P2P情境下基于用戶興趣的個人數(shù)字圖書館資源定位
2017-03-21 08:41:16,
中華醫(yī)學圖書情報雜志 2017年11期
,
近年來,個人計算機上存儲的個性化信息資源數(shù)量大幅增長,有效管理和使用這些資源成為亟待解決的問題,因此個人數(shù)字圖書館應運而生。目前個人數(shù)字圖書館有兩種形式:一種是基于服務器的個人信息空間,一般稱作“My library”(我的圖書館)[1];另一種是基于PC的數(shù)字信息資源庫,一般稱作“Personal Digital Libraries”(PDLs)[2]。本文研究的是第二種形式。
作為個人信息工具,個人數(shù)字圖書館的職能主要有兩種:一種是有效管理和使用個人計算機上的信息資源,這是個人數(shù)字圖書館最基本的職能;另一種是共享個人計算機上的信息資源,促進資源的有效利用和知識再生,這是個人數(shù)字圖書館的核心功能。信息搜索是資源共享的基礎,沒有合適的信息搜索機制就無法構建高效的資源共享平臺。由于個人數(shù)字圖書館的分散性特點,其信息搜索及共享研究在傳統(tǒng)的客戶機/服務器模式下難以突破。為了解決這個問題,P2P(Peer to Peer)技術被引入了個人數(shù)字圖書館領域。
1 個人數(shù)字圖書館與P2P技術簡介
大量學者對個人數(shù)字圖書館的資源共享進行了研究。王小立指出資源共享是個人數(shù)字圖書館的本質屬性,其發(fā)展仍處于初始階段,具有廣闊的前景[3];陳春艷分析了阻礙個人數(shù)字圖書館資源共享的因素,指出傳統(tǒng)的集中式模式(客戶機/服務器和瀏覽器/服務器)阻礙了個人數(shù)字圖書館資源共享的發(fā)展[4];張哲對比了集中式和P2P兩種模式,指出集中式模式共享成本高、效率低,不適合個人數(shù)字圖書館資源共享的發(fā)展,而P2P模式的去中心化與個人數(shù)字圖書館的分散性不謀而合,不需要服務器的參與,能充分發(fā)揮個人數(shù)字圖書館的能力,適合個人數(shù)字圖書館的發(fā)展[5]。
P2P即對等網(wǎng)絡,是相對傳統(tǒng)的客戶機/服務器模式而言的。系統(tǒng)中每個節(jié)點的作用都是對等的,既可以充當服務器為其他節(jié)點提供資源和服務,也可以充當客戶機享用其他節(jié)點的資源和服務。P2P技術因其良好的自組織能力和可擴展性,而受到業(yè)界的廣泛關注,主要應用于搜索引擎、資源共享、協(xié)同工作和實時通訊等領域。目前,P2P技術在個人數(shù)字圖書館方面的應用研究較少,主要集中于文件共享模型的構建和信息搜索。王春梅等介紹了個人數(shù)字圖書館的共享現(xiàn)狀,嘗試用P2P技術構建簡單的個人數(shù)字圖書館共享架構,并通過模擬實驗驗證了P2P應用于個人數(shù)字圖書館的可行性[6];廈門大學Xu Yanfei利用具有相同興趣的個人數(shù)字圖書館形成社區(qū),探討了適合個人數(shù)字圖書館的P2P網(wǎng)絡拓撲結構[7]。資源定位是P2P技術應用于個人數(shù)字圖書館需要突破的一個難題。張銀犬等指出在分布式環(huán)境下個人數(shù)字圖書館的信息檢索還是一個研究空白和難點,并結合P2P技術和Z39.50協(xié)議,對個人數(shù)字圖書館信息檢索策略進行了初步探索[8]。
分布式環(huán)境下沒有集中式環(huán)境中掌管全局信息的中央服務器,資源定位成為一大難題。在非結構化P2P網(wǎng)絡中,洪泛是最常使用的一種檢索策略。這種策略將查詢消息向所有鄰居進行廣播,造成大量通訊開銷,嚴重影響了搜索效率[9]。為了減少消息數(shù)量,一些學者提出了啟發(fā)式搜索機制,利用搜索歷史、節(jié)點狀態(tài)等信息,將消息轉發(fā)范圍控制在局部存有目標資源幾率較高的節(jié)點,可縮小搜索范圍,提高搜索效率。基于興趣的搜索機制就是啟發(fā)式搜索中的一種[10]。文獻[11]根據(jù)節(jié)點之間的交流歷史創(chuàng)建興趣捷徑,從而改進Gnutella的搜索性能。何可等采用基于興趣的完全二叉樹P2P拓撲結構,提出了一種基于Flooding機制的雙向資源搜索算法[12];陳香香等根據(jù)節(jié)點共享文件的差異將網(wǎng)絡分域,并且利用預算值控制搜索范圍[13]。以上研究將最主要的興趣作為節(jié)點的唯一興趣,但是節(jié)點往往有多個興趣,當節(jié)點搜索其他興趣的內容時,就無法體現(xiàn)基于興趣搜索機制的優(yōu)勢。
在以上研究的基礎上,針對個人數(shù)字圖書館搜索機制尚不完善的問題,本文提出一種基于P2P技術采用多興趣的搜索機制的個人數(shù)字圖書館模型(Multi-Interest Personal Digital Library Model,MIPDLM)。
2 基于P2P技術的個人數(shù)字圖書館模型MIPDLM
2.1 興趣的表示
作為個性化特征突出的個人信息工具,個人數(shù)字圖書館(PDL)所存儲的資源(本文只研究文檔類的資源)往往表現(xiàn)出一定的興趣偏好。傳統(tǒng)的興趣表示通常只關注PDL最主要的興趣,這種單一的、靜態(tài)的興趣表示方法無法兼顧PDLs多樣的、動態(tài)變化的興趣,導致PDL搜索效率低下。本文采用多興趣表示方法, PDL可以加入多個興趣簇,即使PDL擁有豐富的動態(tài)變化的興趣,系統(tǒng)也能將搜索消息轉發(fā)到相似度較高的興趣簇,故可大大縮小搜索范圍,提高搜索效率。
本文采用經(jīng)典的向量空間模型(Vector Space Model,VSM)作為興趣表示模型,VSM模型將現(xiàn)實中無法相互比較的興趣轉化為可以計算彼此相似度的向量,如PDLi的興趣向量為{PDLi1,PDLi2,…,PDLik,…,PDLin},表示PDLi共有n個興趣,其中PDLik是PDLi中第k(1≤k≤n)個興趣向量。兩個興趣之間的相似度采用夾角余弦表示,夾角余弦值越大,表示兩個興趣之間的相似度越大;反之,兩個興趣之間的相似度越小。同理,搜索消息向量與文檔向量之間的興趣相似度也取其夾角余弦值。興趣與PDL之間的相似度是指該興趣與PDL中所有興趣相似度的最大值。同理,搜索消息向量與PDL之間的興趣相似度也是如此計算。
2.2 興趣覆蓋網(wǎng)絡的構建
構建適合個人數(shù)字圖書館資源共享的興趣覆蓋網(wǎng)絡。在MIPDLM模型動態(tài)構建過程中,系統(tǒng)需用到個人數(shù)字圖書館的一些數(shù)據(jù)信息。每個PDLi存儲如下3方面的信息:一是PDLi共享文檔的集合,二是PDLi的興趣向量集合,三是兩種鄰居集合即簇內鄰居集合和簇外鄰居集合。簇內鄰居集合存儲與PDLi興趣相似度較高的PDLs,簇外鄰居集合存儲與PDLi興趣相似度較低的PDLs。簇內鄰居和簇外鄰居都包含一組(ip(PDLj),PDLjr)信息,其中簇內鄰居集合中ip(PDLj)是PDLi簇內鄰居PDLj的IP地址,PDLjr是與PDLi的第k個興趣相對應的興趣向量。相反,簇外鄰居集合中ip(PDLj)是PDLi的簇外鄰居PDLj的IP地址,PDLjr是與PDLi的第k個興趣相對應的興趣向量。大量的PDLs根據(jù)簇內鄰居形成一個個興趣簇,這些興趣簇緊密地結合在一起組成一個興趣覆蓋網(wǎng),這種網(wǎng)絡類似于一個規(guī)則網(wǎng)絡。為了保證“小世界”特性,PDLs通過少量的簇外鄰居鏈接到其他的興趣簇[14]。
本文采用全分布式非結構化的P2P網(wǎng)絡結構。當PDLi加入網(wǎng)絡時,首先初始化興趣向量{PDLi1,PDLi2,…,PDLik,…,PDLin},針對每個興趣PDLik,PDLi維護兩個路由表CRPDLik和NCRPDLik,CRPDLik存儲簇內鄰居信息,NCRPDLik存儲簇外鄰居信息。PDLi利用隨機漫步算法在網(wǎng)絡中發(fā)出一個消息,選取收到消息的2m個PDLs作為初始值,分別將m個PDLs的IP和興趣向量存入CRPDLik和NCRPDLik。PDLs的興趣一直處于動態(tài)變化過程中,為了確保網(wǎng)絡拓撲結構適應個人數(shù)字圖書館興趣的變化,使興趣相似度較高的PDLs始終聚集在一起,PDL定期檢測每個興趣PDLik的聚合度DPDLik。聚合度DPDLik的大小是PDLi與所有PDLik相應的簇內鄰居興趣相似度的平均值,如果DPDLik高于或等于某一臨界值γ,說明當前PDLi與簇內鄰居興趣相似度較高,PDLi不需要搜尋新的簇內鄰居;如果DPDLik低于某一臨界值γ,說明當前PDLi與簇內鄰居關于PDLik的興趣相似度較低,系統(tǒng)會重新搜尋興趣相似度較高的PDLs并加入CRPDLik中。
2.3 基于多興趣的搜索機制
哈佛大學社會心理學教授Stanley Milgram在著名的連鎖信實驗中發(fā)現(xiàn)了典型的小世界現(xiàn)象。受該實驗的啟發(fā),在搜索過程中,PDL將消息轉發(fā)到與搜索信息興趣相似度較高的PDL中,這些通過興趣連接在一起的PDLs不停地將消息轉發(fā)到它們認為最有可能擁有目標資源的PDLs中,可大幅度減少搜索范圍。
基于多興趣的算法流程見圖1。其搜索過程如下:步驟①PDLi發(fā)起一個搜索消息q時,首先將q的搜索內容初始化為向量d,定義q的最大轉發(fā)跳數(shù)TTLq,初始化q所經(jīng)過的PDLs列表ADD和搜索到的文檔列表DOC。其中,ADD存放消息q所經(jīng)過的PDLs的IP,DOC存放搜索到的文檔向量以及相應PDL的IP。計算PDLi中與d相似度最大的興趣PDLik,在路由表CRPDLik中計算與d興趣相似度最大的興趣PDLjr。步驟②將搜索消息q轉發(fā)到PDLj,把PDLj的IP添加到ADD中,計算d與PDLj中所有的共享文檔的興趣相似度。當高于閾值θ時,把該文檔向量和IP添加到文檔列表DOC中,將ttlq減1。如果TTLq等于0,搜索消息q返回PDLi,否則轉到步驟③。步驟③計算CRPDLjr中與d相似度最大的興趣PDLlm。如果列表ADD中含有PDLl的IP,說明消息q已經(jīng)到達過PDLl。為了防止環(huán)路的產生,舍棄PDLl,按興趣相似度由大到小的順序繼續(xù)在CRPDLjr中尋找,直到找到IP不在ADD中的PDLlm(如果CRPDLjr和NCRPDLjr中所有PDLs的IP都在列表ADD中,則搜索結束,消息q返回PDLi),其興趣相似度值為value。如果value小于閾值λ,表明CRPDLjr中的PDLs與d興趣相似度不高。在NCRPDLjr中搜尋與d相似度最大的興趣PDLsn(檢查相應的IP是否在列表ADD中,如果在列表ADD中則利用上面的方法尋找下一個興趣),從PDLlm與PDLsn中選取與d興趣相似度較大的那個興趣作為PDLjr。如果value大于或等于閾值λ,表明CRPDLjr中的PDLs與d興趣相似度較高,不必再去NCRPDLjr中尋找相似度更高的興趣而將PDLlm作為新的PDLjr,重復步驟②。當消息返回到PDLi時,搜索到的文檔將按與d興趣相似度由大到小的順序顯示出來。
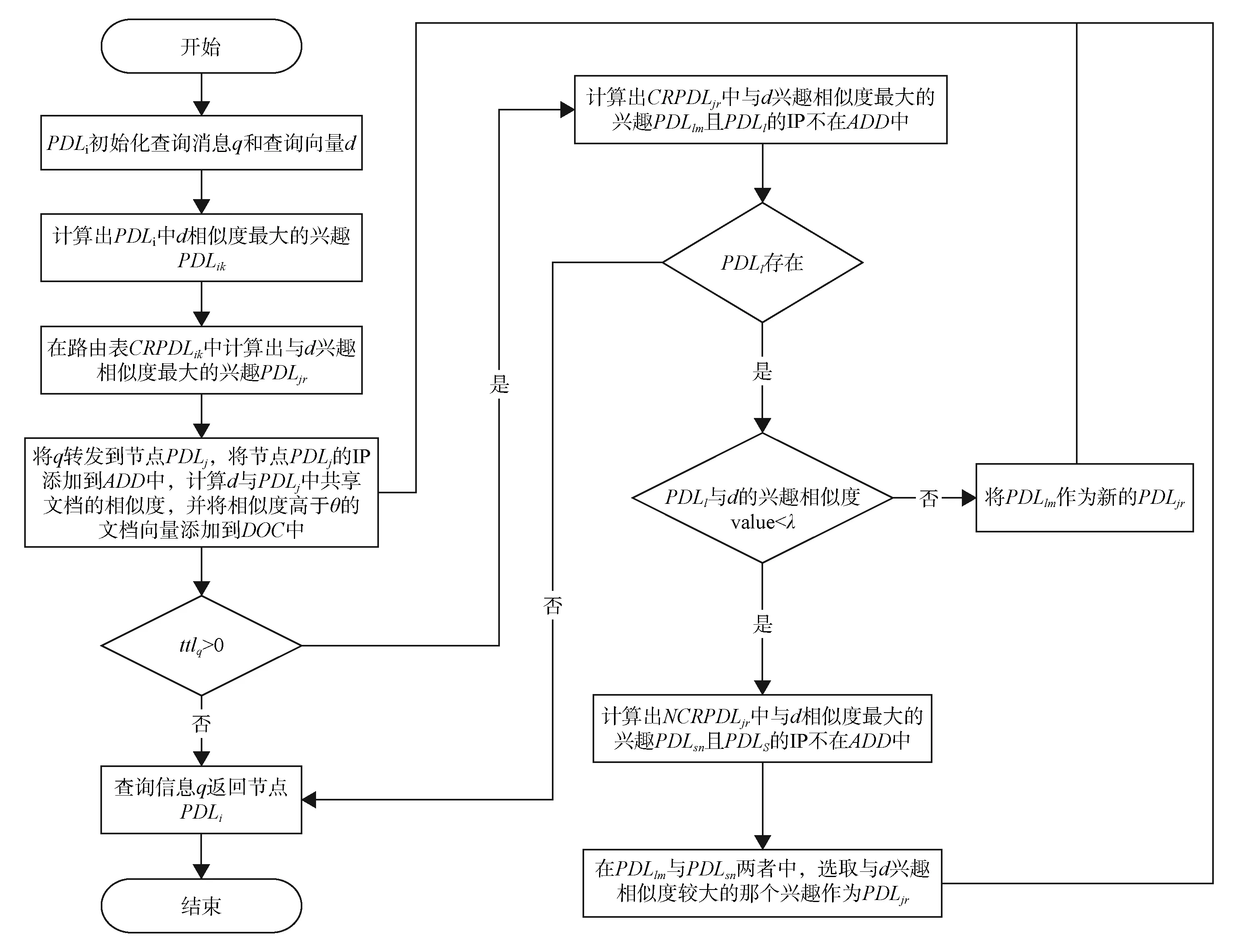
圖1 個人數(shù)字圖書館基于多興趣的資源定位算法流程
3 仿真實驗
3.1 實驗設置
從中國知網(wǎng)期刊論文數(shù)據(jù)庫中選取實驗文檔。根據(jù)中國知網(wǎng)期刊論文數(shù)據(jù)庫的學科分類,從基礎科學、經(jīng)濟與管理科學等10個學科分類中分別選取20個興趣主題,每個興趣主題下載50篇論文。實驗工具采用P2P通用網(wǎng)絡模擬器PeerSim。
在PeerSim中生成一個網(wǎng)絡規(guī)模為1 000個PDLs的全分布式非結構化P2P網(wǎng)絡,將選取的10 000份文檔散布在1 000個PDLs中,每個PDL的文檔所涉及的興趣數(shù)量不超過3個。
3.2 興趣聚合度的確定
系統(tǒng)開始運行后,每個PDL都嘗試啟動聚合度檢測程序,尋找興趣相似度較高的PDLs。為了使PDLs不在同一時刻啟動檢測程序,所有PDLs在0-30分鐘內隨機選擇某一時刻啟動檢測程序。第一次啟動檢測程序后,系統(tǒng)設定PDL定期啟動一次檢測程序,運行10個周期,計算搜索成功率。興趣相似度較高的PDLs聚集在一起是MIPDLM模型正常運行的基礎。閾值γ決定最小聚合度,選取合適的γ值是MIPDLM模型提高搜索效率的前提。為了驗證閾值γ如何取值合適,實驗測試了不同γ值下的搜索成功率,實驗重復10次,每次系統(tǒng)都重新初始化網(wǎng)絡,為每個PDL分配文檔,TTL=6,實驗結果取平均值(圖2)
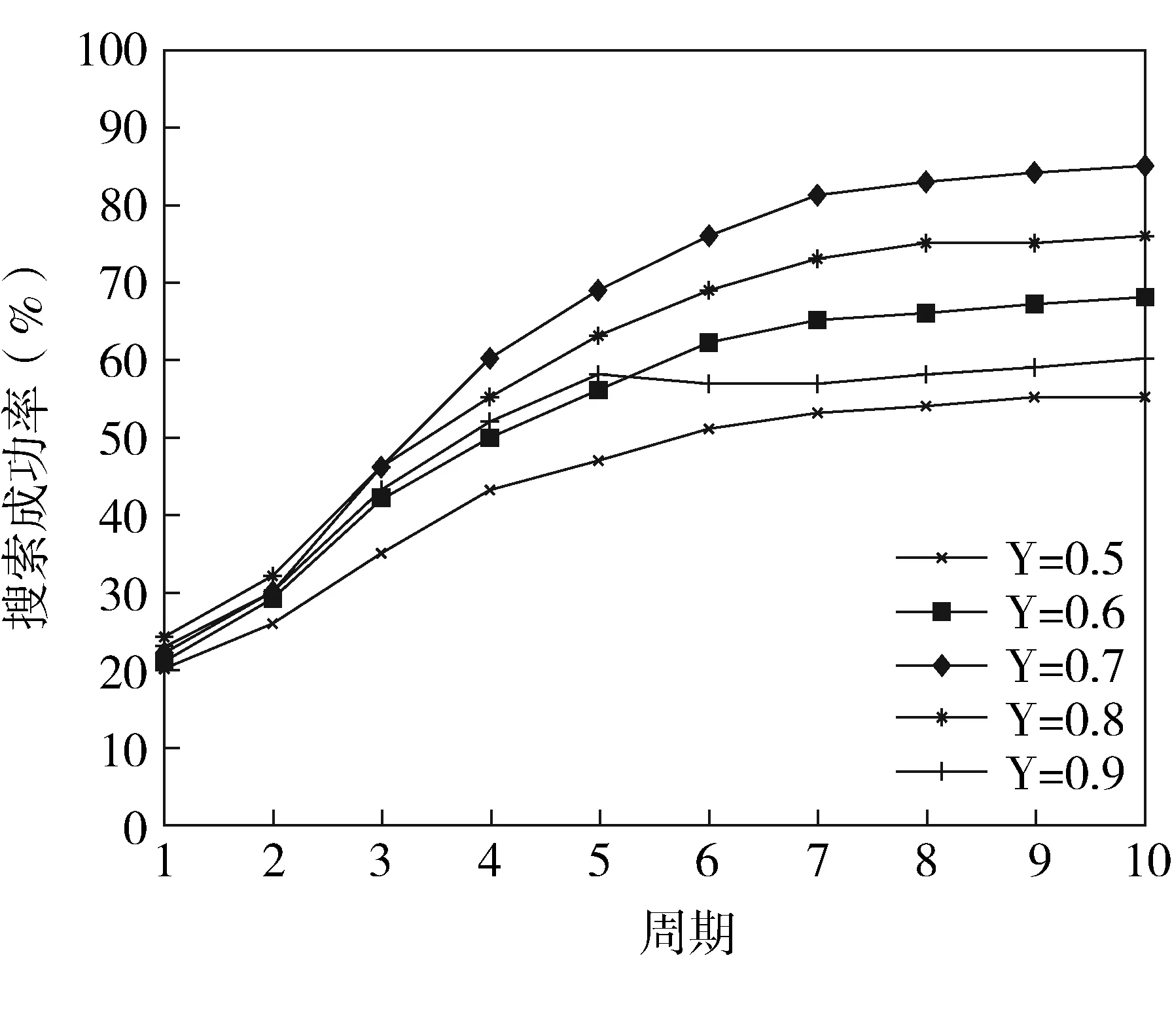
圖2 不同γ值下的搜索成功率
從圖2可以看出,當γ=0.5和γ=0.6時,聚合度太低,興趣相似度較高的PDLs沒能聚集在一起,搜索成功率較低;當γ=0.8和γ=0.9時,興趣相似度較高的PDLs雖然聚集在一起,但是聚合度太高,節(jié)點無法通過興趣相似度較低的PDLs搜索資源,搜索成功率仍然不高;當γ=0.7時,聚合度較為合適,興趣相似度度較高的PDLs聚集在一起,搜索效果較為理想。以下實驗中γ值均取0.7。
3.3 實驗結果及分析
搜索機制的優(yōu)劣主要取決于搜索成功率和平均路徑長度等因素。搜索成功率是指搜索成功次數(shù)在搜索總次數(shù)中所占的比重,搜索成功率越高搜索性能越好;平均路徑長度是指搜索路徑長度的平均值,平均路徑長度越長需要搜索的PDLs越多,在增加延遲的同時也加重了網(wǎng)絡負載,較低的平均路徑長度是搜索機制追求的重要目標。
隨機漫步(Random Walk)是P2P網(wǎng)絡中性能較為優(yōu)越的一種搜索機制[15]。為了驗證MIPDLM模型的性能,需對MIPDLM模型中搜索成功率和平均路徑長度與Random Walk機制進行比較。MIPDLM網(wǎng)絡模型運行一段時間,興趣簇達到一個相對穩(wěn)定的階段后,隨機選取PDL根據(jù)自己的興趣進行搜索,TTL從1增加到10,每個TTL搜索200次,計算結果平均值。
搜索成功率如圖3所示。在TTL相同的情況下,MIPDLM模型的搜索成功率明顯高于Random Walk的。隨著TTL不斷增加,Random Walk的搜索成功率一直處于緩慢上升的趨勢,并且在TTL<4之前搜索成功率上升的幅度較小。當TTL=10時,Random Walk的搜索成功率只有80%左右;當TTL=4時,MIPDLM模型的搜索成功率已接近80%,說明MIPDLM模型中由于PDLs形成興趣簇,興趣一致的PDLs聚集在一起,搜索消息轉發(fā)到興趣相似度較高的PDL中,可大大縮小搜索范圍,絕大部分PDLs能在4跳內搜索到所需資源。搜索平均路徑長度如圖4所示。MIPDLM模型的搜索平均路徑長度明顯低于Random Walk的。Random Walk的平均路徑長度隨著TTL的增加不斷攀升。當TTL=10時,Random Walk的平均路徑長度已接近7。隨著TTL的增加,MIPDLM模型的平均路徑長度維持在4左右,再一次驗證了MIPDLM模型中絕大部分PDLs能在4跳內搜索到所需資源。MIPDLM模型較低的平均路徑長度可減少網(wǎng)絡延遲,減輕網(wǎng)絡負載。
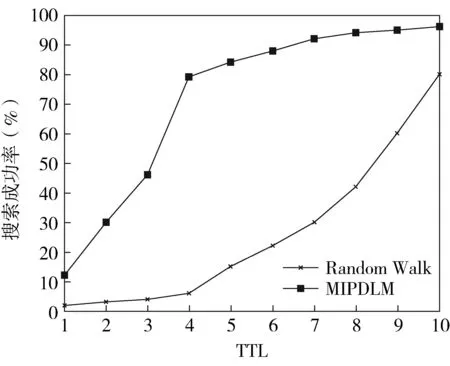
圖3 搜索成功率
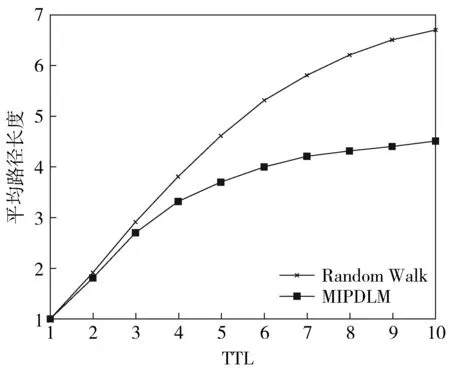
圖4 平均路徑長度
4 結語
本文提出了一種基于多興趣的P2P資源定位機制,個人數(shù)字圖書館可根據(jù)興趣分簇探討基于多興趣的搜索機制。隨著興趣的動態(tài)變化,個人數(shù)字圖書館不斷調整簇內鄰居,系統(tǒng)始終將興趣相似度較高的個人數(shù)字圖書館聚集在一起形成P2P興趣覆蓋網(wǎng)絡。仿真實驗顯示,MIPDLM模型中搜索消息不停地往興趣相似度較高的個人數(shù)字圖書館轉發(fā),個人數(shù)字圖書館基本能在4跳內搜索到所需資源,可大大縮小搜索范圍,提高搜索成功率,減少平均路徑長度,減輕網(wǎng)絡負載,提升個人數(shù)字圖書館的資源定位效率。本文為圖書和檔案共享系統(tǒng)的構建提供的新思路,有助于建立高效的分布式資源定位機制和共享模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
光學精密工程(2016年6期)2016-11-07 09:07:19
