基于機(jī)器視覺的凍干粉中的異物檢測分類技術(shù)研究*
2017-02-09 10:00:56丁金如孟志剛楊燕鶴
計(jì)算機(jī)與數(shù)字工程 2017年1期
關(guān)鍵詞:分類
丁金如 孟志剛 楊燕鶴
(長沙學(xué)院數(shù)學(xué)與計(jì)算機(jī)科學(xué)系 長沙 410003)
?
基于機(jī)器視覺的凍干粉中的異物檢測分類技術(shù)研究*
丁金如 孟志剛 楊燕鶴
(長沙學(xué)院數(shù)學(xué)與計(jì)算機(jī)科學(xué)系 長沙 410003)
利用數(shù)字圖像處理技術(shù)對凍干粉不良品進(jìn)行檢測分類。為了更高效地自動(dòng)檢測并分類出凍干粉中存在的纖維、毛發(fā)、玻璃碎屑等可見異物,研究了基于主成分分析(PCA)特征提取,并用BP神經(jīng)網(wǎng)路和支持向量機(jī)(SVM)算法進(jìn)行分類識(shí)別。通過工業(yè)小樣本數(shù)據(jù)仿真實(shí)驗(yàn),測試結(jié)果表明,兩種方法都具有較好的可行性和實(shí)用性,相比之下基于PCA與SVM算法的識(shí)別率比基于PCA與BP算法的識(shí)別率高。
可見異物檢測; 主成分分析; BP神經(jīng)網(wǎng)絡(luò); 支持向量機(jī)
Class Number TP391
1 引言
凍干粉是在無菌環(huán)境下將藥液冷凍成固態(tài),抽真空將水分升華干燥而成的無菌粉注射劑。該方法使產(chǎn)品的保存更加穩(wěn)定,但是凍干粉針劑產(chǎn)品中的可見異物是一直困擾生產(chǎn)者、使用者的質(zhì)量問題。凍干粉針劑產(chǎn)品中常見的可見異物主要有纖維、毛發(fā)、玻璃碎屑、黑點(diǎn)等,使產(chǎn)品存在著很大的質(zhì)量隱患。為了檢測產(chǎn)品中的不良品,傳統(tǒng)的檢測方法為人工視覺檢測,這種方法不僅效率低、質(zhì)量差、工人勞動(dòng)強(qiáng)度大,易產(chǎn)生視覺疲勞,不僅消耗了大量的勞動(dòng)力,而且增加了生產(chǎn)成本。相比而言,機(jī)器視覺檢測具有長期連續(xù)、無疲勞、快速的工作特點(diǎn),應(yīng)用于凍干粉針劑產(chǎn)品中的可見異物的檢測,既提高了檢測識(shí)別速度,又降低了生產(chǎn)成本,具有較高的實(shí)用價(jià)值。國內(nèi)將機(jī)器視覺用于藥液異物檢測已經(jīng)做了很多工作,肖方良等[1]主要開展安瓿瓶溶液內(nèi)運(yùn)動(dòng)異物的檢測與跟蹤方面的研究。其通過旋轉(zhuǎn)急停的方式來獲取圖像,用差分法對目標(biāo)微粒進(jìn)行提取,并簡述了兩幀差分和三幀差分的原理,采用粒子濾波與模板匹配相結(jié)合的方式跟蹤運(yùn)動(dòng)目標(biāo);葛繼等人[2~3]先采用序列圖像差分方法提取出感興趣區(qū)域,再采用訓(xùn)練后的脈沖耦合神經(jīng)網(wǎng)絡(luò)有效識(shí)別出口服液藥液中異物特征;目前以凍干粉為目標(biāo)用機(jī)器視覺進(jìn)行異物檢測分類的研究還很少見。本文針對數(shù)字圖像識(shí)別分類環(huán)節(jié),研究了基于主成分分析(PCA)特征提取,并用BP神經(jīng)網(wǎng)路和支持向量機(jī)(SVM)算法進(jìn)行分類識(shí)別。來提高凍干粉針劑產(chǎn)品中異物檢測的識(shí)別率。通過工業(yè)小樣本數(shù)據(jù)仿真實(shí)驗(yàn),測試結(jié)果表明,兩種方法都具有較好的可行性和實(shí)用性,相比之下基于PCA與SVM算法的識(shí)別率比基于PCA與BP算法的識(shí)別率高。
2 主成分分析PCA
Pearson在1901年第一次提出了[4~5](Principal Components Analysis,PCA)的方法。主成分又稱主分量、主元素。它的實(shí)質(zhì)是K-L變換,即最優(yōu)正交變換。簡單地說,它的原理就是將一個(gè)高維向量,通過一個(gè)特殊的特征向量矩陣,投影到一個(gè)低維的向量空間中,表征為一個(gè)低維向量,并僅損失一些次要信息。也就是說,通過低維表征的向量和這個(gè)特征向量矩陣,可以重構(gòu)出所對應(yīng)的原來的高維向量。從信息論的觀點(diǎn)來看,就是在所有的正交變換中,K-L變換所對應(yīng)的信息熵最小,所以用PCA方法所獲得的特征空間就是原圖像空間的一個(gè)最優(yōu)低維逼近。
2.1 PCA算法

(1)
其中,n表示樣本的總數(shù),m表示樣本的均值。
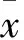
(2)
設(shè)St的秩為k;而λ1,λ2,…,λk是矩陣St的特征值,且λ1≥λ2≥…≥λk,ωi,i=1,2,…,k為對應(yīng)的特征向量。則λi與ωi滿足:
Stωi=λωii=1,2,…,k
(3)
令W=[ω1,ω2,…,ωk]在主分量分析中,可講特征向量ωi,稱為這組樣本的主成分(Principal Components),W稱為這組樣本的主成分矩陣。
對一個(gè)n維隨機(jī)變量x,經(jīng)過下式的變換:
y=WT(x-m)
(4)
可以得到一個(gè)新的n維變量Y,y=[y1,y2,…,yn]T。從代數(shù)空間的角度講,這一變換就是將變量x向W所對應(yīng)的一組基進(jìn)行投影,得到一組投影系數(shù)Y。Y就稱為x在這組數(shù)據(jù)下經(jīng)PCA變換后的結(jié)果。
已知投影系數(shù)y后,可以按下式重構(gòu)出原始數(shù)據(jù):

(5)
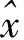
2.2 PCA快速算法
PCA的計(jì)算中最主要的工作量是計(jì)算樣本協(xié)方差矩陣(散布矩陣)的特征值和特征向量。設(shè)樣本矩陣X大小為n×d(n個(gè)d維樣本特征向量),則計(jì)算樣本協(xié)方差矩陣St將是一個(gè)d×d的方陣,所以當(dāng)維數(shù)d較大時(shí),直接計(jì)算的相當(dāng)困難,要得到樣本協(xié)方差矩陣的全部特征值可能要花費(fèi)很長時(shí)間。因此,可采用PCA快速算法。
設(shè)Zn×d矩陣為樣本矩陣X中每個(gè)樣本減去樣本均值m后得到的矩陣,則散布矩陣S為(ZTZ)d×d。現(xiàn)引入一個(gè)新的矩陣R,令
R=(ZZT)n×n
(6)
則很容易發(fā)現(xiàn)矩陣的維數(shù)是n×n。一般情況下由于樣本n數(shù)目遠(yuǎn)遠(yuǎn)小于樣本維數(shù)d,R的尺寸也遠(yuǎn)遠(yuǎn)小于S,計(jì)算R的特征值會(huì)比較方便。借助線性代數(shù)的理論,可以證明S和R有著相同的非零特征值,所以通過計(jì)算R的特征值可以直接得到S所對應(yīng)的特征值。

(7)
式(7)兩邊同時(shí)左乘(ZT),由矩陣的乘法結(jié)合律得到下式:
(8)
利用上面的結(jié)論,可以通過計(jì)算小矩陣的特征值和特征向量,間接得到矩陣的特征值和特征向量,由于矩陣的維數(shù)遠(yuǎn)遠(yuǎn)小于矩陣的維數(shù),所以利用這種做法可以大大減小傳統(tǒng)PCA算法中的計(jì)算量,提高運(yùn)算速度。
3 BP神經(jīng)網(wǎng)絡(luò)
BP[6]網(wǎng)絡(luò)最早于1974年由Werbos提出,但當(dāng)時(shí)無合適的學(xué)習(xí)算法,故沒有得到重視,直到1985年Romelhart和Mcclelland提出了誤差反向傳播算法(error back propagation algorithm),才把BP網(wǎng)真正推向?qū)嵱?BP網(wǎng)也是由此算法而命名。BP網(wǎng)是單向傳播的多層前向網(wǎng)絡(luò),由輸入層、輸出層和隱含層組成,每層有若干個(gè)神經(jīng)元(也稱節(jié)點(diǎn)),同層神經(jīng)元間無耦合,節(jié)點(diǎn)的激活函數(shù)必須可微、非減,通常用Sigmoid函數(shù)。
BP[7~8](反向傳播)名字的得來是因?yàn)樗谶\(yùn)行過程中將輸出層的誤差從后向前逐層傳播。BP把Widrow-Hoff學(xué)習(xí)規(guī)則推廣到具有多層和非線形傳遞函數(shù)(如Sigmoid函數(shù))的神經(jīng)網(wǎng)絡(luò)。標(biāo)準(zhǔn)BP是一個(gè)梯度下降算法,它通過迭代地減小訓(xùn)練樣本的目標(biāo)值和網(wǎng)絡(luò)輸出間的均方誤差來實(shí)現(xiàn)對可能的網(wǎng)絡(luò)權(quán)值空間的梯度下降搜索。BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖如圖1所示。

圖1 BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖
神經(jīng)元i的輸出與輸入的關(guān)系表示為
若用X表示輸入向量,用W表示權(quán)重向量,即:
則神經(jīng)元的輸出可以表示為向量相乘的形式:
neti=XWyi=f(neti)=f(XW)
BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)介紹:x1,…,xn為輸入向量的各個(gè)分量;z1,…,zq為隱含向量的各個(gè)分量;y1,…,ym為輸出向量的各個(gè)分量;v1,…,vn和w1,…,wq為神經(jīng)元各個(gè)突觸的權(quán)值θ為偏置(bias),或者稱之為閾值(threshold);f為傳遞函數(shù),通常為非線性函數(shù)。一般有traingd(),tansig(),hardlim()。
每次輸入一個(gè)樣本,便將網(wǎng)絡(luò)輸出與目標(biāo)輸出相比較。算法將調(diào)整網(wǎng)絡(luò)參數(shù)(連接權(quán)值)以使均方誤差最小化。
常用的包含兩層Sigmoid單元的前向網(wǎng)絡(luò)的BP算法如下:
· 創(chuàng)建具有Nin個(gè)輸入,Qhidden個(gè)隱藏單元,Mout個(gè)輸出單元的網(wǎng)絡(luò);
· 初始化所有的網(wǎng)絡(luò)權(quán)值為較小的隨機(jī)值(例如-0.05~+0.05之間的數(shù));
· 在遇到終止條件(如最大迭代代數(shù)或滿足的性能指標(biāo))前:
對于訓(xùn)練樣本中的每個(gè):把輸入沿網(wǎng)絡(luò)前向傳播
1) 把樣本xk輸入網(wǎng)絡(luò),計(jì)算網(wǎng)絡(luò)中每個(gè)單元的輸出out使誤差沿網(wǎng)絡(luò)反向傳播
2) 對于網(wǎng)絡(luò)的每個(gè)輸出單元i,計(jì)算它的誤差項(xiàng)δi;
3) 對于網(wǎng)絡(luò)的每個(gè)隱藏單元j,計(jì)算它的誤差項(xiàng)δj;
4) 使用梯度下降法更新每個(gè)網(wǎng)絡(luò)權(quán)值Wij。
4 SVM分類器
SVM[9~10]是一種基于統(tǒng)計(jì)學(xué)習(xí)理論的模式識(shí)別方法,它是由Boser,Guyon,Vapnik在COLT-92上首次提出,從此迅速地發(fā)展起來,現(xiàn)在已經(jīng)在許多領(lǐng)域(生物信息學(xué),文本,圖像處理,語言信號(hào)處理和手寫識(shí)別等)都取得了成功的應(yīng)用。
SVM的主要思想[11]可以概括為兩點(diǎn): 1) 它是針對線性可分情況進(jìn)行分析,對于線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉(zhuǎn)化為高維特征空間使其線性可分,從而使得高維特征空間采用線性算法對樣本的非線性特征進(jìn)行線性分析成為可能; 2) 它基于結(jié)構(gòu)風(fēng)險(xiǎn)最小化理論之上在特征空間中建構(gòu)最優(yōu)分割超平面,使得學(xué)習(xí)器得到全局最優(yōu)化,并且在整個(gè)樣本空間的期望風(fēng)險(xiǎn)以某個(gè)概率滿足一定上界。
SVM(支持向量機(jī)學(xué)習(xí))方法主要有以下幾種模型:線性可分支持向量機(jī)、線性支持向量機(jī)及非線性支持向量機(jī)。當(dāng)訓(xùn)練數(shù)據(jù)線性可分時(shí),通過硬間隔最大化,學(xué)習(xí)一個(gè)線性的分類器,即線性可分支持向量機(jī),又稱為硬間隔支持向量機(jī)。當(dāng)訓(xùn)練數(shù)據(jù)近似線性可分時(shí),通過軟間隔最大化,也學(xué)習(xí)一個(gè)線性分類器,即線性支持向量機(jī),又稱軟間隔支持向量機(jī)。當(dāng)訓(xùn)練數(shù)據(jù)線性不可分時(shí),通過使用核技巧和軟間隔最大化,學(xué)習(xí)非線性支持向量機(jī)。
SVM最初是用來對二分類問題進(jìn)行分類的,在線性可分的情況下,對于訓(xùn)練集(xi,yi)其中xi∈RNyi∈{-1,1},i=1,2,3,…,n目標(biāo)是找到一個(gè)超平面,使得它能夠盡可能多地將兩類數(shù)據(jù)點(diǎn)正確的分開,目標(biāo)是找到一個(gè)超平面能夠?qū)深悩颖就耆珠_且兩類間的間隔最大。不妨設(shè)超平面的方程為:w·x+v=0,將w·x+b>0的歸為1類,而w·x+b<0的則歸為-1類。兩類間隔的最大化等價(jià)于最小化:

(9)
約束條件:
yi(w·x+b)≥1,?i∈{1,2,3,…,n}
引入Lagrange乘子αi,得到式(10)的Wolf對偶形式為
(10)
在解得α之后,平面參數(shù)w和b便可以由對偶問題的解α來確定。由此可以得到持向量機(jī)的最優(yōu)分類函數(shù):
(11)
對于非線性可分的情況,則需要利用核函數(shù)將原樣本映射到高維空間中轉(zhuǎn)化為高維空間中的線性可分問題,其對應(yīng)的目標(biāo)函數(shù)變?yōu)?/p>

(12)
式中,C為懲罰因子,ε是松弛變量,此時(shí)約束條件變?yōu)?/p>
yi(w·x+b)≥1-εi,εi≥0,?i∈{1,2,3,…,n}
(13)
而最優(yōu)的分類函數(shù)則變?yōu)?/p>
(14)
式中,K(xi·x)為核函數(shù)。常見的核函數(shù)有:
· 線性核函數(shù):K(x,y)=x·y;
· 多項(xiàng)式核函數(shù):K(x,y)=(x·y+1)d,d=1,2,3,…;
· 徑向基核函數(shù):K(x,y)=exp(-γ‖x-y‖2);
· Sigmoid核函數(shù):K(x,y)=tanh(b(x·y)-c)。
5 實(shí)驗(yàn)及分析
5.1 實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)利用Matlab R2014b編程實(shí)現(xiàn),使用了臺(tái)灣大學(xué)林智仁教授的libsvm工具。使用工業(yè)拍攝的凍干粉針劑不良品圖片作為數(shù)據(jù)集。數(shù)據(jù)包含纖維、毛發(fā)、玻璃碎片等異物,數(shù)據(jù)圖片如圖2、3所示。大多數(shù)圖像的光照方向和強(qiáng)度相差不大,其中相同類異物拍攝的角度有著不同程度的變化,角度差異在20°左右,同一類可見異物的形狀大小也有相當(dāng)程度的變化。將數(shù)據(jù)集中每一類的異物圖像分成兩組,前5張作為訓(xùn)練集,剩余5張作為測試集,實(shí)現(xiàn)兩類可見異物的識(shí)別分類。

圖2 毛發(fā)異物

圖3 玻璃碎屑異物
5.2 實(shí)驗(yàn)過程
5.2.1 PCA算法提取異物特征
利用快速PCA降維去除像素之間的相關(guān)性。從訓(xùn)練集樣本中提取主成分,實(shí)驗(yàn)中將主成分的數(shù)目確定為10,通過投影完成基的轉(zhuǎn)換。經(jīng)過這樣處理,訓(xùn)練集中的每個(gè)異物樣本的特征向量由高維降為10維,在后續(xù)的實(shí)驗(yàn)中就以10維的特征向量來代表該異物樣本。
5.2.2 構(gòu)造BP神經(jīng)網(wǎng)絡(luò)
1) 對樣本集進(jìn)行歸一化
確定輸入樣本和輸出樣本,并對它們進(jìn)行歸一化,使用Matlab的歸一化函數(shù)premnmx將數(shù)據(jù)變換到[-1,1]區(qū)間。
2) 創(chuàng)建BP神經(jīng)網(wǎng)絡(luò)
在樣本集確定之后,即可進(jìn)行網(wǎng)絡(luò)的結(jié)構(gòu)設(shè)計(jì),在Matlab中使用newff創(chuàng)建函數(shù),它不但創(chuàng)建了網(wǎng)絡(luò)對象,還自動(dòng)初始化網(wǎng)絡(luò)的權(quán)重和閾值。如果需要重新初始化網(wǎng)絡(luò)權(quán)重和閾值,可以使用init函數(shù)。
關(guān)鍵語句:net=init(net);
net=newff(P,T,[S1 S2],{'tansig','logsig'});
P為網(wǎng)絡(luò)實(shí)際輸入;T為網(wǎng)絡(luò)應(yīng)有輸出;S1與S2為網(wǎng)絡(luò)層的神經(jīng)元數(shù)目;'tansig'與'logsig'為網(wǎng)絡(luò)層神經(jīng)元的激活函數(shù)。
實(shí)驗(yàn)選用四層BP網(wǎng)絡(luò),輸入層、輸出層、兩層隱含層。
3) 設(shè)置網(wǎng)絡(luò)的訓(xùn)練參數(shù)
net.trainParam.epochs = 50; 最大收斂次數(shù);
net.trainParam.goal = 0.01; 收斂誤差;
4) 訓(xùn)練BP網(wǎng)絡(luò)
關(guān)鍵語句為:net = train(net,P,T);
5) 訓(xùn)練成功,相關(guān)結(jié)果輸出
圖像經(jīng)過PCA提取特征值并用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行識(shí)別分類的方法,通過工業(yè)采集的小樣本數(shù)據(jù)仿真實(shí)驗(yàn),結(jié)果表明:識(shí)別率最高為90%,平均識(shí)別率為84%。
PCA+BP方法的平均識(shí)別率只有84%,為了進(jìn)一步提高小樣本的異物識(shí)別率,又探討了基于PCA特征提取并結(jié)合SVM識(shí)別的方法。
5.2.3 構(gòu)建兩類SVM
1) 根據(jù)給定的數(shù)據(jù),選定訓(xùn)練集和測試集;
訓(xùn)練集:trainset();分別取S1(1:5,:)和S2(1:5,:)作為訓(xùn)練集;
測試集:testset();分別取S1(6:10,:)和S2(6:10,:)作為測試集;
2) 為訓(xùn)練集與測試集選定標(biāo)簽集;
標(biāo)簽集:label();取S1的數(shù)據(jù)為正類標(biāo)簽為1;S2的數(shù)據(jù)為負(fù)類標(biāo)簽為-1。
3) 利用訓(xùn)練集進(jìn)行訓(xùn)練分類器得到model;
4) 根據(jù)model,對測試集進(jìn)行測試集得到accuracy rate。
圖像經(jīng)過PCA提取特征值并用SVM進(jìn)行識(shí)別分類的方法,通過工業(yè)采集的小樣本數(shù)據(jù)仿真實(shí)驗(yàn),結(jié)果表明:平均識(shí)別率為90%,如圖4所示。
5.2.4 實(shí)驗(yàn)結(jié)果與分析
快速PCA算法可以實(shí)現(xiàn)有效的降維,本實(shí)驗(yàn)中可見異物圖像的樣本的特征向量從高維,降到20維。這樣可以降低運(yùn)算量,提高異物的識(shí)別速率。

圖4 PCA+SVM實(shí)驗(yàn)結(jié)果
針對上述的兩種方法分別通過工業(yè)采集的小樣本數(shù)據(jù)進(jìn)行仿真實(shí)驗(yàn)(數(shù)據(jù)完全相同),實(shí)驗(yàn)結(jié)果如圖5,表1所示。

圖5 兩種方法識(shí)別率比較

方法最高識(shí)別率平均識(shí)別率PCA+BP90%84%PCA+SVM90%90%
從表1中可以看出在解決小樣本數(shù)據(jù)集、非線性識(shí)別的問題中,基于PCA特征提取并結(jié)合SVM分類算法的實(shí)驗(yàn)具有較高的識(shí)別率。
6 結(jié)語
本文利用數(shù)字圖像處理技術(shù)對凍干粉針劑產(chǎn)品中存在的纖維、毛發(fā)、玻璃碎屑、黑點(diǎn)等異物進(jìn)行檢測分類。先探究了基于PCA特征提取并結(jié)合BP神經(jīng)網(wǎng)路識(shí)別分類算法。經(jīng)過工業(yè)采集到的凍干粉針劑不良品圖片進(jìn)行實(shí)驗(yàn),平均識(shí)別率可以達(dá)到84%。為了更高效地檢測并分類出不良品,又進(jìn)行了基于PCA特征提取并結(jié)合SVM分類算法的實(shí)驗(yàn),識(shí)別率可以達(dá)到90%。相比之下,對于小樣本數(shù)據(jù)的分類識(shí)別,基于PCA特征提取并結(jié)合SVM分類算法效果較好。實(shí)驗(yàn)結(jié)果表明,采集的凍干粉針劑圖片越多,圖片清晰度越高,識(shí)別的準(zhǔn)確度就越高。在下一步的學(xué)習(xí)過程中可以研究如何有效地選擇SVM的參數(shù)并進(jìn)行多分類的實(shí)驗(yàn),或者探討異物形狀對異物識(shí)別率的影響。
[1] 肖方良,王耀南,章使,等.安瓿制劑中的可見異物實(shí)時(shí)視覺檢測系統(tǒng)研究[J].計(jì)算機(jī)測量與控制,2010,18(2):295-298. XIAO Fangliang, WANG Yaonan, ZHANG Shi, et al. Research on an On-line Detection System for Foreign Substances in ampoule[J]. Computer Measurement & Control,2010,18(2):295-298.
[2] 葛繼,王耀南,張輝,等.基于改進(jìn)型PCNN的智能燈檢機(jī)研究[J].儀器儀表學(xué)報(bào),2009,30(9):1867-1873. GE Ji, WANG Yaonan, ZHANG Hui, et al. Study of intelligent inspection machine based on modified pulse coupled neural network[J]. Chinese Joumal of Scientific Instrument,2009,30(9):1867-1873.
[3] 魯娟,王耀南,余洪山,等.大輸液中可見異物智能在線檢測系統(tǒng)設(shè)計(jì)[J].計(jì)算機(jī)測量與控制,2008,16(12):1802-1805. LU Juan, WANG Yaonan, YU Hongshan, et al. Research on Online Detection System for Foreign Substances in a Transfusing Bottle of Medicinal Solution[J]. Computer Measurement & Control,2008,16(12):1802-1805.
[4] Jawed A. Face Recognition Based on Principal Component Analysis[J]. International Journal of Image, Graphics and Signal Processing(IJIGSP),2013,5(2):38.
[5] He Lianghua. Multi-Dimension Principal Component Analysis based on face recognition[J]. The Journal of New Industrialization,2012,2(1):59-65.
[6] Shi Zhongke. Neural Network Control Theroy[C]//Northwestern Polytechnical Publishing House, Xi’an,1997.
[7] Watrous R L. Learning algorithms for connectionist network: applied gradient methods of nonlinear optimization[C]//Proceedings of IEEE InternationaI Conference on Neural Networks. IEEE Press, New York,1987:619-627.
[8] Shar S, Palmieri F, Datum M. OptimaIfiIteringaIgorithms for fast learning in feedforward neural networks[J]. Neural Networks,1992,5(5):779-787.
[9] Burges C. J. C. A Tutorial on Support Vector Machines for Pattern Recognition[J]. Data Mining and Knowledge Discovery,1998,2(2):121-167.
[10] Comes C., Vapnik V. Support Vector Networks[J]. Machine Learning,1995,20:273-295.
[11] 鄧乃揚(yáng),田英杰.數(shù)據(jù)挖掘中的新方法一支持向量機(jī)[M].北京:科學(xué)出版社,2004:202-354. DENG Naiyang, TIAN Yingjie. A new method in data mining support vector machine[M]. Beijing: Science Press,2004:202-354.
Detection and Classification of the Foreign Matter of Lyophilized Powder Based on Machine Vision
DING Jinru MENG Zhigang YANG Yanhe
(Department of Mathematics and Computer Science, Changsha University, Changsha 410003)
In this paper, digital image processing technology is used to detect and classify the foreign matter of lyophilized powder. In order to more efficiently detect and classify the existing foreign matter in lyophilized powder such as fibers, hair, particles of glass and other visible foreign matter, BP neural network and support vector machine (SVM) algorithms together with principal component analysis (PCA) feature extraction are used to do classification and recognition. Through industrial small sample data simulation, test results show that both methods have good feasibility and practicability. By comparison it is showed that the recognition based on PCA and SVM algorithm is higher than the recognition based on PCA and BP algorithm.
inspection of obviously foreign matter, principal component analysis(PCA), BP neural network, support vector machine(SVM)
2016年7月8日,
2016年8月28日
丁金如,女,研究方向:模式識(shí)別。孟志剛,男,博士,博士后,講師,研究方向:圖像處理機(jī)器學(xué)習(xí)。楊燕鶴,男,研究方向:機(jī)器學(xué)習(xí)。
TP391
10.3969/j.issn.1672-9722.2017.01.007
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
