基于HMM的聯機維吾爾文整詞識別方法研究
2017-08-10 09:52:45劉穎哈力木拉提買買提
現代計算機 2017年17期
劉穎,哈力木拉提·買買提
(新疆大學信息科學與工程學院,烏魯木齊 830046)
基于HMM的聯機維吾爾文整詞識別方法研究
劉穎,哈力木拉提·買買提
(新疆大學信息科學與工程學院,烏魯木齊 830046)
提出一種維吾爾文手寫整詞識別方法,通過拼接單詞中各連體段的特征構建單詞的特征向量,用K-means聚類算法對連體段進行聚類操作降低單詞特征向量的維度并輸出離散的數字序列,通過隱馬爾科夫模型完成單詞的建模和識別。
維吾爾文整詞;隱馬爾科夫模型;特征降維;聯機
0 引言
隱馬爾科夫模型是一種對時序變化信號進行處理的概率模型,它的成功應用在于它對時間序列具有較強的建模能力[1],并被廣泛應用于模式識別領域,例如:語音識別、字符識別、人臉識別等領域。由于維吾爾文聯機手寫單詞,具有時序性,與語音識別中的語言信號有一定的相似性,所以將HMM模型應用到維吾爾文聯機手寫識別中是合理的。
維吾爾文是屬于阿爾泰語系突厥語族,借用了阿拉伯文和部分波斯文字符,目前已有大量針對阿拉伯文手寫體識別的研究[2][3],Maqqor[4]提出了基于HTK的脫機手寫字符識別系統,考慮了阿拉伯文的腳本特點和草書傾向,提高了字符識別效率。Hamdani[5]提出了基于RWTH的針對大量連續詞匯的阿拉伯文手寫識別系統,該系統使用人工神經網(ANN)和隱馬爾可夫模(HMM)作為識別器,在阿拉伯文手寫識別比賽中獲得了較高的名次。
維吾爾文字識別包括印刷體識別和聯機手寫體識別[6-8]。其中,文獻[6]中,將維吾爾文字符分成了主筆劃和附加筆劃兩部分,分別進行特征提取。文獻[7]中,提出了基于支持向量機的維吾爾文聯機手寫字母識別方法,系統研究了樣本采集、預處理、特征提取和分類等模塊。文獻[8]中,提出了一種基于BP神經網絡的維吾爾文字母識別方法。目前大多數的識別技術都是針對維吾爾文單個字母的。但維吾爾文通常都是以單詞為基本單位進行書寫,僅能識別單個字母,并不能滿足人們的應用需求;同時,對單個字母進行識別時,通常要涉及到字母的切分,而高精度的字符切分仍然是該領域的一個難題。本文,提出了一種針對連體段進行特征提取,以維吾爾文單詞為識別基元的手寫識別方法,該系統通過使用隱馬爾科夫模型對維吾爾文整詞進行建模,達到識別維吾爾文整詞的目的,滿足了人們的基本手寫需求,并有效地避開了字符切分困難問題。
1 特征提取
1.1 預處理
維吾爾文一般具有草書特點[9],導致原始手寫樣本中存在噪聲,會影響后續的特征提取的效率和準確率,所以要先對原始樣本進行預處理,通常包括點平滑、歸一化、點聚類[10],拐點提取等操作。圖1所示,表示單詞預處理之后的效果圖。
1.2 特征提取
完成預處理操作后,接下來就是單詞特征的提取。一般特征選取原則要求穩定性強、分類性能好,能高效地反映出該單詞的特點。本文基于聯機手寫維吾爾文單詞的特點,將單詞分為了若干個連體段,分別提取每個連體段的特征。

圖1 單詞預處理效果圖
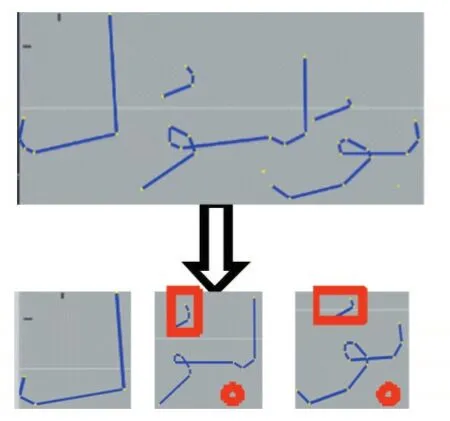
圖2 單詞分為三個連體段
本文中分別選取方向碼特征、環路特征、向量角度特征、附加筆畫特征和穿越特征作為連體段的特征,用于后續單詞特征向量的構建。其具體描述如下:
(1)方向碼特征:方向碼特征是對筆劃方向進行編碼,來確定筆劃走向的。本文中按維吾爾文的書寫特點,將360度的坐標平面平均分成8個方向(0,45,90,135,180,225,270,315),分別對應編碼 0~7,計算主筆劃中相鄰骨架點組成的向量與X軸的夾角,夾角落在哪個區域,則特征值就取該區域的編碼。
(2)環路:統計主筆劃中環路的個數
(3)向量角度特征:先連接連體段中相鄰的點,然后計算相鄰向量之間的夾角,作為一種局部角特征。例如 pi-1,pi,pi+1為點集中相鄰的三個點,則表示向量之間的夾角,作為一個局部角特征。
(4)附加筆劃特征:先通過水平投影的方法計算基線位置,再判斷附加筆劃相對于基線的位置,即基線上方還是下方。
(5)穿越特征:針對于單個連體段,找出它的質心,在質心的y坐標,水平畫直線,統計該水平線與連體段的相交次數,同理,在質心的x坐標,垂直畫線,統計垂直線與連體段的相交次數。
2 訓練
2.1 特征降維
采用第1節中的方法,對單詞中的各連體段完成特征提取后,通過拼接這些連體段的特征就可以形成單詞的特征向量。例如,單詞的特征向量如圖3所示:

圖3 單詞的特征
由于原始的單詞特征向量維數太高,不利于后續的訓練識別,并且特征向量的數值都是連續的,需要先對特征向量進行離散化。
本文將采用K-means聚類算法對單詞特征向量進行降維。具體方法如下:
(1)提取所有連體段的特征,構建連體段的特征庫
(2)使用K-means算法,對所有連體段進行聚類操作,將生成的類中心保存在一個碼本中。為碼本中的每個類中心指定一個數字編號。聚類的目的主要是為了將相同的連體段聚到同一個類中。
(3)判斷單詞中每個連體段屬于碼本中的哪個類,用該類中心的數字編號表示該連體段。
聚類時使用連體段間的歐式距離作為距離度量準則。計算兩個連體段之間的距離時,先分別計算各特征(附加筆畫特征、環數特征、八方向特征、局部角度特征等)之間的距離,不足的位補零,然后將各特征之間的距離相加作為連體段之間的距離。
將單詞特征向量轉化為離散數字序列的具體過程如圖4所示:
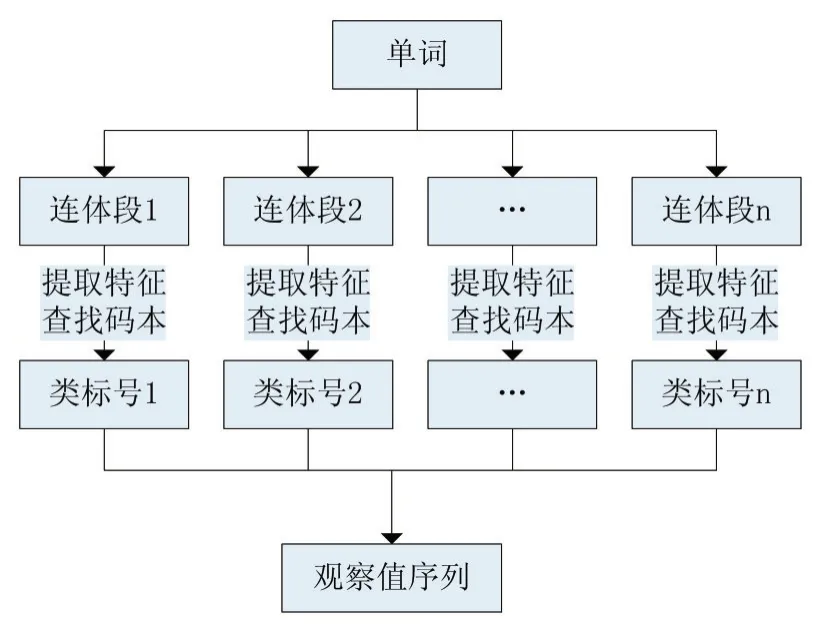
圖4 特征向量的降維流程
2.2 HMM的實現
通過上一小節中介紹的特征降維方法將單詞特征向量轉化為離散觀察值序列后,接下來就可以用HMM中的Baum-Welch算法訓練這些觀察值序列的單詞模型。
在利用HMM解決實際問題時,首先需要確定模型的結構以及狀態數,常用的結構類型為左右模型,而狀態數的確定要根據實際情況進行設定。
本文將采用左右結構的隱馬爾科夫模型,因為這種拓撲結構已經在語音識別中取得了成功的應用[11]。
設置狀態概率轉移矩陣的初始值為,前N-1行,aij=0.5,if j=i||j=i+1;第 N 行,ann=1。 π1=1;πi=0 for i>1。通過多次實驗結果,本文中將狀態個數N設置為20。觀察符號個數M由聚類后生成的簇的個數確定[12],本文中設置為50。
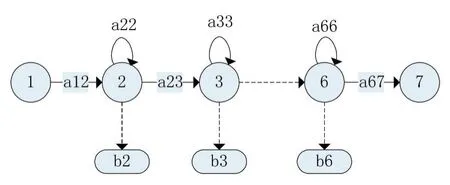
圖5 左右HMM的結構圖
3 識別框架
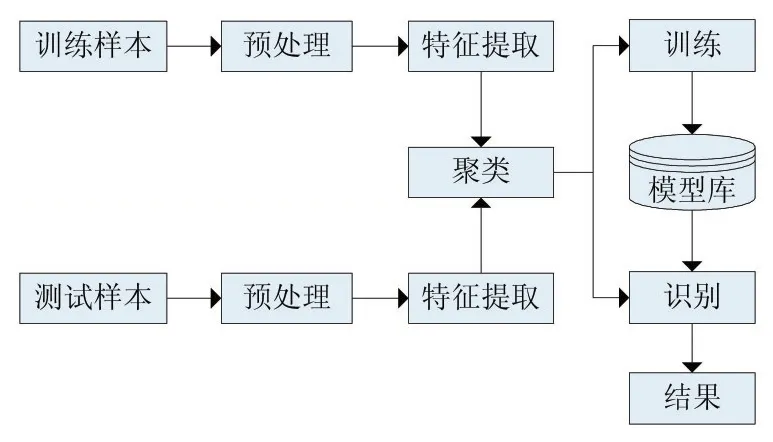
圖6 手寫單詞識別系統結構圖
本文中我們一共收集了70個人的手寫樣本,每個手寫樣本中包含58個維吾爾文單詞,這些單詞包括全部的字母及其所有的形式。其中,隨機抽取50個人的手寫樣本作為訓練集,剩余20個人的手寫樣本作為測試集。具體手寫識別系統結構如圖六所示。單詞識別使用的是HMM中Viterbi解碼算法,具體迭代過程如下:
(1)初始化
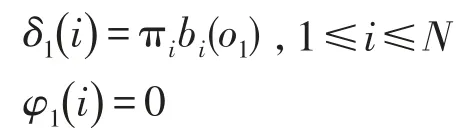
(2)遞歸
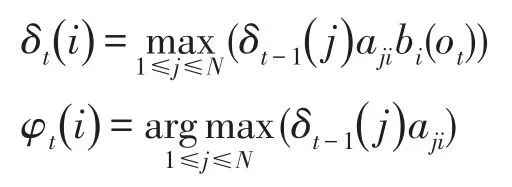
其中,argmax運算符表示使括號中表達式的值最大的索引j。
(3)終止,1≤i≤N,2≤t≤T

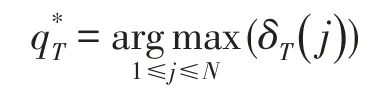
(4)回溯查找路徑,T-1≥t≥1
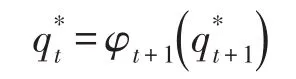
最終實驗結果如表1所示:
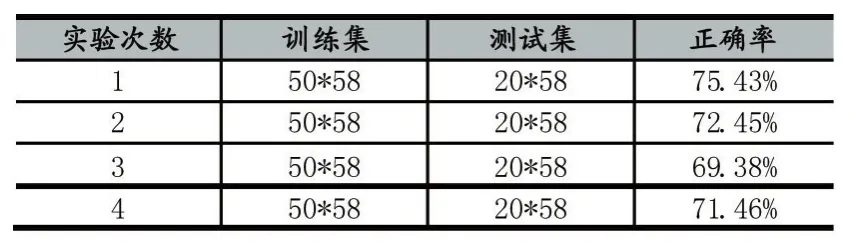
表1 實驗結果
從表1實驗數據可知,本系統最高識別率達到75.43%,最低69.38%。總結分析發現主要有以下幾個因素造成系統識別錯誤:a.主筆劃識別錯誤,誤將主筆劃識別為了附加筆畫,如圖7所示;b.手寫過程中的斷筆問題,將一個連體段分成了多筆書寫。c.使用K-means聚類算法時,k值的選取也會影響最終單詞的識別率。
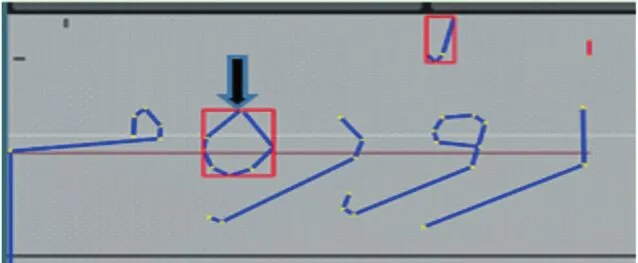
圖7 將主筆劃識別為了附加筆畫
4 結語
本文提出了一種基于HMM模型的維吾爾文整詞識別研究方法。該方法的主要特點是以連體段為特征提取單位,將單詞特征向量表示為各連體段特征的組合,再采用K-means算法對單詞特征向量進行降維操作,生成離散的數字序列,接下來用HMM模型進行單詞訓練和識別,最終達到對維吾爾文整詞進行識別的目的。后續的工作可以進一步改善附加筆劃的識別方法,可以嘗試不同的聚類算法,提高聚類純度,以提高單詞的識別率。
[1]Bengio Y.Markovian Models for Sequential Data.Neural Computing Surveys,1999,2:129-162.
[2]Ahmed H,Azeem S A.Online Arabic Handwriting Recognition System based on HMM[C].Proc of the 2011 International Conf on Document Analysis and Recognition,2011:1324-1328.
[3]Kherallah M,Tagougui N,Alimi A M.Online Arabic Handwriting Recognition Competition[C].International Conference on Document Analysis and Recognition,2011:1454-1458.
[4]Maqqor A,Halli A,Satori K,Et Al.Using HMM Toolkit(HTK)For Recognition of Arabic Manuscripts Characters[C].International Conference on Multimedia Computing And Systems,2014:475-479.
[5]Hamdani M,Doetsch P,Kozielski M,Et Al.The RWTH Large Vocabulary Arabic Handwriting Recognition System[C].Brazilian Symposium on Software Engineering.IEEE Computer Society,2014:111-115.
[6]袁保社,吾守爾·斯拉木.一種手寫維吾爾文字母識別算法[J].計算機工程,2010,36(2):186-188.
[7]木塔力甫·沙塔爾,李春庚,艾斯卡爾·艾木都拉,等.基于可訓練機制的聯機維吾爾手寫字母識別技術研究[J].計算機應用與軟件,2011,28(9):41-44.
[8]任宏宇.基于BP神經網絡的聯機手寫維吾爾字符識別[D].新疆大學碩士學位論文,2011.
[9]哈力木拉提,阿孜古麗.多字體印刷維吾爾文字符識別系統的研究與開發[J].計算機學報:2004,27:1480-1484.
[10]阿力木江·亞森,哈力木拉提.維吾爾文聯機手寫識別的預處理和特征提取[J].新疆大學學報:自然科學版,2010,27(2):232-241.
[11]Rabiner L R.A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition[J].Proceedings of the IEEE,1989,77(2):257-286.
[12]Hassin A H,TANG Xiang-long,LIU Jia-feng.Printed Arabic Character Recognition Using HMM[J].J Comput Sci&Technol,2004,19(4):538-543.
作者簡介:
劉穎(1991-),男,碩士研究生,研究方向為模式識別、新疆少數民族信息處理技術
哈力木拉提·買買提(1959-),男,教授,研究方向為模式識別、新疆少數民族信息處理技術
Research on Online Uighur Whole Word Recognition Method Based on HMM
LIU Ying,Halmurat·MAMAT
(College of Information Science and Technology,Xinjiang University,Urumqi 830046)
Illustrates a recognition method to Uyghur whole word,constructs the word feature vector by splicing feature of each segment in words,then reduces the dimension of the feature vector and output word discrete sequence of numbers by K-means algorithm,completes the modeling and identification of words by using hidden Markov model.
2017-04-06
2017-06-10
1007-1423(2017)17-0050-05
10.3969/j.issn.1007-1423.2017.17.010
Uighur Whole Word;Hidden Markoff Model;Feature Reduction;Online
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
