基于PSO優化SVM制造業公司財務風險預警研究
2017-07-17 00:27:19張金貴陳凡王斌
會計之友 2017年14期
關鍵詞:財務風險
張金貴+陳凡+王斌
【摘 要】 制造業公司是我國市場經濟的重要組成部分,判別分析制造業公司的財務風險對于進一步促進制造業實體經濟健康發展具有重要現實意義。適當選取2013—2015年制造業公司為樣本,利用SPSS統計軟件運用主成分分析方法(PCA)對制造業公司的財務指標進行了篩選,再利用MATLAB軟件借助粒子群算法(PSO)對支持向量機參數進行優選,構建了基于PSO-LIBSVM模型的公司財務風險預警模型。實證分析表明,該模型可以對制造業公司財務風險進行較為準確的度量,是將人工智能算法運用到經濟管理領域的有效嘗試,對分析公司財務風險具有一定的現實指導意義。
【關鍵詞】 財務風險; 主成分分析; 支持向量機; 粒子群算法
【中圖分類號】 F270 【文獻標識碼】 A 【文章編號】 1004-5937(2017)14-0052-05
制造業公司是我國市場經濟的重要組成部分,為我國社會主義市場經濟的繁榮發展起到了至關重要的作用。根據國家統計局公布的最新統計數據,2016年11月的制造業采購經理指數(PMI)為51.7%,比上月上升0.5個百分點,延續上行走勢,升至兩年來的高點。但是,企業生產經營中仍存在一些困難,企業的各項經營活動、投資活動和籌資活動都會引發企業的財務風險[ 1 ]。因此,公司需要加強對企業財務風險的分析和管理,建立有效的財務風險控制機制,從而實現持續經營,營造百年老店。所以,如何判別并改善制造業公司的財務風險,對于進一步促進制造業實體經濟健康發展具有重要現實意義。
本文基于粒子群算法(PSO)優化支持向量機(SVM)模型的公司財務風險實證研究,以二元分類為例,選取36家制造業公司為研究樣本,并將其劃分為訓練樣本和檢驗樣本,每個子樣本根據配比方案分為金融危機公司(ST和*ST)和非金融危機公司(非ST和*ST),運用主成分分析法對36家制造業公司的6大類13個不同方面的財務指標進行綜合評價,通過引入支持向量機(SVM),沿襲LIBSVM工具箱對制造業公司的財務風險進行判別,最后利用粒子群算法(PSO)對支持向量機(SVM)參數進行優化,從而實現對制造業公司財務風險的度量,這有助于制造業公司制定更加有效的財務決策,以降低財務危機發生的概率,促進其自身的可持續發展。
一、指標體系構建
(一)樣本的選取
通過參照國內外相關學者的文獻研究,采用Zavagren提出的正常組與違約者2 :1的配比方案,從數據可得性和真實性考慮,選取上海證券交易所和深圳證券交易所中符合證監會《上市公司行業分類指引》(2012年版)的2013—2015年36家制造業上市公司為研究樣本[ 2 ]。樣本數據主要來自上海證券交易所、深圳證券交易所、各上市公司年報、WIND數據庫、國泰安數據庫以及金融界網站。
行業選擇:因為行業不同,其生產特點和生產周期不同,財務指標也會存在較大差異,為保證判別模型的準確性和實用性,選擇制造業上市公司為研究樣本。
金融危機公司(ST和*ST):在t年因“財務狀況異常”被特殊處理的上市公司,同時確保可以獲得(T-2)財務報表數據。
非金融危機公司(非ST和*ST):在為金融危機公司(ST和*ST)選擇相應的非金融危機公司(非ST和*ST)時,要求根據中國證監會行業分類(2012年版)的制造業行業代碼進行匹配,保證金融危機公司(ST和*ST)和非金融危機公司(非ST和*ST)的行業相同或相似。同時確保相匹配的金融危機公司(ST和*ST)和非金融危機公司(非ST和*ST)的財務數據來源于同一個會計年度。
組間數量分布:選取上海證券交易所和深圳證券交易所中金融危機公司(ST和*ST)12家和非金融危機公司(非ST和*ST)24家,樣本總量合計36家公司2013—2015年的財務數據,具體見表1。
為進行財務風險的有效判別分析,將上述36家制造業上市公司樣本分為兩個子樣本,即訓練樣本和檢驗樣本。考慮到金融危機公司(ST和*ST)和非金融危機公司(非ST和*ST)的財務數據配比,對兩個子樣本的比例進行了適當分配,其中訓練樣本包括16家非金融危機公司(非ST和*ST)以及與之相配對的8家金融危機公司(ST和*ST),檢驗樣本包括8家非金融危機公司(非ST和*ST)以及與之相配對的4家金融危機公司(ST和*ST)。
(二)指標的選取
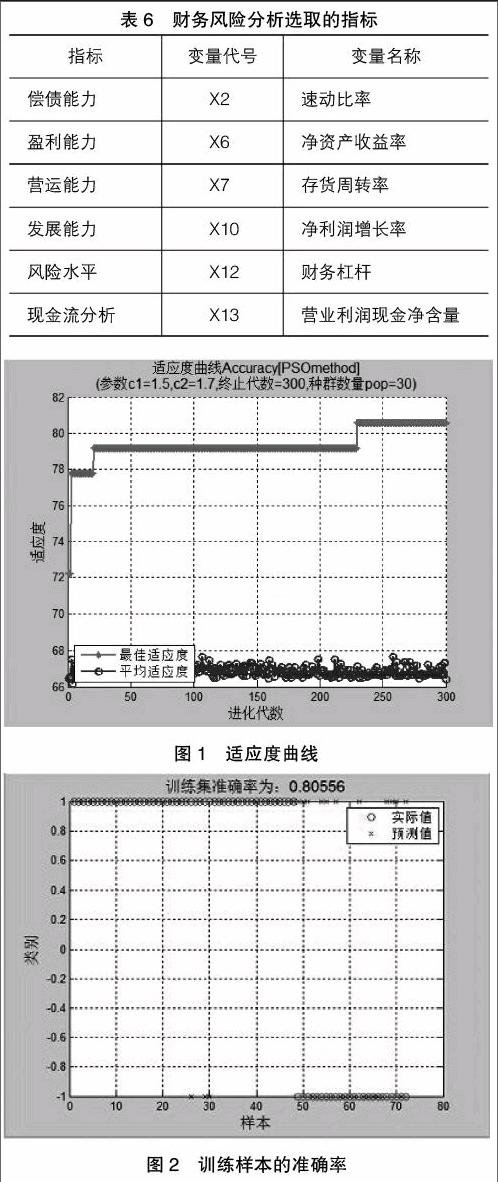
廣泛參考以往國內外相關研究、企業財務特點以及衡量風險的方法[ 3 ],選取6大類13個不同方面的財務指標,用來衡量企業的償債能力、盈利能力、營運能力、發展能力、風險水平及現金流分析[ 4 ],具體見表2。
二、實證研究
(一)主成分分析
為減少多重共線性對模型準確性造成的影響[ 5 ],就選取的36家制造業上市公司2013—2015年的6大類13個財務指標進行正向轉換和標準化,采用KMO(Kaiser-Meyer-Olkin)和Bartlett球形度對變量之間進行相關性檢驗,其KMO數值為0.657>0.5,表示選取的6大類13個財務指標之間存在線性關系,適合作主成分分析,具體見表3。
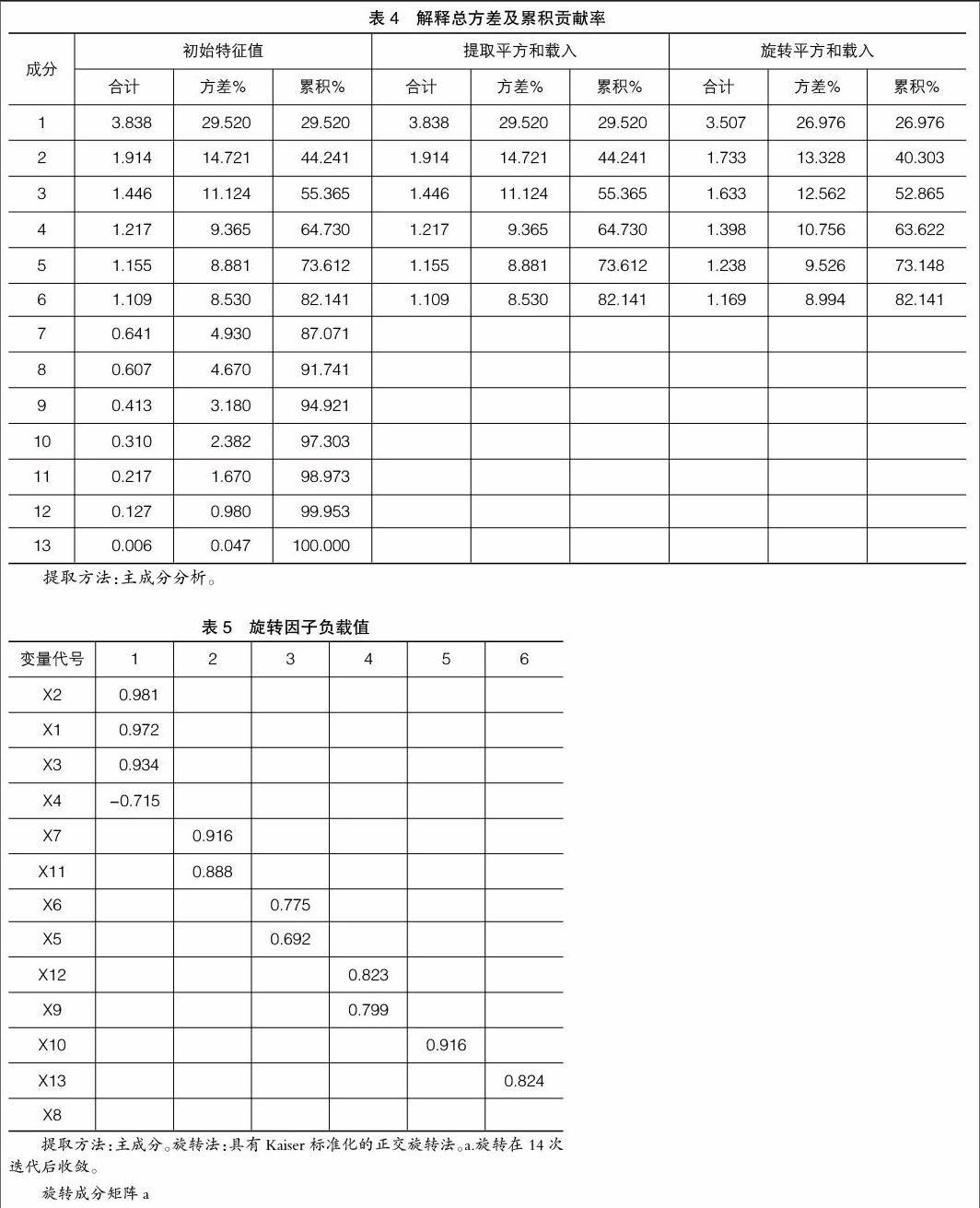
運用最大方差旋轉法提取常用的因子,需通過重復實驗確定的數量來指定共同的因素,以確保累積貢獻率不低于80%。根據最大方差旋轉法提取了6個公因子,其貢獻率合計為82.141%,說明選取的6個公因子能夠代表13個財務指標的基本信息,可以用來對原始指標變量進行分析[ 6 ],具體見表4。
確定了影響因素的個數后,為使各因子的總方差負荷值達到最大值,采用旋轉的最大方差法來闡明各因素的具體含義[ 7 ]。同時,為使結果更加明晰直觀,采用取消小系數法,只顯示旋轉因子負載值大于0.6的系數。旋轉因子荷載的絕對值越大,表明該因子與其關系越密切,越能代表原始變量,具體見表5。
通過選擇負載因子達到最大的變量,可得到6個具有代表性的變量及對應的因素,分別為X2、X6、X7、X10、X12、X13,其中訓練樣本和檢驗樣本中類別1代表非金融危機公司(非ST和*ST),類別-1代表金融危機公司(ST和*ST),具體見表6。
(二)PSO-LIBSVM模型分析
支持向量機(Support Vector Machines,SVM)是一種新興的通用學習方法,其將傳統的算法轉化為一個二次型尋優問題[ 8 ]。基于VC維理論結構風險最小化思想,支持向量機相比其他非線性函數逼近方法具有更強的泛化能力,其拓撲結構主要取決于支持向量,這樣就有效解決了需要根據經驗對傳統的神經網絡拓撲結構進行試湊的問題,例如林智仁博士研發的LIBSVM工具箱。LIBSVM工具箱作為高效支持向量機的算法研究平臺,巧妙地解決了多類問題,根據交叉驗證選擇參數,其核函數包括徑向基函數、線性函數、多項式函數以及S型函數四種。
粒子群中的粒子通過跟蹤記錄下來的pi和pg的歷史值在迭代過程中不斷更新其位置和速度[ 11 ]。選取LIBSVM訓練樣本的預測誤差為評判粒子群中每一個粒子適應度的標準,選擇LIBSVM工具箱中的徑向基核函數(RBF)為支持向量機(SVM)的核函數,再通過粒子群算法(PSO)得到懲罰系數C和核函數參數g的最優組合,其最優解就是粒子群中對應誤差最小的粒子[ 12 ]。粒子群算法(PSO)優化SVM參數主要是通過初始化粒子群的位置、速度,計算每一個粒子的適應度,選擇其中適應度最低的粒子,將其適應度與全局最優值進行比較,如果其適應度低于全局最優值則取其為全局最優值,更新粒子群,未達到終止條件時繼續計算每一個粒子的適應度,達到終止條件時即可輸出gbest,終止條件主要指達到最大迭代字數或者適應度低于預設值。
根據表6的結果,采用LIBSVM訓練算法,結合粒子群算法進行優化,在MATLAB中輸入6個節點,分別對應選取的6個主成分指標[ 13 ]。運行MATLAB程序代碼得出Figure 1適應度曲線,其中參數學習因子c1=1.5,c2=1.7,終止代數=300,種群數量pop=30[ 14 ],參數優化適應度曲線如圖1所示。
模型有效性的判別通常需進行樣本內及樣本外檢驗。樣本內檢驗指根據模型建立的數據,對預測值和實際值的差異進行比較。訓練集樣本中包括表1所列示的16家非金融危機公司(非ST和*ST)以及與之相配對的8家金融危機公司(ST和*ST),其樣本內模型的總體準確率達到80.5556%,運行MATLAB程序代碼得出Figure 2如圖2所示。
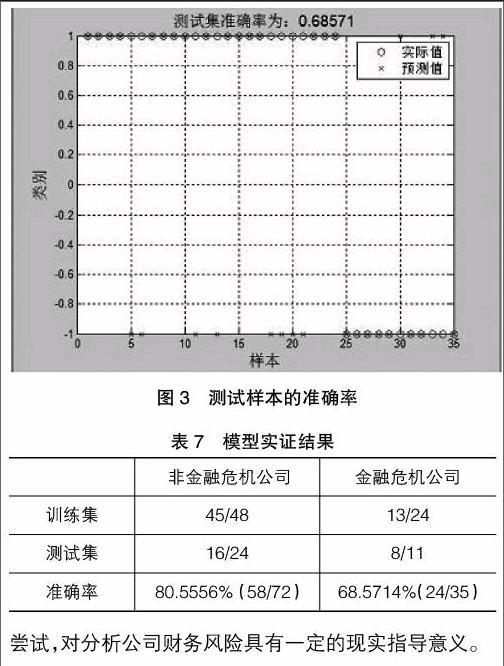
樣本外檢驗指檢驗之前預留的樣本。用于樣本外檢驗的測試集樣本中包括表1所列示的8家非金融危機公司(非ST和*ST)以及與之相配對的4家金融危機公司(ST和*ST),其檢驗總體判斷準確率68.5714%,運行MATLAB程序代碼得出Figure 3如圖3所示。多次運行程序平均用時72.266s,最終結果見表7。
模型實證結果表明,構建的基于粒子群算法(PSO)優化SVM的制造業公司財務風險預警模型是可行的,其樣本內檢驗的準確率、樣本外檢驗的準確率分別達到80.5556%和68.5714%(導致其結果的原因可能是測試樣本中數據缺乏),可以對制造業公司財務風險進行較為準確的度量,是將人工智能算法運用到經濟管理領域的有效嘗試,對分析公司財務風險具有一定的現實指導意義。
三、結論
通過以上構建的基于主成分分析與支持向量機的方法對我國制造業公司財務風險進行分析,運用MATLAB軟件建立了基于粒子群算法(PSO)優化SVM的制造業公司財務風險預警模型,可以得出以下結論:
(1)指標體系的構建是評價制造業財務風險的基礎。采用主成分分析方法,簡化了財務風險指標變量的個數,獲得6個主成分關鍵指標。實證檢驗說明這6個財務指標的選取符合我國制造業公司的特點,適應我國制造業公司面臨的經濟環境。
(2)粒子群算法(PSO)優化SVM的模型對制造業公司的財務風險預警是可行的。粒子群算法(PSO)優化SVM的模型不受制于變量的分布情況,適用于財務分析,具有較高的準確率。同時,粒子群算法(PSO)優化SVM的模型本身具有變量選擇的功能,可以減少計算量和評分的成本,還可以提高模型的判別能力[ 15 ]。實證檢驗表明,構建的制造業公司財務風險預警模型是有效的,樣本內檢驗的準確率、樣本外檢驗的準確率分別達到80.5556%和68.5714%,可以對制造業公司財務風險進行較為準確的度量,可以為財務決策提供依據。
(3)基于PSO優化SVM的制造業公司財務風險預警研究也存在一定的不足之處。文中選取的代表公司財務狀況的特征指標并不全面,不能概括企業經營過程中的非財務因素,而且所提供的信息主要是歷史信息,時效性較差,樣本結構和樣本規模也缺乏廣泛性,缺乏對風險信息和不確定信息的披露。另外,制造業上市公司的個體特征、行業特征、區域經濟發展水平、地方政策等因素存在多變性,這對模型的準確性和可靠性均會造成一定程度的影響。
【參考文獻】
[1] 趙璐.低碳經濟背景下煤炭企業財務風險研究[J].生產力研究,2015(10):143-146.
[2] 孔寧寧,魏韶巍.基于主成分分析和Logistic回歸方法的財務預警模型比較:來自我國制造業上市公司的經驗證據[J].經濟問題,2010(6):112-116.
[3] 朱曉燕,潘美芹.基于Logistics回歸的中小上市公司財務風險評級模型[J].上海管理科學,2015,37(6):91-94.
[4] 王君萍,王娜.我國能源上市公司財務風險評價:基于主成分分析法[J].會計之友,2016(11):60-66.
[5] 閆丹丹,夏虹.基于PCA的上市公司財務風險預測的實證研究[J].商業經濟,2014(12):107-108,126.
[6] 泮敏,曾敏.基于主成分分析法的上市公司財務風險研究:以我國制造業為例[J].會計之友,2015(21):63-67,68.
[7] 吳冬梅,朱俊,莊新田,等.基于支持向量機的財務危機預警模型[J].東北大學學報(自然科學版),2010,31(4):601-604.
[8] 鄔建平.基于主成分分析與最小二乘支持向量機的電子商務信用風險綜合評分[J].物流技術,2016,35(3):87-93.
[9] 鄧敏,韓玉啟.基于支持向量機的大學財務困境預警模型[J].南京理工大學學報(自然科學版),2012,36(3):551-556.
[10] 姜明輝,袁緒川.個人信用評估PSO-SVM模型的構建及應用[J].管理學報,2008(4):511-515,615.
[11] 胡達沙,王坤華.基于PSO和SVM的上市公司財務危機預警模型[J].管理學報,2007(5):588-592.
[12] 紀震,吳青華,廖惠連.粒子群算法及應用[M].北京:科學出版社,2009.
[13] 吳翎燕,韓華,唐菲.基于PSO-SVM的多分類財務預警模型[J].武漢理工大學學報(信息與管理工程版),2013,35(2):265-269.
[14] 史峰,王輝,胡斐,等.MATLAB智能算法30個案例分析[M].北京:北京航空航天大學出版社,2011.
[15] 孫薇,覃銘.基于粒子群優化的SVM的第三方物流企業客戶滿意度評價研究[J].物流工程與管理,2015(3):28-30.
猜你喜歡
現代企業文化·理論版(2016年14期)2016-10-21 10:47:08
現代經濟信息(2016年19期)2016-10-20 18:00:43
現代經濟信息(2016年19期)2016-10-20 17:57:26
現代經濟信息(2016年19期)2016-10-20 17:14:15
現代經濟信息(2016年19期)2016-10-20 17:05:45
現代經濟信息(2016年19期)2016-10-20 17:01:56
商場現代化(2016年22期)2016-10-18 20:03:43
中國市場(2016年33期)2016-10-18 12:52:29
大眾理財顧問(2016年8期)2016-09-28 14:00:43
企業導報(2016年11期)2016-06-16 15:46:45
