基于L—M算法及不變矩特征值優化的神經網絡圖像識別
2017-07-08 22:37:14張鑫孫勇
科技創新與應用 2017年19期
張鑫+孫勇


摘 要:文章采用基于L-M算法的BP神經網絡,并在圖像特征提取量的選擇中,結合了不變矩特征值和灰度共生矩陣導出的基于紋理的特征量,以車牌識別為例進行圖像識別。經過訓練和測試,得到L-M及特征量優化的神經網絡,在精度和識別速度上都優于BP神經網絡。
關鍵詞:圖像識別;不變矩特征值;L-M算法;BP神經網絡
中圖分類號:TP183 文獻標志碼:A 文章編號:2095-2945(2017)19-0001-03
引言
隨著圖像識別技術的不斷發展,應用于圖像識別技術領域的算法也在不斷優化升級,人工神經網絡算法作為一種高度非線性的智能自適應算法,在圖像識別領域中的應用越來越廣泛。基于人工神經網絡實現圖像識別的主要特點是構建分類器,將預處理后圖像樣本中提取出來的特征量輸入神經網絡,經過自學習和自組織,不斷地訓練,最終達到能夠穩定正確識別圖像的狀態。[1]本文識別車牌號為例,對基于L-M算法及不變矩特征值優化的神經網絡進行研究和實驗。
1 圖像預處理
1.1 傾斜校正及灰度處理
實際圖像實時采集系統得到的圖像質量參差不齊,本文采用方差公式推導法進行圖像校正。該方法基于正置圖像的投影圖像邊緣點的方差最小的原則來確定傾斜角度,具有較好的校正效果[2]。通常灰度處理方法有平均值法,最大值法和加權平均值法。平均值法和最大值法一定程度上淡化了圖像中目標物與背景分界,對后續邊緣檢測會產生影響,本文選用加權平均值法,通過最優權值的選擇,能夠獲得較好的處理效果。計算公式為:
式中,WR=0.59,WG=0.30,WB=0.11,此權值設置能獲得最佳灰度圖像。[3]
1.2 圖像分割及卡爾曼濾波
獲得灰度圖像后,通過Ostu算法確定合適的分割閾值,當像素點灰度值超過閾值,將該像素點灰度值賦值為255,否則賦值該像素點灰度值為0,由此得到二值圖像。在分割過程中會產生高斯白噪聲,采用卡爾曼濾波的方法進行濾波。[4]
2 圖像特征提取
2.1 不變矩特征值提取
圖像特征提取可以從基于圖像顏色的統計特性、圖像形狀和圖像紋理特征這些方面入手。為了克服圖像旋轉、平移導致的圖像特征提取誤差較大的情況,本文采用形狀不變矩來提取圖像熵矩陣的特征,作為神經網絡的輸入層參數。
根據不變矩理論,定義圖像f(x,y)的p+q階中心矩為:
由計算得到的單元熵組成熵矩陣,n表示網格分辨率。熵矩陣中包含著局部和全局的圖像信息,從熵矩陣中提取不變矩特征值。[5]
2.2 灰度共生矩陣特征提取
在圖像f(x,y)任取一點組點對,偏移量為(a,b),點(x,y)處灰度值為i,點(x+a,y+b)處灰度值為j,固定(a,b),通過點對在圖像上的移動獲得不同的點對的灰度值(i,j),由于經過二值化以后灰度等級為{0,255},故得到的(i,j)組合共有4組,統計整幅圖中每一種點對灰度出現的頻數,歸一化后得到[Pij]灰度共生矩陣。由此獲得對比度,相關性,能量,逆差矩,分別為Con,Cor,Ene,Hom。[6]
綜合從熵矩陣中提取的7個不變矩特征值和依據灰度共生矩陣得出的4個參數,構成用于進行識別的圖像特征向量,作為神經網絡輸入層參數。表示為
3基于L-M算法的BP神經網絡
3.1 L-M算法概述
BP神經網絡算法基于誤差梯度下降標準,通過實際輸出與期望輸出的誤差來調整連接權值使之達到最優。但通常情況下,BP神經網絡存在學習速率慢,容易陷入局部最小值等問題[7]。作為優化算法之一的L-M算法是梯度下降法與高斯-牛頓法的結合,利用了近似的二階導數信息,具有快速收斂,準確度高的優點,本文嘗試將其與神經網絡算法結和用于圖像識別。
3.2 原理及實現步驟
4 實驗仿真及結果分析
本文以車牌識別為例。在試驗中,選取了數字0-9、英文字母A-Z及車牌上常見的30個漢字共66個字符,每個字符50張訓練樣本圖片進行訓練。由于車牌號由不同字符組合而成,在圖像處理過程中,進行了字符分割和圖像增強,為具體字符的識別提供分類基礎。經過訓練后,將50張測試圖片輸入神經網絡進行測試。經過測試,識別率能達到98%以上,且識別速度快,性能明顯優于傳統BP神經網絡。
4.1 圖像預處理
灰度處理選擇的標準是經過灰度變換后,像素的動態范圍增加,圖像的對比度擴展,使圖像變得更加清晰、細膩、容易識別,處理結果如圖2。圖像二值化處理,結果如圖3。
可以通過求梯度局部最大值對應的點,并認定為邊緣點,去除非局部最大值,可以檢測出精確的邊緣。一階導數的局部最大值對應二階導數的零交叉點,這樣通過找圖像強度的二階導數的零交叉點就能找到精確邊緣點,如圖4。
對圖像做了開運算和閉運算,閉運算可以使圖像的輪廓線更為光滑,它通常用來消掉狹窄的間斷和長細的鴻溝,消除小的孔洞,并彌補輪廓線中的斷裂,如圖5。
對水平投影進行峰谷分析,計算出車牌上邊框、車牌字符投影、車牌下邊框的波形峰上升點、峰下降點、峰寬、谷寬、峰間距離、峰中心位置參數,如圖6。
通過以上水平投影、垂直投影分析計算,獲得了車牌字符高度、字符頂行與尾行、字符寬度、每個字符的中心位置,為提取分割字符具備了條件。
4.2 訓練庫的準備
通過預先的圖像識別提取,得到部分數字與漢字的訓練庫,如圖7。
在車牌識別的過程中數字庫的建立很重要,切割出來的數據要與數據庫的數據作比較,只有數字庫準確才能保證檢測出來的數據正確。
4.3 車牌的識別
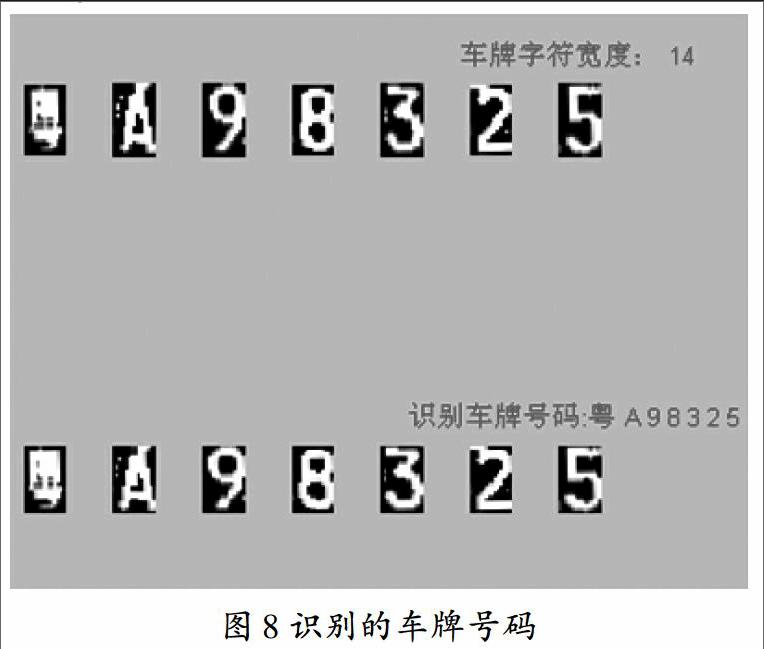
進行車牌識別前需要使用樣本對神經網絡進行訓練,然后使用訓練好的網絡對車牌進行識別。其具體流程為:使用漢字、字母、字母數字、數字四個樣本分別對四個子網絡進行訓練,得到相應的節點數和權值。對已經定位好的車牌進行圖像預處理,逐個的特征提取,然后從相應的文件中讀取相應的節點數和權值,把車牌字符分別送入相應的網絡進行識別,輸出識別結果,如圖8。
5 結束語
基于神經網絡的圖像識別具有廣闊的前景,隨著對識別質量和識別效率要求的不斷提高,用于識別的算法也在不斷更新和優化。基于L-M算法的BP神經網絡在識別速率和精度方面有著巨大的優勢,但是限于計算量較大這一問題,在一些特征向量較多或內存較小的設備中難以適用,而圖像識別所需要的特征量往往又較多,為此進一步研究特征量提取方法的優化和高性能運行設備是圖像識別進一步發展的關鍵。[8]
參考文獻:
[1]牛博雅,黃琳琳,胡健.自然場景下的車牌檢測與識別算法[J].信號處理,2016(07):787-794.
[2]曾曉娟.一種基于神經網絡的圖像識別算法[J].電腦知識與技術,2015(17):171-174.
[3]江偉.機器視覺圖像中目標識別及處理方法研究[D].華北電力大學,2015.
[4]李康順,李凱,張文生.一種基于改進BP神經網絡的PCA人臉識別算法[J].計算機應用與軟件,2014(01):158-161.
[5]張澤琳,楊建國,王羽玲,等.煤粒圖像識別系統的設計與實現[J].煤炭工程,2011(02):17-19.
[6]孫君頂,毋小省.基于熵及不變矩特征的圖像檢索[J].光電工程,2007(06):102-106+115.
[7]王建梅,覃文忠.基于L-M算法的BP神經網絡分類器[J].武漢大學學報(信息科學版),2005(10):928-931.
[8]韓思奇,王蕾.圖像分割的閾值法綜述[J].系統工程與電子技術,2002(06):91-94+102.
