語料庫在語言測試中的應用:回顧與反思*
2016-12-22 06:32:40鄒紹艷
中國海洋大學學報(社會科學版) 2016年6期
鄒紹艷
(1.上海交通大學 外國語學院,上海 200240;2.青島農業大學 外國語學院,山東 青島 266109)
?
語料庫在語言測試中的應用:回顧與反思*
鄒紹艷1,2
(1.上海交通大學 外國語學院,上海 200240;2.青島農業大學 外國語學院,山東 青島 266109)
近年來,語料庫在語言測試領域的應用得到廣泛認可,其應用潛力和前景也備受關注。本文首先回顧并梳理了語料庫在國際語言測試領域四個方面的應用:考試開發、考試效度驗證、自動評分系統、語言能力量表構建,然后對語料庫在國內語言測試領域的應用情況進行了反思,并以中國英語學習者寫作能力量表的構建為例,闡述了語料庫在構建寫作能力量表中的應用。
語料庫;語言測試;中國英語學習者寫作能力量表
一、引言
自20世紀60年代第一個計算機化的語料庫——Brown語料庫在美國問世以來,語料庫作為一種新興的研究方法逐漸滲透到語言學研究的相關領域。20世紀90年代中期,隨著大型本族語者語料庫的建立(例如,英國國家語料庫British National Corpus,以下簡稱BNC和美國國家語料庫American National Corpus,以下簡稱ANC),語料庫在語言測試領域的應用前景開始引起語言測試界的關注。 Alderson在1996年就預測了語料庫在語言測試中的一系列用途:設計考試題目、確立考試構念、分數評定與報道等等。[1]自此之后,語料庫開始被頻繁地用于大規模標準化考試、整體性測評以及發展性測評中。2003年,在英國雷丁大學召開的第26屆國際語言測試研究大會專門就語料庫和語言測試的關系成立了一個專題研討會,學者們分別聚焦本族語者語料庫和二語學習者語料庫在寫作測試、閱讀測試以及口語測試中的應用,闡明語料庫在語言測試領域的應用前景。[2]
當前,我國正在調動英語教學和測試各方面的資源制定中國英語能力等級量表(China Standards of English,簡稱CSE)。在這種背景下,我們重新回顧和反思語料庫在語言測試領域的應用,不僅有助于豐富學界對這一領域研究現狀的認識,也希望發現值得借鑒的經驗亦或可能存在的不足,進而探索語料庫在構建中國英語能力等級量表中的應用前景。
二、語料庫在語言測試領域的應用回顧
縱觀語料庫在語言測試領域的應用,基本涉及以下幾個方面:第一、語料庫用于開發、設計試題;第二、語料庫用于考試效度驗證;第三、語料庫用于開發自動評分系統;第四、語料庫用于構建語言能力量表。以下將結合語言測試領域的相關理論和研究,分別回顧與梳理語料庫在這四個方面的應用情況。
(一)考試開發
20世紀80年代中期以來,隨著交際語言能力理論在應用語言學領域逐漸被接受并得到廣泛應用,語言測試的模式也從傳統的分離式語言測試(discrete- point language test)轉向交際語言測試(communicative language test)。交際語言測試是一種行為測試,是在真實或接近真實的情景中通過完成實際的交際任務來測量考生運用語言知識的能力。[3]可見,真實性、情景化是交際語言測試的關鍵。Bachman認為,真實性就是語言測試任務特征和目標語言使用特征之間的吻合程度,是根據語言測試的成績做出推斷的前提。[4]
語料庫研究方法的興起為提高語言測試的真實性提供了有效的解決途徑。20世紀90年代中期,除了本族語者語料庫之外,大型學習者語料庫(如CLC)以及一些學術英語語料庫(如Michigan Corpus of Academic Spoken English,簡稱MCASE;British Academic Written English corpus,簡稱BAWE語料庫,等)也相繼建立。這些語料庫的主要用途之一便是開發與目標語使用相一致的測試。[5]例如,CLC就是一個含有錯誤標注(error- tagged)、測試文本和學習者信息的語料庫,劍橋考試中心的測試設計者們利用該語料庫來設計和修訂考試。具體而言,測試開發者可以借助語料庫了解本族語者在語言使用中的詞匯、語法特點,包括詞匯和短語的相對頻率、句式、搭配和類聯接、語法結構、程式化表達、詞序等。Park指出,考試的構念(test construct)正是通過觀察這些特征而產生的。[5]
在語料庫用于考試開發的研究方面,Sharpling報告了BAWE語料庫在設計Warwick英語測試的語法和語言使用部分試題中的應用,他建議在計算機化考試和語料庫之間建立更加緊密的聯系,通過相互關聯的數據庫來輔助考試開發。[6]Weir和Milanovic指出,在設計側重考核詞匯、語法的測試任務時(如多項選擇式的完形填空、句子轉換等),可以利用語料庫設計真實的測試題目,以及潛在的干擾項。[7]Barker肯定了語料庫對于提高語言測試真實性的作用,他認為本族語者語料庫和學習者語料庫的建立,使得語言測試的設計者們能夠根據更加真實的語言和文本來設計測試任務,而且在設計任務時能夠更直接地定位到與目標受試者最為相關的語言使用。[8]劍橋大學出版社的官方網站上提供了語料庫使用的諸多案例,其中一例便是學習者語料庫有助于甄別處于某種水平的學習者易犯的典型錯誤,使得這一受試群體的測試題目或測試任務設計更有針對性。
Park總結了語料庫在開發、設計試題中的應用,即語言測試的設計者們可以根據本族語者語料庫或學習者語料庫中包含的豐富信息,如詞匯、語法、搭配、句式、程式化表達等等開發和設計語言測試,而且正是通過觀察語料庫中的這些信息,語言測試的構念才能得以確立。[5]總之,正如鄒申等人所言,在設計與編制試題方面,語料庫可以為我們提供真實的、可供參考的語料,為制定決策提供客觀的數據。[9]
(二)考試效度驗證
效度是語言測試最重要的屬性,[4]也是語言測試的基本出發點。效度研究貫穿于考試的整個過程:即從開發到驗證其有效性,具體包括:語言能力構念的界定、測試任務的設計(如何實現其真實性和交互性)、評分標準的制定(如何保證其科學性和可行性)、評分信度(如何實現評分員之間或自身的一致性)、考試分數的解釋和使用等等。[4]Alderson(1996)曾指出,語料庫的應用可以提高考試的內容效度,因為測試材料選自真實語言文本,具有自然語言特征。[1]繼Alderson之后,Hawkey和Barker也指出,語料庫用于語言測試的效度驗證,主要優勢在于語料庫的發現可以為效度檢驗提供證據。[10]
美國教育考試服務中心(簡稱ETS)就是采用基于語料庫的方法來驗證其旗下的TOEFL考試和GRE考試的效度。例如,為了檢驗TOEFL 2000聽力和閱讀測試中使用的文本是否代表真實的口語和學術語言使用,Biber等人建立了TOEFL 2000學術口語和書面語語料庫(T2K- SWAL),并從語法、詞匯量、詞塊、詞匯分布等方面對該語料庫的文本進行了語言分析,然后把分析的結果與課堂活動中所用語言的特征進行了對比,從而驗證TOEFL 2000聽力和口語測試的效度。[11]Biber還利用T2K- SWAL語料庫檢驗了詞塊的用法,發現立場標記詞塊(stance bundles)在課堂教學中的使用頻率遠遠高于在課本中的使用頻率,盡管這兩種語域在態度確定和目標實現這兩方面都包含了豐富的信息,但是它們卻采用不同的會話來實現各自的目標。[12]換言之,詞塊體現了一種語域的語言模式,因而對詞塊的分析有助于完整地描述學習者的語言和語言需要。根據這一發現,Biber建議在對TOEFL考試以及其它同類考試進行效度驗證時,可開展類似的語料庫分析。總之,Taylor和Barker強調,可以定期地運用學習者語料庫驗證測試設計者對于語言特征以及不同水平等級的語言頻率的直覺判斷。[13]
(三)自動評分系統
在語言測試領域,自動評分系統主要用于口語和寫作這兩種產出性語言能力的評分。最早利用語料庫開展寫作自動評分系統的國家是美國。上世紀60年代,美國杜克大學的Ellis Page教授等人應美國大學委員會的請求,開發了Page Essay Grade(PEG)。PEG首先對一篇文章的可測量特征如長度以及平均句長等進行多元回歸分析,然后基于人工評判的大量作文語料庫建立評分模型。[14]PEG的評分準確率高,但該系統使用的文本特征都是與語言的形式特征有關,對內容、組織、體裁等語義方面的信息卻束手無策。為了彌補這些不足,上世紀90年代,美國的ETS和Vantage learning又分別研制了E- rater和Intellimetric。這兩種評分系統同PEG一樣,也是基于人工評判的作文語料庫建立評分模型,但是包含了更多關于語義信息方面的元素,因此操作起來更加復雜。到本世紀初,由以上評分系統衍生的自動評分軟件如My Access、Criterion等被先后開發出來。除了提供總分之外,這些評分系統還針對寫作的內容、組織結構、語體使用、詞匯和語法等方面提供單項分。不僅如此,這些評分系統還能提供詳略不等的個性化反饋。Park詳細介紹了現代化自動評分系統(以下簡稱 AES)的運作:該系統通過測量作文中蘊含的多種特征,并參考一個囊括結構、銜接詞、錯誤、詞匯和句法復雜度、篇章組織和展開的特征集進行評分。[5]在把特征集和相關理論應用到實際評分的過程中,大多數AES系統都會啟用一個培訓數據庫,即一個已經被人工評閱的作文語料庫,該語料庫被設為最佳基準,與人工評閱高度相關的特征被篩選出來收錄入特征集。
AES系統的設計初衷是節省成本、時間和人力,提高評分信度。但是,正如Park所言,AES系統究竟在多大程度上實現了這些目標,尤其是在評判內容和語言的說服力方面,仍然不得而知。[5]有的學者指出,AES系統的使用導致寫作從一種思辨型極強的創造性活動降格為只追求表面特征和形式特征的活動,這必然對學生的寫作產生負面影響。[15]顯然,目前的AES技術還不足以仿效人工評閱,但是很多研究已經表明在機器評分與人工評分之間的存在很高的相關關系,[16]說明這方面的技術在不斷進步。Warschauer和Ware認為,隨著性能的提高,AES系統必將在語言測試領域大放異彩,廣泛應用于評分員培訓、交互性語言測試、以及展示學生的歷時語言表現等多個方面。[17]
(四)語言能力量表構建
除上述三個方面的應用之外,語料庫在語言測試中發揮的又一個重要作用便是對傳統的評分大綱進行補充,對不同水平學習者的語言能力采用“能做”描述。Park曾指出,語料庫能夠幫助測試開發者發現哪些語言特征是哪種水平的學習者所特有的。[5]例如,Hawkey和Barker通過對學習者語料庫進行分析,篩選出不同水平學習者的寫作特征,然后根據這些特征構建了一個二語寫作能力量表。[10]Granger和Thewissen利用一個包含錯誤標注的學習者語料庫展示了學習者的錯誤如何與現有的評定標準(例如《歐洲語言共同參考框架》,簡稱《歐框》)進行關聯,以便達到評估的目的。他們指出,如果人工評分員參考《歐框》對國際英語學習者語料庫(ICLE)中的某一部分進行評分,就會標識出與《歐框》的每個等級相吻合的錯誤,這些錯誤可以進一步用于判斷一篇作文的錯誤類型以及錯誤頻率。[18]Thewissen則更具體地實現了這一想法,他在語法錯誤類型與《歐框》具體的等級之間建立了關聯。[19]
在利用語料庫補充語言能力量表方面,歐洲理事會自2005年起開展的EP項目(English Profile Program)備受矚目。該項目旨在利用CLC語料庫補充與完善《歐框》從A1級到C2級的描述語,彌補某些等級描述較為粗略、籠統的不足。Hawkins和 Buttery指出,EP項目引入的一個重要概念就是“判別性特征”(criterial features),即與《歐框》的六個等級相對應的語言特征。[20]具體而言,該項目旨在確立這些特征與學習者變量(如水平和母語背景)之間的相關關系,核心理念是我們可以期望低水平的學習者犯某種類型的錯誤或者表現出一些不太地道的語言使用特征(即消極特征),而高水平的學習者表現出這些負面特征的頻率相對較少。另外,與低水平的學習者相比,高水平學習者的語言使用具有更加復雜的語言特征(即積極特征)。例如,新手寫作者所產出的文本中很少會包含語法上比較復雜的結構,如主從句、述謂結構或者程式化表述以及搭配等等;而與之相反,高水平的學習者寫出的文本包含的消極特征較少,除了復雜的語法和程式化表述、[21]更加恰當的應答標記詞、[22][23]短語動詞以外,[24]還有更多其它的積極特征。一旦確定某種判別性特征與特定的水平或等級相關聯,就可以采用更加客觀的描述語來補充傳統評分大綱的不足。
目前,盡管這種利用判別性特征來補充評分量表的做法的準確性還有待于進一步驗證,但是與傳統的評分大綱相比,這種基于語料庫和語言學理論構建的評分量表無疑為測試設計者以及測試的使用者提供了更多關于受試者語言使用的真實案例。
三、語料庫在中國語言測試領域的應用反思
如前所述,語料庫在語言測試領域的用途廣泛。但是與國外研究取得的成果相比,目前中國學者對于語料庫在外語測試領域的應用仍然缺乏足夠的認識和重視。
首先,在考試設計方面,國內幾乎沒有關于語料庫在該領域應用的報道。一方面,可能由于大規模考試的高風險與機密性,相關的研究人員無法獲取考試設計的相關信息;另一方面,盡管國內學者建立了一些學習者語料庫,但這些語料庫并沒有隨著時間的推移得到及時的更新與補充,因此在考試開發方面的作用有待進一步探索。例如,楊惠中等人2003年建成的中國學習者英語語料庫(Chinese Learner English Corpus,簡稱CLEC)和文秋芳等人2005年建立的英語專業學生口筆語語料庫(Spoken and Written English Corpus of Chinese Learners,SWECCL)的規模都較大,但是都已建立10年有余。在這10年中,自然科學領域、社會科學領域新的成果不斷涌現,網絡信息技術飛速發展,新的詞匯、新的術語源源不斷地補充到英語語言中,而且學習者的認知能力和學習方式也發生了很大的變化,這一切都使得庫中語料的代表性受到挑戰。Park曾指出大規模考試的設計者可以利用語料庫甄辨某種水平的學習者易犯的錯誤,并對考試的難度進行相應的調整。[5]但如果語料的代表性不強,那么基于語料庫開發的考試內容的真實性也會因此受到威脅。
其次,國內學者利用語料庫開展考試效度研究的案例比較匱乏,即便開展此類研究,所用語料的代表性和相關性也不夠充分。例如,穆惠峰借助自建小型語料庫、SWECCL語料庫、以及BNC語料庫對大學英語四級考試完形填空題的內容效度進行了驗證。[25]但SWECCL語料庫中的口、筆語語料均來自中國高校的英語專業學生,因此其在該研究中的相關性和代表性值得探討。中國的外語考試種類繁多,而且規模較大,風險較高。在考試的效度驗證方面,語料庫的作用仍有待進一步挖掘和發揮。
再次,與國外研究相比,國內學者在利用語料庫開發自動評分系統方面起步較晚,而且大都偏重于介紹和探討。例如,王金銓和文秋芳回顧了國內外機器自動評分系統的現狀、內容和特點,并進一步探討了現有的機器自動評分技術對中國學生翻譯自動評分系統開發的啟示。[26]近年來,國內學者在作文自動評分系統的研發方面也取得了一定的成果。例如,梁茂成教授研制的大規模英語考試作文自動評分系統(EFL Essay Evaluator,簡稱EEE)1.0,基于大量人工評判的中國大學生作文語料庫建立評分模型,從語言、內容和組織結構三個方面對作文進行評價。還有基于網絡的作文批改系統(如句酷作文批改網),已經在全國許多高校的大學英語教學中使用。但是,這些自動作文批改系統在被廣泛應用的同時,也飽受詬病。例如,蔣艷和馬武林指出,目前的自動評分系統“只能從語言上判斷水平,不能從語義上判斷內容,無法對作文內容錯誤進行識別、部分語言錯誤無法識別”。[27](P76)可能正是因為存在上述弊端,目前這種基于語料庫開發的自動評分系統尚未在國內大規模外語考試中得以推廣和應用。在未來的研究中,如能繼續改進或完善語料庫在這一領域的應用,必將極大地緩解大規模考試中人工評分的壓力,節省閱卷的成本,提高評分的信度。
最后,在國內,盡管有學者開始倡導利用現有的語言能力量表對語料庫中的語料進行分級,[28]但如何利用語料庫構建語言能力量表仍未得到相應的關注。目前,我國自主開發的英語能力等級量表項目正在如火如荼地開展進行中。根據該項目負責人劉建達教授的介紹,CSE量表描述語的分級主要采用專家判斷、教師評定學生和學生自評的方式進行,[29]這在很大程度上與《歐框》的構建方法相吻合。盡管有了Rasch模型等先進統計手段的支撐,這種“自上而下”(top- down)構建量表的方法能夠比較科學地對不同來源的描述語進行難度排序,但也存在一定的問題。例如,Hustijin曾批判《歐框》制定過程中所采用的實證研究方法并非以二語學習者真實的數據為基礎,在很多情況下,教師不得不參照自己所教的某位學生的能力判斷描述語的難度,這在一定程度上影響了描述語判斷的客觀性。[30]鑒于此,我們建議在構建中國英語能力等級量表的過程中充分發揮語料庫的作用,尤其是在量表的后期效度驗證階段,可以利用語料庫對量表進行自下而上(bottom- up)的效度檢驗。以下就以中國英語學習者寫作能力量表(以下簡稱寫作能力量表)的開發為例,具體闡述語料庫在量表開發中的應用。
四、語料庫在構建中國英語學習者寫作能力量表中的應用
寫作能力量表的構建主要遵循CSE總的構建方案,基于前期收集、整理的大量寫作能力描述語,邀請專家、教師和學生對描述語的難度進行判斷,從而實現描述語的分級驗證。但是寫作能力作為一種產出型語言能力,其獨特的優勢在于大量可收集、可保存、可觀察的寫作文本。而且我國學者已經建立了一些大型的書面語語料庫(見表1),我們應該充分利用語料庫提供的信息,彌補專家和教師判斷過程中可能出現的主觀性過強的問題,從而對量表進行補充和完善。具體方案如下:
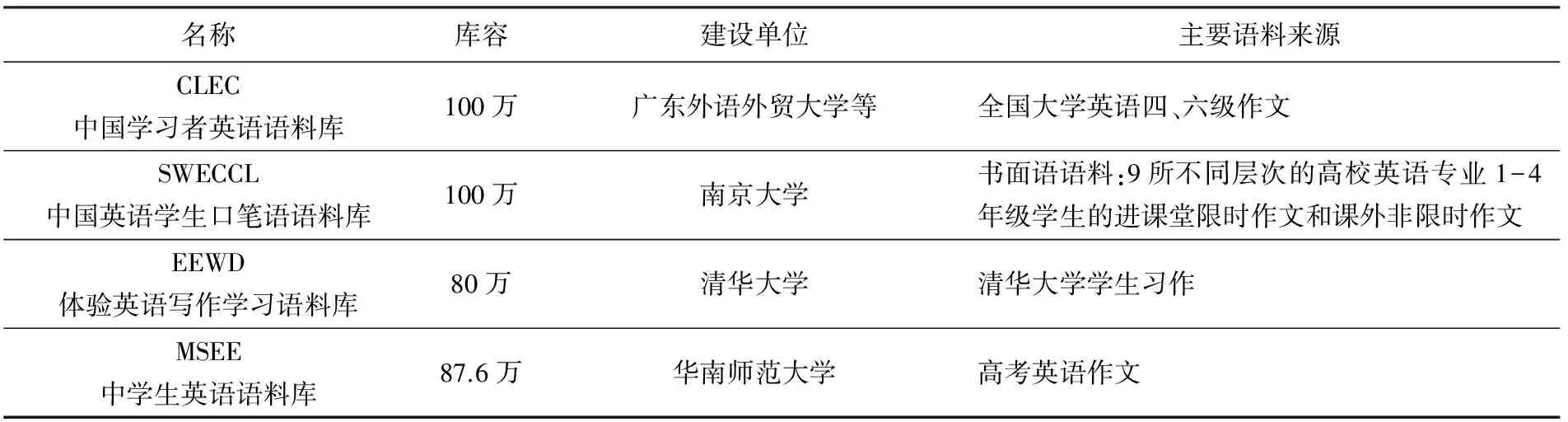
表1 我國學者建立的漢語為母語的英語學習者書面語語料庫
首先,從表1可以看出,目前我國學者建立的書面語語料庫主要源自大學階段的英語寫作文本。低端(如小學和初中)和高端(英語專業碩士、博士和高翻人才)學習者的語料庫比較稀缺,因此建議相關研究人員或機構廣泛收集這兩個群體的寫作語料,建立高、低端英語學習者的寫作語料庫,使得各個英語學習階段的寫作語料庫互相銜接,形成“一條龍”。對于已經建成的語料庫,可以利用近年來大規模考試的寫作文本或學生的日常習作對庫中的語料進行補充和完善,使得庫中的語料更具代表性。
其次,在對語料庫進行補充和完善之后,需要重新審核和修訂庫中語料的分級。王麗和張立英介紹了四種不同的語料庫分級方法:學習者背景、教師判斷、測試成績以及量表等級。[28]第一種方法需要考慮學習者學習目標語的時間以及受教育的程度;第二種方法一般是教師對學生水平或學生作文進行判斷,劃分不同的等級水平;第三種方法是根據學生在標準化考試中的成績進行分級;第四種方法是在語料庫和比較知名的語言能力量表(如《歐框》)之間建立對接,根據量表的等級劃分語料庫的等級。由于我國目前尚未建成符合我國英語學習者特點的語言能力量表,所以第四種方法暫時無法采用。在構建寫作量表的過程中,我們可以綜合運用前三種方法,對寫作語料進行初步分級。
再次,語料庫初步分級之后,可以利用相關的語料庫分析工具(如Wordsmith,Coh- metrix,Concordancer等),并借助先進的統計手段,對庫中不同水平的文本從詞匯、詞頻、搭配、銜接、句長等方面進行特征分析和對比。在這方面,我們可以參考歐洲理事會EP項目的研究成果。例如,2012年由Hawkins教授和Filipovic教授主編、劍橋大學出版社出版的CriterialFeaturesinL2English這本著作展現了英語學習者的語法特征。另外,劍橋大學出版社的官方網站上也在EnglishProfileJournal這本電子期刊上定期刊載該項目最新的研究動態和成果,這些研究采用的工具和方法值得我們學習和借鑒。
最后,根據語料庫分析提取的文本特征或做出的發現對前期通過“自上而下”的方法初步構建的寫作能力量表進行效度驗證,并在此基礎上補充、修改和完善量表,使得量表的等級劃分更加科學,語言能力描述更加細致、具體。當然,在寫作能力量表建成之后,也可以反過來用其驗證語料庫的分級。量表和語料庫相互驗證、互相補充,共同服務于我國的外語教學和測試。
五、結語
在大數據時代,語料庫提供的豐富信息無疑是其他研究方法無法比擬的。但是,語料庫的補充、完善和修訂如同CSE量表的構建一樣,需要語言教學部門、測試機構、專業技術人員以及教育管理部門的通力合作。在構建CSE的過程中,我們需要綜合運用不同來源的證據,例如理論上的證據、專家和教師以及學習者評判情況的證據、語料庫分析的證據。唯有如此,量表的效度才能得到充分驗證,開發出來的量表才能既有相關理論支持,又能反映我國英語學習者的特點和規律,從而更好地服務于中國的英語教學、學習和測試。
[1] Alderson,J. C. Do corpora have a role in language assessment?[A]//Usingcorporaforlanguageresearch. London:Longman,1996:248- 259.
[2] Taylor,L.,Thompson,P.,McCarthy,M. & Barker,F. Exploring the relationship between language corpora and language testing. In Symposium at 25th Language Testing Research Colloquium, Reading,UK,2003: 22- 25.
[3] Carroll,B. J. & Hall,P. J.MakeyourownlanguageTests:APracticalGuidetoWritingLanguagePerformanceTests[M]. Oxford:Pergamon Press,1985.
[4] Bachman,L. F.FundamentalConsiderationsinLanguageTesting[M]. Oxford: Oxford University Press, 1990.
[5] Park,K. Corpora and language assessment:the state of the art[J].LanguageAssessmentQuarterly,2014,(11):27- 44.
[6] Sharpling,G. P. When BAWE meets WELT:the use of a corpus of student writing to develop items for a proficiency test in grammar and English usage[J].JournalofWritingResearch,2010,(2):175- 189.
[7] Weir,C. & Milanovic,M.ContinuityandInnovation:RevisingtheCambridgeProficiencyinEnglishExamination1913- 2002(StudiesinLanguageTesting,Volume15)[M]. Cambridge:UCLES/Cambridge University Press,2003.
[8] Barker,F. Using Corpora in Language Testing:Research and validation of language tests[J].ModernEnglishTeacher,2004,(13):63- 67.
[9] 鄒申,楊任明.語料庫在試題設計和驗證中的應用研究[J].外語電化教學,2008,(5):10- 15.
[10] Hawkey,R. & Barker,F. Developing a common scale for the assessment of writing[J].AssessingWriting,2004,(9):122- 159.
[11] Biber,D.,Conrad,S.,Reppen,R.,Byrd,P.,Helt,M.,Clark,V.,Cortes, V.,Csomay,E. & Urzua,A.RepresentingLanguageUseintheUniversity:AnalysisoftheTOEFL2000SpokenandWrittenAcademicLanguageCorpus,report Number:RM- 04- 03. Educational Testing Service,Princeton,NJ,2004.
[12] Biber,D.UniversityLanguage:ACorpus-basedStudyofSpokenandWrittenRegisters[M]. Amsterdam:John Benjamins,2006.
[13] Taylor,L. & Barker,F. Using corpora for language assessment [A]//EncyclopediaofLanguageandEducation. New York:Springer Science+Business Media,LLC,2008:241- 254.
[14] 唐錦蘭,吳一安.在線英語寫作自動評價系統應用研究述評[J].外語教學與研究,2011,(2):273- 282.
[15] Ericsson,P. F. & Haswell,R. H.Machinescoringofstudentessays:Truthandconsequences[C]. Logan:Utah State University Press,2006.
[16] Attali, Y. & Burstein, J. Automated essay scoring with e- rater?v. 2[J].TheJournalofTechnology,LearningandAssessment, 2006,4(3): 3- 30.
[17] Warschauer, M. & Ware, P. Automated writing evaluation: Defining the classroom research agenda[J].LanguageTeachingResearch, 2006,(10): 157- 180.
[18] Granger,S. & Thewissen,J. The contribution of error- tagged learner corpora to the assessment of language proficiency[A]. Paper presented at the 27th language testing research colloquium. Ottawa,Canada,2005.
[19] Thewissen,J. The phraseological errors of French- ,German- and Spanish- speaking EFL learners:Evidence from an error- tagged learner corpus[A]//Proceedingsfromthe8thteachingandlanguagecorporaconference. Lisbon,Portugal:Associa??o de Estudos e de Investigo??o Científica do ISLA- Lisboa,2008: 300- 306.
[20] Hawkins,J. A. & Buttery,P. Criterial features in learner corpora:Theory and illustrations[J].EnglishProfileJournal,2010,(1):e5.
[21] McCarthy,M. Spoken fluency revisited[J].EnglishProfileJournal,2010,(1): e4.
[22] Farr,F. Engaged listenership in spoken academic discourse:The case of student- tutor meetings[J].JournalofEnglishforAcademicPurposes,2003,(2):67- 85.
[23] McCarthy,M. Good listenership made plain: British and American non- minimal response tokens in everyday conversation[A]//UsingCorporatoExploreLinguisticVariation. Amsterdam:John Benjamins,2002:49- 71.
[24] Negishi,M.,Tono,Y. & Fujita,Y. A validation study of the CEFR levels of phrasal verbs in the English vocabulary profile[J].EnglishProfileJournal,2012,(3):e3.
[25] 穆惠峰.基于語料庫的大學英語四級完型填空測試內容效度驗證研究 [J].外語電化教學,2011,(4):66- 70.
[26] 王金銓,文秋芳.國內外機器自動評分系統評述——兼論對中國學生翻譯自動評分系統的啟示[J].外語界,2010,(1):75- 81,91.
[27] 蔣艷,馬武林.中國英語寫作教學智能導師系統:成就與挑戰——以句酷批改網為例[J].電化教育研究, 2013,(7):76- 81.
[28] 王麗,張立英.學習者語料庫分級方法研究:反思與啟迪[J].中國海洋大學學報(社會科學版),2016,(2):107- 113.
[29] 劉建達.我國英語能力等級量表研制的基本思路.中國考試,2015,(1):7- 11.
[30] Hulstijn,J. H. The shaky ground beneath the CEFR: Quantitative and qualitative dimensions of language Proficiency1. The Modern Language Journal,2007,(4):663- 667.
責任編輯:周延云
The Application of Corpora in Language Assessment——Review and Reflection
Zou Shaoyan1,2
(1. College of Foreign Languages, Shanghai Jiao Tong University, Shanghai 200240;2. College of Foreign Languages, Qingdao Agricultural University, Qingdao 266109, China)
The application of corpora in language assessment has gained wide recognition in recent years and the potential and prospects of its application have been attracting increasing attention as well. Situated in such a context, this research firstly reviewed and combed the application of corpora in the four areas of language assessment: developing and designing test items, validating tests, scoring essays and constructing rating scales. Based on the review, the research reflected the use of corpora in language assessment in China and further elaborated its potential use in developing the writing scales of China Standards of English. writing scales.
Corpora; Language assessment; the Writing Scales of China Standards of English
2016-09-09
教育部哲學社會科學研究重大課題攻關項目--中國英語能力等級量表建設研究(15JZD049)
鄒紹艷(1979- ),女,山東青島人,上海交通大學外國語學院在讀博士,青島農業大學外國語學院講師,主要從事語言測試和外語教學研究。
H05
A
1672-335X(2016)06-0109-06
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學生導刊(低年級)(2016年2期)2016-02-24 23:02:11
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
小天使·五年級語數英綜合(2014年5期)2014-06-25 05:22:42
河南科技(2014年23期)2014-02-27 14:19:15
