基于距離關聯性動態模型的聚類改進算法*
2016-11-30 09:44:00陳雄韜閆秋艷
計算機與生活 2016年2期
陳雄韜,閆秋艷
中國礦業大學 計算機科學與技術學院,江蘇 徐州 221116
基于距離關聯性動態模型的聚類改進算法*
陳雄韜+,閆秋艷
中國礦業大學 計算機科學與技術學院,江蘇 徐州 221116
CHEN Xiongtao,YAN Qiuyan.Clustering improved algorithm based on distance-relatedness dynamic model. Journal of Frontiers of Computer Science and Technology,2016,10(2):248-256.
針對大部分聚類算法無法高效地發現任意形狀及不同密度的簇的問題,提出了一種高效的基于距離關聯性動態模型的聚類改進算法。首先,為提高聚類效率,使用層次聚類算法對數據集進行初始聚類,并剔除樣本點含量過低的簇;其次,為發現任意形狀及不同密度的簇,以初始聚類結果的簇的質心作為代表點,利用距離關聯性動態模型進行聚類,并利用層次聚類的樹狀結構進行有效的剪枝計算;最后,檢驗算法的有效性。實驗采用Chameleon數據集進行測試,結果表明,該算法能夠有效識別任意形狀及不同密度的簇,且與同類算法相比,時間效率有顯著的提高。
聚類;任意形狀的簇;不同密度的簇;距離關聯性;動態模型
1 引言
聚類是把無標簽的對象劃分到若干個簇中,使得同一個簇中的對象相似度最大化,同時不同簇中的對象相似度最小化[1]。聚類是一種重要的分析方法,被普遍地運用在數據挖掘、圖像處理、統計學、生物學和機器學習等多個領域[2]。聚類算法通常可以分為5種類型:基于劃分的方法、層次的方法、基于密度的方法、基于網格的方法和基于模型的方法。
基于劃分的聚類算法,如k-means、k-medoid,CLARANS(clustering large applications based on randomized search)等,大部分是基于中心的劃分方法,將樣本點劃分到與其最接近的簇中,這類方法只能檢測到球形或圓形的簇。基于網格的聚類算法,如STING(statistical information grid)、CliQue(clustering in quest)、WaveCluster和DenClue(density-based clustering),其中WaveCluster和DenClue都能發現任意形狀的簇,但它們使用的是靜態模型,無法發現不同密度的簇。基于層次的聚類算法,如Birch[3](balanced iterative reducing and clustering using hierarchies)、CURE(clustering using representatives)、Rock(robust clustering using links)、Chameleon[4],其中只有Chameleon算法能發現任意形狀和密度的簇[5],但是Chameleon算法的時間復雜度為O(n2)。基于密度的聚類算法,如DBSCAN[6](density-based spatial clustering of applications with noise)、VDBSCAN[7-8](varied density based spatial clustering of applications with noise)和DVBSCAN[9](density variation based spatial clustering of applications with noise)等,此類算法能夠發現任意形狀的簇且能夠處理數據集中的異常值,因此在數據挖掘領域中被廣泛使用[10-13]。其中DBSCAN是經典的基于密度的聚類算法,但因為它使用靜態密度模型,所以只能處理用戶指定密度的簇,且時間復雜度較高。VDBSCAN[7]算法能夠檢測不同密度的簇,能夠根據k-dist(k-distance)自動選擇一些輸入的距離閾值參數(Eps)應對不同的密度。在文獻[8]中VDBSCAN的參數k(k-dist)是基于數據集的特征自動生成的。然而VDBSCAN算法的時間復雜度與DBSCAN一樣大。文獻[9]提出了DVBSCAN算法,克服了DBSCAN不能處理局部密度變化的簇的問題,然而它的時間復雜度比DBSCAN還要高。
一個自然的簇應該可以是任意形狀或密度的簇,因此不應該被局限于一個球形的算法假設,或者局限于用戶指定的密度作為基于密度算法的需求。文獻[5]提出了一種距離關聯性動態模型,用以發現任意形狀及任意密度的簇,聚類算法名為Mitosis,它利用樣本點之間的距離關聯性作為測量來區分不同密度的簇。因為Mitosis算法的處理對象為每一個樣本點,所以時間復雜度有很大的改善空間。
Birch算法引入了聚類特征(clustering feature, CF)和聚類特征樹(clustering feature tree,CF Tree)這兩個概念,只需對數據集進行單次遍歷就可以進行聚類,因此其時間復雜度較低,但是與傳統基于劃分的聚類算法一樣,Birch算法只能發現球形的簇。
針對大部分聚類算法無法高效地發現任意形狀及不同密度的簇的問題,本文將Birch算法與Mitosis算法的聚類思想結合起來,提出了一種兩階段聚類算法。利用Birch算法聚類速度快的特點,將其聚類的結果,以簇的質心作為代表點參與Mitosis的運算,有效降低了Mitosis算法的計算量,使得該方法能夠發現任意形狀及不同密度的簇,且時間復雜度得到了顯著的改善。
2 基本概念
2.1Birch算法與Mitosis算法概述
Zhang等人[3]提出了Birch聚類算法,算法引入了兩個概念:聚類特征和聚類特征樹。聚類特征CF=(N,LS,SS),其中N表示簇中樣本點的數量,LS表示這N個樣本點的線性和,SS表示這N個樣本點的平方和,CF是對簇基本信息的概括,使得存儲信息被高度壓縮。聚類特征樹是一個高度平衡的樹,它含有兩個參數,分別為分支因子B和閾值T,其中分支因子決定了每個非葉子節點最多擁有B個孩子,閾值T決定了每個簇的直徑或半徑不能大于T值。
算法的主要過程:利用樹結構順序處理每一個樣本點,并把它劃分到距離最接近的節點中,葉子節點存儲聚類結果。
Yousri等人[5]提出了Mitosis算法,它能夠發現任意形狀以及不同密度的簇。文中提出了一種基于距離關聯性的動態模型,用以發現自然形狀的簇。距離關聯性的概念反映的是基于距離的密度,即通過簇中樣本點之間的平均距離來反映簇的密度,距離小則密度大,反之亦然。動態模型旨在維護每一個簇中樣本點之間距離的一致性,因為同一個簇中每個樣本點應該有一致的鄰域距離來保持整個簇的密度一致,所以通過判斷樣本點之間是否滿足這樣的距離一致性,即可識別這些樣本點是否屬于同一個簇。該動態模型定義了一個距離關聯性的聚類準則基于以下兩點:(1)樣本點的動態范圍決定了這個樣本點的密度環境(見定義3)。(2)定義了同一簇中樣本點之間距離一致性的標準(見定義8)。
算法的主要過程:首先為每個樣本點尋找其動態范圍最近鄰居,將每個樣本點與其鄰居建立關聯,p1和 p2為關聯的兩個樣本點,為它們之間的距離;將所有關聯按其距離由小到大的順序,依次處理這些關聯的樣本點;根據關聯樣本點之間的距離,以及關聯的兩個樣本點所處的密度環境判斷是否能將它們進行合并,最終得到聚類結果。算法包含兩個參數f和k。f為影響每個樣本點動態范圍大小的自定義參數,k為影響距離一致性的自定義參數。
2.2相關概念
定義1質心:

其中,N為簇中樣本點的數量;Xi為簇中的第i個樣本點。
定義2半徑:

當一個樣本點被分到該簇時,計算該簇半徑,當R>T時,該簇將不接受此樣本點。其中T為自定義的閾值。
定義3動態范圍:

其中,P為樣本點集;f≥1為用戶自定義參數;d(p,q)為樣本點p和q的距離。
定義4動態范圍最近鄰居:
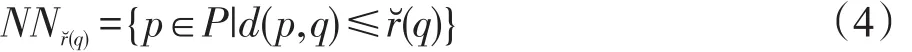
這樣的動態范圍鄰域能夠限制一個樣本點與其鄰居之間的最大距離,即只取距離該樣本點不大于該上界值的鄰居。
定義5局部平均距離:

用于檢測一個樣本點是否應該與另一個樣本點或簇合并。
定義6簇的平均距離:

用于檢測一個簇是否應該與另一個簇或樣本點合并。其中Ac為簇c的關聯集合,即在樣本點合并為簇c的過程中所有滿足合并條件(見定義8)的關聯的集合。
定義7鄰域平均距離:當樣本點為獨立樣本點時,其鄰域平均距離由式(5)計算,若樣本點屬于某個簇時,則其鄰域平均距離由式(6)計算。
定義8合并條件:
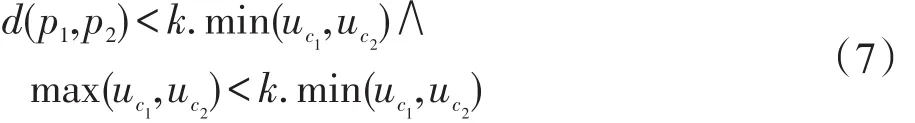
假設 p1和 p2為關聯的樣本點,其中 p1和 p2分別屬于簇c1和c2,如果c1、c2滿足式(7),那么它們將合并。其中分別為簇c1和c2的平均距離,由定義(6)計算,k≥1為用戶自定義參數。開始時每個樣本點自成一簇,如果簇只包含一個樣本點,那么簇平均距離由式(5)計算。
3 本文算法
3.1算法思想
為了提高聚類算法的時間效率,本文旨在將數據集進行初始劃分,形成多個大小近似的小簇,作為對原始數據的壓縮表示,進而將充分接近的樣本點作為一個整體處理,再依次將最接近的初始劃分的小簇的密度是否近似作為判斷依據進行合并,最終得到聚類結果。本文將結合Birch算法和Mitosis算法的優點提出一種高效的基于距離關聯性動態模型的聚類算法BMitosis(Birch-Mitosis algorithm)。因為Birch算法為單次遍歷數據聚類,具有算法時間效率高的特點,所以將Birch算法聚類結果作為對原始數據的壓縮。而Mitosis算法提出了一種新穎的動態模型,具有發現任意形狀及密度的特點,因此以Mitosis算法作為本文算法的第二階段。
3.1.1算法的核心思想
假設符號x、y分別表示一個樣本點,d(x,y)表示樣本點x與y之間的距離,以元組(x,y,d(x,y))表示樣本點x與y的關聯。k≥1表示用戶參數,u表示鄰域平均距離。
圖1說明了在聚類合并過程中滿足式(7)的重要性。對于關聯,在參考了兩個樣本點所處的鄰域平均距離的情況下,它們之間的距離較小,滿足條件,但是兩個樣本點的鄰域平均距離相差較大,不滿足。由圖1可以看出 p1與 p2足夠接近,但它們所處的鄰域平均距離不近似,p2圓中方點的平均距離明顯比p1圓中圓點的平均距離小。而對于關聯,兩個樣本點的鄰域平均距離相近似,滿足,但它們之間的距離d(p3,p4)太大,不滿足。由圖1可以看出,p3圓中圓點的平均距離與p4圓中三角點的平均距離接近,但p3、p4之間的距離太大,明顯大于它們的鄰域平均距離。因此,在這兩種情形中兩個樣本點都不能合并。
合并條件(式(7))同時考慮了兩種情況:(1)兩個關聯的樣本點是否接近,通過它們之間的距離與這兩個樣本點的鄰域平均距離的對比來進行判斷,若滿足條件,則表示這兩個樣本點足夠接近。(2)兩個關聯樣本點的鄰域平均距離是否近似,根據是否滿足條件進行判斷。這里的參數k決定了所能接受的近似程度。因此,算法在合并兩個樣本點為一個簇時,基于這樣的思路:這兩個樣本點之間的距離應該是接近的,且它們所處的密度環境也是近似的。
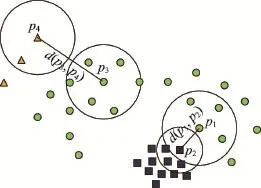
Fig.1 Importance of distance consistency圖1 滿足距離一致性的重要性
3.1.2算法的改進
(1)用Birch算法對數據集進行初始劃分,剔除異常的簇,以每個簇的質心作為該簇內所有樣本點的代表點,參與Mitosis算法的運算,以減少Mitosis算法的計算量,提高運算速度。
(2)在Birch算法的層次樹狀結構上提出剪枝策略,以降低為每個樣本點求動態范圍最近鄰居的計算量。
(3)由于第一階段以Birch初始劃分得到的簇的質心作為該簇中所有樣本點的代表點,為了兼顧這些簇中其他樣本點分布的影響,將局部平均距離改為代表點局部平均距離,即將代表點到其動態范圍最近鄰居的平均距離改為代表點到其所代表的簇中所有樣本點的平均距離。
在本文算法中,將式(5)改為:

其中,c(p)為代表點p所代表的簇;||c(p)為該簇中樣本點的數量;x為c(p)中的所有樣本點。而式(8)的值很容易在第一階段的Birch算法中獲得。在計算簇的平均距離時,關聯集合將包括簇中所有代表點到其所代表簇中所有樣本點的關聯。
3.2算法步驟
BMitosis算法的整體步驟:
(1)Birch算法對數據集進行初始聚類,將聚類得到的小簇作為一個處理對象,為避免噪音數據的影響,將樣本點數量小于閾值V的簇視為噪音數據,不參與第二階段的聚類。將每個正常簇的質心作為該簇中所有樣本點的代表點參與第二階段的聚類運算。
(2)在層次結構上提出剪枝策略。第二階段的運算需要為每個代表點計算其動態范圍最近鄰居,直接計算時間復雜度將是O(n2),其中n為代表點的個數。因為層次聚類的結構中每一層簇為當前最相近簇的集合,所以在計算每個代表點的動態范圍最近鄰居時,先比較其所在簇的其他代表點,若當前層不能求得其動態范圍內的所有最近鄰居,則再往上一層繼續查詢,直到求得所有最近鄰居為止。這樣在為每個代表點求動態范圍最近鄰居時能有效縮小計算比較的范圍,避免了相距甚遠的代表點間的計算,有效降低了時間復雜度。
如圖2所示:o1、o2、o3、o4、o5、o6分別為各自簇的代表點,O為它們上一層簇的質心。R為該層簇中O到其包含的所有代表點中距離最遠的距離,由圖可見R=d(O,o1)。d1為o3到該層簇中其他代表點的最近距離,則r1為o3的動態范圍;d2為o2到該層簇中其他代表點的最近距離,則r2為o2的動態范圍,如式(3)。d(O,o2)、d(O,o3)分別為質心O到代表點o2、o3的距離。當d(O,o3)+r1≤R時,如右虛線圓所示,則求o3的動態范圍最近鄰居,只需比較該層簇的所有其他代表點。當d(O,o2)+r2>R時,如左虛線圓所示,則求o2的動態范圍最近鄰居,需要繼續往上一層更大的簇中比較其他代表點。
(3)將代表點作為改進后Mitosis的數據集,將聚類結果中原始樣本點數量小于總樣本點數量1%的簇視為異常簇,將異常簇中的代表點劃分到其最近的正常簇中。
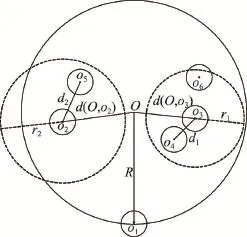
Fig.2 Pruning strategy圖2 剪枝策略圖示
3.3算法偽代碼


4 實驗及分析
實驗由Windows 7操作系統,Intel?CoreTMi5-3470 CPU 3.20 GHz,4 GB內存作為實驗環境。實驗數據集采用Chameleon數據集[4]t5.8k、DS5和DS3,如圖3所示。3個數據集均為8 000個二維數據點。t5.8k數據集包含6個不同大小、形狀的簇,同時伴隨隨機噪音數據和一條直線痕跡貫徹這些簇。DS3數據集包含6個不同大小、形狀的簇,同時伴隨著隨機噪音數據和特殊的痕跡貫徹這些簇。DS5數據集包含8個不同形狀、大小、密度的簇,同時伴隨著隨機噪音數據,該數據集的難點在于它的每個簇彼此都很接近,且它們為不同的密度。
本文算法涉及5個用戶自定義參數B、T、V、f、k。其中B為分支因子,T為聚類閾值,V為噪音閾值,f為動態范圍參數,k為合并條件參數。在對以上3個數據集的聚類過程中,本文算法取值B=5,V=10,即在初始聚類時將小簇中樣本點數量小于10的簇視為噪音數據。

Fig.3 View of datasets圖3 數據集視圖
4.1時間效率對比
圖4顯示了使用剪枝策略前后的時間效率對比。從圖中可以看出當DS3數據集大于2 000時使用剪枝策略的時間消耗更低,而數據集小于2 000時使用剪枝策略的時間消耗略高。原因在于數據對象個數小于2 000時,由于代表點的數量較少,使用剪枝算法增加了額外的計算開銷。而對數據集t5.8k與DS5的聚類過程,使用剪枝策略的算法運行時間始終比未使用剪枝策略低。這是由于不同的數據集有不同的數據分布情況,即使數據量一樣,產生代表點的數量及分布情況也不一樣。3個數據集的整體走勢說明對大數據集聚類時使用剪枝策略能有效降低運行時間。
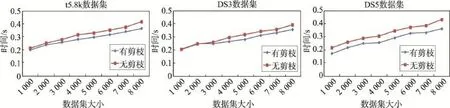
Fig.4 Time efficiency of pruning strategy圖4 剪枝策略的時間效率
圖5顯示了本文算法的兩個階段的運行時間對比。第一階段使用Birch算法,Birch算法為單遍掃描,因此時間整體呈線性增長。第二階段在第一階段基礎上進行Mitosis算法,因此消耗時間均比Birch高。但因為第二階段的處理對象為代表點,當數據集規模增加時代表點增加的速度較樣本點慢,所以隨著數據集規模的增加出現了算法運行時間增幅減緩的趨勢,如DS3數據集大小從2 000到3 000的過程及DS5數據集大小從3 000到4 000及6 000到7 000的過程中,運行時間出現了平緩增加的現象。
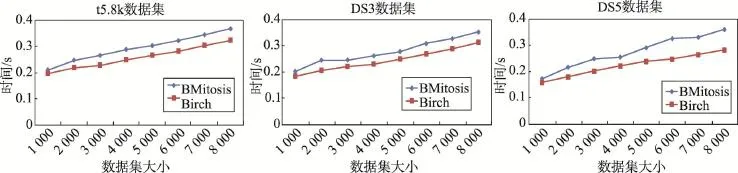
Fig.5 Comparison of time spending in two stages of BMitosis圖5 本文算法兩個階段的時間效率
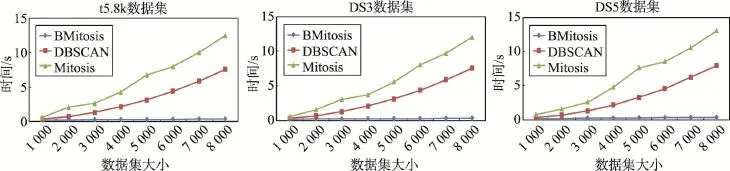
Fig.6 Time efficiency of BMitosis compared to other algorithms圖6 本文算法與同類算法的時間效率對比
圖6顯示了本文算法與其他聚類算法的時間效率比較。因為Mitosis算法處理對象為單個樣本點,需要對每個關聯是否能夠合并進行判斷,所以算法運行時間隨著數據集的大小波動較大。而本文算法以代表點作為處理對象,代表點的數量將遠小于樣本點,且當樣本點數量增加時,樣本點相距較近時可能被分在同一個簇中,因此代表點的數量不會直線增加,使得算法處理對象數量將大大降低。圖中3個數據集本文算法運算時間均不足1 s。
4.2準確性對比
圖3為數據集原圖,圖7為本文算法的聚類結果,聚類得到的簇以不同的顏色表示。從圖7中可以清晰地看到不同的形狀,且排除了大部分的噪音數據。對數據集t5.8k聚類算法參數為T=6.75,f=2.5,k= 3.0。對數據集DS3聚類算法參數為T=11.95,f= 2.6,k=2.7。對數據集DS5聚類算法參數為T= 14.25,f=1.3,k=3.24。
因為Mitosis算法以單個樣本點為處理對象,所以容易對周圍的噪音數據進行聚類,不能有效地排除噪音數據。圖8為Mitosis算法對數據集t5.8k的聚類結果,算法參數為 f=2.3,k=2.65,數據集t5.8k含有很多的噪音數據,因此Mitosis算法在聚類6個正確的簇的同時,也對周邊的噪音數據進行了聚類,沒有很好地排除噪音數據。DBSCAN算法能夠很有效地屏蔽噪音數據的干擾,但它只能發現靜態密度的簇,當數據集中存在不同密度的簇時,算法不能有效地區分。圖9為DBSCAN算法對數據集DS5的聚類結果,算法參數為Eps=10,Minpts=4,由于數據集DS5包含不同密度的簇,DBSCAN算法只能聚出6個簇。

Fig.7 Result of BMitosis圖7 本文算法聚類結果

Fig.8 Clustering result of Mitosis圖8 Mitosis的聚類結果

Fig.9 Clustering result of DBSCAN圖9 DBSCAN的聚類結果
為比較算法的準確性,本文采用F-Measure[14]進行評估,計算公式為:
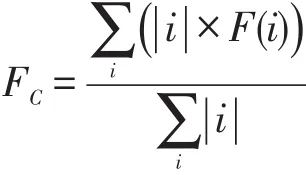
其中,|i| 為類i的樣本點數量。
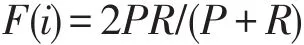
其中,Nij為同時在類i和簇 j的樣本點數量;Nj為簇j中樣本點的數量;Ni為類i的樣本點數量。
從表1中可以看出本文算法的準確性介于兩個算法之間,而DBSCAN算法在處理單一密度的數據集時有很高的準確性,然而在處理存在不同密度的數據集時準確性較差。
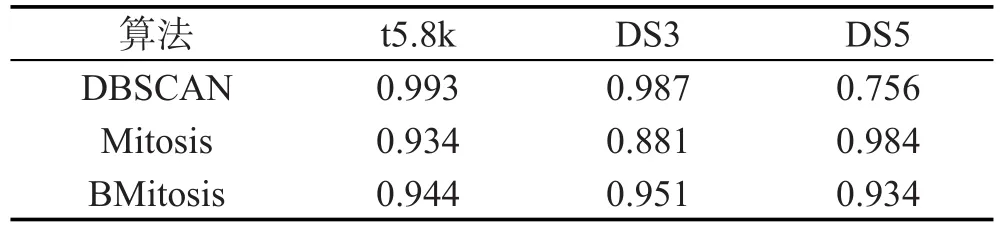
Table 1 Evaluation result of F-Measure表1 F-Measure評估結果
4 結束語
針對大部分聚類算法無法高效發現任意形狀及不同密度的簇的問題,本文提出了一種高效的聚類改進算法BMitosis。該方法主要分為兩個階段:第一階段用Birch算法對數據集進行初始聚類,并排除樣本點數量小于閾值的簇,避免噪音數據的影響,以簇的質心作為整個簇的代表點參與第二階段的聚類。第二階段在層次結構上提出剪枝策略,降低計算每個代表點動態最近鄰居的時間復雜度,再進行改進的Mitosis算法運算。實驗表明BMitosis算法能有效排除噪音數據的影響,且能有效發現任意形狀及不同密度的簇,在準確性較好的情況下,時間效率得到了顯著的提高。當然本文算法引入的參數較多,減少算法對參數的依賴性是進一步需要解決的重要問題。
References:
[1]Mai S T,He Xiao,Feng Jing,et al.Anytime density-based clustering of complex data[J].Knowledge and Information Systems,2015,45(2):319-355.
[2]He Jinyuan,Zhao Gansen,Zhang Haolan,et al.An effective clustering algorithm for auto-detecting well-separated clusters[C]//Proceedings of the 2014 IEEE International Conference on Data Mining Workshop,Shenzhen,China, Dec 14,2014.Piscataway,USA:IEEE,2014:867-874.
[3]Zhang Tian,Ramakrishnan R,Livny M.BIRCH:an efficient data clustering method for very large databases[C]// Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data,Montreal,Canada,Jun 1996.New York,USA:ACM,1996:103-114.
[4]Karypis G,Han E H,Kumar V.Chameleon:hierarchical clustering using dynamic modeling[J].Computer,1999,32 (8):68-75.
[5]Yousri N A,Kamel M S,Ismail M A.A distance-relatedness dynamic model for clustering high dimensional data of arbitrary shapes and densities[J].Pattern Recognition,2009,42 (7):1193-1209.
[6]Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining,1996:226-231. [7]Liu Peng,Zhou Dong,Wu Naijun.VDBSCAN:varied density based spatial clustering of applications with noise[C]// Proceedings of the 2007 International Conference on Ser-vice Systems and Service Management,Chengdu,China, Jun 9-11,2007.Piscataway,USA:IEEE,2007:1-4.
[8]Chowdhury A K M R,Mollah M E,Rahman M A.An efficient method for subjectively choosing parameter‘k’automatically in VDBSCAN(varied density based spatial clustering of applications with noise)algorithm[C]//Proceedings of the 2nd International Conference on Computer and Automation Engineering,Singapore,Feb 26-28,2010.Piscataway,USA:IEEE,2010:38-41.
[9]Ram A,Jalal S,Jalal A S,et al.A density based algorithm for discovering density varied clusters in large spatial databases[J].International Journal of Computer Applications, 2010,3(6):1-4.
[10]Kriegel H P,Kr?ger P,Sander J,et al.Density based clustering[J].Wiley Interdisciplinary Reviews:Data Mining and Knowledge Discovery,2011,1(3):231-240.
[11]Rinaldo A,Wasserman L.Generalized density clustering[J]. TheAnnals of Statistics,2010,38(5):2678-2722.
[12]Encyclopedia of machine learning[M].[S.l.]:Springer Science&Business Media,2011.
[13]Nanda S J,Panda G.A survey on nature inspired metaheuristic algorithms for partitional clustering[J].Swarm and Evolutionary Computation,2014,16:1-18.
[14]Hammouda K M,Kamel M S.Phrase-based document similarity based on an index graph model[C]//Proceedings of the 2002 IEEE International Conference on Data Mining, Washington,USA,2002.Piscataway,USA:IEEE,2002: 203-210.

CHEN Xiongtao was born in 1989.He is an M.S.candidate at School of Computer Science and Technology,China University of Mining and Technology.His research interests include data mining technology and pattern recognition,etc.
陳雄韜(1989—),男,福建政和人,中國礦業大學計算機科學與技術學院碩士研究生,主要研究領域為數據挖掘,模式識別等。

閆秋艷(1978—),女,江蘇徐州人,2010年于中國礦業大學獲得博士學位,現為中國礦業大學計算機科學與技術學院副教授,主要研究領域為時間序列挖掘,流數據挖掘等。
Clustering ImprovedAlgorithm Based on Distance-Relatedness Dynamic Model*
CHEN Xiongtao+,YAN Qiuyan
School of Computer Science and Technology,China University of Mining and Technology,Xuzhou,Jiangsu 221116, China
+Corresponding author:E-mail:chenxiongtao1989@163.com
In view of the fact that most of clustering algorithms fail to find arbitrary shaped and different density clusters efficiently,this paper proposes an efficient clustering improved algorithm based on distance-relatedness dynamic model.Firstly,in order to improve the efficiency of clustering,using hierarchical clustering algorithms for the data set to get the initial clusters and remove abnormal clusters.Secondly,in order to obtain arbitrary shaped clusters,taking the centroid of initial clusters as the representative point of all points in it,then running the distancerelatedness dynamic model for clustering,and using the tree structure of hierarchical clustering for pruning.Finally, verifying the effectiveness of the proposed algorithm.The algorithm is tested on the Chameleon dataset,the experimental results show that the algorithm can obtain arbitrary shape and different density clusters,and compared with the same algorithms,the time efficiency is improved significantly.
clustering;arbitrary shaped clusters;different density clusters;distance-relatedness;dynamic model
2015-06,Accepted 2015-08.
YAN Qiuyan was born in 1978.She the Ph.D.degree from China University of Mining and Technology in 2010.Now she is an associate professor at School of Computer Science and Technology,China University of Mining and Technology.Her research interests include time series mining and stream data mining,etc.
10.3778/j.issn.1673-9418.1507069
*The Natural Science Foundation of Jiangsu Province under Grant No.BK20140192(江蘇省自然科學基金);the Youth Science Foundation of China University of Mining and Technology under Grant No.2013QNB16(中國礦業大學青年科技基金項目).
CNKI網絡優先出版:2015-08-12,http://www.cnki.net/kcms/detail/11.5602.TP.20150812.1632.005.html
A
TP301.6
