降低數據稀疏性的多維時序序列時間戳對齊方法
2022-04-28 14:10:12李廣盛鄭建立車霞靜
智能計算機與應用 2022年4期
李廣盛,鄭建立,車霞靜
(1上海理工大學 健康科學與工程學院,上海 200093;2上海交通大學附屬仁濟醫院,上海 200127)
0 引 言
在過去的二十年中,時間序列分類(time series classification,TSC)被認為是數據挖掘中最具挑戰性的問題之一。隨著時間數據可用性的增加,自2015年以來已有數百種TSC算法被提出。由于時間序列數據的自然時序性,幾乎每一個需要某種人類認知過程的任務中都會出現時間序列數據。時間序列廣泛存在各類研究工作中,包括電子健康記錄、人類活動識別到聲學場景分類和網絡安全等領域。但由于種種原因,如收集錯誤、故意損壞、醫療事件、節省成本、設備異常等,往往會不可避免地出現丟失觀測數據和不規則采樣等現象,使得時序序列數據稀疏性大大增加,阻礙了分類任務的開展。
針對時序序列中缺失問題,從不同的解決方法來看,主要可以分為2類。一是以專家知識為基礎進行手工填補和重采樣;二是利用深度學習等方法實現端到端的數據填補及分類。前者主要利用專家知識,根據時序序列數據的觀測變量等信息進行缺失值的填補和修正,后者利用深度學習強大的抽象表征能力和擬合能力來實現數據的填補和分類[11-14]。
基于專家知識的方法盡管可解釋性較強,但是卻費時費力;而基于深度學習方法在原始數據集上直接填補盡管能夠取得不錯的效果,但是卻忽視了不規則采樣等問題。此外,數據集中可能存在部分數據缺失率過高,使得模型無法抽取其潛在信息,模型的填補效果大打折扣。本文提出一種基于數據集中自帶的時間戳數據,通過數據時間戳對齊和下采樣方法,在多個公開數據集以及私有數據集和近年來提出的深度學習時序序列分類算法上的實驗表明,該方法能夠在基本不損失模型效果的同時,有效減小數據集的稀疏規模和模型訓練時間。
1 相關方法
在本節中,本文先給出多維時序序列的相關定義,之后將相關方法分為時間戳對齊和基于分布密度的下采樣兩步講述,具體流程示意圖如圖1所示。
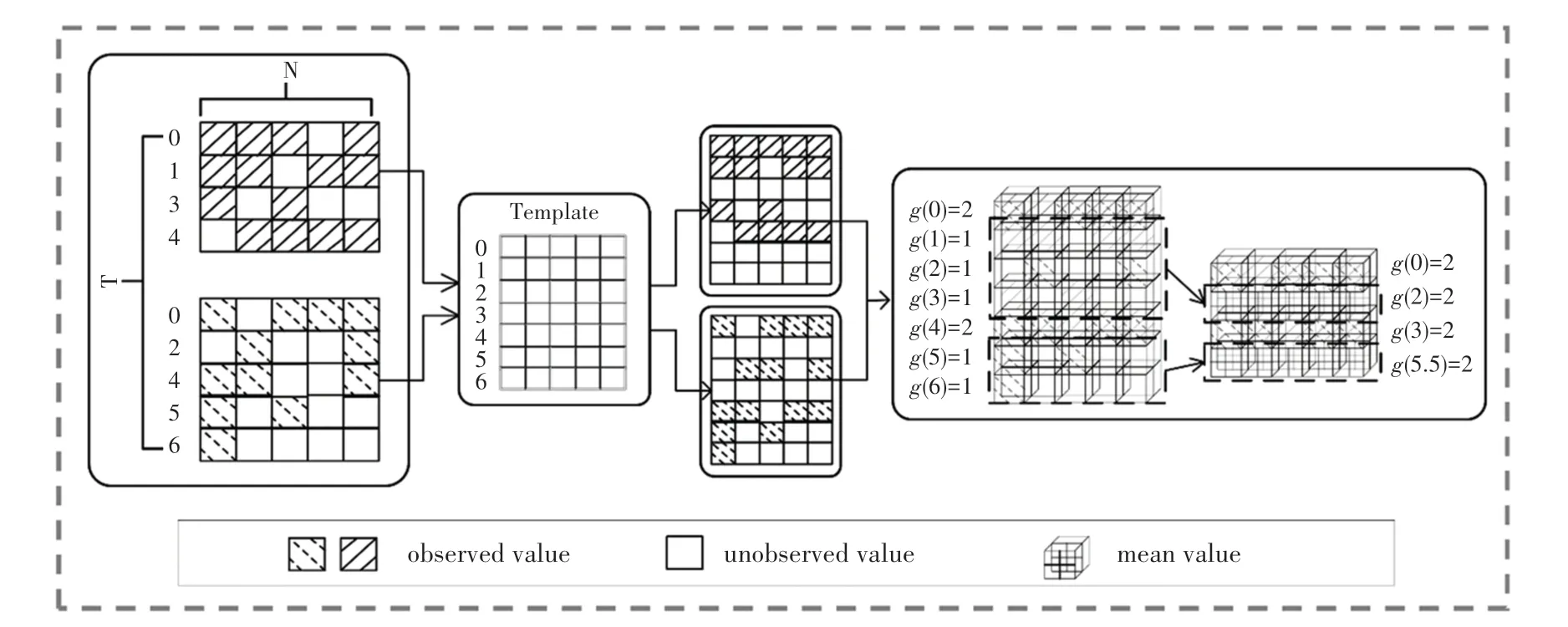
圖1 時間戳對齊和下采樣流程示意圖Fig.1 Schematic diagram of time stamp alignment and downsampling process
1.1 多維時序序列的定義
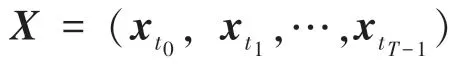

1.2 時間戳對齊
由于數據集的不規則采樣,導致雖然數據采樣點的時間跨度非常大,但是數據點的個數卻非常少,具體到每一個樣本更是不盡相同。例如在Physionet數據集中,總共有48×60 min,共2 880個數據可采樣點。但事實上該數據集中最大樣本的數據采樣點個數只有249,而最小樣本的數據采樣點個數只有1。考慮到深度學習模型在訓練時一般采用小批量(mini-batch)做法,因此需要在較短的樣本尾部填充無意義的屏蔽值(mask value),使模型的輸入等長。但是這樣的對齊在RNN模型中是有缺陷的,RNN模型的每一個時刻輸入是mini-batch在時間維上的切片,上述做法會使得切片中包含的不同樣本數據點沒有對齊,即樣本的t時刻的數據和樣本的t時刻數據同時輸入RNN模型,這樣會導致模型效果欠佳。因此,需要做數據對齊。
首先本文根據時間戳的最小粒度和其時間跨度,構建一個具有最長數據點長度的無值背景板,再根據原始數據對應的時間戳將每一個數據點嵌入其中,這樣就得到了一個完整的所有樣本數據點都對齊了的數據集,實現了數據點的物理位置和邏輯位置的統一。根據上述做法,Physionet數據集的維度從原始的3 994×203×41,最終則轉換成了3 994×2 881×41。
1.3 基于數據分布密度的下采樣
在將數據對齊后,數據集的稀疏性會進一步擴大,需要做進一步的處理來減小數據集的稀疏性。本文定義在時間軸上的數據集分布密度函數,具體如下:
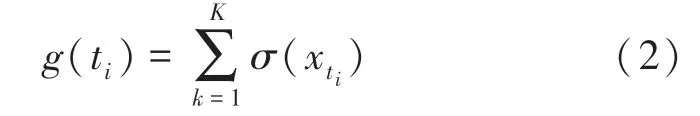
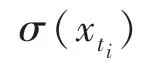
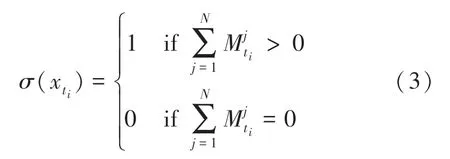
根據定義可知,當()較小時,說明樣本在對應時間戳∈[t,t)中分布較少,該區間的稀疏性較大。本文通過求解該區間所有觀測變量的均值來替代該稀疏區域,實現數據稀疏性的減小,計算公式如下:
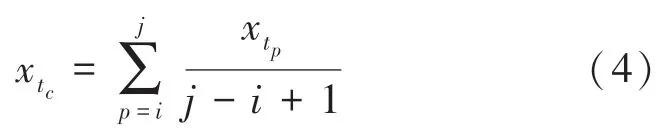
其中,t可用如下數學公式計算得出:
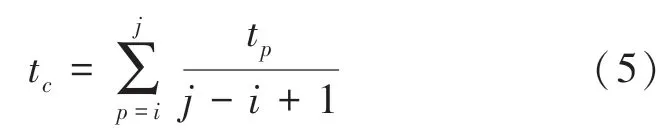
圖2給出了Physionet數據集原始和預處理后的數據密度分布圖像。從圖2中可以明顯看出,經過預處理的數據在時間軸上的分布密度顯著提升,并且基本保留原始分布密度的分布趨勢。
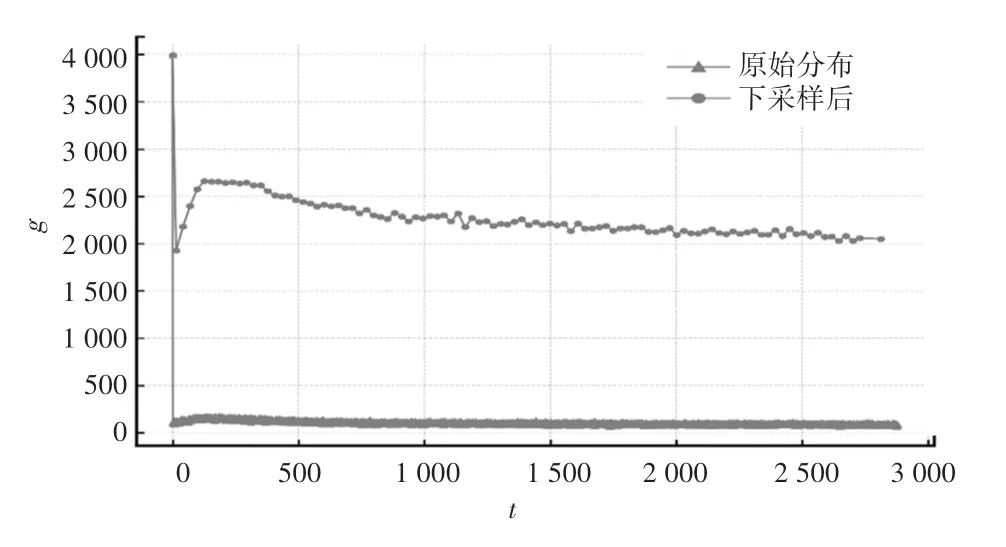
圖2 Physionet數據集數據分布密度Fig.2 Data distribution density of Physionet data set
在經過預處理后,Physionet數據集大小從經過時間戳對齊后的3 994×2 881×41轉換成了3 994×100×41。對比該數據集原始的大小可以發現,經過處理后的Physionet數據集的大小是原來的0.493倍,顯著減少了數據集的尺寸。
2 實驗結果
2.1 數據集
Physionet challenge 2012是physionet.org在2012年舉辦的一個多維時序序列分類和回歸比賽。該比賽使用的數據是12 000名因心臟病、內科、外科等原因而住院的ICU病人的記錄,包括白蛋白(Albumin)、堿性磷酸酶(ALP)、谷丙轉氨酶(ALT)等36個觀測變量和年齡、身高、體重等6個一般描述符,共42個變量。除一般描述符外,囿于病人身體狀態差以及醫療設備工作性質等原因,在36個觀測變量中有很多缺失值,且每一個觀測的時間間隔也不相同。數據集中給出了每一個觀測的相關時間戳,該時間戳的分度值是分鐘,即時間的最小粒度為每分鐘。該挑戰賽設立了5個分類任務和一個回歸任務。本文主要使用的是其中的死亡預測任務,即預測病人在48 h后是否死亡。這也是下文涉及的算法在提出時被使用到的任務。
MIMIC-III Clinical DataBase是一個大型的公開數據庫,其中包括了2001年至2012年期間在美國BIDMC醫療中心重癥監護病房住院的超過4萬名患者的已確認的健康相關數據。該數據庫包括人口統計信息、在床邊進行的生命體征觀測、實驗室檢測結果、程序、藥物、護理記錄、影像報告和死亡率等記錄。通過數據挖掘、信息提取等手段,從該數據庫中提取了份存在大量缺失值和不規則采樣的ICU住院病人48 h內的時序序列數據、對應的時間戳和死亡預測標簽。該數據一共有12個觀測變量,包括血氧飽和度(SpO2)、心率(HR)、呼吸速率(RR)、收縮壓(SBP)等。和Physionet一樣,本文也是使用其作為分類任務。
腎移植術后數據集是來自某三甲醫院腎移植科的931名腎移植患者術后生理檢查的數據集,其中包括血常規、尿常規和血藥濃度等共87個觀測變量。該數據集的時間戳較為特殊,以腎移植手術當天為第零天,手術后所做檢查的時間戳都為正整數,手術前所做檢查的時間戳皆為負整數,時間戳的單位長度為一天。一般腎移植患者術后需住院幾周,因此,數據在第零天周圍分布比較密集。之后因病人經濟原因、個人意愿以及地域等因素,使得病人做生理檢查次數較少、檢查范圍不全,從而導致數據分布十分稀疏且不規則。該數據集的標簽分為感染、排異和正常三個類型,分別描述了病人腎移植術后自身免疫力水平低、高、正常對移植腎的影響。
圖3給出了上述3個數據集原始缺失率和經過下采樣后的缺失率。從圖3中可以發現,腎移植數據集缺失率較另外2個數據集缺失率更高,下采樣效果不明顯,但是對于Physionet數據集和MIMIC-III數據集,下采樣均有效降低了數據集的缺失率。
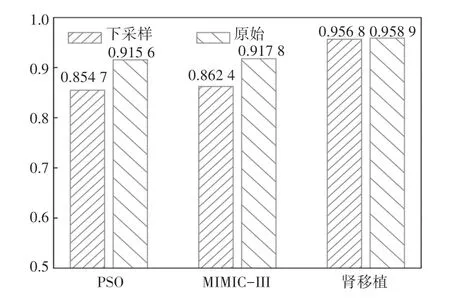
圖3 3個數據集下采樣前后缺失率對比圖Fig.3 Comparison of missing rates among three data sets with and without downsampling
2.2 相關分類算法
GRUD,全稱GRU-deacy。文獻[12]通過分析缺失值的類型給出了2個缺失模式,分別是:固定缺失值模式和衰減收斂缺失值模式。其中,固定缺失值模式指某個觀測變量的缺失值和該觀測變量最早的記錄值相同;衰減收斂缺失值模式指觀測變量在經過較長時間變化后逐漸收斂,如MIMIC-III中SpO2等觀測變量。研究中根據這2種缺失值模式提出了填補函數,并將填補過程嵌入普通GRU模型,構建了一個端到端的對具有缺失值和不規則采樣的多維時序序列進行分類的深度學習算法,在原始Physionet數據集實驗表明,該算法能夠有效地實現對病人死亡與否的預測,其達到了0.831,是一個強有力的基線。
Interp-net通過構建了一個插值網絡來捕獲輸入數據的平滑趨勢、瞬態和觀測強度信息共三個維度的信息,以適應使用稀疏和不規則采樣數據作為有監督學習輸入的復雜性,從而得到一個規則間隔和無缺失值的輸出,在此基礎上將利用預測網絡計算出最后的分類結果。與GRUD不同的是,該模型完全是模塊化的,其插值網絡和預測網絡是分開的。在原始MIMIC-III數據集上達到了0.853。
2.3 結果
由于3個數據集標簽分布并不均勻,因此本文采用ROC曲線下面積來衡量模型的效果。的計算方法同時考慮了分類器對于正例和負例的分類能力,在樣本不平衡的情況下,依然能夠對分類器做出合理的評價。實驗中將數據集分為訓練集、驗證集、測試集,其比例為0.64:0.16:0.2。模型超參數均為模型研發者提供的默認值,其中,Physionet數據集和腎移植數據集的批次大小為128,MIMIC-III批次大小為256。
表1顯示了上述模型在3個原始數據集和預處理后訓練的最終效果。從表1中可以看出,模型在經過預處理的數據集上的效果幾乎同模型在原始數據集上效果相同,損耗在0.003。

表1 GRUD、Interp-net模型在Physionet、MIMIC-III、腎移植數據集上AUC效果表Tab.1 AUC effect table of GRUD and Interp-net models on Physionet,MIMIC-III,and kidney transplantation data sets
本文還對比了上述模型在這2類數據集上訓練所需時間,所有訓練內容都在一張Nvidia Tesla P40顯卡上進行。實驗結果見表2,單位為hour/epoch。從表2中可以明顯看出模型在經過預處理的數據集上達到收斂點的時間較短,能夠有效地縮短模型的訓練時間:在相同模型情況下,經過處理后的數據集的訓練時間與原始數據集訓練時間相比,平均減少了42.1%。尤需指出的是,腎移植數據集在GRUD算法上則減少了50%。

表2 GRUD、Interp-net模型在Physionet、MIMIC-III、腎移植數據集上訓練時間表Tab.2 Training schedule of GRUD and Interp-net models on Physionet,MIMIC-III,and kidney transplantation datasetshour·epoch-1
3 結束語
本文提出了一種新的多維時序序列預處理方法。首先利用數據集自帶的時間戳,實現原始數據在時間刻度上的對齊;然后通過觀察數據集在時間軸上的分布密度來縮小分布密度較低的區間,最終得到一個規則采樣且數據稀疏性大大減少的新數據集。實驗結果顯示與原始數據集相比,在基本不損失模型效果的情況下,該方法顯著減小了模型訓練所需要的時間。但是,該方法不夠自動化,仍需要手動選擇需要縮小的區間。因此,性能上更為優越的自動化是未來探索的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
