基于基站數據挖掘個人駐留規律①
2017-09-15 07:19:27單桂華
計算機系統應用 2017年9期
關鍵詞:方法
齊 帥, 單桂華, 田 東, 劉 俊
(中國科學院 計算機網絡信息中心,北京 100190)
基于基站數據挖掘個人駐留規律①
齊 帥, 單桂華, 田 東, 劉 俊
(中國科學院 計算機網絡信息中心,北京 100190)
個人移動通訊設備和位置感知設備的廣泛應用,使得運營商積累了大量的用戶位置數據.后前對位置數據的研究大都關注于活動軌跡的挖掘,而少量對于個人駐留規律的研究也只停留在識別出駐留點,卻缺乏進一步的挖掘.本文基于基站采集的位置數據進行研究,依據基站數據的特點,提出了一種簡單的識別駐留點的方法.繼而提出了兩種挖掘駐留規律的方法.最后使用真實數據對算法效果進行了驗證.
基站數據;活動停留;密度聚類;最大頻繁項集挖掘算法
隨著跟蹤定位技術的迅速發展,人們可以通過很多方式獲取客體位置的數據,從而激發了位置數據在諸多領域中的應用.手機作為采集人們位置數據的天然信號接收裝置,在國內被普遍使用.一般情況下一部手機只被一個人使用,手機便成為個人隨身攜帶的定位器.運營商根據自身的需求,會采集大量用戶的位置信息,這為挖掘人們的出行規律提供了豐富的數據源.另一方面,大量的研究已經證實,人們的出行是有規律的.這些研究發現,盡管個體存在差異,但他們大多數時間只訪問少量的幾個地方.更確切的說,Schlich and Axhausen的研究揭示70%的出行是到2到4個不同的地方,90%的出行是以8個不同的地方為后的地;Song的研究顯示,人們大多數時間停留在少量幾個地方,具體一點說,75%的時間用在最頻繁訪問的5個地方.這些研究為我們挖掘出有意義的結果提供了理論支持.
后前關于駐留規律的研究基本停留在識別出駐留點的階段.關于識別出駐留點的研究方法大致分為以下幾種:行進速度、方向變化、信號缺失、軌點密度、K-中值算法、DJ-Cluster算法、CB-SMoT算法.對于在駐留點駐留的時段和時長的研究卻非常缺乏.本文提出了兩種方法來挖掘出個人在駐留點駐留的時段和時長,填補了這方面的空白.
1 基站數據特點
基站數據即通過基站采集的數據,主要提供了以下三方面的信息:個人加密后的ID,采樣時用戶的位置(經度,緯度)和時間.基站數據有以下兩個特點:
(1)用戶在某個基站的信號覆蓋范圍內活動,基站會定位到同一個位置點.
(2)采樣時間間隔長且隨機.
基站采樣效果如圖1所示,圖中每個藍色短線表示一個采樣點.本文為了避免采樣點重合,將短線設置成360度隨機擺動.特點(1)意味著采集的位置數據和真實位置存在一定偏移,且一個采樣點標識的是用戶在一定范圍內的活動,范圍大小由最近基站的信號覆蓋范圍決定.也就意味著地圖由于各個基站的信號覆蓋范圍不同,被劃分成大小不規則的塊.特點(2)意味著用戶發生位置變化的時間點很不明確.基站數據采樣時間間隔平均在20分鐘以上,具體的采樣時間間隔因個人會有差異.比如某人規律性的在早晨八點離開家去公司,但由于采樣的隨機性,七點采樣一次,用戶在家,下次采樣間隔兩個小時,九點采樣時用戶在公司,我們只能得到用戶在七點到九點的時間段內離開家,而不能得到更準確的離開家的時間點信息.
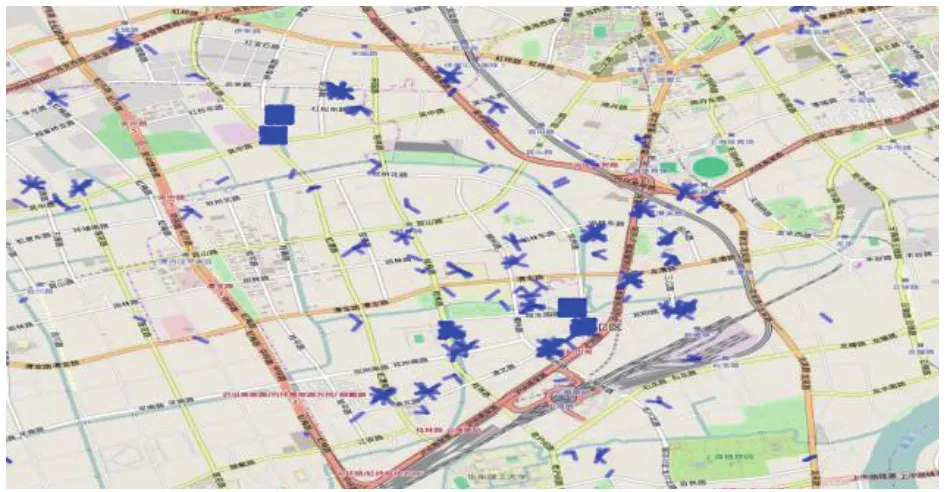
圖1 基站對一個人七個月的采樣結果展示
2 識別駐留點
駐留點就是一個人長期頻繁駐留的區域,比如家,公司,餐廳等.后前識別駐留點的方法很多,但是都不能直接用來解決基站數據的駐留點識別問題.根據基站數據的特點,本文提出了一種簡單的統計方法來識別駐留點.
因為用戶在一定范圍內的活動,基站會定位到同一個位置點上,采樣點有自動聚類的效果.因此我們可以輕松的得到用戶在某個區域停留的時長.比如某人7:50在A點,8:02在B點,8:10在B點,8:30在C點,我們可以簡單的理解為8:02此人出現在B點,8:30離開了B點.那么此人在B點的停留時長為28分鐘.統計一天中停留時長超過半小時的點,我們把這些點定義為一天的停留點.
假如我們設置一個閾值(比如0.5),統計一個人被基站記錄以來,A點作為一天中的駐留點的天數超過了設置的閾值乘以記錄天數,那么我們就可以把A點定義為駐留點.簡單來說,設閾值為0.5,若記錄時長為六個月,一個人有90天以上在A點停留時間超過了半個小時,我們就把A點定義為駐留點.我們使用openstreetmap開源地圖來驗證找到的駐留點,發現大都定位在居住區和工作區內.這說明我們的方法是有效的.
3 挖掘駐留規律
3.1 分割時間段挖掘駐留規律
駐留規律是指個人在駐留點頻繁的駐留時段和時長.因為時間是一個連續的變量,如果要對時間進行頻繁模式挖掘,首先需要把它轉換為離散的變量.因此本部分的思路為,先將一天的時間劃分為時間段,然后將一天的位置和時間點歸到相應的時間段內.最后使用頻繁項集挖掘算法找到頻繁的駐留時段和時長.
(1)劃分時間段
將一天的時間劃分為時間段,以一小時為間隔舉例,那么一天劃分為0~1,1~2,2~3…23~24共 24 個時間段.
(2)時間點轉化為時間段
將時間點和位置用相應的時間段表示,將有駐留點存在時間段標記為此駐留點,沒有記錄的時間段標記為None,有記錄但不在駐留點的時間段標記為M.比如A點和B點為駐留點,以一小時為間隔劃分時間,某人一天的記錄如下所示:
00:01 A,01:10 A,06:05 A,08:10 C,09:20 B,11:15 B,13:12 D,15:16 B,17:10 B,19:02 E,20:10 A
那么這一天的記錄轉化為:
A,A,None,None,None,None,A,None,M,B,None,B,None,M,None,B,None,B,None,M,A,None,None,None.
通過轉化,可以直觀的得到一天中一個人在相應的時段所在的位置.
(3)填補無記錄時間段
為減少隨機記錄造成的影響,我們將前后有相同駐留點標記的,而中間沒有記錄的時間段,標記為此駐留點.如上例所示,1~2時間段為A點,6~7時間段也為A點,中間的時間段都為None,則中間的時間段全部標記為A,上面的例子轉化為:
A,A,A,A,A,A,A,None,M,B,B,B,None,M,None,B,B,B,None,M,A,None,None,None.
因為基站數據的特點是,對于對象發生移動時,基站更可能去采樣.而對于長時間的靜止,基站則不會去記錄.通過這種方法,來填補記錄的一部分空白.
(4)標記時間屬性
為降低算法的復雜度,為每個時間段標記上時間屬性,把求頻繁序列問題轉化為求頻繁組合問題.上面的例子轉化為:
0 A,1 A,2 A,3 A,4 A,5 A,6 A,7 None,8 M,9 B,10 B,11 B,12 None,13 M,14 None,15 B,16 B,17 B,18 None,19 M,20 A,21 None,22 None,23 None.
(5)挖掘頻繁時段和時長
將每天的記錄按照上述步驟轉化為步驟四的樣式,之后對長期的記錄采用最大頻繁項集挖掘算法就可以得到在駐留點頻繁的駐留時段和時長,效果如下所示:
0點~7點A,9點~17點B,20點~24點A
通過挖掘的結果,我們可以推測A點為此人的居住地,B點為此人的工作地.
分割時間段挖掘駐留規律的方法優點是簡單,計算量小.缺點也很明顯,只能挖掘出粗糙的結果.比如某人每天在8:00~8:10離開家,我們只能得到其在8點到9點發生了位置變化.而且此方法切割了時間的連續性.比如某人每天到家的時間在18:50~19:20之間,離開家的時間在8:40~9:10之間,造成同樣的規律可能被分割成不同的記錄,繼而造成需要降低頻繁項的閾值來挖掘最大頻繁項集.
3.2 密度聚類挖掘駐留規律
在上一部分中,我們為了將連續型的時間變量轉化為離散型,采取了分割時間段的方法,但是效果并不好.為了克服這個方法的缺點,我們提出了密度聚類挖掘駐留規律的方法.本方法的思路是:首先將離開或到達駐留點的時間點進行密度聚類.然后將一天的記錄轉化為用類名來表示.最后使用最大頻繁項集挖掘算法找到在駐留點頻繁的駐留時段和時長.
(1)DBSCAN密度聚類
我們對離開或到達一個駐留點的時間點進行聚類,在聚類方法的選擇中,我們發現DBSCAN密度聚類更適合解決我們的問題.DBSCAN算法的后的在于過濾低密度的區域,發現密度高的區域.跟傳統的基于層次聚類和劃分聚類的凸形聚類簇不同,該算法可以發現任意形狀的聚類簇.與傳統的算法相比,它有如下優勢能更好的解決我們的問題.
一:聚類簇的形狀沒有偏倚;
二:與K-MEANS比較,不需要輸入要劃分的聚類個數.
我們首先找到所有的離開或到達駐留點的時間點,其中離開駐留點的時間點由發生位置變化后的那個時間點來確定,比如A點為駐留點,若8:02在A點,8:15在B點,則離開A點的時間點為8:15.對于到達駐留點的時間點也由發生位置變化后的那個時間點來確定.比如A點為駐留點,20:02在B點,20:16在A點,則到達A點的時間點為20:16.對離開或到達駐留點的時間點進行DBSCAN密度聚類后,用類中的最小值和最大值組成的區間來表示這個類.比如,對某人離開A點的時間點進行DBSCAN密度聚類得到的效果為:
類1:7:30,7:35,7:40,7:32,7:45,7:39,8:00,8:02
類2:8:30,8:32,8:35,8:40,8:29,8:42,8:45
那么類1表示為[7:30,8:02],類2表示為[8:29,8:45].
挖掘結果說明,此人頻繁的在[7:30,8:02]和[8:29,8:45]這兩個時間區間內離開A點.
(2)時間點轉化為類
我們把一天的記錄轉化為用聚類后的類名表示.比如某人有A,B兩個駐留點,對離開A點的時間點聚類后分成兩個類:類1[7:30,8:02],類2[8:29,8:45].對到達A點時間點聚類后分成兩類:類3[19:45,20:10],類4[20:30,20:59].離開或到達B點的時間點聚類都為一個類,分別為類5[17:02:17:30],類6[9:10,9:45].若此人一天的記錄為:7:35離開A點,9:10到達B點,17:10離開B點,20:35到達A點.那么此人一天的記錄應轉化為:類1,類6,類5,類4.
(3)挖掘頻繁的駐留時段和時長
將每天的記錄用類名表示后,對長期的記錄采用最大頻繁項集挖掘算法,得到的效果如下所示:
[7:35,8:10]離開A點,[9:12,9:25]到達B點,[17:40,18:03]離開B點,[20:02,20:34]到達A點.
由此我們可以知道此人在A點頻繁的停留時間段大約在晚上八點到第二天八點之間,在B點頻繁的停留時間段為上午九點到下午六點.并且可以推測A點為此人的居住地,B點為此人的工作地.
4 實驗分析
后前我們的數據為運營商基站數據,因為涉及到保密問題,不可能通過運營商獲得特定某個人的數據.為了驗證我們提出方法的效果,我們通過GPS數據來模擬基站數據.根據基站數據的特點一,用戶在某個基站的信號覆蓋范圍內活動,基站會定位到同一個位置點,我們將地圖分塊來模擬基站將地圖分塊的效果.我們以緯度跨度0.003為高,經度跨度0.0025為寬將地圖分塊,落在某個塊的采樣點,將這個采樣點定位到這個塊的中心.通過這種方式,GPS數據滿足了基站數據的第一個特點.根據基站數據的特點二,采樣時間間隔長且隨機,我們將一天24小時分割成半小時為一個單位,其中每個單位內隨機選取一個采樣點.這樣我們一天之內可以采樣48個點,且采樣點的時間間隔隨機且保持在小于一個小時的范圍內.通過這種方式,GPS數據滿足了基站數據的第二個特點.
我們征集了十個志愿者,在他們的手機上下載GOOGLE開發的“我的足跡”APP來記載他們每天的軌跡.記錄時間為2016年11月01號到2016年12月01號一個月的時間.我們從中選取周一到周五的數據,經過上面介紹的兩項處理之后,將GPS數據轉變為基站數據.經過我們提出的方法處理得到的結果與志愿者后期自己填寫的規律性表格來對比,從而來評估我們方法的有效性.
4.1 識別駐留點
我們首先選取其中一個志愿者的數據來具體分析方法的效果.通過簡單的統計方法來識別駐留點,得到兩個駐留點,其中一個落在青年公寓所在的方格,一個落在騰達大廈所在的方格.經過與此志愿者填寫的表格對比,發現得到的結果是正確的.在分別對這十個志愿者的數據做處理后,得到的正確率為90%,即十個志愿者的結果中有九個是正確的.其中有一個錯誤是因為此志愿者在這段時間在外地出差.錯誤是由于采樣時間太短造成的.
4.2 分割時間段挖掘駐留規律
為驗證分割時間段挖掘駐留規律的方法,我們還是首先選取其中一個志愿者的數據來具體分析效果.以一小時為間隔對一天的時間分段.以總記錄個數*0.2為最大頻繁項集挖掘算法的閾值,得到最大頻繁項集有四十多條記錄.數據量比較大,這是由于時間間隔設置帶來的問題.我們限定挖掘出的記錄長度大于等于16,則結果如下所示:
[‘0 116.34296,39.98840’,‘1 116.34296,39.98840’,
‘2 116.34296,39.98840’,‘3 116.34296,39.98840’,
‘4 116.34296,39.98840’,‘5 116.34296,39.98840’,
‘6 116.34296,39.98840’,‘7 116.34296,39.98840’,
‘9 116.33312,39.94396’,‘10 116.33312,39.94396’,
‘11 116.33312,39.94396’,‘14 116.33312,39.94396’,
‘15 116.33312,39.94396’,‘16 116.33312,39.94396’,
‘17 116.33312,39.94396’,‘19 116.34296,39.98840’,
‘20 116.34296,39.98840’,‘21 116.34296,39.98840’,
‘22 116.34296,39.98840’,‘23 116.34296,39.98840’]
語言表述為:晚上七點到早晨七點在家,九點到達工作地點,到上午十一點,午休,下午兩點到五點在工作地點,晚上七點到家.
通過這個實驗,我們可以看到這個方法帶來的問題,挖掘出的頻繁項過多,并且此人大約在七點多到八點多到家,通過這個方法把一個規律割裂成兩種不同的規律.由于這個方法存在太多的缺陷,我們不再對這個方法的有效性做評估.
4.3 密度聚類挖掘駐留規律
我們選取一個志愿者的數據,以離開居住地點為例,首先找到所有離開居住地點的時間點,可視化在時間軸上如圖2(a)所示,使用DBSCAN密度聚類,我們設置半徑為5分鐘,最小點數為10.對所有離開居住地點的時間點進行密度聚類,聚類效果如圖2(b)所示.
可以得到,離開家的時間分為兩類,分別為[6:29,7:08]和[7:35,7:48].以同樣的方法對其他駐留點的離開到達時間進行密度聚類,將每天的記錄替換為類號,使用最大頻繁項集挖掘算法,最后得到的結果為:
6:29-7:08 離開居住地點 7:40-8:12到達工作地點11:18-11:34 離開工作地點 14:02-14:34回到工作地點18:20-19:10 離開工作地點 19:15-19:46 回到居住地點
而此志愿者填寫的規律性表格為:
6:30-7:00 離開居住地點 7:45-8:00 到達工作地點11:10-11:30 離開工作地點 14:20-14:40 回到工作地點18:40-19:00 離開工作地點 19:30-19:50 回到居住地點.

圖2 志愿者數據的聚類分析結果
我們以挖掘的結果與表格的結果重合的時間段長度除以挖掘結果的時間段長度來評估算法的準確率.那么此志愿者離開居住地點時間段的準確率為重合時間段長度30 min除以挖掘結果的時間段長度39 min,即為77%.其他時間段的準確率分別為47%,80%,43%,40%,52%.最后我們取他們的平均數作為最終的準確率,其結果為57%.其他九個志愿者的準確率分別為34%,60%,45%,43%,33%,55%,38%,41%,52%.
此方法消除了分割時間段方法的缺點,非常詳盡的挖掘出對象的駐留規律.
5 結語
本文首先分析了基站數據的特點,根據基站數據的特點,提出了一種簡單的統計方法來識別駐留點.然后提出了時間段分割挖掘駐留規律的方法,但是這個方法出現了挖掘的頻繁項太多,割裂時間連續性的缺點.為了消除這些缺點,本文又提出了密度聚類挖掘駐留規律的方法.最后通過實驗驗證,發現密度聚類的方法能有效詳細的挖掘出個人的駐留規律.
1 Cao HP,Mamoulis N,Cheung DW.Discovery of periodic patterns in spatiotemporal sequences.IEEE Trans.on Knowledge and Data Engineering,2007,19(4):453–467.[doi:10.1109/TKDE.2007.1002]
2 Elgethun K,Fenske RA,Yost MG,et al.Time-location analysis for exposure assessment studies of children using a novel global positioning system instrument.Environmental Health Perspectives,2003,111(1):115–122.
3 Spaccapietra S,Parent C,Damiani ML,et al.A conceptual view on trajectories.Data &Knowledge Engineering,2008,65(1):126–146.
4 Stopher PR.Collecting and processing data from mobile technologies.Proc.of the 8th International Conference on Survey Methods in Transport.Annecy,France.2008.
5 H?gerstrand T.What about people in regional science?Papers of the Regional Science Association,1970,24(1):6–21.[doi:10.1007/BF01936872]
6 Goulias K,Janelle D.GPS tracking and time-geography:Applications for activity modeling and microsimulation.Final Report of an FHWA-sponsored Peer Exchange and CSISS Specialist Meeting.Santa Barbara,CA,USA.2005.
7 Schuessler N,axhausen KW.Processing raw data from global positioning systems without additional information.Transportation Research Record:Journal of the Transportation Research Board,2009,(2105):28–36.[doi:10.3141/2105-04]
8 Stopher PR,Jiang Q,FitzGerald C.Processing GPS data from travel surveys.Proc.of the 2nd International Colloquium on the Behavioural Foundations of Integrated Land-Use and Transportation Models:Frameworks,Models and Applications.Toronto,Canada.2005.
9 Schuessler N,Axhausen KW.Processing raw data from global positioning systems without additional information.Transportation Research Record:Journal of the Transportation Research Board,2009,(2105):28–36.[doi:10.3141/2105-04]
10 張治華.基于GPS軌跡的出行信息提取研究[博士學位論文].上海:華東師范大學,2010.
11 張用川.基于手機定位數據的用戶出行規律分析[碩士學位論文].昆明:昆明理工大學,2013.
Mining the Pattern of Personal Stay Based on the Base-Station Data
QI Shuai,SHAN Gui-Hua,TIAN Dong,LIU Jun
(Computer Network Information Center,Chinese Academy of Sciences,Beijing 100190,China)
With the widespread use of personal mobile communication devices and location-aware devices,the mobile communication service provider has accumulated a lot of its users’ location data.At present,most researches on location data are focused on the mining of active trajectories.A small amount of researches on the pattern of personal stay only determine activity stops,but lack further mining.We conduct researches based on the base station data and propose a simple method to identify the activity stops according to the characteristics of the base station data.Then we propose two methods for mining the pattern of personal stay.Finally,the real data are used to verify the effectiveness of the algorithm.
base-station data;activity stops;density-based clustering;mining algorithm for maximum frequent itemsets
齊帥,單桂華,田東,劉俊.基于基站數據挖掘個人駐留規律.計算機系統應用,2017,26(9):176–180.http://www.c-s-a.org.cn/1003-3254/5955.html
① 基金項后:國家自然科學基金(91530324);國家高技術研究發展計劃(2015AA01A302)
2016-12-28;采用時間:2017-01-18
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
