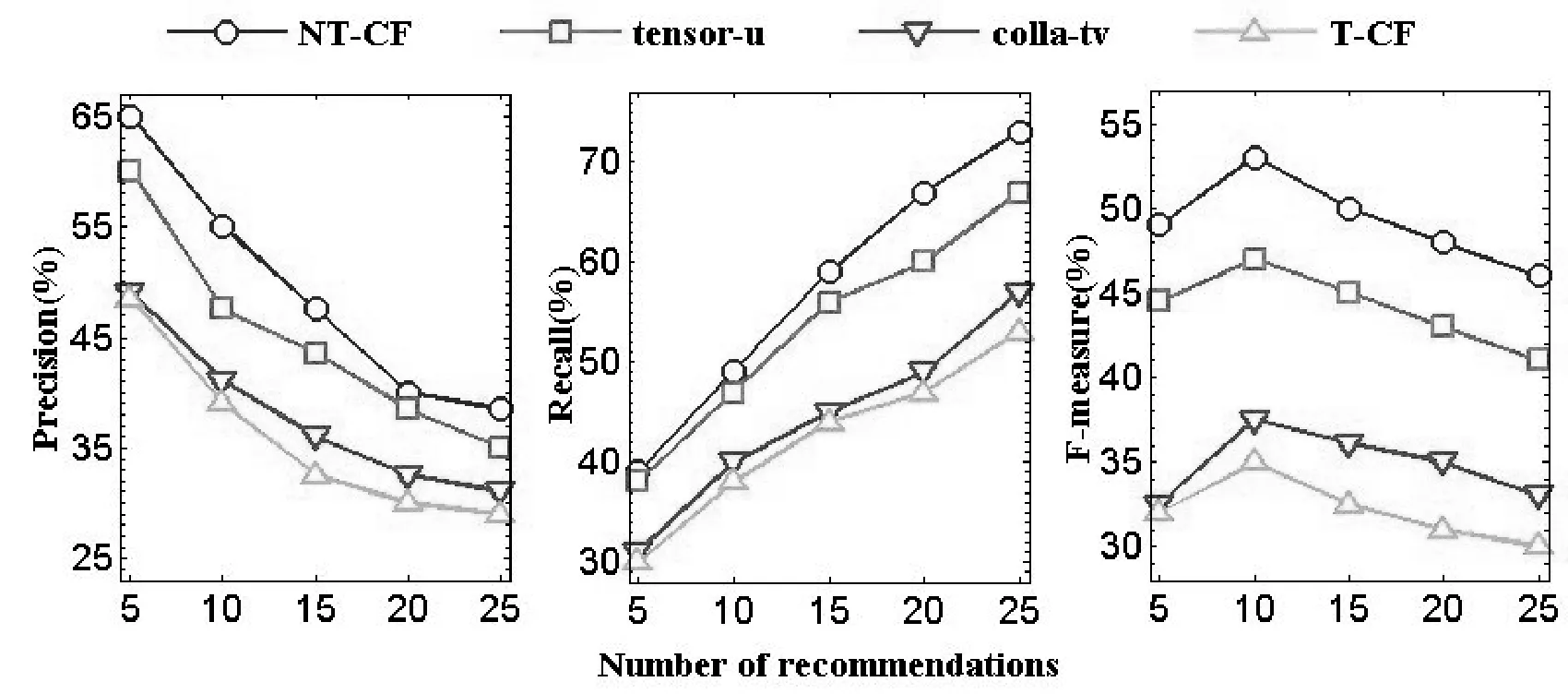
圖2 Delicious數據集結果對比
4 結 語
鑒于目前所有的數據集和具體任務的需求,本文圍繞“基于網絡分割聚類的標簽語義規范化推薦算法”問題,首先引入英文維基百科詞庫訓練Word2vec語義模型,以便于構建標簽之間的語義關聯,計算獨立標簽之間的語義相似度;繼而分析用戶標注行為數據,構建基于融合相似度的標簽共現網絡,實現基于節點核心度和相似性的加權網絡分割聚類算法。將用戶的自定義標簽用能表示所在類簇的特征標簽即規范化標簽代替并構建用戶興趣模型,在不改變用戶的前提下一定程度上減少向量維數簡化計算,并將規范化標簽構建用戶興趣模型并應用到協同過濾算法中。與已有的基于標簽的推薦算法在三個度量標準上進行對比,從而驗證了本文算法的有效性。
[1] Verma C,Hart M,Bhatkar S,et al.Improving Scalability of Personalized Recommendation Systems for Enterprise Knowledge Workers[J].IEEE Access,2016,4:204-215.
[2] Wei S,Zheng X,Chen D,et al.A hybrid approach for movie recommendation via tags and ratings[J].Electronic Commerce Research and Applications,2016,18:83-94.
[3] Martins E F,Belém F M,Jussara M.On cold start for associative tag recommendation[J].JASIST,2016,67(1):83-105.
[4] Gan M,Sun L,Jiang R.Trinity:walking on a user-object-tag heterogeneous network for personalised recommendations[J].Journal of Computer Science and Technology,2016,31(3):577-594.
[5] Cao J,Wu Z,Wang Y,et al.Hybrid Collaborative Filtering algorithm for bidirectional Web sevice recommendation[J].Knowledge and Information Systems,2013,36(3):607-627.
[6] Kim H N,Alkhaldi A.Collaborative user modeling with user-generated tags for social recommender systems[J].Expert Systems with Applications,2013,2(32):564-572.
[7] Xu G,GuY,Dolog P,et al.SemRec:A Semantic Enhancement Framework for Tag Based Recommendation[C]//Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence.SanFrancisco,California:AAAI Press,2015:321-330.
[8] Xie H,Li X,Wang T,et al.Incorporating sentiment into tag-based user profiles and resource profiles for personalized search in folksonomy[J].Information Processing & Management,2016,52(1):61-72.
[9] Servan C,Berard A,Elloumi Z,et al.Word2vec vs DBnary:Augmenting meteor using vector representations or lexical resources?[C]//Proceedings of COLING 2016,the 26th International Conference on Computational Linguistics,2016:1159-1168.
[10] Flati T,Vannella D,Pasini T,et al.MultiWiBi:The multilingual Wikipedia bitaxonomy project[J].Artificial Intelligence,2016,241(12):66-102.
[11] Yilmaz R M,Baydas O.Pre-service teachers’ behavioral intention to make educational animated movies and their experiences[J].Computers in Human Behavior,2016,63(12):41-49.
[12] Chen J,Li K,Tang K.A parallel patient treatment time prediction algorithm and its applications in hospital queuing-recommendation in a big data environment[J].IEEE Access,2016,4:1767-1783.
[13] Zhang S,Ge Y.Personalized tag recommendation based on transfer matrix and collaborative filtering[J].Journal of Computer and Communications,2015,3:9-17.
[14] Peng J,Zeng D.Collaborative filtering in social tagging systems based on joint item-tag recommendations[C]//Proceedings of the 19th ACM international conference on Information and knowledge management,2014:809-818.
[15] Tso-Sutter K H L,Marinho L B,Schmidt-Thieme L.Tag-aware recommender systems by fusion of collaborative filtering algorithms[C]//Proceedings of the 2010ACM Symposium on Applied Computing.NewYork:ACM press,2010:1995-1999.
ARECOMMENDATIONALGORITHMWITHTAGSSEMANTICNORMALIZATIONBASEDONNETWORKSEGMENTATIONCLUSTERING
Ye Ting Cao Jie
(CollegeofInformationandEngineering,NanjingUniversityofFinanceandEconomics,Nanjing210046,Jiangsu,China)
The traditional recommendation algorithm mostly uses the user rating data to calculate the user’s interest preference and the resource similarity, and the recommendation quality to the sparse data as well as the new user is low. Considering the randomness and semantic ambiguity of user label data, a semantic normalization method based on label network segmentation clustering is proposed and a user interest model based on canonical label is established. The model can effectively reduce the vector dimension of the user’s tag interest model without changing the user’s interest. It can avoid the complicated process of tag semantics and obtain user interest according to the user’s own understanding. Moreover, the label interest model has applied to the recommendation algorithm. Compared with the classical recommendation algorithm, it is verified that the algorithm can effectively alleviate the sparsity of data and recommend the cold start problem. It can improve the accuracy of the recommended results, and obtain better recommendation results.
Tag Semantic normalization Recommendation algorithm
2017-01-16。葉婷,碩士,主研領域:數據挖掘,推薦系統。曹杰,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.11.012
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
商周刊(2017年23期)2017-11-24 03:24:09
資源再生(2017年3期)2017-06-01 12:20:59
現代語文(2016年21期)2016-05-25 13:13:44
中國衛生產業(2015年10期)2015-03-11 18:58:41
中國當代醫藥(2015年9期)2015-03-01 02:02:15
大連民族大學學報(2015年2期)2015-02-27 08:28:11
