基于異常數據驅動的WSN簇內數據融合方法*
2017-04-13 09:19:08譚德坤付雪峰涂振宇
傳感技術學報 2017年2期
譚德坤,付雪峰,趙 嘉,涂振宇
(1.南昌工程學院信息工程學院,南昌330099;2.江西省水信息協同感知與智能處理重點實驗室,南昌330099)
基于異常數據驅動的WSN簇內數據融合方法*
譚德坤1,2*,付雪峰1,2,趙 嘉1,涂振宇1
(1.南昌工程學院信息工程學院,南昌330099;2.江西省水信息協同感知與智能處理重點實驗室,南昌330099)
引入數據驅動的思想,提出了一種基于異常數據驅動的簇內數據融合方法。在節點數據采集過程中,僅當異常數據發生時才發送給簇頭,減少了監測網絡的數據傳輸量。在簇頭數據融合過程中,建立了各傳感器之間的相互支持度矩陣,支持度值較低的監測數據將被剔除,支持度值較高的監測數據進行最優加權融合,從而保證了融合結果的準確性和有效性。仿真實驗結果表明,與算術平均值法及自適應加權融合法相比,本文方法能有效去除冗余信息,在融合精度、能量消耗方面具有明顯的優勢。
無線傳感器網絡;異常數據驅動;數據融合;支持度矩陣
無線傳感器網絡是由許多具有感知、計算和通信能力的微型傳感器節點組成,各節點之間通過無線方式傳輸信息[1]。作為一種全新的信息獲取和處理技術,無線傳感器網絡具有節點分布區域廣、成本低、體積小、多跳、自組織等特點[2],在國防軍事、環境監測、智能交通、醫療衛生、工業自動化等領域得到了越來越廣泛的應用[3]。然而,WSN是資源受限的網絡,傳感器節點的電池容量、計算能力、存儲空間及通信帶寬均有限,為了能及時有效地監測周圍環境的信息,在監測區域通常會部署大量節點,并以較高的頻率采集并傳輸數據,從而造成大量的重復冗余的數據,浪費系統的能量和帶寬資源,大大縮減網絡的壽命[4]。因此,如何減少網絡中大量冗余信息的傳輸,降低節點能源消耗,延長網絡的生命周期,是目前WSN研究中亟需解決的問題之一。
數據融合是上述問題的一種有效解決方法。其基本思想是將具有一定冗余度的多傳感器數據進行融合,從而減少數據的傳輸量,節約傳感器節點的能量,同時也能夠有效提高獲取信息的準確性[5]。傳統的WSN數據融合方法主要歸為兩大類,一類是基于隨機理論的加權平均法、最小二乘法、貝葉斯估計法、D-S證據理論等;另一類是基于人工智能理論的人工神經網絡法、模糊推理法、粗糙集方法等[6]。傳統方法通常周期性地將源節點信息發送給匯聚節點,匯聚節點則采用相應的數學模型將不同傳感器節點采集到的信息融合處理成一條簡單的信息,然后再向上級節點轉發。傳感器節點以固定周期采集并發送數據存在如下問題:在實際應用中,節點監測的數據大多都是緩慢變化的量,如溫度、濕度、流量、壓力等,若沒有特殊事件發生時,監測到的數據絕大部分屬于重復性監測,且實際意義較低。若節點一直頻繁地處于監測狀態,仍然會造成節點能耗的增加以及網絡帶寬的浪費。文獻[7]提出增大節點的采樣周期以減少數據傳輸量,但是采樣周期過大,則很可能丟失重要的監測信息。采樣周期設置越大則異常變化數據的監測概率就越小,從而漏掉重要事件的發生。
異常數據在傳感器網絡實時監測中具有重要的應用意義。異常數據是指那些明顯偏離傳感器正常模式的測量數據[8],這里的異常是指“不尋常”,而不僅僅指“不正常”。若傳感器網絡中出現數據的異常,一是意味著周圍環境有重要事件的發生;二是表明節點出現了故障,從而采集到明顯偏離正常值的錯誤數據。無論是外部事件的發生還是節點故障,此兩種情況均應該引起相當程度的重視。近年來,國內外學者對傳感器網絡中異常數據的檢測做了大量研究。Krishnamachari等[9]提出了一種基于Bayes理論的異常節點檢測方法,通過相鄰節點的異常概率來確定某節點是否異常。譚義紅和林亞平等[10]基于線性自回歸分析法給出了傳感器數據流的預測模型,采用該預測模型提出了異常事件檢測和壓縮處理的算法。Atakli等[11]提出了一種加權可信度的檢測方法來檢測異常節點。Zheng和Baras[12]利用協助信任模型進行異常檢測并定位異常節點,結果表明該方法獲得了較好的頻帶寬度和較低的能耗。李光輝等[8]提出了基于K-means聚類的WSN異常數據檢測算法,根據與聚類中心的距離區分正常數據與異常數據。在文獻[13]中他們又提出基于神經網絡的異常數據檢測方法,通過歷史數據訓練神經網絡,判定實際測量值是否落入預報區間來判斷數據是否異常。
分析國內外文獻資料我們可以看出,對傳感器網絡中異常數據的檢測研究較多,而對異常數據在WSN數據融合中的作用研究較少。WSN異常數據對數據融合結果的正確性及融合效率有非常重要的影響。為了保證數據融合結果的正確性,由節點故障(如軟件缺陷、天氣變化、電池電量不足、電磁干擾等)所引起的數據異常[14],必須在數據融合過程中將這些不可靠數據剔除;WSN實際應用中監測目標大多都是以事件的形式出現,而外部事件的發生具有隨機性和突發性,由外部事件發生所引起的數據異常,必須實時準確地將這些信息進行識別并向外傳送。在實際應用中,觀測者主要關注的是傳感器采集到的數據的變化情況,即關心是否有重要事件的發生。因此,本文引入數據驅動的思想,以異常數據作為數據融合的驅動源,提出基于異常數據驅動的無線傳感器網絡數據融合方法,該方法僅當異常數據發生時才觸發WSN的數據融合處理機制,從而大大減少節點間的數據通信量,提升數據融合效率,節約傳感器節點能源消耗并延長網絡壽命。
1 網絡模型
在傳感器網絡中,由于網絡規模大,節點數目眾多,采用平面組織的方式會造成匯聚節點周圍的中繼節點能耗過快耗盡而無法工作的問題。為此常采用分簇的方法對網絡進行劃分,一定數量的鄰近傳感器節點形成一個簇。每簇自成一個區域,簇內節點被分成簇頭節點和普通節點。普通節點主要負責網絡狀態和事件的監測,簇頭節點主要負責從它的簇成員中采集信息并進行數據融合和轉發的任務,同時要維護簇內網絡同步和網絡管理。傳感器網絡的分簇結構如圖1所示。
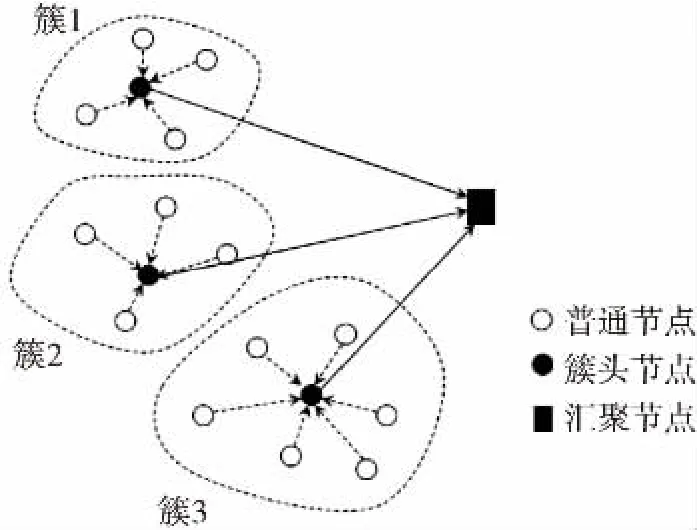
圖1 傳感器網絡節點分簇結構圖
在上述分簇的前提下,本文假定網絡節點隨機分布在監測區域內,且該網絡符合以下性質:①無線傳感器網絡節點部署后不再移動;②匯聚節點唯一,且部署在監測區域外固定位置;③簇內各節點由電池供電,初始能量相同且不能補充,發射功率有限。匯聚節點能量足夠,能進行復雜的運算并實現與外部網絡(如Internet、GPRS等)的連接;④簇跟簇之間沒有干擾,簇內成員只跟簇頭通信;⑤節點能夠獲取其自身位置信息;⑥簇內各節點同構且在地理位置上鄰近。
2 基于異常數據驅動的簇內數據融合
監測區域內的節點分好簇之后,簇內節點將測得的數據發送給簇頭節點,簇頭節點則接收成員節點數據并進行融合處理,然后將融合結果轉發給匯聚節點,此即簇內數據融合。當然,匯聚節點針對不同的簇頭信息,也可進行更高層級的決策級信息融合。具體的數據融合模型如圖2所示。

圖2 簇內數據融合模型
數據驅動思想方法具有較強的適應性,能夠適應來自傳感器的動態數據變化,也能夠適應計算需求的變化,從而最終有效地為用戶提供決策支持。在簇內數據融合的過程中,為了節省能量和數據傳輸量,簇頭采用基于異常數據驅動的融合策略。當無異常數據發生時,簇頭僅需發送分簇網絡及成員節點自身的狀態信息,此時分簇網絡處于抑制狀態;當有異常數據發生時,意味著有外部事件發生,從而驅動簇頭節點進行數據融合處理工作,此時分簇網絡處于興奮狀態。特別需要說明的是,當用戶發起查詢請求時,也視為有外部異常數據發生,從而觸發簇頭的融合處理機制運行工作。
2.1 異常數據定義
在統計學中,異常數據有許多不同的定義。我們采用基于距離的定義,即兩個數據之差的絕對值。設ai為傳感器節點i采集到的當前數據,pi為節點i在采集ai之前向簇頭發送的最近一次異常數據。則異常數據定義為:
定義1 對于數據ai,若|ai-pi|≥ε,則稱ai為異常數據。其中,ε為異常數據判定閾值,其值為常數,它的大小會顯著影響節點向簇頭發送異常數據的頻率。
對于分簇內各個傳感器節點采集的數據信息,節點內部通過比較監測到的數據與最近發送的異常數據的差值大小,然后根據差值判斷是否有必要進行當前周期采樣數據的發送。若差值大于預設的閾值,則認為產生了異常數據,將其發送給簇頭;若差值小于規定的閾值,則不用發送數據到簇頭。此種方式有效降低了節點數據發送的頻率,但是又不會漏掉重要事件所引起的“異常數據”的發送。
2.2 異常數據有效性判斷方法
簇內各節點將異常數據發送到簇頭,從而觸發簇頭節點進行數據融合處理。而異常數據分為兩種,一是由傳感器故障產生的異常數據,稱為無效異常數據;另外一種是由監測事件引起的異常數據,稱為有效異常數據。若無效數據參與數據融合,會嚴重影響數據融合結果的正確性,從而誤導整個網絡決策。因此,簇頭節點在融合處理過程中,必須首先確定被融合數據的有效性。
簇頭接收到其成員節點發送的異常數據后,僅憑單個簇頭節點本身很難對數據的有效性做出判斷。本文引入群體支持度方法對數據的有效性進行評價。本方法的基本思想是每個傳感器節點提供的異常數據都有一個支持度,其值表示簇內其他鄰居節點對該異常數據有效性的支持程度。設多個傳感器測量同一參數,第i個傳感器和第j個傳感器測得的數據分別為ai和aj。若數據ai的有效性越高,那么ai被其余節點測量數據所支持的程度就越高。所謂ai被節點j支持,即從節點j來看ai為有效數據的可能程度,亦即數據ai和aj之間的一致性程度。為了表征傳感器數據之間的這種相互支持關系,Yager[15]提出采用支持度函數sup(a,b)來表示數據b對a的支持程度。支持度函數須滿足如下3個條件:
①sup(a,b)∈[0,1];
②sup(a,b)=sup(b,a);
③若|a-b|<|x-y|,則sup(a,b)>sup(x,y)。
本文的支持度函數采用高斯函數形式進行描述,即
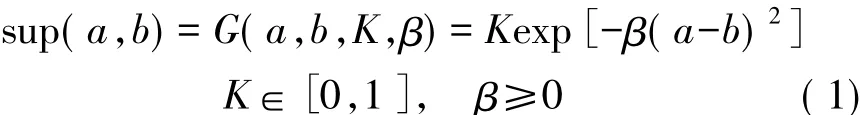
式中:參數K控制支持度函數的幅度,β為支持度衰減因子。β值越大則支持度越小,表明支持度函數的衰減幅度增大。式(1)給出的高斯函數是連續函數,它能夠準確表達傳感器數據之間的支持度關系。
定義2 傳感器節點i和j所測量數據之間的支持度為:
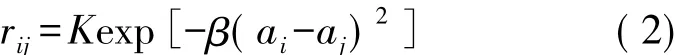
設簇內有n個傳感器節點,它們均測量同一特性指標,根據式(2)所給出的支持度公式,可得到傳感器各節點測量數據之間的支持度矩陣R:
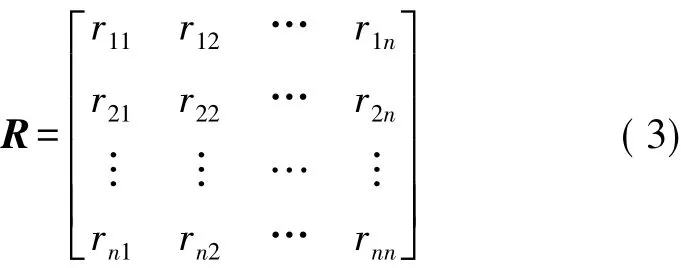
式中:ri1,ri2,…,rin分別表示節點i所測得數據ai被a1,a2,…,an所支持的程度。為了反映ai被其他傳感器測量值的綜合支持程度,定義第i個節點數據ai的綜合支持度為:
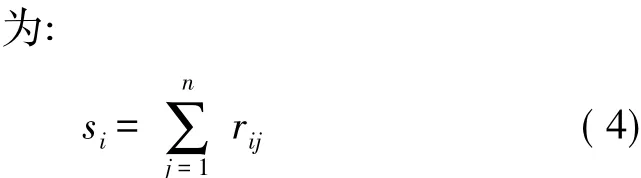
si的大小反映了ai被其他傳感器綜合支持程度的高低。si越大,說明第i個傳感器所測數據與多數傳感器接近,它被較多的傳感器支持,此時它發送給簇頭的異常數據ai為有效異常數據的可能性較高;反之,則表明第i個傳感器所測數據偏離多數傳感器的測量數據,ai為有效異常數據的可能性低,為節點故障引起的無效異常數據可能性較大。可以看出,群體支持度方法的思想較符合人們的認識實際,因為同一簇內的各傳感器節點地理位置分布較近,且節點同構,則各傳感器對同一環境特性參數的測量值應該是相互接近的。若第i個傳感器由于故障發送無效異常數據ai,而其他傳感器正常,則ai會明顯背離其他傳感器測量值,從而其綜合支持度si很小,除非簇內節點大面積同時出現故障,但是此種情況發生的概率極低,幾乎可以忽略不計。針對傳感器節點i發送的異常數據ai,下面給出判斷該數據有效性的定義:
定義3 設數據ai的綜合支持度為si,若si≥δ,則ai為有效數據;否則,ai為無效數據。其中,δ為數據有效性判定閾值。
若一個傳感器不被其他傳感器所支持,或只被少數傳感器支持且綜合支持度值小于閾值δ時,則認為該傳感器所發送的異常數據是故障引起的,因此其測量值是無效的,在進行數據融合時應把這樣的測量值剔除掉。
2.3 簇內數據融合策略
對于簇內各成員節點發送給簇頭的測量數據,簇頭采用2.2節提供的方法對數據進行有效性判定。若為無效數據,則剔除;若為有效數據,則進行數據融合處理。對于成員節點提供的有效數據ai,首先按下式計算其重要性權重:

式中:wi表示第i個傳感器測量的有效數據ai在融合過程中所占權重,m為有效數據的個數(m≤n)。通過加權求和可以得到簇內最終的融合數據為

在WSN分簇網絡中,設成員節點的數據采集周期為T,為了避免丟失重要事件的監測,而且數據采集及計算的耗能較低,因此可以將T值定得小一些。該時間周期由簇頭進行管理和同步,則各成員節點的采集時間是一致的。
在分簇網絡中,一旦有異常數據發生,則會觸發簇頭的數據融合處理機制運行工作,此時簇頭就會要求每個節點發送測量數據給自己,以便判斷各測量數據的有效性并按式(5)和式(6)進行融合計算處理。假如某分簇中有一個成員節點發生了故障,其采集的數據穩定性很差,而其余節點均正常,且監測環境中無重要事件發生。那么故障節點在每個采集周期都可能會產生異常數據發送給簇頭,從而觸發簇頭進行數據融合處理工作。雖然故障節點的異常數據不被其余正常節點的數據支持而被剔除,但每個周期正常節點的數據均被動參與了融合處理,從而造成了節點能耗增加和網絡帶寬浪費。為了防止少數故障節點頻繁發送無效異常數據而引起能量和帶寬資源的浪費,本文采用簡單多數原則來確立簇頭是否啟動數據融合處理工作。
定義4 簇頭刺激強度閾值γ。該值用于設定簇頭興奮門限,設簇內成員節點個數為n,根據簡單多數原則,則γ定為0.5n。在一個采集周期內產生異常數據的節點個數為l,若l≥γ,意味著產生異常數據的節點占多數,簇頭受到簇內異常數據刺激強度足夠,簇頭進入興奮態,需進行數據融合處理。否則,忽略本周期采集數據,不予處理。
在每個數據采集周期,由于節點不同其功能行為也不同。在簇內數據融合過程中,為了描述節點的動作行為,特定義如下3個狀態參數。
定義5 簇頭興奮標志位hTag。hTag存在于簇頭節點中,表示簇頭是否處于興奮狀態。其初值為0,表示網絡中異常數據節點個數小于閾值γ,此時分簇網絡處于抑制狀態,簇頭不做數據融合處理工作。若節點異常數據刺激強度超過閾值 γ,則將hTag置為1,此時網絡處于興奮狀態,異常數據驅動簇頭進行數據融合處理,融合處理完畢并將結果發送給匯聚節點后,簇頭將hTag重置為0。
定義6 異常數據產生標志位mTag和數據強制發送標志位send。mTag和send均置于各成員節點中。mTag表示成員節點是否產生異常數據,0為否,1為是。send表示成員節點是否收到簇頭“數據強制發送”消息,0為未收到,1為已收到。
在第k個采集周期Tk,則對于簇頭節點,其動作行為描述為:①若分簇網絡處于抑制狀態,此時hTag=0,在Tk周期內簇頭未收到任何成員節點發送的異常數據或者異常數據節點個數未超過閾值γ,則簇頭只需發送少量的本簇狀態信息給匯聚節點,不進行任何數據融合及測量數據發送工作。②在Tk周期內,若簇頭接收到成員節點發送的異常數據個數超過閾值γ,令hTag=1,同時將“數據強制發送”消息給其他成員節點,則簇頭激發分簇網絡進入興奮狀態。簇頭收到各節點的測量數據后,利用式(3)計算各節點支持度矩陣R,并利用式(4)計算各節點的綜合支持度,接著利用式(5)和式(6)進行有效數據融合處理,并將融合結果發送給匯聚節點。最后,將hTag重置為0。③若簇頭收到上層用戶查詢請求,則置hTag=1,表示該分簇網絡也受到了外部查詢請求驅動,其動作執行與上文描述相同。
在采集周期Tk,對于簇內各成員節點,其動作行為描述如下:①若mTag=0且send=0,表示該節點處于抑制狀態。成員節點將采集的數據與緩存內存放的最近發送數據進行比較,若為異常數據,則將其發送給簇頭,并置mTag為1,同時更新緩存數據;否則,不用發送本周期采集數據。②若mTag=0且send=1,表示節點處于興奮狀態,雖然該節點未產生異常數據但收到簇頭“數據強制發送”消息。此時節點應將其采集的測量數據發送給簇頭,同時更新緩存數據。③在每個采集周期末,節點將mTag和send的值重置為0。
2.4 融合算法描述
根據以上算法思想,在簇內數據融合處理過程中,算法包含成員節點異常數據判斷及數據傳輸算法和簇頭節點數據融合算法。
成員節點異常數據判斷及數據傳輸算法的主要步驟詳述如下:
Step 1 初始化參數。包括數據采集周期T,異常數據判定閾值ε。還有設定異常數據產生標志位mTag和數據強制發送標志位send的初始值。
Step 2 節點執行數據采集命令。傳感器采集周圍環境特性參數。
Step 3 進行異常數據判斷。根據定義1對采集的數據進行異常數據判斷。若為異常數據,則發送給簇頭,置mTag為1,同時更新緩存數據;否則,轉Step 4。
Step 4 啟動消息接收計時器,等待接收簇頭“數據強制發送”消息。若消息接收計時器未超時且send=1同時mTag=0,節點將其采集的測量數據發送給簇頭,同時更新緩存數據。若消息接收計時器超時且send=0,則節點丟棄本次采集數據。
Step 5 重置狀態參數mTag及send的值。返回Step 2,節點繼續下一數據采集周期。
簇頭負責將各成員節點的數據的數據進行融合操作并發送給匯聚節點。簇頭節點數據融合算法具體描述如下:
Step 1 初始化簇頭端參數。包括成員節點個數n,產生異常數據節點個數l,簇頭刺激強度閾值γ,數據有效性判定閾值δ以及簇頭興奮標志位hTag。
Step 2 統計產生異常數據節點個數。簇頭收到各節點發送的數據并判斷異常數據產生標志位mTag,從而確定節點發送的是否為異常數據。
Step 3 判斷分簇網絡狀態。若l≥γ或者簇頭收到上層用戶查詢請求,則置hTag為1,表明分簇網絡進入興奮態,轉Step 4;否則,分簇網絡處于抑制狀態,轉Step 7。
Step 4 簇頭觸發網絡進入興奮態。簇頭發送“數據強制發送”消息給那些未產生異常數據的節點并置send為1。
Step 5 進行數據有效性判斷。簇頭接收各成員節點測量數據后,利用式(3)和式(4)計算節點綜合支持度,根據定義3判定各節點數據有效性。
Step 6 進行數據融合處理。對各節點發送的有效數據,利用式(5)和式(6)進行融合計算,最后將融合結果上傳給匯聚節點。
Step 7 重置標志位hTag。返回Step 2,簇頭重新開始下一輪數據融合處理過程。
3 仿真實驗結果及分析
為了分析和比較算法的性能,本文利用MATLAB平臺進行了仿真實驗。實驗背景設定為200 m×200 m的溫室大棚內,隨機部署100個溫度傳感器節點對溫室內環境溫度變化進行監測,溫度變化模擬采用正弦函數法,傳感器節點故障、天氣變化、大棚薄膜破損、人工增溫等情況均會導致異常數據的產生。匯聚節點坐標設定為(100,200),區域內所有傳感器節點采用經典的Leach算法進行分簇,并按照隨機選舉策略生成簇頭節點,由于簇頭節點消耗能量巨大,為了均衡網絡節點能耗,在選舉簇頭時,還考慮了其當前剩余能量,剩余能量較多的節點被選為簇頭的概率較大。簇頭將數據融合后直接把結果發送給匯聚節點。在數據傳輸過程中,能耗計算采用文獻[16]中所使用的一階無線電模型,節點實驗參數設置如表1所示。
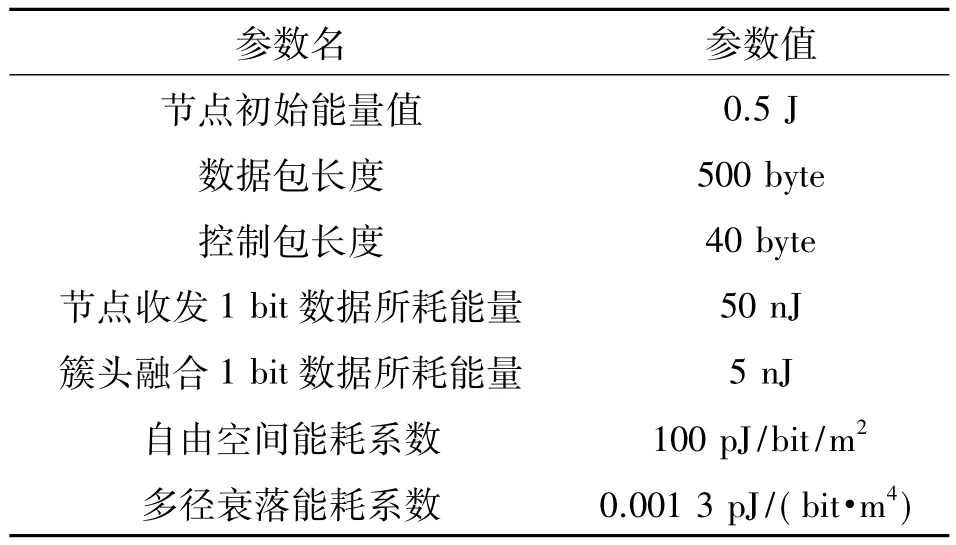
表1 節點實驗參數
3.1 融合效果比較
依據本文所提出的融合方法,將節點所采集的數據進行融合計算,取50次仿真實驗的數據融合結果。如圖3所示,將本文融合結果與傳統的算術平均值法和文獻[6]提出的自適應加權融合方法進行比較,從圖中可以看出,采用本文方法所得到的融合結果誤差較小,而其他兩種方法融合結果波動比較大,本文方法在融合精度上有明顯的優勢,其原因是本文方法在數據融合過程中,通過異常數據有效性判定方法事先剔除了故障節點所采集的數據,這些無效數據不參與融合處理過程,從而改善了數據融合的效果。
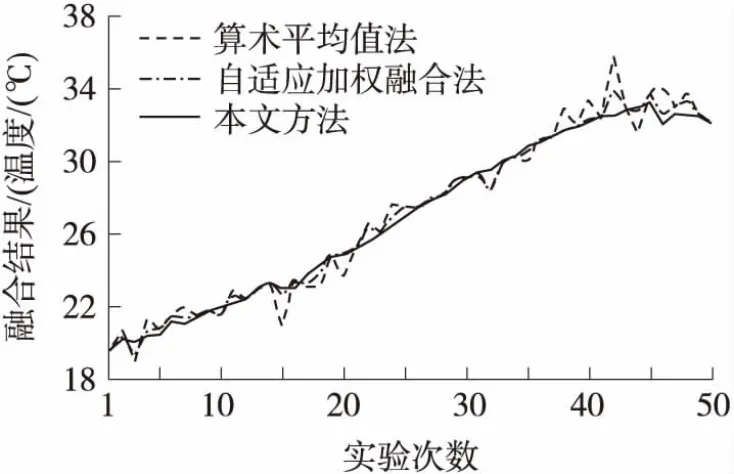
圖3 不同方法融合結果比較
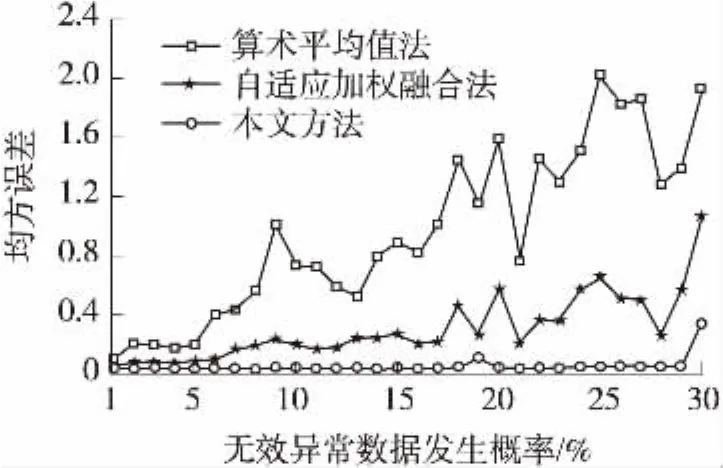
圖4 不同方法均方誤差比較
由于傳感器所采集的數據信號總會受到外在環境的干擾,故節點采集的數據難免會存在誤差,而采集數據的誤差是一個隨機變量,所以對于融合算法的優劣一般都采用均方誤差作為評價指標。圖4給出了3種方法的均方誤差隨無效異常數據發生概率的變化情況。由圖可見,在無效異常數據發生概率較低時,3種方法融合結果的均方誤差相差不大;而隨著無效異常數據發生概率的增加,本文提出的方法均方誤差較小,所得結果進一步說明了本文方法融合精度較高,在無效異常數據較多時亦能保證網絡數據融合過程的有效性。
3.2 能量消耗比較
圖5對比了3種方法的網絡存活節點剩余總能量隨運行時間輪數的變化曲線。從圖5可以看出,輪數相同時,本文方法剩余總能量都要明顯高于均值法和加權融合法。從網絡的生命周期來看,采用均值融合法的網絡運行至762輪,加權融合法運行至695輪進入死亡期,而采用本文融合方法的網絡死亡期延長至892輪。對比結果說明本文方法能量使用效率更高,更加節約能量,網絡延續時間也更長。其原因是本文方法從兩個方面節約了網絡能量耗費,一是從成員節點來看,僅當該節點有異常數據產生或者網絡處于興奮態時才發送數據給簇頭,其余時間均處于低功耗的抑制態;二是從簇頭來看,僅在足夠數量的異常數據節點激發時簇頭才進行數據融合處理工作,而異常數據的產生并非周期性的,其產生數量有限,從而顯著降低了網絡進行數據融合處理的頻次。
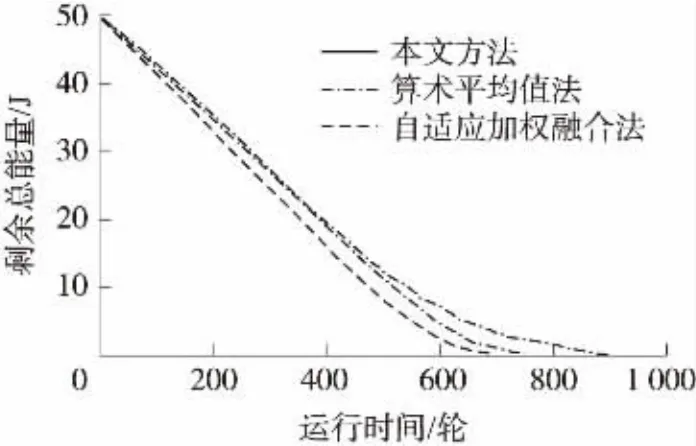
圖5 不同方法剩余總能量比較
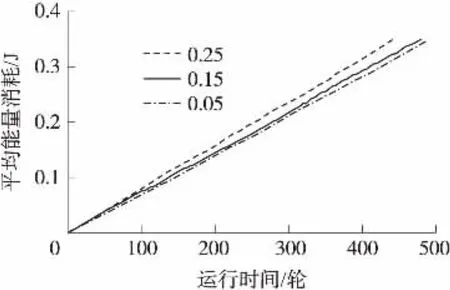
圖6 不同異常數據發生概率下網絡節點平均能耗比較
為了反映異常數據發生概率對網絡能量消耗的影響,本文給出了不同異常數據發生概率下分簇網絡運行至第1個節點死亡時節點平均能耗的變化規律,如圖6所示。從圖6比較可知,異常數據發生概率(取值0.25)越大時,網絡節點的平均能量消耗也越大,其原因是本文方法的數據融合策略是由異常數據驅動的,異常數據產生越頻繁,越有可能激發整個分簇網絡進入興奮態,普通節點轉發給簇頭的異常數據量也比較大,簇頭也必需對數據進行融合處理并轉發給上層節點,以便及時向用戶反饋突發事件的發生情況,從而引起節點通信及處理能耗的增加。若周圍環境的監測數據變化緩慢,亦即異常數據發生概率(取值0.05)較低時,整個網絡節點的平均能耗顯著降低,其第1個節點的死亡時間也得到了延長。
4 結論
針對監測環境中突發異常事件的產生以及網絡能量受限的特點,本文提出了一種基于異常數據驅動的WSN簇內數據融合方法。本算法以異常數據作為數據融合的驅動源,僅當異常數據發生時才觸發WSN的數據融合處理機制運行。由于異常數據的產生是隨機的,且產生頻次是有限的,該方法既有效降低了節點數據發送的頻率,從而減少了網絡中的數據通信量,但是又不會漏掉隨機事件所引起的“異常數據”的發送,因而具有明顯的優越性。仿真實驗結果進一步表明,與傳統的均值法及自適應加權融合法相比,本文方法融合精度高,能量耗費小,在網絡中故障數據率較高的情況下也能保證數據融合結果的有效性,是一種綜合性能較優的數據融合方法。
[1] 陸亞芳,易可夫,馮緒,等.基于模糊理論的無線傳感器網絡多層分簇式路由算法[J].傳感技術學報,2014,27(7):933-938.
[2] 熊迎軍,沈明霞,陸明洲,等.溫室無線傳感器網絡系統實時數據融合算法[J].農業工程學報,2012,28(23):160-166.
[3] Rashmi R R,Soumya K G.Adaptive Data Aggregation and Energy Efficiency Using Network Coding in a Clustered Wireless Sensor Network:An Analytical Approach[J].Computer Communications,2014,40:65-75.
[4] 徐曉斌,張光衛,孫其博,等.一種誤差可控傳輸均衡的WSN數據融合算法[J].電子學報,2014,42(6):1205-1209.
[5] Yuan F,Zhan Y J,Wang Y H.Data Density Correlation Degree Clustering Method for Data Fusion in WSNs[J].IEEE Sensors Journal,2014,14(4):1089-1098.
[6] 張明陽,沈明玉.基于WSN的數據融合在水質監測中的研究[J].計算機工程與應用,2014,50(23):234-238.
[7] 王沁,李翀,萬亞東,等.實時管理約束下節點級低功耗數據融合技術[J].通信學報,2008,29(11):220-226.
[8] 費歡,李光輝.基于K-means聚類的WSN異常數據檢測算法[J].計算機工程,2015,41(7):124-128.
[9] Krishnamachari B,Iyengar S.Distributed Bayesian Algorithms for Fault-Tolerant Event Region Detection in Wireless Sensor Networks[J].IEEE Transactions on Computers,2004,53(3):241-250.
[10]譚義紅,林亞平,董婷,等.傳感器網絡中異常數據實時檢測算法[J].系統仿真學報,2007,19(18):4335-4341.
[11]Atakli I M,Hu H,Chen Y,et al.Malicious Node Detection in Wireless Sensor Networks Using Weighted Trust Evaluation[C]// Proc 2008 Spring Simulation Multiconference,2008:836-843.
[12]Zheng S,Baras J S.Trust-Assisted Anomaly Detection and Localization in Wireless Sensor Networks[C]//SECON 2011,IEEE,2011:386-394.
[13]胡石,李光輝,盧文偉,等.基于神經網絡的無線傳感器網絡異常數據檢測方法[J].計算機科學,2014,41(11A):208-211.
[14]侯鑫,張東文,鐘鳴.基于事件驅動和神經網絡的無線傳感器網絡數據融合算法研究[J].傳感技術學報,2014,27(1):142-148.
[15]Yager R R.The Power Average Operator[J].IEEE Transactions on Systems,Man,and Cybernetics,2001,31(6):724-731.
[16]葉繼華,王文,江愛文.一種基于LEACH的異構WSN能量均衡成簇協議[J].傳感技術學報,2015,28(12):1853-1860.

譚德坤(1973-),男,重慶開縣人,博士,副教授,主要研究方向為無線傳感器網絡、數據融合、智能優化算法等,dktan@nit.edu.cn;

付雪峰(1978-),男,江西宜春人,博士,講師,主要研究方向為無線傳感器網絡、本體推理等,fxfcn@126.com。
A Data Aggregation Method Based on Abnormal Data-Driven in Clusters of Wireless Sensor Networks*
TAN Dekun1,2*,FU Xuefeng1,2,ZHAO Jia1,TU Zhenyu1
(1.School of Information Engineering,Nanchang Institute of Technology,Nanchang 330099,China; 2.Jiangxi Province Key Laboratory of Water Information Cooperative Sensing and Intelligent Processing,Nanchang 330099,China)
Aiming at the deficiency of traditional data aggregation methods,a new aggregation method based on abnormal data-driven is proposed by introducing the mechanism of data-driven.In the phase of data acquisition,the sensor nodes only send the abnormal data to cluster head when exceptional event occurs randomly,this can effectively reduce the network traffic.In the phase of data aggregation for cluster head,the support matrix is constructed between sensors,those monitoring data which has lower support values will be eliminated,only the higher support value data is aggregated by cluster head with the method of optimal weight,thus ensuring the accuracy and validity of aggregation results.The simulation experiments show that,compared with the mean value method and the self-adaptive weighted aggregation method,the proposed method can effectively remove redundant information in the period of data transmission,which has obvious advantages in aggregation precision and energy consumption.
wireless sensor networks;abnormal data-driven;data aggregation;support matrix
TP393
A
1004-1699(2017)02-0306-07
C:7230
10.3969/j.issn.1004-1699.2017.02.024
項目來源:國家自然科學基金項目(61261039);江西省科技支撐計劃項目(20142BBE50040,20142BBG70034,20151BBE50077)
2016-07-06 修改日期:2016-08-22
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
