密度峰值優化初始中心的K-medoids聚類算法*
2016-11-30 09:43:52謝娟英屈亞楠
計算機與生活 2016年2期
謝娟英,屈亞楠
陜西師范大學 計算機科學學院,西安 710062
密度峰值優化初始中心的K-medoids聚類算法*
謝娟英+,屈亞楠
陜西師范大學 計算機科學學院,西安 710062
針對快速K-medoids聚類算法和方差優化初始中心的K-medoids聚類算法存在需要人為給定類簇數,初始聚類中心可能位于同一類簇,或無法完全確定數據集初始類簇中心等缺陷,受密度峰值聚類算法啟發,提出了兩種自適應確定類簇數的K-medoids算法。算法采用樣本xi的t最近鄰距離之和倒數度量其局部密度ρi,并定義樣本xi的新距離δi,構造樣本距離相對于樣本密度的決策圖。局部密度較高且相距較遠的樣本位于決策圖的右上角區域,且遠離數據集的大部分樣本。選擇這些樣本作為初始聚類中心,使得初始聚類中心位于不同類簇,并自動得到數據集類簇數。為進一步優化聚類結果,提出采用類內距離與類間距離之比作為聚類準則函數。在UCI數據集和人工模擬數據集上進行了實驗測試,并對初始聚類中心、迭代次數、聚類時間、Rand指數、Jaccard系數、Adjusted Rand index和聚類準確率等經典聚類有效性評價指標進行了比較,結果表明提出的K-medoids算法能有效識別數據集的真實類簇數和合理初始類簇中心,減少聚類迭代次數,縮短聚類時間,提高聚類準確率,并對噪音數據具有很好的魯棒性。
聚類;K-medoids算法;初始聚類中心;密度峰值;準則函數
1 引言
聚類基于“物以類聚”原理將一組樣本按照相似性歸成若干類簇,使得屬于同一類簇的樣本之間差別盡可能小,而不同類簇的樣本間差別盡可能大。聚類算法包括基于劃分的方法、基于層次的方法、基于密度的方法、基于網格的方法和基于模型的方法[1]。經典的劃分式聚類算法包括K-means算法[2]和K-medoids算法[3]。K-medoids算法克服了K-means算法對孤立點敏感的缺陷,PAM(partitioningaroundmedoids)算法[3-4]是最經典的K-medoids算法。然而,K-medoids算法同K-means算法一樣,存在著聚類結果隨初始聚類中心改變而變化的問題。
快速K-medoids算法[5]從初始聚類中心選擇和聚類中心更迭兩方面對PAM算法進行改進,取得了遠優于PAM算法的聚類效果。然而快速K-medoids算法選擇的初始聚類中心可能位于同一類簇。鄰域K-medoids聚類算法[6]提出鄰域概念,使選擇的初始聚類中心盡可能位于不同樣本分布密集區,得到了優于快速K-medoids算法的聚類效果,但該算法的鄰域半徑需要人為設定。引入粒度概念,定義粒子密度,選擇密度較大的前K個粒子的中心樣本作為K-medoids算法的初始聚類中心,得到了更好的初始聚類中心和聚類結果,且避免了文獻[6]主觀選擇鄰域半徑的缺陷[7-8]。但是基于粒計算的K-medoids算法[7]構造樣本去模糊相似矩陣時需要人為給定閾值。粒計算優化初始聚類中心的K-medoids算法將粒計算與最大最小距離法結合[9],且使用所有樣本的相似度均值作為其構造去模糊相似度矩陣的閾值,改進了文獻[7]需要人為設定閾值進行模糊相似矩陣去模糊操作的缺陷。文獻[10]中算法完全依賴數據集自身的分布信息,以方差作為樣本分布密集程度度量,分別以樣本間距離均值和相應樣本標準差為鄰域半徑,選取方差值最小且其間距離不低于鄰域半徑的樣本為初始聚類中心,使K-medoids算法的初始聚類中心盡可能完全反應數據集樣本原始分布信息,得到優于快速K-medoids和鄰域K-medoids算法的聚類結果,且不需要任何主觀參數選擇。但是該算法當鄰域半徑過大時,不能得到數據集真實類簇數。Rodriguez等人[11]基于聚類中心比其近鄰樣本密度高且與其他密度較高樣本的距離相對較遠的特點,提出快速搜索密度峰值聚類算法(clustering by fast search and find of density peaks,DPC),以密度峰值點樣本為類簇中心,自動確定類簇個數,并分配樣本到距離最近的密度較高樣本所在類簇實現聚類。但是該算法需要人為給定截斷距離參數,聚類結果隨截斷距離參數改變而波動。
本文針對快速K-medoids算法[5]和方差優化初始中心K-medoids算法[10]的潛在缺陷,受文獻[11]啟發,提出了密度峰值優化初始中心的K-medoids聚類算法DP_K-medoids(density peak optimized K-medoids)。DP_K-medoids算法使用樣本xi的t近鄰距離之和的倒數度量樣本xi的局部密度ρi,并定義樣本xi的距離δi為樣本xi到密度大于它的最近樣本xj的距離的指數函數,構造樣本距離相對于樣本密度的決策圖,選擇決策圖中樣本密度ρ和樣本距離δ都較高,且明顯遠離數據集大部分樣本點的決策圖右上角的密度峰值點作為初始聚類中心,使得初始聚類中心位于不同類簇,同時自適應地確定類簇個數。
劃分式聚類算法的思想是使類內距離盡可能小,而類間距離盡可能大,因此本文提出以類內距離與類間距離之比作為新聚類準則函數,得到了改進DP_K-medoids算法DPNM_K-medoids(density peak optimized K-medoids with new measure)。其中類內距離度量定義為聚類誤差平方和,類間距離定義為各類簇中心樣本距離之和。
通過UCI數據集和人工模擬數據集實驗測試,以及對不同聚類有效性指標進行比較,結果表明本文提出的DP_K-medoids算法和DPNM_K-medoids算法均能識別數據集的類簇數,并選擇到數據集的合理初始聚類中心,有效減少了聚類迭代次數,縮短了聚類時間,提高了聚類準確率。
2 基本概念
設給定含n個樣本的數據集X={x1,x2,…,xn},每個樣本有p維特征,欲將其劃分為k個類簇Cj,j= 1,2,…,k,k<n,第i個樣本的第 j個屬性值為xij。


3 本文K-medoids算法
本文提出密度峰值優化初始中心的K-medoids聚類算法,主要針對快速K-medoids算法和方差優化初始中心的K-medoids算法的缺陷展開,其主要貢獻是樣本xi的局部密度ρi采用其t最近鄰距離之和的倒數度量,樣本xi的距離δi定義為樣本xi到密度大于它的最近樣本xj的距離的指數函數,利用樣本距離相對于樣本密度的決策圖,自適應地確定數據集類簇數和K-medoids算法的合理初始類簇中心。
3.1DP_K-medoids算法思想
針對快速K-medoids算法和方差優化初始中心K-medoids算法需要人為設定類簇數k,以及前者初始聚類中心可能位于同一類簇,后者初始聚類中心受到鄰域半徑影響,可能不能得到數據集真實類簇數的缺陷,本文DP_K-medoids算法使用樣本的t最近鄰距離之和的倒數度量樣本xi的局部密度ρi,采用式(6)定義度量樣本xi的距離δi。以ρ為橫軸,δ為縱軸構造樣本距離相對于樣本密度的決策圖,選擇決策圖中樣本密度ρ和樣本距離δ都較高,且明顯遠離大部分樣本點的決策圖右上角區域的密度峰值點為初始類簇中心,密度峰值點個數即為類簇數,使選擇的初始聚類中心位于不同類簇。
步驟1初始化。
(1)根據式(7)對樣本進行標準化;
(2)根據式(5)計算樣本xi的局部密度ρi,根據式(6)計算樣本xi的距離δi;
(3)構造以ρ為橫軸,δ為縱軸的決策圖,選擇決策圖中樣本密度ρ和樣本距離δ都較高,且明顯遠離大部分樣本的右上角區域的密度峰值點為初始聚類中心,密度峰值點個數為類簇數k。
步驟2構造初始類簇。
(1)根據距離最近原則,將其余樣本點分配到最近初始類簇中心,形成初始劃分;
(2)計算聚類誤差平方和。
步驟3更新類簇中心并重新分配樣本。
(1)為每個類簇找一個新中心,使得簇內其余樣本到新中心距離之和最小,用新中心替換原中心;
(2)重新分配每個樣本到最近類簇中心,獲得新聚類結果,計算聚類誤差平方和;
(3)若當前聚類誤差平方和與前次迭代聚類誤差平方和相同,則算法停止,否則轉步驟3。
3.2DPNM_K-medoids算法思想
DPNM_K-medoids使用類內距離與類間距離之比作為聚類準則函數,求聚類表達式(4)的最小優化。當準則函數達到最小值時,得到最優聚類結果。DPNM_K-medoids算法的初始聚類中心選擇與DP_K-medoids的初始聚類中心選擇方法相同,二者的區別在于聚類準則函數不同,也就是聚類的停止條件不同。將DP_K-medoids算法的步驟2和步驟3計算聚類誤差平方和修改為計算聚類結果的新聚類準則函數值,同時將步驟3中的第3小步修改為,若當前新聚類準則函數值不小于前次迭代的新聚類準則函數值,則算法停止,否則轉步驟3繼續執行,便得到DPNM_K-medoids算法。
3.3本文K-medoids算法分析
K-medoids算法的時間復雜度由初始聚類中心選擇和聚類中心更迭兩部分組成。密度峰值聚類算法的時間復雜度由初始聚類中心選擇和樣本分配兩部分組成。
本文DP_K-medoids和DPNM_K-medoids算法,以及密度峰值聚類算法[11]通過計算樣本局部密度和樣本距離選取初始聚類中心。由式(5)樣本局部密度計算和式(6)樣本距離計算以及密度峰值聚類算法描述[11]可見,該3種算法計算一個樣本局部密度與距離的時間復雜度均為Ο(n),因此本文DP_K-medoids和DPNM_K-medoids算法,以及密度峰值聚類算法[11]計算所有樣本密度的時間復雜度為Ο(n2)。
快速K-medoids算法[5]通過計算樣本全局密度選取初始聚類中心。方差優化初始中心的MD_K-medoids和SD_K-medoids算法[10]通過計算樣本方差選取初始聚類中心。快速K-medoids算法[5]和方差優化初始中心的K-medoids算法[10]計算一個樣本密度的時間復雜度分別為Ο(n2)和Ο(n),因此快速K-medoids算法計算所有樣本密度的時間復雜度為Ο(n3),方差優化初始中心的K-medoids算法計算所有樣本方差的時間復雜度為Ο(n2)。
本文兩種K-medoids算法、快速K-medoids算法[5]、方差優化初始中心的MD_K-medoids和SD_K-medoids算法[10]聚類中心更迭的時間復雜度均為Ο(nk×iter),其中iter為算法迭代次數,n為樣本數,k為類簇數。密度峰值聚類算法[11]在獲得初始聚類中心后,將其余樣本分配給密度比它大的最近鄰樣本所在類簇,因此樣本分配時間復雜度為Ο(n)。
因此,本文DP_K-medoids和DPNM_K-medoids算法,以及方差優化初始中心的MD_K-medoids和SD_K-medoids算法的時間復雜度為Ο(n2+nk×iter)。快速K-medoids算法的時間復雜度為Ο(n3+nk× iter)。密度峰值聚類算法的時間復雜度為Ο(n2+n)。由此可見,盡管上述6種聚類算法的時間復雜度可統一表達為O(n2)數量級,但密度峰值聚類算法是該6種聚類算法中速度最快的聚類算法。
5種K-medoids算法均先獲得k個初始聚類中心,然后根據距離最近原則將其余樣本分配到最近初始聚類中心,得到初始類簇劃分。初始劃分通常不是最優聚類結果,當前聚類準則函數值通常不是最小的。此時,進行聚類中心更迭,當一次聚類中心更替發生,并重新分配樣本得到新類簇分布時,計算當前分布的聚類準則函數值,若比上次迭代的聚類準則函數值小,則繼續迭代。經過若干次迭代后,聚類準則函數值達到最小,即聚類結果不再發生改變,聚類算法收斂到最優解。
4 實驗結果與分析
為了測試本文K-medoids算法的性能,分別在UCI數據集和兩種人工模擬數據集上進行實驗。實驗環境是Inter?CoreTMi5-3230M CPU@2.60 GHz,4GB內存,400GB硬盤,Matlab應用軟件。
算法聚類結果采用迭代次數、聚類時間、聚類準確率,以及外部有效性評價指標Rand指數[12]、Jaccard系數[13-15]和Adjusted Rand index[16-17]參數進行評價。
4.1UCI數據集實驗結果與分析
本部分實驗采用UCI機器學習數據庫[18]的iris等13個聚類算法常用數據集對本文算法進行測試。所用數據集描述見表1,pid是pima indians diabetes數據集的簡寫,waveform40是waveform21增加19個噪音屬性得到的數據集。本文DP_K-medoids和DPNM_ K-medoids算法分別與快速K-medoids算法[5]、方差優化初始中心的MD_K-medoids和SD_K-medoids算法[10],以及密度峰值聚類算法[11]進行比較,以檢驗本文提出的密度峰值優化初始中心的K-medoids算法的有效性。
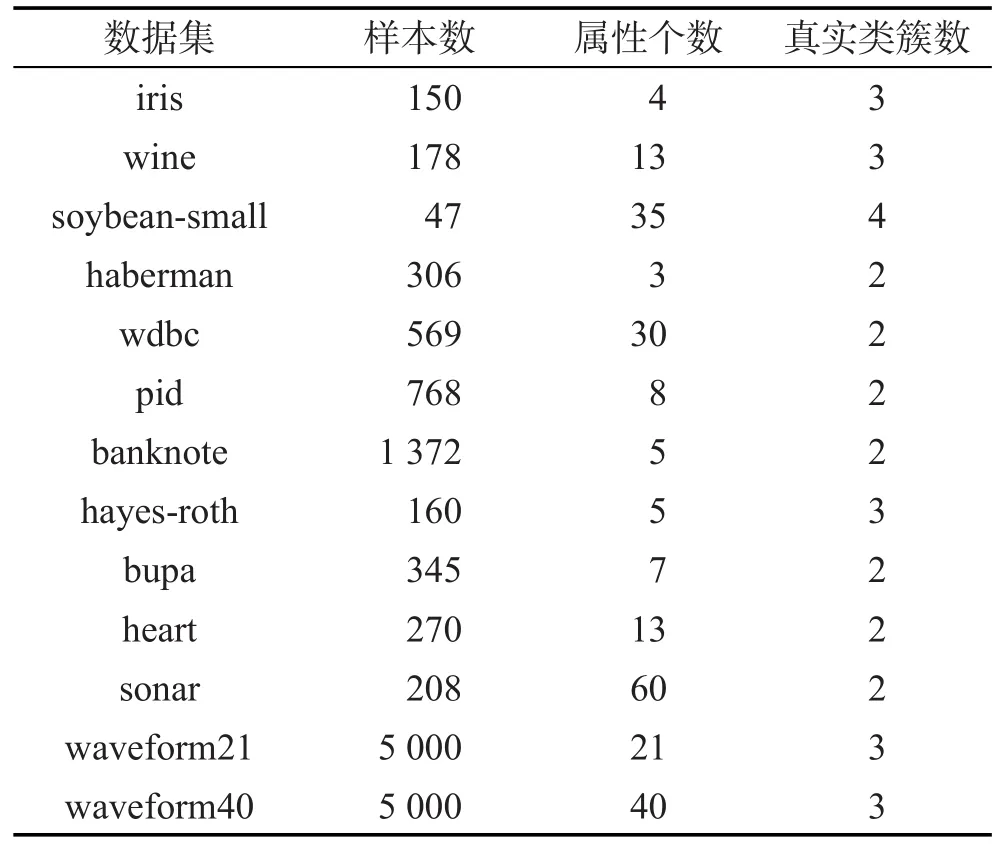
Table 1 Datasets from UCI machine learning repository表1 UCI數據集描述
由于各數據集樣本空間分布不同,本文K-medoids算法選取的樣本最近鄰數t值也不盡相同,數據集haberman、hayes-roth、sonar、waveform21和 waveform40的樣本最近鄰數t=6,數據集pid的樣本最近鄰數t=7,其余7個UCI數據集的樣本最近鄰數t=8。密度峰值聚類算法的結果隨截斷距離參數值的改變而不同,實驗展示的是在各數據集多次實驗得到的最好聚類結果值。本文K-medoids算法在UCI數據集上的決策圖及其初始聚類中心如圖1所示,圖中矩形框內的加粗黑圓點為所選初始聚類中心。表2是6種聚類算法對表1 UCI數據集選擇的初始聚類中心樣本。表3是6種聚類算法對表1 UCI數據集10次運行的平均迭代次數和平均聚類時間。其中,加粗字體表示相應的最好實驗結果。密度峰值聚類算法不存在聚類中心更迭的過程,因而比較算法平均迭代次數時不將密度峰值聚類算法作為對比算法。圖2展示了6種聚類算法的Rand指數、Jaccard系數、AdjustedRandindex參數和聚類準確率的平均值比較。
圖1所示實驗結果對比表1的數據集描述可以看出,本文兩種K-medoids算法能發現數據集的真實類簇數和相應的初始聚類中心。因此,本文兩種K-medoids算法克服了快速K-medoids算法、MD_K-medoids算法和SD_K-medoids算法需要人為給定類簇數,及其選擇初始類簇中心時的缺陷。
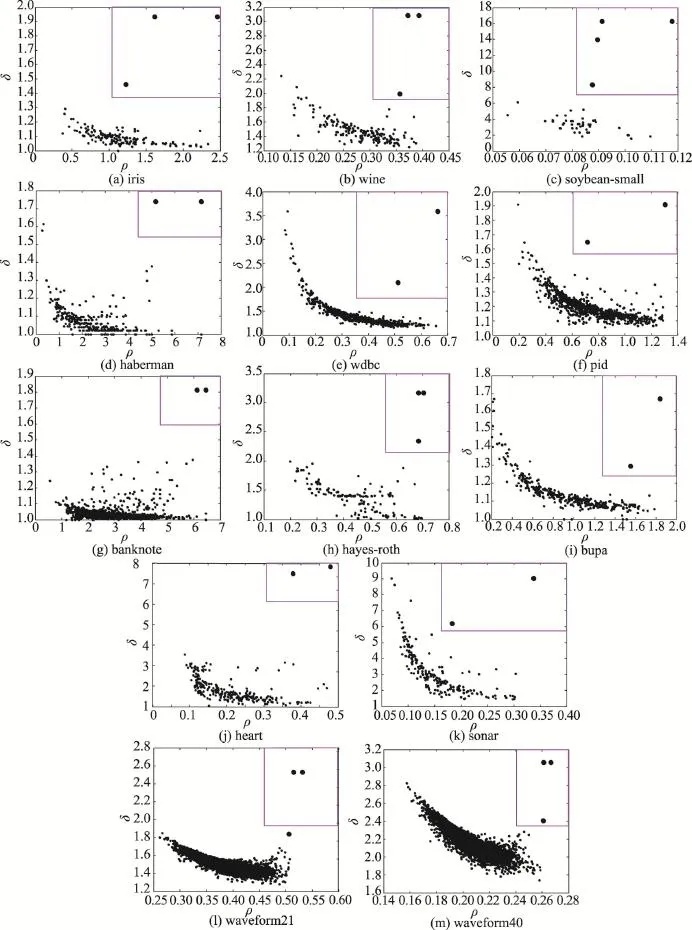
Fig.1 Decision graphs and initial seeds of the proposed K-medoids algorithms on UCI datasets圖1 本文K-medoids算法對各UCI數據集的決策圖及其初始聚類中心
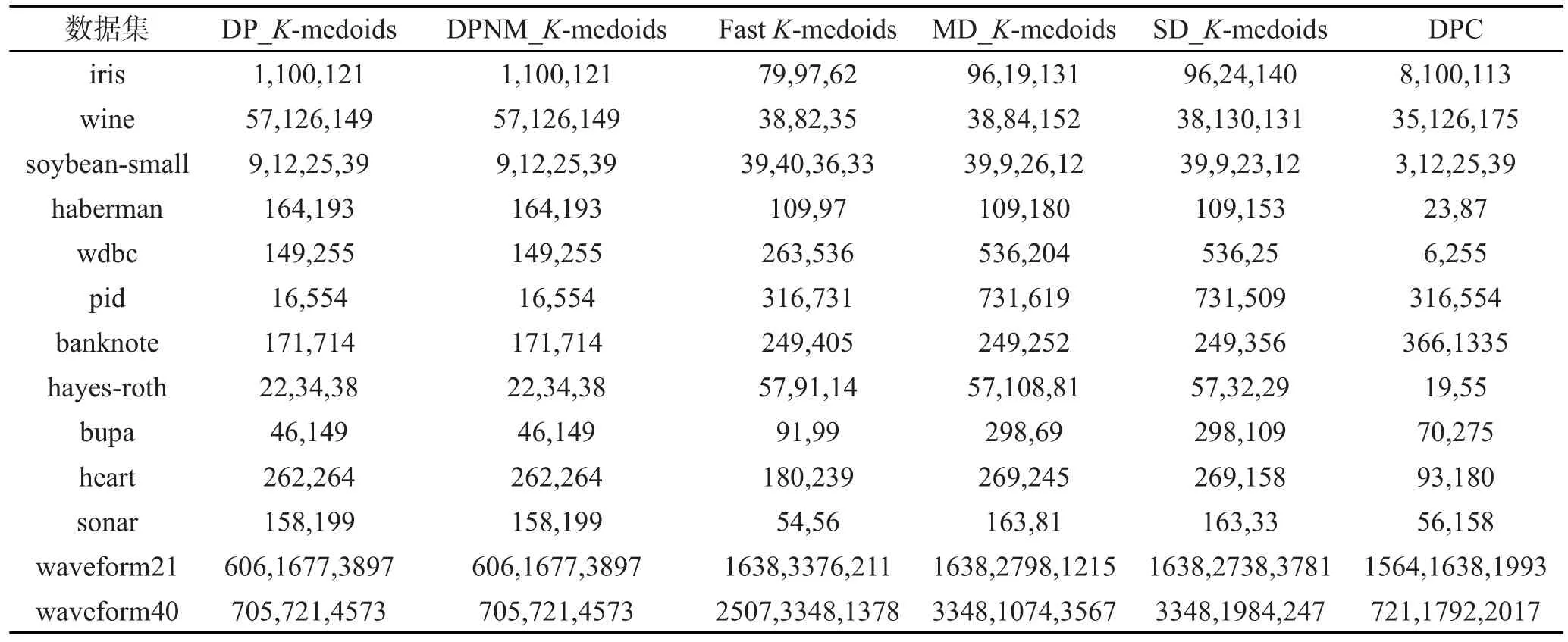
Table 2 Initial seeds selected by six algorithms on UCI datasets表2 6種算法在UCI數據集上選擇的初始聚類中心
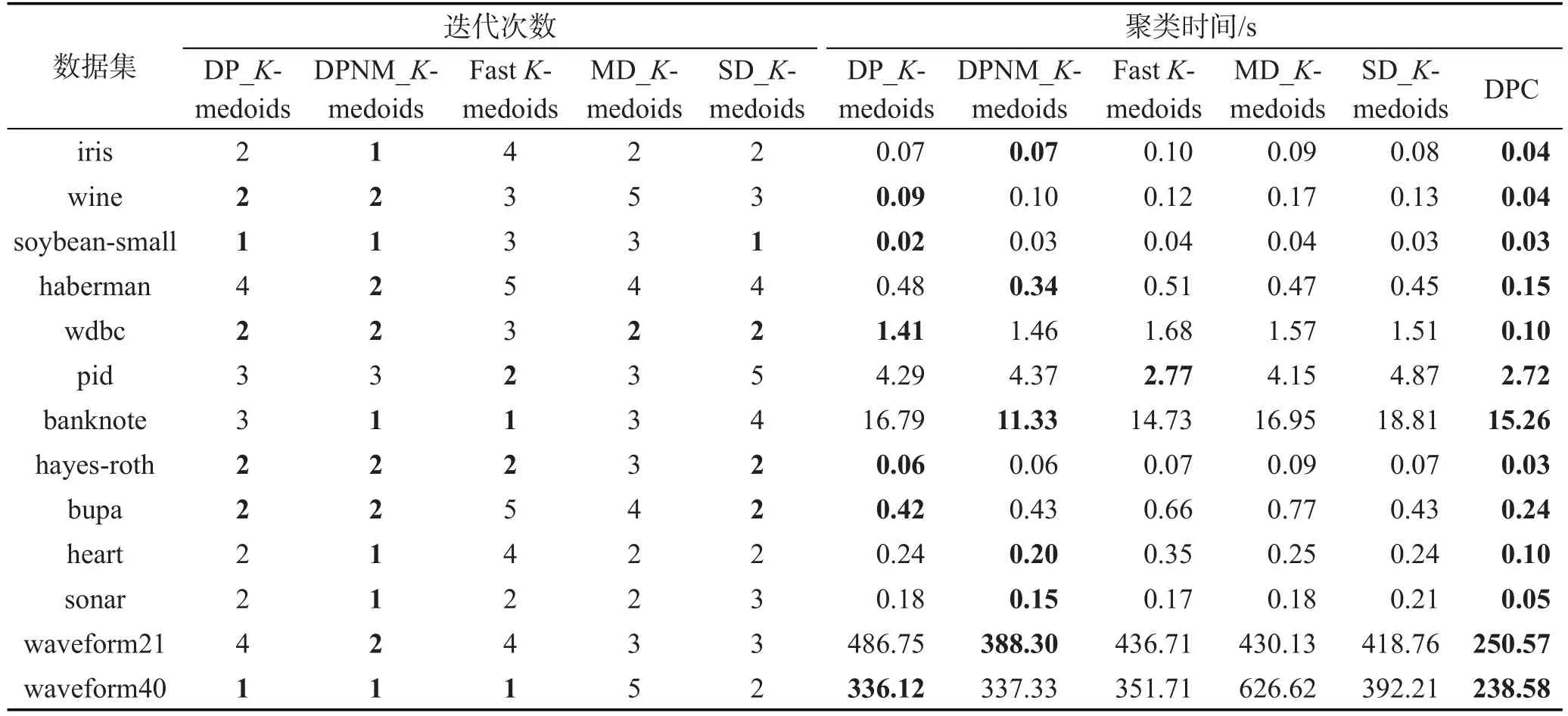
Table 3 Iterations and clustering time of six algorithms on UCI datasets表3 UCI數據集上6種算法的迭代次數和聚類時間
分析表2實驗結果與各數據集真實分布可知,本文DP_K-medoids和DPNM_K-medoids算法除了在haberman、banknote、hayes-roth和sonar數據集選擇的初始聚類中心存在位于同一類簇的現象,在其余9個UCI數據集上選擇的初始聚類中心均位于不同類簇。快速K-medoids算法在iris、wine、pid和bupa這4個數據集選擇的初始聚類中心位于不同類簇,在其余9個數據集的初始聚類中心均存在位于同一類簇的現象。MD_K-medoids算法在7個數據集選擇的初始聚類中心位于不同類簇,在haberman、pid、banknote、hayes-roth、bupa和heart數據集選擇的初始聚類中心位于同一類簇。SD_K-medoids算法在haberman、banknote、hayes-roth、heart和waveform21數據集選擇的初始聚類中心位于同一類簇,在其余8個數據集選擇的初始聚類中心均位于不同類簇。密度峰值聚類算法在7個數據集選擇的初始聚類中心位于不同類簇,在haberman、pid、hayes-roth、bupa、waveform21和waveform40數據集選擇的初始聚類中心均存在位于同一類簇的現象。由此可見,本文提出的DP_K-medoids和DPNM_K-medoids算法選擇的初始聚類中心更好,從而可以得到較好的初始類簇劃分,加快算法收斂速度,并增加算法收斂到全局最優解的概率。
從表3所示實驗結果可以看出,本文提出的兩種K-medoids算法在除數據集pid之外的其他12個UCI數據集上的迭代次數和運行時間都優于其他3種K-medoids算法。快速K-medoids算法在pid數據集的迭代次數和聚類時間都最優。表3實驗結果揭示,本文DPNM_K-medoids算法的迭代次數優于DP_K-medoids算法,在迭代次數相同的情況下,本文DP_K-medoids算法的運行時間更快。分析原因是,本文DPNM_K-medoids算法采用新聚類準則作為收斂性判斷依據,而DP_K-medoids算法采用聚類誤差平方和作為聚類準則判斷算法是否收斂。新聚類準則函數值需要更多計算時間,因此當迭代次數相同時,DP_K-medoids算法的運行時間更快。密度峰值聚類算法在13個UCI數據集上的聚類時間是6種聚類算法中最短的,與3.3節的算法分析結果一致。密度峰值聚類算法聚類時間最短的原因是:密度峰值聚類算法的樣本分配策略是一步分配,使其時間消耗最少。
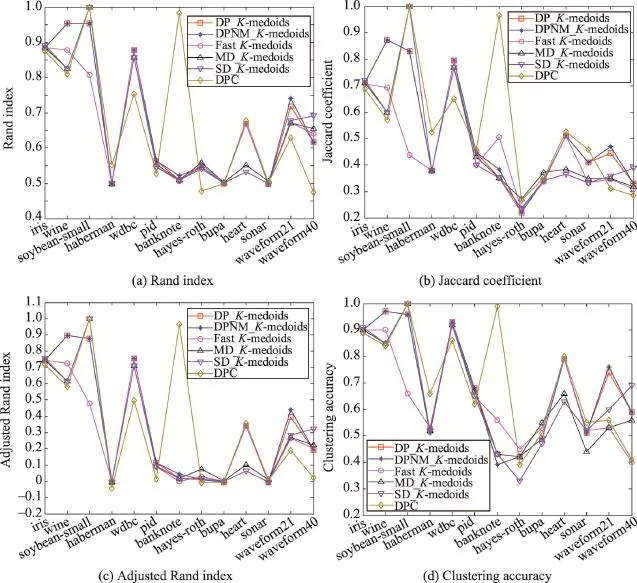
Fig.2 Rand index,Jaccard coefficient,Adjusted Rand index and clustering accuracy of six algorithms on UCI datasets圖2 6種算法在UCI數據集上的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率
從圖2可以看出,本文DP_K-medoids和DPNM_K-medoids聚類算法在soybean-small數據集的4個聚類有效性指標Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率均不如方差優化初始聚類中心的K-medoids算法和密度峰值聚類算法,但是優于快速K-medoids算法。圖2顯示,密度峰值聚類算法在banknote數據集的4個聚類有效性指標均值高于其余5種K-medoids算法,原因是,5種K-medoids算法對該數據集初始聚類中心確定后,均根據距離最近原則,將數據劃分為上下分布的兩個類簇;而密度峰值聚類算法根據密度較大最近鄰樣本所在類簇將數據劃分為左右分布的兩個類簇,符合banknote數據集的真實類簇分布。從圖2還可以看出,密度峰值聚類算法在數據集haberman的Rand指數、Jaccard系數和聚類準確率高于其余5種K-medoids算法,Adjusted Rand index稍低于其余算法。圖2還顯示,SD_K-medoids在waveform40數據集的4個聚類有效性指標均優于其余算法,而密度峰值聚類算法在該數據集的各項指標值最差。從圖2(a)可見,本文提出的兩種K-medoids算法在其他10個數據集的聚類有效性指標都優于其他3種K-medoids算法。圖2(b)顯示,本文K-medoids算法在8個UCI數據集的聚類有效性指標Jaccard系數值優于其他3種K-medoids算法;快速K-medoids算法在banknote數據集的聚類有效性指標Jaccard系數最好,方差優化初始聚類中心的MD_K-medoids算法在hayes-roth和bupa數據集的Jaccard系數聚類指標最優。圖2(c)關于各算法聚類結果的Adjusted Rand index參數比較揭示,本文算法在10/13個數據集的聚類性能最好,方差優化初始聚類中心的MD_K-medoids算法在hayes-roth數據集的聚類效果最好。圖2(d)的聚類準確率比較揭示,本文算法在8/13個數據集的聚類準確率高于其他3種K-medoids算法,快速K-medoids算法在hayes-roth數據集聚類準確率最高,方差優化初始聚類中心的K-medoids算法在bupa和soybean-small數據集聚類準確率最高。
綜合以上分析可知,本文提出的DP_K-medoids和DPNM_K-medoids算法能在較短時間內實現對數據集的有效聚類,各項聚類有效性指標比較揭示本文兩種K-medoids算法整體性能更優。
4.2人工數據集實驗結果與分析
本實驗分為兩部分,分別測試本文提出的兩種K-medoids算法的魯棒性,以及其對經典人工數據集的聚類性能。
4.2.1本文K-medoids算法魯棒性測試實驗
為測試本文算法的魯棒性,隨機生成分別含有0%、5%、10%、15%、20%、25%、30%、35%、40%、45%不同比例噪音的人工模擬數據集。每一組數據集含有4個類簇,每一類簇有100個二維樣本,這些樣本符合正態分布。其中第i類簇的均值為 μi,協方差矩陣為σi,在第一類簇加入噪音數據,噪音數據的協方差矩陣為σn,數據集的生成參數如表4所示。第一類簇分布在數據集的中間,在中間類簇加入噪音數據,使其與周圍3個類簇的樣本都有部分交疊,以更好地測試本文算法的魯棒性。

Table 4 Parameters to generate synthetic datasets表4 人工模擬數據集的生成參數
在10組含有不同比例噪音的人工模擬數據集上分別運行本文DP_K-medoids和DPNM_K-medoids算法、快速K-medoids算法、MD_K-medoids算法和SD_K-medoids算法以及密度峰值聚類算法。每個算法各運行10次,實驗結果為10次運行的平均值。表5為6種算法在各數據集選擇的初始聚類中心,表6為6種算法的迭代次數和聚類時間,圖3為6種算法對各數據集聚類結果的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率比較。
從表5中可以看出,本文算法對該10組含噪人工模擬數據集確定的類簇數與數據集真實類簇數一致,且針對各數據集選擇的初始聚類中心分布在不同類簇。對該10組含不同比例噪音的人工模擬數據集,MD_K-medoids算法選擇的初始聚類中心均位于不同類簇,快速K-medoids算法選擇的初始聚類中心存在位于同一類簇的現象,SD_K-medoids算法在噪音比例為20%和25%的人工模擬數據集上選擇的初始聚類中心存在兩個中心位于同一類簇的現象,密度峰值聚類算法在噪音比例為30%時存在兩個類簇中心位于同一類簇的現象。因此,快速K-medoids算法在該10組含噪音人工模擬數據集上選擇的初始聚類中心是5種K-medoids算法中最差的,本文K-medoids算法選擇的初始聚類中心最優,MD_K-medoids算法和SD_K-medoids算法以及密度峰值聚類算法居中。
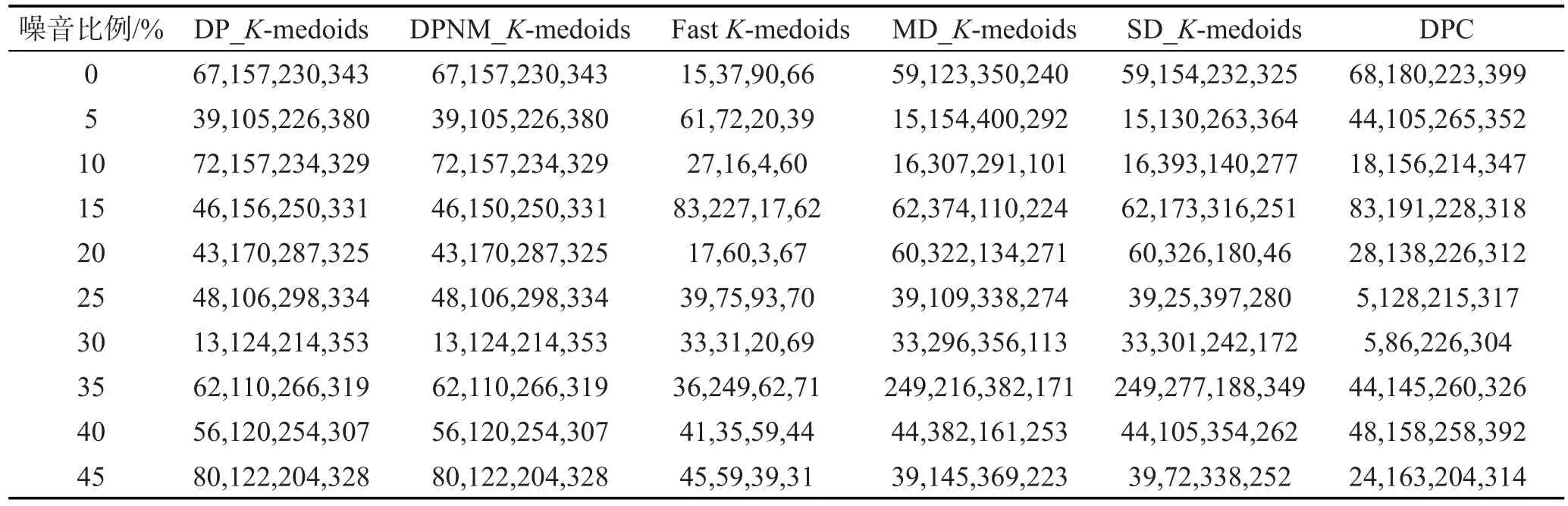
Table 5 Initial seeds selected by six algorithms on synthetic datasets with noises表5 6種算法在帶噪音人工模擬數據集上選擇的初始聚類中心
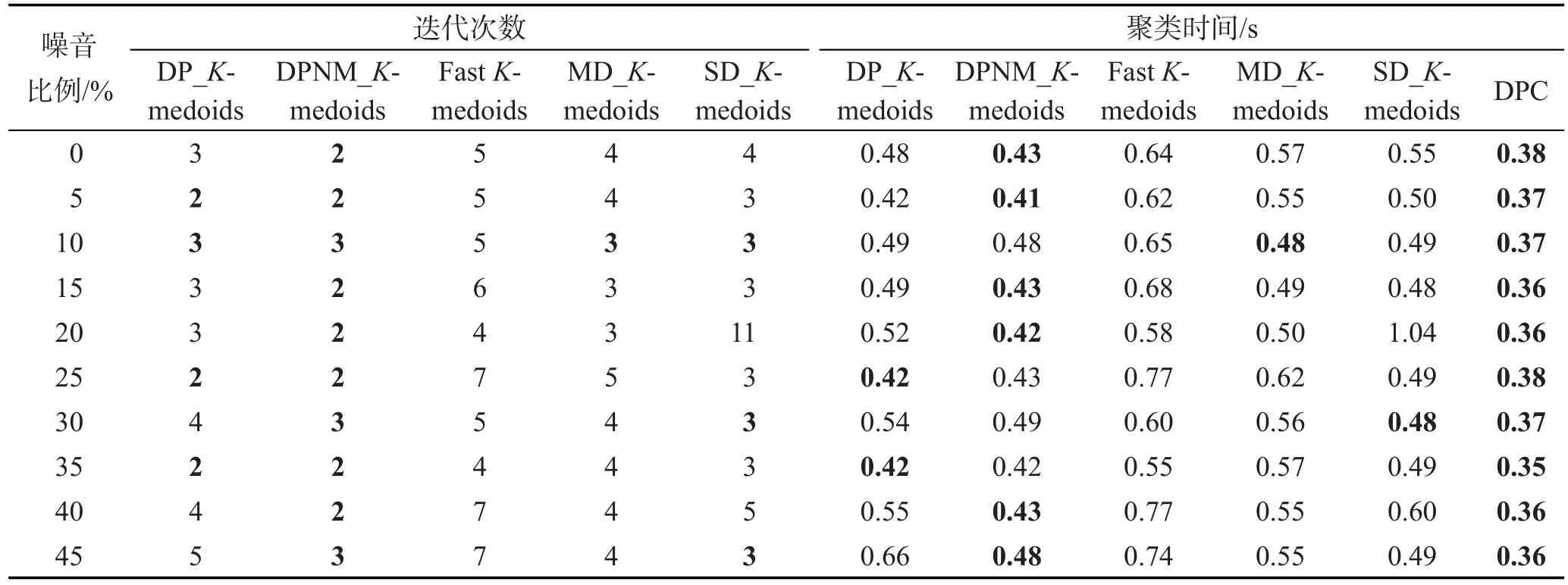
Table 6 Iterations and clustering time of six algorithms on synthetic datasets with noises表6 帶噪音人工模擬數據集上6種算法的迭代次數和聚類時間
從表6中可以看出,本文DPNM_K-medoids算法在各噪音數據集的迭代次數最少。從聚類時間來看,本文兩種K-medoids算法優于其他3種K-medoids算法。本文兩種K-medoids算法相比,在迭代次數相同的情況下,DP_K-medoids算法聚類時間更短,因為DPNM_K-medoids算法的聚類準則函數計算更費時間。密度峰值聚類算法在帶噪音人工模擬數據集上的聚類時間是6種算法中最短的,因為密度峰值聚類算法的一步分配策略使其時間消耗最低。
從圖3的實驗結果可以看出,本文K-medoids算法在含噪音的數據集上明顯優于其他4種聚類算法。本文DPNM_K-medoids算法在含有40%噪音的人工模擬數據集上的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率均優于其他5種聚類算法。密度峰值聚類算法在不帶噪音的人工模擬數據集的各項聚類指標最優,在噪音比例為20%、25%、35%和45%的人工模擬數據集的各項指標值最差。由此可見,本文新提出的聚類準則使得基于密度峰值點優化初始聚類中心的K-medoids算法的聚類性能更優,具有更強的魯棒性。
綜合表5、表6和圖3的實驗結果分析可知,本文采用密度峰值點優化初始聚類中心的K-medoids算法對噪音具有很好的魯棒性,能發現數據集的真實類簇數和合理初始類簇中心,實現有效聚類。
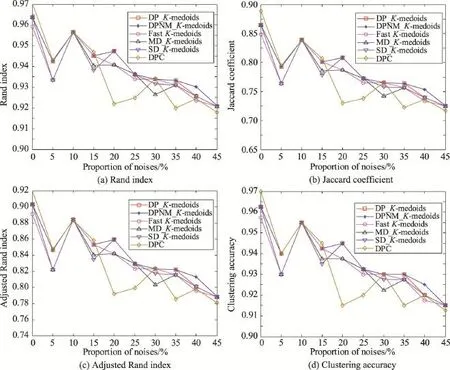
Fig.3 Rand index,Jaccard coefficient,Adjusted Rand index and clustering accuracy of six algorithms on synthetic datasets with different ratio noises圖3 6種算法在不同比例噪音人工模擬數據集上的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率
4.2.2經典人工模擬數據集實驗結果分析
本小節采用測試聚類算法性能的經典人工模擬數據集對本文提出的密度峰值優化初始聚類中心的K-medoids算法的聚類性能進行測試。實驗使用的經典人工模擬數據集原始分布如圖4所示。該經典人工模擬數據集的共同點是:類簇個數較多,類簇形狀任意。其中S1、S2、S3和S4數據集均各含有5 000個樣本,15個類簇,數據集樣本重疊程度依次增加[19]。R15數據集也含有15個類簇,樣本數為600[20],D31數據集含有31個類簇,樣本數為3 100[20]。
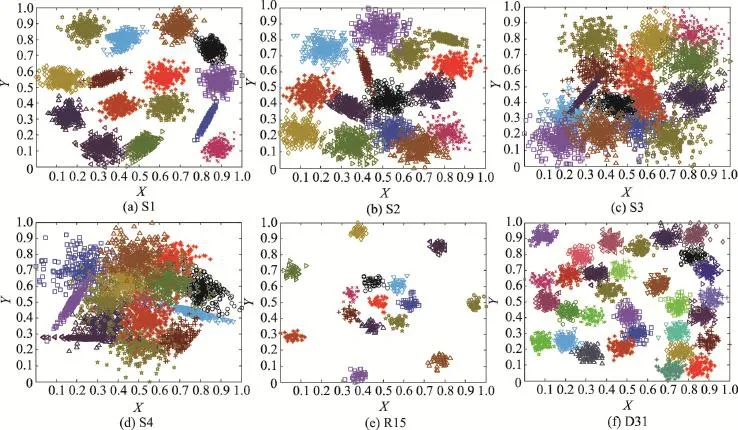
Fig.4 Original distribution of classic synthetic datasets圖4 經典人工模擬數據集的原始分布
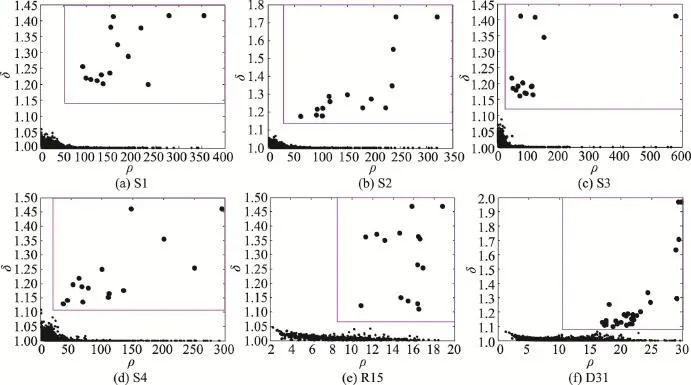
Fig.5 Decision graphs and initial seeds of two K-medoids algorithms on classic synthetic datasets圖5 兩種K-medoids算法對經典人工模擬數據集的決策圖和初始聚類中心
在這些經典人工模擬數據集上分別運行5種K-medoids聚類算法和密度峰值聚類算法,其中本文兩種K-medoids算法的最近鄰樣本數t取8。本文K-medoids算法確定初始聚類中心的決策圖如圖5所示,其中矩形框內的加粗黑圓點為初始類簇中心。MD_K-medoids算法在S1和R15數據集僅能確定出4個初始聚類中心,在S2、S3、S4和D31數據集僅能確定出5個初始聚類中心。SD_K-medoids算法在R15數據集僅能確定出4個初始聚類中心,在S1、S2、S3和D31數據集僅能確定出5個初始聚類中心,在S4數據集能確定出6個初始聚類中心。原因是:當被選為初始聚類中心的樣本鄰域半徑過大時,使得該樣本鄰域內包含的樣本數過多,導致剩余樣本集合為空,因而無法確定足夠的初始聚類中心。因此,下面將僅比較本文DP_K-medoids、DPNM_K-medoids算法、快速K-medoids算法和密度峰值聚類算法在經典人工模擬數據集上的聚類結果。4種聚類算法在S1、S2、S3、S4數據集的聚類結果分別如圖6、圖7、圖8和圖9所示。4種聚類算法在R15、D31數據集上的聚類結果分別如圖10和圖11所示。4種聚類算法在經典人工模擬數據集聚類結果的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率比較如圖12所示。
從圖5的實驗結果可以看出,本文兩種K-medoids算法在經典人工模擬數據集上識別的類簇個數與對應數據集的真實類簇數完全一致,而且決策圖中的密度峰值點和非密度峰值點可以清晰分離,因此當類簇個數較多時,采用本文新定義的樣本局部密度ρ和樣本距離δ能準確選擇密度峰值點,從而準確地確定初始聚類中心。因此,本文兩種K-medoids算法在經典人工模擬數據集上能克服快速K-medoids、MD_K-medoids和SD_K-medoids算法需要人為給定初始類簇數,以及MD_K-medoids和SD_K-medoids算法當類簇個數較多時不能完全確定初始聚類中心的缺陷。
從圖6至圖9的實驗結果可以看出,本文兩種K-medoids算法和密度峰值聚類算法在S1和S2數據集的聚類結果和原始分布幾乎一樣,只將個別邊界樣本錯分。本文兩種K-medoids算法和密度峰值聚類算法會將S3和S4數據集中重疊區域的樣本誤分,非重疊區域樣本能夠實現正確分類。快速K-medoids算法對S1、S2、S3和S4數據集不僅將重疊區域樣本分錯,而且將原本屬于兩個類簇但是距離較近的樣本聚為一類,同時還將一個類簇誤分為兩個類簇。由此可見,本文兩種K-medoids算法和密度峰值聚類算法對S1、S2、S3和S4數據集的聚類效果優于快速K-medoids算法。
從圖10和圖11實驗結果可知,本文K-medoids算法和密度峰值聚類算法能將R15數據集完全正確分類,將D31數據集個別重疊樣本誤分。快速K-medoids算法將R15數據集最中間一個類簇分為兩類;將D31數據集最中間那個類簇分為3類,同時快速K-medoids算法將D31數據集原本屬于多個類簇,但是距離較近的樣本聚為一個類簇。因此,本文DP_K-medoids和DPNM_K-medoids算法與密度峰值聚類算法對經典人工數據集R15和D31的聚類效果遠優于快速K-medoids算法對該兩數據集的聚類效果。
從圖12實驗結果可以看出,本文DP_K-meoids和DPNM_K-medoids算法以及密度峰值聚類算法對S1、S2、S3、R15和D31數據集聚類結果的各項聚類有效性指標值均比快速K-medoids算法的相應指標值高很多,說明本文新提出的密度峰值選取初始聚類中心的K-medoids聚類方法能獲得非常好的聚類結果。本文兩種K-medoids算法、快速K-medoids算法和密度峰值聚類算法在S4數據集的各項聚類有效性指標值幾乎相等,原因是S4數據集各類簇間樣本重疊度非常高,各類簇間樣本不易區分,這也是本文DP_K-meoids、DPNM_K-medoids算法和密度峰值聚類算法在S4數據集各項聚類有效性指標值偏低的原因。
綜合圖5~圖12的實驗結果分析可知,本文提出的密度峰值優化初始聚類中心的DP_K-medoids和DPNM_K-medoids算法以及密度峰值聚類算法能準確識別S1~S4、R15和D31這些經典人工模擬數據集的類簇數和合理初始聚類中心,并對這些數據集實現有效聚類。
5 結束語
本文提出了采用密度峰值優化初始聚類中心的K-medoids算法,采用樣本t近鄰距離之和的倒數度量樣本局部密度,并定義了新的樣本距離,構造樣本距離相對于樣本密度的決策圖,選擇決策圖中局部密度較高且距離相對較遠的樣本作為初始聚類中心,自適應地識別數據集的類簇數和合理初始類簇中心,并提出新的聚類準則函數。UCI數據集實驗結果揭示,本文提出的兩種K-medoids聚類算法DP_K-medoids和DPNM_K-medoids在UCI真實數據集的各項聚類有效性指標優于快速K-medoids算法、MD_K-medoids算法、SD_K-medoids算法以及密度峰值聚類算法。人工模擬數據集實驗結果揭示,本文兩種K-medoids算法能準確發現數據集的真實類簇數和合理初始類簇中心,實現有效聚類,有效減少聚類迭代次數,縮短聚類時間,加快算法收斂速度,并對噪音有很好的魯棒性。
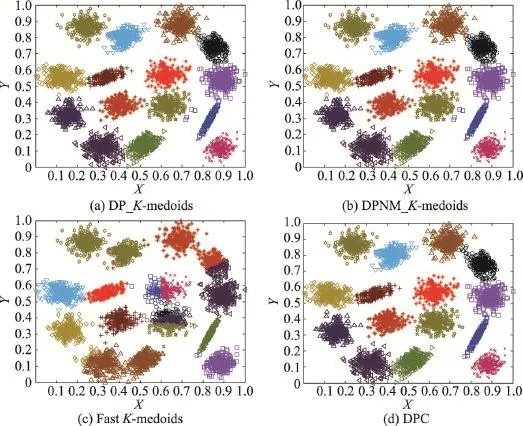
Fig.6 Clustering results of four algorithms on S1圖6 4種算法在S1數據集上的聚類結果
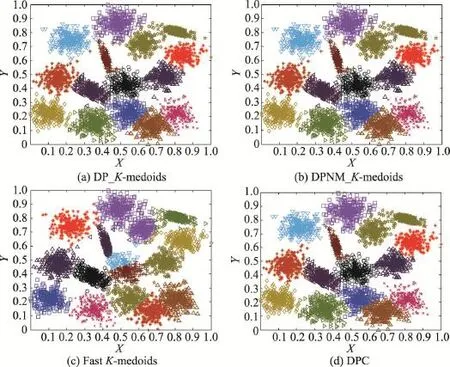
Fig.7 Clustering results of four algorithms on S2圖7 4種算法在S2數據集上的聚類結果
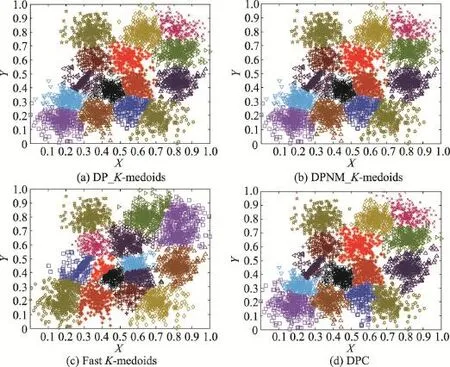
Fig.8 Clustering results of four algorithms on S3圖8 4種算法在S3數據集上的聚類結果
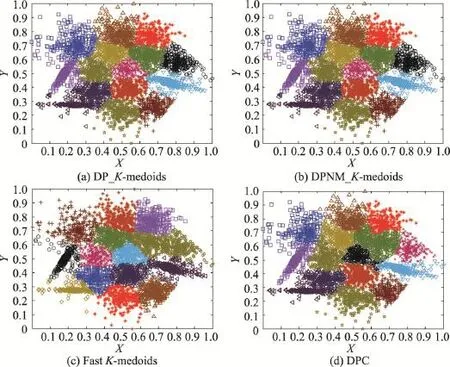
Fig.9 Clustering results of four algorithms on S4圖9 4種算法在S4數據集上的聚類結果
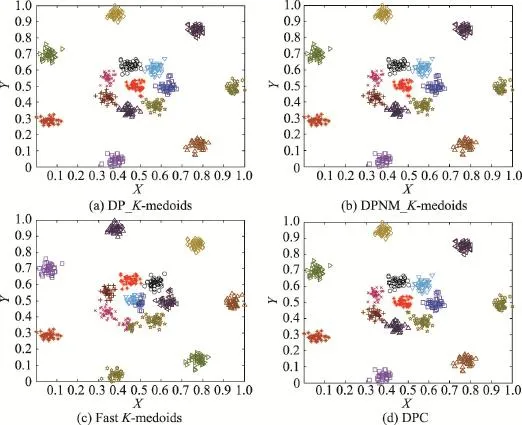
Fig.10 Clustering results of four algorithms on R15圖10 4種算法在R15數據集上的聚類結果
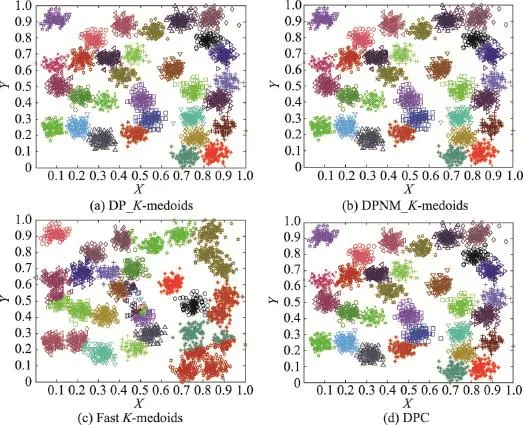
Fig.11 Clustering results of four algorithms on D31圖11 4種算法在D31數據集上的聚類結果
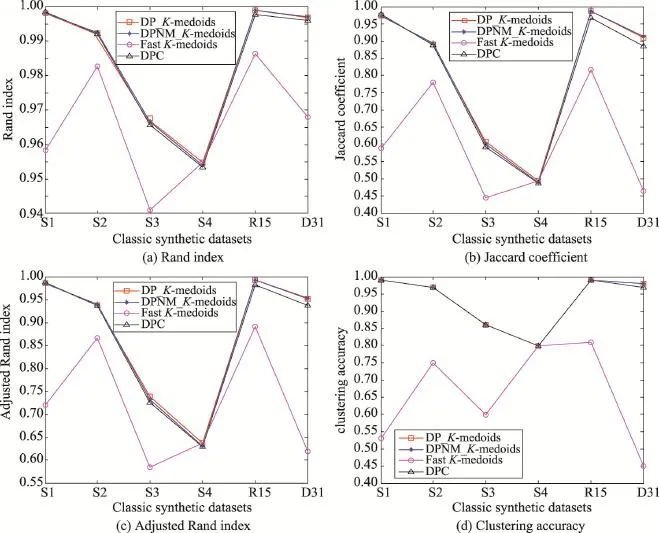
Fig.12 Rand index,Jaccard coefficient,Adjusted Rand index and clustering accuracy of four algorithms on classic synthetic datasets圖12 4種算法在經典人工模擬數據集上的Rand指數、Jaccard系數、Adjusted Rand index參數和聚類準確率
References:
[1]Han Jiawei,Kamber M,Pei Jian.Data mining concepts and techniques[M].Beijing:China Machine Press,2012:398-400.
[2]MacQueen J.Some methods for classification and analysis of multivariate observation[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley,Jun 21-Jul 18,1965.Berkeley,USA:University of California Press,1967:281-297.
[3]Kaufman L,Rousseeuw P J.Finding groups in data:an introduction to cluster analysis[M].New York,USA:John Wiley&Sons,1990:126-163.
[4]Theodoridis S,Koutroumbas K.Pattern recognition[M].Boston,USA:Academic Press,2009:745-748.
[5]Park H S,Jun C H.A simple and fast algorithm for k-medoids clustering[J].Expert Systems with Applications,2009,36 (2):3336-3341.
[6]Xie Juanying,Guo Wenjuan,Xie Weixin,et al.Aneighborhoodbased K-medoids clustering algorithm[J].Journal of Shaanxi Normal University:Natural Science Edition,2012,40(4): 1672-4291.
[7]Ma Qing,Xie Juanying.New K-medoids clustering algorithm based on granular computing[J].Journal of Computer Applications,2012,32(7):1973-1977.
[8]Pan Chu,Luo Ke.Improved K-medoids clustering algorithm based on improved granular computing[J].Journal of Com-puterApplications,2014,34(7):1997-2000.
[9]Xie Juanying,Lu Xiaoxiao,Qu Yanan,et al.K-medoids clustering algorithms with optimized initial seeds by granular computing[J].Journal of Frontiers of Computer Science and Technology,2015,9(5):611-620.
[10]Xie Juanying,Gao Rui.K-medoids clustering algorithms with optimized initial seeds by variance[J].Journal of Frontiers of Computer Science and Technology,2015,9(8):973-984.
[11]Rodriguez A,Laio A.Clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[12]Rand W M.Objective criteria for the evaluation of clustering methods[J].Journal of the American Statistical Association, 1971,66(336):846-850.
[13]Zhang Weijiao,Liu Chunhuang,Li Fangyu.Method of quality evaluation for clustering[J].Computer Engineering,2005, 31(20):10-12.
[14]Yu Jian,Cheng Qiansheng.The search scope of optimal cluster number in the fuzzy clustering method[J].Science in China:Series E,2002,32(2):274-280.
[15]Yang Yan,Jin Fan,Kamel M.Survey of clustering validity evaluation[J].Application Research of Computers,2008,25 (6):1631-1632.
[16]Hubert L,Arabie P.Comparing partitions[J].Journal of Classification,1985,2(1):193-218.
[17]Vinh N X,Epps J,Bailey J.Information theoretic measures for clustering comparison:is a correction for chance necessary?[C]//Proceedings of the 26thAnnual International Conference on Machine Learning,Montreal,Canada,Jun 14-18,2009.New York,USA:ACM,2009:1073-1080.
[18]Frank A,Asuncion A.UCI machine learning repository[EB/ OL].Irvine,USA:University of California,School of Information and Computer Science(2010)[2015-03-19].http:// archive.ics.uci.edu/ml.
[19]Franti P,Virmajoki O.Iterative shrinking method for clustering problems[J].The Journal of the Pattern Recognition Society,2006,39(5):761-765.
[20]Veenman C J,Reinders M J T,Backer E.A maximum variance cluster algorithm[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,2002,24(9):1273-1280.
附中文參考文獻:
[6]謝娟英,郭文娟,謝維信.基于鄰域的K中心點聚類算法[J].陜西師范大學學報:自然科學版,2012,40(4):1672-4291.
[7]馬箐,謝娟英.基于粒計算的K-medoids聚類算法[J].計算機應用,2012,32(7):1973-1977.
[8]潘楚,羅可.基于改進粒計算的K-medoids聚類算法[J].計算機應用,2014,34(7):1997-2000.
[9]謝娟英,魯肖肖,屈亞楠,等.粒計算優化初始聚類中心的K-medoids聚類算法[J].計算機科學與探索,2015,9(5): 611-620.
[10]謝娟英,高瑞.方差優化初始中心的K-medoids聚類算法[J].計算機科學與探索,2015,9(8):973-984.
[13]張惟皎,劉春煌,李芳玉.聚類質量的評價方法[J].計算機工程,2005,31(20):10-12.
[14]于劍,程乾生.模糊聚類方法中的最佳聚類數的搜索范圍[J].中國科學:E輯,2002,32(2):274-280.
[15]楊燕,靳蕃,Kamel M.聚類有效性評價綜述[J].計算機應用研究,2008,25(6):1631-1632.

XIE Juanying was born in 1971.She is an associate professor at School of Computer Science,Shaanxi Normal University,and the senior member of CCF.Her research interests include machine learning and data mining.
謝娟英(1971—),女,陜西西安人,博士,陜西師范大學計算機科學學院副教授,CCF高級會員,主要研究領域為機器學習,數據挖掘。

QU Yanan was born in 1991.She is an M.S.candidate at School of Computer Science,Shaanxi Normal University. Her research interest is data mining.
屈亞楠(1991—),女,陜西渭南人,陜西師范大學計算機科學學院碩士研究生,主要研究領域為數據挖掘。
K-medoids ClusteringAlgorithms with Optimized Initial Seeds by Density Peaks*
XIE Juanying+,QU Yanan
School of Computer Science,Shaanxi Normal University,Xi’an 710062,China
+Corresponding author:E-mail:xiejuany@snnu.edu.cn
XIE Juanying,QU Yanan.K-medoids clustering algorithms with optimized initial seeds by density peaks. Journal of Frontiers of Computer Science and Technology,2016,10(2):230-247.
To overcome the deficiencies of the fast K-medoids and the variance based K-medoids clustering algorithms whose number of clusters of a dataset must be provided manually and their initial seeds may locate in a same cluster or cannot be totally found etc.Stimulated by the density peak clustering algorithm,this paper proposes two new K-medoids clustering algorithms.The new algorithms define the local densityρiof pointxias the reciprocal of the sum of the distance betweenxiand itstnearest neighbors,and new distanceδiof pointxiis defined as well,then the decision graph of a point distance relative to its local density is plotted.The points with higher local density and apart from each other located at the upper right corner of the decision graph,which are far away from the rest points in the same dataset,are chosen as the initial seeds for K-medoids,so that the seeds will be in different clusters and the number of clusters of the dataset is automatically determined as the number of initial seeds.In order to get a better clustering,a new measure function is proposed as the ratio of the intra-distance of clusters to the interdistance between clusters.The proposed two new K-medoids algorithms are tested on the real datasets from UCI machine learning repository and on the synthetic datasets.The clustering results of the proposed algorithms are evaluated in terms of the initial seeds selected,iterations,clustering time,Rand index,Jaccard coefficient,Adjusted Randindex and the clustering accuracy.The experimental results demonstrate that the proposed new K-medoids clustering algorithms can recognize the number of clusters of a dataset,find its proper initial seeds,reduce the clustering iterations and the clustering time,improve the clustering accuracy,and are robust to noises as well.
2015-05,Accepted 2015-07.
clustering;K-medoids algorithm;initial seeds;density peak;measure function
10.3778/j.issn.1673-9418.1506072
*The National Natural Science Foundation of China under Grant No.31372250(國家自然科學基金);the Key Science and Technology Program of Shaanxi Province under Grant No.2013K12-03-24(陜西省科技攻關項目);the Fundamental Research Funds for the Central Universities of China under Grant No.GK201503067(中央高校基本科研業務費專項資金).
CNKI網絡優先出版:2015-07-14,http://www.cnki.net/kcms/detail/11.5602.TP.20150714.1609.002.html
A
TP181.1
