結構稀疏表示分類目標跟蹤算法*
2016-10-12 02:39:03侯躍恩李偉光
計算機與生活 2016年7期
侯躍恩,李偉光
1.嘉應學院 計算機學院,廣東 梅州 514000 2.華南理工大學 機械與汽車工程學院,廣州 510000
結構稀疏表示分類目標跟蹤算法*
侯躍恩1+,李偉光2
1.嘉應學院 計算機學院,廣東 梅州 514000 2.華南理工大學 機械與汽車工程學院,廣州 510000
HOU Yue?en,LI Weiguang.Structured sparse representation classification object tracking algorithm.Journal of Frontiers of Computer Science and Technology,2016,10(7):1035-1043.
為提高目標跟蹤算法在復雜條件下的魯棒性和準確性,研究了一種基于貝葉斯分類的結構稀疏表示目標跟蹤算法。首先通過首幀圖像獲得含有目標與背景模板的稀疏字典和正負樣本;然后采用結構稀疏表示的思想對樣本進行線性重構,獲得其稀疏系數;進而設計一款貝葉斯分類器,分類器通過正負樣本的稀疏系數進行訓練,并對每個候選目標進行分類,獲得其相似度信息;最后采用稀疏表示與增量學習結合的方法對稀疏字典進行更新。將該算法與其他4種先進算法在6組測試視頻中進行比較,實驗證明了該算法具有更好的性能。
目標跟蹤;粒子濾波;稀疏表示;字典;貝葉斯分類
1 引言
目標跟蹤算法在視覺機器人控制、輔助駕駛、智能監控、人機交互等許多領域中有廣泛的應用。但是,在實際應用中往往存在目標形態變化,光照條件變化,目標被遮擋和復雜背景的影響,開發一種具有魯棒性、準確性和實時性的目標跟蹤算法仍然具有很大的難度[1-2]。目標跟蹤算法的研究主要集中在運動模型和表示模型兩方面。運動模型用于在視頻的連續幀中預測目標的狀態,主要方法有卡爾曼濾波[3]和粒子濾波[4]等。表示模型用于對樣本的特征進行數學建模,并計算樣本與真實目標的相似度。近年來,一種名為稀疏表示的外觀建模技術在模式識別領域得到了廣泛關注[5-7]。稀疏表示受人類視覺系統的工作原理啟發而提出,其主要思想是對樣本進行線性重構,并通過約束項限制重構系數的稀疏度。Wright等人[5]將該技術應用于人臉識別任務中,取得了理想的識別效果。Agarwal等人[6]在物體識別的算法中使用了稀疏表示技術,有效提高了識別的準確率,同時使識別對噪聲干擾有更強的魯棒性。Song等人[7]研究了一種基于稀疏表示技術的遙感圖像分類方法,有效提高了分類性能。在2009年IEEE計算機視覺和模式識別國際會議上,Mei等人[8]首次將稀疏表示技術應用于目標跟蹤算法的設計中,提出了一種L1跟蹤算法。算法使用目標模板和瑣碎模板構建稀疏字典,用稀疏字典對候選目標進行線性重構,并對其重構系數進行?1最小化約束。該算法在光照條件變化或噪聲干擾時有較強的魯棒性,但解稀疏方程需要較大的運算量,影響算法的實時性,采用瑣碎模板構建稀疏字典雖然在一定程度上降低了目標遮擋對跟蹤的影響,但增加了算法對干擾目標的敏感性。由于稀疏表示技術在目標跟蹤上取得了良好的效果,研究人員提出了許多改進算法提高跟蹤性能。Wang等人[9]將主元分析法與稀疏表示相結合構建目標方程,并設計了一種迭代算法對方程進行求解,提高了跟蹤的穩定性。文獻[10]在使用模板字典重構候選目標的同時,采用候選目標重構模板字典,將跟蹤問題轉換為目標方程優化問題,提高了算法的性能。但是文獻[9-10]采用樣本的整體構建稀疏方程,只考慮了樣本的整體信息,沒有考慮樣本的局部信息,跟蹤準確性有進一步提升的空間。
Xu等人[11]采用樣本分塊的思想,開發了一種自適應本地結構稀疏表示模型,該模型既考慮了樣本的全局信息,又考慮了樣本的局部信息,并從候選目標的稀疏系數里提取相似度信息,提高了跟蹤的魯棒性和準確性。在此基礎上,Hou等人[12]進一步提取重構殘差里的相似度信息,采用排名的思想將其與稀疏系數里的相似度信息進行融合,提高了算法的魯棒性。文獻[11]和[12]均采用Alignment-Pooling方法提取稀疏系數中的相似度信息,該方法只考慮了與候選目標對應的分塊的稀疏系數,而忽略了其他稀疏系數里的相似度信息;同時,該方法不具備對稀疏系數的學習能力,跟蹤魯棒性有提升的空間。
受文獻[11]的啟發,本文提出了一種基于結構稀疏表示的貝葉斯分類目標跟蹤算法。算法采用首幀獲得的目標樣本分塊和背景樣本分塊構建稀疏字典。在跟蹤過程中,每個候選目標的分塊都用稀疏字典進行稀疏重構,從而獲得候選目標的稀疏系數。為了更有效地利用稀疏系數里的相似度信息,設計了一種貝葉斯分類器對稀疏系數進行分類,分類器通過跟蹤過程中獲得的正負樣本進行訓練,可以有效地適應目標形態和光照變化。
本文的主要貢獻有以下幾點:
(1)傳統的稀疏表示目標跟蹤算法大多采用目標模板和瑣碎模板構建稀疏字典,瑣碎模板雖然可以在一定程度上降低遮擋或噪聲的干擾,但有時也會讓跟蹤算法錯誤地鎖定相似的目標。而本文算法則采用背景模板替代瑣碎模板,有效增加了算法對相似目標的識別能力。
(2)文獻[11]設計了一種Alignment-Pooling方法提取其相似度,但該方法只是提取了與被重構分塊相應的稀疏系數的相似度信息,而忽視了其他分塊稀疏系數里的相似度信息,同時該方法不具有學習能力,不能很好地適應目標形態的變化。本文算法采用貝葉斯分類器對候選目標的稀疏系數進行分類,可以更有效地利用稀疏系數里的相似度信息,同時具有學習能力,使其能夠適應目標形態的變化。
2 算法研究
2.1結構稀疏表示
算法采用灰度對樣本特征進行描述,假設在首幀獲得m1個目標模板[t1,t2,…,tm1]和m2個背景模板[b1,b2,…,bm2],其中,ti∈Rk×1為第i個目標模板特征向量,bi∈Rk×1為第i個背景模板特征向量,k為每個樣本的維數。稀疏字典D采用目標模板和背景模板構建,即D=[t1,t2,…,tm1,b1,b2,…,bm2]。將 D里的每個模板分成n個分塊[11],可以得到結構稀疏模板字典,其中,∈ Rp×1為第i個目標模板的第 j個分塊,為第i個背景模板的第j個分塊,p為每個分塊的維數。設y∈Rk×1為一候選目標,用同樣的分塊方法可以得到n個分塊 y1,y2,…,yn,其中,yi∈Rp×1為y的第i個分塊。將結構稀疏模板字典每個列向量和候選目標分塊進行?2規范后,yi可以用模板字典稀疏表示為:
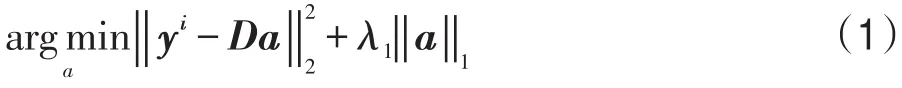
式中,a∈R(m1+m2)n×1為稀疏系數。式(1)為?范數最小
1化問題,對其求解有較大的運算量。文獻[13]證明了采用?2范數對稀疏系數進行約束可以獲得與?1范數對稀疏系數進行約束相似的識別效果,但前者的運算量大大減少,對式(1)改進如下:
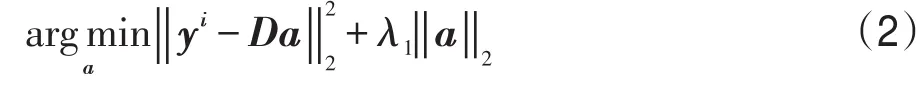
式(2)可以用下式求解:

式中,I為單位對角矩陣。
設Q=(DTD+λ1I)-1,則a=Qyi。由此可以看出,在模板字典不被更新的情況下,Q不必重復計算,可以減少算法的計算量。
2.2結構稀疏系數貝葉斯分類器
2.2.1分類器構建
設y為一候選目標,對其進行分塊處理后可以得到y1,y2,…,yn,yi∈Rp×1,其對應的結構稀疏系數分別為a1,a2,…,an,其中,∈ R(m1+m2)n×1。假如y為正確的目標,yi為y的第i個分塊,則結構稀疏字典里與ai對應的目標樣本的分塊能更好地對其進行重構,對應的稀疏系數會獲得較大的值,而與其不對應的目標樣本分塊和背景分塊不能很好地對其進行重構,其稀疏系數會獲得較小的值。根據這一規律,可以從每個候選目標的稀疏系數中獲得其相似度信息。
文獻[11]研究了一種Alignment-Pooling方法從稀疏系數中獲取相似度信息。該方法將每個分塊對應的稀疏系數進行累加,以分塊yi為例,其對應分塊的稀疏系數為,對這些稀疏系數進行累加可以得到該分塊的相似度,對于樣本整體y,相似度由全部分塊的相似度累加而成,即。從Alignment-Pooling方法的原理可以看出,它只考慮了與候選目標分塊對應的稀疏系數,而忽略了其他稀疏系數信息,同時該方法只是計算與候選目標分塊對應的稀疏系數的累加值。當目標形態發生變化時,稀疏系數會發生變化,而Alignment-Pooling方法不具有學習能力,不能適應這種變化。
本文使用貝葉斯分類器對樣本的所有稀疏系數進行處理,更深入地挖掘了所有稀疏系數中的相似度信息,分類器可以通過訓練提升分類能力,能夠更好地適應目標形態的變化。
y為一候選目標,對應的稀疏系數為 A=[a1, a2,…,an]T,其中,A∈Rnn(m1+m2)×1,。采用貝葉斯分類器以候選目標的稀疏系數作為特征進行分類。首先,計算A中每個元素屬于目標和屬于背景的概率,以元素為例,它屬于目標的概率為,屬于負樣本的概率為,其中1和0分別為正樣本和負樣本的標記。假設p(y=1)=p(y=0),計算A中每個元素屬于正負樣本的概率,并用下式計算候選目標y的相似度LK(y):
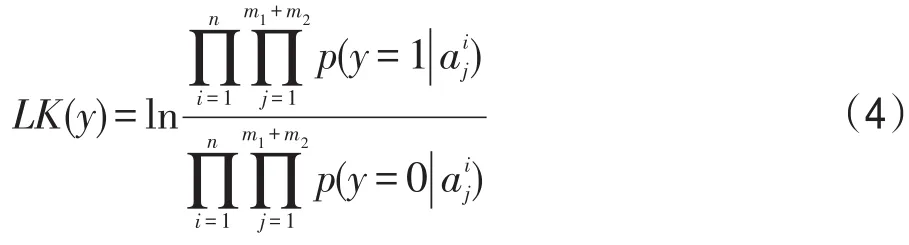
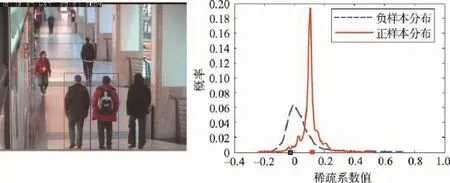
Fig.1 Principle of classifier圖1 分類器工作原理
圖1為分類器工作原理示意圖,左圖中,紅色方框和藍色方框分別表示真實目標和干擾目標。右圖中,紅色和藍色曲線為正樣本和負樣本稀疏系數的分布,紅色點和藍色點分別表示真實目標和干擾目標的稀疏系數。從圖中可以看出,紅色點屬于正樣本的概率高于其屬于負樣本的概率,而藍色點屬于負樣本的概率高于其屬于正樣本的概率。因此,分類器可以有效區分目標和相似目標或背景。
2.2.2分類器訓練
分類器用跟蹤過程中獲得的正負樣本進行訓練。假設跟蹤獲得的目標中點坐標為s=[x,y],正樣本采集范圍滿足,其中sp為正樣本的中點坐標,r1為正樣本采集范圍的半徑。負樣本的采集范圍滿足,其中sn為負樣本的中點坐標,r2為負樣本采集范圍。
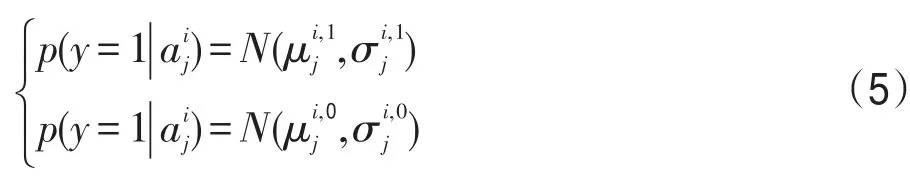

[F,G]的方差可以表示為:
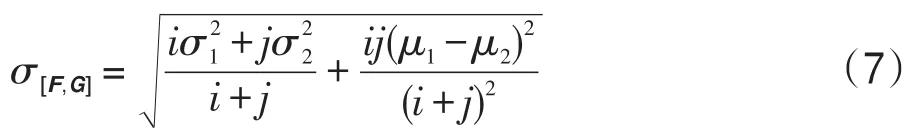
F可以看成前面若干幀獲得的訓練樣本的某個稀疏系數,G可以看成后面若干幀獲得的訓練樣本的某個稀疏系數。對分類器進行訓練的本質就是使用新獲得訓練樣本更新分類器的均值和方差。如果采用式(6)和(7)更新分類器的均值和方差,隨著跟蹤的進行,新的訓練樣本對分類器的貢獻會逐漸減小,這是因為i值將遠遠大于 j。為了解決這個問題,引入一個學習參數 l替換式(6)和(7)中的i/(i+j),使新的訓練樣本對分類器的貢獻保持在一定范圍內,正負樣本稀疏系數的均值可以用下式更新:

正負樣本稀疏系數的方差可以用下式更新:
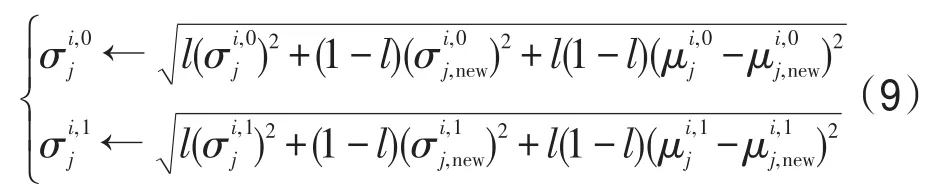
當目標形態發生變化時,其稀疏系數也會發生相應變化,使用正負樣本對分類器進行訓練,可以通過新獲得的目標的狀態調整每個稀疏系數的分布,使分類器能夠適應目標形態的變化,提高算法的抗干擾能力。
2.3目標跟蹤算法
本文算法在粒子濾波框架下進行,[z1,z2,…,zt]為前t幀的觀察值,則在第t幀時,目標狀態由下式計算:

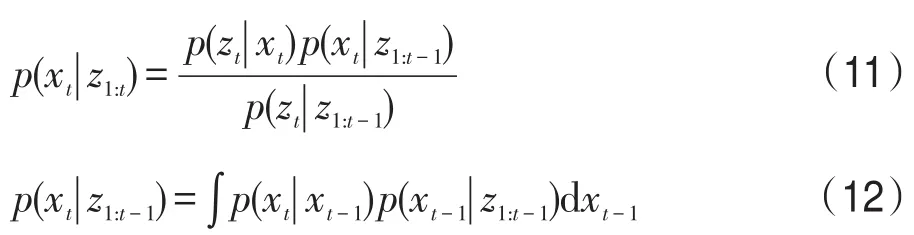
其中,p(zt|xt)為相似度變量;p(xt|xt-1)為狀態轉移變量。本文采用 Σ=[γ1,γ2,γ3,γ4,γ5,γ6]定義目標的狀態,它們分別是x方向坐標、y方向坐標、尺度、長寬比、旋轉角度和扭曲角度。在跟蹤過程中,假設這6個變量都是獨立的,且服從高斯分布,則可以用下式描述狀態轉移變量:

而相似度變量則與分類結果相關:

與文獻[12]類似,本文采用稀疏表示和增量學習相結合的方法更新字典里的目標模板,這里不再詳細介紹。至于字典里的背景模板,則每隔若干幀用負樣本進行更新。本文目標跟蹤算法流程見算法1。
算法1目標跟蹤算法
輸入:t幀圖像,首幀目標狀態。
1.for i=1:t
2.if i==1
3.構建初始結構稀疏模板字典D
4.end if
5.獲得正負訓練樣本
6.用式(2)計算正負訓練樣本的稀疏系數
7.用式(8)和(9)訓練貝葉斯分類器
8.用式(13)更新粒子狀態
9.用式(4)計算每個候選目標的相似度并獲得目標狀態
10.更新模板字典
11.end for
輸出:各幀目標狀態。
3 實驗
本文算法采用Matlab 2009b編程實現,運行電腦的CPU主頻為2.4 GHz,內存為4 GB。算法在粒子濾波框架下進行,粒子個數為600。為了兼顧計算量和跟蹤效果,每個樣本映射到32×32的矩陣上。稀疏字典由30個目標模板和50個背景模板構成,每個樣本分為9個分塊,式(2)中,λ1的取值為0.01[8]。在跟蹤過程中,每幀獲得10個正樣本和30個負樣本,每5幀進行一次分類器的訓練。圖2為式(8)和(9)中的學習參數l選取不同值時跟蹤算法在測試視頻“Trellis”時的跟蹤誤差(跟蹤誤差定義為真實目標中點與跟蹤結果中點的歐式距離,單位為像素)。可以看出,當沒有引入學習參數l時(即使用式(6)和(7)更新分類器),由于新獲得的樣本對分類器的貢獻逐漸變小,算法在后期偏離了目標。當l較小時(如l=0.6),新樣本占的權重較大,導致容易積累誤差,使跟蹤出現漂移。當l較大時(如l=0.99),新樣本占的權重較小,分類器不能充分反映目標的變化。經反復實驗,l取0.96時效果最理想。
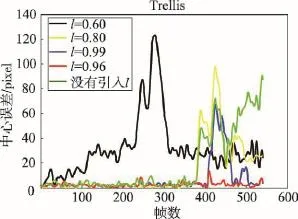
Fig.2 Tracking errors with different learning parameters圖2 不同學習參數下的跟蹤誤差
與此同時,還選擇了4種先進的目標跟蹤算法與本文算法進行比較,它們分別是L1算法[8]、ASL算法[11]、DSSM算法[15]和SCM算法[16],這些算法都是在粒子濾波框架下進行的,與本文算法有相同的狀態轉移模型,與本文算法具有可比性。算法在視頻“Woman-Sequence”、“Faceocc”、“Trellis”、“SYLV”、“Three-PastShop2cor”和“Board”上進行測試,這些視頻存在目標形態變化,光照變化,目標被遮擋或復雜背景的影響,對視頻中的目標進行跟蹤具有一定的挑戰性。

Fig.3 Tracking results圖3 跟蹤結果
第1個測試視頻是“WomanSequence”,視頻主要的難點是目標被遮擋。如圖3(a)所示,除文中算法與SCM算法外,其他算法均由于目標被遮擋的影響丟失了目標。說明本文構造的分類器在目標被部分遮擋時仍可以有效地區分目標。第2個測試視頻為“ThreePastShop2cor”,視頻主要測試在相似目標的干擾下目標跟蹤算法的性能。如圖3(b)所示,ASL算法和DSSM算法均受干擾目標的影響,鎖定了錯誤的目標。L1算法在178和264幀時鎖定了干擾目標,本文算法和SCM算法不受干擾目標影響,完成了跟蹤任務。第3個測試視頻為“Trellis”,視頻中的目標存在形態變化和光照變化。從圖3(c)可以看出,除本文算法和DSSM算法外,其他算法均由于目標光照和形態變化丟失了目標。第4個測試視頻為“Faceocc”,視頻目標存在被遮擋的現象。從圖3(d)可以看出,DSSM算法在跟蹤過程中丟失了目標,而本文算法、L1算法、ASL算法和SCM算法則完成了跟蹤任務。第5個測試視頻為“Board”,視頻主要測試算法在復雜背景和目標翻轉的時候跟蹤算法的性能。如圖3(e)所示,在前373幀,本文算法、SCM算法和ASL算法沒有丟失目標,但在第544幀,由于目標出現了翻轉,所有算法均偏離了目標。第6個測試視頻為“SYLV”,該視頻為一個長視頻,共有1 344幀,視頻中被跟蹤的玩偶存在拍攝角度的變化、光照的變化和尺度的變化。如圖3(f)所示,在第546幀,L1算法丟失了目標,在第994幀,ASL和SCM算法丟失了目標,在第1 335幀,除了DSSM算法沒有丟失目標外,所有算法均不同程度地偏離了目標。
圖4為5種算法在5個視頻中的跟蹤誤差,表1統計了平均跟蹤誤差,最好結果用加粗字體標出,第二好的結果用下劃線標出。從表中可以看出,本文算法在視頻“WomanSequence”、“ThreePastShop2cor”和“Trellis”中取得了最小的平均誤差,在視頻“Faeocc”和“SYLV”中有第二小的平均誤差。
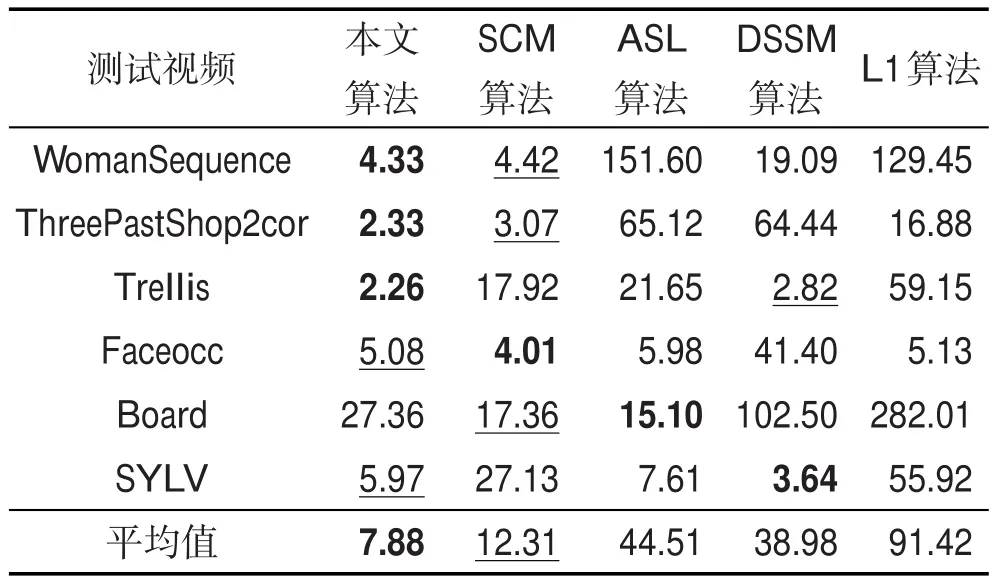
Table 1 Means of tracking errors表1 跟蹤平均誤差
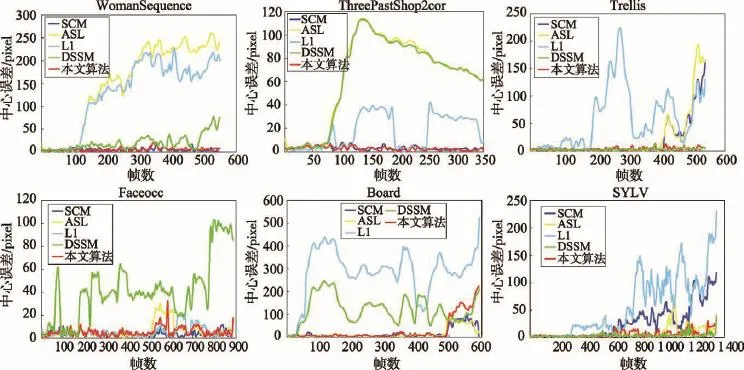
Fig.4 Tracking errors圖4 跟蹤誤差
平均誤差只能度量跟蹤結果中心點的距離,不能反映跟蹤結果形狀與真實目標形狀之間的差異,實驗進一步采用PASCAL VOC標準[17]度量跟蹤成功率。該標準用跟蹤結果與真實結果的重合率判斷某幀跟蹤是否成功,設跟蹤結果為Ar,真實結果為Ag,則跟蹤重合率Rate為:

式中,S(?)為計算面積,如果某幀的Rate≥50%,則認為該幀跟蹤成功,否則認為跟蹤失敗。
表2統計了5種算法在5個測試視頻中的跟蹤成功率,最好結果用下劃線標出。從表中可以看出,本文算法在視頻“WomanSequence”、“ThreePastShop2cor”、“Board”中有最高的成功率,在“SYLV”中有第二高的成功率。從測試結果可以看出,本文算法具有較強的抗光照變化、形態變化、遮擋和復雜背景的能力。本文算法與ASL算法[11]都采用結構稀疏表示的思想構建跟蹤算法,從實驗結果可以看出,本文算法的性能要優于ASL算法。
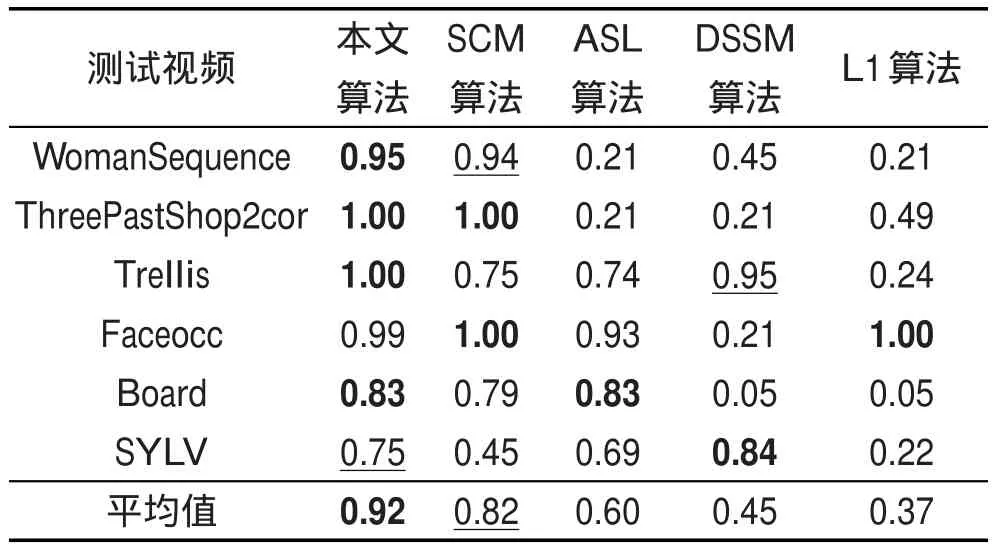
Table 2 Success rates of tracking 表2 跟蹤成功率
5種算法幀均計算時間從短到長依次為:本文算法(0.15 s/幀),ASL算法(0.22 s/幀),DSSM算法(0.73 s/幀)、SCM算法(2.13 s/幀)和L1算法(3.03 s/幀)。可見,本文算法在提高跟蹤性能的同時具有較快的運算速度,這得益于采用2范數對目標方程進行稀疏約束,減少了解目標方程的計算量。
4 結束語
本文研究了一種基于結構稀疏表示和貝葉斯分類原理的目標跟蹤算法。算法構建含有目標和背景信息的稀疏表示模板字典,通過結構稀疏表示的方式對樣本進行稀疏重構,在重構過程中,采用?2最小化約束替代傳統的?1最小化約束,提高了算法的速度。通過正負樣本構建和訓練貝葉斯分類器,該分類器可以有效挖掘結構稀疏系數里的相似度信息,同時具有學習能力,能夠適應目標形態和光照等變化。通過6組對比實驗驗證了本文算法具有較高的魯棒性、準確性和穩定性。
雖然本文算法取得了一定的效果,但是還存在一些不足,比如在視頻Board中,當目標出現翻轉時,算法無法適應目標形態的變化,丟失了目標,在未來工作中,將進行深入研究克服這個問題。
[1]Hou Zhiqiang,Han Chongzhao.A survey of visual tracking[J]. ActaAutomatica Sinica,2006,32(4):603-617.
[2]Zhang Huanlong,Hu Shiqiang,Yang Guosheng.Video object tracking based on appearance models learning[J].Journal of Computer Research and Development,2015,52(1): 177-190.
[3]Comaniciu D,Member V R,Meer P.Kernel-based object tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2003,25(5):564-575.
[4]Li Yuan,Ai Haizhou,Yamashita T,et al.Tracking in low frame rate video:a cascade particle filter with discriminative observers of different life spans[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30 (10):1728-1740.
[5]Wright J,Yang A Y,Ganesh A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,31(2):210-227.
[6]Agarwal S,Roth D.Learning a sparse representation for object detection[C]//LNCS 2353:Proceedings of the 7th European Conference on Computer Vision,Copenhagen,Denmark,May 28-31,2002.Berlin,Heidelberg:Springer,2002: 113-127.
[7]Song Xiangfa,Jiao Licheng.Classification of hyperspectral remote sensing image based on sparse representation and spectral information[J].Journal of Electronic and Information Technology,2012,34(2):268-272.
[8]Mei Xue,Ling Haibin.Robust visual tracking using ?1 min-imization[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision,Kyoto,Japan,Sep 29-Oct 2,2009.Piscataway,USA:IEEE,2009:1436-1443.
[9]Wang Dong,Lu Huchuan,Yang M H.Online object tracking with sparse prototypes[J].IEEE Transactions on Image Processing,2013,22(1):314-325.
[10]Wang Baoxian,Zhao Baojun,Tang Linbo,et al.Robust visual tracking algorithm based on bidirectional sparse representation[J].Acta Physica Sinica,2014,63(23):166-176.
[11]Jia Xu,Lu Huchuan,Yang M H.Visual tracking via adaptive structural local sparse appearance model[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 16-21,2012.Piscataway,USA:IEEE,2012:1822-1829.
[12]Hou Yue?en,Li Weiguang,Sekou J,et al.Target tracking algorithm with structured sparse representation based on ranks[J].Journal of South China University of Technology: Natrual Science Edition,2013,41(11):23-29.
[13]Yang Meng,Zhang Lei,Zhang D,et al.Relaxed collaborative representation for pattern classification[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 16-21,2012.Piscataway,USA:IEEE,2012:2224-2231.
[14]Diaconis P,Freedman D.Asymptotics of graphical projection pursuit[J].TheAnnals of Statistics,1984,12(3):793-815.
[15]Zhuang Bohan,Lu Huchuan,Xiao Ziyang,et al.Visual tracking via discriminative sparse similarity map[J].IEEE Transactions on Image Processing,2014,23(4):1872-1881.
[16]Zhong Wei,Lu Huchuan,Yang M H.Robust object tracking via sparsity-based collaborative model[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 16-21,2012.Piscataway,USA:IEEE,2012:1838-1845.
[17]Everingham M,van Gool L,Williams C K I,et al.The Pascal visual object classes(VOC)challenge[J].International Journal of Computer Vision,2010,88(2):303-338.
附中文參考文獻:
[1]侯志強,韓崇昭.視覺跟蹤技術綜述[J].自動化學報, 2006,32(4):603-617.
[2]張煥龍,胡士強,楊國勝.基于外觀模型學習的視頻目標跟蹤方法綜述[J].計算機研究與發展,2015,52(1):177-190.
[7]宋相法,焦李成.基于稀疏表示及光譜信息的高光譜遙感圖像分類[J].電子與信息學報,2012,34(2):268-272.
[10]王保憲,趙保軍,唐林波,等.基于雙向稀疏表示的魯棒目標跟蹤算法[J].物理學報,2014,63(23):166-176.
[12]侯躍恩,李偉光,四庫,等.基于排名的結構稀疏表示目標跟蹤算法[J].華南理工大學學報:自然科學版,2013,41 (11):23-29.

HOU Yue?en was born in 1983.He received the Ph.D.degree in machine manufacture and automation from South China University of Technology in 2014.Now he is a lecturer at Jiaying University.His research interests include robotics technology and machine vision,etc.
侯躍恩(1983—),男,廣東梅州人,2014年于華南理工大學獲得博士學位,現為嘉應學院講師,主要研究領域為機器人技術,機器視覺等。

LI Weiguang was born in 1958.He received the Ph.D.degree in machine manufacture and automation from South China University of Technology in 1999.Now he is a professor at South China University of Technology.His research interests include robotics technology and machine vision,etc.
李偉光(1958—),男,江西南昌人,1999年于華南理工大學獲得博士學位,現為華南理工大學教授,主要研究領域為機器人技術,機器視覺等。
Structured Sparse Representation Classification Object TrackingAlgorithm?
HOU Yue?en1+,LI Weiguang2
1.School of Computer,Jiaying University,Meizhou,Guangdong 514000,China 2.School of Mechanical andAutomotive Engineering,South China University of Technology,Guangzhou 510000,China +Corresponding author:E-mail:houyueen@jyu.edu.cn
In order to enhance the robustness and precision of tracking algorithm in complex scenarios,this paper proposes a Bayes classification based structured sparse representation object tracking algorithm.Firstly,in the first frame, a sparse dictionary is obtained,which contains target and background templates,as well as positive and negative samples.Secondly,all samples are linearly combined based on the idea of structured sparse representation,hence the coding coefficients can be gotten.Thirdly,a kind of Bayes classifier is designed,which is trained by the coding coefficients of positive and negative samples.The classifier is able to detect the candidate target and obtain the likelihood information of them.Fourthly,the dictionary is updated by combining incremental subspace learning and sparse representation method together.Finally,the proposed tracker performs favorably against 4 state-of-the-art trackers on 6 challenging video sequences.
object tracking;particle filter;sparse representation;dictionary;Bayes classification
2015-10,Accepted 2015-12.
10.3778/j.issn.1673-9418.1511060
A
TP391
*The National High Technology Research and Development Program of China Grant No.2015AA043005(國家高技術研究發展計劃(863計劃)).
CNKI網絡優先出版:2015-12-18,http://www.cnki.net/kcms/detail/11.5602.TP.20151218.1038.002.html
