基于二分Kmeans的協同過濾推薦算法
2017-03-06 21:01:39吳金李張建明
軟件導刊 2017年1期
吳金李+張建明

摘要摘要:針對傳統協同過濾推薦算法中存在的數據稀疏性問題,提出了一種基于二分Kmeans的協同過濾推薦算法。該算法在Kmeans算法的基礎上,為了降低初始質點選擇對聚類結果的影響,在運行中逐個添加質點。首先初始化評分數據并將其作為初始簇,然后選擇合適的簇隨機產生兩個質點將簇分裂為兩個簇,重復上述步驟,直到聚類完成。最后為了降低不同用戶評分標準差異,將用戶評分的平均值和用戶同簇內相互間的相似度相結合,計算預測評分矩陣,生成推薦結果。實驗結果表明,改進后的算法較好地解決了數據稀疏問題,提高了推薦質量。
關鍵詞關鍵詞:Kmeans算法;二分Kmeans;協同過濾;推薦算法
DOIDOI:10.11907/rjdk.162275
中圖分類號:TP312文獻標識碼:A文章編號文章編號:16727800(2017)001002603
引言
隨著網絡的發展,互聯網上的信息量飛速增長,推薦系統根據這些用戶行為信息,挖掘對用戶有用的信息對用戶進行個性化推薦。隨著個性化推薦系統的發展,協同過濾算法成為目前使用最廣泛的推薦系統基礎算法[12]。其基本思想是找到與目標對象最相似的對象生成推薦結果[34]。
Goldberg等[5]最早提出協同過濾思想,后來明尼蘇達大學在實際網站建設時又提出基于用戶和基于項目的協同過濾推薦系統,形成傳統的協同過濾推薦算法。在實際應用中隨著用戶數和項目數的增加,系統需要計算的數據量也相應增加,同時用于計算的用戶項目評分矩陣數據變得更稀疏,這些都對推薦系統的性能產生影響。因此Sarwar等[6]利用Kmeans算法對用戶進行聚類,縮小最近鄰的搜索范圍,改善可擴展性問題。Herlocker J等[7]對項目進行聚類,縮小了目標項目的最近鄰搜索范圍,有效減少了運算數據量。Tsai CF等[8]在理論和實驗上闡明,基于SOM和Kmeans聚類方法可以作為協同過濾算法的基準,提高了推薦系統的精度。
針對網絡數據量大、信息種類復雜等問題,在協同過濾推薦算法的基礎上采用大數據處理中的Kmeans算法,可以有效地將數據進行分類,但初始質點的選擇對Kmeans算法聚類的結果影響較大。為解決初始質點選擇問題,本文提出改進二分Kmeans方法,動態地為數據集添加質點,經迭代計算出所有質點,降低初始質點選擇帶來的誤差,并且添加邊界值處理。計算預測評分時針對用戶的評分標準不同,采用平均值法降低其所帶來的影響,結合對象之間的相似度對預測評分方法加以改進。實驗結果表明,本實驗方案效果更好。
1基于Kmeans的協同過濾推薦算法
1.1傳統協同過濾推薦算法
協同過濾算法包括兩種思想,基于用戶協同過濾和基于項目的推薦算法。基于用戶協同過濾算法的基本思想:①找到和目標用戶興趣相似的用戶集合;②找到該集合中用戶喜歡的,且目標用戶沒有聽說過的物品推薦給目標用戶[8],如圖1所示。
圖1基于用戶推薦
首先收集并處理所有用戶信息,然后將目標用戶的信息與用戶信息集合中的信息作相似計算得出相似用戶集合。其中關鍵是計算用戶間的相似度,通過第一步數據的處理,用戶信息已經轉化為空間向量信息,計算空間向量的相似性有效方法,即皮爾森相關系數(PCC)[9]相對于其它方法而言較為準確,例如相對于余弦相似性計算,PCC對向量作去中心和歸一化處理,降低了不同用戶評分標準不同所產生的影響,皮爾森相關系數如式(1)所示。最后根據用戶相似矩陣計算目標用戶未接觸的商品的預測評分產生推薦結果,對用戶進行推薦。
其中Ri、Rj表示用戶評分均值,Rik、Rjk表示用戶對k項目的評分。
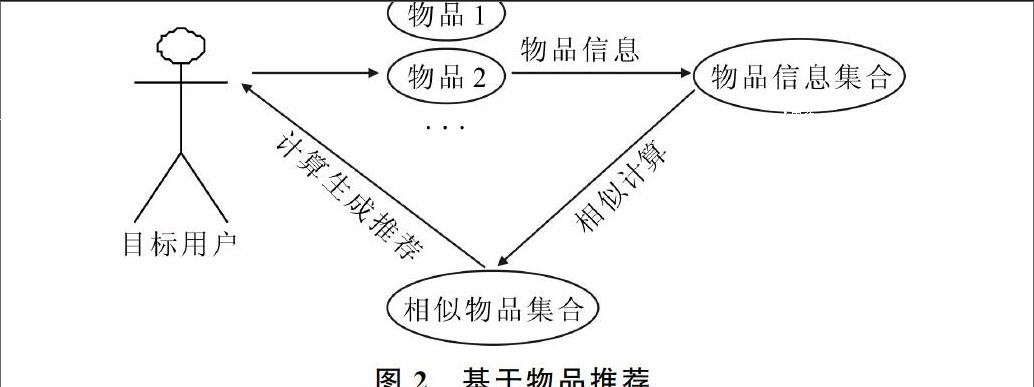
基于物品協同過濾算法基本思想:①計算物品之間的相似度;②根據物品的相似度和用戶的歷史行為生成推薦列表[10],如圖2所示。與基于用戶協同過濾類似,基于物品協同過濾算法首先計算出物品之前的相似度,再根據目標用戶的歷史信息,計算預測與之相似的物品,最后對目標用戶形成推薦。
圖2基于物品推薦
隨著網絡用戶數目的增加,計算用戶相似性的難度加大,運算時間復雜度和空間復雜度的增長和用戶數的增長近似于平方關系。因此,著名的電子商務公司亞馬遜提出了基于物品的協同過濾算法[11]。由此可以看出,基于用戶推薦算法注重找到與用戶相似的用戶集合中的熱點,而基于物品推薦算法則注重用戶的歷史信息,更傾向于個性化推薦。1.2基于Kmeans的協同過濾推薦算法
在計算對象間的相似度時,傳統推薦算法首先計算出每兩位用戶的相似度,當對象的數據量達到一定程度時,相似度計算量將會非常大。因此,為了降低數據計算量,采用大數據中用于數據分類的Kmeans聚類方法。算法首先根據數據大小確定k個質點做初始質心,計算數據集中所有數據距離最近的質點,將數據指派到該質點所在的簇中。然后根據指派到簇的點,更新每個質心。重復以上步驟,直到質心不再變化,數據被指派到不同的簇[1013]。
為了計算目標用戶的相似用戶,首先計算目標用戶和每個簇內質心的相似性,計算出目標用戶所屬簇。再計算出目標用戶和簇內用戶的相似性,得出目標用戶相似用戶集合。最后對目標用戶未接觸的物品預測評分后生成推薦。
2基于二分Kmeans的協同過濾推薦算法
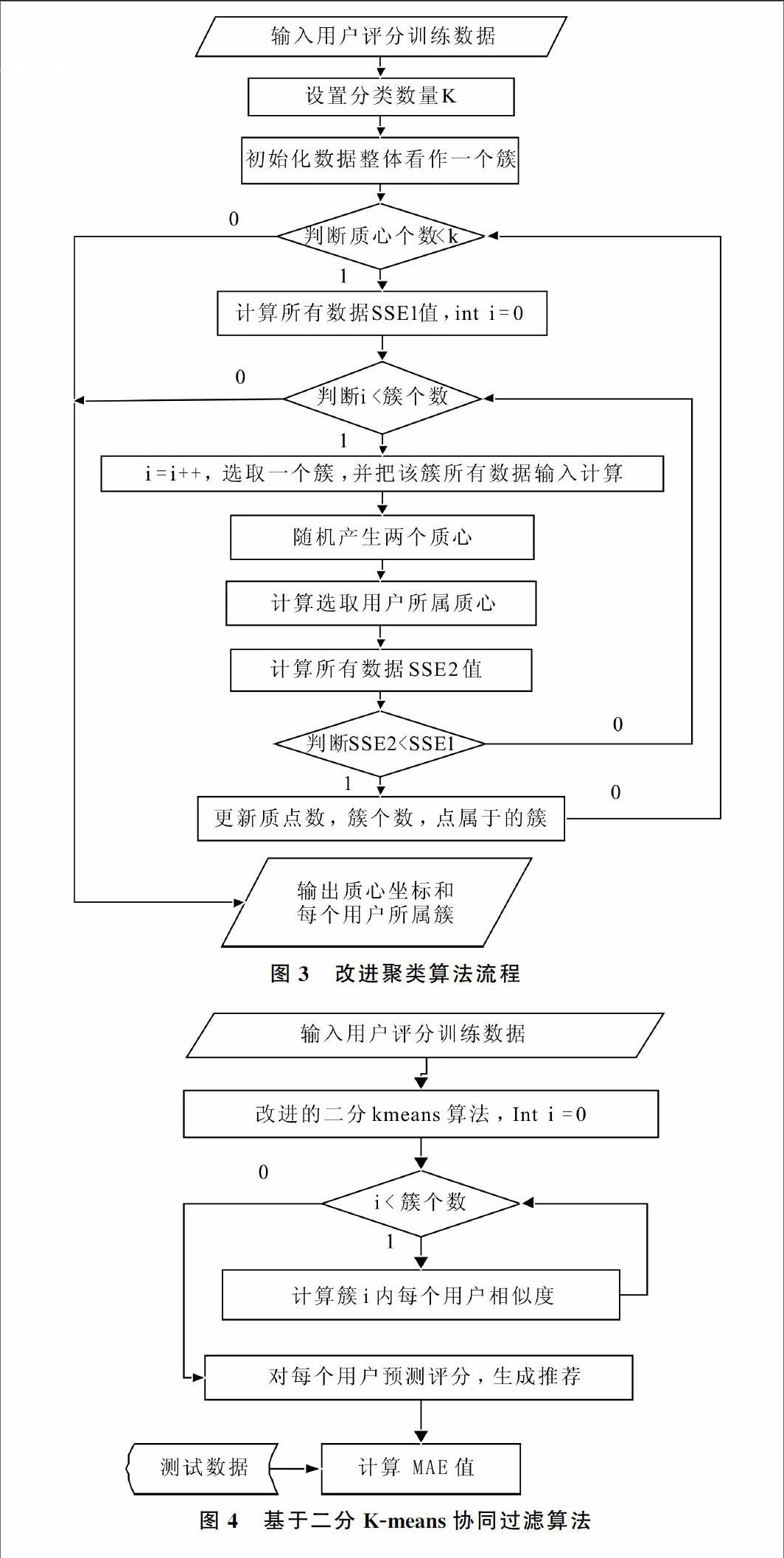
Kmeans算法最重要的是質心的選擇,質心的選擇可以根據數據集中數據的范圍,隨機生成指定個數的質心。當簇的數量比較大時,比較容易出現質點在簇中分布不均,即可能出現有些簇中質點個數相當少的情況,此時這些初始質心到其它質心的距離較大[12]。當質心相對距離較遠時,Kmeans算法不能很好地在簇與簇之間重新計算分布質點,因而聚類結果不佳。為了改善Kmeans聚類方法初始質心選擇所帶來的影響,采用二分Kmeans算法。二分Kmeans算法思想是為了得到k個簇,將所有點的集合分裂成兩個簇,再根據SSE值從這些簇中選取一個最大的繼續分裂,直到產生k個簇。其中SSE表示javascript:;用數據集中每個數據和其質心的歐幾里得距離計算誤差平方,然后求得所有誤差和。SSE公式如式(2)所示[13]。
其中,ci表示質心坐標,x表示質心為ci的數據。dist表示空間兩個向量的歐幾里得距離。每次選定最小的SSE后,重新計算每個簇的質心,采用均值法來計算。第i個簇的質心由式(3)定義。
ci=1mi∑x∈Cix(3)
一般二分Kmeans算法在選取對哪一簇分類有多種方法時,可以選擇SSE結果最大簇或者基于一個標準SSE值來選擇,并且不考慮邊界情況。本文在選取分類簇上按照簇的編號,依次選取。如果在已有的簇中找不到分類后更小的SSE值,并且質心個數小于k,則停止循環,輸出現有質心坐標和分類結果。具體流程如圖3所示。首先初始化數據,然后判斷質心個數是否小于k值,若成立則循環計算分類前SSE1值和分類后SSE2值直到SSE2 對每個簇中所有用戶的數據根據皮爾森相關系數[14]計算同一簇內每兩個用戶間的相似性,然后對用戶未評分的部分預測評分。根據相似性,由于每個用戶評分標準不同,在計算評分時消除個人評分對目標評分結果的影響。具體實現如式(4)所示。 pu,i=Ru+∑j∈Misim(u,j)×(Rj,i-Rj)∑j∈Mi(|sim(u,j)|)(4) 其中,Pu,i表示用戶u對項目i的評分,Ru表示用戶評分均值,Rj,i表示j用戶對i項目的評分,Rj表示j用戶評分均值。 基于二分Kmeans推薦算法首先對初始數據聚類,然后計算每個簇中用戶相似性,最后對用戶評分矩陣進行評分預測后,找出預測評分最高的前N個物品形成推薦[15]。具體實現步驟如圖4所示。 Step1:將用戶評分數據分為訓練集和測試集,將兩類數據分別存入二維數組中。 Step2:設置分類數量k。 Step3:將訓練集數據帶入圖3流程圖進行計算,得到k個質心坐標,并為數組存放每位用戶所屬的簇。 Step4:根據式(1)計算k個簇內每位用戶在其對應的簇內與同簇內每位用戶的相似性,求出k個相似矩陣表。 Step5:將相似矩陣表和初始數據表中數據帶入式(4)得到預測評分,根據topN得到推薦。 3實驗結果及分析 實驗數據是MovieLens數據集中小規模的庫,包括943位獨立用戶對1 682部電影的100 000次評分數據。用戶對已看過的電影評分,評分范圍為1~5。實驗采用Java開發平臺,根據用戶評分生預測評分矩陣從而形成推薦。 評價推薦系統推薦質量的度量標準采用平均絕對誤差MAE進行度量。通過計算預測評分和實際評分的MAE值來判斷推薦效果。當MAE值越小時,推薦的質量越高,反之推薦的質量越低。MAE公式如式(5)所示,其中pi表示系統對用戶的預測評分,qi表示用戶的實際評分。 MAE=∑Ni=1|pi-qi|N(5) 本文對Kmeans協同過濾和二分Kmeans協同過濾算法在相同數據集中進行比較,實驗結果如圖5所示,最近鄰個數增加時MAE值減小,表示預測結果越好,基于二分Kmeans的協同過濾推薦效果優于基于Kmeans協同過濾的推薦效果。 4結語 隨著互聯網科技的發展,網絡數據蘊含的信息將逐漸被人挖掘,推薦系統可以有效地處理數據,但由于網絡數據存在數據稀疏、數據量大等問題,因而本文采用基于二分Kmeans的協同過濾推薦算法。該算法將相同類別的數據聚集在一起,將不同類別的數據加以分離,降低運算量。對數據動態地添加質點,再更新數據類別,可提高數據分類效果,使得每個類別內的數據結合更緊密,類之間的差距也相應增加。實驗結果表明,本文采用基于二分Kmeans的協同過濾推薦算法能夠有效提高算法性能。 參考文獻: [1]LINDEN G,SMITH B,YORK J.Amazon.com recommendations:itemtoitem collaborative filtering[J].IEEE Internet Computing,2003,7(1):7680. [2]CHUNG K Y,LEE D,KIM K J.Categorization for grouping associative items using data mining in itembased collaborative filtering[J]. Multimedia Tools & Applications,2014,71(2):889904.
