404 Not Found
404 Not Found
基于自適應PCA的油田生產故障診斷方法
楊豐銘(遼河油田興隆臺采油廠,遼寧 盤錦 124010)
基于自適應PCA的油田生產故障診斷方法
楊豐銘(遼河油田興隆臺采油廠,遼寧 盤錦 124010)
油田生產過程中的故障診斷分析,不僅能夠有效的保護生產設備,而且能有效降低生產維護成本,增加生產運行的穩定性。針對由于生產工況發生變化,生產數據特征變化而造成的模型失效問題,本文提出一種自適應的多模型PCA故障診斷方法,實現故障的實時準確診斷。
故障診斷;主元分析(PCA);多模型;自適應
在實際油田開采過程中,由于其復雜的生產環境影響,容易造成故障發生點不能精確定位和故障發現、處理不及時的缺點,發生重大經濟損失,使得生產運行受到極大的影響。對于智能化的故障診斷方法[1]研究變得非常熱門。本文針對由于生產數據和工況條件發生變化而造成模型固化的問題,提出了一種能夠自適應生產變化的多模型PCA故障診斷方法。
1 PCA故障診斷原理
PCA是對數據做空間映射進行特征提取和降維處理的一種方法,提取原數據中的有效信息數據作為新變量替換原來的變量,通過計算一些統計量的性能指標來進行故障的診斷分析。首先,采用PCA方法[2]對歷史數據進行處理建立系統正常運行狀態下的PCA模型;然后對實際生產過程中的數據向量進行正交元子空間和殘差子空間上的投影,計算數據向量在相應空間上的主元平方T2統計量和平方預測誤差統計量SPE性能指標;對數據向量采用故障重構的方法在每一個故障方向上進行投影,對比重構后數據的統計量值和正常統計量值的區別,分析辨別和確定故障的來源。T2統計量代表的是采樣數據在主元空間內對模型的偏離程度;而SPE統計量則代表的是采樣數據在殘差空間內對模型的偏離程度,具體計算如下:
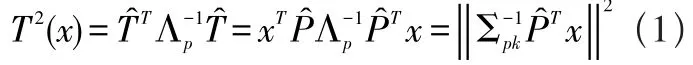
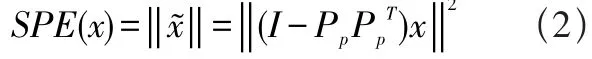
式(2)中,Pp由載荷矩陣的前p個向量組成。
2 多模型的PCA算法
在實際生產過程中,當生產工況發生變化時,原先采用歷史數據建成的PCA模型容易會出現固化問題,不能準確診斷故障信息,出現故障誤判和故障漏判的缺陷,對實際正常生產造成重大的影響。對此,本文根據不同工況條件下的采樣數據特點,對歷史數據進行分類建立不同工況條件下的PCA故障診斷模型,以提高模型的故障識別診斷效率。首先根據歷史樣本數據均值作為初始數據聚類中心,對歷史樣本數據進行聚類,利用分類后的樣本數據建立不同工況條件下的PCA模型,計算相應的統計量控制限;對于新采集的生產數據,進行最短歐氏距離的方法進行歸類,找到相應的主元模型,計算對應的統計量指標并與統計量指標控制限值作對比,分析故障點的來源。本文采用的歐氏距離如下:

式(3)中,n是變量的個數;cj為數據聚類中心。
3 模型的更新
隨著油田的生產運行,由于生產數據的動態特性,導致傳統PCA模型會面臨一個逐漸失效的問題,不再能準確進行系統的故障診斷分析。這時,如何更新模型適應數據的動態特性變化顯得尤為重要。本文利用遞推數據矩陣的方法,通過剔除模型中的舊數據和引入新數據的思想,完成PCA模型的更新過程。通過更新計算模型的統計量控制限,使模型能夠自適應生產數據變化的動態特性。
4 實驗驗證
采用遼河油田生產現場采集到的水箱液位、示功圖和泵路溫度的歷史數據作為實驗數據。根據壓裂和蒸汽吞吐等不同工況條件對8000組歷史樣本數據進行分類,根據不同的工況條件建立相應的PCA模型1、PAC模型2,計算不同模型對應的統計量控制限值SPE。利用新的4000組采樣數據進行故障實驗驗證分析,采用自適應的多模型PCA方法與傳統的PCA模型進行比較。在故障試驗中,對采集到的3000-3300組數據增加偏差為30%的故障,仿真實驗結果如下所示:
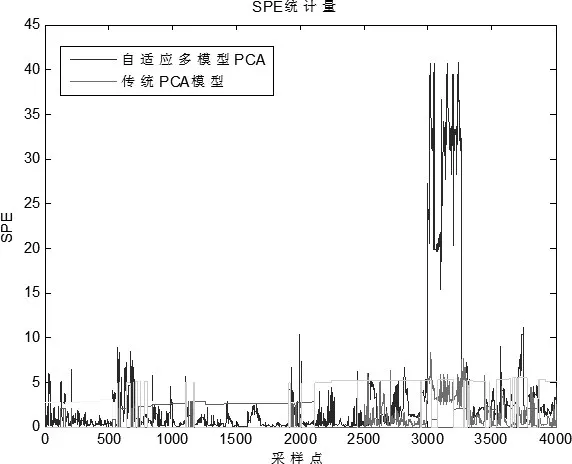
圖1 故障數據SPE統計量圖
根據實驗仿真圖可知,該方法在樣本數據為3000-3300組的統計量指標SPE均明顯超過了控制限值,而傳統PCA模型在故障數據段的SPE統計量指標沒有超過控制限,不能有效檢測到故障,所以自適應多模型PCA具有更好的診斷靈敏度和精度,實驗結果與實驗的前提假設一致。實驗證明本方法,確實能夠提高原PCA模型的故障診斷靈敏度和精度,更好的應用于生產實際。
5 結語
本文針對傳統PCA模型在故障診斷過程中存在的辨識率不高、不能適應生產工況變化的缺點,提出了一種能適應生產工況變化的多模型PCA故障診斷方法。根據歷史數據特性建立不同工況下的PCA模型,對于新的采樣數據通過數據歸類,找到對應的模型進行主元分析,計算相應的統計量與控制限值進行比較,完成故障診斷分析。經過實驗驗證可得,本方法能夠改善傳統PCA診斷存在的誤判斷和漏判斷等不足,具有較高的故障診斷靈敏度,能及時發現和診斷故障來源。
[1]廖銳全等.基于神經網絡的抽油機井井下故障診斷專家系統.[J]武漢理工大學學報,2002,26(4):457~459.
[2]張承彪,羅運柏,文習山.主成分分析在變壓器故障診斷中的應用研究[J].高電壓技術,2005,31(8):9-11.
