含特定比例均勻隨機刪失生存數據的SAS模擬實現*
2017-01-10 03:46:42肖媛媛許傳志趙耐青
中國衛生統計 2016年6期
肖媛媛許傳志趙耐青
含特定比例均勻隨機刪失生存數據的SAS模擬實現*
肖媛媛1許傳志1趙耐青2△
刪失(censoring)是生存分析時經常會遇到的一個實際問題,為生存數據的處理分析帶來了一定困難。針對這一問題,在實際研究中往往需要通過隨機模擬來產生含一定刪失比例的特定生存分布數據,供探索性研究或對比性研究使用。文獻檢索后發現,目前國內外針對刪失生存數據的模擬研究數量較少[1-3]。
按照其發生是否與研究對象的其他特征有關,刪失分為隨機刪失(random censoring)和非隨機刪失(non-random censoring)兩類,即非信息刪失(non-informative censoring)和信息刪失(informative censoring)[4]。由于非隨機刪失的影響因素眾多,故其特征難以全面捕捉,因此目前在模擬產生含刪失的生存分析數據時,大都假定為完全隨機刪失。
本文針對現有模擬思路和方法中存在的某些問題或疑議,提出一種模擬產生含特定比例均勻隨機刪失生存數據的思路,以及實現這一思路的SAS宏程序,為科學工作者開展生存分析提供便利。
現有方法回顧
模擬產生含隨機刪失的生存數據時,步驟一般為:先產生符合特定分布的完整數據,再在此基礎上產生刪失數據。
生成完整數據時,一般采用的是Bender等2005年提出的模擬方法[5]。該方法的基本思想是,從某一時刻風險函數的一般表達式入手:

得到當前時刻仍存活的概率為:
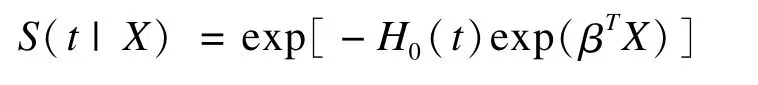

假設Y是函數F的自變量,如果生存曲線足夠平滑,可以得知服從在[0,1]區間上的均勻分布,同樣可得知,1-F(Y)也服從在[0,1]上的均勻分布,即U=exp[-H0(t)exp(β′X)]服從[0,1]上的均勻分布U[0,1]。
假設生存時間為T,對前式取反函數,得到:
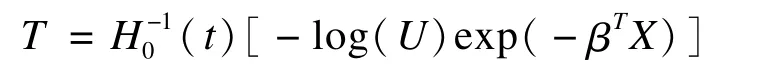
基于上述思想,根據目標生存分布所對應的累積風險函數表達式H0和隨機模擬產生的均勻分布U,即可產生目標生存時間。Weibull分布的累積風險函數表達式為:
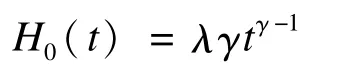
因此可得到其生存時間T的計算公式為:
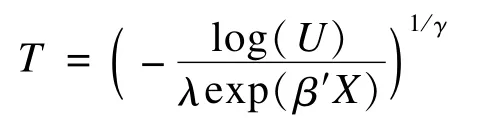
在進一步產生含隨機刪失的生存數據時,一般的思路為:假設生存時間T和刪失時間C服從相互獨立的兩個分布S(T)和B(C)。在模擬研究中,S(T)的參數已經設定,可以順利產生生存時間Ti。再根據定義的刪失分布類型(即刪失發生時間的概率分布),如指數分布或均勻分布,結合設定的刪失比例,采用迭代或近似公式計算的方法得到刪失時間分布的參數,在此基礎上隨機產生刪失時間Ci。最后通過比較生存時間Ti和刪失時間Ci的大小,形成結構為(Ai,Ii)的數據形式。其中,A=min(T,C),I為指示變量,T<C時等于1,指代事件發生,T>C時等于0,指代截尾發生。
不難看出,通過上述模擬方法,確實可以順利得到隨機刪失的生存數據,即刪失的發生與否與生存時間長短無關。但其在邏輯架構上卻存在不恰當之處。其一,我們通過S(T)已經得到了“真實”的生存時間T,而按照定義,刪失的發生時間一定是小于真實生存時間的,即C一定小于T。而按照上述方法,將T和C完全當作兩個相互獨立的分布來模擬,則可能出現C>T的情況。雖然在上述方法中,正好將這種情況定義為事件發生,但顯然已經混淆了真實情況下事件發生的概念。其二,刪失分布一定是在真實生存時間T確定的基礎上,刪失時間C的概率分布,如某觀察對象真實生存時間為Ti,又已知其發生了刪失,假設其刪失分布為均勻分布,則表示Ci在[0,Ti]范圍內取任意值的概率相等。因此,上述方法直接在同一時間維度上同時定義真實生存分布和刪失分布,同樣有悖常理。除此之外,在估計刪失分布的參數時,有學者提及的“迭代法”缺乏明確、詳細的出處和表述,按照Halabi等提出的公式計算得到的刪失分布參數,經實際驗證卻不能得到預先設定的刪失比例[6]。
模擬思路
由于現有模擬方法中存在著如上所述的問題或疑議,我們按照如下思路模擬產生含特定比例均勻隨機刪失的生存數據:
步驟一:按照如前所述的步驟生成樣本含量為N的特定分布的完整生存數據;
步驟二:根據預先設定的刪失比例P,在其中隨機抽取N×P個觀測,作為“刪失觀測”;
步驟三:每個刪失觀測的真實生存時間為Ti,由于為均勻刪失,因此在[0,Ti]的均勻分布上隨機產生其刪失時間Ci;
步驟四:將刪失觀測的刪失時間Ci與其他未刪失觀測的真實生存時間Tj整合為同一變量,定義為觀察時間,另外增加指示變量I,I=1表示發生結局,I=0表示刪失。
SAS模擬宏程序
模擬宏程序以理論生存時間滿足Weibull分布為例,讀者可自行拓展至指數分布和Gompertz分布,也可重新定義研究變量的數量、類型及參數,程序中只分析了單一的二項分布自變量factor1~B(1,0.5)。
具體程序如下:


討 論
在當前研究中,我們針對現有刪失生存數據模擬方法中存在的問題和疑議,提出了一種含特定比例均勻隨機刪失生存數據的模擬方法,并給出了實現這一方法的SAS宏程序。經反復驗證,這一宏程序能正確產生設定特征的刪失生存數據。
模擬產生具有不同刪失特征的生存數據,對于探索生存分析方法并驗證其價值來說,有著十分重要的意義。在當前研究中,我們僅設定了非常理想化的假設前提:即刪失的發生完全隨機,且刪失分布滿足最簡單的均勻分布。需要指出的是,在現實情況下,生存數據中刪失的發生及其分布特征可能千變萬化。雖然無法對每一種可能都進行模擬,但以下兩個方向卻值得進一步研究:
方向一:同樣在完全隨機刪失的假設前提下,研究不同刪失分布類型生存數據的模擬實現,如指數分布、對數分布等。
方向二:在方向一研究的基礎上,進一步打破“完全隨機刪失”這一強假定,探索當刪失的發生和理論生存時間之間存在關聯,且滿足不同的關聯模式時,含不同刪失比例、不同刪失分布生存數據的模擬實現。
[1]高峻,董偉,高爾生,等.多結局生存分析模型與Cox模型的隨機模擬比較.中國衛生統計,2007,20(3):248-251.
[2]錢俊,張超,陳平雁.模擬研究中隨機數據的產生及SAS實現.中國衛生統計,2008,21(6):704-706.
[3]錢俊,劉國慶,周業明.不同刪失比例下生存數據模擬生成的方法.數理醫藥學雜志,2013,26(6):644-646.
[4]Leung KM,Elashoff RM,Afifi AA.Censoring issues in survival analysis.Annual Review of Public Health,1997,18:83-104.
[5]Bender R,Augustin T,Blettner M.Generating survival times to simulate Cox proportional hazardsmodels.Statistics in Medicine,2005,24(11):1713-1723.
[6]Halabi S,Singh B.Sample size determ ination for comparing several survival curves w ith unequal allocations.Statistics in Medicine,2004,23(11):1793-1815.
(責任編輯:劉 壯)
國家自然科學基金(81460519);云南省自然科學基金(2013FZ064)
1.昆明醫科大學公共衛生學院流行病與衛生統計學系(650500)
2.復旦大學公共衛生學院生物統計學教研室
△通信作者:趙耐青,E-mail:nqzhao1954@163.com
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
兒童故事畫報(2019年5期)2019-05-26 14:26:14
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
