基于MapReduce的Apriori算法并行化改進
2017-05-02 05:43:22郝天曙董倩倩
計算機技術與發展 2017年4期
關鍵詞:數據庫
秦 軍,郝天曙,董倩倩
(1.南京郵電大學 教育科學與技術學院,江蘇 南京 210003;2.南京郵電大學 計算機學院,江蘇 南京 210003)
基于MapReduce的Apriori算法并行化改進
秦 軍1,郝天曙2,董倩倩2
(1.南京郵電大學 教育科學與技術學院,江蘇 南京 210003;2.南京郵電大學 計算機學院,江蘇 南京 210003)
基于MapReduce的并行Apriori算法解決了傳統Apriori算法多次掃描數據庫的問題,但是其候選集仍然由頻繁項集經過串行自連接產生,并產生了大量的候選集中間數據。為了提高Apriori算法挖掘頻繁項集的效率,在基于MapReduce的Apriori算法的基礎上對連接步進行并行化改進,提出大數據環境下挖掘頻繁項目集的新算法—CApriori算法。新算法通過Map、Reduce過程從頻繁k-項集中并行得到k+1項候選集,使得Apriori算法產生頻繁項集的整個過程并行化,減少了迭代過程中候選集數目,節約了存儲空間和時間開銷。通過對時間復雜度進行分析比較,改進算法在處理大規模數據時會大大減少連接步的時間消耗。將CApriori算法在Hadoop平臺上進行了實驗,結果表明改進算法在大數據和較小支持度環境下都具有更高的效率,且能取得優異的加速功能。
關聯規則;數據挖掘;MapReduce;Apriori
0 引 言
關聯規則[1]挖掘用于從大量數據中挖掘出有價值的數據項之間的相關關系。關聯規則揭示了數據項間未知的依賴關系,根據所挖掘的關聯關系,可以從一個數據對象的信息來推斷另一個數據對象的信息。關聯規則最為經典的是Apriori算法,該算法采用逐層迭代方法,通過連接和剪枝得到頻繁項集。其缺點是重復掃描數據庫,產生大量的候選集,算法效率較低。因此,國內外很多學者通過布爾矩陣、哈希技術、基于事務壓縮矩陣相乘、分區技術和采樣技術等對Apriori算法進行改進和優化,提出基于Apriori算法的并行算法,包括:CD、DD以及CaD算法。然而,這些算法很難處理具有大容量、多樣性、快速度、商業價值高的“4V”特征大數據。例如:基于壓縮事務矩陣相乘的改進算法在矩陣相乘上花費了較多時間[2];并行算法CD、DD和CaD[3]在通信和同步方面都存在一些問題。
云計算為提高海量數據挖掘效率提供了新思路。MapReduce是一種編程模式,它可以產生并處理海量數據集。MapReduce編程模型的一個關鍵優勢在于它能自動處理運行故障,隱藏很多繁瑣的細節并且可以在物理集群上實現并行化處理。國內外學者應用MapReduce思想對Apriori進行了并行化改進[4-7],但是這些改進的Apriori算法只考慮計數步,產生了大量的候選集中間數據,或者多次掃描全局數據庫,以一種空間代價換取時間代價的方法來加速頻繁項集的產生。當數據集很大而且支持度低時,將會產生巨大候選集,嚴重影響算法的運行效率。
文中提出通過并行的Map,Reduce過程從頻繁k-項集中并行得到k+1項候選集Ck+1,極大減少了迭代過程中候選集數量,節約了大量的存儲空間和自連接結果在各個節點之間傳輸的網絡開銷、時間開銷,從而提高了算法的執行效率。改進算法稱之為完全并行Apriori算法,即CApriori算法。
1 基本概念
Apriori算法是挖掘關聯規則頻繁項集的最經典的算法[8],但傳統的關聯規則挖掘技術已經不能滿足大數據的需求,因此云技術與數據挖掘的融合以及改進成為當下焦點。本節主要介紹Apriori算法以及MapReduce框架模型。
1.1 Apriori算法
通過反復掃描數據庫,Apriori算法逐層搜索候選項集,最終目的在于迭代地產生頻繁項集。Apriori算法的思想[9]為:通過k次掃描產生長度為k的頻繁k-項集Lk,通過串行自連接產生候選項集Ck+1;統計事務集DB中所有長度為k+1的候選集Ck+1的出現次數,直到無法再找到頻繁項集。可見,每找出一個Lk,需要掃描一次數據庫,而且產生的候選集也極為龐大。
Apriori算法時間主要消耗在三個方面:
(1)Apriori算法在執行“連接-剪枝”的迭代過程中需要多次掃描數據庫,如果生成的頻繁項目集中含有k-項集,則要掃描k遍數據庫。當k數值較大時,系統I/O負載非常大,每次掃描時間就會很長。
(2)頻繁項集自身連接生成候選項集時,所產生的侯選項集數目龐大。若事務數據集中頻繁項集長度為30,至少會產生230-1=109個候選集。
(3)當頻繁項集巨大,串行自連接產生候選集將消耗很長時間。
1.2 MapReduce編程模型
MapReduce[10]模型的基本思想是將問題分解為兩個處理階段—Map階段和Reduce階段[11],由用戶實現的Map函數和Reduce函數完成大規模的并行化計算。開源的云計算平臺Hadoop實現了MapReduce模型。在該模型中,數據文件被切分成大小相同的多個數據分片存儲在Hadoop分布式文件系統HDFS[12]中。在input階段,MapReduce支持庫將數據分片的記錄解析為
2 基于MapReduce的CApriori算法
通過分析基于MapReduce框架下的Apriori算法,針對其并行化存在的不足提出CApriori算法。對比MapReduce框架下的CApriori算法和Apriori算法的時間復雜度,證明CApriori算法在處理海量數據時的先進性,并把CApriori算法移植到MapReduce框架下實現海量數據集的挖掘。
2.1 MapReduce框架下的Apriori算法
運用Apriori算法掃描存儲海量的數據庫時將消耗大量的時間和內存空間,這成為了Apriori算法的瓶頸。雖然對Apriori算法進行并行優化改進,但是隨著數據規模的增大,傳統的并行方案因資源需求過大或通信消耗過多而變得低效[13]。Apriori算法利用MapReduce“分而治之”的設計思想生成頻繁項集:對事物數據進行水平分割,將事務數據庫DB水平劃分為n個規模相當的數據塊,然后把數據塊發送到m個節點;運行Map程序,通過掃描每個數據塊,找出頻繁1-項集,再產生每個數據塊的局部候選k項集Ck,局部候選項集的產生算法與經典Apriori算法相同,采取串行自連接的方式產生候選集;編寫Combine將Map階段結果進行合并;利用Reduce函數生成全局候選頻繁項集;依次迭代,找出所有頻繁項集。
基于MapReduce的Apriori算法減少了對事物數據庫的依賴,執行效率相對于傳統的Apriori算法提高顯著,但是在迭代過程中會產生巨大候選集數目,連接步依然由頻繁項集Lk-1自連接生成候選項集Ck,非常耗時。
2.2 Apriori算法并行化改進
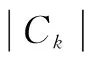
具體思路:把上一輪迭代產生的頻繁k-項集Lk分割成若干份相同的數據塊,然后調用Mapper接口對每個數據塊進行Map函數處理。通過Map函數的處理,產生一組新的
實例如圖1所示。
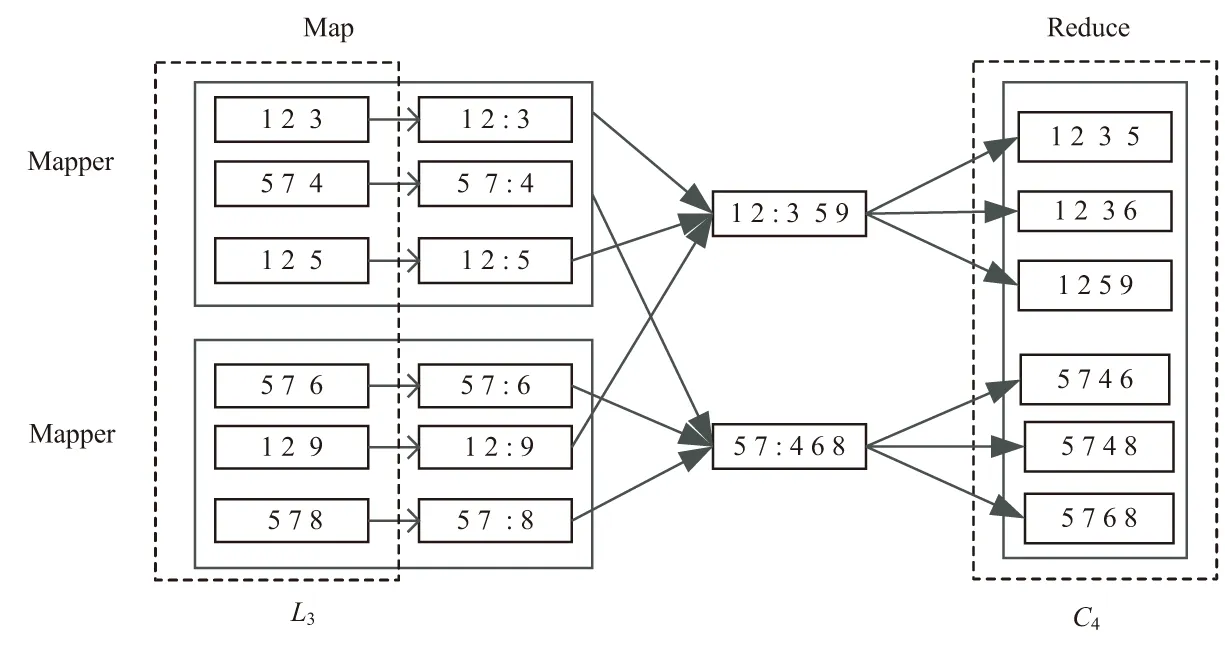
圖1 CApriori連接步具體實現
輸入的頻繁項集L3被分割成塊,傳送給Map函數;Map函數把頻繁{1,2,3}變換成一個鍵值對{{1,2}:3},然后具有相同鍵的鍵值對會組合起來形成{1,2,3 5 9}傳遞給Reduce函數。Reduce函數對鍵值對進行處理,形成候選集C4。
Apriori算法連接步的時間復雜度是O(|Lk|2)。CApriori算法的連接步時間復雜度由三部分組成,即Map,Reduce階段以及在Map函數和Reduce函數通信時間,具體如式(1)所示。
Tc=Tmap+Tcomm+Treduce
(1)
其中,Tc表示總時間;Tmap表示Map階段消耗時間;Tcomm表示兩個函數的通信時間;Treduce表示Reduce階段消耗時間。
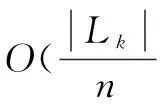
(2)
其中,Vkey(i)為i-1項事務集;num為事務個數;n為Reduce函數個數。
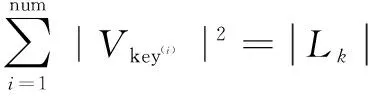
在MapReduce并行框架下,數據集的大小對通信時間影響輕微,定義通信時間為t。然后,可以算出CApriori連接步的時間復雜度,如式(3)所示。
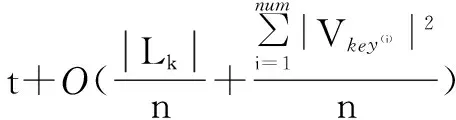
(3)
基于MapReduce的CApriori算法產生頻繁項集的具體實現流程如下:
(1)對事物數據進行水平分割。InputFormat將事務數據庫DB水平劃分為n個規模相當的數據塊,并將n個數據塊格式化為
(2)運行Map程序,通過掃描每個數據塊,將輸入的鍵值對轉換成<項,支持度>格式。Map函數先找出頻繁1-項集。
(3)為了減少節點間的通信量,編寫Combiner[14]將Map階段本地輸出的不同數據塊有相同候選集的支持度進行合并,減少輸出中間結果的數據量,降低網絡延時,增加傳輸效率。
(4)利用Reduce函數把滿足最小支持度的局部頻繁項集合并,對不滿足最小支持度的項進行剪枝操作,生成全局候選頻繁項集。
(5)通過Reduce階段得到的頻繁項集并行產生候選集。把頻繁項集分割成若干份相同的數據塊,然后調用Mapper接口對每個數據塊進行Map函數處理。通過Map函數對數據塊的處理,把頻繁項集變換成鍵值對,Map函數獨自處理輸入的數據塊;然后具有相同鍵的鍵值對會組合起來并將(key,values)傳遞給Reduce函數。每個Reduce函數得到的是從所有Map節點傳過來的具有相同的鍵的鍵值對。Reduce函數把鍵與值分開生成候選集。
(6)頻繁項集為空時停止整個過程,否則k=k+1循環步驟(3)~(5)。
3 實 驗
3.1 實驗環境
選取11臺計算機在Linux環境下建立Hadoop集群,Hadoop平臺版本為2.2,操作系統均采用Ubuntu12.04,JDK版本為Sun JDK1.7。一臺計算機作為Master和JobTracker服務節點,其他10臺計算機作為Slave TaskTracker服務節點,每個節點的處理器為Intel酷睿i5,4 GB內存。使用某超市銷售數據作為實驗數據集,共1 025 840條事務,有50個不同的項,其中最長的事務有40項。基于MapReduce對CApriori算法和Apriori算法在數據集上進行了實驗操作,通過實驗數據說明了CApriori算法性能的優越性。
3.2 實驗結果與分析
實驗一:首先設置支持度為0.5%,數據集大小為1 025 840條事務,觀察CApriori算法和Apriori算法在不同數目節點上運行的時間,如圖2所示。
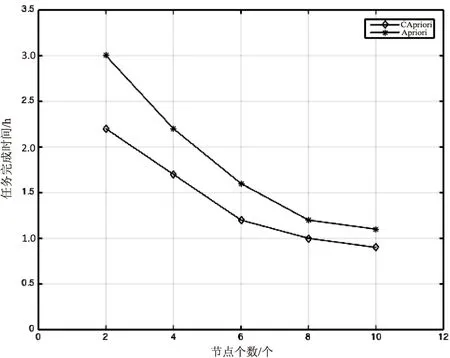
圖2 兩種算法在不同節點下的運行時間
從圖2中可以看出:當計算機節點數目相同時,CApriori算法比Apriori算法運行時間短,體現了CApriori算法的優越性。當計算機節點數目增加時,計算所需的時間減少。這是因為MapReduce把數據劃分成片分布到不同的服務器節點上,并行執行算法,提高了運行效率。但是隨著節點數的增加,再增加節點數對減少運行時間已沒有多大幫助,最終會使系統性能達到瓶頸。
實驗二:在10臺計算機集群上處理1 025 840條事務集,設置支持度為0.4,0.5,0.6,0.7,結果如圖3所示。
從圖3中可以看出,支持度越小,CApriori算法比Apriori算法的效率越高。這是由于支持度越小挖掘過程中會產生更多候選集,Apriori算法自連接消耗更多時間。在數據集很大且支持度很低的情況下,傳統并行Apriori算法會出現死機現象。
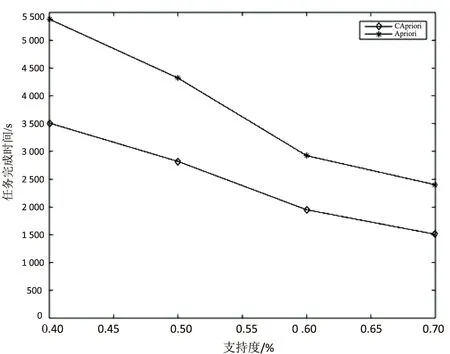
圖3 兩種算法在不同支持度下的運行時間
實驗三:為了便于觀察實驗改進效果,選取十萬個數據集為基數,設置支持度為0.5%,在10臺計算機集群上挖掘不同大小數據塊,結果如圖4所示。
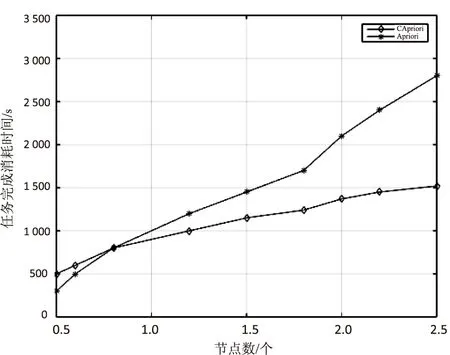
圖4 兩種算法在不同數量集下的運行時間
從圖4中可以看出,在數據規模較小時,CApriori算法的平均效率低于傳統并行Apriori算法。這是由于剪枝步分布式計算中對節點的管理和分配增加了額外的計算開銷,在事務規模較小的時候這個開銷占了主要運行時間。隨著項目集的增加,傳統并行Apriori算法的時間消耗迅速上升,遠大于CApriori算法,體現了CApriori算法的優越性。這是因為傳統并行Apriori算法在計算候選項集時使用串行自連接方法,尤其在處理海量數據集時,自連接產生的候選集的數量非常大,大大增加了MapReduce處理時間。而CApriori算法,通過并行的Map,Reduce過程來產生下一輪的候選集,其大大減少了MapReduce處理時間。
4 結束語
文中提出一種基于MapReduce的Apriori算法的并行化改進算法CApriori。在現有的并行Apriori算法的基礎上,頻繁k-項集Ck通過并行的Map,Reduce過程來得出下一輪的候選集Ck+1。實驗結果表明,與傳統Apriori算法計算頻繁項集執行時間相比,CApriori執行速度快,明顯提高了挖掘效率。
[1]HippJ,GüntzerU,NakhaeizadehG.Algorithmsforassociationrulemining-ageneralsurveyandcomparison[J].ACMSIGKDDExplorationsNewsletter,2000,2(1):58-64.
[2] 羅 丹,李陶深.一種基于壓縮矩陣的Apriori算法改進研究[J].計算機科學,2013,40(12):75-80.
[3]AgrawalR,ShaferJC.Parallelminingofassociationrules[J].IEEETransactionsonKnowledge&DataEngineering,1996,8(6):962-969.
[4] 劉 鵬.云計算[M].第2版.北京:北京工業大學出版社,2011.
[5]LiL,ZhangM.Thestrategyofminingassociationrulebasedoncloudcomputing[C]//Internationalconferenceonbusinesscomputingandglobalinformatization.Shanghai:IEEE,2011:475-478.
[6] 張 圣.一種基于云計算的關聯規則Apriori算法[J].通信技術,2011,44(6):141-143.
[7] 朱安柱.基于Hadoop的Apriori算法改進與移植的研究[D].武漢:華中科技大學,2012.
[8]AgrawalR,ImielinskiT,SwamiA.Databasemining:aperformanceperspective[J].IEEETransactionsonKnowledgeandDataEngineering,1993,5(6):914-925.
[9] 張 震,汪斌強,陳庶樵,等.基于多維計數型布魯姆過濾器的大流檢測機制[J].電子與信息學報,2010,32(7):1608-1613.
[10] 張建勛,古志民,鄭 超.云計算研究進展綜述[J].計算機應用研究,2010,27(2):429-433.
[11] 孫芬芬.海量數據并行挖掘技術研究[D].北京:北京交通大學,2014.
[12] 章志剛.云計算環境下頻繁項目集挖掘算法研究[D].南京:南京師范大學,2014.
[13] 王 鄂,李 銘.云計算下的海量數據挖掘研究[J].現代計算機,2009(11):22-25.
[14] 李玲娟,張 敏.云計算環境下關聯規則挖掘算法的研究[J].計算機技術與發展,2011,21(2):43-46.
Parallel Improvement of Apriori Algorithm Based on MapReduce
QIN Jun1,HAO Tian-shu2,DONG Qian-qian2
(1.College of Education Science & Technology,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
The parallel Apriori algorithm based on the MapReduce solves the problem that the traditional Apriori algorithm scans database for many times,but the candidates are still generated from the connection of serial by the frequent itemsets and generate a large number of data.In order to improve the efficiency of mining frequent itemsets for Apriori,an improved parallel Apriori algorithm named CApriori is proposed in large data environment,which realizes parallel candidate generation steps under MapReduce framework.The new algorithm generates thek+1candidateitemsetsfromkfrequentitemsetsthroughtheprocessofMapandReduce,whichmakesthewholeprocessofgeneratingfrequentitemsetsinparallel,reducingthenumberofcandidatesets,savingstoragespaceandtimeoverhead.OnanalysisofthetimecomplexityofCApriorialgorithmandApriorialgorithm,itindicatesthatCApriorialgorithmreducesthetimeconsumedwhenconnectedindealingwithlarge-scaledata.CAprioriisexecutedonHadoopplatformandtheresultsshowthattheimprovedalgorithminbigdataenvironmentandsmallersupportismoreefficient,andcanobtainexcellentacceleration.
association rules;data mining;MapReduce;Apriori
2016-04-27
2016-08-17
時間:2017-02-17
江蘇省自然科學基金項目(BK20130882)
秦 軍(1955-),女,教授,研究方向為計算機網絡技術、多媒體技術、數據庫技術;郝天曙(1991-),男,碩士研究生,研究方向為計算機網絡技術、云計算。
http://www.cnki.net/kcms/detail/61.1450.TP.20170217.1632.070.html
TP
A
1673-629X(2017)04-0064-05
10.3969/j.issn.1673-629X.2017.04.015
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
