一種高效的模式串匹配算法
2017-01-11 10:35:46何立風(fēng)巢宇燕王亞妮
陜西科技大學(xué)學(xué)報 2017年1期
趙 曉, 何立風(fēng), 王 鑫, 姚 斌, 巢宇燕, 王亞妮
(1.陜西科技大學(xué) 電氣與信息工程學(xué)院, 陜西 西安 710021; 2.日本名古屋產(chǎn)業(yè)大學(xué) 環(huán)境商務(wù)信息學(xué)院, 愛知縣 尾張旭市 488-8711)
一種高效的模式串匹配算法
趙 曉1, 何立風(fēng)1, 王 鑫1, 姚 斌1, 巢宇燕2, 王亞妮1
(1.陜西科技大學(xué) 電氣與信息工程學(xué)院, 陜西 西安 710021; 2.日本名古屋產(chǎn)業(yè)大學(xué) 環(huán)境商務(wù)信息學(xué)院, 愛知縣 尾張旭市 488-8711)
基于BM算法和Horspool算法,提出了一種簡單且高效的模式串匹配算法.將匹配成功部分的每個字符作用于壞字符移動策略以獲得多個移動參考量,從這多個參考量中選擇最大值作為模式串的當(dāng)前移動量.模式串在每個不匹配位置的移動量可以僅根據(jù)模式串預(yù)先計算獲得.實驗結(jié)果表明,該算法在任意不匹配位置所給出的移動量均是當(dāng)前模式串的最大移動量,提高了模式串匹配的效率.
模式匹配; 字符串匹配; BM算法; Horspool算法
0 引言
模式串匹配操作是計算機(jī)科學(xué)領(lǐng)域中的一種基本運算,常用于解決在一個大文本中查找給定模式串是否存在的問題.模式串匹配操作被廣泛應(yīng)用于信息檢索、病毒檢測、計算生物學(xué)、拼寫檢查等研究領(lǐng)域.提高模式串匹配處理效率是信息科學(xué)和計算機(jī)科學(xué)領(lǐng)域的重要研究之一[1].
從1977年至今,在模式串匹配問題上取得了許多的研究成果,其中最著名的算法是Boyer-Moore(BM)算法[2].自從BM算法提出后,研究者對其進(jìn)行了許多改進(jìn)[3-8],Horspool算法為最有效的簡化算法之一[3],且在入侵檢測中有較好的應(yīng)用[9].
本文結(jié)合BM算法和Horspool算法處理中的壞字符策略,提出一種高效、簡單的模式串匹配算法.當(dāng)不匹配發(fā)生時,新提出算法確保了模式串向前的移動量總是最大值.實驗結(jié)果表明,該算法要比Horspool算法更加有效.
1 BM算法和Horspool算法的基本原理
為了描述方便,在本文的圖中用text表示文本串;用pattern表示待匹配的模式串;當(dāng)前用于匹配的文本子串用t[i]…t[i+m-1](0 ≤i≤n-m),其中i表示當(dāng)前文本子串的起始位置,n表示文本串的長度,m表示待匹配子串的長度;模式串pattern中的字符用p[0]…p[m-1]表示,其中m用于表示模式串的長度.
1.1 BM算法基本原理
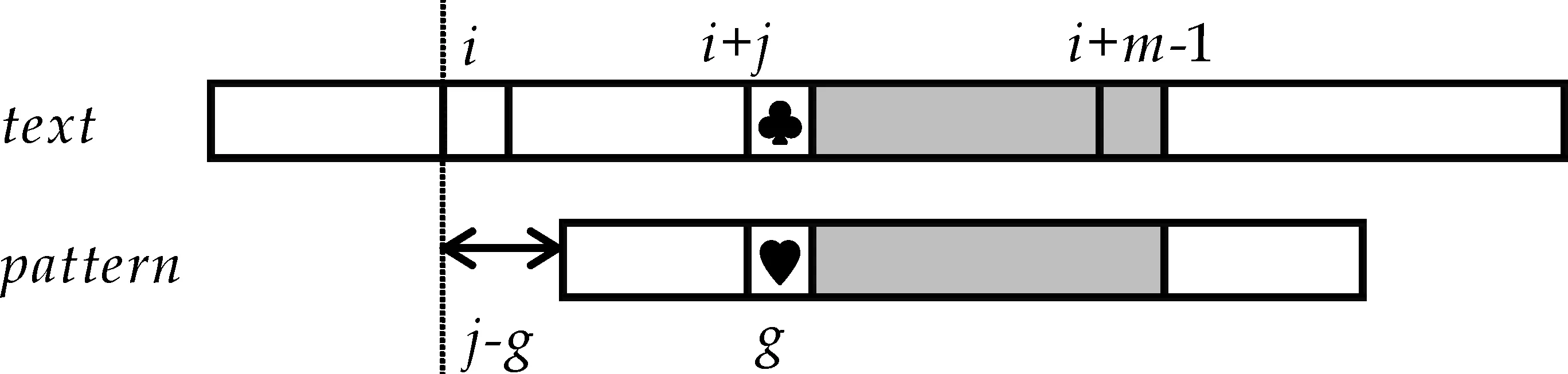
1977年,Boyer和Moore提出了著名的BM模式串匹配算法[2],該算法從右向左對模式串p[0]…p[m-1]和當(dāng)前文本子串t[i]…t[i+m-1]進(jìn)行匹配檢查.當(dāng)p[j]和t[i+j]不匹配發(fā)生時(圖1(a)所示),BM算法通過兩種策略(壞字符移動策略和好后綴移動策略)計算模式串的移動量,并選擇其中的最大值作為模式串向前的移動量.
壞字符移動策略利用字符t[i+j]來計算模式串的移動量,表示為skip1[t[i+j]].當(dāng)字符t[i+j]不是模式串中的字符時,由于t[i+j]與模式串中的任何字符都無法匹配,故可以將模式串向前移動至字符t[i+j]之后,使模式串的第一個字符和字符t[i+j+1]對齊.相應(yīng)的模式串移動量為skip1[t[i+j]]=j+1,如圖1(b)所示.另一方面,如果字符t[i+j]與模式串中的字符p[k]相同,通過移動模式串使t[i+j]與p[k]對齊時,所對應(yīng)的文本子串和模式串就有完全匹配的可能,需要進(jìn)一步檢驗.這時的模式串移動量為skip1[t[i+j]]=j-k,如圖1(c)所示.很明顯,根據(jù)給定的模式串,對于文本中的任何字符α,可以預(yù)先計算出skip1[α].
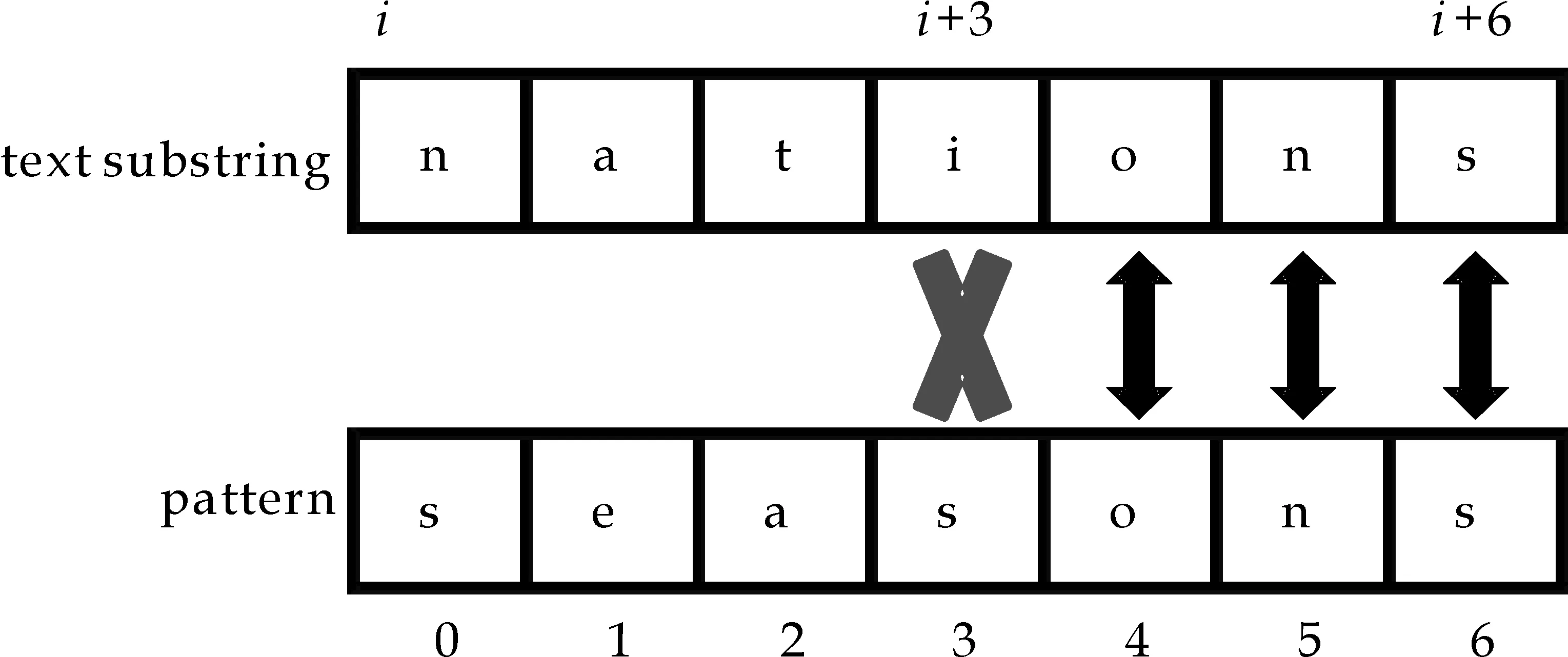
好后綴移動策略根據(jù)不匹配發(fā)生前匹配成功的部分(圖1(a)中灰色的部分,也就是t[i+j+1]…t[i+m-1]=p[j+1]…p[m-1])來計算模式串的另一個移動量skip2[j].計算的依據(jù)是查看子串p[j+1]…p[m-1]與模式串p[0]…p[m-1]中的子串是否存在有完全匹配或者部分匹配的子串,例如存在p[j+1]…p[m-1]=p[g+1]…p[m-1+g-j]并且p[j]≠p[g](0≤g (a)字符p[j]和t[i+j]不匹配 (c)模式串移動量為j-k (d)模式串移動量為j-g (e)模式串移動量為m圖1 BM算法工作原理圖 當(dāng)p[j]和t[i+j]不匹配時,即p[j]≠t[i+j],BM算法選擇skip1[t[i+j]]和skip2[j]中的最大值作為模式串向前的移動量. 1.2 Horspool算法基本原理 Horspool算法是一種簡化的BM算法,當(dāng)不匹配發(fā)生時,Horspool僅利用BM算法中的壞字符移動策略計算模式串向前的移動量[3]. 如圖2所示,當(dāng)p[j]和t[i+j]發(fā)生不匹配時(如圖2(a)所示),Horspool算法使用當(dāng)前文本子串的最右邊的字符t[i+m-1]作為壞字符,利用壞字符策略計算模式串的移動量.如果t[i+m-1]不出現(xiàn)在p[0]…p[m-2]中,可以將模式串向前移動至字符t[i+m-1]之后,移動量為skip[t[i+m-1]]=m,如圖2(b)所示;反之,如果t[i+m-1]=p[k](0 ≤k (a)出現(xiàn)不匹配字符 (b)模式串移動量為m (c)模式串移動量為m-1-k圖2 Horspool算法工作原理圖 提高模式串匹配算法效率的有效方法之一是在不匹配發(fā)生后盡可能地加大模式串向前的移動量.如上所述,當(dāng)發(fā)現(xiàn)p[j]和t[i+j]不匹配時,Horspool算法將t[i+m-1]用于壞字符移動策略來計算模式串的移動量,該移動量表示為skip[t[i+m-1]].但實際上,按照Horspool算法的思路,t[i+j+1]和t[i+m-2]之間的任何一個文本字符也都可以用于壞字符移動策略,在t[i+m-1]上獲得的移動量并不一定是最大的. 例如,在圖3所示的文本實例中,假設(shè)當(dāng)前的文本子串是nations,模式串是seasons,其中模式串長度m=7.在下標(biāo)3位置出現(xiàn)不匹配時,字符t[i+m-1]是s,即t[i+6]=s,用Horspool算法計算得到的移動距離是3,然而,如果用字符t[i+5],即字符n計算得到的移動距離是6,顯然這個移動量比用Horspool算法計算得到的移動量大. 圖3 用于解析本文算法基本原理的文本實例 為了獲得盡可能大的移動量,在p[j]和t[i+j]不匹配時,將t[i+j+1]…t[i+m-1](也就是p[j+1]…p[m-1])之間的每一個字符t[i+k](也就是p[k])作為壞字符,用于壞字符移動策略計算出移動參考值Δ(k),然后從移動參考值Δ(j+1),…,Δ(m-1) 中選取最大值作為模式串的移動量,顯而易見,skip[j]=max{Δ(j+1),…,Δ(m-1)},大于至少等于Horspool算法計算出的移動量skip[t[i+m-1]]. 還是圖3的實例,在圖4中給出了兩種不同算法的預(yù)處理結(jié)果.圖4(a)是Horspool算法的預(yù)處理結(jié)果,圖4(b)是本文算法的預(yù)處理結(jié)果.從圖4(a)可以看出,因為t[i+6]=s,不管在任何位置出現(xiàn)不匹配時,Horspool算法給出的模式串的移動量始終都等于TD(s),即就是3.而本文算法的移動量是和不匹配出現(xiàn)的位置有關(guān),當(dāng)在下標(biāo)位置0到4任一位置出現(xiàn)不匹配時,模式串的移動量是6,當(dāng)在下標(biāo)位置5和6任一位置出現(xiàn)不匹配時,模式串的移動量是3.可見,本文算法的模式串移動量始終大于等于Horspool算法的模式串移動量. 根據(jù)模式串和BM算法的壞字符策略很容易實現(xiàn)本文算法的預(yù)處理部分.從右向左計算模式串的移動量,用skip[j](0 ≤j≤m-1)表示,其中skip[j](0 ≤j≤m-2)是用本文算法預(yù)處理計算得到,skip[m-1]等于Horspool算法的移動量skip[t[i+m-1]].在本文算法中分兩步驟完成預(yù)處理,計算skip[j](0≤j≤m-2)值的計算分兩步完成.首先,計算移動參考值Δ(j)(0≤j≤m-2),其中已知Δ(m-2)=TD(p(m-1))TD(p(m-1)表示用壞字符p(m-1)計算得到的移動量.用于計算參考值Δ(j)的模式子串是p[0]…p[j],壞字符是p[j+1],根據(jù)壞字符策略計算得到參考值Δ(j).假設(shè)k是滿足p[j+1]=p[k]的最大值,其中0≤k≤j,那么Δ(j)=j+1-k.其次,基于參考值Δ(j)(0≤j≤m-2)計算移動量skip(j)(0≤j≤m-2).開始skip[m-2]被賦值為Δ(m-2),接下來計算其它skip[j]的值,每一個skip[j]的值都是選自Δ(j)和skip[j+1]中的最大值.例如,如果Δ(m-3)>skip[m-2],那么skip[m-3]=Δ(m-3),否則skip[m-3]=skip[m-2].顯然,skip[j]是從Δ(j) 到Δ(m-2)中所有移動量的最大值. (b)本文算法的預(yù)處理結(jié)果圖4 兩種不同算法的預(yù)處理結(jié)果 (a)Horspool 算法的預(yù)處理結(jié)果 本文算法計算所有的 skip [ j ]( j =0,…, m -2)的預(yù)處理如下所示: /*第一步,計算Δ(j)*/ Δ(m-2)=TD[p[m-1]]; for(j=m-3;j >= 0;j--) for(i=j;i>=0;i-- ) if(p[i]==p[j+1]) Δ(j)=j+1-i; /*第二步,計算移動量skip[j]*/ skip[m-2]=Δ(m-2); for(j=m-3;j>=0;j--) if(Δ(j)>skip[j+1]) skip[j]=Δ(j); else skip[j]=skip[j+1]; 顯然,根據(jù)模式串很容易計算每一個位置的移動量,實現(xiàn)預(yù)處理過程. 為了有效的比較本文算法和Horspool算法的效率,作者選用兩種不同的文本對兩種算法進(jìn)行測試,這兩種文本分別是:二進(jìn)制文本和DNA(Deoxyribonucleic acid)序列,所有測試使用的源數(shù)據(jù)均下載自網(wǎng)站SMART ,其中二進(jìn)制文本大小為5.0 MB,DNA序列大小為4.5 MB.實驗所用的各種類型及不同長度的模式串均隨機(jī)產(chǎn)生于以上的源數(shù)據(jù).實驗運行時間單位為毫秒. (1)實驗1:測試文本為5.0 MB二進(jìn)制文本,模式串的長度從3到10,20,30,40,50,60,70,80,90,100等共選取了18種,其中長度從3到7的模式串測試了0和1的所有組合情況,其他長度的模式串均隨機(jī)從測試文本中選取了100個模式串用于實驗,實驗結(jié)果如圖5所示.其中,圖5(a)為模式串長度從3到10的測試結(jié)果,圖5(b)為模式串長度為10,20直到100的測試結(jié)果.從圖5(a)和圖5(b)的匹配結(jié)果發(fā)現(xiàn),幾乎在所有匹配長度上,均提高了10 ms的匹配時間. (a)模式串長度為3-10 (b)模式串長度為10-100圖5 兩種算法在二進(jìn)制文本上 平均運行時間比較 (2)實驗2:測試文本為4.5 MB的DNA 序列,模式串長度的選取同實驗2,其中模式串長度為3的模式串有64個,其它長度的100個模式串均從DNA序列中隨機(jī)選取的,實驗結(jié)果如圖6所示.圖6(a)是模式串長度從3到10的實驗結(jié)果,圖6(b)是其他模式串長度的實驗結(jié)果.從圖6(a)和6(b)來看,本文算法均比Horspool算法的效率高,但是模式串長度不同,效率提高的程度不同,圖6(a)的結(jié)果顯然沒有圖6(b)的提高效率程度高,所實現(xiàn)的效率與模式串長度成正比. (a)模式串長度為3-10 (b)模式串長度為10-100圖6 兩種算法在DNA序列上 的平均匹配時間 本文算法對基本模式串匹配算法BM的壞字符策略進(jìn)行改進(jìn),實現(xiàn)了任一位置不匹配時,均有大于或等于同為壞字符策略實現(xiàn)匹配的Horspool算法的移動量.算法的基本思想簡單、容易實現(xiàn),在不同性質(zhì)的實驗數(shù)據(jù)上測試結(jié)果有效. 本文提出了一種有效的模式串匹配算法.當(dāng)不匹配出現(xiàn)時,按照BM算法的壞字符策略計算當(dāng)前已經(jīng)匹配的每個字符的移動量為參考量,并從多個參考量中選擇一個最大值作為模式串當(dāng)前的移動量,任意位置的移動量均可以通過預(yù)處理計算得到.實驗結(jié)果表明:在不匹配出現(xiàn)時,本文算法獲得的模式串移動量總是最大的,從而有效地提高了模 式串的匹配效率.模式匹配算法已被廣泛地應(yīng)用于入侵檢測和情報檢索等系統(tǒng)中,并隨著信息技術(shù)的不斷發(fā)展,對于檢索效率提出了更高的要求,高效率的匹配算法的提出具有極大的現(xiàn)實意義.本文作者的下一步工作將本文算法思想和其它模式串匹配技術(shù)相結(jié)合應(yīng)用于病毒檢測及DNA檢測中. [1] 范洪博,姚念民.一種高速精確單模式串匹配算法[J].計算機(jī)研究與發(fā)展,2009,46(8):1 341-1 348. [2] R.Boyer,J.Moore.A fast string searching algorithm[J].Communications of the ACM,1977,20(10):762-772. [3] R.N.Horspool.Practical fast searching in strings[J].Software-Practice & Experience,1980,10(6):501-506. [4] M.Sunday.A very fast substring search algorithm[J].Communications of the ACM,1990,33(8):132-142. [5] Zhao X,Li S,Yang Y,et al.A new substring searching algorithm[J].Ieice Transactions on Information & Systems,2014,E97-D(7):1 893-1 896. [6] 胡金柱,熊春秀,舒江波,等.一種改進(jìn)的字符串模式匹配算法[J].模式識別與人工智能,2010,23(1):103-106. [7] 李明月,張善卿,陸劍鋒,等. 一種改進(jìn)的Sunday匹配算法[J].杭州電子科技大學(xué)學(xué)報,2015,35(1):93-96. [8] 韓光輝,曾 誠.Boyer-Moore串匹配算法的改進(jìn)[j].計算機(jī)應(yīng)用,2014,34(3):865-868. [9] Sun Kelei.Fast algorithm for pattern matching in intrusion detection system[J].Journal of Anhui University of Science and Technology (Natural Science),2006,26(3):52-55. [10] G.Navarro,M.Raffinot.Flexible pattern matching in strings[M].Cambridge:Cambridge University Press,2002:19-22. 【責(zé)任編輯:蔣亞儒】 An efficient pattern matching algorithm for string searching ZHAO Xiao1, HE Li-feng1, WANG xin1, YAO Bin1,CHAO Yu-yan2, WANG Ya-ni1 (1.College of Electrical and Information Engineering, Shaanxi University of Science & Technology, Xi′an 710021, China; 2.Faculty of Environment, Information and Business, Nagoya Sangyo University, Aichi 488-8711, Japan) According to the analysis of the famous BM algorithm and the Horspool algorithm,we propose a simple and efficient pattern matching algorithm for string searching.When a mismatch happens,for shifting the pattern to the right,the shift amount in the Horspool algorithm is computed by using the rightmost character of the current text substring to the bad-character strategy.In comparison,the shift amount of our algorithm is the maximum one among all the shift amounts computed by using each of the already-matched characters.The maximum shift amount for each mismatch position of the pattern can be pre-computed by using the pattern only.Experimental results demonstrated that our algorithm can obtain a larger shift amount for a mismatch,and thus enhanced the efficiency of pattern matching for string searching. pattern matching; string searching; BM algorithm; Horspool algorithm 2016-09-19 國家自然科學(xué)基金項目(61601271,61471227,61603234); 陜西省科技廳科技計劃項目(2016SF-444); 陜西省教育廳自然科學(xué)專項科研計劃項目(16JK1087) 趙 曉(1978-),女,陜西西安人,講師,在讀博士研究生,研究方向:模式識別 1000-5811(2017)01-0183-05 TP393.0 A





2 本文算法的基本原理


3 實驗結(jié)果




4 結(jié)論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10電子制作(2018年18期)2018-11-14 01:48:06數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
