云計算下農作物病情災害預警模型的構建
2017-05-04 00:54:39王師陳學斌
智能計算機與應用 2017年2期
關鍵詞:云計算
王師+陳學斌

摘 要: 通過傳感器采集到的作物數據進行統一管理建立作物災情數據集群池,Map-Reduce模型映射歸類預處理后,再利用BP網絡動態訓練,最后利用權重歸總輸出預測結果。充分利用云計算技術優勢在網絡訓練時動態調整計算資源,有效縮短訓練周期,優化調整改進BP網絡結構,從而提高系統的整體運行效率并且達到作物準確預警的目的。實踐表明該模型收斂速度快,穩定性好,能夠解決作物病情災害預警問題,是作物綜合防治的有效模型。
關鍵詞: 云計算;BP網絡; Map-Reduce;作物預警
中圖分類號:TP301.6
文獻標志碼:A
文章編號:2095-2163(2017)02-0105-03
Abstract:In this paper, the crop data collected by the sensors are uniformly managed to establish data cluster pool, and after Map-Reduce model mapping classification preprocessing, BP network dynamic training are applied, further weights are summed up to output prediction results.Make full use of cloud computing technology advantages to dynamically adjust computing resources in network training, effectively shorten the training cycle, optimize and improve BP network structure, so as to improve the overall efficiency of the system and achieve crop accurate early warning. The experiment shows that this model which has good convergence speed and good stability, can solve the problem of crop disease and disaster warning. It is concluded that the proposed construction is an effective model of comprehensive prevention and control of crop.
Keywords:cloud computing; BP network; Map-Reduce; crop warning
0 引 言
我國農業生產勞作形式呈多樣化分布,致使作物生長受多因素影響,對作物生長狀況探索推出準確的判定是農務工作者做好種植工作和實現作物大豐收的基礎和前提。傳統技術上采取人工干預的手段對作物進行必要的例行檢查,隨后對作物設計引入生長狀況判定,一般情況下進行人工干預的參與人員大都是農業專業學者或從事農業生產多年、并具深厚經驗的工作者。人工手段預警既費時又費力,而且往往由于專業人員短缺,多數情況下未能及時開展例行作物檢查,使得作物遇到災情警情時得不到最佳預警處理造成作物大面積病害,給農民將直接帶來可觀經濟損失。為了解決這個問題,研究決策開發建立農作物數字化監測預警平臺,利用數字化手段收集作物病蟲害數據、分析定義后供專家學者參考預測,這種數字化預測手段某種程度上降低了人工干預的依賴度,能夠及時發現、精細調控受災作物,而且隨著物聯網的興起與發展,利用智能算法獲得現場自動采集數據,同時利用云計算技術設計構建大數據平臺,這就為智能算法事實推理提供有效技術支持。具體來說,BP網絡集分布并行分析處理、非線性映射功能、自適應學習能力和強魯棒性于一體,從而重點、全面地解決了非線性系統模型預測問題。另據研究可知,云計算擁有的強大計算能力,能更加靈活、高效地組織、分配和使用計算資源;云計算擁有的海量存儲能力,能承載大眾參與的云計算中的海量信息和服務;云計算擁有的友好交互能力,還能為用戶確保提供智能化、多元化的服務[1]。此外,Map-Reduce則是一種可擴展的通用并行計算模型,可以有效地處理海量數據[2]。
目前,國外部分國家采取農作物病蟲害數字化監測預警的方式對作物進行評估、識別診斷、網絡互聯預警和數據樣式的規范統一,通過建立病蟲害診斷和綜合治理體系、網絡遠程互聯體系、病蟲害信息系統實現農作物病蟲害監測數字化、信息采集自動集成化和一線監測人員技能化[3-5]。中國已有數省也推廣試行了農作物病蟲害數字化監測預警,但是針對我國農業信息資源的開發利用仍比較分散、獨立性也有待完善以及信息資源多樣化亦難以整合,省份間建立數字化監測預警系統的框架不同、功能各異、系統運行的軟硬件配置存在較大差異而使得作物災情數據無法通用共享等多重現實問題,數字化監測預警在全國進入實踐應用也仍尚需一定時日,而物聯網和云計算的研發運用則成功地解決了信息共享問題[6]。基于我國目前現狀,本文則將打造海量作物數據信息共享平臺作為出發點,通過云計算技術與智能算法相結合設計實現一套農作物災情預警機制,用戶借助本機制可以方便獲取到作物的生長情況,并依據由此生成的有效信息,定制形成完備結果預判[7]。
本文引入云計算優化BP網絡訓練結構,設計一個結構合理、運行效率高、預警速度快的模型,該模型能夠輔助專家學者對作物的生長狀況做出判定,最終得出預警結果。利用云計算的彈性伸縮和動態調配的優良特性,不僅解決了原BP網絡訓練所需計算資源動態調配和預警速度慢從而導致模型預測不準確、不及時等問題,而且更進一步改善了用戶體驗,同時還可顯著突出地提高數據處理能力。
1 模型系統設計
1.1 模型算法設計
考慮到以往由于使用智能算法推算事實根據時所使用的數據信息未臻充分客觀,導致智能算法模型預測存在準確性差、偏差大的問題,通過傳感器采集作物生長的信息,包括作物生長環境的溫濕度和土壤情況、平均風速、光照強度、降雨量等,通過有針對性地采集存儲影響作物生長的有關信息,在此基礎上設計建立作物災情數據集群池。
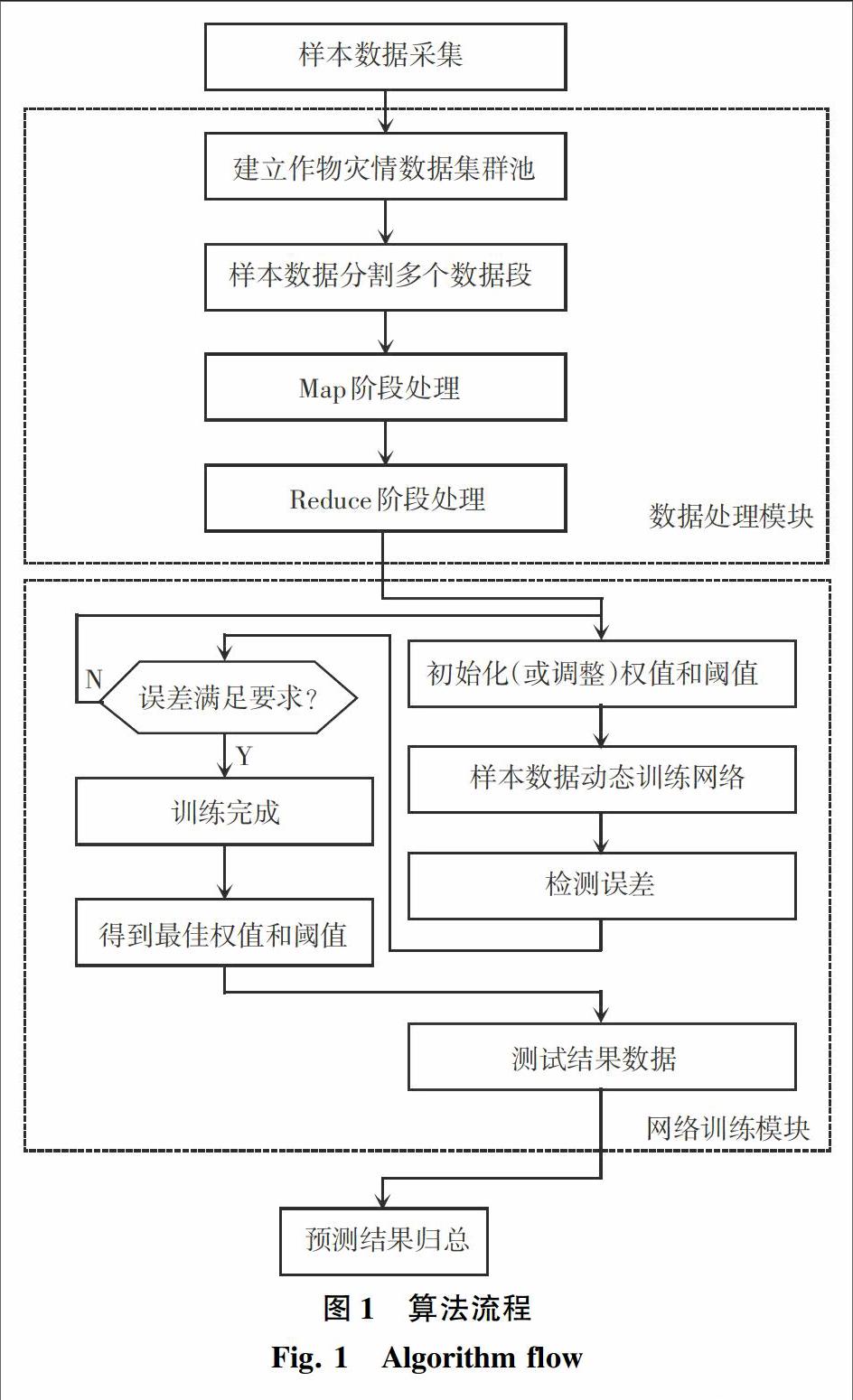
面向集群池中大樣本、大數據處理,傳統BP網絡在計算資源的動態使用情況、訓練周期長短等方面將面臨嚴峻挑戰,為了提高作物預警的準確度,本文對收集的大數據樣本在加工經過了必要的數據預處理后,再利用BP網絡進行動態訓練,優化結構,算法流程如圖1所示。
Map-Reduce模型對作物災情數據資源池進行數據映射歸類預處理,研究給出的運作機制過程如圖2所示。本文即是利用該運作機制處理海量作物災情數據,滿足網絡訓練對數據的處理要求。
1.2 模型總體結構
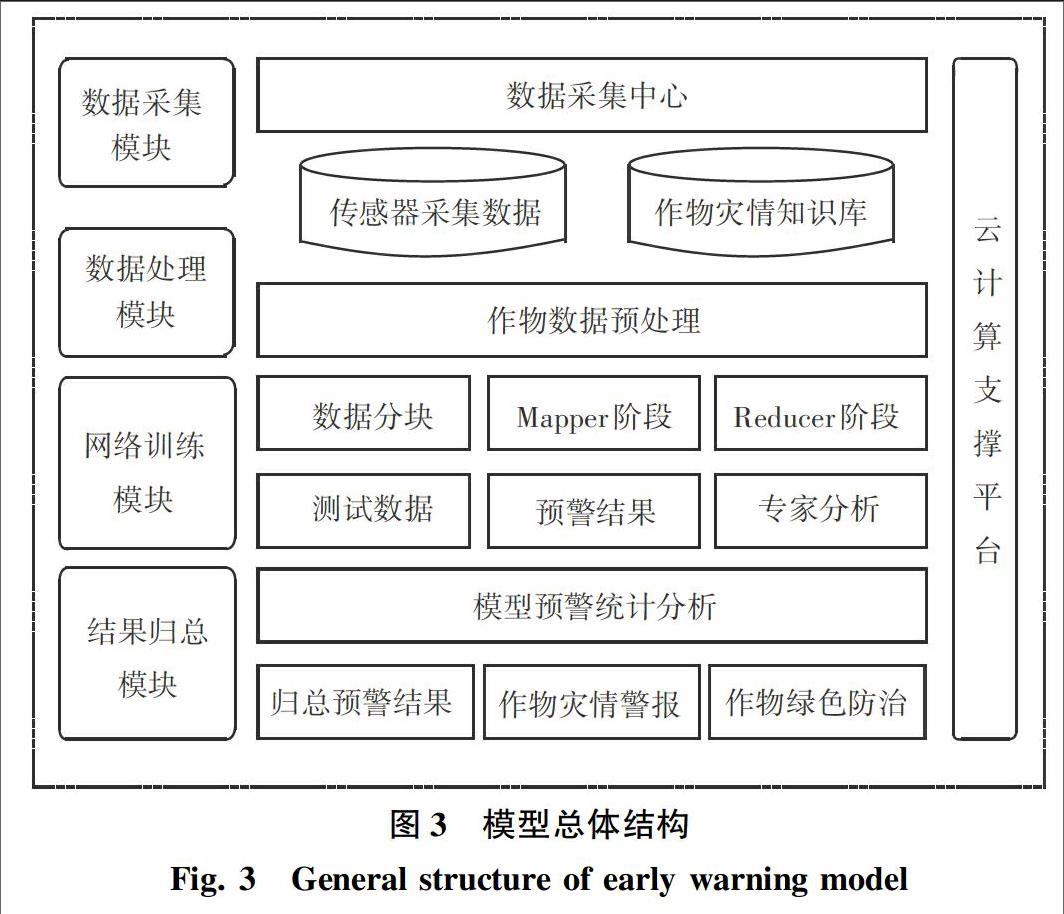
為了解析得到一個具備適應作物災情海量數據處理能力的BP神經網絡結構,本文采取在傳統BP結構的基礎上匹配指定一個數據處理模塊和結果歸總模塊,前者是建立在海量數據并行處理上的,采用Google提出的分布式并行編程模型組織集群處理大規模數據集,即Map-Reduce模型,后者是建立在動態調整加權歸總輸出的基礎上。至此,本文則基于開源Hadoop云計算支撐平臺,研究設計BP算法的Map-Reduce并行海量數據處理作物預警模型。模型總體結構如圖3所示。
由圖3可見,這里將給出模型總體結構中各個關鍵模塊的技術功能展示,可做如下論述。
1)數據處理模塊。采用Map-Reduce模型處理機制,作物災情數據經過設定操作后分割轉換為互不相交、最小分解的Task,主服務器對這些Task分析產生
2)網絡訓練模塊。利用Map-Reduce模塊輸出的結果集,拓展加入了MATLAB必要的數據處理后將產生網絡訓練樣本集,網絡訓練的目的也是為了得到最佳的權值閾值,利用誤差反向傳播調整權值。模型可以對后來數據進行預測判斷。
3)結果歸總模塊。網絡訓練模塊對多種數據構建自適應學習,得出預測結果集,本模塊將根據網絡訓練結果預測集合按照權重歸總得出最終預測結果,可結合專家意見后實現協同優化智能研判。
1.3 模型設計實現
1.3.1 建立數據采集中心
為了更好地對作物災情進行準確預測,對傳統數據采集個人使用的局面進行升級處理,在信息大爆炸時代,信息共享則顯得尤為重要,建立作物預警模型的基礎就是建立作物災情數據集群池,在農作物生長環境中架設多類傳感器實時采集存儲影響作物生長因素,研發創立了數據采集中心。采集的數據主要有作物的受害部位圖像、生長環境的溫濕度和土壤情況、平均風速、光照強度、降雨量等,作物信息數據可根據用戶的個人需求靈活選取、自主收集。
1.3.2 建立數據集群池
為了實現農作物災情數據信息共享最大化和統一管理高效化,就要規劃創建分布式數據集群模式化的存儲模型。數據采集中心利用云計算技術靈活調度全網區域資源合理分配,并對數據采集中心的數據提供高效可靠、整體統一的存儲管理,從而技術可行地實施建立了信息共享池。
1.3.3 數據預處理
數據處理模塊是網絡訓練模塊的前提基礎,也是整個作物預警模型的核心關鍵。數據預處理對于模型建立更是具有首要地位作用,數據處理的好與壞直接影響模型建立的成敗。本文提出采用Map-Reduce模型對數據共享池中的作物數據進行分類處理[8],以及運用MATLAB工具對數據集成設定加工處理及網絡訓練。
1.3.4 模型網絡訓練
數據處理后,網絡通過智能算法自學習找到樣本數據的自身規律,得到一般的非線性映射預測模型的權值和閾值。網絡訓練模塊充分利用云計算技術優勢,在網絡訓練時動態調整計算資源,明顯縮短訓練周期,高效快捷地得到準確度頗高的預警模型。
1.3.5 結果歸總輸出
為了準確預測作物災情,綜合多方面預測影響因素,即需對網絡訓練輸出結果集進行歸總處理,可根據準確度高低加進不同的權重對這些預測結果形成加權輸出。確定權重是重點關鍵,模型初態取平均比例,后期根據預測結果與實際結果的誤差大小設計選擇動態調整,調整規則可表述為:
1)初始狀態采用平均權重的方式進行歸總。
2)將輸出結果與期望結果來構建對比,偏差大的,權重相應減小;偏差小或無誤差的,權重相應增加;偏差不變的,權重保持不變。
3)若同一權重閾值的預測結果多次出現較大預測偏差,權重將會減小至零值,即該網絡的權重閾值將舍棄不用。
2 結束語
本文在BP基礎上融入云計算技術對研究模型結構進行調整優化,對預測結果綜合切入了多方位、多因素的全面考慮,對預測結果的準確度設計展開了動態調整優化,對于預測結果差、準確度低的實際輸出通過調整降權,使模型預測偏向預測準確度更高的一方,最終整體獲得智能高效的作物災情預測結果。經實踐驗證,模型呈現出良好的收斂性、較高的準確率以及較好的預測能力。作物災情數據資源池和知識庫的建立將為作物智能監控提供有力保障,突破傳統信息采集模式,實現作物實時監測與控制,進而提升我國農業生產智能化、管理科學化的發展水平。同時,模型還可準確地對作物災情進行預測,給農耕者和專家學者們報送有價值的作物生長狀況信息,并有利于及早做出合理的種植計劃、以及制定正確的決策部署,模型應用具有廣闊可觀現實前景。
參考文獻:
[1] 鄧維, 劉方明, 金海, 等. 云計算數據中心的新能源應用:研究現狀與趨勢[J]. 計算機學報, 2013, 36(3):582-598.
[2] 李成華, 張新訪, 金海, 等. MapReduce:新型的分布式并行計算編程模型[J]. 計算機工程與科學, 2011, 33(3):129-135.
[3] 劉萬才, 劉宇, 曾娟, 等. 推進農業有害生物數字化監測預警建設芻議[J]. 中國植保導刊, 2009, 29(10):11-15.
[4] 劉萬才, 武向文, 任寶珍, 等. 美國的農作物病蟲害數字化監測預警建設[J]. 中國植保導刊, 2010, 30(8):51-54.
[5] 劉宇, 劉萬才, 韓梅. 農作物重大病蟲害數字化監測預警系統建設進展[J]. 中國植保導刊, 2011, 31(2):33-35.
[6] 陳學斌, 張淑芬, 王向東. 物聯網在小麥病蟲草害監控中的應用[J]. 中國植保導刊, 2014, 34(5):38-42.
[7] 張寧. 關聯數據下的農業信息資源構建[J]. 中國農機化學報, 2013, 34(5):214-216.
[8] 陳學斌, 王師, 董巖巖. 面向大數據的并行分類混合算法研究[J]. 微電子學與計算機, 2016, 33(4):138-140.
猜你喜歡
數字技術與應用(2016年9期)2016-11-09 22:56:18
數字技術與應用(2016年9期)2016-11-09 00:07:05
知音勵志·社科版(2016年8期)2016-11-05 04:28:47
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
科技視界(2016年22期)2016-10-18 14:33:46
中國新通信(2016年16期)2016-10-18 10:49:17
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
