語言計量特征在譯者身份判定中的應用*
——以《傲慢與偏見》的兩個譯本為例
2016-10-25 09:39:22詹菊紅
外語學刊 2016年3期
詹菊紅 蔣 躍
(西安交通大學,西安 710049)
語言計量特征在譯者身份判定中的應用*
——以《傲慢與偏見》的兩個譯本為例
詹菊紅 蔣 躍*
(西安交通大學,西安 710049)
本研究提出將語言計量特征應用于語言風格對比及譯者身份判斷的方法。通過對各10萬字的兩個訓練譯本語料庫中14個語言結構特征分布的統計對比,發現兩個譯本中5個具有顯著性差異的語言計量特征。以這5個特征作為譯本表征,對各10萬字的兩個未知譯者文本作相關分析并進行譯者身份識別實驗,根據這5個計量特征準確地判定未知譯本的譯者。研究證明,將基于語料庫的計量研究方法與統計學方法相結合,用語言結構的計量特征標識譯本的方法有助于加強譯者身份、譯本的判定以及譯者風格辨別的可解釋性和客觀科學性,有助于彌補傳統的譯者風格定性研究的不足,使翻譯研究趨于客觀、科學并具有可解釋性。
譯者身份判定;語言計量特征;相關性分析
1 引言
近20年來,作為一門新興的語言學分支,計量語言學成為研究語言結構和語言演化的一個利器(劉海濤 2015:40),也成為文學文本、翻譯語言研究的重要工具。計量語言學認為,作者不同的語言風格是由于語言單位使用頻率差異而形成的(黃偉 劉海濤 2009:25)。近30年來,人們開始利用計量語言學的統計方法進行語言風格特征比較、文本年代的判定、文章作者的判定和作者風格的識別等 (Hanlein 1999,Oakes 1998:139)。黃偉、劉海濤(2009:26)和陳芯瑩(2012:137)等曾通過對不同作家作品中語言結構特征的統計得出語言風格的一致性或區別性特征,利用語言結構的分布數據測量作家語言風格的計量特征,并且用以判斷陌生文本的作者。同理,語言單位在譯作中的分布數據成為體現譯者語言風格的語言計量特征。因此,本研究假設,利用計量的方法對譯作的語言進行統計分析,提取一些能夠標識譯者語言風格的語言計量特征集(set of quantitative properties),然后基于這些語言特征進行未知譯本的譯者識別或判定,它應該像陌生文本作者的判定一樣是可行的。霍躍紅(2010)用語料庫方法分析典籍英譯譯者的文體并進行文本譯者識別的實驗。王青等(2012:81-93)也用類似的方法進行作者指紋的建立和識別。但目前,采用基于語料庫的計量研究方法判定未知譯本譯者,尤其是對翻譯漢語文學作品的譯者判定和識別的研究尚未見報道。
本研究基于語料庫,運用計量語言學的方法,獲取王科一和張經浩《傲慢與偏見》譯本中有區別性的語言計量特征集,然后將這些計量特征與未知文本語言結構方面的數據進行文本相關性比對,進行未知文本譯者的判定實驗。研究的問題包括:(1)王科一和張經浩在《傲慢與偏見》譯本中表現出的區別性的語言計量特征有哪些;(2)如何獲取這些特征;(3)如何運用這些特征判定未知譯本的譯者?通過回答上述問題,以期為譯者譯本風格研究及譯本譯者的判定提供比較客觀的和科學的研究方法和途徑。
2 語料與工具
本研究語料的收集處理具體包括:語料的選取、語料清洗和分詞賦碼、分詞語料的人工干預等。使用的語料庫語言學軟件主要包括Ant Conc,CLAWS7,ABBYY,Ultra Edit和ICT CLAS 2015等。
2.1 語料選取
秉承權威性和代表性的原則,本研究選取簡·奧斯汀的小說PrideandPrejudice為源語文本。該小說的中譯本有30多部,在中國讀者中影響廣泛。選取的譯文語料樣本分別為王科一和張經浩的譯本。前者是20世紀后半葉的著名翻譯家,其外國文學功底深厚且對英語語言駕輕就熟,曾翻譯過多部世界文學名著,如《遠大前程》、《十日談》等,而且是第一位《傲慢與偏見》的中文譯者,譯著在1955年2月首次出版,并由上海譯文出版社于1980年再版,已為廣大讀者所熟知,并且廣受好評。王科一的翻譯語言準確通順、形神兼備、極其負責并忠實地傳達原作的精神實質(李雪嬌 2014:48-49),是研究翻譯語言語體和語用特征的理想樣本。20世紀末,隨著對外開放很多杰出的中國翻譯家致力于把經典文學名著介紹給中國讀者,對很多名著開展重譯,《傲慢與偏見》的重譯本如雨后春筍般出現。其中最具代表性的當屬1996年張經浩的譯本。張經浩是這一時期最杰出的英譯漢翻譯家之一,翻譯經驗豐富,翻譯風格與王科一的迥異。他主張在翻譯過程中“去翻譯腔”(張經浩 1999:38),語言通達流暢,力求貼近目標語言。上述兩譯本首版時間相差40年,譯者所處的不同時代背景和不同的翻譯主張造成明顯的譯本語言結構差異和計量特征方面的不同,具有較強的可比性,是較理想的語料來源。
2.2 語料清洗
語料清洗是建立語料庫的首要工作。通過掃描獲得兩譯本的PDF格式文件,使用ABBYY軟件進行格式轉換,生成Word文檔。由于Word文本均存在錯別字和亂碼的現象,因此,為了保證研究的準確性和客觀性,須進行語料清洗和人工糾錯,然后生成兩個完整的譯本分別保存為wkypap.doc(218,425字)和zjhpap.doc(196,513字)。清洗后的兩個樣本字數差別小于10%,對語言特征的計量結果不產生實質性影響,可忽略。
2.3語料加工
本研究采用中國科學院計算技術研究所開發的ICTCLAS 2015漢語詞性標注軟件對清洗后的兩個譯本進行分詞標注。由于標注軟件自身的局限性,詞性標注加工完成后,不可避免地會出現一些錯誤。例如,由于電腦對句子語義的識別能力有限,會導致分詞和標注錯誤。如“麗迪雅”是人名,軟件將其標識為“麗/ag迪雅/n_newword”,而不能正確地處理成“麗迪雅/nrf”.因此,本研究對標注加工后的譯文再檢查和校對,校對過程中,參照《CLAWS 7詞性賦碼集》和《中科院計算所漢語詞性標記集(3.0)》(劉群等 2008)以及《漢語現代詞典》(第五版),對軟件標注錯誤的地方進行人工糾錯。分詞標注后的文件分別保存為wkypap.txt和zjhpap.txt.
3 方法
研究方法涉及語言結構計量特征的確定與甄選、數據統計以及數據處理與分析。使用的軟件主要是AntConc 3.4.3、WordSmith6和SPSSv21。
3.1 語言結構計量特征的確定
本研究考察語言結構的指標均為詞匯層面和句子層面的語言結構特征。按照語料庫翻譯學和計量語言學文本聚類分析的慣例,主要選擇部分代表語言結構長度、詞匯豐富程度、詞類和句式使用等方面的語言結構特征作為考察對象。參照黃偉和劉海濤(2009:25-26)提出的用于文本聚類的漢語計量特征選擇詞長、句長、型例比、副詞比例等12種結構類型作為考察對象,用以有效區分文本語體特征。須特別指出的是,在翻譯文本中,形容詞比例和四字慣用語比例也是體現譯者風格(translator style)差異的一個重要計量特征(蔣躍 2014:99-100)。所以,本研究把這兩項也納入考察指標中。基于文本聚類的漢語計量特征,本研究最終確定14種語言結構特征作為分析對象:詞長、句長、型例比、形容詞比例、副詞比例、名詞比例、代詞比例、助詞比例、慣用語比例、標點符號比例、陳述句比例、疑問句比例、感嘆句比例和單現詞。
3.2 實驗設計
為了測試和探尋到底哪些語言計量特征可以有效地判定未知譯本的譯者,本研究擬以文本為單位計算特定語言結構在文本中的頻率和百分比,基于樣本的均值比較這些語言結構在兩組樣本中的分布是否具有差異。即用訓練樣本獲取的具有顯著性差異的語言結構數據作為依據,對測試樣本的相同語言結構特征進行檢索和顯著性差異分析,通過該實驗實現譯者身份的判定。
3.21 訓練文本和測試文本的確定
首先,將王譯本(wkypap.doc)和張譯本(zjhpap.doc)對半平分成前后兩部分,平分時保留截分處句子的完整性。前一部分作為訓練文本,后一部分作為測試文本。也就是說,兩個訓練文本取自兩譯本的前一半字數;待判定譯者的兩個測試文本為兩個譯本的后一半文本,與訓練文本數據無交叉。截分的結果是,王譯本均分為訓練文本TTT1.doc(109,211字)和待判定譯者文本ETT1.doc(109,214字);張譯本均分為訓練文本TTT2.doc(98,262字)和待判定譯者文本ETT2. doc(98,251字)。之后,在相同截分處將分詞賦碼后的王科一全譯本wkypap.txt和張經浩全譯本zjhpap.txt進行相應的均分,生成兩個訓練文本TTT1.txt和ETT1.txt以及兩個測試文本TTT2.txt和ETT2.txt.
3.22 研究樣本的獲取
為求得更加客觀和準確的統計數據,并獲取足夠的樣本量,本研究進一步對兩訓練文本和兩測試文本的4個.doc文件以每5,000字為單位進行均分,均分結果既保證每個樣本字數基本相同,又保證樣本之間的可比性;同時,使得每組產生20個左右的樣本,樣本量比較合理。為保證截分處句子的完整性,每個文檔的字數并非5,000整,但基本確保每個文檔字數在4,990-5,010之間。而后,在相同截分點處,對4個.txt文檔進行截分,最終生成王科一訓練樣本22個,張經浩訓練樣本20個,未知譯者A測試樣本22個以及未知譯者B測試樣本20個。所有樣本均為分詞賦碼過的文檔,擴展名均為.txt,用utf(8)格式保存。
3.3數據統計與分析
首先對wky和zjh的兩組訓練樣本中的14個語言計量特征進行顯著性差異分析,獲取其中具有顯著性差異的語言計量特征,組成一個指標集(set of index)。然后對未知譯者文本A和未知譯者文本B中的兩組樣本中的相同指標用AntConc 3.4.3進行檢索計算,得出這兩組樣本中相應的語言指標的數據。之后,以這些指標為變量,4組樣本兩兩交叉,進行獨立樣本T檢驗,以驗證4組樣本的計量語言特征之間是否具有顯著性差異。如果兩組數據間具有顯著差異,說明它們并非來源于同一總體,即為不同譯者所譯。如果兩組數據間的差異不大,且無統計學意義,則可判定它們來源于同一個總體,即為同一譯者所譯。
4 結果
4.1 訓練樣本中語言計量特征顯著性差異分析
對王科一的22個訓練樣本和張經浩的20個訓練樣本中的詞數、句數(以句號、問號和感嘆號為標記)、副詞數、形容詞數、名詞數、代詞數、助詞數、慣用語數、陳述句數、疑問句數、感嘆句數、標點符號數、單現詞以及型例比(TTR/每5,000字)以及慣用語用AntConc 3.4.3進行統計檢索,然后將數據導入Excel中進行計算,得出前述14個語言特征的計量數據。
用SPSS對兩組訓練樣本中的14個語言計量特征的數據進行獨立樣本T檢驗,最終從兩組樣本中發現14個語言特征中有5個特征的分布數據存在顯著性差異。表1和表2所示是這5個特征的描述性統計結果和T檢驗結果。
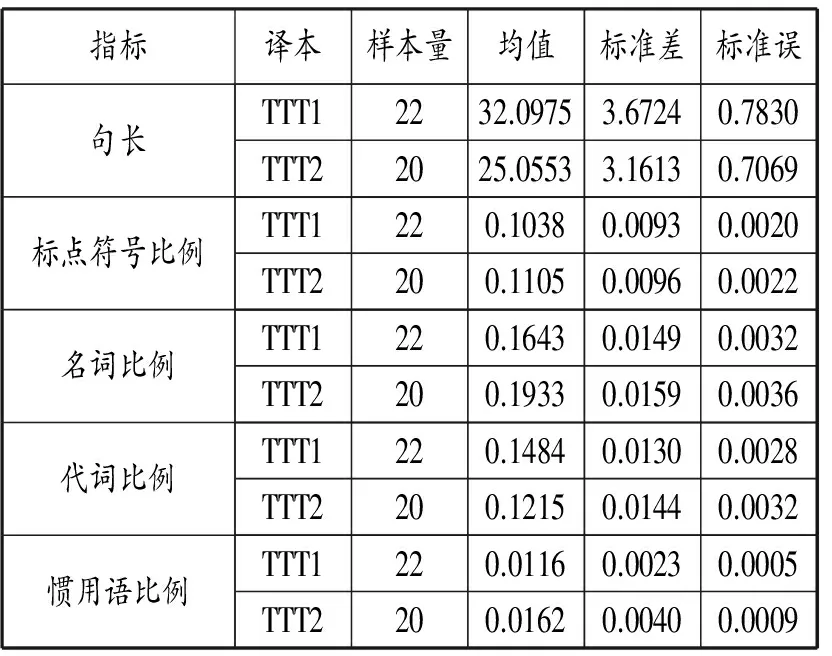
表1 兩組訓練樣本中5個語言特征的描述性統計結果
注: 表中數據均四舍五入到小數點后4 位。(1)句長=字數(不含標點符號)/句數;(2)名詞比例=名詞數/詞數;(3)代詞比例=代詞詞數/詞數;(4)慣用語比例=各類慣用語總數/詞數;(5)標點符號比例=標點符號數量/字數。
從表1可看出,通過比較均值可知TTT1(wky譯本)的句長和代詞比例高于TTT2(zjh譯本),而TTT2(zjh譯本)在標點符號比例、名詞比例和慣用語比例上高于TTT1(wky譯本)。

表2 兩組訓練樣本中5個語言特征的獨立樣本T檢驗結果
注:獨立樣本檢驗前要假設具備兩個條件,一個是兩個總體呈現正態分布,另一個是兩個總體具有相同方差。因此,先用SPSS對兩組數據做正態分布檢驗,如果不符合正態分布,則對數據進行轉化,使之符合正態分布;另外,獨立樣本T檢驗自帶方差齊性檢驗(Levene’s test), T檢驗的報表顯示方差齊性檢驗的結果,只要sig>.05,就代表兩組數據方差相同,取T檢驗結果中的第一行sig值;檢驗結果發現,所有樣本符合方差齊性。
由表2可知,經過獨立樣本T檢驗得出的5個語言特征的sig值均小于臨界值.05。兩譯本的訓練樣本在句長、標點符號比例、名詞比例、代詞比例和慣用語比例這5個語言計量特征上均存在顯著性差異。尤其值得注意的是,句長、名詞、代詞和慣用語比例的sig值均為.000。在統計學上,P值小于.001說明兩組數據之間呈現極其顯著的差異。這一數據表明,王科一和張經浩譯本中這5個語言結構特征的分布差異極其顯著,兩譯者在4個語言結構的使用方面差別非常大。因此,上述5個語言結構特征形成本研究要重點考察的語言計量特征集,提示兩位譯者在《傲慢與偏見》訓練文本中這5個語言結構的使用方面具有區別性差異。那么,這些語言特征在測試樣本中的表現如何,在訓練樣本與測試樣本間是否具有顯著性差異?本研究將進一步分析檢測,并據此驗證未知譯本的譯者。
4.2 測試樣本中語言計量特征顯著性差異分析
為了驗證兩組訓練樣本間的5個語言計量特征是否存在顯著性差異,研究對未知譯者文本ETT1的22個測試樣本和未知譯者文本ETT2的20個測試樣本中的5個語言結構特征頻次,用正則表達式在AntConc 3.4.3中進行統計檢索,之后將數據導入Excel進行計算,得出各個語言結構的計量數據。并用SPSS對兩組數據進行獨立樣本T檢驗,得出這5個特征描述性統計結果(見表3)和顯著性差異檢驗數據(見表4)。
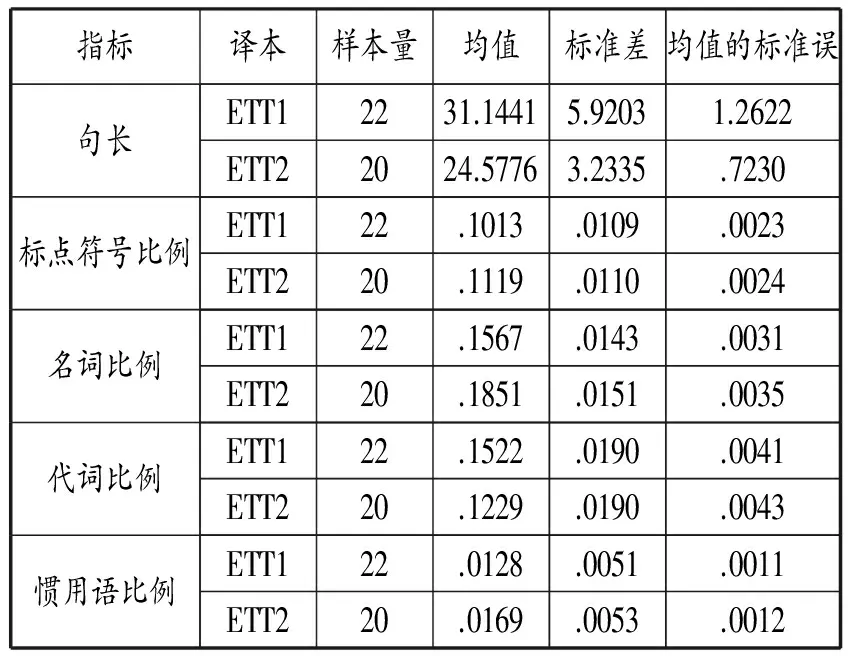
表3 兩組測試樣本中5個語言特征的描述性統計結果
從表3可以看出,通過比較均值可知未知譯者文本ETT1的句長和代詞比例均高于未知譯者文本ETT2,而未知譯本ETT2在標點符號的比例、名詞比例、慣用語比例的使用頻率上高于未知譯本ETT1。
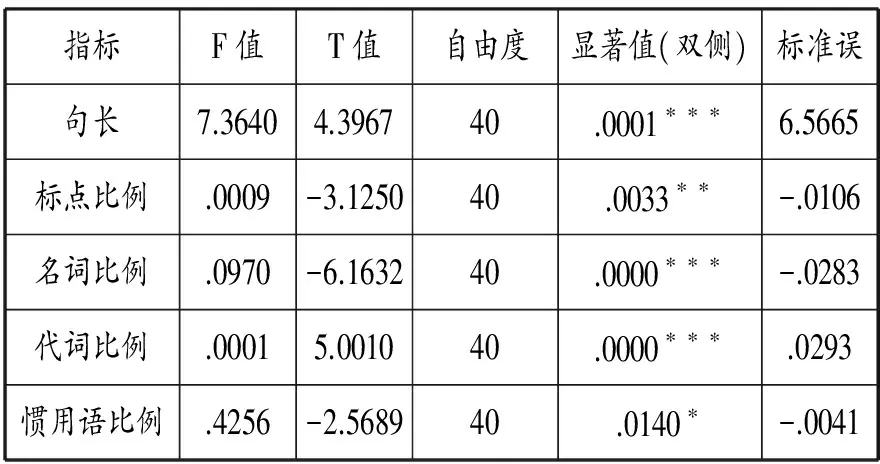
表4 兩組測試樣本中5個語言特征的獨立樣本T檢驗結果
表4顯示,經過獨立樣本T檢驗得出5個語言特征的sig值均小于臨界值.05。由此可知,兩個未知譯者測試樣本在句長、標點符號比例、名詞比例、代詞比例和慣用語比例這5個語言結構特征方面均存在顯著性差異。其中,句長、名詞以及代詞比例sig值為.000,小于.001,表明兩未知譯者文本在這5個方面存在極其顯著的差異,尤其是在標點符號和慣用語的分布上存在更為顯著的差異。據此可以判定,未知譯者文本A和未知譯者文本B來自于不同的譯本,為不同譯者所譯。
4.3 4 組樣本間語言計量特征的顯著性差異分析
將兩組訓練樣本和兩組測試樣本交叉進行語言特征的比對。為了判定未知譯本ETT1是否來自wky譯本,是否為王科一所譯,需要將未知譯者A樣本中的5個語言特征數據與wky訓練樣本TTT1中相應的語言特征數據進行顯著性差異分析,如果存在顯著性差異,則可斷定未知文本ETT1并非王科一所譯;如果5個指標均不存在顯著性差異,則可判定未知文本ETT1來自于wky譯本,為王科一所譯。同理,為判定未知譯本ETT2是否為王科一所譯,需要將未知譯本ETT2中的5個語言特征的數據與wky樣本TTT1中的語言特征數據進行顯著性差異分析,如果存在顯著性差異,則可判定未知譯本B并非王科一所譯,反之亦然。同樣,將未知譯本ETT1與未知譯本ETT2和張經浩文本TTT2中的5個語言計量特征分別進行顯著性差異檢驗,判定未知譯本B是否為張經浩所譯。表5顯示4組樣本兩兩交叉的獨立樣本T檢驗結果中的顯著值,即P值的情況。
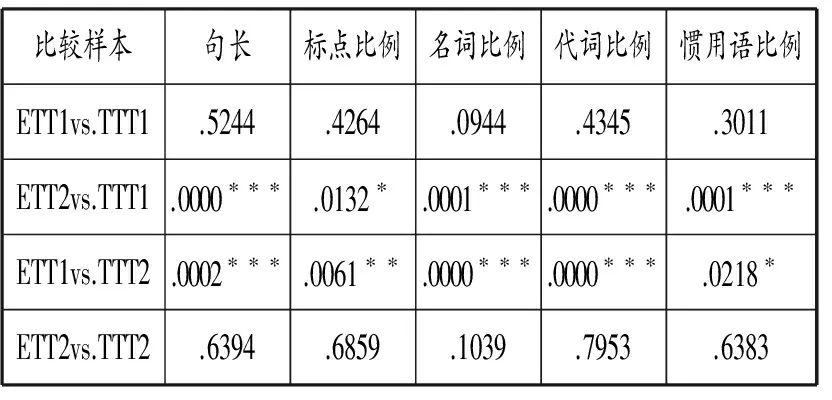
表5 4組樣本間5個語言計量特征獨立樣本T檢驗的顯著值(P值)
由表5可知,未知譯者文本ETT1與wky訓練文本TTT1的5個語言特征經過獨立樣本T檢驗得出的sig值均遠遠大于臨界值.05,所顯示的差異不顯著,無統計學意義。未知譯者文本ETT1與TTT1在上述5個語言結構特征上均不存在顯著性差異。換言之,ETT1與TTT1來自于同一譯本。結合本研究實際情況可以判定,ETT1來自于wky譯本,為王科一所譯。ETT2與wky訓練文本的5個語言特征獨立樣本T檢驗得出的sig值均小于臨界值.05。其中,句長、標點符號比例、代詞比例和慣用語比例sig值均為.000,P值小于.01說明兩組數據之間的差異具有顯著的統計學意義。可知,ETT2與TTT1在5個語言結構特征方面均差異顯著。據此可以判定,ETT2不是來自于wky譯本,非王科一所譯。
未知譯者文本ETT1與zjh訓練文本TTT2的5個語言特征經過獨立樣本T檢驗得出的sig值均小于臨界值.05,而且所有sig值均小于.01。當P值小于.01時,說明兩組數據間存在極其顯著的差異。因此可知,未知譯者文本ETT1與zjh訓練文本TTT2在上述5個語言結構特征的比例方面均差異顯著。據此可以斷定,ETT1并非來自于zjh譯本,非張經浩所譯。未知譯者文本ETT2與zjh訓練文本TTT2的5個語言特征經過獨立樣本T檢驗得出的sig值均遠遠大于臨界值.05,因此可知,ETT2與TTT2在上述5個語言結構特征比例方面的差異很小,或者均不存在顯著性差異,沒有統計學意義。據此可以判定,ETT2來自于zjh譯本,為張經浩所譯。
5 討論
本研究對王科一訓練文本TTT1、張經浩訓練文本TTT2、未知譯者文本ETT1和未知譯者文本ETT2,分別以句長、標點符號比值、名詞比值、代詞比值和慣用語比值為考察對象,進行語言計量特征顯著性差異分析,并進行譯者身份識別實驗。實驗結果驗證出我們的研究假設,證明運用譯文中獲取的語言計量特征可以準確地判定未知文本的譯者,這一點我們通過回顧未知譯者文本內容進行驗證。
盡管黃立波等(2011)通過對照《紅樓夢》幾個英譯本以及英國“翻譯英語語料庫”(TEC)翻譯小說子庫文學類翻譯英語在類符/形符比、平均句長、敘述結構(這里指選擇性that的使用)方面的比較,發現譯者風格差異不明顯,這些語言結構和特征“并不足以區分不同譯者的翻譯風格”(黃立波 2011:917)。另外,黃立波等人考察葛浩文英譯中國小說的翻譯風格后發現,利用語料庫統計數據(如標準類/形比和平均句長等)并不能夠有效地將一個譯者與另一個譯者的翻譯風格區分開,這些統計結果更像是翻譯文本表現出的一種共性。但是,本研究采用顯著性差異分析方法,能夠準確區分王科一和張經浩兩譯者的5個語言結構計量特征,證明盡管譯者風格在宏觀層面可能差異不大,盡管翻譯文體表現出明顯的共性,但是不能否認在某些語言形式的使用偏好上,不同譯者、不同譯本確實存在顯著性差異,并且這些特征可以用來判定不同譯者及其譯作。
5.1 名詞與代詞
通過統計整個譯本發現,王科一譯本的代詞比例為15.03%,而張經浩的則為12.22%,王科一代詞的使用頻率比張經浩的高出約3%。此外,通用英漢對應語料庫(CEPC)中漢語原創文學的代詞比例為8.83%,漢語翻譯文學作品的代詞使用頻率為11.81%(王克非 2012:63)。兩譯本的代詞比例均遠遠高出漢語原創文學,這是因為漢語代詞的類型較少,沒有主賓格之分,使用頻率較低,從而證實文學翻譯中指代關系的“顯化”現象 (王克非 2012:87)。王科一的代詞使用頻率遠高于漢語翻譯文學的整體水平,而張經浩則略高,比較接近漢語原創作品的代詞使用情況。
王科一在翻譯中本著“極其負責任和忠實原文的思想態度”(李雪嬌 2014:48-51),在翻譯方法上趨向于靠近源語。王克非認為,英語作為一種形式化比較高的語言,代詞使用的頻率要明顯高于漢語原創文學,“譯者的忠實”會使代詞從英語向漢語譯本遷移,導致譯本代詞冗余現象。這個現象也與譯者所處的年代有關,20世紀50年代新中國剛剛成立,社會主義建設正在起步階段,漢語與英語之間的社會地位懸殊造成翻譯策略和翻譯產品的“逆差”(王克非 2012:114),代詞的使用便是這種逆差的見證。雖然王科一譯本形神兼備,迄今依然被推崇為《傲慢與偏見》最為經典和備受歡迎的譯本之一,但譯者身上深深的時代烙印藉此可見一斑。我們在1∶2平行語料庫中對兩譯本代詞使用情況進行檢索觀察,也能看出兩譯本的差異。比如:
① She_PPHS1 felt_VVDanew_RRthe_AT justice_NN1 of_IOMr._NNB Darcy_NP1 ’s_GE objections_NN2;and_CCnever_RRhad_VHD she_PPHS1 before_RTbeen_VBNso_RGmuch_RRdisposed_VVNto_TOpardon_VVIhis_APPGE interference_NN1 in_IIthe_AT views_NN2 of_IOhis_APPGE friend_NN1. //王譯:她/rr 重新/d 又/d 想到/v 達西/nrf 先生/n 的確/d 沒有/d 冤枉/v 她們/rr,/wd他/rr指出/v 她們/rr的/ude1 那些/rz缺陷/n 確/d 是/vshi 事實/n,/wd她/rr深深/d 感覺/v 到/v,/wd 實在/d 難怪/d 他/rr 要/v 干涉/v 他/rr朋友/n 和吉英/nr 的/ude1 好事/n./wj
張譯:她/rr 又/d 在/p 想/v,/wd 達西/nrf 先生/n 看不慣/v 自/p 有/vyou其/rz 看不慣/v 的/ude1 道理/n./wj他/rr 替/p 朋友/n 著想/vi,/wd 插/v 了/ule 一/m 手/n,/wd 現在/t 看來/v 的確/d 情有可原/vl./wj
例①對同一英文原句的翻譯,王譯本中代詞出現8次,而張譯本中則只有3次。兩位譯者代詞使用頻率的懸殊顯而易見。
王譯本的名詞比例為16.05%,而張譯本的名詞比例為18.92%,可以看出王科一的名詞使用頻率低于張經浩將近3個百分點。兩譯本中名詞與代詞比例總和分別是31.08%與31.14%,對比漢語翻譯文學的研究數據,翻譯漢語名詞與代詞的比例總和為31.33%(王克非 2012:63)。兩譯本及漢語翻譯文學作品的名詞與代詞所占的詞頻比例總和基本都在31%左右。數據顯示,名詞詞頻比例高的文本,則代詞比例低;而代詞比例偏高時,則名詞比例偏低。其原因可能是因為“漢語常規的指代方式主要以“名詞復現”和“零指代為主,顯性人稱代詞的使用頻率一般較低;而代詞是替代名詞的一種詞類,漢語中多數代詞具有與名詞相同的指別(deixis)功能”(王克非2012:87),因此,代詞與名詞在指稱功能上呈現一種“詞頻互補的關系”。張經浩的譯本更加靠近漢語,翻譯中刻意弱化源語的影響,盡量消除“翻譯腔”。因此張經浩譯本的代詞使用頻率相比于源文和王科一譯本都大大降低。但是,為了避免因指代不明而引起的歧義,譯者勢必會使用相對多的名詞明示原文的指代關系,這或許是張經浩譯本名詞比例增高的原因。
② Mr._NNB Bennet_NP1 saw_VVDthat_CSTher_APPGEwhole_JJ heart_NN1 was_VBDZin_IIthe_ATsubject_NN1 ;_; and_CCaffectionately_RRtaking_VVGher_APPGE hand_NN1,_, said_VVDin_II reply_NN1. //王譯:班納特/nrf先生/n看到/v 她/rr鉆進/v 了/ule牛角尖/n,/wd 便/d 慈祥/a 地/ude2 握住/v 她/rr的/ude1 手/n 說/v :/wp
張譯:貝內特/nrf先生/n看/v 得/ude3 出來/vf,/wd女兒/n說/v 的/ude1 這/rzv 番/qv 話/n 完全/ad 是/vshi內心/n 話/n,/wd 親切/a 地/ude2 拉/v 起/vf她/rr的/ude1 手/n,/wd 答道/v:/wp
③ Very_RGfrequently_RRwere_VBDR they_PPHS2 reproached_VVNfor_IF this_DD1 insensibility_NN1 by_II Kitty_NP1 and_CC Lydia_NP1,whose_DDQGEown_DA misery_NN1 was_VBDZextreme_JJ,and_CCwho_PNQScould_VMnot_XXcomprehend_VVIsuch_DA hard-heartedness_NN1 in_IIany_DDof_IOthe_AT family_NN1.//王譯:可是/c 吉蒂/nrf和/cc 麗迪雅/nrf已經/d 傷心/a 到/v 極點/n,/wd便/d 不由得/d 常常/d 責備/v 兩/m 位/q 姐姐/n 冷淡/a 無情/a./wj她們/rr真/d 不/d 明白/v,/wd家里/s 怎么/ryv竟/d 會/v 有/vyou這樣/rzv沒有/v 心肝/n的/ude1 人/n !/wt
張譯:基蒂/nrf 與/p 莉迪亞/nrf則/d 難過/a 至極/vi,/wd 多次/mq 埋怨/v 她們/rr 太/d 冷漠/a 無情/a./wj 雖然/c 是/vshi 自家/rr 的/ude1 姐姐/n,/wd 這樣/rzv 沒/v 心肝/n 基蒂/nrf 與/p 莉迪亞/nrf看/v 不/d 過去/vf./wj
在例②中,王譯本中出現兩例人稱代詞“她”,而張譯本中“她”只出現一次,但卻用“女兒”來明示代詞“她”的所指。另外,從名詞的整體比例來看,王譯本中名詞的使用頻率為4次,而張譯本中達到7次。可以看出,兩譯者名詞使用頻率的差別,單憑名詞使用頻率的差異也能區分兩個譯本;同時也直觀地呈現出兩譯本中名詞頻率與代詞頻率的“互補關系”。而例③中,張譯本“基蒂”、“莉迪亞”分別出現兩次,符合漢語以“名詞復現”的方式明確指代關系的語言特征。
5.2 句長與標點
從句長與標點兩個指標來看,王科一譯本的句長均值為31.63%,張經浩的則是24.82%。相比原創漢語平均句長25.46%和漢語翻譯文學作品的平均句長25.81%(王克非 2012:58-59),王科一譯本的平均句長顯然遠遠高于原創漢語文學作品、翻譯文學作品和張經浩譯本的句長,而張經浩的平均句長則接近翻譯漢語的整體水平。王克非認為,“漢語翻譯時的句子擴張與英語源語有關”(王克非 2012:60),譯者越靠近源語,譯本擴張越明顯。張經浩譯本的標點符號使用比例略高于王科一,這與他的譯文盡量靠近漢語目標語,語言凝練、句子短小精悍有很大的關系。例如:
④ I_PPIS1 am_VBMonly_RRashamed_JJof_IOhis_APPGEasking_VVGso_RG little_DA1. //王譯:他/rr 要/v 得/ude3 這么/rz 少/a,/wd 我/rr 倒/d 覺得/v 不好意思/a 呢/y./wj//張譯:我/rr 還/d 嫌/v 他/rr 開價/v 太/d 低/a./wj
從例④可以看出兩譯文句長的差異,王譯文句子較長,張譯文的句子比較簡潔。同時王譯本在形式上比張譯本更加貼近源語,譯文從詞匯與句子層面都與原文形成鮮明的對應,卻并非死譯硬譯,譯語溫婉徐緩,這應該也是王譯本備受推崇的原因之一;而張譯本更加貼近目標語,一個“嫌”字盡顯漢語的凝練之妙,這種翻譯取向使張譯本語言緊湊簡練,比王譯本總字數少1.5萬字之多。
5.3 慣用語
本研究所界定的慣用語包括習慣用語和四字成語,由軟件自動分詞標注人工校對的方法進行確定。張經浩的慣用語比例為1.66%,而王科一的為1.22%。慣用語形式短小、含義豐富,可使語言生動形象、含蓄幽默,意在言外。“常用詞、習慣用語比例增高說明譯本語言趨向于漢語目標語”(胡顯耀 2010:457);“慣用語使用的密集程度或者分布特征,往往能表明譯者對譯入語慣用語掌握的熟練程度,也能表明其語言和詞匯的豐富度和變化度”(黃立波 2009:84)。張譯本比王譯本更頻繁地使用習慣用語和四字成語,使譯文語言精辟凝練,富有文采,更貼近目標語文化。例如:
⑤ They_PPHS2 must_VMhave_VHIseen_VVN them_PPHO2 together_RL for_RR21 ever_RR22. //王譯:照理/v 應該/v 常常/d 看到/v 他們/rr 兩/m 人/n 在/p 一起/s 呀/y. /wj//張譯:他們/rr 一定/d 看見/v 了/ule 這/rzv 兩/m 人/n 形影不離/vl./wj
⑥ I_PPIS1 am_VBMso_RGgrieved_JJfor_IF him_PPHO1. //王譯:我/rr 真/d 為/v 他/rr 難受/a./wj//張譯:我/rr 拿/v 他/rr 也/d 無可奈何/vl./wj
在以上兩例中,張譯文使用“形影不離”和“無可奈何”兩個成語,譯文讀起來絲毫沒有“翻譯腔”,帶有原創漢語文學作品的韻味。“負責任的譯者在穿梭于兩種語言之間進行協調時,總會盡量減少信息傳輸過程中的損耗和丟失,便于讀者的理解和吸收。”(柯飛 2005:307)比照源語不難發現,王譯本的語言表達更加精準嚴謹,這也印證其“忠實地傳達原文精神實質”的翻譯主張。
6 結束語
本研究以《傲慢與偏見》譯本為例,獲取能夠有效區分王科一和張經浩語言特色的5個語言結構指標;并經過實驗和統計學分析,證明使用上述5個語言結構的分布數據作為文本的表示特征,可以在未知文本的譯者身份判別方面取得可信任的結果。本研究證明,即使在譯者風格不存在整體差異的情況下,也可以運用計量語言特征進行未知譯者的身份判定,并為之提供可以借鑒的方法和基本思路。
陳芯瑩 李雯雯 王 燕.計量特征在語言風格比較及作家判定中的應用——以韓寒《三重門》與郭敬明《夢里花落知多少》為例[J]. 計算機工程與應用, 2012(3).
胡顯耀. 基于語料庫的漢語翻譯語體特征多維分析[J]. 外語教學與研究, 2010(6).
黃立波 王克非. 語料庫翻譯學:課題與進展[J].外語教學與研究, 2011(6).
黃 偉 劉海濤.漢語語體的計量特征在文本聚類中的應用[J].計算機工程與應用,2009(29).
霍躍紅. 譯者研究:典籍英譯譯者文體分析與文本的譯者識別[M]. 上海:中西書局, 2014.
蔣 躍.人工譯本與機器在線譯本的語言計量特征對比——以5屆韓素音翻譯競賽英譯漢人工譯本和在線譯本為例[J]. 外語教學, 2014(9).
柯 飛. 翻譯中的隱和顯[J]. 外語教學與研究, 2005(4).
李雪嬌. 從譯者序分析譯本特色——以《傲慢與偏見》的兩個中譯本為例[J]. 河北北方學院學報, 2014(4).
劉海濤 潘夏星. 漢語新詩的計量特征[J].山西大學學報(哲學社會科學版) 2015(2).
王克非 胡顯耀. 基于語料庫的翻譯漢語詞匯特征研究[J].中國翻譯, 2008(6).
王克非. 語料庫翻譯學探索[M].上海:上海交通大學出版社, 2012.
張經浩. 重譯《艾瑪》有感[J].中國翻譯,1999(3).
Adolphs, S.IntroducingElectronicTextAnalysis:APracticalGuideforLanguageandLiteraryStudies[M]. London and New York: Routledge, 2006.
Hanlein, H.StudiesinAuthorshipRecognition—ACorpus-basedApproach[M]. New York: Peter Lang Pub Inc, 1999.
Oakes, M. P.StatisticsforCorpusLinguistics[M]. Edinburgh: Edinburgh University Press, 1998.
Wang, Q., Li, D.-F. Looking for Translator’s Fingerprints: A Corpus-based Study on Chinese Translations of Ulysses[J].Literary&LinguisticComputing, 2012(1).
ApplicationofQuantitativeLinguisticPropertiestoTranslatorshipRecognition
Zhan Ju-hong Jiang Yue
(Xi’an Jiaotong University, Xi’an 710049, China)
This paper proposes a method of using quantitative linguistic properties to contrast different translation styles and to recognize the translators of unknown translation texts. The Chinese translations ofPrideandPrejudiceby two different translators were cleaned, segmented, tagged and used as two corpora for analysis. The two corpora were divided into halves: the first halves to be used as training translation texts(TTT1 and TTT2) and the second as experimental translation texts(ETT1 and ETT2) whose translators were assumed unknown. Fourteen linguistic properties were explored and compared for significant differences between two training translation texts (TTT1 and TTT2). It eventually discovered five contrastive and differentiative linguistic properties typical of two different translators. Data of the five linguistic properties of two experimental translation texts (ETT1 and ETT2) whose translators were assumed unknown were also acquired and cross-compared with those of ETTs for statistical significance of differences by using Significance Test of Difference. It was found out that the five linguistic properties show no statistical significant difference between TTT1 and ETT1, and between TTT2 and ETT2; while the five properties show highly significant diffe-rence between TTT1 and ETT2, TTT2 and ETT1, and ETT2 and TTT2. Thus, it can be concluded that ETT1 and TTT1 belong to the same translator, WKY; and ETT2 and TTT2 belong to the other author, ZJH. The paper has successfully determined the contrastive linguistic properties between two translators, and based on these quantitative linguistic properties, ideally recognized the translators of experimental texts. The paper provides a new method for the research of different translation styles, translators’ styles and translatorship recognition or even identification, which is intended to improve the accuracy, objectivity and explai-nability of the traditional studies of translation and translator styles.
translatorship recognition; quantitative linguistic properties; significance test of difference
*本文系教育部人文社科研究項目“中醫漢英平行語料庫的構建與應用研究”(15YJC740127)和“在線機譯與人工翻譯的語言計量特征對比”(15YJA740016)的階段性成果。
*蔣躍為本文通訊作者。
H059
A
1000-0100(2016)03-0095-7
10.16263/j.cnki.23-1071/h.2016.03.019
定稿日期:2016-03-01
【責任編輯孫 穎】
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
