眾包在國內(nèi)古籍?dāng)?shù)據(jù)庫建設(shè)中的應(yīng)用研究
2016-11-18 03:44:03顏運梅
圖書館研究 2016年5期
顏運梅
(廣州圖書館,廣東廣州510623)
眾包在國內(nèi)古籍?dāng)?shù)據(jù)庫建設(shè)中的應(yīng)用研究
顏運梅
(廣州圖書館,廣東廣州510623)
元數(shù)據(jù)眾包和文本建設(shè)眾包是國外圖書館界眾包項目的主要模式。以國內(nèi)CADAL數(shù)據(jù)庫和《廣州大典》數(shù)據(jù)庫為例,闡述了元數(shù)據(jù)眾包和文本建設(shè)兩種眾包模式在國內(nèi)古籍?dāng)?shù)據(jù)庫中的應(yīng)用,提出這兩種模式存在的問題,并結(jié)合《廣州大典》數(shù)據(jù)庫的文本建設(shè)的眾包功能,提出優(yōu)化改進措施。
眾包;CADAL;廣州大典;文本建設(shè)
1 資源的使用者與創(chuàng)造者
在知識創(chuàng)新時代,圖書館的用戶,既是資源的使用者,也是資源的創(chuàng)造者。圖書館的未來定位,不僅僅是存儲知識的機構(gòu),還應(yīng)當(dāng)成為促進知識創(chuàng)新、幫助創(chuàng)造知識的主體,積極鼓勵用戶參與知識的生產(chǎn)與創(chuàng)新。
澳大利亞國家圖書館在《2015-2019年規(guī)劃》中明確提出將“促使和參與知識的創(chuàng)造”,在規(guī)劃期內(nèi)將通過第三方服務(wù)如Flickr平臺增加數(shù)字內(nèi)容,繼續(xù)豐富Trove的資源[1]。
眾包這一概念由杰夫·豪(Jeff Howe)于2006年6月《連線雜志》首次提出后[2],國外圖書館界已將眾包模式大量地引入圖書館建設(shè)中,并通過實踐發(fā)現(xiàn),眾包可以提升資源的使用率、豐富資源,減輕圖書館的人力負擔(dān),擴大共建共享的邊際,同時提高資源的可發(fā)現(xiàn)性。眾包因此成為國外圖書館鼓勵用戶參與知識共建共享的主要模式。國內(nèi)圖書館界對眾包的研究頗多,但實際應(yīng)用并不多,尤其是在古籍?dāng)?shù)據(jù)庫的建設(shè)方面。
2 眾包在國內(nèi)古籍?dāng)?shù)據(jù)庫中的應(yīng)用情況
自上個世紀80年代以來,古籍?dāng)?shù)據(jù)庫建設(shè)經(jīng)歷了30年的發(fā)展,成績斐然,據(jù)2010年統(tǒng)計,古籍?dāng)?shù)據(jù)庫數(shù)量就達到580余種[3]。國內(nèi)大型的古籍?dāng)?shù)據(jù)庫大部分由于建設(shè)較早,用戶參與程度低。古籍?dāng)?shù)字化產(chǎn)品提供商和用戶、用戶與用戶之間交流的渠道少。
數(shù)字技術(shù)、社交媒體的快速發(fā)展使得古籍?dāng)?shù)據(jù)庫的一些功能得到拓展,古籍閱讀作為古籍全文數(shù)據(jù)庫的核心功能不再那么重要,用戶更注重與其他用戶就古籍相關(guān)內(nèi)容進行交流和學(xué)習(xí)等功能,古籍研究者更注重在線古籍研究的功能。交互設(shè)計,成為古籍服務(wù)平臺新的重要建設(shè)理念。近幾年建成使用的國內(nèi)古籍?dāng)?shù)據(jù)庫也相應(yīng)地增加了用戶互動和參與的功能,增設(shè)了交互模塊、共建模塊,提高了用戶參與的積極性,提升了資源的使用率。這些模塊包含糾錯、論壇、書評和社交。如國內(nèi)大型的CADAL平臺有專門的網(wǎng)絡(luò)用戶社區(qū),用戶可以根據(jù)喜好建立群組,在群組里討論、寫書評、聊天等[4]。
國內(nèi)的古籍?dāng)?shù)據(jù)庫中除了這些交互和開放功能,采用眾包模式建設(shè)的古籍?dāng)?shù)據(jù)庫還比較少。據(jù)筆者調(diào)研,CADAL古籍?dāng)?shù)據(jù)庫的元數(shù)據(jù)眾包模式較為成熟,2015年底上線的《廣州大典》影像全文數(shù)據(jù)庫平臺也開發(fā)了文本建設(shè)的眾包,這兩者的模式較有代表性,本文以這兩個數(shù)據(jù)庫為例,討論國內(nèi)古籍?dāng)?shù)據(jù)庫的眾包模式。
3 CADAL古籍?dāng)?shù)據(jù)庫圖書元數(shù)據(jù)的眾包
大學(xué)數(shù)字圖書館國際合作計劃(China Academic Digital Associative Library,簡稱為CADAL)數(shù)據(jù)庫中的古籍和民國期刊的元數(shù)據(jù)建設(shè)采取了眾包的模式。用戶在平臺注冊、登錄之后,即可參與元數(shù)據(jù)的眾包,CADAL眾包功能包括三個方面。
3.1 確定電子書元數(shù)據(jù)的質(zhì)量
在古籍電子書的元數(shù)據(jù)頁面有個評價功能,用戶可以對這些圖書的元數(shù)據(jù)質(zhì)量進行評價,評價共分為四個等級,包括:很好,較好,較差、很差。用戶對同一本電子書只能提交一次選項,不能重復(fù)提交。
3.2 修改圖書元數(shù)據(jù)信息
用戶可以在古籍電子圖書的詳情頁面對圖書的信息作修改。對圖書的元數(shù)據(jù),如出版社、出版日期、關(guān)鍵字等信息進行編輯,在此頁面上還可以查看某個字段的編輯歷史。
3.3 補充電子期刊的元數(shù)據(jù)
某些民國電子期刊的元數(shù)據(jù),可能缺乏期刊名稱、出版社、關(guān)鍵詞等信息,用戶可以在這些期刊的詳細頁面新增、修改這些元數(shù)據(jù)。同時某種期刊可能包含多種刊物內(nèi)容,用戶也可以協(xié)助找出每一種刊物所對應(yīng)的起始頁。
3.4 CADAL的獎懲制度
為了吸引用戶積極參與眾包功能,CADAL數(shù)據(jù)庫采用了一些獎懲制度,包括積分、閱讀扣分規(guī)則,詳見表1。平臺根據(jù)用戶貢獻的程度,獎勵讀者獲得限量圖書的全球訪問,無需受到所在學(xué)校IP的限制。這種利用特色資源吸引用戶參與眾包的方式具有一定的吸引力。同時扣分規(guī)則可以有效地遏制一些用戶的惡意編輯數(shù)據(jù),降低網(wǎng)站管理者在后臺的審核成本。
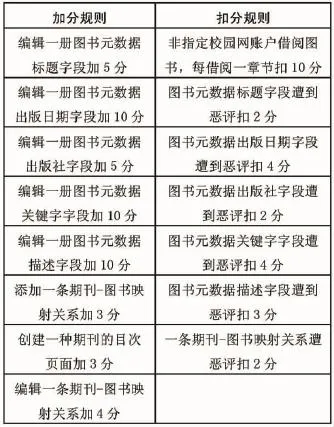
表1 CADAL的獎懲規(guī)則
4 《廣州大典》影像數(shù)據(jù)庫文本的眾包
4.1 數(shù)據(jù)庫介紹
《廣州大典》影像數(shù)據(jù)庫是廣州市重要的歷史文獻全文數(shù)據(jù)庫,是由中共廣州市委宣傳部、廣東省文化廳策劃并組織研究編纂的大型地方文獻叢書,大體依經(jīng)、史、子、集、叢五部分類,收錄廣州人士(含寓賢)著述、有關(guān)廣州歷史文化的著述及廣州版叢書。所收文獻下限為1911年,個別門類延至民國。《廣州大典》收錄4 064種文獻,編成520冊。珍本、善本等稀見文獻眾多,收有稿抄本462種,清乾隆以前刻本357種[5]。《廣州大典》根據(jù)古籍原文影印出版。數(shù)據(jù)庫是根據(jù)原版影像建成、基于PDF格式的影像全文數(shù)據(jù)庫。這種古籍影像數(shù)據(jù)庫,用戶無法進行全文搜索,目前僅僅能通過古籍的題名、著者、版本項進行搜索,使用不便,資源無法被深入挖掘與發(fā)現(xiàn),無法滿足學(xué)術(shù)研究群體的高層次需求,僅能滿足一般程度的閱讀與使用推廣。提供《廣州大典》全文文本數(shù)據(jù)和實現(xiàn)全文搜索是數(shù)據(jù)庫建設(shè)的二期任務(wù)。目前數(shù)據(jù)庫平臺開發(fā)試用的文本眾包功能,為二期文本建設(shè)提供了基礎(chǔ)。
《廣州大典》文本建設(shè)的眾包模式,包括對文本進行錄入和糾錯兩個重要的功能模塊。錄入指網(wǎng)絡(luò)志愿者利用人工手段,錄入《廣州大典》影像的文本,文本糾錯指志愿者可以對其他用戶錄入的文本或通過OCR識別的文本進行審校和糾誤(糾錯功能暫未開通)。
4.2 眾包的流程
4.2.1 注冊登錄
用戶要參與《廣州大典》的文本眾包,必須先注冊成為廣州數(shù)字圖書館的用戶或者訪客。《廣州大典》數(shù)據(jù)庫由廣州圖書館建設(shè),主要面向廣州市的用戶開放。非廣州市的用戶,只需要在廣州數(shù)字圖書館平臺上注冊成為訪客身份即可參與眾包。
4.2.2 領(lǐng)取任務(wù)
《廣州大典》全文頁面的右上角有“未加工頁”下拉菜單,注冊用戶在此選取未被錄入或者未被領(lǐng)取錄入的任務(wù)頁碼。用戶選擇頁碼后,頁面直接跳轉(zhuǎn)鏈接到相對應(yīng)頁面,在“文本建設(shè)”框即可錄入文字。
4.2.3 加工提交
在文本加工頁面有說明文字提醒用戶:在錄入文本時必須忠實于原文,不必糾正原文錯誤;對于無法輸入的文字或符號,使用X代替;以原文語種(漢語繁體)加工文本。錄入完畢可點擊提交按鈕,數(shù)據(jù)提交到后臺,如果未錄入完畢,則可先保存留待繼續(xù)錄入。
4.2.4 后臺審核
用戶加工文字、錄入完畢提交數(shù)據(jù)到后臺,由管理員進行審核,審核反饋意見為通過、不通過。通過審核后文本內(nèi)容則可由管理員保存,同時前臺的任務(wù)頁面則不能再領(lǐng)取任務(wù)。如果審核不通過,則由管理員釋放任務(wù),在前臺可以重新被領(lǐng)取加工。
4.3 眾包的后臺管理
《廣州大典》文本眾包的后臺管理模塊包括表2中的功能:
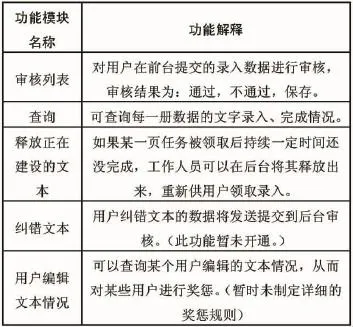
表2 眾包的后臺管理功能模塊
5 兩種不同的眾包模式
5.1 元數(shù)據(jù)的眾包與文本的眾包
國外特色數(shù)據(jù)庫建設(shè)的眾包模式較多,其中,資源的標引以及文字錄入、糾錯是其主要的兩種方式。資源標引又主要包括給資源設(shè)TAG標簽和元數(shù)據(jù)標引。
CADAL古籍?dāng)?shù)據(jù)庫和《廣州大典》數(shù)據(jù)庫的眾包模式是兩種不同的模式。CADAL古籍?dāng)?shù)據(jù)庫的眾包功能主要在于圖書的元數(shù)據(jù)標引、補充和糾錯。CADAL項目二期提出了“多維度標簽分類實踐”,標簽的生成包括其中一項是“讓用戶為文獻添加標簽”[6]。相對于《廣州大典》的全文文本錄入來說,CADAL古籍庫的眾包項目的難度和工作量都較小。《廣州大典》數(shù)據(jù)庫的元數(shù)據(jù)由《廣州大典》編輯部提供,是完整和準確無誤的,沒有必要對這方面的數(shù)據(jù)進行眾包。《廣州大典》的二期建設(shè)任務(wù)是要提供《廣州大典》的全文文本數(shù)據(jù),其前提條件是必須有古籍?dāng)?shù)據(jù)的文本內(nèi)容。如果對影像版的古籍進行OCR識別,底本、手抄本、手稿等字體較難識別,識別率較低。如果圖書館負責(zé)全部文本錄入,又將花費大量的人力。《廣州大典》建設(shè)方原計劃招聘志愿者協(xié)助完成文本錄入的工作,并給予一定的報酬。但經(jīng)過大量的調(diào)研之后,決定將數(shù)據(jù)開放在網(wǎng)站上進行文本眾包,這是國內(nèi)大型古籍?dāng)?shù)據(jù)庫對文本眾包建設(shè)模式的大膽嘗試。
5.2 眾包的效果
CADAL數(shù)據(jù)庫于2011年上線至今,以《民國匯報》為例,其目次頁面的貢獻人(次數(shù))有5人8次,說明還是有用戶關(guān)注、嘗試眾包功能。《廣州大典》數(shù)據(jù)庫的眾包參與度、效益和影響都不甚理想。2015年12月平臺正式上線,推出眾包功能至今半年多,暫未收到用戶有用的參與數(shù)據(jù)。
相較而言,CADAL眾包項目的管理體制比《廣州大典》數(shù)據(jù)庫成熟,平臺設(shè)計也更便于用戶操作,單個任務(wù)不用耗費用戶大量的時間,用戶可以隨時退出任務(wù)而不至于對任務(wù)和對其他用戶造成影響。同時制定了嚴格的獎懲制度,有效地遏制了用戶的惡意數(shù)據(jù)。而《廣州大典》數(shù)據(jù)庫的用戶在前臺領(lǐng)取了文本錄入任務(wù),如果用戶在規(guī)定時間內(nèi)沒有完成任務(wù),系統(tǒng)必須將這些任務(wù)重新釋放出來供其他用戶重新領(lǐng)取錄入。另外,也沒有制定嚴格的獎懲制度。
5.3 眾包存在的問題
5.3.1 項目工作量大,過于專業(yè)
《廣州大典》影像數(shù)據(jù)庫的用戶只需要簡單注冊后即可參與眾包。與商業(yè)性質(zhì)的眾包不同,公共圖書館由于其公益性而更易于獲得志愿者支持[7]。但是眾包的實際效果,與眾包任務(wù)本身的特性有密切關(guān)系。如Holley提出的圖書館實施眾包的六項原則,其中一項是:“眾包項目的活動應(yīng)簡單有趣”[8];李書寧與曾姍在對國外圖書館眾包項目調(diào)查后也認為:“具有無版權(quán)、工作任務(wù)簡單、單個任務(wù)耗時短、內(nèi)容有趣、數(shù)據(jù)量極大等特點的資源更適合應(yīng)用眾包理念”[9]。美國國會圖書館、大英圖書館和丹麥國家圖書館都以館藏照片作為眾包內(nèi)容,因為對普通大眾來說,圖片比文字更具吸引力。另外,澳大利亞國家圖書館和芬蘭國家圖書館報紙數(shù)字化項目,也是由于報紙內(nèi)容通俗易懂,具有吸引力。此外,國外圖書館在開展眾包項目時還注重對任務(wù)進行分解,把龐大的工作分解成細小的任務(wù),將數(shù)據(jù)庫建設(shè)分解成收集、整理、組織、描述、審校、糾錯等小任務(wù),參與者只需完成自己的一部分即可,互不干涉,隨時參與,隨時退出[10]。
國內(nèi)外圖書館眾包項目效果差異的原因在于眾包任務(wù)本身的差異性,同時也與中英文字體的差異性和文字本身的構(gòu)成有關(guān)。英文單詞,無論古今,都是由26個字母的組合,在校對錄入過程中,字體辨認的難度不大,即使有誤差,也不會錯得太離譜。手稿錄入、校對的難度也較漢字繁體字的錄入、審校容易。
漢字的古籍?dāng)?shù)字化是個慢工出細活的工作,按照程序,一般先要根據(jù)掃描書頁影像交由電腦OCR系統(tǒng)自動識別為文字,其中不少集外字、模糊字、通假字、異體字極易產(chǎn)生識別錯誤,這些問題只能靠人工進行校對更正,許多都要根據(jù)上下文意進行判斷,由錄入校對者在空缺的位置補錄上正確的文字。所以錄校人員不僅需要古漢語知識,同時也要具備一定歷史常識的儲備,而不僅僅是單純的錄入工作。
《廣州大典》一共520冊,國際大16開本,每冊約850頁,共有約44 200張書頁。眾包項目將所有書頁都放出來供用戶錄入校對,工作量過于龐大。Martin Moyle在總結(jié)倫敦大學(xué)學(xué)院J.Bentham手稿錄入項目時認為,文本加工是一項非常復(fù)雜的工作,難度不亞于、甚至超過其它眾包項目[11]。《廣州大典》數(shù)據(jù)庫文本建設(shè)如此龐大的工作量由眾包來完成,難度可想而知。
5.3.2 用戶體驗不佳
CADAL的古籍頁面因為可以針對元數(shù)據(jù)進行糾錯和補充,導(dǎo)致頁面不整潔和紊亂。在使用數(shù)據(jù)信息時,用戶體驗不佳,同時也給人不夠?qū)I(yè)的印象。《廣州大典》數(shù)據(jù)庫典籍版面是豎排,而文本錄入頁面是橫排,在“保真”還原效果上差一些。
5.3.3 數(shù)據(jù)質(zhì)量差
CADAL的元數(shù)據(jù)眾包,有可能導(dǎo)致本來是應(yīng)該比較權(quán)威的元數(shù)據(jù)被用戶改得不夠?qū)I(yè),增加了后臺審核的難度和人力。《廣州大典》的后臺收到一些用戶眾包的數(shù)據(jù),質(zhì)量低下,完全無法使用。
5.3.4 人力成本高
用戶錄入文本、提交到后臺的數(shù)據(jù),需要專業(yè)館員負責(zé)審核,如果數(shù)據(jù)質(zhì)量不佳,人力成本就會隨之增加。
6 《廣州大典》眾包的改進措施
在國內(nèi)圖書館界,眾包還是“摸著石頭過河”,在實踐中不斷地修正和改進。較之CADAL數(shù)據(jù)庫的眾包,《廣州大典》網(wǎng)絡(luò)服務(wù)平臺的眾包項目,對用戶而言更為專業(yè)和艱深,不是公共圖書館的一般用戶可以勝任的。為了避免產(chǎn)生大量無用數(shù)據(jù),平臺可以對眾包的流程做一些改動,優(yōu)化項目難度較大的工作流程,達到更加理想的狀態(tài)。
6.1 資源篩選
首先,對《廣州大典》的數(shù)據(jù)進行篩選。對一些經(jīng)典傳世之作,特別是已出版印刷、有文字版的資源進行篩選,這一部分數(shù)據(jù)不再釋放出來錄入。而目前《廣州大典》眾包的做法是將所有古籍的影像版全部釋放出來供用戶選擇進行文本錄入、內(nèi)容建設(shè),這必將造成重復(fù)建設(shè)。
6.2 優(yōu)化程序
資源去重之后,對剩下的資源,特別是識別度較高的文本先進行OCR識別,然后組織人力對其進行校對錄入。對一些難度較高、識別率低的古籍專門組織人力進行校對錄入,而不是對所有的資源率先進行文本的眾包錄入校對。
6.3 尋找合適的志愿者
古籍?dāng)?shù)字化的真實再現(xiàn),是建立在正確理解原文基礎(chǔ)上的文字轉(zhuǎn)化,這對從業(yè)人員提出了較高的要求。從業(yè)者必須是文理兼?zhèn)涞娜瞬牛纫莆沼嬎銠C技術(shù),又必須有深厚的國學(xué)功底。其中涉及的國學(xué)知識,包括古籍中異體字關(guān)聯(lián)、簡繁體關(guān)系,正體異體關(guān)系,正字訛(偽)字關(guān)系,通假被通假關(guān)系,古今字關(guān)系,新舊字形關(guān)系,形近異義字,避諱字等。如果對參與眾包的用戶資格進行審核,會提高數(shù)據(jù)的質(zhì)量,減少審核的人力成本和難度。
平臺可以對申請參與眾包的用戶進行篩選、審核。對具備一定專業(yè)水準的用戶開放權(quán)限。同時采用適當(dāng)?shù)募顧C制,對積極參與或者數(shù)據(jù)質(zhì)量較高的用戶給予一定的獎勵。《廣州大典》數(shù)據(jù)庫眾包功能目前還沒有出臺相對應(yīng)的獎懲措施。制定獎懲制度,或者是適量的現(xiàn)金獎勵模式可以吸引更多用戶參與。沒有獎勵,難以吸引穩(wěn)定、有粘性的用戶參與這項專業(yè)工作。同時設(shè)置用戶黑名單功能,如果發(fā)現(xiàn)有用戶大量提交惡意無效數(shù)據(jù),管理員可以將其加入黑名單,限制其參與眾包的功能,有效地減少無效、低質(zhì)量數(shù)據(jù)。
6.4 開發(fā)易用的平臺
建設(shè)方應(yīng)該完善眾包功能,優(yōu)化平臺的用戶體驗,促使資源的發(fā)現(xiàn)、使用、交流。平臺的操作程序要簡潔易用,不要過于復(fù)雜。在此基礎(chǔ)上,征集專家與用戶的意見,持續(xù)完善與改進眾包的功能模塊,使之更具操作性。
6.5 眾包的宣傳推廣
對眾包模式進行宣傳推廣,使圖書館界與用戶知道、了解、接受、參與這一模式。在2015年全國圖書館年會會議上,廣州圖書館對《廣州大典》影像數(shù)據(jù)庫做了專場報告,尤其對數(shù)據(jù)庫的眾包功能做了重點介紹,古籍?dāng)?shù)據(jù)庫的眾包模式已經(jīng)引起國內(nèi)圖書館的關(guān)注。
7 結(jié)束語
眾包在國內(nèi)特色數(shù)據(jù)庫中的應(yīng)用雖然已經(jīng)引起了關(guān)注,但還不普遍,也不成熟。對于項目的難度把握還不是很好。國內(nèi)圖書館可以考慮將一些非專業(yè)化且工作量不是特別大的項目眾包,讓用戶參與,吸引用戶參與建設(shè)、豐富資源。期望圖書館界的專家學(xué)者共同探討眾包在中國古籍?dāng)?shù)據(jù)庫中應(yīng)用的理論與實踐。
[1]National Library of Australia.Corporate Plan 2015-2019 [EB/OL].[2016-05-20].http://www.nla.gov.au/corporatedocuments/corporate-plan-2015-2019.
[2]SAXTON G D,OH O,KISHORE R.Rules of crowdsourcing:Models,issues and systems of control[J].Information Systems Management,2013(1):2-20.
[3]李明杰.中文古籍?dāng)?shù)字化實踐及研究[M].武漢:武漢大學(xué)出版社,2010.
[4]CADAL數(shù)據(jù)庫[EB/OL].[2016-05-20].http://www.cadal. zju.edu.cn/index.
[5]廣州大典網(wǎng)絡(luò)服務(wù)平臺[EB/OL].[2016-05-20].http:// gzdd.gzlib.gov.cn/HRCanton/.
[6]劉翔,黃晨.共享的邊界:CADLIS創(chuàng)新模式再析[J].大學(xué)圖書館學(xué)報,2014(1):41-43,40.
[7]HOLLEY R.Crowdsourcing:How and Why Should Libraries Do It[J/OL].D-Lib Magazine,2010(3/4)(16):[2016-05-07]. http://www.dlib.org/dlib/march10/holley/03holley.html.
[8]HOLLEY R.Tagging full text searchable articles:An overview of social tagging activity in historic Australian newspapers,August 2008-August 2009[J/OL].D-Lib Magazine,2010(1/2)(16):[2016-05-07].http://www.dlib.org/ dlib/january10/holley/01holley.html.
[9]李書寧,曾姍.國外圖書館數(shù)字館藏眾包建設(shè)實踐調(diào)查與分析[J].圖書情報工作,2014(12):83-90.
[10]關(guān)富英,李書寧.眾包——圖書館特色資源建設(shè)路徑新選擇[J].圖書館雜志,2015(2):58-62,93.
[11]MOYLE M.Manuscript transcription by crowdsourcing: Transcribe Bentham[J].Liber Quarterly,2011(3/4):347-356.
(編發(fā):王域鋮)
Application Research on Crowdsourcing in the Construction of Ancient Books Database in China
YAN Yun-mei
(Guangzhou Library,Guangzhou 510623,China)
Crowdsourcing metadata and text construction are two main models crowdsourcing projects in the libraries.Taking CADAL database and Guangzhou Encyclopedia Database for example,this article describes the application of the two models in domestic ancient database,puts forward existing problems and the optimization measures.
crowdsourcing;CADAL;Guangzhou Encyclopedia;text construction
G250
G250
A
2095-5197(2016)05-0030-05
顏運梅(1979-),女,副研究館員,碩士,研究方向:圖書館數(shù)字資源建設(shè)、網(wǎng)站建設(shè)。
2016-05-24
猜你喜歡
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小太陽畫報(2018年1期)2018-05-14 17:19:25
財經(jīng)(2017年2期)2017-03-10 14:35:35
少年博覽·小學(xué)低年級(2016年10期)2016-11-24 06:48:23
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
