基于互信息最大化正則的生成式對抗網絡
2017-10-18 03:44:31浦煜王曉峰
現代計算機 2017年26期
關鍵詞:模型
浦煜,王曉峰
(上海海事大學信息工程學院,上海 201306)
基于互信息最大化正則的生成式對抗網絡
浦煜,王曉峰
(上海海事大學信息工程學院,上海 201306)
目前生成式對抗網絡(GAN)面臨的一大難點是模型訓練過程中普遍存在著不收斂性,其最為突出的表現即“模式坍塌”現象,從而導致生成的目標對象缺乏多樣性。首先從信息論角度簡要解釋原始GAN的理論方法,在此基礎之上,提出一種基于互信息最大化的正則方法,通過最大化隨機噪聲變量和生成樣本之間的互信息,為生成網絡的目標函數提供一個上界函數,迫使生成的數據分布更加趨于真實數據分布。對MNIST手寫字符數據進行的實驗結果表明,引入互信息正則,有助于提升生成樣本的多樣性。
生成式對抗網絡;模式坍塌;多樣性;互信息;上界函數
0 引言
近些年來,隨著深度學習技術的發展,無監督學習作為機器學習的一大分支也進步斐然。盡管在大部分情況下,有監督學習比無監督學習能獲得更好的效果,但是在實際應用中,有標注的數據是相對較少的,因此,如何從海量的無標注數據中抽取高階的數據表征是人工智能領域的核心問題。最近,以生成式對抗網絡[1](Generative Adversarial Nets,GAN)為代表的深度生成模型為解決這一問題提供了新的計算框架。
生成式對抗網絡的思想啟發自博弈論中的零和博弈(zero-sum game),博弈雙方分別由生成式模型G(generative model)和判別式模型 D(discriminative mod?el)充當。G通過將輸入的隨機噪聲映射為新的樣本數據,來捕捉真實訓練樣本的概率分布;而D本質上是一個二分類器,用于判別輸入的樣本數據是采樣自訓練集還是生成的樣本集,通過交替訓練D和G的參數化網絡,兩個模型都會得到提升,最終生成的數據分布會收斂于真實數據分布。目前,GAN已經在多項任務中展現了它們的潛力,如圖像生成[2-4],超分辨率圖像重建[5],3D對象生成[6]和視頻預測[7]等應用。
與傳統的生成模型[8-10]相比,GAN不需要真實數據的先驗知識和復雜的建模過程,具有明顯的優勢,但是它過于自由的訓練方式帶來的缺點也很明顯,例如訓練過程不穩定,對于參數極其敏感。除此之外最為突出的問題即“模式坍塌(mode collapse)”現象:生成的數據分布無法去擬合真實分布的完整流形[11,12](僅僅生成了“子流形”)導致樣本集中在少數幾個模態上。為了穩定GAN的訓練過程,國內外的研究者提出了一系列改進方法。在理論框架層面,Mirza和Osindero[13]等人通過引入一個數據標簽向量同時作為G和D的額外輸入,將純無監督學習變成半監督學習,明顯提升了訓練的穩定性,雖然改進方式較為直接,但效果顯著。Nowozin[14]等人從距離度量的角度出發提出并證明了GAN的優化目標可以泛化為某種f-divergence的最小化問題,為GAN的理論解釋提供了新的思路。最近,DJ Im[15]等人通過同時訓練多個GAN,讓它們的判別模型D交替去判別其他生成模型G產生的樣本,使得到的樣本不易丟失模態,但計算代價過于龐大。此外,在訓練技巧層面,Radford[2]等人基于深度卷積網絡提出了DCGAN模型,針對GAN這種不穩定的學習方式,作者引入了步長卷積,批規范化等技術,使得訓練過程更加可控,這一工程性的突破也讓DCGAN成為后續研究者工作的基礎框架。Salimans[16]等人提出了特征匹配、單邊標簽平滑(One-sided Label Smoothing)和minibatch discrimination等一系列策略來提高模型的魯棒性,并且在半監督分類問題上取得較好的效果。
與以上工作不同的是,本文在Ferenc Huszár[17]和Yingzhen Li[18]等人的基礎上從信息論角度去闡述生成對抗網絡。生成模型G和鑒別模型D的相互競爭本質上可以看成標簽和樣本之間互信息的最小化,原始的目標函數只是最小化互信息的下界而非上界,因此我們在此基礎上再次引入一個互信息正則項,最小化其上界函數,實驗證明這種方法可以有效解決“模式坍塌”問題,生成更具多樣性的樣本。本文工作和Xi Chen[19]等人提出的InfoGAN相關,他們通過拆解GAN先驗的方式,對噪聲分布的隱變量加以約束,使其學習更加解構的
數據表示,從而生成的結果具有可解釋性,而本文更加注重生成樣本的多樣性,避免模態單一化。
1 GAN的形式化描述
原始GAN模型的基本框架如圖1所示,其主要目標是迫使判別模型D輔助生成模型G產生與真實數據分布相似的偽數據,其中G和D一般為非線性映射函數,通常由多層感知機或卷積神經網絡等網絡結構來形式化。給定隨機噪聲變量z服從簡單分布Pz(z)(常為均勻分布或高斯分布),生成模型G通過將z映射為G(z)隱式地定義了一個生成分布Pg來擬合真實樣本分布Pdata。判別模型D作為一個二分類器,分別以真實樣本x和生成樣本G(z)作為輸入,以一個標量值作為概率輸出,表示D對于當前輸入是真實數據還是生成的偽數據的置信度,以此來判斷G生成數據的好壞。當輸入為真實訓練樣本x∽pdata時,D(x)期望輸出高概率(判斷為真實樣本),當輸入為生成樣本G(z)時,D(G(z) )期望輸出低概率(判斷為生成樣本),而對于G來說要盡可能使D(G(z) )輸出高概率(誤判為真實樣本),讓D無法區分真實數據和生成數據。兩個模型交替訓練,從而形成競爭與對抗。整個優化過程可以視為一個極小極大博弈,表達式如下:
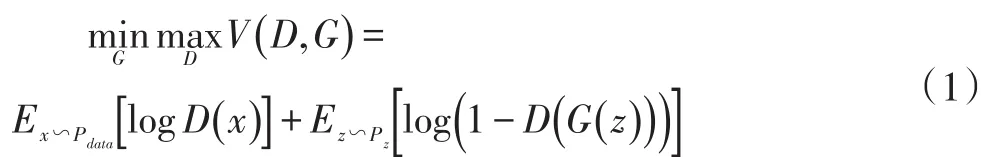
然而,在實際訓練過程中,(1)式中D(G(z))在初始時值很小,導致log(1 -D(G(z) ) )的梯度趨向于飽和狀態,所以為了避免梯度消失的情況,本文采用(2)式去優化G。

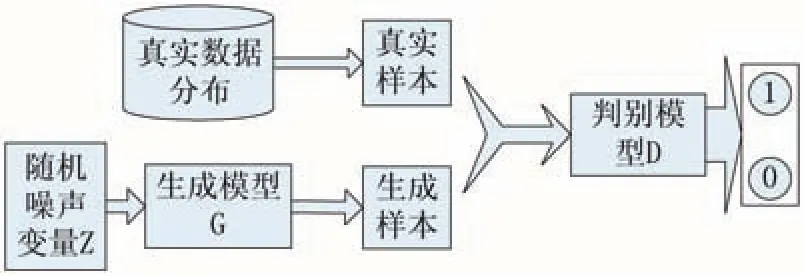
圖1 GAN模型結構圖
2 基于互信息最大化正則的GAN
2.1 GAN的信息論解釋
令s∈{0 ,1}表示樣本標簽,當s=1時,以真實樣本作為判別模型D的輸入,反之s=0時,以生成模型G生成的樣本作為D的輸入。用數學語言描述如(3)所示:
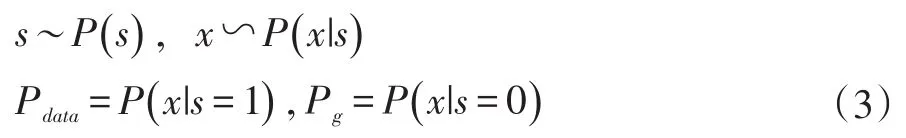
其中P(s)為s的先驗,由于取值的等可能性,服從參數為0.5的伯努利分布;x表示輸入的樣本。從第一節可知GAN的理想目標是使生成樣本的分布Pg與真實數據的分布Pdata相一致,即D判斷輸入樣本的真假與標簽信息s無關。在信息論中,互信息可以衡量兩個隨機變量之間的相關性。對于給定的兩個隨機變量X和Y,它們之間的互信息如(4)式所示:
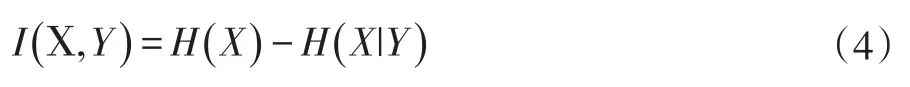
其中,H()表示隨機變量的熵值。當X和Y的相關性越強,它們之間的互信息就越大。為此可以通過最小化樣本標簽變量s和樣本變量x的互信息來消除其之間的相關性。由于P(x|s)是未知的,無法直接計算,根據變分推斷[20]的理論得到互信息的下界函數,具體推導如(5)所示:
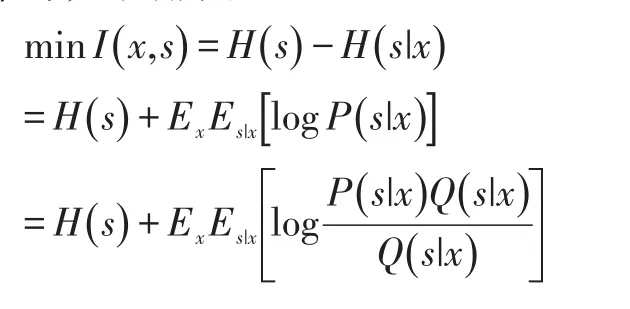

由此得到互信息I(x,s)的下界L(P,Q)。其中,Q(s|x)為引入的參數分布,可以視為對s后驗分布P(s|x)的近似,當兩者相一致時,kL距離為零,L(P,Q)取得最大值。進一步地,若將輔助分布Q(s|x)視為一個判別模型網絡,(5)式可以展開成(6)式:
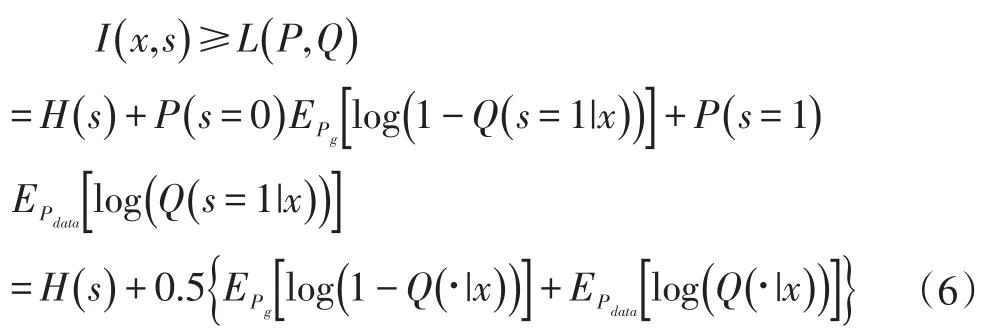
其中,由于s的分布已知,H(s)則為固定值。很明顯(6)式的第二項即是GAN最小化的目標函數(見(1)式)。換句話說,GAN實際上最小化的是互信息的下界函數而非互信息本身,顯然這會帶來一定偏差,因為相比下界最小化上界函數可以獲得更加緊的界,以至于模型能更好地收斂到穩定點。
2.2 引入互信息最大化正則
為了抵消上述優化目標帶來的不穩定因素,本文方法受InfoGAN[19]的啟發,引入一個額外的互信息損失函數作為正則項。在樸素的GAN模型中,生成模型G的輸入是一個連續的噪聲分布z,由于缺少約束,G將會以高度糾纏的方式將若干個不同的輸入z映射到相同的生成樣本G(z),導致G(z)僅僅依賴于z的少數維度,從而生成的分布只是真實數據分布的“子分布”。為此,我們利用互信息來約束z,讓I(z,G(z) )最大,使z的每一個維度都盡可能與G(z)產生特定的對應關系,迫使G(z)生成的分布更加趨近于真實分布。而Info?GAN認為生成模型G的輸入應由噪聲分布z和一組隱變量c組成,通過最大化隱變量c與生成數據的互信息,使得控制c的變化,能生成可解釋的圖像特征。
圖2所示的是GAN的概率圖模型。其中,z是隨機噪聲變量滿足簡單的連續分布,s是樣本標簽,xreal是真實的數據樣本,xfake是生成的樣本,x表示鑒別器D的輸入樣本,其值取決于標簽s,當s=1時,x即為真實樣本,當s=0時,x則為生成的樣本。由上文可知,需要最大化z和G()z的互信息。
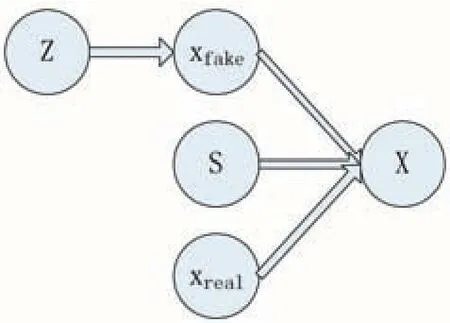
圖2 GAN概率圖模型
同樣的,由于z的后驗P(z|G(z) )無法計算,所以I(z,G(z) )很難直接最大化,根據變分推斷的理論,可以得到其下界函數如(7)式所示:
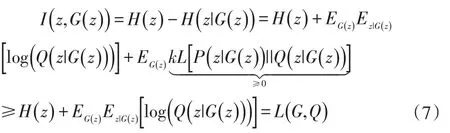
其中,Q(z|G(z))可視為P(z|G(z))的近似后驗。由2.1節可知GAN的理想目標是最小化I(x,s),則引入最大化正則后的目標函數可以表達成(8)式:

當優化(8)式的第一項,實質上是最小化其互信息的下界,而優化其第二項時,由于有負號,最大化其下界等同于最小化其上界,結合(1)(5)(6)(7)(8)式,本文方法實際優化的目標如(9)所示:
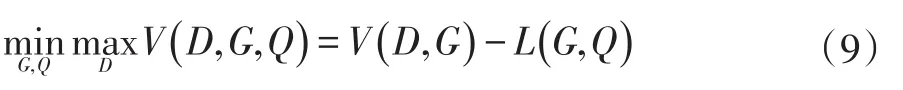
具體的算法描述如下:
輸入:隨機噪聲分布Pz(z);真實樣本;判別器D的迭代次數k(默認為1),學習率l1;生成器G的學習率l2;采樣維度m。
輸出:D的網絡參數w,G的網絡參數θ。
Step0:初始化:w0,θ0。
Step1:whileθ未收斂 do
Step2:D :Forj=0,1,2,…,kdo
Step3: 從隨機噪聲分布Pz(z)中采樣m個噪聲樣本
Step4: 從真實數據分布Pdata中采樣m個數據樣本
Step5:
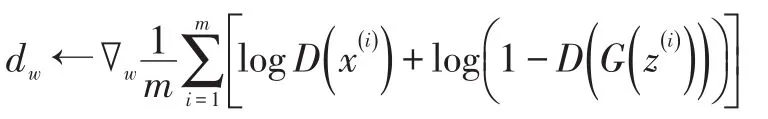
Step6:w←w+l1?Adam( )w,dw
Step7: end for
Step8: G:從隨機噪聲分布Pz()z中采樣m個噪聲樣本
Step9:
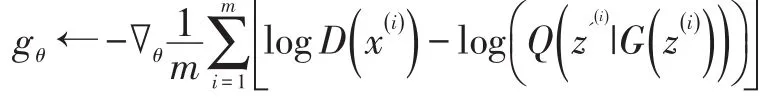
Step10:θ←θ-l2?Adam( )θ,dθ
Step11:end while
3 實驗及結果分析
本文實驗在Ubuntu 14.04平臺上由Tensorflow 0.10編程實現,處理器為Intel Core i5-6300HQ,2.9GHz四核CPU,內存為4G,顯卡為GTX960,顯存為4G。
為了驗證本文算法的可行性,實驗在公開數據集MNIST上進行。MNIST[21]是一個手寫數字數據庫,內容包含0-9的阿拉伯數字,它有60000個訓練樣本圖像和10000個測試樣本圖像。數據集經過了統一的標準化處理,每個字符圖像由28×28的像素構成。
在實際實驗中,為了減少計算代價,引入的額外參數分布Q可以形式化為一個多層神經網絡,讓Q與鑒別網絡D共享大部分卷積層,僅在最后輸出層,以全連接層取代sigmoid層。由于GAN網絡難以訓練,本實驗的基礎網絡架構采用DCGAN模型去穩定訓練,具體參數設置如表1和表2所示。通過與標準GAN模型在MNIST上生成的圖像作對比,得出試驗結果如圖3所示。
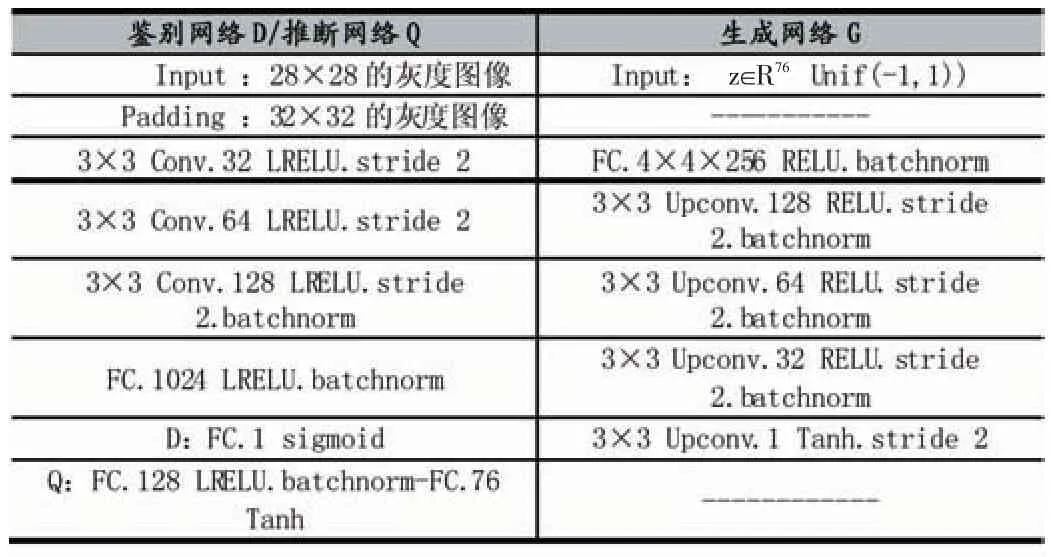
表1 網絡參數設置
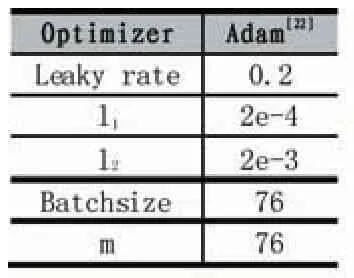
表2 網絡超參數設置
從圖 3 可以看出,與(a)相比,(b)和(c)生成的圖像質量差別不大,較為明顯的是,(b)中生成的數字重復較多并且同一數字形態相似性較大表現出來更為“規整”,而反觀(c)中生成的數字形狀各異與真實圖像更為貼近。為了形式化表現生成數字的多樣性,將(b)和(c)中生成的數字個數加以統計,得到圖4的生成數字分布對比圖。從圖4可以看出,標準GAN模型生成的圖像中,數字“0”的個數占比最高約為21%,而數字“6”的占比卻為0%。這表明生成器生成的樣本差異性較小,出現了較多的重復樣本,導致了樣本多樣性的丟失。而采用本文方法生成的數字分布較為均衡,有效的解決了“模式坍塌”的問題。

圖3 真實圖像、GAN生成圖像和本文方法生成圖像的對比
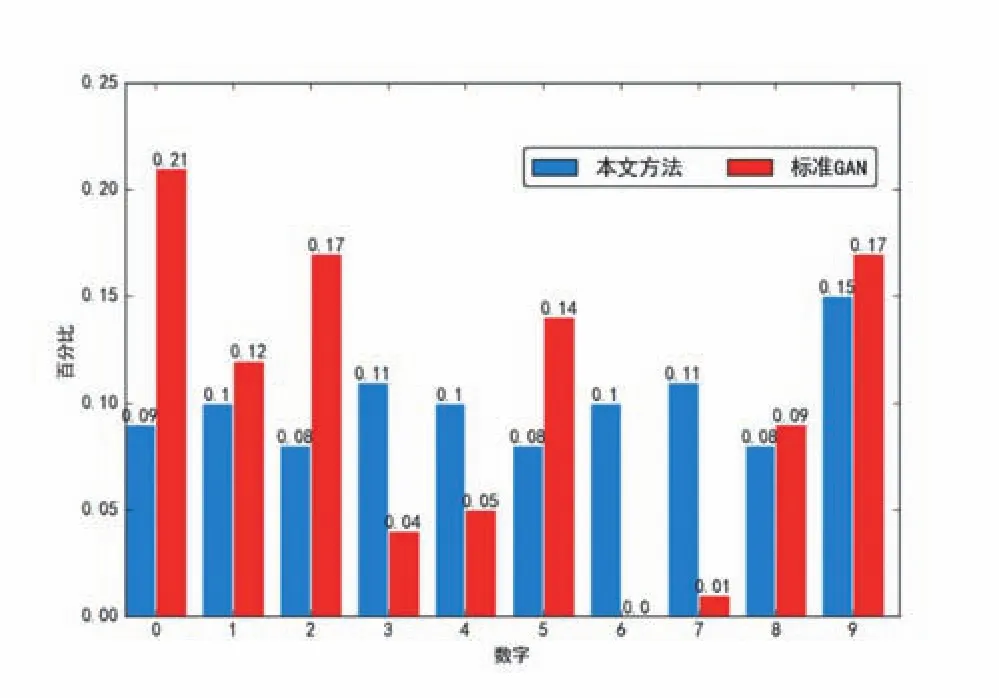
圖4 標準GAN和本文方法生成數字分布對比圖
4 結語
GAN作為無監督生成模型一個強有力的算法框架,已經受到越來越多的廣泛關注。相對于傳統的生成模型,GAN引入了網絡對抗訓練的機制,去逼近難以計算的概率分布,避免了對真實數據似然性的依賴。然而由于GAN訓練過程難以收斂,導致在擬合真實數據分布的過程中常常出現模式的丟失或多個模式趨于同一模式的現象,從而生成的樣本缺乏多樣性。為此,本文受互信息理論的啟發,在InfoGAN的基礎上提出了基于互信息最大化的正則方法,彌補了原始GAN優化目標的誤差,實驗結果表明,所提算法在生成的圖像質量不降低的前提下,樣本多樣性也更為豐富。下一步將深入研究生成器目標函數對GAN訓練的影響,提出更為直觀和穩定的優化目標。
[1]Ian Goodfellow,Jean Pouget-Abadie,Mehdi Mirza,Bing Xu,David Warde-Farley,Sherjil Ozair,Aaron Courville,and Yoshua Bengio.Generative adversarial nets.Advances in Neural Information Processing Systems.2014.2672–2680.
[2]Alec Radford,Luke Metz,Soumith Chintala.Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.arXiv Preprint arXiv:1511.06434,2015.
[3]Odena,Augustus,Christopher Olah,and Jonathon Shlens.Conditional Image Synthesis With Auxiliary Classifier GANs.arXiv Preprint arXiv:1610.09585,2016.
[4]Reed,S.,Akata,Z.,Yan,X.,Logeswaran,L.,Schiele,B.,&Lee,H.Generative Adversarial Text to Image Synthesis.arXiv Preprint arXiv:1605.05396,2016
[5]Christian Ledig,Lucas Theis,Ferenc Huszar,Jose Caballero,Andrew Aitken,Alykhan Tejani,Johannes Totz,Zehan Wang,Wenzhe Shi.Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network.arXiv Preprint arXiv:1609.04802,2016.
[6]Jiajun Wu,Chengkai Zhang,Tianfan Xue,William T Freeman,Joshua B Tenenbaum.Learning a Probabilistic Latent Space of Object Shapes Via 3d Generative-Adversarial Modeling.In Neural Information Processing Systems(NIPS),2016.
[7]Michael Mathieu,Camille Couprie,Yann LeCun.Deep Multi-Scale Video Prediction Beyond Mean Square Error.arXiv Preprint arXiv:1511.05440,2015.
[8]Bengio,Y.,Thibodeau-Laufer,E.,Yosinski,J.Deep Generative Stochastic Networks Trainable by Backprop.International Conference on Machine Learning,2014.
[9]Hinton,G.E.,Osindero,S.,The,Y.A Fast Learning Algorithm for Deep Belief Nets.Neural Computation,2006,18,1527-1554.
[10]Salakhutdinov,R.and Hinton,G.E.Deep Boltzmann machines.In AISTATS,2009,448-455.
[11]Tong Che,Yanran Li,Athul Paul Jacob,et al.Mode Regularized Generative Adversarial Networks.International Conference on Learning Representations,2017.
[12]Hariharan Narayanan and Sanjoy Mitter.Sample Complexity of Testing the Manifold Hypothesis.In Advances In Neural Information Processing Systems,2010.23,1786-1794.
[13]Mehdi Mirza and Simon Osindero.Conditional Generative Adversarial Nets.arXiv Preprint arXiv:1411.1784,2014.
[14]Sebastian Nowozin,Botond Cseke,Ryota Tomioka.f-gan:Training Generative Neural Samplers Using Variational Divergence Minimization.arXiv Preprint arXiv:1606.00709,2016.
[15]Daniel Jiwoong Im,He Ma,Chris Dongjoo Kim,Graham Taylor.Generative Adversarial Parallelization.arXiv Preprint arXiv:1612.04021,2016.
[16]Tim Salimans,Ian Goodfellow,Wojciech Zaremba,Vicki Cheung,Alec Radford,Xi Chen.Improved Techniques for Training Gans.arXiv Preprint arXiv:1606.03498,2016.
[17]Ferenc Huszar.InfoGAN:using the Variational Bound on Mutual Information(twice).http://www.inference.vc/infogan-variationalbound-on-mutual-information-twice/,2016.
[18]Yingzhen Li.GANs,Mutual Information,and Possibly Algorithm Selection.http://www.yingzhenli.net/home/blog/?p=421.
[19]Chen,Xi,et al.Infogan:Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets.arXiv Preprint arXiv:1606.03657,2016.
[20]D.Barber and F.V.Agakov.The IM Algorithm:A Variational Approach to Information Maximization.In Conference on Neural Information Processing Systems,2003.
[21]LeCun,Y.,Bottou,L.,Bengio,Y.,Haffner,P.Gradient-Based Learning Applied to Document Recognition.Proceedings of the IEEE,1998,86(11),2278-2324.
[22]Diederik P.Kingma and Jimmy Ba.Adam:A Method for Stochastic Optimization.arXiv Preprint arXiv:1412.6980,2014.
Abstract:Currently,one of the great difficulty of Generation adversarial nets(GAN)is the prevalence of non-convergence in the training dynamics of model,and its most prominent manifestation is the mode collapse phenomenon,which leads to the lack of diversity of the target object.First explains the theoretical method of the original GAN from the perspective of information theory.On this basis,proposes a regular method based on maximization of the mutual information.By maximizing the mutual information between the noise source and the generated sam?ples,it provides an upper bound function of the objective that forces the produced data distribution to converge more toward the real data distribution.The experimental results of MNIST data show that the maximization of the mutual information introduced is useful to increase the diversity of samples.
Keywords:Generative Adversarial Nets;Mode Collapse;Diversity;Mutual Information;Upper Bound Function
Generative Adversarial Nets Based on Mutual Information Maximization Regularity
PU Yu,WANG Xiao-Feng
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
1007-1423(2017)26-0057-06
10.3969/j.issn.1007-1423.2017.26.015
浦煜(1992-),男,安徽合肥人,碩士研究生,研究方向為深度學習、數據挖掘
王曉峰(1958-),男,遼寧燈塔人,工學博士,教授,研究方向為人工智能及其在交通信息與控制工程中的應用、數據挖掘與知識發現
2017-06-02
2017-09-10
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
