數字圖書館中的關聯書目檢索推薦方法改進與設計
2017-07-25 09:03:34劉培明駱新泉
現代電子技術 2017年14期
劉培明+駱新泉

摘 要:針對數字圖書館中書目資源規模的增大導致對關聯圖書書目檢索的時效性和準確性不好的問題,提出一種基于相似度標簽索引和關聯規則挖掘的數字圖書館中的關聯書目檢索推薦方法。計算數字圖書館中的關聯圖書書目的相似度標簽信息參量,在相似度便簽索引下進行圖書檢索的語義分析,在語義本體模型中通過關聯規則挖掘實現對相似用戶和相似書目的信息融合和協同推薦,提高了對數字圖書館的檢索效能。仿真測試結果表明,該推薦方法相比于傳統方法具有較高的推薦準確性。
關鍵詞: 數字圖書館; 關聯規則挖掘; 信息融合; 書目檢索
中圖分類號: TN914.3?34; TP391 文獻標識碼: A 文章編號: 1004?373X(2017)14?0072?03
Abstract: Aiming at poor timeliness and low accuracy of association books bibliography retrieval caused by the increase of bibliographic resources in digital library, a recommendation retrieval method of association bibliographic in the digital library is put forward, which is based on similarity label index and association rules mining. The similarity label information parameters of correlation book bibliography in the digital library are calculated. Semantic analysis of book retrieval is conducted in combination with the similarity label index. The association rules mining is used to realize information fusion and collaborative recommendation of similar users and similar bibliography in the semantic ontology model, and improve the retrieval efficiency of digital library. The simulation test result show that the recommended method has higher accuracy, compared with the traditional methods.
Keywords: digital library; association rule mining; information fusion; bibliography retrieval
0 引 言
數字圖書館資源作為一種開放性的公共資源,隨著大數據的更新和圖書出版的增多,數字圖書館館藏的書目規模不斷增多。圖書館館藏資源的增加和大數據信息規模的增大具有關聯關系。在進行數字圖書館的資源檢索和圖書借閱中,需要有效的檢索方法,結合圖書館管理系統的有效推薦,提高對圖書資源的準確檢索和獲取能力,對數字圖書館的關聯圖書的可靠性檢索成為評價圖書館的智能化和個性化服務水平的重要參考標準。研究圖書館的圖書個性化推薦服務模型,對解決圖書的過載借閱和用戶不能有效獲取有用圖書之間的矛盾關系[1?2]同樣具有重要意義。本文對當前國內外圖書館推薦模型研究的基礎上,以協同過濾推薦和內容推薦模型為基礎,提出一種基于相似度標簽索引和關聯規則挖掘的數字圖書館中的關聯書目檢索推薦方法,實現圖書資源的個性化推薦。
1 圖書關聯書目的相似度計算
為了實現對數字圖書館中的關聯書目檢索推薦,需要分析標簽的上下文信息,這就需要進行圖書管關聯書目的相似度計算,用戶相似度計算方法包括皮爾遜相關系數法、向量余弦法、斯皮爾曼相關系數法等[3?4]。采用不同的方法計算用戶的不同關聯信息特征,圖書檢索用戶在進行圖書檢索中,備選標簽集特征向量是依賴于其所有鄰居節點,對用戶文檔進行分析,顯性特征數據表示為:
式中:表示用戶對數字圖書館中的關聯書目的推薦評分;表示用戶對數字圖書館中的關聯書目推薦已給出的評分;是利用式(1)求得的歧義標簽的權值。則用戶u對圖書館關聯書目推薦的語義相關度矩陣可表示為:
基于同義詞和歧義詞的協作過濾,提高推薦的可靠性,更好地反映圖書內容和用戶興趣,采用余弦相似度進行圖書推薦過程中的同義詞過濾,余弦相似度計算式描述為:
式中:sim(i,j)表示瀏覽圖書的關鍵詞和圖書之間的相似度;和表示被同一用戶評分同義詞和歧義詞的評分向量。
采用皮爾遜相關系數(Pearson Correlation Coefficient)方法分析對圖書檢索中的語義隱形特征數據挖掘用戶之間的關聯性[5],皮爾遜相關系數相似度計算為:
式中:表示關聯規則挖掘中待推薦的圖書組合集合;表示WordNet詞匯本體的推薦結果平均評分。在皮爾遜相關系數約束下,得到基于相似度標簽索引的關聯書目推薦的皮爾遜準則為:
分析標簽的上下文信息進行圖書數目的關聯行為替換,構建圖書館關聯書目相似度約束下的優先級列表見表1。
通過表1所示的相似度約束下的優先級列表進行書目檢索的協同過濾推薦控制,確定一個標簽的涵義,根據優先級列表,分析標簽的上下文信息,采用皮爾遜相關系數相似度算法,進行推薦模型的積極評估和消極評估。
2 基于關聯規則挖掘的推薦方法實現
根據上述關聯規則設計方案,在語義本體模型中通過關聯規則挖掘實現對相似用戶和相似書目的信息融合和協同推薦,計算相似用戶對圖書檢索中的語義信息的相似度。用表示用戶感興趣的圖書集,間的相似度,其值在0和1之間變化,相似用戶對圖書感興趣時,,否則。最終的推薦圖書包含在圖書集,中,語義本體為,其中的計算公式為:
式中:和分別表示用戶感興趣的圖書集的目標用戶相似的用戶集數目;表示推薦圖書的公共結點數目。的計算公式為:
式中:表示相似用戶集中相似標簽之間的詞義消岐向量;,分別表示圖書書目集,中推薦結果生成器對備選標簽集的數目。
計算相似標簽之間的相似度,計算完和后,對結果進行綜合,并對每個語義返回相似度值,形成語義相似度,如下:
式中,當時,查詢圖書標簽有最高的相似度值,在協同過濾推薦模塊中計算中的連接度如下:
式中,表示圖書集中選出相似用戶感興趣的圖書。根據用戶查詢請求,從WordNet詞匯本體數據庫中提取標簽信息進行查詢索引,從而將經過過濾的圖書集推薦給目標用戶,實現關聯書目的檢索推薦。
3 實驗結果分析
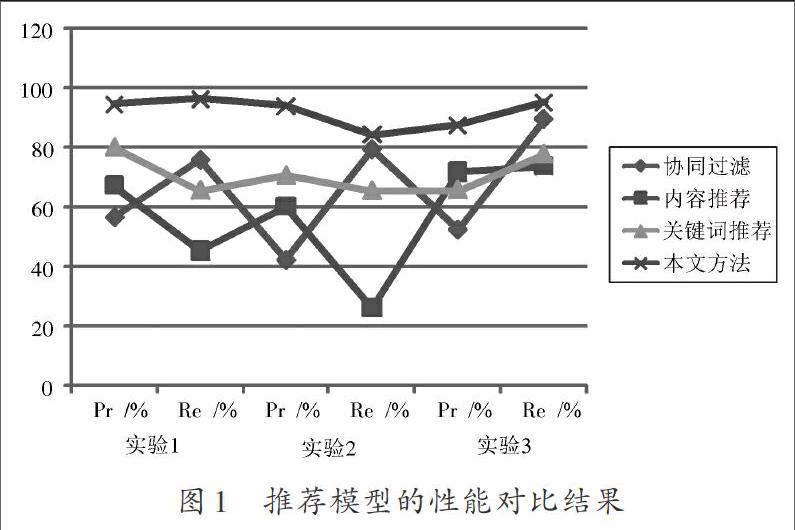
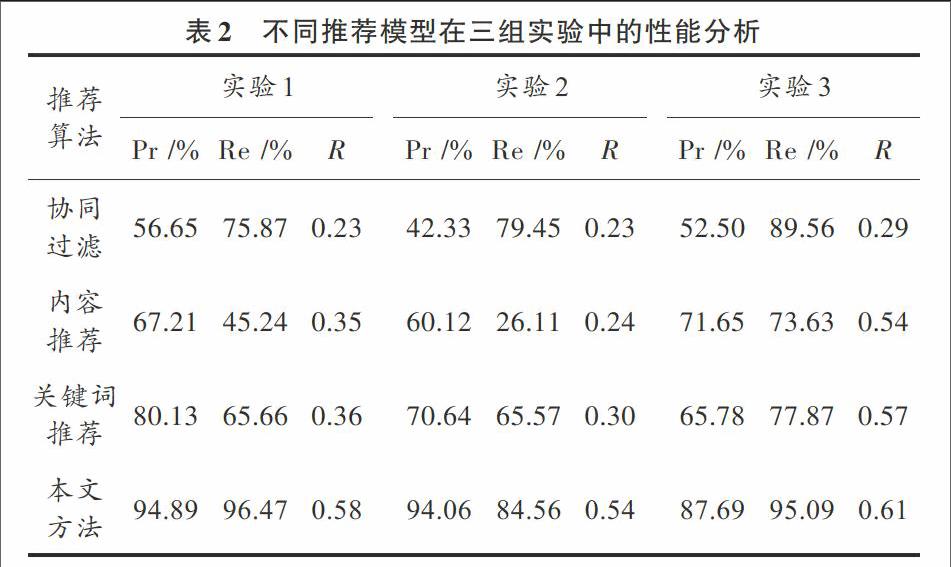
在Matlab仿真軟件中進行數字圖書館關聯書目檢索推薦的仿真分析,實驗采用大型網絡數字圖書館的BookCrossing數據集作為測試集,測試數據[6]有1 000 000條,使用爬蟲程序采集圖書標簽數據進行語義分析和信息加載,關聯規則的閾值設定為:規則1,0.033 5;規則2,0.045 5;規則3,0.054 59;規則4,0.290 9;規則5,0.098 5;規則6,0.089 76;規則7,0.087 53;規則8,0.257 8。以圖書書目檢索推薦準確率(Precision,Pr)、召回率(Recall,Re)、準確率和召回率的相關性關系R為測試指標,R值越大,表示推薦的可靠度越高,采用不同推薦算法在三組實驗中取平均值,得到不同方法進行圖書推薦的測試結果見表2。
為了更好地直觀分析,對上述數據進行繪圖處理,得到不通推薦模型進行圖書推薦的準確性和召回性對比結果如圖1所示。
分析上述實驗結果得知,采用本文方法進行數字圖書館的關聯書目推薦,準確度較高,可靠度較好,表明本文方法具有優越性。
4 結 語
為了提高數字圖書館的圖書推薦和檢索能力,本文提出一種基于相似度標簽索引和關聯規則挖掘的數字圖書館中的關聯書目檢索推薦方法。首先在傳統的內容推薦和協同過濾推薦的基礎上,計算數字圖書館中的關聯圖書書目的相似度標簽信息參量。然后在相似度便簽索引下進行圖書檢索的語義分析,在語義本體模型中通過關聯規則挖掘實現對相似用戶和相似書目的信息融合和協同推薦,提高了對數字圖書館的檢索效能。研究得出。本文提出的推薦方法相比于傳統方法具有較高的推薦準確性和可靠性。
參考文獻
[1] 王翠萍,楊冬梅.知識門戶的個性化服務現狀及優化研究[J].中國圖書館學報,2009,35(5):117?122.
[2] MAHMOUD E E. Complex complete synchronization of two nonidentical hyperchaotic complex nonlinear systems [J]. Mathematical methods in the applied sciences, 2014, 37(3): 321?328.
[3] PALOMARES I, MARTINEZ L, HERRERA F. A consensus model to detect and manage non?cooperative behaviors in large scale group decision making [J]. IEEE trans on fuzzy system, 2014, 22(3): 516?530.
[4] ZHANG H, WANG Z, LIU D A. Comprehensive review of stability analysis of continuous?time recurrent neural networks [J]. IEEE trans on neural networks and learning systems, 2014, 25(7): 1229?1262.
[5] CRESPOA Rubén González, MART?NEZB Oscar Sanjuán, LOVELLEB Juan Manuel Cueva, et al. Recommendation system based on user interaction data applied to intelligent electronic books [J]. Computers in human behavior, 2011, 27 (4): 1445?1449.
[6] AHU Sieg, BAMSHAD Mobasher, ROBIN Burke. Improving the effectiveness of collaborative recommendation with ontology?based user profiles [C]// Proceedings of the 1st International Workshop on Information Heterogeneity and Fusion in Recommender Systems. [S.l.]: HetRec, 2010: 39?46.
