基于反饋合并的中英文混排版面OCR技術研究
2017-03-29 04:52:48任榮梓
計算機技術與發展 2017年3期
任榮梓,高 航
(南京航空航天大學 計算機科學與技術學院,江蘇 南京 210016)
基于反饋合并的中英文混排版面OCR技術研究
任榮梓,高 航
(南京航空航天大學 計算機科學與技術學院,江蘇 南京 210016)
迄今,光學字符識別(OCR)技術已普遍應用于社會生活的方方面面,單一字符集OCR技術領域已經取得重大突破。但由于中文和英文版面分析之間存在的明顯差異,現有中英文混排OCR技術的表現均不盡如人意。針對傳統OCR方法實現方式的缺點和不足,在研究中英文混合版面分析切分技術難點的基礎上,提出了一種改進的基于反饋合并的中英文混合版面分析切分方法。該方法在綜合應用Canny算子的圖像二值化方法和中值濾波法進行濾波預處理的基礎上,采用投影法兩次分割字符區域,并對具體切分技巧進行了較為深入的研究。對比驗證實驗結果表明,所提出的版面分析切分方法可成功分離中英文混合文檔中的中文、英文和數字字符,正確率比傳統方法高出約8個百分點,可達到97%,較好地解決了傳統方法對粘連字符處理效果不佳的問題。
文字識別;中英混排;版面分析;分離
0 引 言
近年來,關于OCR(光學字符識別)技術的研究蓬勃發展,優秀的OCR算法更是層出不窮。例如,由南開大學機器智能研究所研究的英文OCR技術在OCR英文核心技術評測中獲得世界第一,而由北京信息工程學院研究的中文OCR核心技術在UNLV(美國內華達大學拉斯維加斯分校)的一次中文評測中獲得最佳。其他比較著名的OCR技術包括Tesseract-OCR、漢王等。
上述OCR技術雖然在各自單純語種環境下表現優異,但是均不能保證對中文和英文及標點符號混排的圖片進行有效識別。絕大部分針對中英文混合圖片的現行OCR技術都是先采用版面分析技術,即先實行中英文的分割,再運用兩種不同的算法分別進行識別,由此可見版面分析過程就顯得尤為重要。目前常用的版面分析算法分為三種:自頂向下法、自下而上法和綜合法。
自頂向下法重視全局信息,從頁面的整體入手,先利用圖像處理的常用方法將文本圖像劃分成若干區域,再根據文本結構信息將第一次劃分出來的區域進行二次劃分。此類方法包括投影二分法[1]、循環X-Y切分法[2]等,但該類方法對于信息內容復雜的版面分割精度并不理想。
與自頂向下法相反,自下而上法重視局部信息,其從圖像像素開始,將圖像由小區域逐步整合成大區域,最終覆蓋整個文本圖像。該方法彌補了自頂向下法存在的技術缺陷,包括游程碼平滑切分法[3]、K_近鄰聚類方法[4]、連通域提取算法切分[5]等,但缺點在于耗時較長。
綜合法是文中采用的方法,既汲取了上述兩種方法的優點,實現了全局信息與局部信息的融合,又較好地解決了兩者存在的技術缺陷,在保證分割精度的前提下兼顧了時間的節省。有代表性的綜合法包括基于背景間隔的版面切分算法[6]、基于復雜度的中文版面分析算法[7]等。
形近字是中文字符不同于英文等西方字符的獨特之處。現代漢語常用的3 500個字符中形近字就不止500個,占總數的14%。此類字符多為左右結構或上下結構,其部首或偏旁又是常見的漢字,給中文字符的識別造成了較大的麻煩。如“明、月”“汪、王”“由、甲”之類的字符通常極易被誤混或割裂,嚴重影響了文本的正確識別。因此在版面分析的切分過程中,對于形近字的識別應充分重視。
1 處理流程
文中介紹的基于反饋合并算法的中英混合版面分析處理流程為:首先進行預處理,對輸入的數字圖片進行二值化和去噪,預處理完成后利用行分割和字符分割方式對圖片進行區域分割,將其分割為中文區域以及英文和數字區域,之后分別采用相對應的方法對兩種區域進行二次分割,然后利用評估系數對二次分割結果進行判別,屬于粘連字符的情況下則對其再次進行分割,直至檢測不到粘連字符時,分割完畢。流程如圖1所示。

圖1 處理流程圖
2 預處理
2.1 二值化
對原始圖像進行預處理,包括將圖像進行常規初始化操作即二值化[8]和降噪處理。所謂圖像二值化即把圖像上所有像素點的值進行分化:設置為0或1。二值化的圖像具有非常明顯的視覺效果即非黑即白,在OCR處理中具有極其重要的作用。通常進行二值化的方法是全局二值化閾值法:即設定一個閾值T,大于等于T的所有像素置為1,小于T的像素置為0。所以選取合適的閾值T是關鍵。目前比較先進的二值化方法有結合Canny算子的圖像二值化[9]等。文中采用這種二值化方式。
2.2 圖像去噪
在二值化完成之后,雖然文本圖片已被分割為包含文本信息的前景圖片和不包含文本信息的背景圖片,可是在前景信息中仍然具有一些零星的噪聲點,如果此時不對其進行消除,則對OCR后期操作的破壞性影響是很大的。噪聲一般分為加性噪聲、乘性噪聲和量化噪聲三種。其中,加性噪聲主要是由于攝像機在掃描圖像過程中產生的,與信號本身無關。乘性噪聲則是圖像信號本身所附帶的,例如影視圖像中產生的雪花點等等。而圖像量化中產生的量化誤差導致的噪聲則稱為量化噪聲。
目前對去噪方法而言,常用的主要有均值濾波、自適應維納濾波和中值濾波[10]等。其中,均值濾波主要采用相鄰區域像素平均值的均值濾波器,這種方法對于加性噪聲的清除效果較為顯著,但缺點也十分明顯:即因為平均而容易導致圖像局部模糊。而自適應維納濾波是根據圖像的局部方差來調整濾波器的輸出,克服了圖像模糊的問題,但是缺點在于其計算量過大。中值濾波是采用一種較為簡單的非線性平滑濾波器,它根據噪聲往往都是孤立的特性,把圖像中一點的值用其附近有效區域的個點值的中值替代,從而使周圍像素差別較大的點得到平均,以此來消除噪聲點。因為中值濾波法性能的優異和操作的簡便,文中在去噪處理中使用了中值濾波。
3 中英混合區域分割
預處理完成后,利用行分割和字符分割方式對混合區域進行區域分割,之后再分別利用兩種不同的方法對確定塊中的中文和英文數字塊進行分割,直到完成所有字符的分割工作。對于其中的中文字符塊,先行判斷它是否是粘連字符,如果是,則對其進行字符再分割。當不再能檢測到粘連字符時則證明分割完成。
3.1 行分割
正常的文本圖片行與行之間的空格間距是固定的,通常情況下也會小于單行文本的字符高度。因為行與行之間空白的存在,通過檢測空白區域,就可以利用它確定一行的首末。可以使用一個固定的比較大的閾值來幫助確定,而這個閾值通常情況下可以使用比二倍于一個字符的寬度略大。對于一個正常文本文件而言,極少有大于兩個字符寬度的空格,即使有,因為當一個文本出現大于兩個字符寬度的時候,文意已經產生了變化,按照分開行的做法也并不會產生錯誤。當一行空白的區域高度小于這個閾值時,可以斷定它是一個空白。當黑色區域大于某一個閾值時,可以認為它是一行的開始,當黑色區域小于閾值時,可以判斷其為一行的結尾。按照這種方法可以把文本按行分割完畢,之后再對字符分割也就更加便捷。
圖2展示了多行文字的水平投影。
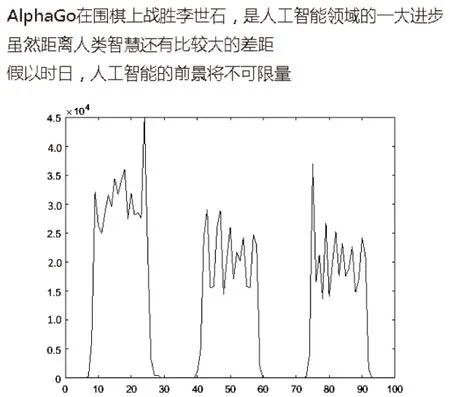
圖2 水平投影
3.2 字符分割
行分割完成之后,就可以進行字符分割。除了行與行之間,同一行以內的字符間也是存在些許空白的,可以利用這些空白把字符分割出來。垂直投影法就是一種不錯的方法。把數字圖像具體化為一個M×N的矩陣g(i,j),每一列的垂直投影為:
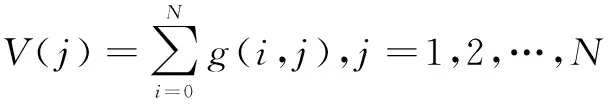
(1)
其中,投影值為0的點是字符間的空白。從第一個不為0的點Ja開始,分割程序從左至右掃描每一行文本,當遇到V(j)=0的點Jb時停止,兩點之間視為一個字符。使用這種方法循環至一行的結尾。圖3展示了單行文字的垂直投影。
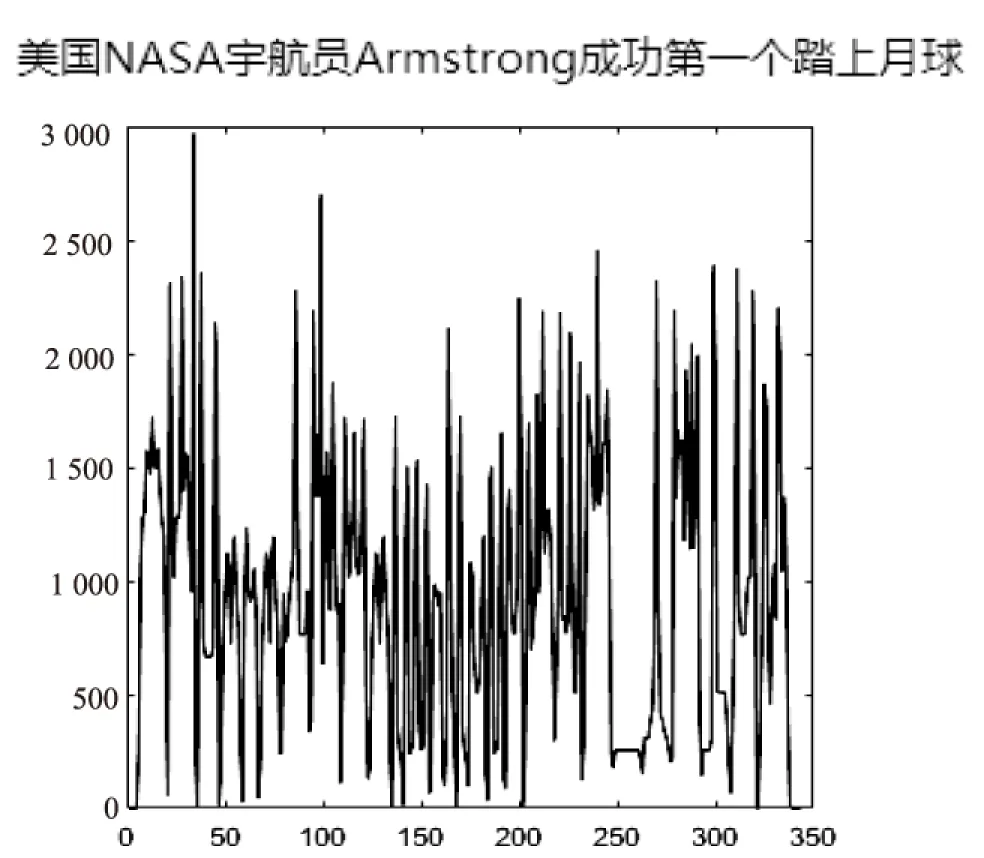
圖3 垂直投影
3.3 區域分割
把中文字符的中心投影映射到同一水平線上,可以發現中文字符的水平間隔是均勻且固定的,而且根據反復觀察得知該特性并不受字體或者樣式的改變影響,例如華文仿宋和加粗等。這意味著可以用水平間隔的恒定性來判斷一些字符是否為中文。與之類似,英文字符也具有類似的性質,只是每隔一段時間就會出現大的跨越;但是當中文、英文以及數字混合出現在一行的時候,間隔將會變得混亂。根據這種差異性可以由此來進行中英區域的分割。
因為英文字符和數字字符有類似的寬度和周期,并且在一行之中都會有一些固定的單詞之間的空格。英文以及數字字符的長和寬遠遠小于中文字符。所以,可以利用監測字符的長和寬來分離出中文字符區域。之后在剩下的英文區域和數字區域中,依據相同的方法,鑒于標點符號的長寬比相對來說要小很多,可以依此迅速分離出標點符號。由此,中文和英文數字得以分離開來。圖4展示了分離結果。

圖4 區域分離結果
4 中英字符二次分割
4.1 中文字符二次分割
相關文獻中提出了很多分離中文的算法,例如基于可見性的中文字符分離[11]、基于中文筆畫結合的手寫中文字符分離[12]、基于多信息融合的中文字符分離[13]、基于單元合并的中文字符分離[14]以及基于反饋的中文字符分割算法[15]等等。以上方法在一定程度上可以較好地分離中文字符,但是對部分較為生僻且結構特殊的中文字符都會出現不同程度的錯誤,而且單純經過分割算法,雖然絕大部分中文字符可以被分離出來,但是在已經分理出的字符中仍有一部分粘連字符,例如常見的“日”和“月”就容易粘連為“明”。為保證最終的識別結果正確,需要對已分離出的結果進行粘連字符的檢測和二次分離。所以文中將已有的算法進行綜合改進,提出了一種反饋合并算法用來分離中文字符。具體過程如下:
(1)設立評估系數。
(L,U),(R,D)表示i的位置,其中(L,U)和(R,D)分別是該單元左上角坐標和該單元右下角坐標;
待評估字符的寬度Pw、高度Ph、行間距Pl和所占空間Ps;
(a1,a2,a3,a4,a5,a6)是根據先驗知識確定的系數;
Wi和Hi代表正在合并的某個特定單元的字符的寬和高,Hij表示合并后的高度;
M表示總單元個數,N表示剩余單元個數。
(2)
(3)
(2)設立一個評估標志位Flag并將其置為FALSE。
對任意單元i,遍歷單元集合,當存在單元j滿足下面所述條件時,則將單元i和單元j合并為一個字符。
(4)
(3)記錄在第二步中進行合并之后的單元的合并信息,并將它們的標志位Flag置為TRUE,當有一個字符通過評估時,將合并為它的字符記為“通過單元”。全部結束之后將會有一部分單元被保留下來而沒有被合并,此時就需要對剩余未標記為“通過單元”的所有單元使用第二次反饋因子進行二次合并。即當剩余非“通過單元”滿足以下條件時,對其進行合并。
(5)
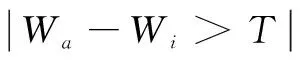
(5)分離粘連字符:上一步尋找到粘連字符之后,需要首先確定一個正確的分割點。對于中文字符的粘連字符,它的寬度可以根據所有中文字符的平均高度來確定,因為中文字符獨特的矩形結構,它們的高寬比在1.05~1.15之間,因此可以利用投影法來確定字符的邊界:即從左至右掃描每一行以確定全部的粘連字符的區域并標識出全部的分割點,分割完成。
4.2 英文和數字的二次分割
對英文和數字字符的再分離可以利用字符圖像背景的上下凹區域進行再切分[16]。通過計算圖像的背景域,提取出上下凹區域,再采用相鄰匹配原則和最小面積選擇原則確定切分域,從而提取出切分線進行切分。文中采用該方法進行英文和數字的二次分割,達到了較為理想的效果。
5 中英文及數字混合字符分割實驗結果
實驗選取了包含中英混合文字的報紙、書刊、網頁快照作為測試文件,字體主要是由宋體標準和加黑組成,英文為主要正常字體包含部分斜體,字號大小均有差異,掃描分辨率為300~400 dpi。將混合材料分成三組,數量分別控制在1 500、3 000和5 000數量級(因為材料本身限制會有一些浮動),三組材料中文所占比例大致均衡,約為44%(668)、56%(1 650)、48%(2 502)。結果見表1。
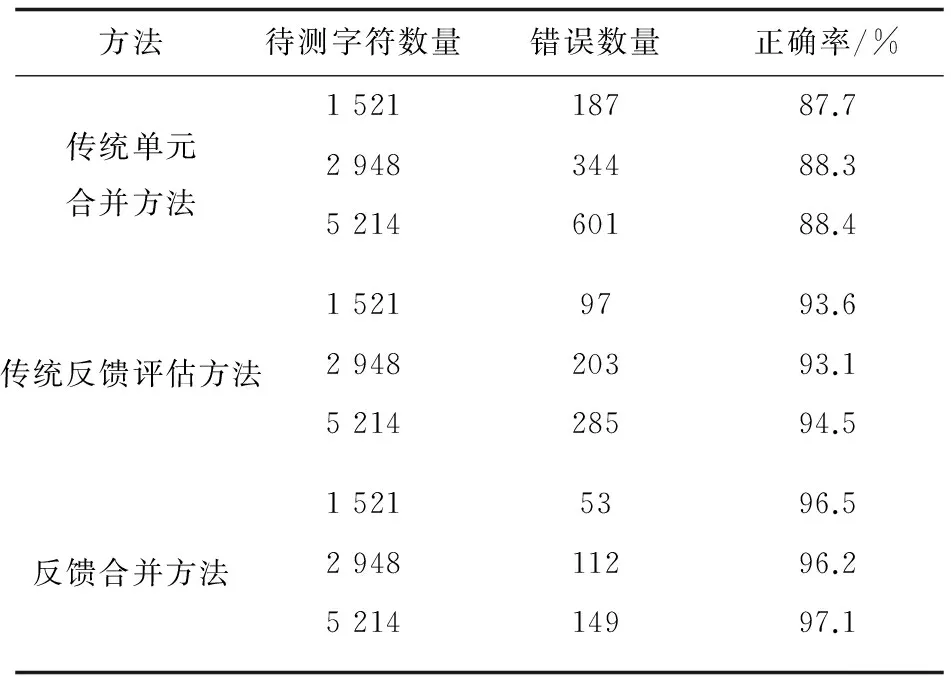
表1 實驗結果
表1記錄了測試樣本的數量及錯誤數量,其中錯誤數量按照原本正確的材料中的字符中未出現的來計數,即兩個字符粘連成一個字符記為兩次錯誤,而一個字切分成兩個的情況則記為一次錯誤。最終的結果表明,文中方式對字符的切割效率較好,比使用傳統單元合并的版面分析法提高約8%,比使用傳統反饋評估的方法提高約3%。
6 結束語
針對傳統OCR方法實現方式的缺點和不足,在研究中英文混合版面分析切分方法技術難點的基礎上,提出了一種改進的基于反饋合并的中英文混合版面分析切分方法。該方法在綜合應用Canny算子的圖像二值化方法和中值濾波法進行濾波預處理的基礎上,采用投影法兩次分割字符區域,并對具體切分技巧進行了較為深入的研究。對比驗證實驗結果表明,所提出的版面分析切分方法可成功分離中英文混合文檔中的中文、英文和數字字符,且具有普遍高于傳統方法的正確率,較好地解決了傳統方法對粘連字符處理效果不佳的問題。
[1] 王 丹,劉 江.基于投影直方圖的文檔圖像快速匹配研究[J].計算機技術與發展,2011,21(7):129-131.
[2] Mao S,Kanungo T.Empircal perforinanoce evaluation of page segmentation algorithms[C]//Proceeding of SPIE conference on document recognition and retrieval.[s.l.]:[s.n.],2000:303-312.
[3] 張 利,朱 穎,吳國威.基于游程平滑算法的英文版面分割[J].電子學報,1999,27(7):102-104.
[4] 周國兵,吳建鑫,周 嵩.一種基于近鄰表示的聚類方法[J].軟件學報,2015,26(11):2847-2855.
[5] 陳 艷,孫羽菲,張玉志.基于連通域的漢字切分技術研究[J].計算機應用研究,2005,22(6):246-248.
[6] 楊 寧.基于背景間隔的中文版面分析系統[D].南京:南京理工大學,2002.
[7] 范玉鳳.基于復雜度的自適應中文版面分析方法研究[D].青島:中國海洋大學,2011.
[8] Zhang Y L,Zhang S C.Image rotation and binaryzation based on .Net[C]//7th international conference on electronic measurement and instruments.Beijing:[s.n.],2005:406-408.
[9] 陳 強,朱立新,夏德深.結合Canny算子的圖像二值化[J].計算機輔助設計與圖形學學報,2005,17(6):1302-1306.
[10] 張 恒,雷志輝,丁曉華.一種改進的中值濾波算法[J].中國圖象圖形學報,2004,9(4):408-411.
[11] Xu Liang,Yin Fei,Wang Qiufeng,et al.Touching character separation in Chinese handwriting using visibility-based foreground analysis[C]//11th international conference on document analysis and recognition.Los Alamitos,CA,USA:IEEE Computer Society,2011:859-863.
[12] 趙姝巖,郭 捷,施鵬飛.基于筆畫分析和背景細化的粘連手寫漢字切分[J].上海交通大學學報,2003,37(9):1434-1437.
[13] 付 強,丁曉青,蔣 焰.基于多信息融合的中文手寫地址字符串切分與識別[J].電子與信息學報,2008,30(12):2916-2920.
[14] Liu Mingzhu,Suo Yuxiu,Ding Yinan.Research on optimization segmentation algorithm for Chinese/English mixed character image in OCR[C]//4th international conference on instrumentation and measurement,computer,communication and control.New York,NY,USA:IEEE,2014:764-769.
[15] 安艷輝,董五洲.基于識別反饋的粘連字符切分方法研究[J].河北省科學院學報,2008,25(2):32-35.
[16] 羅 佳.一種對粘連英文字符串的快速切分算法研究[J].計算機技術與發展,2014,24(8):59-62.
Investigation on Layout Analysis Technology of Chinese and English Mixed OCR Based on Feedback Merging
REN Rong-zi,GAO Hang
(School of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China)
So far,Optical Character Recognition (OCR) technology has been widely applied in all aspects of social life,and a single character set OCR has made a major breakthrough in the technology field.However,due to the obvious differences between Chinese and English layout analysis,the performance of the existing English and Chinese mixed OCR technology is not satisfactory.According to the shortcomings and deficiencies of traditional OCR method,on the basis of the analysis of the segmentation technique difficulties in the study of Chinese and English mixed layout,an improved segmentation method of Chinese and English mixed layout OCR analysis based on feedback merging is proposed.Based on the comprehensive utilization of the Canny operator image binary method and median filter method for filter preprocessing,this method segments the character region twice by projection method,and has conducted the thorough research to the specific segmentation techniques.Experiment results show that the proposed method can be successfully separated in mixed document in Chinese,English and numeric characters.The correct rate is higher than the traditional method about 8 percentage points,which can reach 97%,effectively solving the problem of ineffective adhesion character for the traditional methods.
character recognition;English and Chinese mixed;layout analysis;separation
2016-04-13
2016-08-10
時間:2017-01-10
江蘇省科技成果轉化專項資金(BA2012023)
任榮梓(1993-),男,碩士研究生,研究方向為圖像處理;高 航,副教授,碩士生導師,研究方向為圖像處理、嵌入式應用。
http://www.cnki.net/kcms/detail/61.1450.TP.20170110.1028.074.html
TP301
A
1673-629X(2017)03-0039-05
10.3969/j.issn.1673-629X.2017.03.008
猜你喜歡
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
