基于機器學(xué)習(xí)的多語言文本抽取系統(tǒng)實現(xiàn)
2017-04-24 10:24:53周國富
計算機應(yīng)用與軟件 2017年4期
曾 軍 周國富
(武漢大學(xué)軟件工程國家重點實驗室 湖北 武漢 430072)
基于機器學(xué)習(xí)的多語言文本抽取系統(tǒng)實現(xiàn)
曾 軍 周國富
(武漢大學(xué)軟件工程國家重點實驗室 湖北 武漢 430072)
基于統(tǒng)計機器學(xué)習(xí)的信息抽取方法正日益成為研究的熱點,在研究與應(yīng)用方面雖然也產(chǎn)生了一些實用的基于機器學(xué)習(xí)的文本信息抽取框架與系統(tǒng),但大多面臨著交互性弱、可擴展性低、語言移植能力差等缺陷。為此,研究并提出一種通用可行的支持多語言的信息抽取框架,并基于該框架實現(xiàn)了一個原型系統(tǒng)。原型系統(tǒng)集成了最大熵、支持向量機兩種機器學(xué)習(xí)算法,使用這兩種算法對中英文文本的實驗驗證了系統(tǒng)的實用性。
統(tǒng)計機器學(xué)習(xí) 信息抽取 多語言 最大熵模型 支持向量機
0 引 言
網(wǎng)絡(luò)技術(shù)的高速發(fā)展造就了海量的電子文本資源,如何從眾多的電子文本中自動、迅速、準(zhǔn)確地得到用戶所感興趣的信息正日益成為一個亟待解決的重大研究課題,基于統(tǒng)計機器學(xué)習(xí)的信息抽取方法可以很好地滿足這一需求。近年來,隨著已標(biāo)注樣本集的不斷增加與積累,基于統(tǒng)計機器學(xué)習(xí)的信息抽取技術(shù)的研究與應(yīng)用受到越來越多研究者的青睞,而本文研究的主題正是基于機器學(xué)習(xí)的文本信息抽取。
盡管當(dāng)前抽取算法的研究發(fā)展相對迅速,但對于信息抽取系統(tǒng)的設(shè)計還不充分。主要的問題包括:1)有一些文本抽取系統(tǒng)只是針對特定的應(yīng)用,如GATE中集成的ANNIE,能夠識別“地名”,“句子成分”等,但不能廣泛地直接用在其他抽取任務(wù);2)有一些系統(tǒng)只是針對一種特定的抽取算法,如Amilcare,集成了LP2,但不能集成其他算法;3)有一些系統(tǒng)只使用一種語言的文本。這些問題就使得對一個新的領(lǐng)域的信息抽取任務(wù)或者對一個現(xiàn)有信息抽取任務(wù)應(yīng)用另一種不同的機器學(xué)習(xí)算法,幾乎所有的工作都要重新開始。那么是否能夠設(shè)計和實現(xiàn)一個信息抽取的平臺,使得不同的信息抽取任務(wù),和應(yīng)用不同的抽取模型都能夠在這個平臺上方便的進行呢?這就是本文所關(guān)注的主要內(nèi)容。
針對當(dāng)前信息抽取系統(tǒng)存在的交互性弱、可擴展性低、語言移植能力差等缺點,本文設(shè)計和實現(xiàn)了一個實用的、易于擴展的、具有較好移植性的基于機器學(xué)習(xí)的信息抽取系統(tǒng),該系統(tǒng)能夠充分利用機器學(xué)習(xí)算法以及系統(tǒng)模塊化設(shè)計的優(yōu)勢,達(dá)到較好的可擴展性與可移植性。
1 信息抽取系統(tǒng)模型
1.1 機器學(xué)習(xí)抽取過程
圖1給出了基于機器學(xué)習(xí)進行信息抽取的通用流程。首先在訓(xùn)練樣本集和測試樣本集上,根據(jù)文檔中信息特點來進行特征定義與算法選擇,然后將特征和算法相結(jié)合在訓(xùn)練樣本集上進行學(xué)習(xí)以構(gòu)造抽取模型,最后再在測試集文檔上使用構(gòu)造的信息抽取模型進行模型測試。
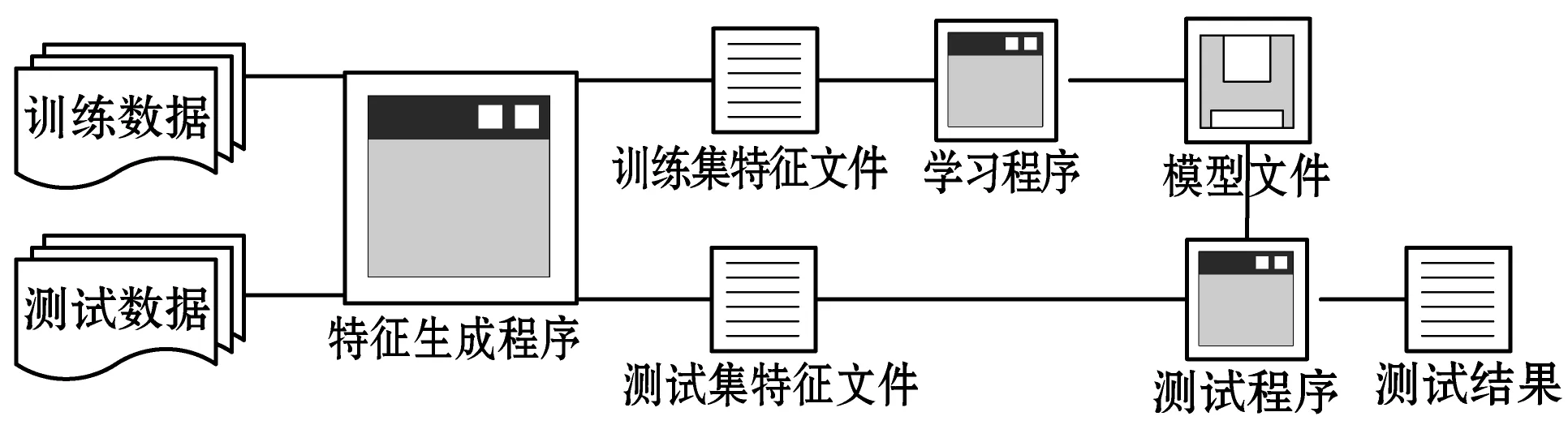
圖1 基于機器學(xué)習(xí)的通用抽取流程
1.2 信息抽取系統(tǒng)的框架設(shè)計
基于上述信息抽取流程本文設(shè)計的基于機器學(xué)習(xí)的支持多語言的文本信息抽取系統(tǒng)的整體框架如圖2所示。
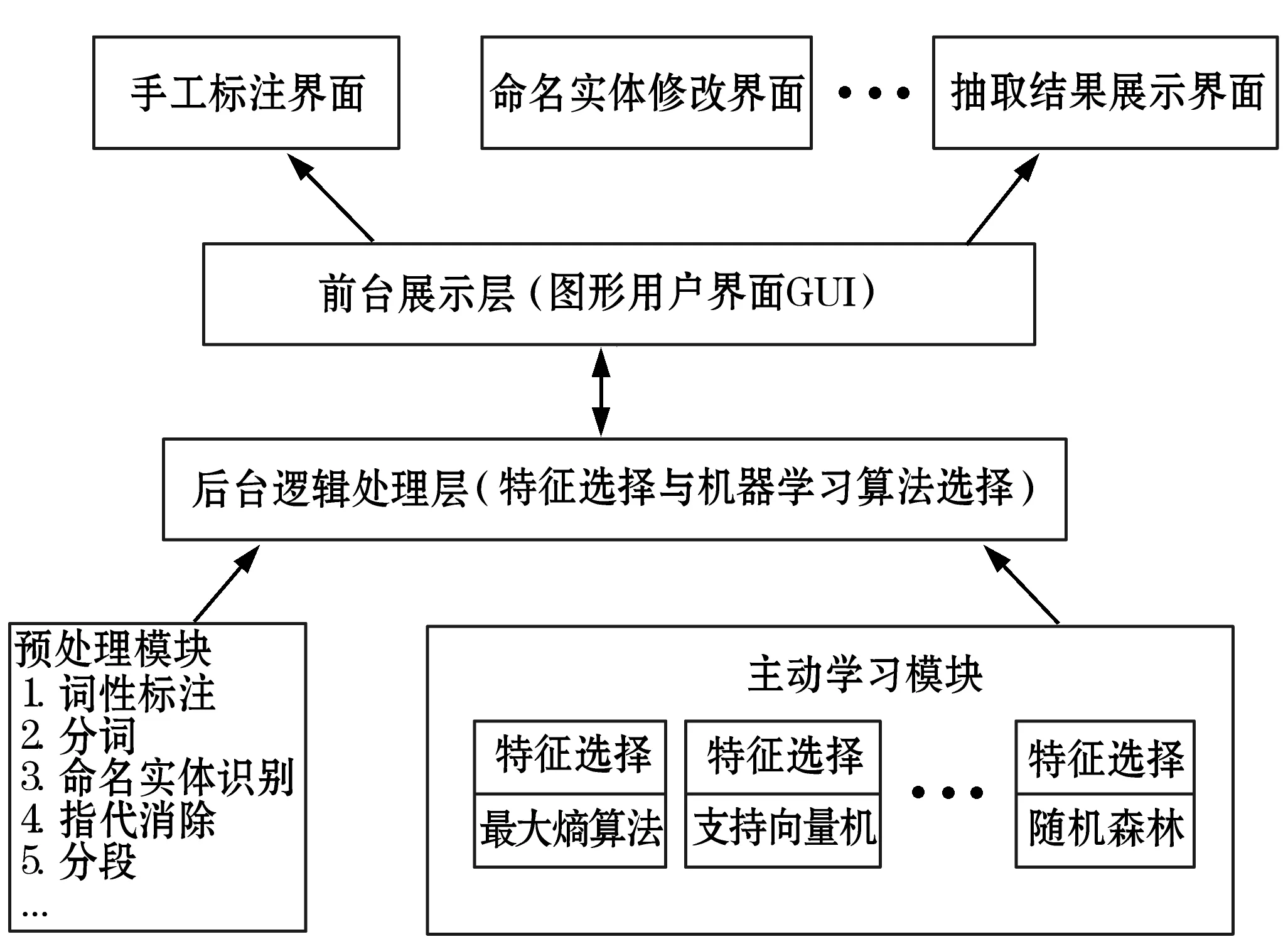
圖2 基于信息抽取系統(tǒng)整體框架
該框架分為兩個層次:前臺展示層和后臺邏輯處理層。前臺展示層,主要用在抽取的不同階段,通過友好的圖形用戶界面GUI的方式為用戶觀察和處理數(shù)據(jù)提供方便,同時也簡化了用戶的操作流程。后臺邏輯處理層主要包括預(yù)處理模塊和主動學(xué)習(xí)模塊。預(yù)處理模塊主要用于對錄入的文檔進行文本符號化、詞性標(biāo)注、分詞等操作,每一個步驟都可以根據(jù)需要進行個性化定制。主動學(xué)習(xí)模塊包括特征選擇的子模塊與機器學(xué)習(xí)分類算法選擇子模塊兩個部分,主要用于根據(jù)已標(biāo)注的文檔進行機器學(xué)習(xí),之后利用主動學(xué)習(xí)所訓(xùn)練的抽取模型對未標(biāo)注的文檔進行信息抽取。其中,特征可以從給定的通用特征中選擇符合數(shù)據(jù)樣本特點的特征,也可以使用用戶自定義的特征;機器學(xué)習(xí)算法也同樣可以根據(jù)用戶需要進行個性化定制,這樣可以方便用戶選擇不同的特征或者機器學(xué)習(xí)方法進行模型訓(xùn)練與信息抽取,最終找到抽取效果較優(yōu)的參數(shù)組合。此外,前臺展示層和后臺邏輯處理層之間是通過規(guī)定的接口進行通信的。
該框架的優(yōu)勢主要體現(xiàn)在:①分層的設(shè)計增強了系統(tǒng)的靈活性與可擴展性;②模塊化設(shè)計增強了系統(tǒng)的魯棒性與可移植能力;③預(yù)處理模塊的可定制化設(shè)計提高了系統(tǒng)的語言移植能力。例如對于中文文檔的信息抽取,預(yù)處理模塊中的分詞操作可以指定調(diào)用分詞效果較好的中科院開發(fā)的中文分詞工具NLPIR[7];對于英文文檔信息抽取可以指定為比較常用的Stanford CoreNLP[8]提供的分詞接口。
1.3 抽取過程特征選擇
從通用抽取流程和系統(tǒng)整體框架可以看出,信息抽取的關(guān)鍵在于特征生成程序的編寫以及機器學(xué)習(xí)算法的選擇。
對于特征的選擇,可以采用集成一些通用的特征的方式以供用戶進行選擇的方法,如“單詞或漢字的數(shù)目”,“是否在同一句”,實體總數(shù)等特征。同時,可以將通用特征集劃分為兩類類別,并將其定義為稀疏性特征集與聚簇性特征集。如果一個特征被加入稀疏特征集中,那么該特征將被用于構(gòu)造文本的線性分類器。同樣,如果一個特征被加入聚簇性特征集中,那么該特征將被用于構(gòu)造文本的非線性分類器。
信息抽取用戶可以根據(jù)需要從通用特征中的選擇一個或多個通用特征用于信息抽取系統(tǒng)。當(dāng)然,用戶也使用自定義的特征進行信息抽取。
1.4 抽取過程算法選擇
對于機器學(xué)習(xí)算法,可以選擇采用最大熵算法(EM)與支持向量機算法(SVM),也可以選擇一些其他開源的機器學(xué)習(xí)算法,以便對它們的抽取效果與性能作比較。本文為了觀察不同算法的抽取效果實現(xiàn)了EM與SVM兩種算法。下面本文將以文本分類為實驗,以最大熵算法為例構(gòu)造一個簡單的自動文本分類系統(tǒng),其中實驗語料來自譚松波博士的個人主頁[9]中提供的中文文本分類語料庫。該語料庫分為兩個層次:一個層次為12個類別,另一個層次為60個類別,其中每個層次都包含文本14 150篇。本實驗采用12個類別的單層語料,語料的類別與數(shù)據(jù)詳細(xì)信息具體如下表1所示。
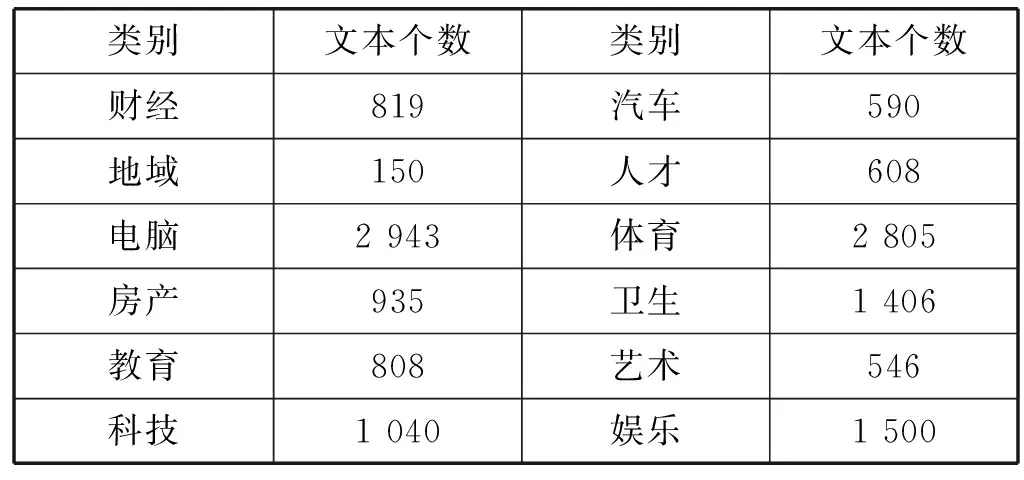
表1 實驗中使用的單層語料的類別與數(shù)目
利用最大熵算法進行文本分類的具體實驗步驟如下所示:
(1) 收集數(shù)據(jù)集:從譚松波博士的網(wǎng)站個人主頁將本實驗用到的分類語料下載到本地。
(2) 預(yù)處理數(shù)據(jù)集:基于python語言編寫一個預(yù)處理腳本,該腳本主要用于統(tǒng)計所有文本中的單詞,計算每個文本中每個單詞的詞頻,并將其中80%的文作為訓(xùn)練樣本集,另外20%作為測試樣本集。
(3) 模型構(gòu)建:筆者基于python語言實現(xiàn)了完整的GIS[10](Generalized Iterative Scaling)算法。之后使用GIS算法在上一步處理好的訓(xùn)練文本上對表征每個特征權(quán)重的數(shù)組參數(shù)向量lamda進行參數(shù)訓(xùn)練,其中精度閾值ε設(shè)定為0.001,并且在訓(xùn)練樣本集上運行GIS算法時對模型參數(shù)的最大迭代次數(shù)maxLooNum采用不同的取值,以觀察迭代次數(shù)對算法分類效果的影響。
(4) 模型測試:根據(jù)上一步估計的參數(shù)向量lamda的值,對預(yù)處理的測試樣本集進行測試,并計算測試文本中錯誤分類文本的個數(shù)以及錯誤分類文本率。
(5) 實驗完成:整理實驗結(jié)果,如表2所示。
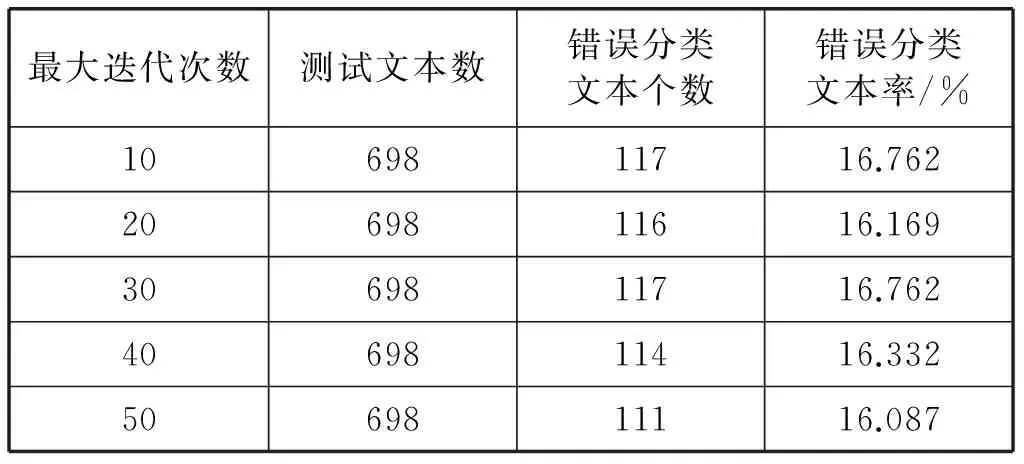
表2 設(shè)置不同最大迭代次數(shù)時的文本分類效果
從表2中的實驗結(jié)果可以看出,最大熵算法的文本分類效果還是可以接受的,且隨著迭代次數(shù)的增加,錯誤分類的文本個數(shù)以及錯誤文本率的整體呈遞減趨勢。從表2還可以看出,最大迭代次數(shù)并不是越大越好,也有可能會出現(xiàn)迭代次數(shù)增加,而錯誤分類文本的個數(shù)反正增加的特殊情況。如表中當(dāng)最大迭代次數(shù)為20的時的錯誤分類文本個數(shù)反而要比最大迭代次數(shù)為30時的錯誤分類文本個數(shù)要小。
2 信息抽取系統(tǒng)的實現(xiàn)
基于上文所設(shè)計的抽取框架和機器學(xué)習(xí)算法,本文基于Python語言實現(xiàn)了一個原型系統(tǒng)。主要包括圖形用戶界面GUI、預(yù)處理模塊、主動學(xué)習(xí)模塊。
2.1 圖形用戶界面GUI的實現(xiàn)
該模塊主要將信息抽取過程中的一些操作以圖形化界面GUI的方式友好地展示給信息抽取人員,以提高信息抽取人員的操作效率。該模塊主要包括實體類型管理、實體事件管理、實體關(guān)系管理、抽取文檔管理以及標(biāo)記管理,如圖3所示。
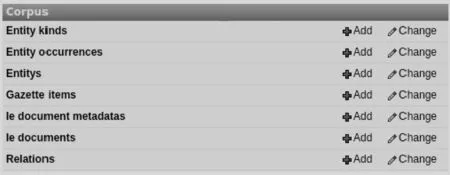
圖3 抽取系統(tǒng)圖形用戶界面GUI
實體類型管理默認(rèn)使用的是Stanford NER[11](Stanford Named Entity Recognizer)中識別的實體類型,在預(yù)處理階段,信息抽取系統(tǒng)會進行命名實體識別操作以對文檔進行自動分析與發(fā)現(xiàn),并創(chuàng)建相應(yīng)的實體類型。
實體事件管理,在預(yù)處理階段信息抽取系統(tǒng)會通過Stanford NER對待抽取文檔進行自動分析以發(fā)現(xiàn)并創(chuàng)建實體事件,其中記錄了實體事件的名稱、實體事件所在的文本段以及實體事件所在的開始偏移量與結(jié)束偏移量。
實體關(guān)系管理,主要用于預(yù)定義抽取的目標(biāo),即自定義待抽取的實體關(guān)系。在原型系統(tǒng)中,在主動學(xué)習(xí)模塊執(zhí)行之前,需要信息抽取人員在實體關(guān)系管理子模塊定義一個實體關(guān)系,之后按照圖形用戶界面GUI的提示對待抽取文檔進行標(biāo)記以達(dá)到學(xué)習(xí)的目的。
此外,該系統(tǒng)提供兩種方式的數(shù)據(jù)樣本集錄入方式:一種是在抽取文檔管理模塊中將準(zhǔn)備好的數(shù)據(jù)樣本進行逐個添加,另一種則是將數(shù)據(jù)樣本以csv文件格式進行整合,之后只需將此csv格式的文件導(dǎo)入系統(tǒng)中即可,其導(dǎo)入格式csv文件的范例如圖4所示。

圖4 csv文件范例
其中第一行
標(biāo)記管理主要用于主動學(xué)習(xí)模塊的模型訓(xùn)練。在創(chuàng)建實體關(guān)系并運行主動學(xué)習(xí)模塊之后,系統(tǒng)會以交互式的方式讓信息抽取人員以對訓(xùn)練文檔以逐個標(biāo)記的方式進行模型訓(xùn)練。
2.2 預(yù)處理模塊的實現(xiàn)
在預(yù)處理模塊,本文采用的是Stanford CoreNLP用于對輸入文檔進行處理。Stanford CoreNLP是斯坦福大學(xué)使用Java語言開發(fā)的一套開源自然語言分析工具包,該工具包整合了多種自然語言處理技術(shù),其中包括:詞性標(biāo)注、命名實體識別、句法分析、共指消解、情感分析、引導(dǎo)模式學(xué)習(xí)等工具。
原型系統(tǒng)的預(yù)處理操作:文本符號化和句子分割、文本詞形化、詞性標(biāo)注、命名實體識別、指代消解、句法分析以及文本分段都使用Stanford CoreNLP中提供的接口進行處理。由于篇幅限制本文只對Stanford CoreNLP提供的句法分析工具進行簡單的說明介紹。
句法分析就是分析出句子的語法結(jié)構(gòu),得出語法結(jié)構(gòu)樹并將其存儲在Penn Treebank notation中。本文原型系統(tǒng)通過NLTK Tree object將語法結(jié)構(gòu)樹在圖形用戶界面GUI中展示給信息抽取人員。默認(rèn)情況下,原型系統(tǒng)采用Stanford CoreNLP工具提供的Stanford Parser對句子進行句法分析。例如,對于英文文本“Join the dark side, we have cookies.”經(jīng)Stanford Parser解析后得到的語法結(jié)構(gòu)樹如圖5所示。

圖5 Stanford Parser解析后得到的語法結(jié)構(gòu)樹
預(yù)處理模塊雖然默認(rèn)了許多的步驟,對文本進行一系列的處理,但是該模塊中的每一步都可以根據(jù)信息抽取用戶的需要進行個性化定制,以體現(xiàn)原型系統(tǒng)的可擴展性與可移植性。
下面以mongoDB文檔為例,觀察其經(jīng)過預(yù)處理后的結(jié)果,如表3所示。
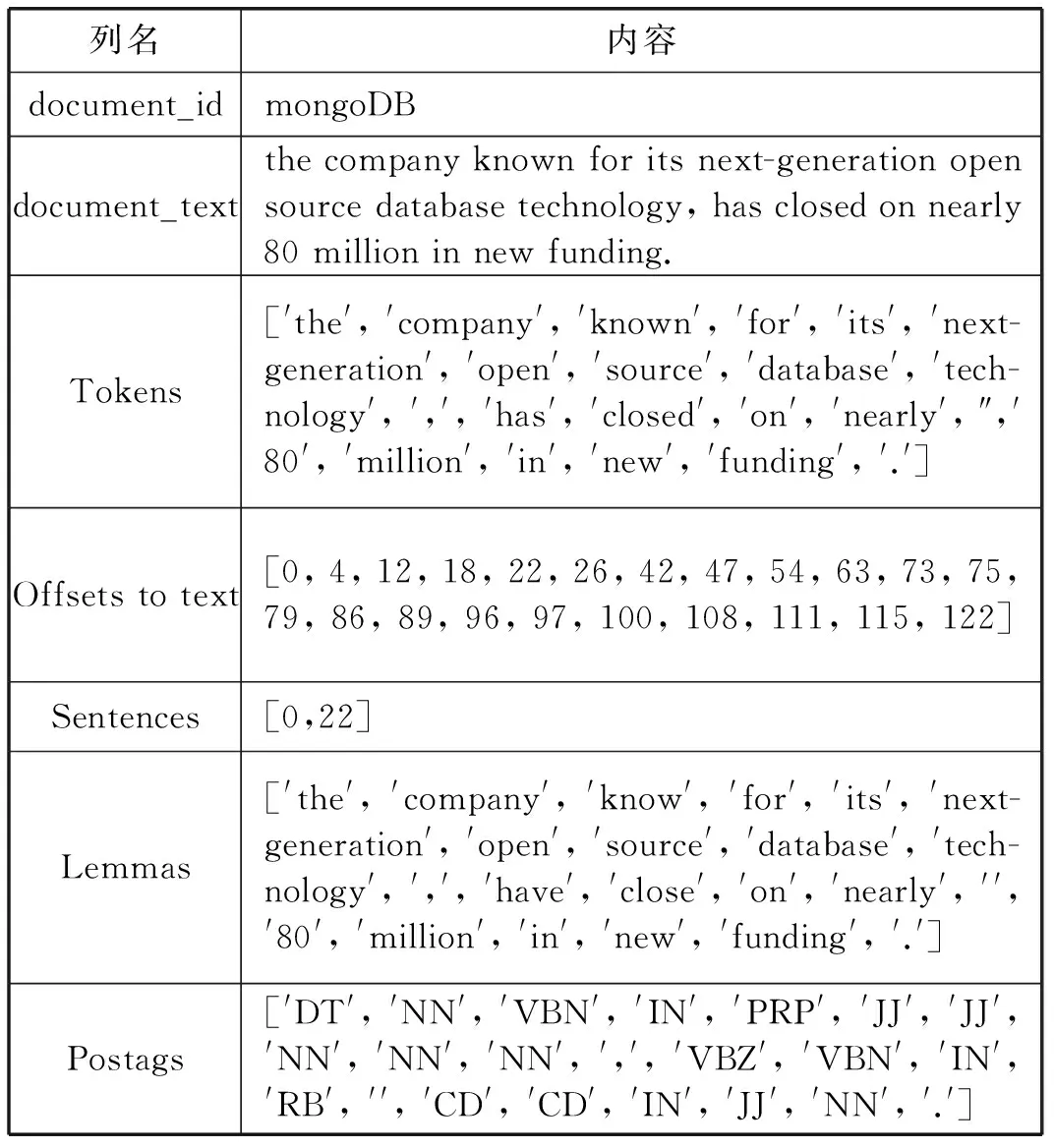
表3 mongoDB文檔經(jīng)過預(yù)處理階段后的結(jié)果展示
2.3 主動學(xué)習(xí)模塊的實現(xiàn)
該系統(tǒng)提供了兩種運行主動學(xué)習(xí)的模式:高精確度模式和高召回率模式。它們可以相互協(xié)調(diào)以達(dá)到滿意的抽取性能。例如可以通過減少召回率來得到較高的精確度;同樣也可以通過減少精確度來獲得較高的召回率。
另外,在主動學(xué)習(xí)模塊運行之后,原型系統(tǒng)會在圖形用戶界面上提示用戶進行訓(xùn)練樣本集的標(biāo)注工作,同時在后臺的命令行界面也為信息抽取人員提供了與用戶交互的三個命令:run、refresh以及STOP。其中run命令的作用就是根據(jù)系統(tǒng)獲得的標(biāo)注信息重新運行主動學(xué)習(xí);refresh的作用則是查看信息抽取人員已經(jīng)標(biāo)記了多少個訓(xùn)練樣本;STOP的作用就是停止主動學(xué)習(xí)模塊。下面以事先建立的實體關(guān)系“funded”為例來查看主動學(xué)習(xí)模塊運行之后的后臺命令行的提示情況,如圖6所示。

圖6 后臺命令行的提示情況
本文原型系統(tǒng)默認(rèn)提供了一些常用的機器學(xué)習(xí)算法用于主動學(xué)習(xí),其中包括隨機梯度下降算法、k近鄰算法、最大熵算法、支持向量機算法。本文主要使用的最大熵算法以及支持向量機算法。
對于特征的選擇,該系統(tǒng)也提供了一些通用的特征,如“實體間距離”、“實體的數(shù)量”等。
3 實驗結(jié)果與分析
3.1 評估指標(biāo)
MUC[12](Message Understanding Conference)作為信息抽取領(lǐng)域的頂級會議,采用的評價標(biāo)準(zhǔn)被廣泛應(yīng)用,本文也采用其評價標(biāo)準(zhǔn)來對系統(tǒng)性能進行評價。MUC系列會議主要使用以下三個評估標(biāo)準(zhǔn):精確度PRE(Precision,正確抽取的個數(shù)占全部抽取個數(shù)的百分比)、召回率REC(Recall正確抽取的個數(shù)占全部可能正確抽取個數(shù)的百分比)以及F值(前兩者的加權(quán)平均值)。cn、ln、en分別表示正確抽取的實體關(guān)系個數(shù)、沒有抽取出的實體關(guān)系個數(shù)和錯誤抽取的實體關(guān)系個數(shù),那么其對應(yīng)的評估標(biāo)準(zhǔn)的結(jié)果為:
精確度:
(1)
召回率:
(2)
F值:
(3)
其中,β是PRE和REC的權(quán)重之比。當(dāng)β等于1時,表示兩者同等重要;當(dāng)β大于1時,表示PRE比REC更重要;當(dāng)β小于1時,表示REC比PRE更重要。在MUC會議的評估指標(biāo)上,β的值常被設(shè)定為:0.5、1或2,在本文中取β為1。
此外,本文增加了一個時間性能指標(biāo)用于對信息抽取系統(tǒng)的抽取效率進行評估。時間性能指標(biāo)主要用于評估信息抽取系統(tǒng)抽取一篇文檔平均所需要花費的時間。dn表示信息抽取系統(tǒng)一次性抽取的文檔數(shù)目,t表示抽取dn篇文檔所消耗的時間(以秒為單位),那么平均抽取時間AT(篇/s)的計算公式為:
(4)
3.2 實驗內(nèi)容
本實驗在Ubuntu14.04LTS操作系統(tǒng)下,采用上一節(jié)所設(shè)計并實現(xiàn)的原型系統(tǒng)進行實體關(guān)系的信息抽取實驗。為了觀察和分析原型系統(tǒng)的可移植能力與可擴展性,筆者從美國知名科技新聞聚合網(wǎng)站TechCrunch中、英文版中分別收集了300篇與“funded”領(lǐng)域相關(guān)的文檔,總共600篇(即,文檔分為兩類:300篇英文文檔和300篇中文文檔)。對于其中的每一類文檔的240篇用于原型系統(tǒng)的主動學(xué)習(xí),剩下的60篇用于原型系統(tǒng)的抽取測試。
為了便于展示本文基于機器學(xué)習(xí)的支持多語言文本信息抽取系統(tǒng)的抽取效果與語言移植能力,本實驗將原型系統(tǒng)分別對中、英文文本在兩種模式下運行:基于最大熵算法的機器學(xué)習(xí)模式、基于支持向量機的機器學(xué)習(xí)模式,并分別對中、英文測試數(shù)據(jù)集進行信息抽取。實驗的具體步驟如下所示:
(1) 收集實驗數(shù)據(jù)。使用基于python的爬蟲框架Scrapy從美國新聞聚合網(wǎng)站TechCrunch中、英文版上分別爬取300篇和funded有關(guān)的新聞文章,并存儲于本地文件夾中。
(2) 實驗數(shù)據(jù)的分類與格式化處理。使用基于python編寫的隨機分類腳本將這些文本隨機分入兩個文件夾中,一個文件夾存入樣本集中的80%文本用于對模型進行訓(xùn)練,另一個文件夾存入剩下的20%用于對模型的測試。用事先編寫好的格式化腳本分別將訓(xùn)練樣本集和測試樣本集整合為一個csv格式的文件,其中存儲測試樣本集的文件名為testSet.csv,存儲訓(xùn)練樣本集的文件名為trainSet.csv。
(3) 訓(xùn)練數(shù)據(jù)集導(dǎo)入原型系統(tǒng)。使用以下命令將訓(xùn)練數(shù)據(jù)導(dǎo)入到原型系統(tǒng)中:
python bin/csv_to_iepy.py trainSet.csv
(4) 運行預(yù)處理模塊。為了對輸入的文檔集進行自動分詞、詞性標(biāo)注、文本分段等操作,使用以下命令運行預(yù)處理模塊:
python bin/preprocess.py
(5) 創(chuàng)建待抽取實體關(guān)系。在圖形用戶界面GUI的實體關(guān)系管理模塊新建待抽取的實體關(guān)系,并指明實體關(guān)系中左側(cè)實體類型以及右側(cè)實體類型,其中的實體類型從預(yù)處理模塊產(chǎn)生的類型中選擇。本實驗中,創(chuàng)建的實體關(guān)系名為“funded”,左側(cè)實體類型選擇的是ORGANIZATION,右側(cè)實體類型選擇的是MONEY。
(6) 運行主動學(xué)習(xí)模塊構(gòu)造模型。用于如下方法開啟主動學(xué)習(xí)模塊:
python bin/iepy_runner.py funded outputFileName
這一步需要進入抽取系統(tǒng)的GUI主頁,并按照提示進行手動標(biāo)注。
(7) 測試數(shù)據(jù)集導(dǎo)入原型系統(tǒng)。使用以下命令將訓(xùn)練樣本集導(dǎo)入到原型系統(tǒng)中:
python bin/csv_to_iepy.py testSet.csv
(8) 運行主動學(xué)習(xí)或規(guī)則抽取對測試數(shù)據(jù)樣本集進行信息抽取。
(9) 將事先準(zhǔn)備的240篇中文文本,同樣執(zhí)行上述步驟(2)-步驟(8)中所執(zhí)行的操作,并且將第(4)步中預(yù)處理模塊的接口修改為中科院提供的接口,以便對中文文本進行信息抽取。
(10) 實驗結(jié)果整理與分析。
3.3 實驗結(jié)果與分析
按照上述實驗步驟,并經(jīng)過對實驗結(jié)果的適當(dāng)整理,得到該信息抽取系統(tǒng)在基于最大熵算法的機器學(xué)習(xí)模式、基于支持向量機的機器學(xué)習(xí)模式分別對60篇中文檔和60篇英文文檔測試樣本集的信息抽取結(jié)果在精確度、召回率和F值這三個指標(biāo)上的表現(xiàn),如表4所示。
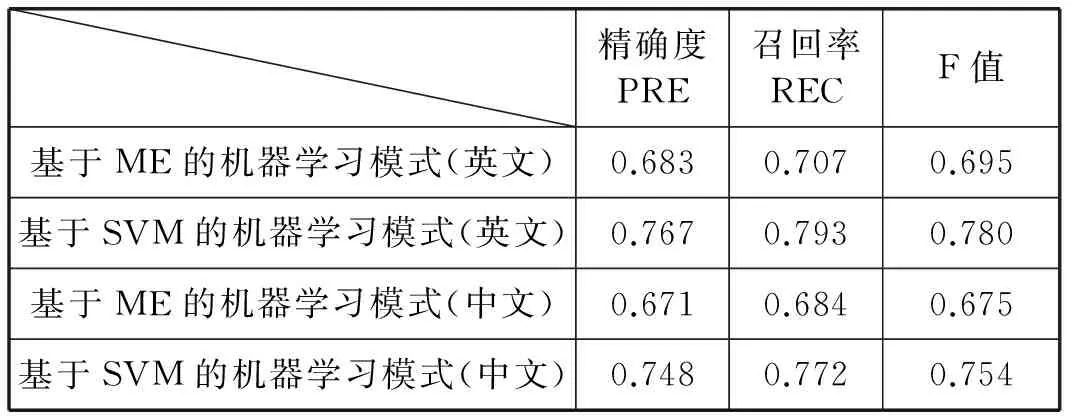
表4 兩種模式在中英文文本精確度、召回率、F值上的比較
對于兩種基于機器學(xué)習(xí)的信息抽取系統(tǒng)的抽取效果在精確度、召回率和F值三個指標(biāo)上的表現(xiàn),可以從表4中的實驗結(jié)果可以看出基于SVM算法的信息抽取方法在三個評估指標(biāo)上的表現(xiàn)要比基于ME的機器學(xué)習(xí)算法的抽取效果要好一些。同時兩種算法在文本分類中有不錯的精確度。
從表5可以看出在時間性能指標(biāo)上,兩種機器學(xué)習(xí)算法在對中文文本進行信息抽取所需要花費的平均抽取時間要比對英文文本進行信息抽取要多,其原因主要是在對中文文本進行處理時,需要在預(yù)處理模塊中增加中文分詞的任務(wù),而英文文本由于詞與詞之間存在空格等天然優(yōu)勢,所以不需要對其進行分詞處理。
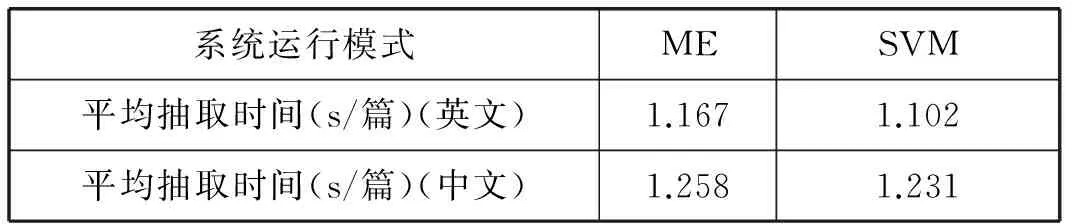
表5 兩種模式在中英文文本上時間性能的比較
4 結(jié) 語
本文基于對已有信息抽取流程的研究,以及對其中每個階段可能存在的問題進行分析,設(shè)計了一種通用可行的支持多語言的文本信息抽取框架,并基于該框架實現(xiàn)了一個原型系統(tǒng)。
對于原型系統(tǒng)的實驗結(jié)果可以看出,不管是在精確度、召回率、F值三個指標(biāo)上,還是在時間性能指標(biāo)上,對英文文本進行處理的原型系統(tǒng)都可以很好地遷移到了中文文本的處理上,表現(xiàn)出了原型系統(tǒng)較好的可移植能力。另外,在處理中文文本時需要增加英文文本處理所不需要的分詞模塊,然而由于原型系統(tǒng)的模塊化設(shè)計與個性化定制,此時只需在預(yù)處理模塊中添加上中科院提供的分詞接口即可,這在一定程度上展現(xiàn)了原型系統(tǒng)較好的語言移植能力與可擴展能力,達(dá)到了目的。
[1] Jacobs P S. Text-based intelligent systems: Current research and practice in information extraction and retrieval[M]. London: Psychology Press, 1992.
[2] Alpaydin E. Introduction to machine learning[M]. 2nd ed. Cambridge, MA, USA: The MIT press, 2014.
[3] Bontcheva K, Derczynski L, Funk A, et al. TwitIE: An Open-Source Information Extraction Pipeline for Microblog Text[C]//Proceedings of Recent Advances in Natural Language Processing, 2013: 83-90.
[4] Yao X, Durme B V. Information Extraction over Structured Data: Question Answering with Freebase[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014: 956-966.
[5] Rebentrost P, Mohseni M, Lloyd S. Quantum support vector machine for big data classification[J]. Physical Review Letters, 2014, 113(13): 130503.
[6] Wu N. The maximum entropy method[M]. Berlin: Springer, 2011.
[7] Zhou L, Zhang D. NLPIR: A theoretical framework for applying natural language processing to information retrieval[J]. Journal of the American Society for Information Science and Technology, 2003, 54(2): 115-123.
[8] Manning C D, Surdeanu M, Bauer J, et al. The Stanford CoreNLP Natural Language Processing Toolkit[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2014: 55-60.
[9] 譚松波, 王月粉. 中文文本分類語料庫-TanCorpV1.0[EB/OL]. http://www.searchforum.org.cn/tansongbo/corpus.htm.
[10] Goodman J. Sequential conditional Generalized Iterative Scaling[C]//Proceedings of the 40thAnnual Meeting on Association for Computational Linguistics, 2002: 9-16.
[11] The Stanford Natural Language Processing Group. Stanford named entity recognizer[OL]. http://nlp.stanford.edu/software/CRF-NER.shtml.
[12] Surhone L M, Tennoe M T, Henssonow S F, et al. Message Understanding Conference[M]. Mountain View, CA, USA: Betascript Publishing, 2010.
[13] 何清, 李寧, 羅文娟, 等. 大數(shù)據(jù)下的機器學(xué)習(xí)算法綜述[J]. 模式識別與人工智能, 2014, 27(4): 327-336.
[14] 成衛(wèi)青, 于靜, 楊晶, 等. 基于頁面分類的Web信息抽取方法研究[J]. 計算機技術(shù)與發(fā)展, 2013, 23(1): 54-58.
[15] 昝紅英, 張騰飛, 林愛英. 基于介詞用法的事件信息抽取研究[J]. 計算機工程與設(shè)計, 2013, 34(7): 2570-2574.
[16] 孫師堯, 妙全興. 基于改進SVM和HMM的文本信息抽取算法[J]. 計算機應(yīng)用與軟件, 2015, 32(11): 281-284,292.
[17] 涂眉, 周玉, 宗成慶. 基于最大熵的漢語篇章結(jié)構(gòu)自動分析方法[J]. 北京大學(xué)學(xué)報(自然科學(xué)版), 2014, 50(1): 125-132.
[18] 汪海燕, 黎建輝, 楊風(fēng)雷. 支持向量機理論及算法研究綜述[J]. 計算機應(yīng)用研究, 2014, 31(5): 1281-1286.
IMPLEMENTATION OF MULTI-LANGUAGE TEXT INFORMATION EXTRACTION SYSTEM BASED ON MACHINE LEARNING
Zeng Jun Zhou Guofu
(StateKeyLaboratoryofSoftwareEngineering,WuhanUniversity,Wuhan430072,Hubei,China)
The method of information extraction based on statistical machine learning is becoming a hot research topic day by day. Although there are some practical frameworks and systems for text information extraction based on machine learning, most of them face weaknesses such as weak interactivity, low scalability and poor language transplanting ability. To solve this problem, a universal and feasible information extraction framework based on multi-language is proposed and implemented, and a prototype system is implemented. The prototype system integrates the maximum entropy and support vector machines, and the two algorithms are used to verify the practicability of the system in both English and Chinese texts.
Statistical machine learning Information extraction Multi-language ME SVM
2016-02-27。曾軍,碩士生,主研領(lǐng)域:數(shù)據(jù)挖掘。周國富,副教授。
TP39
A
10.3969/j.issn.1000-386x.2017.04.016
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
