一種不完備混合數據集成聚類算法
2016-10-13 03:51:15史倩玉梁吉業趙興旺
計算機研究與發展 2016年9期
關鍵詞:方法
史倩玉 梁吉業 趙興旺
(山西大學計算機與信息技術學院 太原 030006)(計算智能與中文信息處理教育部重點實驗室(山西大學) 太原 030006)
?
一種不完備混合數據集成聚類算法
史倩玉梁吉業趙興旺
(山西大學計算機與信息技術學院太原030006)(計算智能與中文信息處理教育部重點實驗室(山西大學)太原030006)
(ljy@sxu.edu.cn)
集成聚類技術由于具有較好的泛化能力,目前引起了研究者的高度關注.已有研究主要關注數值型完備數據的集成聚類問題.然而,實際應用中面臨的數據往往是兼具數值屬性和分類屬性共同描述的混合型數據,而且通常帶有缺失值.為此,針對不完備混合數據提出了一種集成聚類算法,首先利用3種缺失值填充方法對不完備混合數據進行完備化處理;其次在3種填充后的不同完備數據集上分別多次執行K-Prototypes算法產生基聚類結果;最后對基聚類結果進行集成.在UCI真實數據集上與傳統聚類算法通過實驗進行了比較分析,實驗結果表明提出的算法是有效的.
集成聚類;不完備數據;混合數據;缺失值填充;K原型聚類算法
聚類分析是針對給定的數據集,根據元素之間的相似性度量自動將相似的元素劃分到同一組,使得組內的元素相似性達到最大而組間元素的相似性達到最小的過程.目前,聚類分析技術已經在生物信息學、社會網絡、圖像處理等領域得到了廣泛的應用[1].
目前,研究者針對不同應用領域已經提出了許多聚類算法[2-3],但是已有算法存在一定的局限性.例如,針對同一數據集算法在不同參數設置下會得到不同的聚類結果,或者是傳統的聚類算法在復雜結構的數據集上很難得到有效的聚類結果.
針對這些問題,研究者提出了聚類集成的方法[4-6].聚類集成的宗旨是合并某個數據集的多重“基聚類”結果,將其轉化成統一的、綜合的最終聚類結果,其主要包括3個階段:生成基聚類、獲取集成關系和確定最終聚類[7].例如,文獻[4]介紹的CSPA算法是基于共協關系矩陣生成一個無向帶權圖,然后利用METIS算法對圖進行分割從而得到最終的一致性聚類結果.Fred等人在文獻[5]中提出的EAC算法同樣基于共協關系矩陣,將該矩陣作為層次聚類算法的輸入得到最終聚類結果.文獻[6]構造了一個對象和類的加權二部圖,運用譜聚類劃分該圖確定最終聚類.然而,現有的方法主要針對數值型屬性或分類型屬性單一類型的完備數據進行集成聚類.近年來,針對完備混合型數據的集成聚類問題,國內外學者已經開展了一些探索性的工作[8-10].文獻[8]提出的混合數據集成方法首先分別對數值型屬性和分類型屬性部分進行聚類,然后將以上聚類結果看成是分類型數據,在其上應用分類型數據聚類算法來進行聚類集成并得到最終聚類結果.為了避免直接計算混合型數據間相似性的難題,文獻[10]利用聚類集成技術產生混合數據間的相似性矩陣,最后基于此矩陣應用譜聚類算法得到混合數據聚類結果.但是,在實際應用中,面臨的數據不僅是由數值型屬性和分類屬性共同描述的混合型數據,而且通常帶有缺失值,是一種不完備混合數據.因此,如何針對不完備混合數據進行集成聚類就顯得尤為必要.
為了解決這一問題,本文提出了一個基于缺失值填充的不完備混合數據的集成聚類算法.1)為了產生基聚類數據源的多樣性,利用3種缺失值填充方法對缺失數據進行填充;2)分別針對每種填充方法得到的完備數據多次執行K原型(K-Prototypes)聚類算法[11],從而形成一系列基聚類結果;3)構造一個相似度矩陣合并基聚類,進而通過集成技術得到最終的聚類結果.在UCI真實數據集上與傳統聚類算法進行了實驗比較分析,實驗結果表明本文提出的算法是有效的.
1 相關工作
本節首先對本文中使用的缺失值填充方法及K-Prototypes聚類算法進行介紹.
1.1缺失值填充方法
針對缺失數據的處理問題,國內外學者提出了許多不同策略,其中填充法是一種最常用的技術[12].填充法利用數據集中的完備數據對每個缺失值進行估計,從而達到非完備數據完備化的目的.目前,研究者已經提出了多種填充方法,其中,平均值填充法及以K最近鄰為基礎的填充法由于簡單有效得到了廣泛的應用[13-16].下面分別對常用的3種缺失值填充方法進行介紹.
1) 平均值填充法
由于數值型屬性和分類型屬性的差異性,下面將分別對不同屬性下缺失值的填充方法進行描述.如果缺失值對應的屬性為分類型屬性,根據統計學中眾數(modes)的原理,用該屬性下非缺失值樣本中取值頻數最多的值來對缺失值進行填充;如果缺失值對應的屬性為數值型屬性,則利用該屬性下所有完備樣本取值的平均值(means)來對缺失值進行填充.該方法利用現有完備數據的多數信息來推測缺失值,以最可能的取值來對缺失值進行填充,具有簡單易實現的優點.但是,由于所有的填充值都集中于眾數或均值,填充后的數據集在分布上容易形成尖峰,進而出現變量分布扭曲的問題,導致樣本之間差異的弱化.
2)K最近鄰填充法KNN
在K最近鄰填充法中,一個樣本的缺失值是通過找到與該樣本最相似的K個完備樣本,利用這K個完備樣本的相關信息對缺失值進行填充.
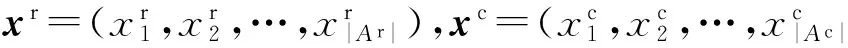
(1)
樣本x和y在分類型屬性上的相異度DAc可表示為
(2)
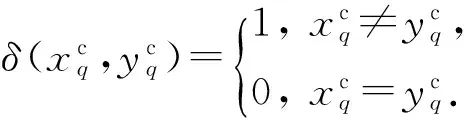
樣本x和y的相異度計算如下:
(3)
其中,M(·)是一個函數,可以將樣本x和y在數值型屬性上的相異度DAr和分類型屬性上的相異度DAc有效地結合起來以度量它們之間的相異性.
基于上述距離度量公式,K最近鄰填充法主要流程描述如下:
算法1.K最近鄰填充算法KNN.
Step1. 將數據集D劃分為2個子集Dm和Dc,其中Dm表示由包括屬性值缺失的樣本組成的樣本子集,Dc表示完備樣本組成的樣本子集.
Step2. 從集合Dm中提取出一個帶有缺失值的樣本xm.
Step2.1. 將帶有缺失值的樣本xm分成屬性值完備和屬性值缺失2部分.
Step2.2. 僅使用樣本xm中屬性值完備的部分來計算該樣本和Dc集中所有樣本的相異性.假設Dc集中的一個完備樣本為xc,基于式(1)(2),利用以下公式
D(xm,xc)=
(4)
來計算xm和xc的相異性.
Step2.3. 從完備樣本集Dc中選擇與帶有缺失值的樣本xm相異度最小的前K個完備樣本組成集合DK.
Step2.4. 如果樣本向量xm的缺失值對應的屬性為分類型屬性,用該屬性下與xm相異度最小的K個樣本DK中眾數對缺失值進行填充;如果缺失值對應的屬性為數值型屬性,則取該屬性下DK中K個樣本的平均值來對缺失值進行填充.
Step3. 重復進行Step2,直至集合Dm中所有樣本的缺失值都填充完畢.
作為一種填充方法,K最近鄰填充法考慮了樣本之間的相關性,填充結果較為準確,而且該方法具有簡單易實現、計算高效的優點.然而,在屬性值缺失較多的情況下,該方法的性能和準確性具有一定的缺陷.
3) 有序最近鄰填充法SKNN
有序最近鄰填充法SKNN是在KNN算法的基礎上做了進一步的改進,算法主要流程如下:
算法2. 有序最近鄰填充算法SKNN.
Step1. 將數據集D劃分為2個子集Dm和Dc,其中,Dm表示由存在屬性值缺失的樣本組成的樣本子集,Dc表示完備樣本子集.
Step2. 將集合Dm中所有帶有缺失值的樣本按照缺失率(帶有缺失值的屬性個數占樣本屬性總數的比例)由低到高的順序進行排序.
Step3. 從集合Dm中選擇一個缺失率最低的樣本,利用K最近鄰法KNN從完備樣本子集Dc中選出與該樣本相異度最小的前K個完備樣本對其缺失值進行填充.
Step4. 把填充后得到的完備樣本加入完備數據子集Dc中.
Step5. 重復進行Step3~Step4,直至集合Dm中所有帶有缺失值的樣本填充完畢.
SKNN算法在填充過程中可以使用先前缺失數據填充得到的完備樣本信息.與KNN填充算法相比,SKNN填充算法明顯提高了對數據的利用率,在數據缺失率較大、完備數據樣本相對匱乏的情況下,SKNN填充算法采取邊填充邊擴展完備數據樣本的策略,充分地利用了缺失數據的信息,使得填充效果更加符合客觀事實,填充效果更為合理.
1.2K-Prototypes算法介紹
文獻[11]提出的K-Prototypes聚類算法是處理混合型數據最經濟有效的一種算法.該算法在度量對象與類中心的相異性的過程中同時考慮了分類型屬性和數值型屬性部分的貢獻.其中,對象與類中心在分類型屬性下的相異性通過0-1簡單匹配來度量,數值型屬性下的相異性由歐氏距離表示.如果對象為分類型數據,則該算法將退化為K-Modes算法[11];類似地,如果對象為數值型數據,則該算法退化為K-Means算法[17].因此,K-Prototypes算法實質上同時結合K-Modes算法和K-Means算法來解決現實世界中廣泛存在的混合型數據的聚類問題.
假設在聚類過程中,由n個樣本組成的混合型數據集合D={x1,x2,…,xn}在當前聚類中被劃分為k個類Ck={C1,C2,…,Ck},類原型為Zk={z1,z2,…,zk},基于式(1)(2),利用以下公式
(5)
來度量樣本xi(1≤i≤n)和類原型zj(1≤j≤k)之間的相異性[18].
基于以上的相異性度量,K-Prototypes聚類算法描述如下:
算法3.K-Prototypes聚類算法.
Step1. 從數據集中隨機選取k個不同的樣本作為初始聚類中心.
Step2. 對數據集中的每個樣本,根據式(5)計算其與每個類原型的相異性,將樣本分配到與其最近的類原型所代表的類中.
Step3. 對于每個聚類結果,重新計算聚類原型.
Step4. 根據式(5)重新計算每個樣本到新的類原型之間的相異性,根據最近鄰原則重新分配樣本.
Step5. 重復進行Step3~Step4,直到各個聚類中的樣本不再發生變化為止.
2 不完備混合數據集成聚類算法
不完備混合數據的集成聚類算法主要分為4個階段:第1階段分別使用1.1節介紹的3種不同的缺失值填充方法對缺失值進行填充得到完備數據;第2階段分別在填充后的完備數據集上基于隨機產生初始類中心的方式多次進行K-Prototypes聚類算法,從而得到基聚類結果集Π(D);第3階段合并基聚類結果構造相似度矩陣SMn×n;第4階段基于相似度矩陣運用層次聚類方法進行集成得到最終的聚類結果.本文算法的框架示意圖如圖1所示:
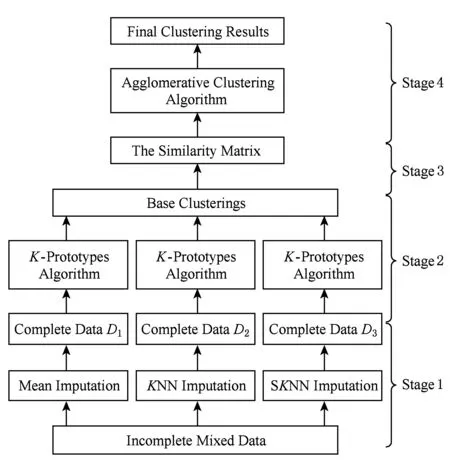
Fig. 1 The framework of the proposed algorithm.圖1 本文算法框架
2.1生成基聚類
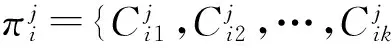
2.2獲取集成關系
對于處理多個基聚類結果,現有的方法主要利用基聚類結果所提供的信息來得到數據集中樣本之間的關聯,構造一個相似度矩陣,然后基于此矩陣進行聚類集成,進而獲得最終的聚類結果.
(6)
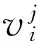
2) 根據所有基聚類產生的關系矩陣就可以得到樣本之間的相似度矩陣SMn×n,其中樣本xp和xq(1≤p,q≤n)之間的相似度表示為
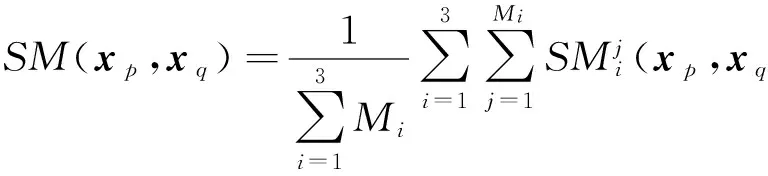
(7)
該矩陣的每個元素值由所有基聚類產生的關系矩陣對應元素的均值得到,反映了樣本之間的相似度.傳統的相似度度量方法往往完全依靠屬性值來衡量樣本之間的相似度,使得聚類結果不夠準確,充分利用基聚類提供的信息來度量樣本之間的相似性具有一定的有效性.
2.3確定最終聚類
在獲取到集成關系的基礎上,利用層次聚類算法來確定最終聚類.本文采用層次聚類算法自底向上的策略,首先將每個樣本作為一個類,然后將2個相似度最大的類合并為一個類,重復循環此步驟,直到合并為k個類.
在層次聚類過程中假設有2個類C和C′,它們之間常用的3種相似性度量如下:
1) 單鏈(single link)方法.由2個類中相似度最大的2個樣本決定.
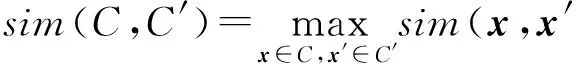
(8)
2) 全鏈(complete link)方法.由2個類中相似度最小的2個樣本決定.
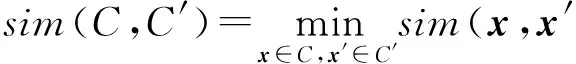
(9)
3) 組平均(average link)方法.由2個類中所有樣本點相似度的平均值決定.
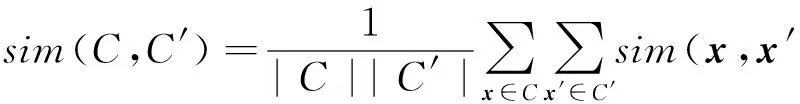
(10)
其中,樣本之間的相似度sim(x,x′)為相似度矩陣SMn×n中的對應元素值.
2.4不完備混合數據的集成聚類算法
基于以上對不完備混合數據的集成聚類算法各個主要階段的介紹,本文算法描述如下:
算法4. 不完備混合數據集成聚類算法.
輸入:帶有缺失值的數據集D、聚類個數k;
輸出:最終聚類結果π*(D).
Step1. 對數據集D分別運用平均值填充法、KNN填充法、SKNN填充法填充得到完備數據集D1,D2,D3.
Step2. 對Di(1≤i≤3)分別執行Mi次K-Prototypes聚類算法,得到基聚類結果集Π(D).
Step3. 根據式(7),計算樣本與樣本之間的相似度矩陣SMn×n.
Step4. 基于相似度矩陣SMn×n,分別根據式(8)(9)(10)運行層次聚類算法得到最終的聚類結果π*(D).
3 實驗分析
3.1實驗數據
為了驗證本文提出算法的有效性,我們從UCI真實數據集中分別選取了數值型、分類型和混合型3種不同屬性特征的不完備數據集進行了測試.數據集的信息描述如表1所示:
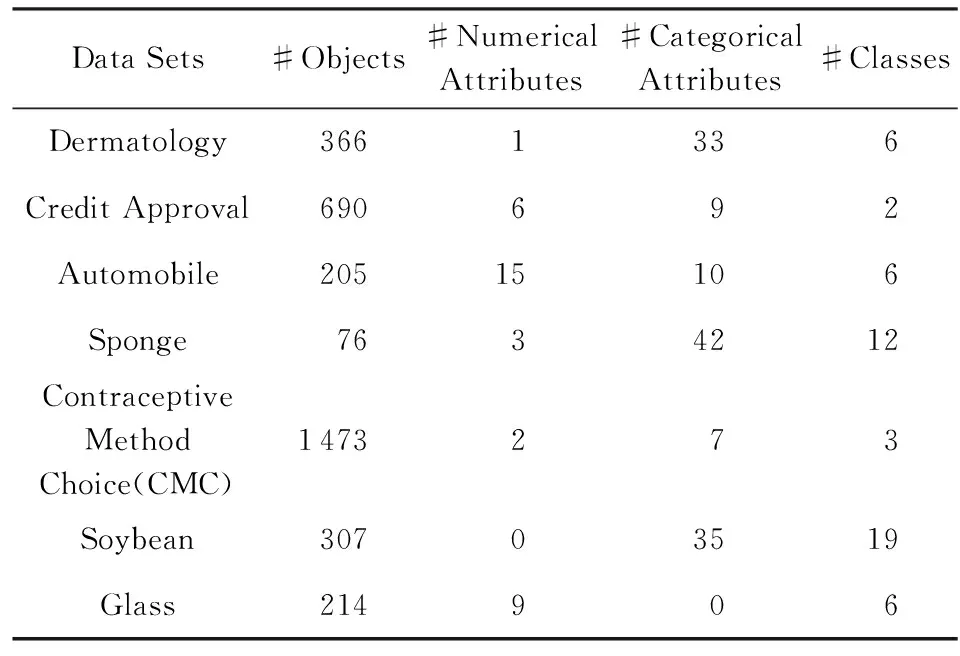
Table 1 The Summary of UCI Datasets
3.2聚類有效性度量指標
本文分別采用分類準確率(classification accuracy,CA)[19]、調整蘭德系數(adjusted rand index,ARI)[19],標準互信息(normalized mutual information,NMI)[4]三種評價指標對聚類結果進行評價.
(11)
其中,k為類個數,ai表示正確聚類為對應類別Ci的樣本個數,n表示樣本總數.
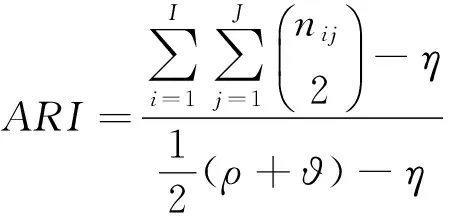
(12)
其中,
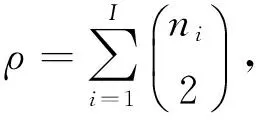
(13)
(14)
其中,nij表示聚類結果的第i個簇中包含原數據集類標簽為j的樣本總數,ni表示聚類結果的第i個簇的樣本總數,nj表示原數據集類標簽為j的樣本總數,n表示樣本總數;I和J分別表示聚類得到的簇個數和原數據集的類個數.
CA,ARI,NMI的值越大,表明聚類結果越好.
在下面的實驗中,我們將本文提出的算法根據層次聚類過程中所選取的類間相似度度量方法分為single-link集成(SLCE)、complete-link集成(CLCE)、average-link集成(ALCE).將3種集成方法分別與用平均值填充、KNN填充、SKNN填充得到的完備數據進行單一的K-Prototypes聚類(分別簡記為Mean_SK,KNN_SK,SKNN_SK)所得的聚類結果進行比較.
在實驗過程中,針對表1所描述的CMC和Glass兩個完備數據集,分別隨機刪除10%的屬性值作為缺失數據.以下實驗結果均為同一方法在相同的數據集上分別運行20次的CA,ARI,NMI的平均值和方差.其中本文提出的算法分別在每種填充方法得到的完備數據上進行50次K-Prototypes聚類算法來得到基聚類.
3.3實驗結果分析
當KNN和SKNN填充法選取的最近鄰個數K=5時,本文提出算法和其他聚類方法在不同評價指標下的實驗結果的平均值及方差如表2~4所示:
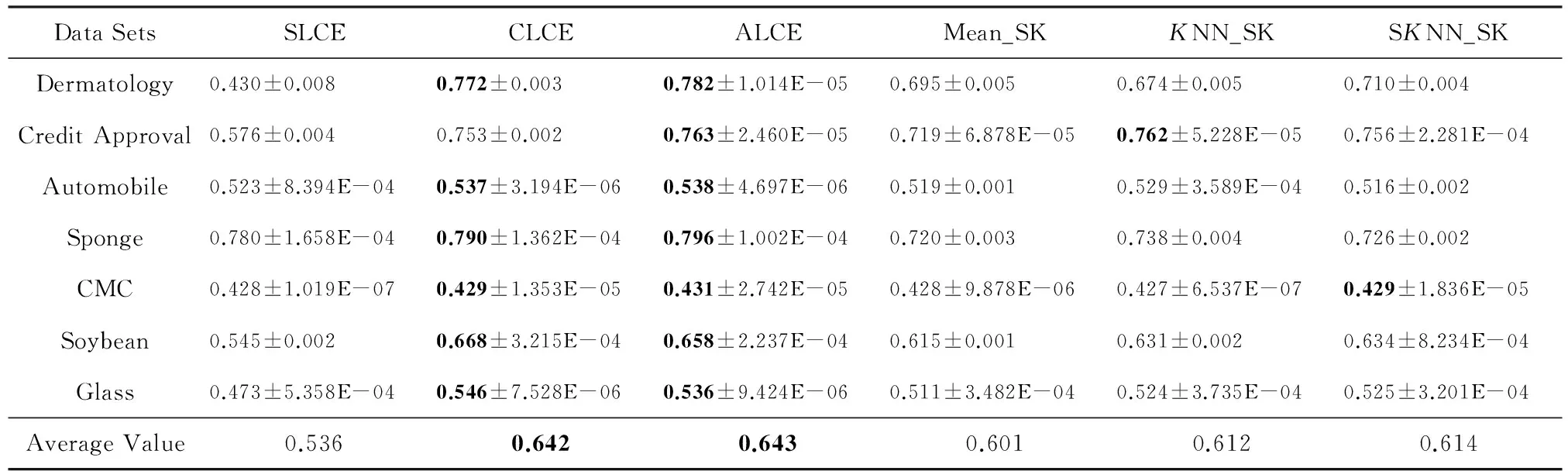
Table 2 Clustering Results of Different Algorithms with Respect to Mean±Var of CA
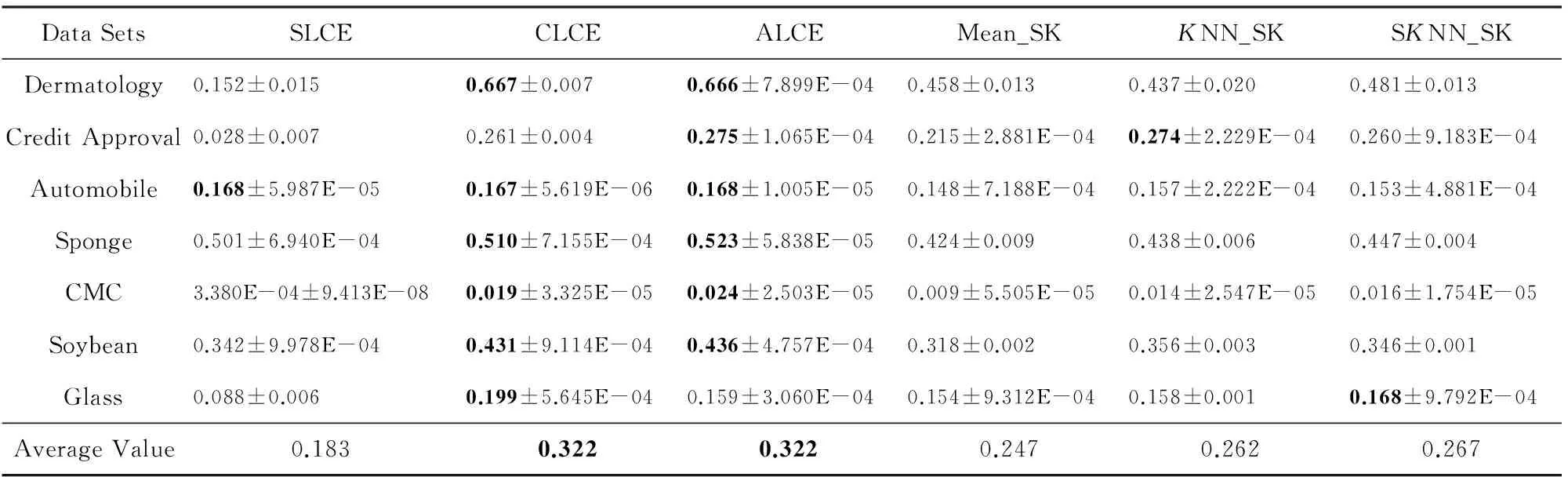
Table 3 Clustering Results of Different Algorithms with Respect to Mean±Var of ARI
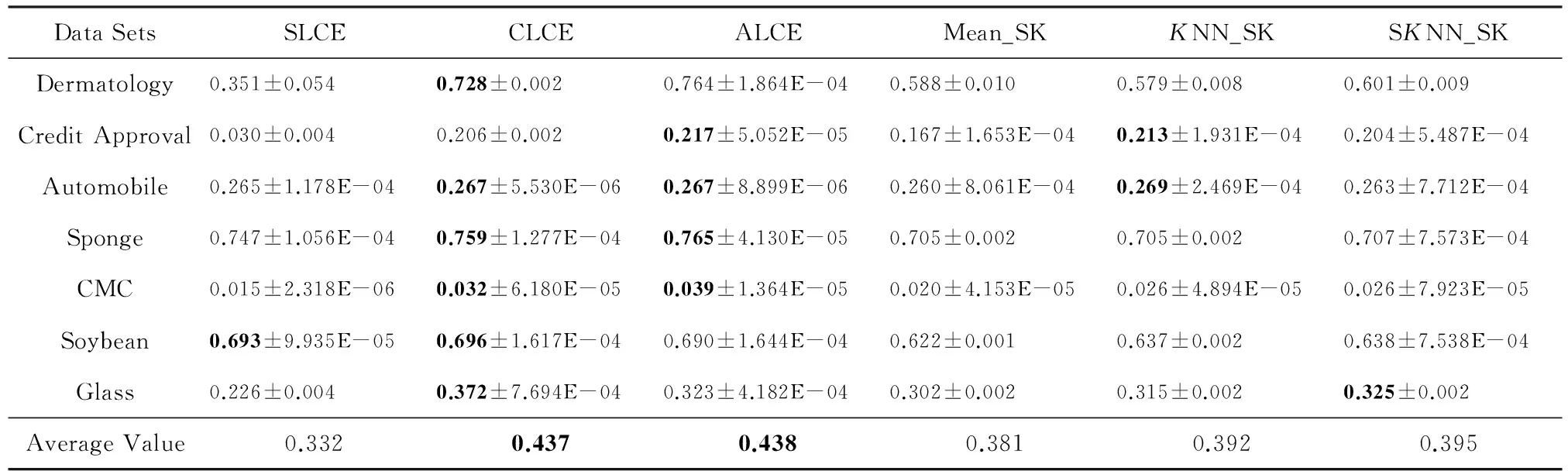
Table 4 Clustering Results of Different Algorithms with Respect to Mean±Var of NMI
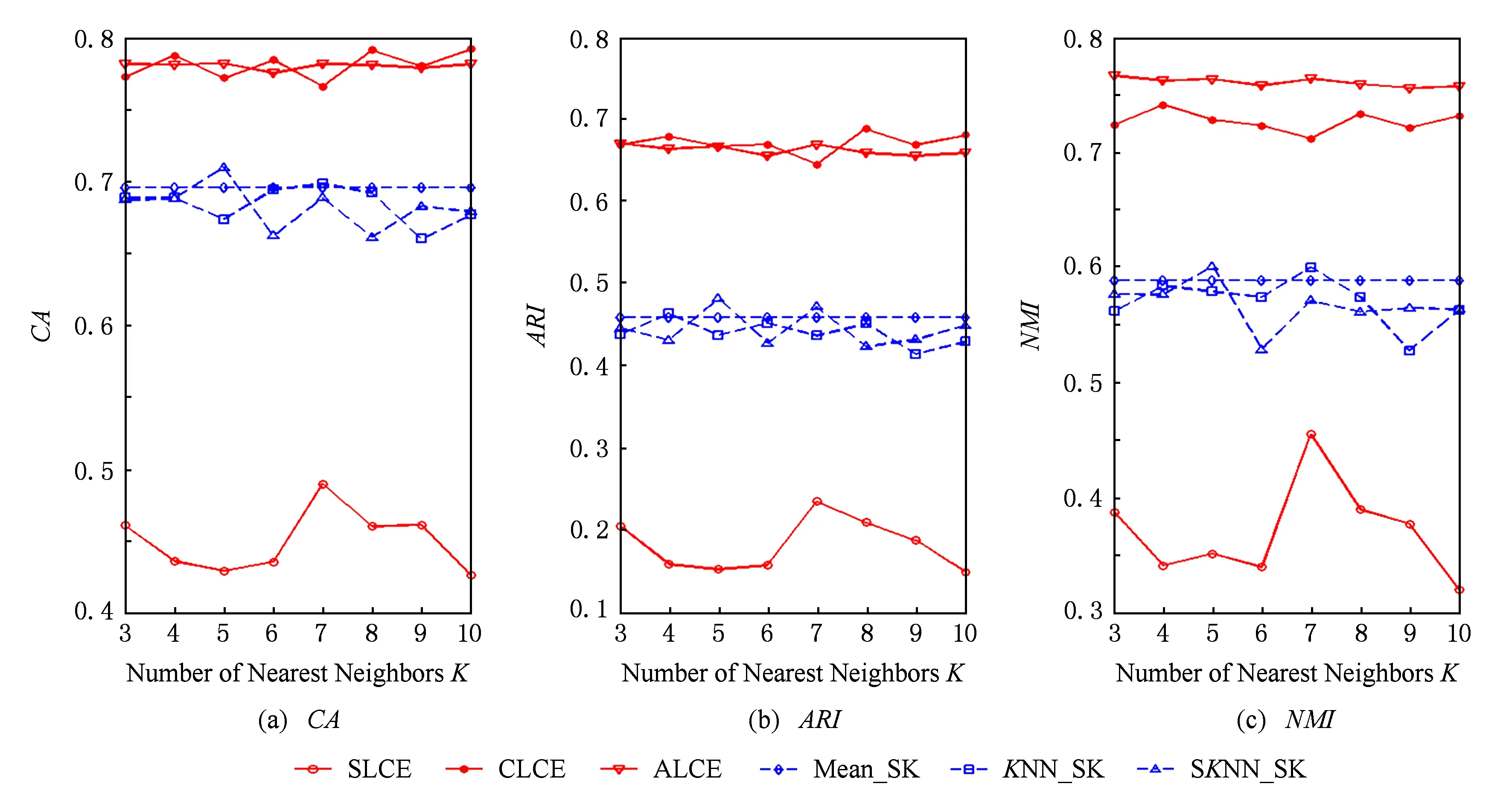
Fig. 2 The performance of different algorithms with respect to different number of neighborhood on the Dermatology dataset.圖2 數據集Dermatology上不同算法的聚類結果
其中,在每一數據集上不同方法的實驗結果的最優值和次優值用粗體標識.通過表中數據分析可知,不論選取哪種指標作為評價標準,對于UCI中7個數據集,在多數情況下average-link集成和complete-link集成的聚類準確性優于其他算法,2種方法在所有數據集上的平均值都能達到最優值或次優值.average-link集成的性能比complete-link集成略好,這是因為complete-link集成確定類間距離時僅考慮有特點的數據,average-link集成考慮了類內數據的整體特點,因此在多數情況下,average-link集成得到的聚類準確性比較高,而complete-link集成表現出的性能次之.single-link集成確定類間距離時也只考慮了有特點的數據,而且沒有考慮類內部的結構,所以表現出的聚類結果較差.此外,average-link集成在7個數據集上的方差都幾乎為0,說明該方法具有較強的穩定性.
當KNN和SKNN填充法選取的最近鄰個數K取不同值時,本文提出算法和其他聚類方法的實驗結果如圖2~8所示.由圖2~8可知:
1) average-link集成和complete-link集成受到最近鄰個數變化的影響較小,它們在多數情況下都能取到最優和次優的聚類結果.average-link集成在數據集Dermatology,Credit Approval,Sponge,CMC上的聚類準確度最高,在Automobile上的CA值和在Soybean上的ARI值也是較高的.complete-link集成在數據集Dermatology,Sponge,Soybean,Glass上表現出較高的性能,尤其在Glass上,complete-link集成的聚類性能明顯優于average-link集成,這可能是由于Glass數據集的類結構比較緊湊,complete-link集成是取2個類中距離最遠的2個樣本點作為2個類的距離,這種集成方法就比較傾向于找到一些緊湊的類,所以該方法在這個數據集上的效果較優.
2) single-link集成除了在Sponge數據集上表現略好以外,在其他數據集上的聚類結果都不理想.這主要是由于single-link度量方法僅僅依靠距離最近的2個樣本點來決定類間的差異性而沒有考慮類內部的結構,因此聚類效果不佳.
3) Mean_SK,KNN_SK,SKNN_SK三種方法除了在Credit Approval數據集上表現較好外,在其他數據集上都明顯不如average-link集成或complete-link集成.這是由于average-link集成和complete-link集成不僅對多次K-Prototypes聚類算法產生的多個基聚類進行集成,而且還將不同填充方法得到的完備數據集也作為產生基聚類的一種方法,這樣就使得基聚類結果集更具有多樣性,聚類結果的準確度也越高.
4) 隨著最近鄰個數K的變化,average-link集成和complete-link集成的實驗結果是比較穩定的,它的性能對最近鄰個數K的變化并不敏感,算法具有一定的魯棒性.總之,average-link集成聚類方法在大多數數據集上都是較好的選擇.
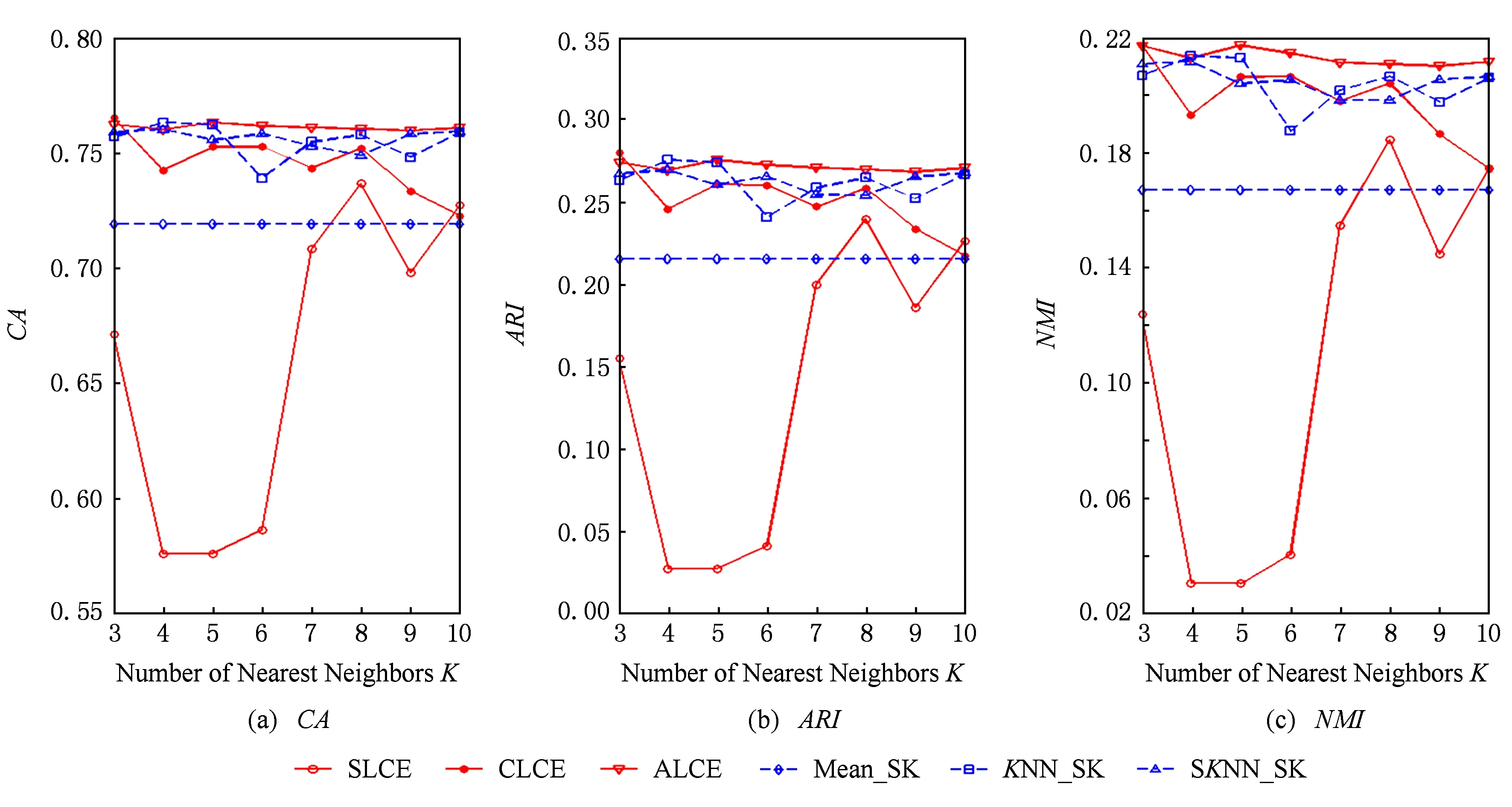
Fig. 3 The performance of different algorithms with respect to different number of neighborhood on the Credit Approval dataset.圖3 數據集Credit Approval上不同算法的聚類結果
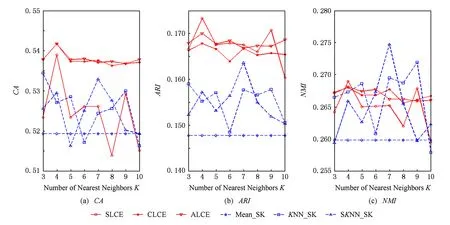
Fig. 4 The performance of different algorithms with respect to different number of neighborhood on the Automobile dataset.圖4 數據集Automobile上不同算法的聚類結果
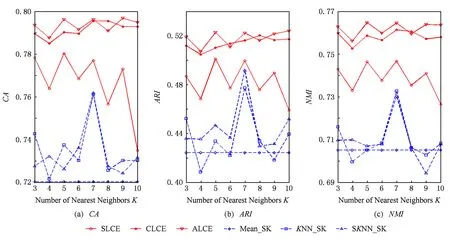
Fig. 5 The performance of different algorithms with respect to different number of neighborhood on the Sponge dataset.圖5 數據集Sponge上不同算法的聚類結果
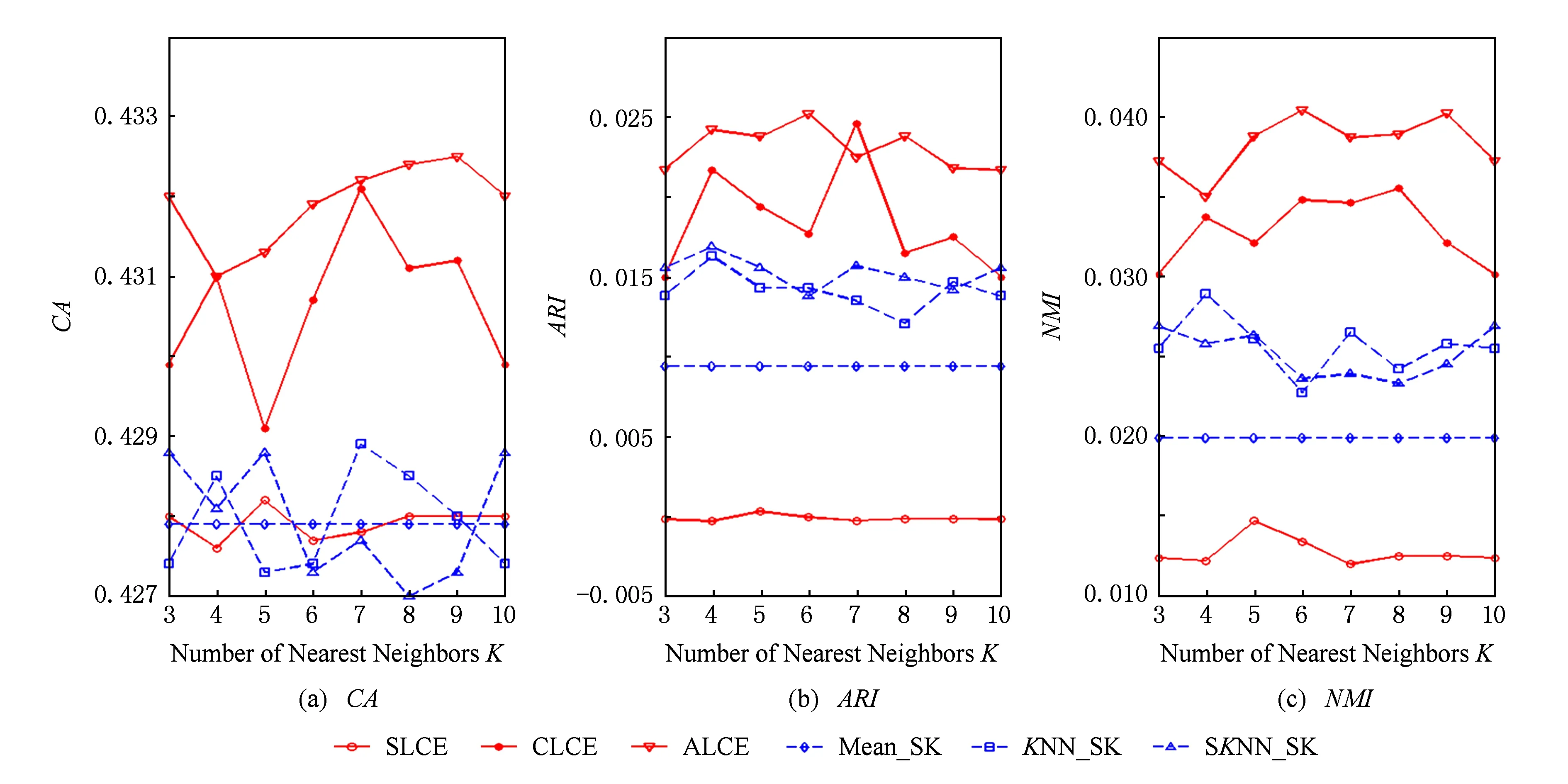
Fig. 6 The performance of different algorithms with respect to different number of neighborhood on the CMC dataset.圖6 數據集CMC上不同算法的聚類結果
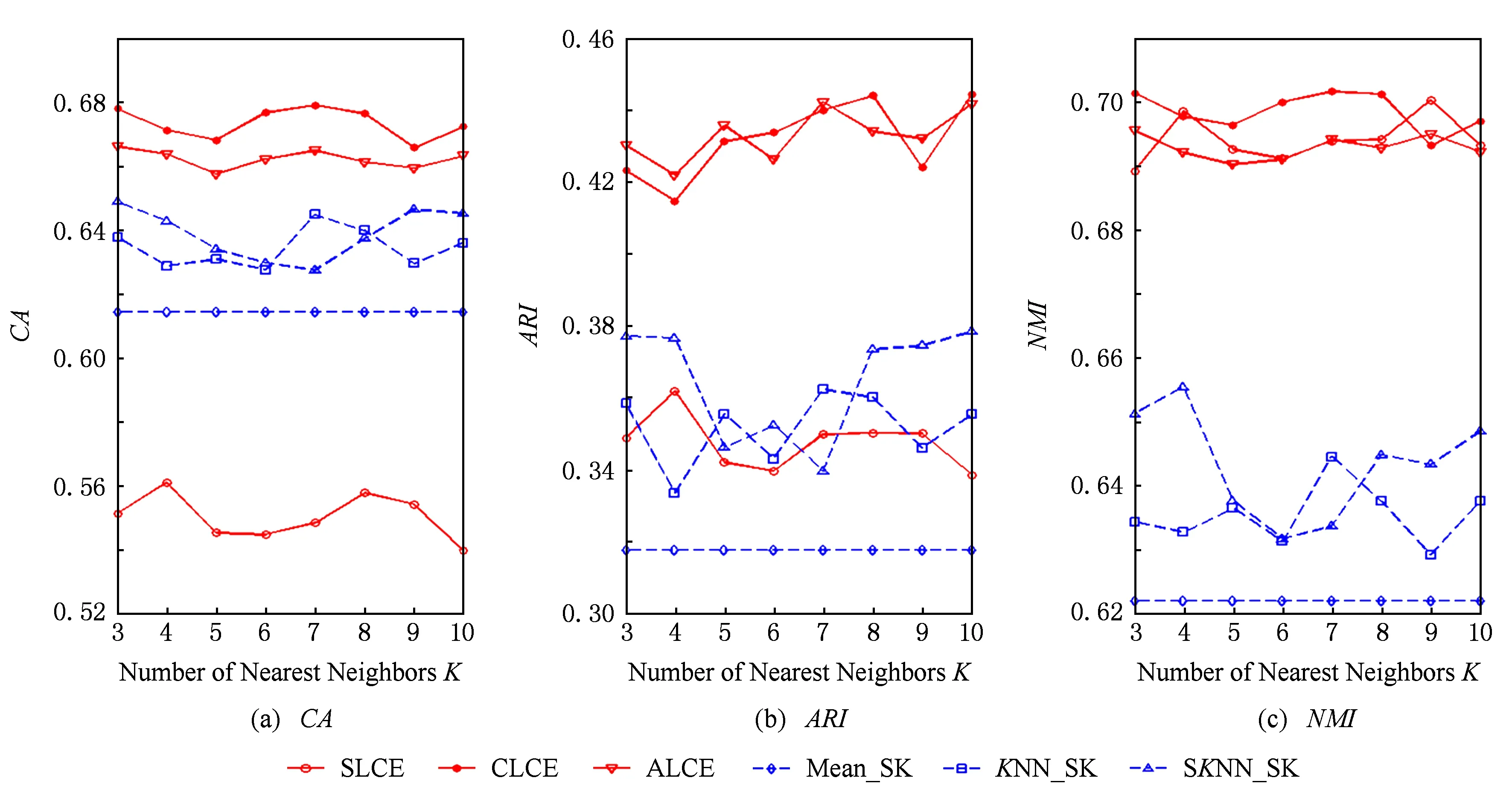
Fig. 7 The performance of different algorithms with respect to different number of neighborhood on the Soybean dataset.圖7 數據集Soybean上不同算法的聚類結果
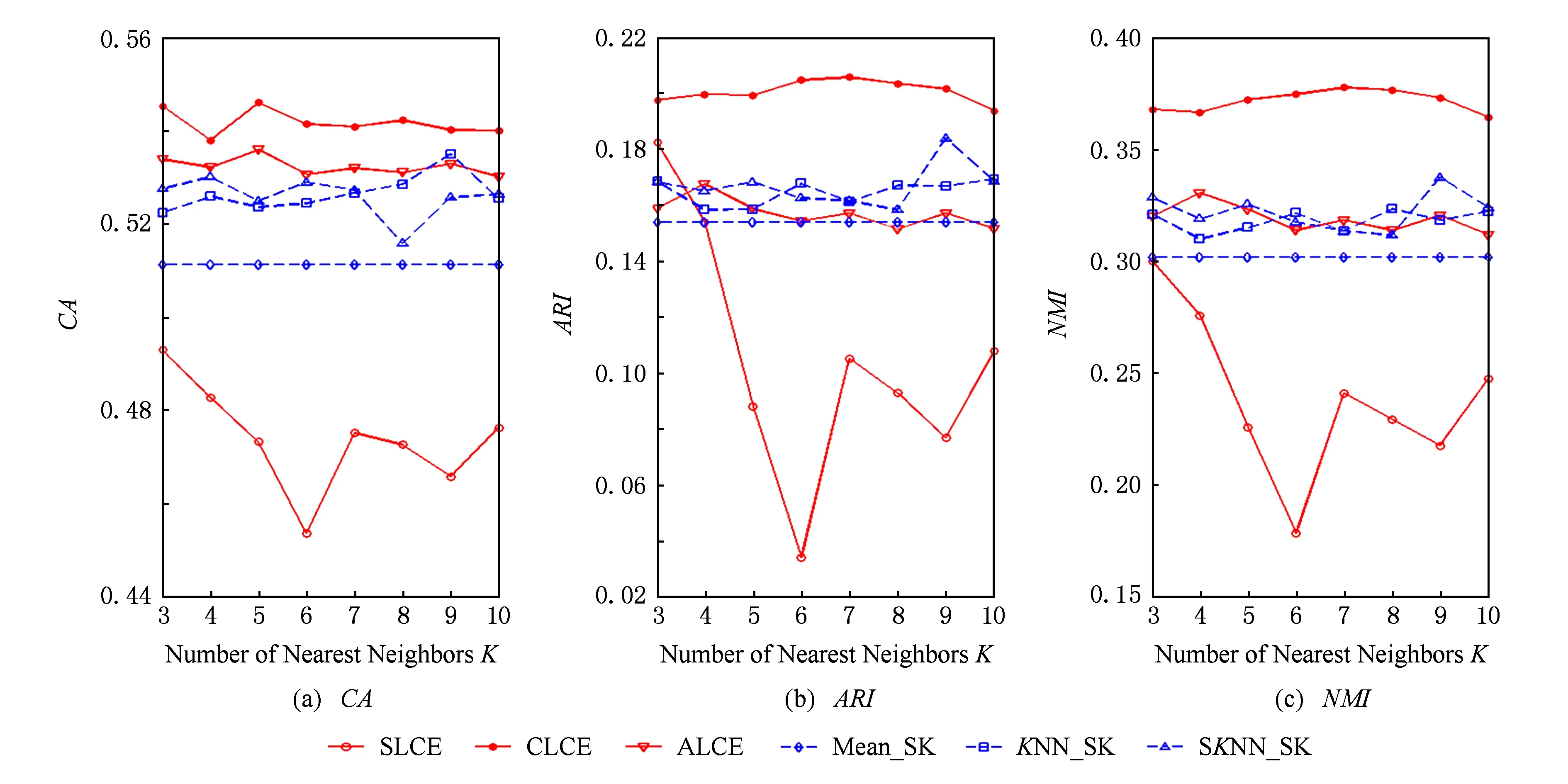
Fig. 8 The performance of different algorithms with respect to different number of neighborhood on the Glass dataset.圖8 數據集Glass上不同算法的聚類結果
4 結 論
本文針對不完備混合數據首先利用3種缺失值填充方法對缺失值進行填充得到完備數據集,有效地克服了單一填充方法帶來的缺陷;其次在3種不同的完備數據集上基于隨機產生初始類中心的方式多次執行K-Prototypes算法,從而形成一系列基聚類結果;最后構造一個相似度矩陣合并這些基聚類,進而利用層次聚類方法進行集成得到最終的聚類結果.在UCI真實數據集上進行了實驗驗證,與傳統聚類算法相比,本文提出的算法可以獲得較高的聚類質量.
然而,目前集成聚類算法面臨著計算量大、時間復雜度較高的問題,在未來的工作中,我們將考慮如何提高算法的計算效率來解決大數據集成面臨的挑戰.
[1]Han Jiawei, Kamber M, Pei Jian. Data Mining: Concepts and Techniques [M]. 3rd ed. San Francisco, CA: Morgan Kaufmann, 2011[2]Sun Jigui, Liu Jie, Zhao Lianyu. Clustering algorithms research [J]. Journal of Software, 2008, 19(1): 48-61 (in Chinese)(孫吉貴, 劉杰, 趙連宇. 聚類算法研究 [J]. 軟件學報, 2008, 19(1): 48-61)[3]Xu Rui, Wunsch D. Survey of clustering algorithm [J]. IEEE Trans on Neural Networks, 2005, 16(3): 645-678[4]Strehl A, Ghosh J. Cluster ensembles: A knowledge reuse framework for combining multiple partitions [J]. Journal of Machine Learning Research, 2002, 3: 583-617[5]Fred A L, Jain A K. Combining multiple clusterings using evidence accumulation [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2005, 27(6): 835-850[6]Iam-On N, Boongoen T. Comparative study of matrix refinement approaches for ensemble clustering [J]. Machine Learning, 2015, 98(12): 269-300[7]Ghosh J, Acharya A. Cluster ensembles [J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2011, 1(4): 305-315[8]He Zengyou, Xu xiaofei, Deng Shengchun. Clustering mixed numeric and categorical data: A cluster ensemble approach[OL]. ArXiv cs0509011, 2005: 1-14 [2015-09-08]. http:arxiv.orgabscs0509011[9]Shaqsi J, Wang Wenjia. A clustering ensemble method for clustering mixed data[C]Proc of the Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2010: 1-8[10]Luo Huilan, Wei Hui. Clustering algorithm for mixed data based on clustering ensemble technique [J]. Computer Science, 2010, 37(11): 234-274 (in Chinese)(羅會蘭, 危輝. 一種基于聚類集成技術的混合型數據聚類算法[J]. 計算機科學, 2010, 37(11): 234-274)[11]Huang Zhexue. Extensions to thek-means algorithm for clustering large data sets with categorical values [J]. Data Mining and Knowledge Discovery, 1998, 2(3): 283-304[12]Wu Sen, Feng Xiaodong, Shan Zhiguang. Missing data imputation approach based on incomplete data clustering[J]. Chinese Journal of Computers, 2012, 35(8): 1726-1738 (in Chinese)(武森, 馮小東, 單志廣. 基于不完備數據聚類的缺失數據填補方法 [J]. 計算機學報, 2012, 35(8): 1726-1738)[13]Qiao Zhufeng, Tian Fengzhan, Huang Houkuan, et al. A comparison study of missing value datasets processing methods [J]. Journal of Computer Research and Development, 2006, 43(Suppl): 171-175 (in Chinese)(喬珠峰, 田鳳占, 黃厚寬, 等. 缺失數據處理方法的比較研究 [J]. 計算機研究與發展, 2006, 43(增刊): 171-175)
[14]Silva L O, Zárate L E. A brief review of the main approaches for treatment of missing data [J]. Intelligent Data Analysis, 2014, 18(6): 1177-1198[15]Acock A C. Working with missing values [J]. Journal of Marriage and Family, 2005, 67(4): 1012-1028[16]Batista G E, Monard M C. An analysis of four missing data treatment methods for supervised learning [J]. Applied Artificial Intelligence, 2003, 17(5): 519-533[17]Macqueen J. Some methods for classification and analysis of multivariate observations [C]Proc of the 5th Berkeley Symp on Mathematical Statistics and Probability. Berkeley, CA: University of California Press, 1967: 281-297[18]Liang Jiye, Zhao Xingwang, Li Deyu, et al. Determining the number of clusters using information entropy for mixed data [J]. Pattern Recognition, 2012, 45(6): 2251-2265[19]Liang Jiye, Bai Liang, Dang Chuangyin, et al. Thek-means-type algorithms versus imbalanced data distributions [J]. IEEE Trans on Fuzzy Systems, 2012, 20(4): 728-745

Shi Qianyu, born in 1992. Master candidate. Student member of China Computer Federation. Her main research interests include data mining and machine learning (m15735170907@163.com).

Liang Jiye, born in 1962. Professor and PhD supervisor. Distinguished member of China Computer Federation. His main research interests include granular computing, data mining and machine learning (ljy@sxu.edu.cn).

Zhao Xingwang, born in 1984. PhD candidate. Member of China Computer Federation. His main research interests include data mining and machine learning (zhaoxw84@163.com).
A Clustering Ensemble Algorithm for Incomplete Mixed Data
Shi Qianyu, Liang Jiye, and Zhao Xingwang
(SchoolofComputerandInformationTechnology,ShanxiUniversity,Taiyuan030006)(KeyLaboratoryofComputationalIntelligenceandChineseInformationProcessing(ShanxiUniversity),MinistryofEducation,Taiyuan030006)
Cluster ensembles have recently emerged a powerful clustering analysis technology and caught high attention of researchers due to their good generalization ability. From the existing work, these techniques held great promise, most of which generate the final results for complete data sets with numerical attributes. However, real life data sets are usually incomplete mixed data described by numerical and categorical attributes at the same time. And these existing algorithms are not very effective for an incomplete mixed data set. To overcome this deficiency, this paper proposes a new clustering ensemble algorithm which can be used to ensemble final clustering results for mixed numerical and categorical incomplete data. Firstly, the algorithm conducts completion of incomplete mixed data using three different missing value filling methods. Then, a set of clustering solutions are produced by executingK-Prototypes clustering algorithm on three different kinds of complete data sets multiple times, respectively. Next, a similarity matrix is constructed by considering all the clustering solutions. After that, the final clustering result is obtained by hierarchical clustering algorithms based on the similarity matrix. The effectiveness of the proposed algorithm is empirically demonstrated over some UCI real data sets and three benchmark evaluation measures. The experimental results show that the proposed algorithm is able to generate higher clustering quality in comparison with several traditional clustering algorithms.
clustering ensemble; incomplete data; mixed data; missing value imputation;K-Prototypes clustering algorithm
2015-06-19;
2015-11-16
國家自然科學基金重點項目(61432011);國家自然科學基金項目(61573229,61502289);山西省科技基礎條件平臺建設項目(2012091002-0101);山西省自然科學基金項目(201601D202039);山西省研究生教育創新項目(2016SY002)
趙興旺(zhaoxw84@163.com)
TP391
This work was supported by the Key Program of the National Natural Science Foundation of China(61432011), the National Natural Science Foundation of China(61573229, 61502289), the Construction Project of the Science and Technology Basic Condition Platform of Shanxi Province(2012091002-0101), the Natural Science Foundation of Shanxi Province of China (201601D202039), and the Graduate Education Innovation Project of Shanxi Province (2016SY002).
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
