一種改進的深度學習視頻分類方法
2017-04-22 10:11:30楊曙光
現代計算機 2017年8期
楊曙光
(四川大學計算機學院,成都 610065)
一種改進的深度學習視頻分類方法
楊曙光
(四川大學計算機學院,成都 610065)
目前在深度學習領域最典型的視頻分類方法是3D卷積深度網絡。但是3D卷積網絡對于較長的視頻只能把視頻截成小段,分別提取特征向量,求均值,最后在特征均值基礎上進行分類。均值操作會造成分類精度下降,針對此問題,提出一種改進的方法,對3D卷積方法提取的短視頻特征放入LSTM進行序列識別,并通過實驗來驗證改進的有效性。
視頻分類;3D卷積深度網絡;LSTM;深度學習
0 引言
視頻分類在視頻分析中具有重要意義,目前在深度學習中經典的視頻分類方法是3D卷積深度網絡。3D卷積深度網絡巧妙地利用了2D卷積深度網絡在圖像分類中的優勢,通過在時間維度增加一維卷積來達到對視頻數據的分類。相比于傳統算法,不用人工提取復雜的圖像特征,可以實現端到端的訓練。3D卷積深度網絡是一種空間網絡,由于受深度網絡后端全連解層的影響,在設計3D卷積深度網絡的時候,我們必須首先確定網絡輸入視頻的寬、高和幀數。由于限制了固有的幀數,當模型要對很長的視頻進行分類時,就必須把長視頻分成一段段長度相等的短視頻,對這些短視頻進行3D卷積運算會提取一段段特征向量,對得到的特征向量求均值得到一個均值特征向量,然后把均值特征向量放入最后的Softmax層進行分類。
視頻本質上是一個時序數據,視頻幀之間如果發生錯亂就會破壞這個視頻數據的規律性。而上述3D卷積深度網絡對提取的短視頻特征向量加和求均值的做法就會破壞時序特性。反過來思考,對于特定的一堆數字,無論怎么打亂它們的次序,加和求均值后的結果總是不變的。所以加和求均值不會反映原來數據的次序性。
針對這個問題,本文提出用LSTM融合3D卷積網絡來分類視頻。LSTM是一種時序識別網絡,加入LSTM可以克服3D卷積深度網絡中對提取的特征加和求均值所帶來的時序丟失問題。
1 改進的3Dcnn-LSTM算法流程圖及原理
典型的3D卷積深度網絡視頻分類的流程如圖1所示,可以看到原始長視頻片段被分成一個個短視頻片段,每個短視頻片段通過3D卷積深度網絡后都會提取到一個特征,所有的提取特征加和求均值后的值放入最后的分類層進行分類。
改進的3Dcnn-LSTM融合模型的視頻分類流程如圖2所示,可以看出,3D卷積網絡已經成為了LSTM的特征提取層,長視頻被分成一個個短視頻,每個短視頻通過3D卷積網絡時候被提取成一個特征向量,特征向量又被送如LSTM,不斷重復這一過程,直至所有短視頻片段識別完成。這一過程對比傳統的3D卷積方法能夠更加合理地處理視頻分類的問題,對于一個超長視頻識別問題來說,通過3D卷積來識別視頻短跨度的規律,通過全局的LSTM來識別視頻的長跨度的規律。
就像2D卷積網絡比較擅長圖像分類一樣,3D卷積神經網絡對一定幀長的視頻分類比較優秀。LSTM是在RNN(Recurrent Neural Networks)基礎上發展起來的一種優秀的序列識別網絡,通過加入輸入門、輸出門以及遺忘門等結構,再加上誤差流截斷等技術,很大程度上克服了RNN梯度消失和爆炸等問題,特別適合序列問題的識別。所以LSTM和3D卷積神經網絡來識別視頻是符合視頻數據的特征原理的。
2 試驗介紹
本次實驗對比在UCF101上進行。為了分析兩種算法的有效性,分別在UCF101上進行了5類、30類、101類的試驗對比。
(1)數據集介紹
UCF101[3]是從YouTube上收集的一個行為識別數據集,它包含了101類行為,共13320個短視頻。UCF101通過拍攝相機的運動,拍攝對象的外觀姿勢變化,目標尺度變化,背景光照的變化,視角的變化來保證數據的多樣性。每一類的視頻分為25組,每組有4到7個短視頻,每一組里的視頻有許多共有特征,例如:相似的背景、相似的視角等。
視頻總體上可分為五大類:人與物互動,人與人互動,肢體運動,演奏樂器,體育運動。在詳細的類別上有小孩爬行,射箭,籃球運動,刷牙,跳高,騎自行車,遛狗等,類別如圖3所示。

圖3 UCF101數據的代表類別圖
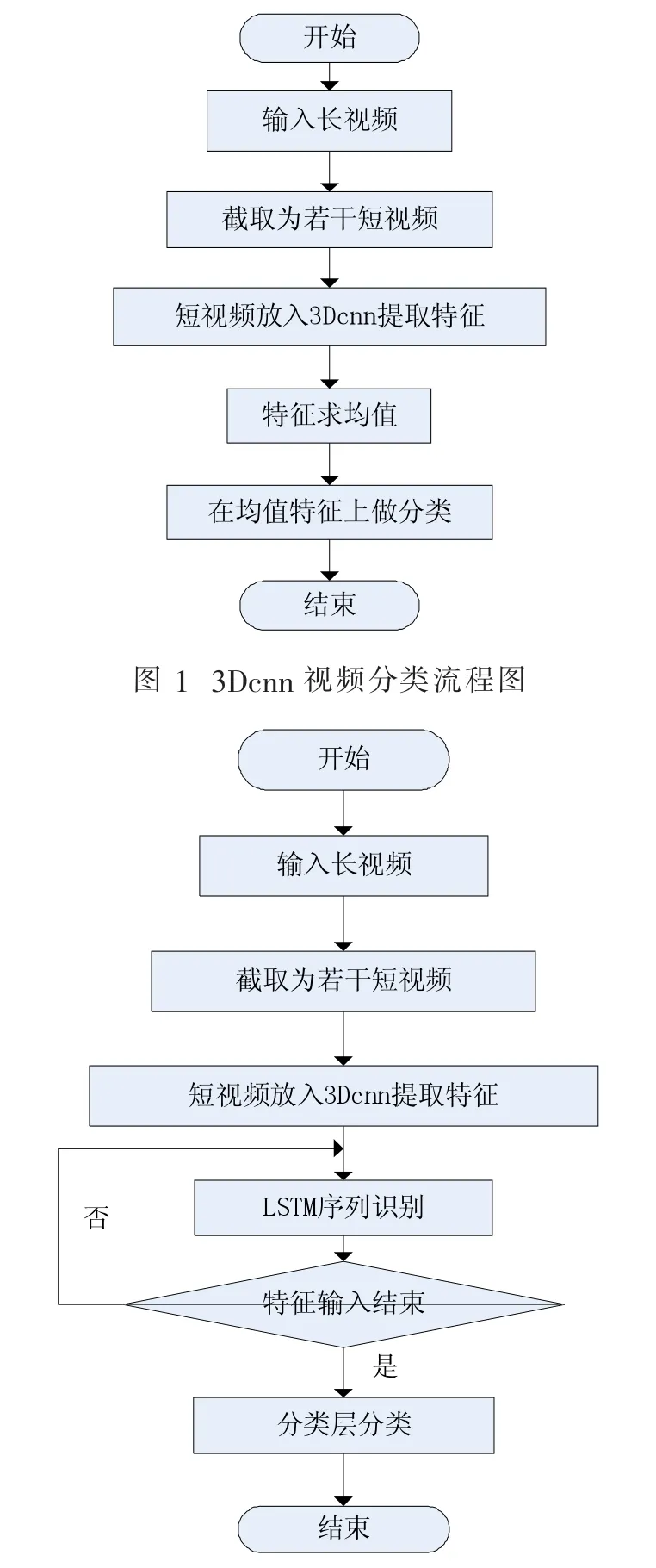
圖2 3Dcnn-LSTM視頻分類流程圖
(2)數據預處理
原始視頻是三通道的320×240彩色圖像,在實驗過程中綜合考慮了運行的時間成本和試驗精度,把視頻放縮為54×40。在時間維度上,原始視頻是每秒24幀,由于相鄰視頻幀之間的動作差異性很小,數據的冗余性很大,冗余的數據一方面會降低運算速度,另一方面也會增加分類識別難度,所以本文對視頻進行了丟幀處理,具體做法就是每三幀丟掉兩幀,總的視頻識別長度是240幀,丟幀后,輸入網絡的數據是80幀,分成16個幀序列,每個幀序列有5幀。UCF101雖說是當前比較全,也是比較大的視頻數據集之一,但是一萬多的樣本對于深度神經網絡來說還是太少了,所以為了克服過擬合的問題,本文采用了圖像增強技術,對每個視頻就行了視頻的水平反轉,抖動生成3個視頻。
(3)網絡設計
考慮到視頻樣本的不足又沒有一個訓好的3D卷積網絡來做遷移學習,本文設計了一個比較小的8層神經網絡功能層,3個3D卷積層,2個池化層,一個LSTM層,一個全連接層,一個Softmax分類層。各層都采用ReLU作為激活函數,為了克服過擬合問題,在最后一個3D卷積層之后加入了BN(Batch Normalization)層。在實驗中發現這樣的網絡配置還是容易過擬合,為了解決這個問題,被迫采用了遷移學習的技術,但是在做遷移學習遇到困難,因為沒有現成的訓好的3D卷積網絡,也沒有數量龐大,質量很好的視頻樣本來供自己預訓練網絡,最后采取了一個折中的方法,首先用Cifar100數據集來預先訓練一個2D卷積神經網絡,然后把這個2D卷積網絡擴充成3D卷積網絡,用這個擴充的3D卷積神經網絡來初始化網絡參數。具體網絡結構如表1所示。
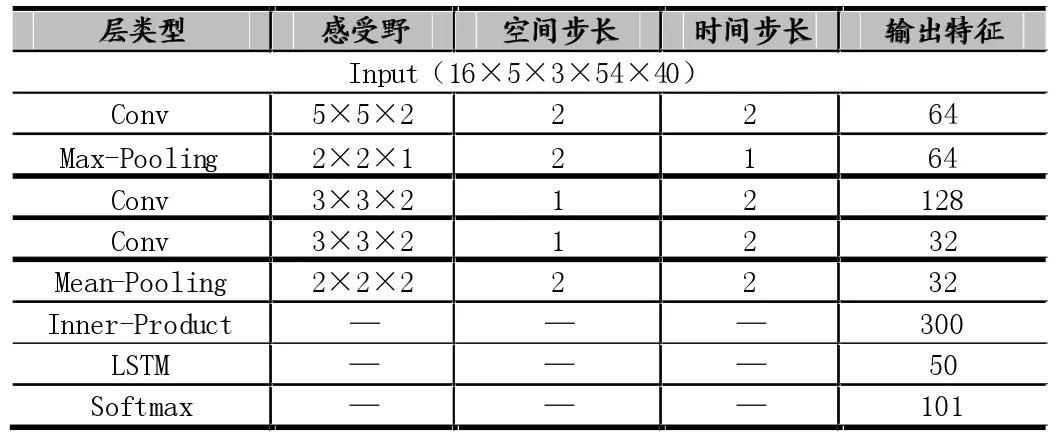
表1 深度分類網絡
3 結果討論
本次實驗是在Theano框架上進行,在圖像分類中我們已經有了預訓練好的模型來做遷移學習,這些模型是指百萬級別甚至千萬級別的優質數據上訓練的,所以做遷移學習時能夠很好的避免過擬合,遺憾的是,截至到目前,視頻領域的優質數據集還遠遠達不到這個規模,所以也沒有一個成熟的預訓練模型來初始化3D卷積模型的參數,本文在這方面做了很多嘗試,發現即使用成熟的大型的2D卷積網絡擴展成3D卷積網絡來初始化參數,做UCF101數據集的分類,仍會出現過擬合現象,所以本文采用了一個小型的2D卷積網絡在cifar100上做預先訓練,訓練出的參數擴展成3D卷積網絡,然后用擴展成的網絡做參數初始化,用初始化的3D卷積網絡來訓練視頻分類器。
本文為了對比改進算法的有效性,分別進行了5類,30類,101類的視頻分類試驗。5類,30類是從UCF101數據集中隨機抽取的,101類是全部的UCF101數據集。基本網絡采用表1的網絡,不同類別只是把最后的分類層的輸出個數進行更改,對比的3D卷積網絡只是把表1的LSTM層去掉,優化算法采用自適應adadelta優化方法。結果發現在5類視頻分類任務上,3D卷積網絡能夠達到75%的準確率,改進的3Dcnn-LSTM算法可以達到80%的準確率;在30類的分類任務上,3D卷積網絡可以達到57%的準確率,而改進的3D-LSTM算法可以達到63%的準確率;在101類的識別任務上,3D卷積網絡能夠達到39%的準確率,而改進的3Dcnn-LSTM可以達到43%的準確率。
從試驗結果上看,我們的改進算法在各種條件下都是優于經典的3D卷積網絡的,證明了改進算法的有效性。
4 結語
本文把序列識別網絡LSTM和3D卷積網絡融合在一起來做視頻的分類,彌補了經典3D卷積網絡的時序丟失問題,使得分類精度更高。由于視頻相對于圖像數據量要大很多,訓練普通圖像模型很快的機器來訓練視頻分類任務就特別慢,所以本實驗不得把視頻的分辨率調到很低,這些因素顯然會影響分類的精度。另外目前優質的大規模的視頻數據集的缺少使得訓練大規模的3D卷積模型比較困難,3D卷積模型要從2D模型的基礎上進行擴展來進行遷移學習,這也在很大程度上影響了分類的精度。本實驗只是這些不利情況下進行的試驗對比,相信兩種模型都沒發揮出它們的最大潛力,未來隨著計算速度的提升和公共大型優質的視頻數據集的完善,兩種模型尤其是改進的3Dcnn-LSTM模型會有很大的精度提升。
參考文獻:
[1]Shui-wang Ji,Wei Xu,Ming Yang,Kai Yu,D Convolutional Neural Networks for Human Action Recognition,Pattern Analysis and Machine Intelligence,IEEE Transactions on(Volume:35,Issue:1),2013
[2]S.Hochreiter,J.Schmidhuber.Long Shortterm Memory.Neural Computation,9(8):1735-1780,1997.
[3]K.Soomro,A.R.Zamir,M.Shah.UCF101:A Dataset of 101 Human Action Classes from Videos in the Wild.CRCVTR-12-01, November,2012.
An Improved Video Classification Method of Deep Learning
YANG Shu-guang
(College of Computer Science,Sichuan University,Chengdu610065)
3D Convolutional Neural Networks is the most typical video classification method in deep learning at present.But the 3D convolution network can only segment the long video into many short videos,extract the feature vectors of those short videos,solve the mean value of those feature vectors and then classify the long video based on the mean value.The above average operation will result in decreased precision.To solve this problem,proposes an improved method which puts the feature extracted by 3D Convolutional Neural Networks into the LSTM method for sequence recognition.The effectiveness of the improvement is verified by experiments.
Video Classification;3D Convolutional Neural Network;LSTM;Deep Learning
1007-1423(2017)08-0066-04
10.3969/j.issn.1007-1423.2017.08.014
楊曙光(1987-),男,河南周口人,碩士研究生,研究方向為機器學習
2016-12-22
2017-02-25
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
