基于行業(yè)分類標準的債券新聞自動多分類
2017-07-16 21:53:42陳欽明賴澤華呂威
中國新通信 2017年11期
陳欽明+賴澤華+呂威
【摘要】 本文首先介紹了文本分類的研究背景包括傳統(tǒng)的人工分類以及基于文本數(shù)據(jù)挖掘相關技術的文本分類,接著根據(jù)實際需求通過跟蹤多家債券主體相關的新聞,基于行業(yè)分類標準,完成債券新聞的自動多分類。新聞多分類處理流程包括數(shù)據(jù)集獲取、數(shù)據(jù)集的預處理、分類算法設計與實現(xiàn)、評估及穩(wěn)定性檢測等方面。
【關鍵字】 行業(yè)分類標準 多分類 數(shù)據(jù)預處理 人工標記 SVM 交叉驗證 算法穩(wěn)定性
一、研究背景
自上個世紀80年代以來,信息化的浪潮開始席卷全球,特別是互聯(lián)網(wǎng)技術的不斷普及與完善,信息技術迅速地滲透到社會的各個行業(yè)領域。近幾年,隨著網(wǎng)絡技術的迅猛發(fā)展以及電腦的普遍使用,電子化文檔的規(guī)模得到了急劇的增長,這些文檔都包含了大量的非結構化信息,為了充分利用這些非結構化數(shù)據(jù),我們便需要使用相關的文本數(shù)據(jù)分析技術對其進行處理和利用,當數(shù)據(jù)挖掘的對象完全由文本這種數(shù)據(jù)類型組成時,這個過程便是文本數(shù)據(jù)挖掘[1]。事實上,最近研究表明公司信息有80%包含在文檔中[2]。文本數(shù)據(jù)挖掘正逐漸成為一個熱門領域,吸引各大高校以及專家學者不斷深入研究。
傳統(tǒng)的文本分類是依靠大量的人工完成的。在不同的行業(yè)領域,主要依靠專業(yè)的人員針對特定的領域進行人工標注與分類。如政府機關人員針對公文的分類、早期圖書館對圖書的分類歸檔,專利部門對專利的分類。著名的國際網(wǎng)站Yahoo曾雇傭一百多名來自各個領域的專家,他們即使?jié)M負荷地工作,也沒能對每天不斷涌現(xiàn)在互聯(lián)網(wǎng)上新網(wǎng)頁進行標注與分類[3]。
本文根據(jù)它說債券資訊模塊開發(fā)的實際需求,通過跟蹤4528家債券主體的相關新聞,基于文本分類的相關算法如樸素貝葉斯、K最近鄰算法[4]、支持向量機[5]等,最終完成它說債券資訊模塊的新聞自動分類的功能。
數(shù)據(jù)源介紹
本文的新聞文本數(shù)據(jù)來源于第三方數(shù)據(jù)庫萬德數(shù)據(jù)庫的相關表如公司表、行業(yè)負面表、行業(yè)正面表等,數(shù)據(jù)采集的規(guī)模,采集的時間等具體見如下表1: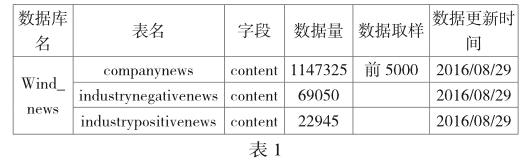
二、數(shù)據(jù)預處理
本文對文本數(shù)據(jù)做了如下的數(shù)據(jù)預處理:將每一條數(shù)據(jù)庫記錄轉化為txt文檔;將文本的編碼從非UTF-8編碼轉化為UTF-8編碼;過濾掉小于1kb的文檔、英文文檔及無意義文檔;去掉html標記、換行符、多余空格。
三、人工標記
接著,對經(jīng)數(shù)據(jù)預處理后的新聞文本數(shù)據(jù),按照行業(yè)分類標準表根據(jù)文檔內(nèi)容對樣本數(shù)據(jù)按分類主題進行人工分類。最終的分類結果如下表2:(Result——19/19/4988)
四、基于多種分類算法新聞模塊實現(xiàn)
文本分類算法是構成一個成熟的文本分類系統(tǒng)不可或缺的一個非常重要的部分,基于高效地文本分類算法可以提高文本分類的時效性及準確度。目前比較常用的文本分類算法包括K-最近鄰算法、樸素貝葉斯、支持向量機等等。下面簡單介紹一下樸素貝葉斯、k最近鄰算法及支持向量機。
(1)樸素貝葉斯分類算法。它基于一個前提假設:即在給定的文本類集合中,文本間的屬性是獨立的,互不影響。對文本分類,就是求該文本在文本類集合中各個類別的概率,概率值最大的那個類別就作為該文本的類別。
(2)K-最近鄰計算的是待分類的文本與所有訓練文本之間的距離,然后將距離按照從小到大進行排序,返回前K個距離最小的樣本,統(tǒng)計這K個樣本所屬的類別數(shù)目,最后將類別數(shù)目最大的類別作為待分類文本的類別。
(3)支持向量機,即SVM,它由V.Vapnik提出。可以應用于非線性分類及模式識別,在解決非線性、小樣本及高維模式識別等問題中具有很大的優(yōu)勢。它的主要思想是在樣本空間中尋找一個最優(yōu)超平面,從而最大化的將兩大類劃分開來。
本文使用經(jīng)數(shù)據(jù)預處理后剩下的4988條新聞作為最終的樣本集,并對樣本集進行中文分詞處理,構造樣本集文本對象,構建樣本集TF_IDF詞向量空間,然后使用相關分類算法進行預測分類結果。具體的算法流程圖如下圖1:
五、文本分類評價性能指標
在完成文本分類的訓練與測試之后,往往需要對分類算法進行分類性能評估,以確定一個算法的優(yōu)劣及進行算法之間的性能比較。目前常用的文本分類性能評價指標包括召回率、錯分率、準確率、F1-score等。
1、召回率(Recall Rate,也叫查全率):是檢索出的相關文本數(shù)和文本庫中所有相關文本數(shù)的比率,衡量的是分類系統(tǒng)的查全率。
召回率(Precision)= 系統(tǒng)檢測到的相關文本 / 系統(tǒng)所有相關的文本總數(shù)
2、錯分率為另外一個角度對召回率的刻畫,滿足錯分率+召回率=1
3、精度(Precision,也稱為準確率):是檢索出的相關文本數(shù)與檢索出的文本總數(shù)的比率,衡量的是分類系統(tǒng)的查準率。
精度(Precision)= 系統(tǒng)檢索到的相關文本 / 系統(tǒng)所有檢索到的文本總數(shù)
4、F1-score綜合考慮了精度以及召回率,是兩者的協(xié)調評價指標。
本文按照20%測試集、80%訓練集,10%測試集、90%訓練集,20%測試集、100%訓練集三種不同的數(shù)據(jù)集隨機切分方式對分類結果進行了交叉驗證(cross_validation),最終的分類結果如下表2:
六、債券新聞多分類穩(wěn)定性檢測
評價一個分類系統(tǒng)的好壞不僅僅考慮系統(tǒng)分類的準確度等指標還要考慮分類系統(tǒng)的穩(wěn)定性。因此本文對分類算法做了算法穩(wěn)定的檢測工作。數(shù)據(jù)檢測來源為companynews表,取樣時間為2016年09月03日到2016年09月10日,持續(xù)一個星期,取樣的標準為每次獲取數(shù)據(jù)最新更新時間的前一天的數(shù)據(jù),數(shù)據(jù)量較大時隨機取樣10%作為測試樣本,并對其進行人工分類形成最終測試樣本集。
最終針對各種分類算法的穩(wěn)定性檢測結果如下表3所示,由下表可知綜合比較貝葉斯,knn,svm三種算法,svm在文本多分類的穩(wěn)定性上較好。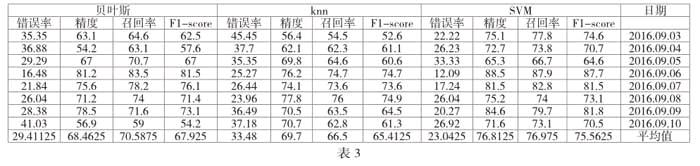
參 考 文 獻
[1]王偉強, 高 文. Internet 上的文本數(shù)據(jù)挖掘[J ] . 計算機科學, 2000 , 27 (4) : 32 - 37.
[2] AH - HWEE TAN. Text Mining : The state of the art and the challenges[ Z] . PAKDD99 Workshop on Knowledge discovery from Advanced Databases ( KDAD99) , Beijing , 1999.
[3] J.M Gomez.Text Representation for automatic Categorization.In Proceeding of Eleventh Conference Of the European Chapter Of the Association for Computational Linguistic,2003
[4]亞南.KNN文本分類中基于遺傳算法的特征提取技術研究[D].中國石油大學,2011.
[5]毛雪岷,丁友明.基于語義引導與支持向量機的中文文本分類[J].情報雜志,2007,26(1 1):56-58
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
小學教學參考(2015年20期)2016-01-15 08:44:38
信息通信技術(2015年6期)2015-12-26 01:16:46
